







文章目录
首页
首页帖子的分页展示(热度排行重构)
此时,还是按照时间和帖子类型进行默认的排序展示
由于前端视图层需要展示,这个帖子具体的内容以及这个帖子是谁发的,所以需要封装对象,分别对应帖子的实体和帖子的发布人的user实体,这两个封装在一个map集合中,所有的帖子形成一个map的list集合(前端使用这些数据进行渲染展示)。
注意需要手动封装一个分页的实体类,实现前端的按照这个分页实体类进行分页(主要是按照帖子总数动态的分页,每页只显示limit条数据)动态计算当前页,总页数,开视页与结束页—前端附近放了一个动态的分页查询帖子的动态url链接,每次点击一个新页–计算新的分页参数–进行controller业务进行插叙----这个项目就是使用sql的物理分页!!!
package com.newcoder.community.entity;
/**
* @Author:jiangll
* @Date:2022-02-27-15:44
* @Description:com.newcoder.community.entity(用来分装的分页类)
* @version:1.0
*/
/*用于配置封装分页的信息*/
public class Page {
// 当前页码(输入的参数)
private int current = 1;//注意这个初始化的值,很关键,相当于每次进入首页总是展示第一页的帖子
// 显示上限(输入的参数)
private int limit = 10;
// 数据总数--总的帖子的数量(用于计算总页数)
private int rows;
// 查询路径(用于复用分页链接,第几页第几页实际都是一个链接)
private String path;
public int getCurrent() {
return current;
}
public void setCurrent(int current) {
//防止用户将页面数写成了负整数
if (current >= 1) {
this.current = current;
}
}
public int getLimit() {
return limit;
}
public void setLimit(int limit) {
//每页显示的上下限必须是合法的数据
if (limit >= 1 && limit <= 100) {
this.limit = limit;
}
}
public int getRows() {
return rows;
}
public void setRows(int rows) {
if (rows >= 0) {
this.rows = rows;
}
}
//用于分页的页码之间的跳转,实际保证还是在首页的路径
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
/**
* 获取当前页的起始行
*
* @return
*/
public int getOffset() {
// current * limit - limit
return (current - 1) * limit;
}
/**
* 获取总页数
*
* @return
*/
public int getTotal() {
// rows / limit [+1]
if (rows % limit == 0) {
return rows / limit;
} else {
return rows / limit + 1;
}
}
/**
* 获取起始页码(当前页的相邻的前面2页)
*
* @return
*/
public int getFrom() {
int from = current - 2;
return from < 1 ? 1 : from;
}
/**
* 获取结束页码(获取相邻页的后面两页)
*
* @return
*/
public int getTo() {
int to = current + 2;
int total = getTotal();
return to > total ? total : to;
}
}
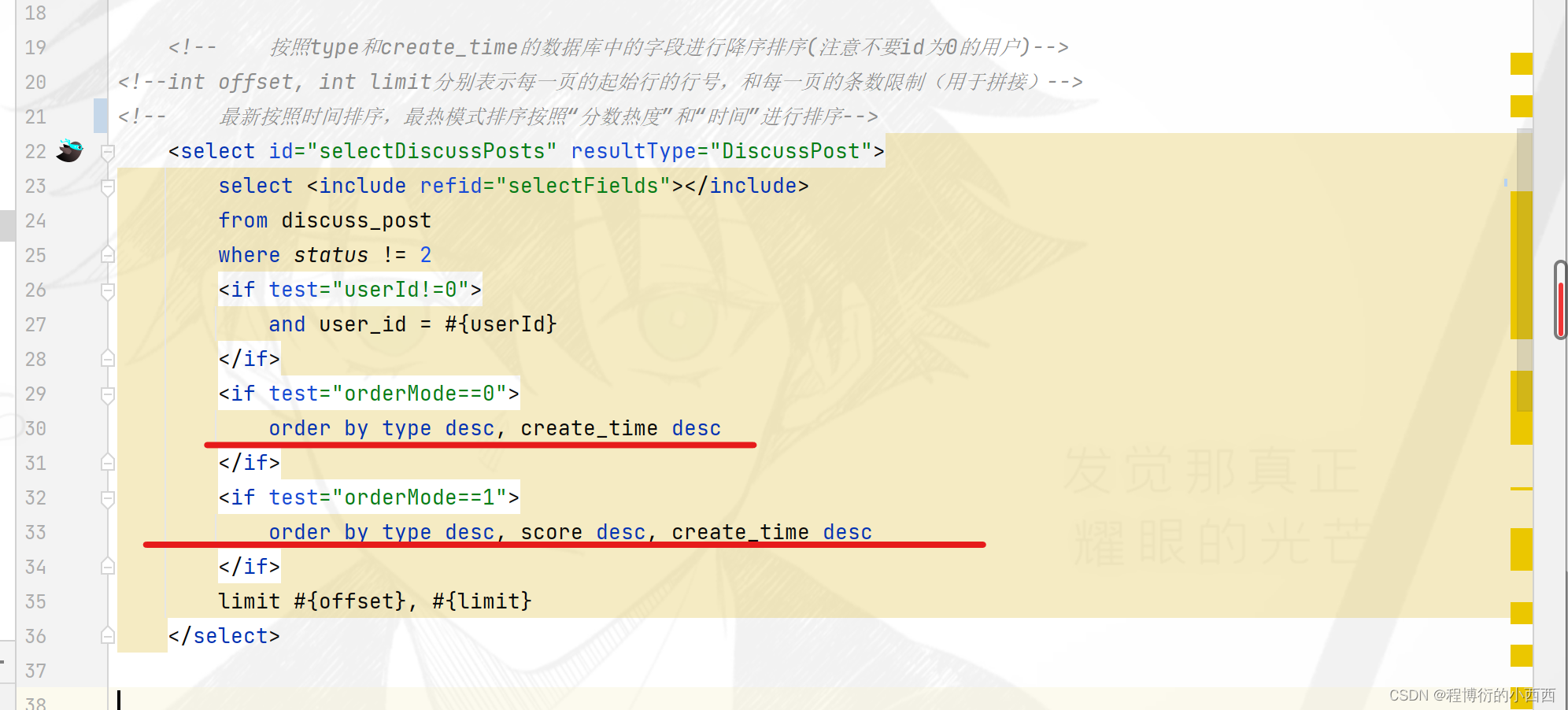
分页查询帖子的具体的sql语句(0就是查询全部),按照帖子的排序类型进行排序,默认就是按照时间来进行排序
<select id="selectDiscussPosts" resultType="DiscussPost">
select <include refid="selectFields"></include>
from discuss_post
where status != 2
<if test="userId!=0">
and user_id = #{userId}
</if>
<if test="orderMode==0">
order by type desc, create_time desc
</if>
<if test="orderMode==1">
order by type desc, score desc, create_time desc
</if>
limit #{offset}, #{limit}
</select>
用户注册与登录功能
用户邮箱注册
邮箱工具类的配置
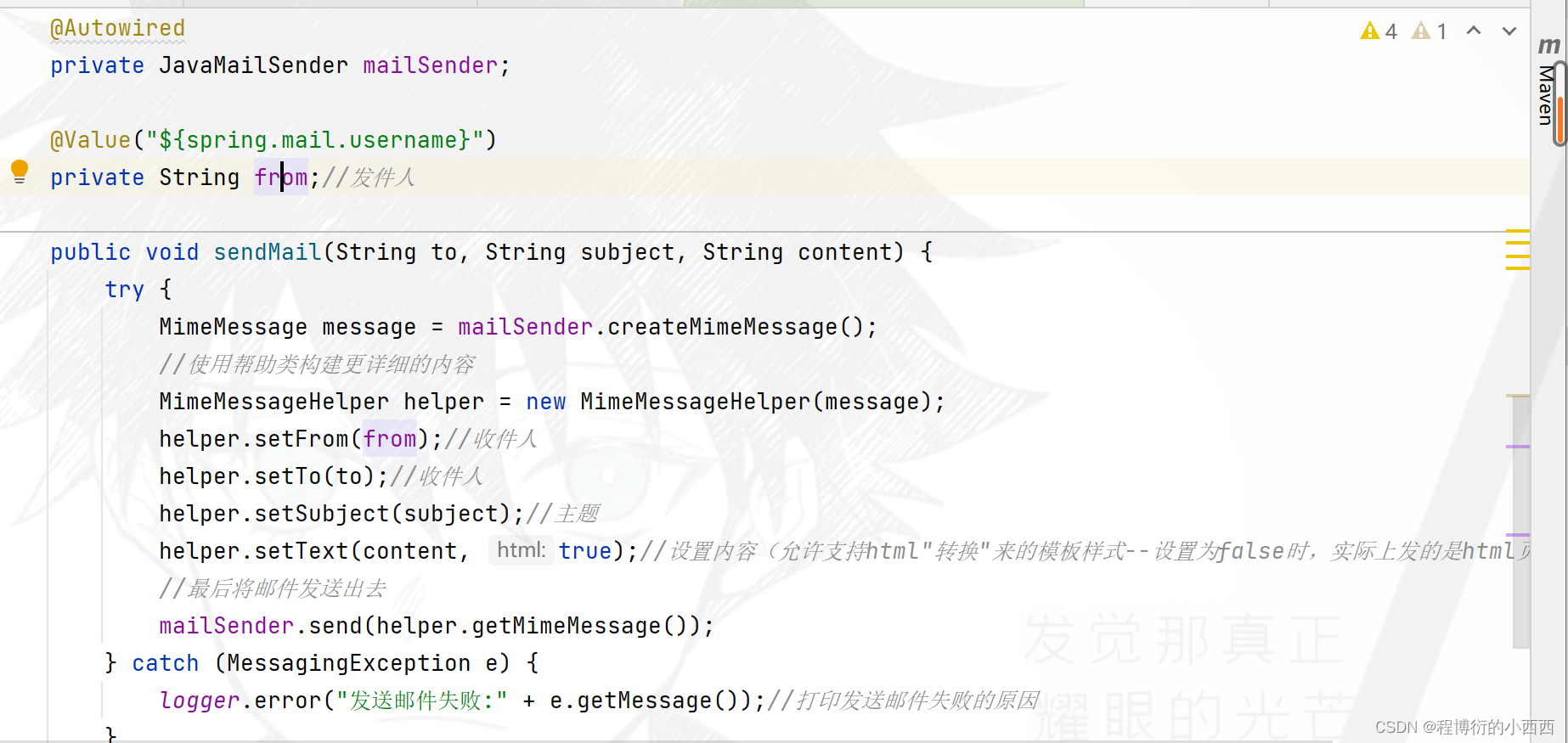
使用spring家的mail依赖的工具包,配置好mailclient定义好邮件发送的模板
发送的对象的邮件。发送的主题和具体的内容
注册的具体逻辑
前端提交注册的表单信息封装为User对象,后端进行检查(账号,密码,邮箱–用于注册激活)
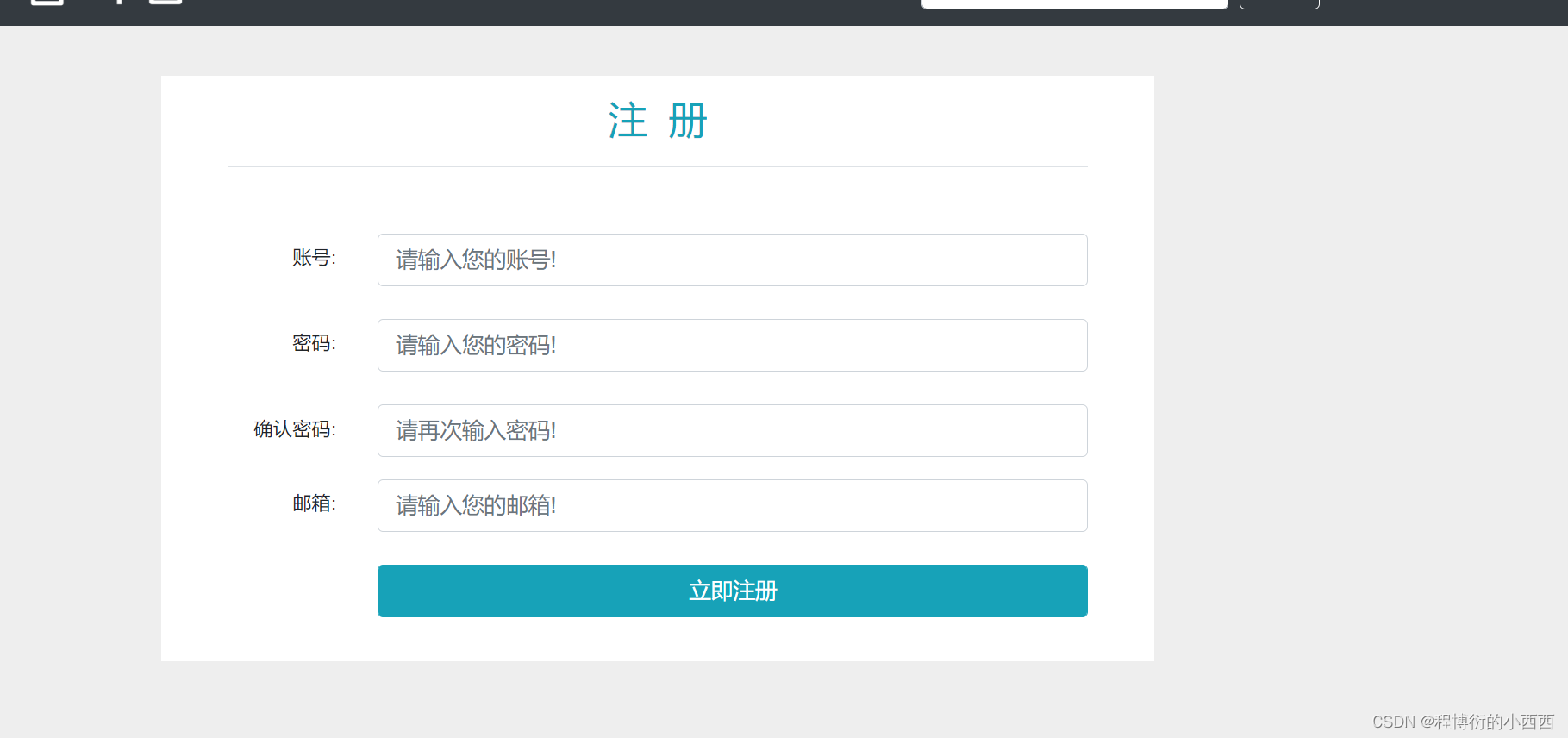
注册用户检查的逻辑:有一个封装错误信息的容器(容器为空–说明注册成功了)
检查1:账号密码以及邮箱非空—有错误封装错误信息在map集合,直接返回
检查2:查询数据库是否有账号和邮箱重复了—有错误封装错误信息在map集合,直接返回
步骤1:用户注册的数据合法,开始后台辅助帮助注册–对用户的密码进行盐值加密后存入mysql(防止有人窃取密码)+设置默认的用户权限、头像的url、用户注册的时间+激活码(用于邮箱激活,前端激活码与mysql的激活码进行对比)&&默认激活状态为未激活
步骤2:发送注册邮件给用户的邮箱,邮件的内容是一条激活的链接—userid+激活码作为路径变量(点击触发后台的注册激活的业务)—激活码的作用就是防止恶意的post请求进行乱码的激活;注意由于拼接的激活路径是字符串&&用户的邮箱,使用thymeleaf的模板引擎将这两个信息传入一个模板的html页面,最后发给邮箱的信息是一个thymeleaf的邮箱模板html信息,应该会自动渲染给用户展示的!!
最后:如果最后没有问题,返回的map是个空的容器!!
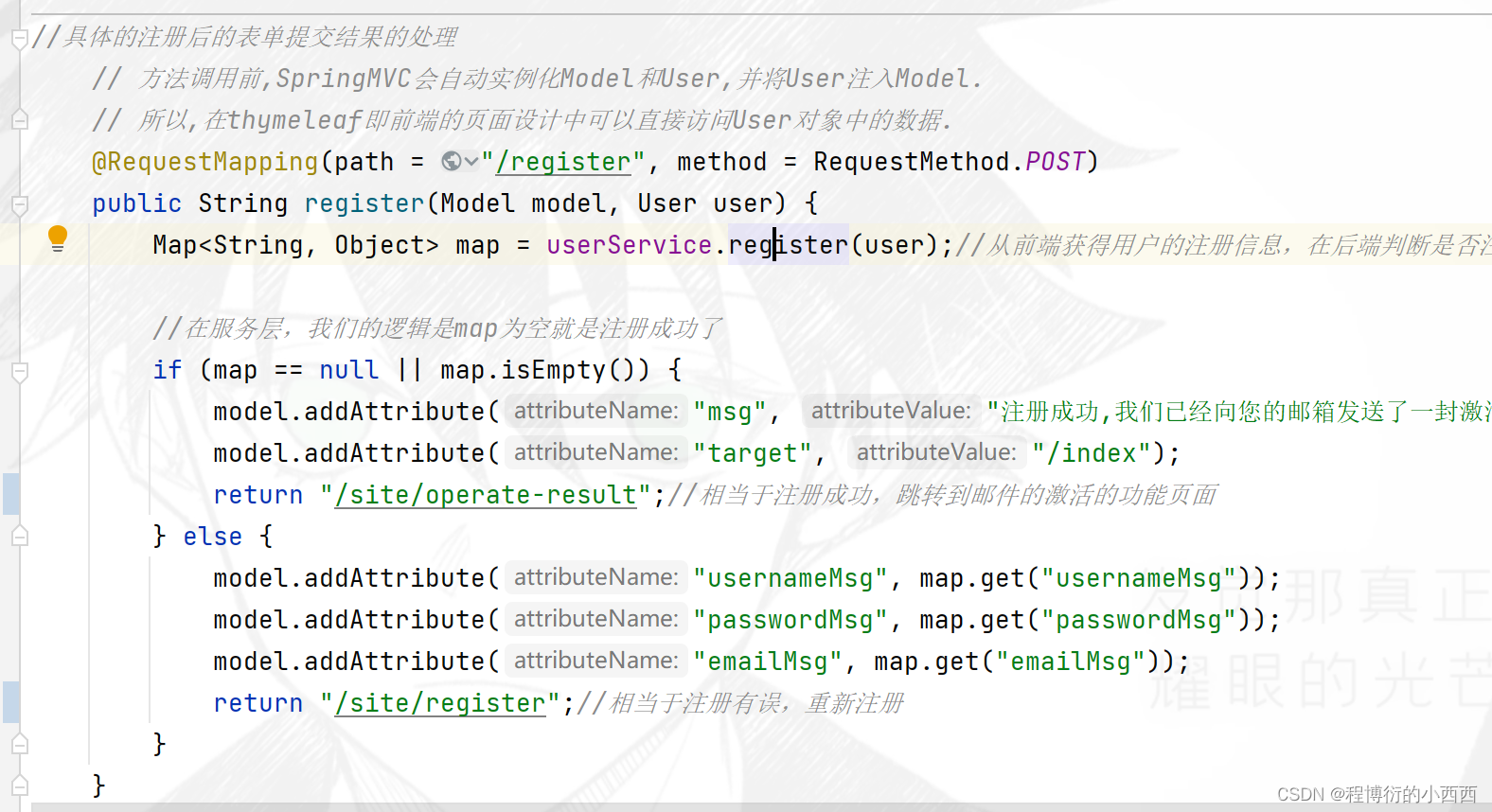
controller调用register的具体的service服务之后,判断map集合是否为空----
1.如果为空,说明激活成功,返回注册成功的页面,并model传入注册成功的提示信息(注册成功,去邮箱激活)+主页的路径,用于让页面的跳转;
2. 如果不为空,将封装的错误信息传入的前端的注册的页面,重新进行注册
// 注册用户的服务
public Map<String, Object> register(User user) {
Map<String, Object> map = new HashMap<>();
//注册的用户信息正确且没有重复
// 空值处理(优先处理)
if (user == null) {
throw new IllegalArgumentException("参数不能为空!");
}
if (StringUtils.isBlank(user.getUsername())) {
map.put("usernameMsg", "账号不能为空!");
return map;
}
if (StringUtils.isBlank(user.getPassword())) {
map.put("passwordMsg", "密码不能为空!");
return map;
}
if (StringUtils.isBlank(user.getEmail())) {
map.put("emailMsg", "邮箱不能为空!");
return map;
}
// 验证账号(去数据库查询是否已经存在该用户,各种非空值)
User u = userMapper.selectByName(user.getUsername());
if (u != null) {
map.put("usernameMsg", "该账号已存在!");
return map;
}
// 验证邮箱(去数据库查询是否已经存在该邮箱)
u = userMapper.selectByEmail(user.getEmail());
if (u != null) {
map.put("emailMsg", "该邮箱已被注册!");
return map;
}
// 开始注册真正的用户---合法的用户会收到邮件
user.setSalt(CommunityUtil.generateUUID().substring(0, 5));//设置随机的盐值并保存给用户,用于md5加密
user.setPassword(CommunityUtil.md5(user.getPassword() + user.getSalt()));//利用用户设置的密码和盐值进行加密
user.setType(0);//用户的权限设置(默认为用户权限)
user.setStatus(0);//默认为非激活的状态
user.setActivationCode(CommunityUtil.generateUUID());//设置激活码
//牛客网的http://images.nowcoder.com/head/1t.png有1000个这样的头像,从中随机的挑选一张(使用占位符)
user.setHeaderUrl(String.format("http://images.nowcoder.com/head/%dt.png", new Random().nextInt(1000)));
user.setCreateTime(new Date());
userMapper.insertUser(user);//最终将用户添加到库里
// 激活邮件(能够发送到用户的邮件中)的API接口的使用
Context context = new Context();//需要传入thymeleaf的模板文件的上下文内容
context.setVariable("email", user.getEmail());
// http://localhost:8080/community/activation/101/ActivationCode
String url = domain + contextPath + "/activation/" + user.getId() + "/" + user.getActivationCode();
context.setVariable("url", url);
String content = templateEngine.process("/mail/activation", context);//具体的模板html的路径
mailClient.sendMail(user.getEmail(), "激活账号", content);//最终发送邮件
return map;//最后的空map表示注册激活没有问题
}
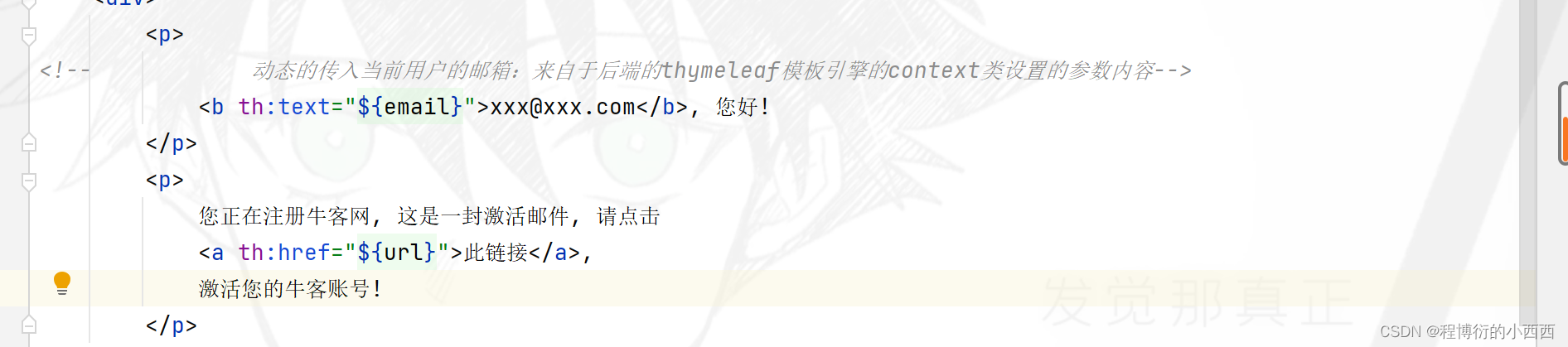
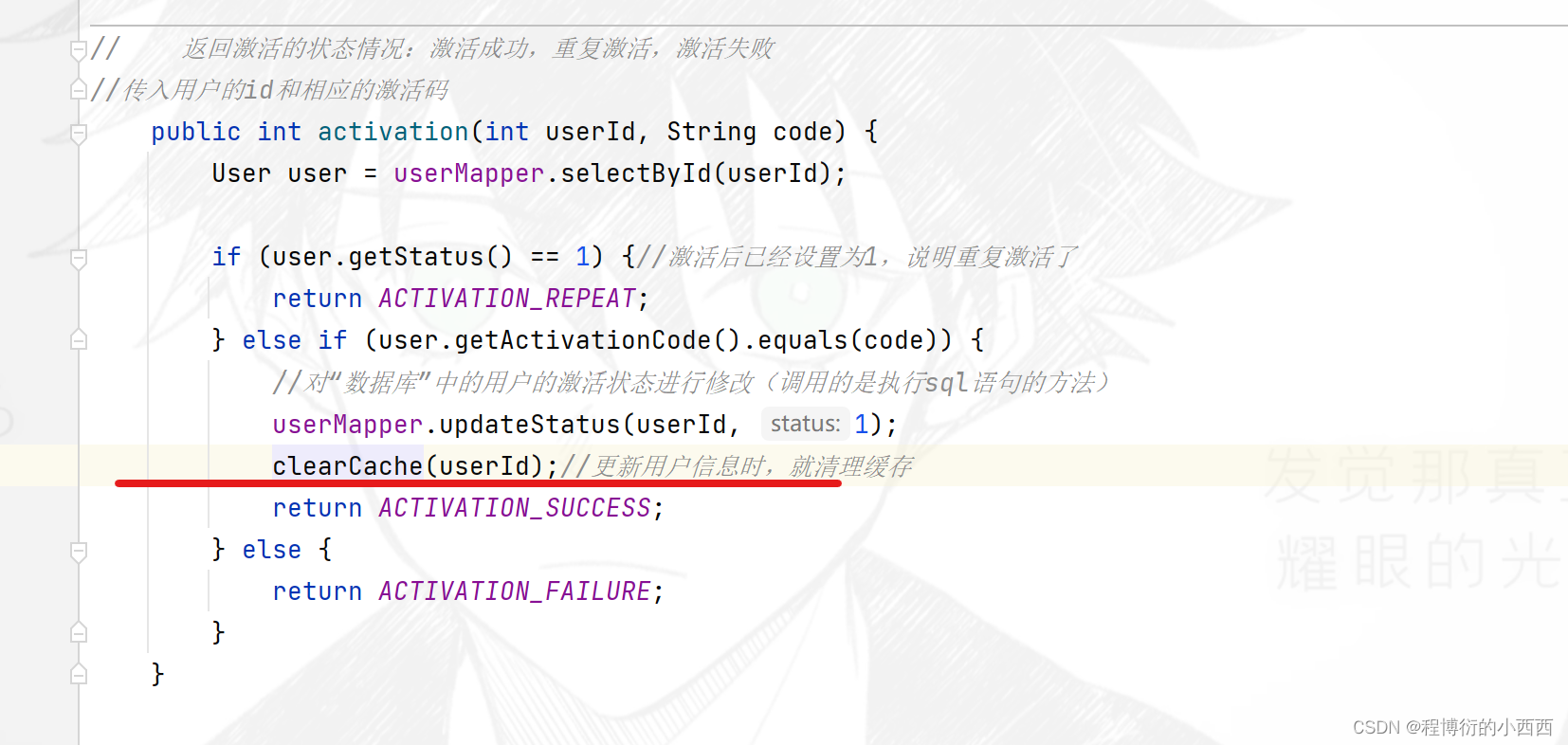
激活的具体逻辑(用户点击激活链接)
提取激活链接的路径变量:用户的id和激活码(防止有人攻击—恶意调用接口进行激活)
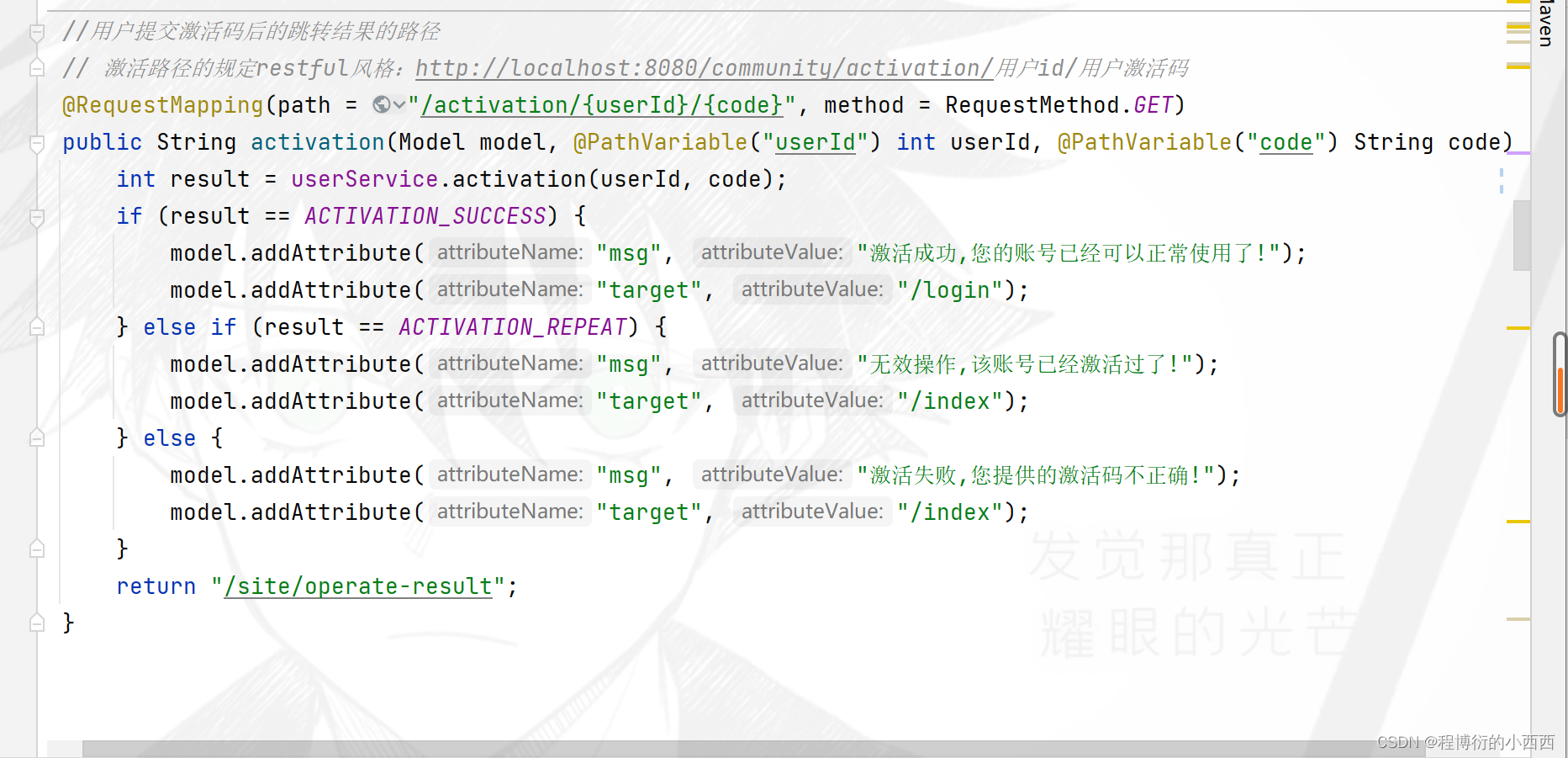
调用的激活的业务的三种情况:重复的激活,激活成功,激活失败----返回三种情况的码信息,让controller判断
1.首先根据userid获取用户实体的USer的信息,判断激活码是否已经变为激活的状态,如果是,直接返回重复激活的状态码给controller;
2.没有激活,判断前端传入的路径变量的激活码和数据库当时注册时的激活码是否一致:
2.1 激活码一致,将用户的激活的状态改为1已经激活,并存入数据库,返回激活成功;
2.2 激活码不一致,直接返回,激活失败的状态码。
controller层调用的激活的业务的service:重复的激活,激活成功,激活失败----返回三种情况的码信息,让controller判断,根据激活码处理结果的情况,进行将结果信息model给处理结果页面(operate-result),并分配不同的跳转链接的路径。
1.如果是激活成功,model的信息就是注册成功,并给的跳转链接是登录的页面;
2.如果激活失败或者重复激活,model错误的信息,并跳转到论坛的首页。
// 返回激活的状态情况:激活成功,重复激活,激活失败
//传入用户的id和相应的激活码
public int activation(int userId, String code) {
User user = userMapper.selectById(userId);
if (user.getStatus() == 1) {//激活后已经设置为1,说明重复激活了
return ACTIVATION_REPEAT;
} else if (user.getActivationCode().equals(code)) {
//对“数据库”中的用户的激活状态进行修改(调用的是执行sql语句的方法)
userMapper.updateStatus(userId, 1);
clearCache(userId);//更新用户信息时,就清理缓存
return ACTIVATION_SUCCESS;
} else {
return ACTIVATION_FAILURE;
}
}

用户登录与退出
验证码登录的逻辑(redis)
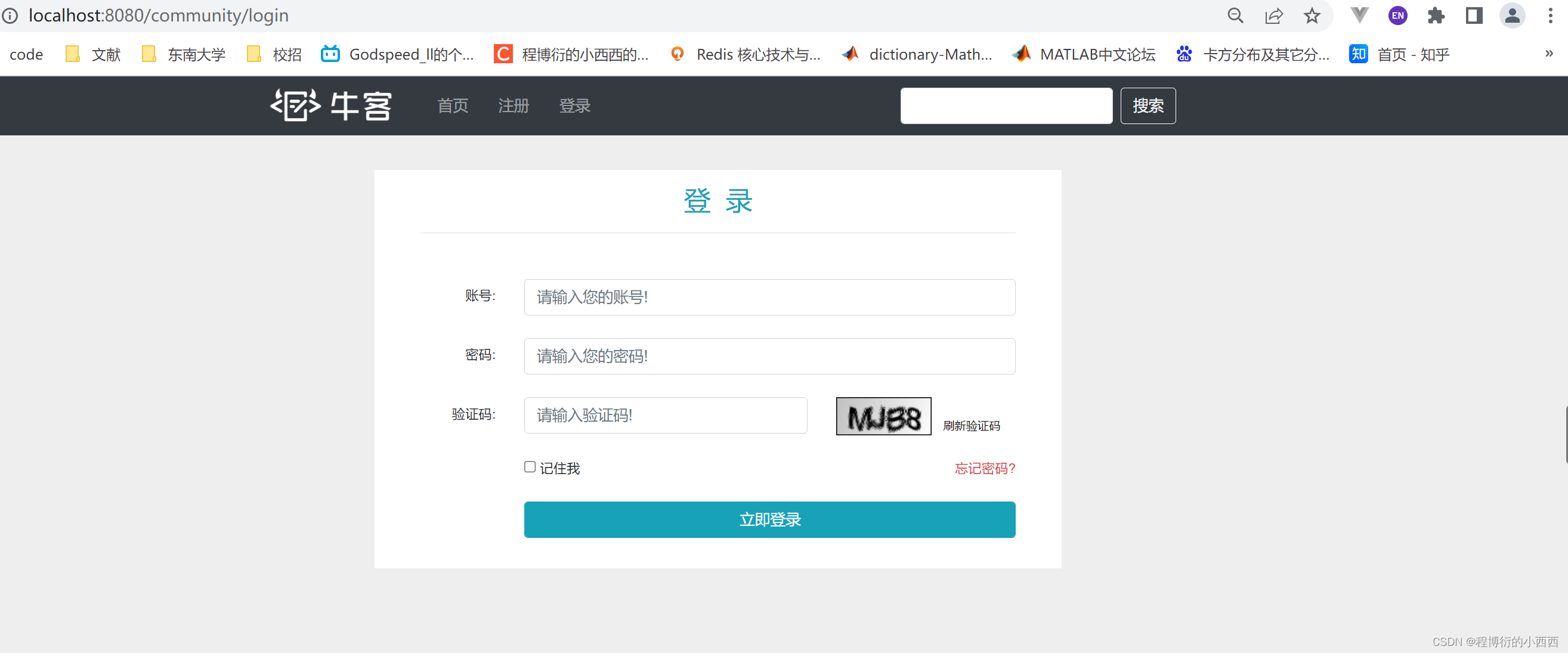
验证码的生成与存储(API)
相关的配置:创建一个验证码上的图片的配置方法,设定验证码的长度+验证码图片的颜色字体大小等;配置好KaptchaProducer的属性
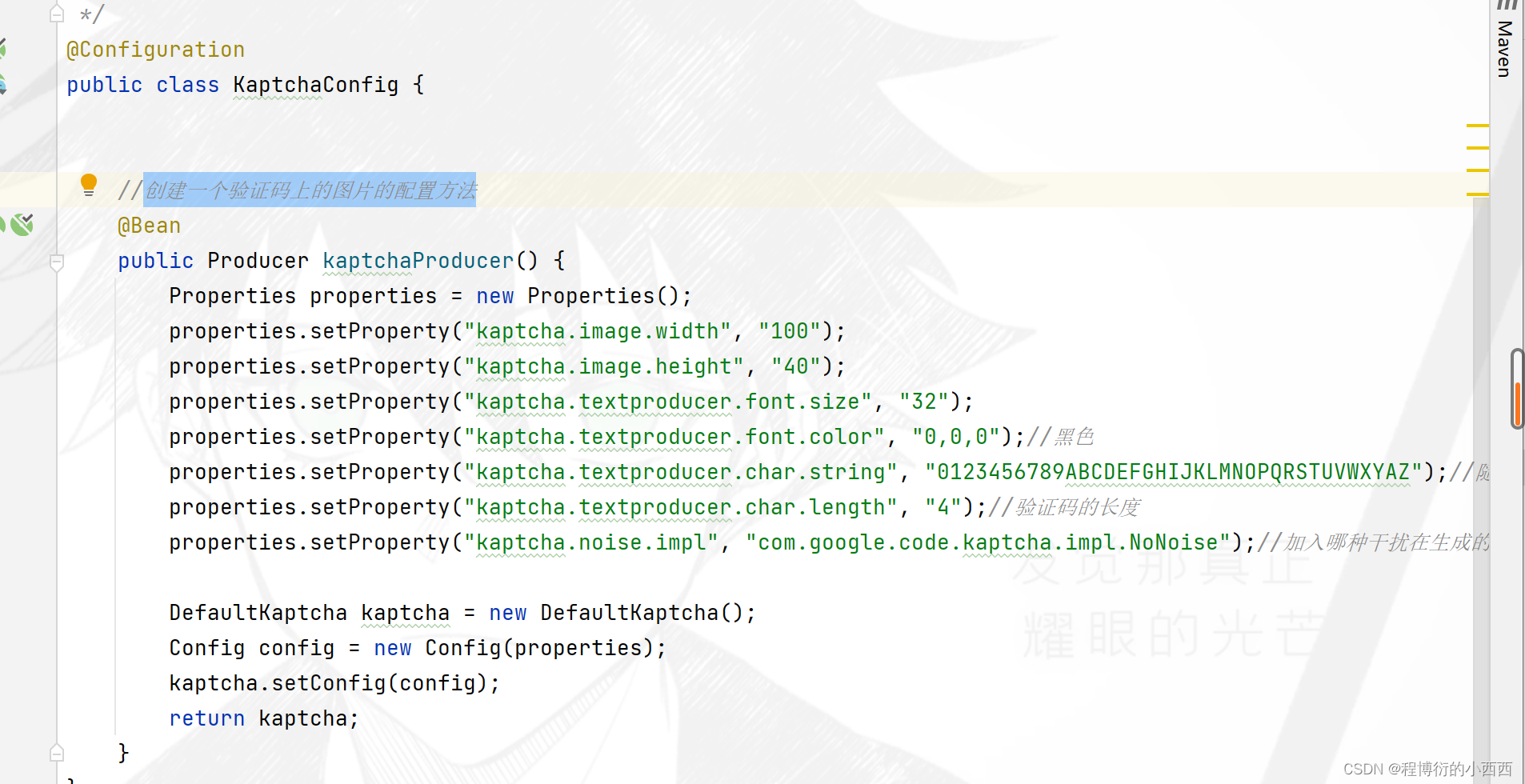
注意已进入登录的页面,就会触发AJax异步请求验证码的业务的服务(本事给一个随机的传入的参数,但是后端业务不会真正的使用这个参数,只不过是实现不断的调用验证码的生成的业务)

给一个kaptcha分配一个临时拥有者的id,这个id存放在cookie中(cookie的有效时间也是60秒),用这个id作为redis的键–验证码作为具体的值,这个key的过期时间设置为60秒。(不直接将验证码放在session中,是为了防止恶意的登录攻击)
1.利用kaptchaProducer生成一个验证码text,并将这个验证码生成为图片;
2.为这个验证码生成一个随机的ownerid,实现将这个ownerid存放在cookie中,对应的cookie的name是"kaptchaOwner",value就是ownerid,设定cookie的过期时间是60秒;
3.将验证码的真实text值,存放在redis中,对应的key就是ownerid,对应的value就是验证码text,同样设定的过期时间也是60秒(用户登录时与redis的验证码进行对比验证);
4.最后将生成的验证码图片,以IO流(OutputStream)的方式传入前端展示,传给浏览器。(用户视觉读取验证码)

//redis优化后de验证码登录(实际上是cookie的作用获取验证码的键,再从redis获取值)
@RequestMapping(path = "/kaptcha", method = RequestMethod.GET)
public void getKaptcha(HttpServletResponse response) {
// 生成验证码text
String text = kaptchaProducer.createText();
BufferedImage image = kaptchaProducer.createImage(text);//验证码图片
// 验证码的临时归属(暂时的存在cookie里)
String kaptchaOwner = CommunityUtil.generateUUID();
Cookie cookie = new Cookie("kaptchaOwner", kaptchaOwner);
cookie.setMaxAge(60);//60秒失效
cookie.setPath(contextPath);
response.addCookie(cookie);
// 将验证码存入Redis(原来的验证码存在了session)
String redisKey = RedisKeyUtil.getKaptchaKey(kaptchaOwner);
redisTemplate.opsForValue().set(redisKey, text, 60, TimeUnit.SECONDS);
// 将突图片输出给浏览器
response.setContentType("image/png");
try {
OutputStream os = response.getOutputStream();
ImageIO.write(image, "png", os);
} catch (IOException e) {
logger.error("响应验证码失败:" + e.getMessage());
}
}
登录判断逻辑(登录凭证redis)
前端提交了登录的表单信息(用户名+密码+验证码+记住我Rememeber Me+Cookie中的Ownerid),后端根据这个来验证用户的登录情况
判断1- -验证码:首先根据前端的cookie中的ownerid来获取redis缓存中的真实的验证码信息,对比前端用户传过来的验证码,比较两个是否一致,如果不一致,直接model错误的信息,并重新返回到登录的页面;
判断2- -判断用户名&密码&记住我过期时间:根据记住我设定登录凭证的过期时间(记住30天,不记住12个小时),userService.login的业务的调用----具体如下(判断用户名和密码和激活状态,生成新的登录凭证存入redis缓存中)。
结果- -成功:根据返回的map集合中是否含有“ticket”的键,判断用户是否登陆成功;如果登录成功,取出对应的loginticket,设置在HttpResponse的Cookie中(name=ticket,value=loginticket中具体的登录凭证的随机号码,设定cookie的过期时间为记住我的过期时间,注意存放的ticket用于后期的登陆拦截器从redis中获取用户的登录凭证信息),最终成功登录后,重定向至首页,注意携带这个cookie;
结果- -失败:直接将map里封装的错误的信息model给前端登录的页面,让用户进行重新登录
*判断用户名密码的验证登录的情况&&根据记住我设置登录凭证的过期时间,如果登陆成功,返回的map集合里封装了key为ticket“”的键值对,供controller层进行判断
判断1:用户名和密码不能为空,直接返回封装错误信息的map集合
判断2:(用户名)根据用户名,查找user实体,如果user=null说明该账号不存在,直接返回封装错误信息的map集合;
判断3: (密码)用户实体存在,判断前端的明文的密码是否正确,首先对明文的密码同样进行盐值加密(注意这个salt当时存在了数据库中),加密后再与数据库的密码进行验证对比,直接返回封装错误信息的map集合;
判断4:(激活)判断查到的user实体的激活码,如果没有激活,直接返回封装错误信息的map集合;
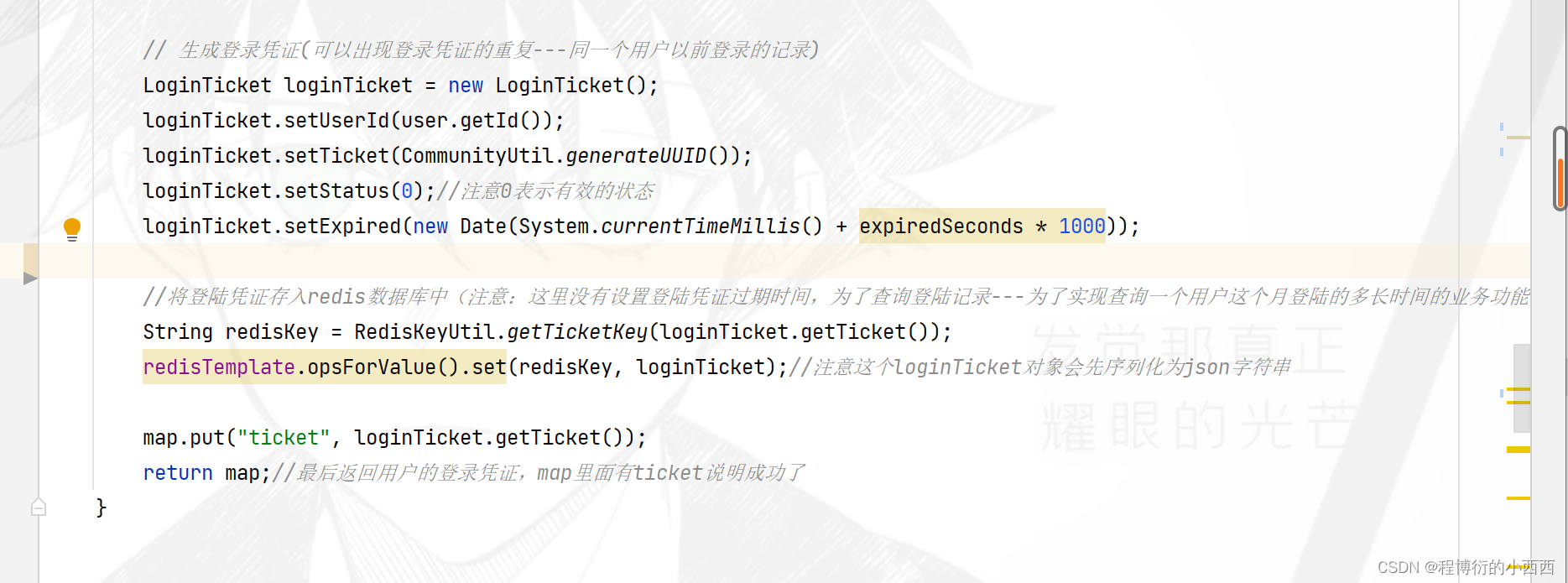
登录凭证:针对经过验证的,为用户生成一个新的登录凭证(loginticket:用户id, ticket的随机码,ticket的有效状态,ticket的过期时间),其中过期的时间节点是当前的时间加上记住我的时间。注意将这个用户的登录凭证存放在“redis缓存中”(key=ticket:登录凭证的随机号码,value的loginticket的对象的json序列化的字符串)(因为我们的登陆拦截器需要频繁的查询),同时我们不设定过期时间-----后期根据存放在cookie中的ticket来查找redis中的登录凭证信息(用于后续的业务–查询用户的过去时间段的登录的情况)。最后将key=“ticket”,value为登录凭证的map集合返回给controller层
//使用redis优化之后:登录时的验证码检验以及登录凭证的检验
@RequestMapping(path = "/login", method = RequestMethod.POST)
public String login(String username, String password, String code, boolean rememberme,
Model model, HttpServletResponse response,
@CookieValue("kaptchaOwner") String kaptchaOwner) {
// 检查验证码(从cookie获得暂时的用户凭证--键,来查取redis数据库验证码)
String kaptcha = null;
if (StringUtils.isNotBlank(kaptchaOwner)) {
String redisKey = RedisKeyUtil.getKaptchaKey(kaptchaOwner);
kaptcha = (String) redisTemplate.opsForValue().get(redisKey);
}
// 比较前端用户传入的验证码值code与kaptcha比较 kaptcha.equalsIgnoreCase可以忽略大小写进行比较两个字符串
if (StringUtils.isBlank(kaptcha) || StringUtils.isBlank(code) || !kaptcha.equalsIgnoreCase(code)) {
model.addAttribute("codeMsg", "验证码不正确!");
return "/site/login";
}
// 检查账号,密码
//----------- 检查账号,密码(根据rememberme 来设置登录凭证的有效时间)-----------
int expiredSeconds = rememberme ? REMEMBER_EXPIRED_SECONDS : DEFAULT_EXPIRED_SECONDS;
Map<String, Object> map = userService.login(username, password, expiredSeconds);
if (map.containsKey("ticket")) {
//将这个登录的凭证(以字符串的形式,实际ticket本身就是string类型的)存入到cookie,用于下一次注销登录
//用途:用于用户的注销登录+检查网页当前是否有用户登录(拦截器LoginTicketInterceptor)
Cookie cookie = new Cookie("ticket", map.get("ticket").toString());
cookie.setPath(contextPath);
cookie.setMaxAge(expiredSeconds);
response.addCookie(cookie);
return "redirect:/index";
} else {
model.addAttribute("usernameMsg", map.get("usernameMsg"));
model.addAttribute("passwordMsg", map.get("passwordMsg"));
return "/site/login";
}
}
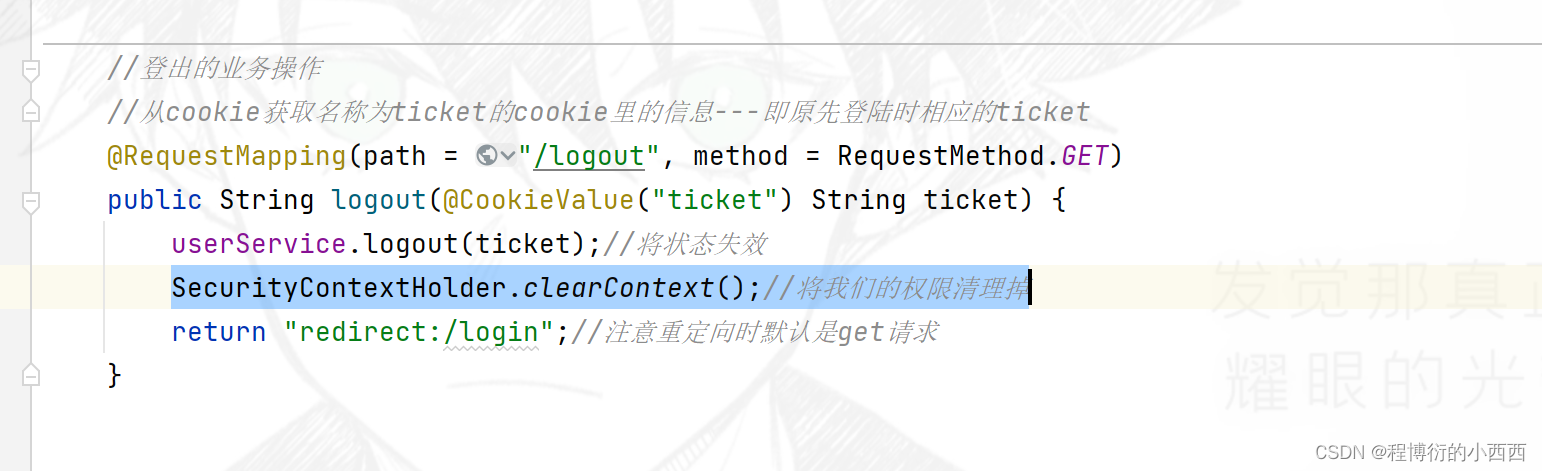
登录的退出
主要是设置redis中的loginticket的登录凭证状态status为无效的状态&& SecurityContextHolder.clearContext();//清除线程中用户相关密码权限的token的信息
认证:登录凭证的拦截器(检查当前线程的是否登录用户—SpringSecurity授权)
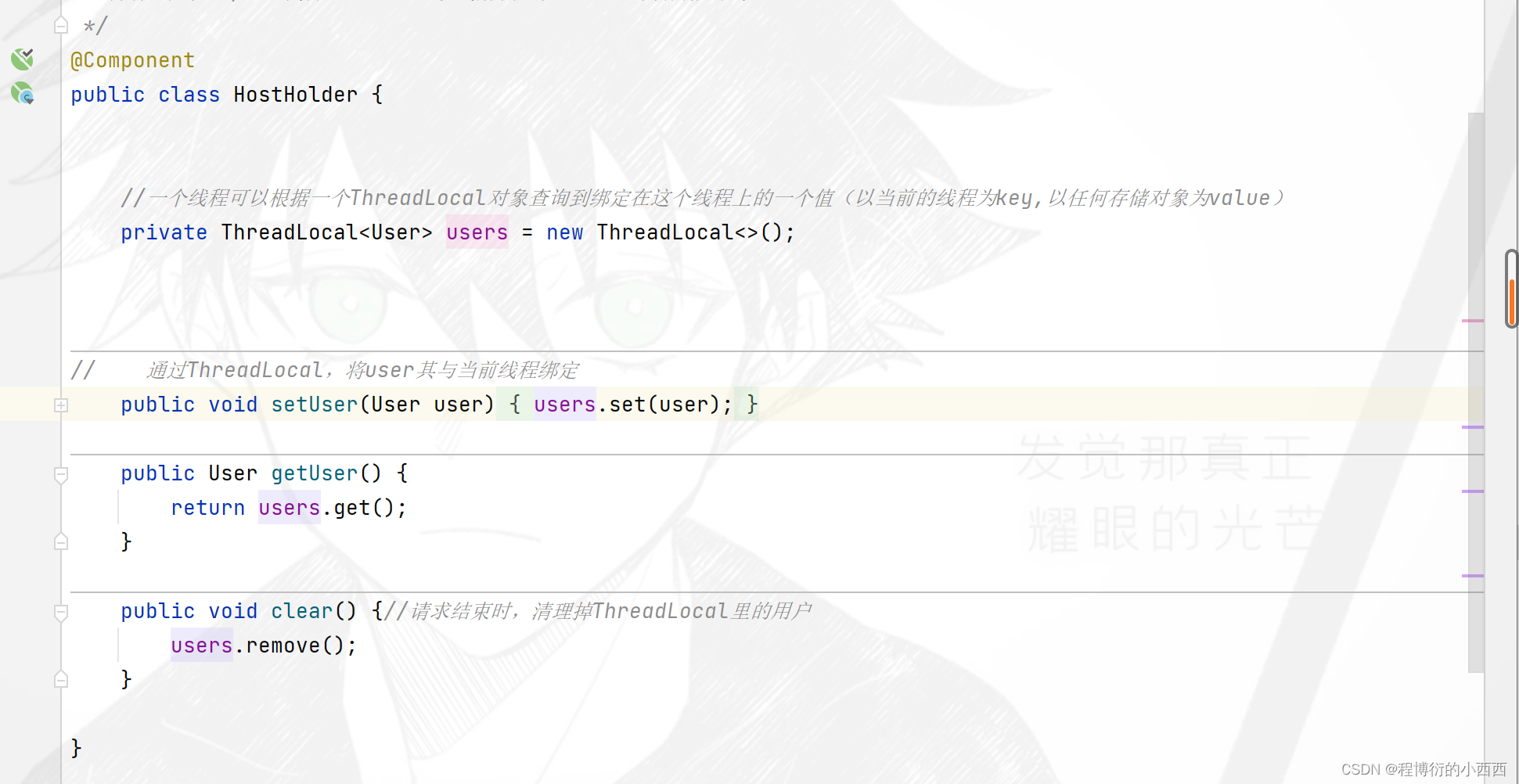
controller之前(Threadlocal绑定user信息)
注意这个拦截器不会真正的去拦截重定向至某个登录页面,只是拦截将用户的信息封装在Threadlocal中,后续判断threadlocal中是否有登录用户的信息再继续进行重定向至登录的页面也不迟!!!!
在每次controller之前,拦截器首先从cookie中获取用户成功登陆时的ticket的登录凭证的凭证码,从redis中查询具体的登录凭证的对象的具体信息loginTicket(里面封装凭证的过期时间以及有效的状态)
判断1(cookie):cookie的这个ticket是否还存在,可能也已经过期了,毕竟当时是按照remember me的时间设定的过期的时间;
判断2(redis–loginticket):根据从redis获得的loginticket的对象,判断这个登录凭证的状态是否是有效状态&&并且过期的时间点在当前时间的之后,说明这个登录凭证真的是有效的
操作1(ThreadLocal):根据登录凭证中的userid查询出整个的user的实体对象的信息,将这个信息绑定在本地线程ThreadLocal中,实现同一个线程中可以共享用户的数据信息,不用频繁的查用户是否登录
操作2(SpringSecutiry授权需要认证的token):封装用户名密码的认证令牌,传到SpringSecurity的上下文环境中,用于后续的用户de相关的业务的授权
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 从cookie中获取凭证(我们当时在登录用户时,成功登录的用户将登陆凭证存入了cookie)
String ticket = CookieUtil.getValue(request, "ticket");
if (ticket != null) {
// 查询凭证
LoginTicket loginTicket = userService.findLoginTicket(ticket);
// 检查凭证是否有效:凭证结果非空;状态为0有效(我们推出登录时设置为了1,所以退出登陆后此时不会在当前线程放入用户);
// 并且超时时间晚于当前的时间---才是有效的凭证
if (loginTicket != null && loginTicket.getStatus() == 0 && loginTicket.getExpired().after(new Date())) {
// 根据凭证的用户id来进行查询用户
User user = userService.findUserById(loginTicket.getUserId());
// 在分布式的环境下,使用session存在共享数据的问题
// 在本次请求中持有用户(在多个线程之间隔离存储用户),并存入threadlocal里
hostHolder.setUser(user);
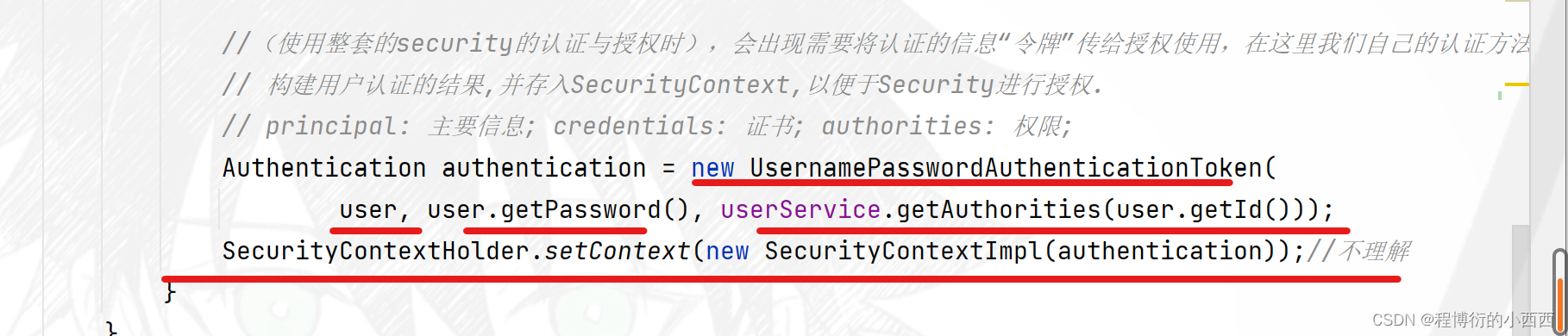
//(使用整套的security的认证与授权时),会出现需要将认证的信息“令牌”传给授权使用,在这里我们自己的认证方法,同样需要手动传入信息
// 构建用户认证的结果,并存入SecurityContext,以便于Security进行授权.
// principal: 主要信息; credentials: 证书; authorities: 权限;
Authentication authentication = new UsernamePasswordAuthenticationToken(
user, user.getPassword(), userService.getAuthorities(user.getId()));
SecurityContextHolder.setContext(new SecurityContextImpl(authentication));//不理解
}
}
return true;
}
controller之后视图渲染之前( 原来前端拿到数据是在这里!!!登陆拦截器这块传进来的 )
在每次controller之后,视图渲染之前,我们需要从当前的线程中把登录的用户信息取出,model给前端,这样前端可以按照用户是否登录进行一些组件的显示与不显示功能(例如:未登录,显示需要登录的按钮,注册的按钮等等;登录的用户,展示登录用户的个人主页以及账号设置等等)
// 在Controller之后执行,但在TemplateEngine之前执行
// 使用ModelAndView类用来存储处理完后的结果数据,以及显示该数据的视图。
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
//从当前的线程中获取用户,存入modelandview之中(如果当前的线程有这个用户的信息,就会传入前端的模型视图中,前端渲染页面也可以判断当前的用户是否登录!!!)
User user = hostHolder.getUser();
if (user != null && modelAndView != null) {
modelAndView.addObject("loginUser", user);//在视图渲染之前,将用户传入模型视图
}
}
视图渲染之后
清除Threadlocal中的用户(防止出现内存的泄露的问题),SecurityContextHolder上下文环境的清理----线程之间的隔离
// 在TemplateEngine(网页视图渲染之后,完成整个请求流程之后)之后执行(整个请求结束之后)
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//清除当前线程的user
hostHolder.clear();//防止出现内存泄露
SecurityContextHolder.clearContext();//将我们的权限清理掉(SecurityContextHolder也是使用Threadlocal实现的)
}
用户账号的设置(修改头像与密码的修改)
修改用户头像的具体逻辑
注意这个必须在用户登录的情况下,才会用户的相关的账号设置(归功于登录凭证拦截器将用户loginuser信息model到了前端),点击账号设置,跳转到上传用户头像的页面
头像的重新上传 (头像本地存储—本业务约定的本机服务器的D盘的某个文件下!!!)
这样很不好,将所有的用户的头像文件,都保存在了服务器的磁盘上,会非常的耗内存(最好的方法是保存在别家的服务器上,利用别家给的url进行访问!!)
前端form表单提交,传入一个MutipartFile对象(存储了图片及其原始名称的信息), 提取图片文件名称的后缀+重新生成一个随机码的文件名称(固定的MutipartFile的API接口)
step1(图片本地保存): MultipartFile的tansferto将图片重新保存到本服务器机子下的一个专门存放头像的文件下;
step2(头像地址更新mysql): 拼接一个用户头像显示业务的一个url地址,根据用户的id和新的文件名称进行拼接,将这个地址保存到mysql中,更新对用户的头像的显示的具体的地址(这个地址是用来回显用户头像的请求地址)


//用于接收表单提交的上传头像
// (spring的MultipartFile headerImage即为从前端上传的文件)
@LoginRequired
@RequestMapping(path = "/upload", method = RequestMethod.POST)
public String uploadHeader(MultipartFile headerImage, Model model) {
//前端上传的文件没有找到
if (headerImage == null) {
model.addAttribute("error", "您还没有选择图片!");
return "/site/setting";
}
//提取前端上传文件的格式
String fileName = headerImage.getOriginalFilename();//获取图片原始的文件名
String suffix = fileName.substring(fileName.lastIndexOf("."));//提取图片名称的后缀
if (StringUtils.isBlank(suffix)) {
model.addAttribute("error", "文件的格式不正确!");
return "/site/setting";
}
// 生成随机文件名(并拼接上图片格式的后缀名)
fileName = CommunityUtil.generateUUID() + suffix;
// 确定文件存放的路径(本地的路径)
File dest = new File(uploadPath + "/" + fileName);
try {
// 将前端上传的图片文件存储到本地的目标文件
headerImage.transferTo(dest);
} catch (IOException e) {
logger.error("上传文件失败: " + e.getMessage());
throw new RuntimeException("上传文件失败,服务器发生异常!", e);
}
// 更新当前用户的头像的路径(web访问路径:实际上这个web访问路径里面是从本地获取的图片)
// http://localhost:8080/community/user/header/xxx.png
User user = hostHolder.getUser();// 从当前的线程获取用户,用于更新用户的头像路径
String headerUrl = domain + contextPath + "/user/header/" + fileName;
userService.updateHeader(user.getId(), headerUrl);
return "redirect:/index";//重定向至首页,看看头像更新了没
}
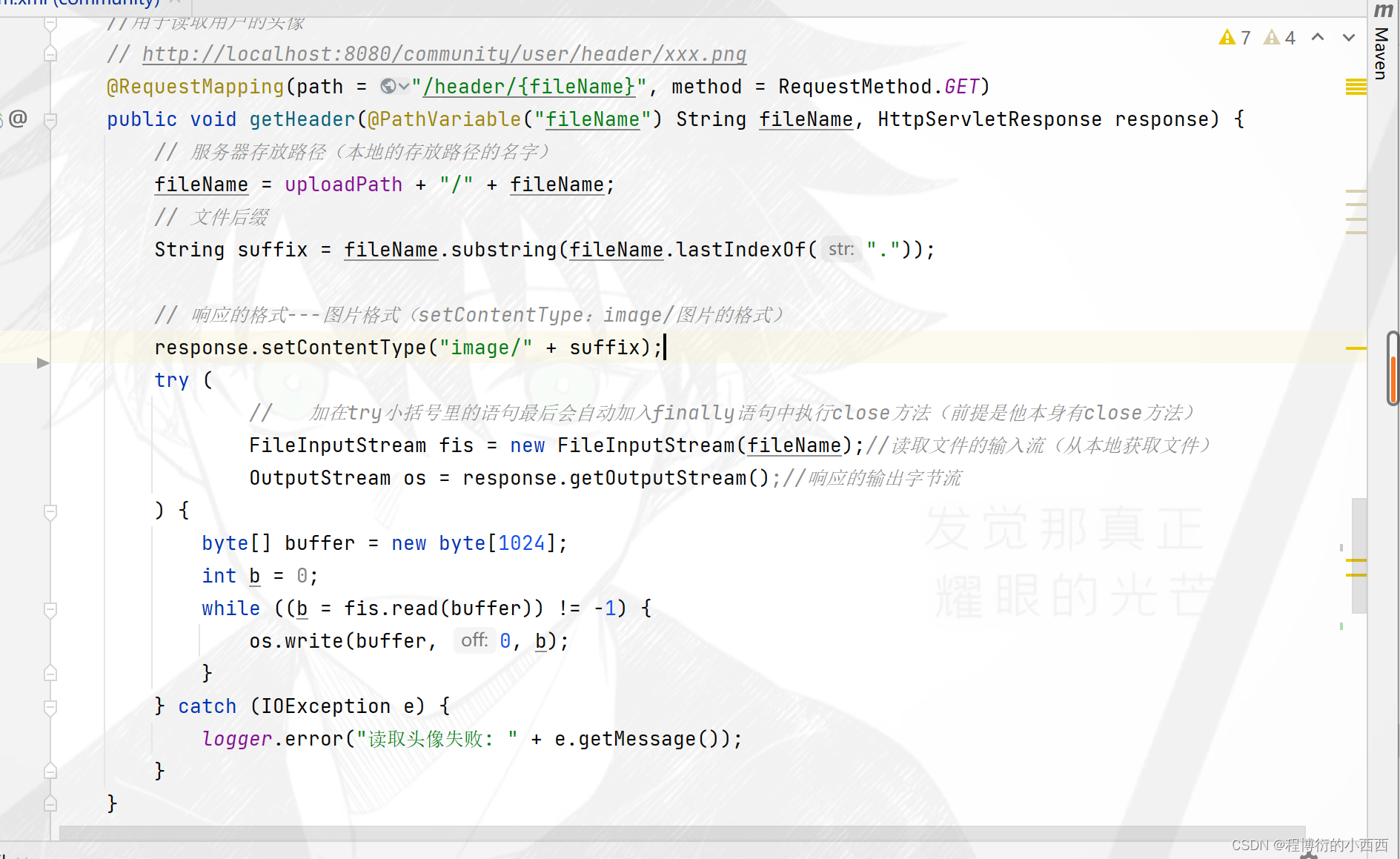
头像的显示
注意前端头像的显示本质上是异步的请求后端的一个显示头像的业务,我们数据库存放了头像显示的具体的链接请求信息----(数据库存放的头像的url地址实际是一个业务请求,路径变量中含有用户头像的文件的名称。)(头像信息存放在本机服务器的一个磁盘的文件夹下)
step1(本地的头像的文件路径):从前端头像展示的请求url地址中,获取路径变量—文件的名称,重新拼接本地服务器的头像的具体文件路径(我们约定好了本级服务器的那个文件下存放用户的所有的头像信息);
step2: 读取本地磁盘的头像数据流(FileInputStream),将头像的数据流在前端输出(Outpustream)显示即可!!!
发帖、评论、私信核心功能(Kafka待完善)
敏感词的过滤器(来不及弃)
step1(前缀树结构对象):首先创建一棵前缀树class TrieNode的对象,成员变量:subnodes子节点----HashMap<Character,TrieNode>的结构+isKeywordEnd是否是敏感词的结束字符;
step2(txt):提前准备好一个存放敏感词的txt文件,每一行只有一个敏感词;
step3(添加敏感词的API): 添加一个敏感词至前缀树的方法,注意需要一个字符一个字符的级联添加;
step4(初始化敏感词的前缀树):@PostConstruct +public void init() ,一旦构造器一初始化,就将txt文件中的所有的敏感词都添加到前缀树中(@PostConstruct 这个注解代表这是一个“初始化”的方法,在这个构造器之后,即该构造器被注入进来(服务启动之后)之后就会自动初始化);
step5(过滤文本的方法–太复杂了): 传入需要“过滤的文本”,经过过滤之后输出“过滤之后的文本”。这边有三个指针,一个指针指向前缀树的位置,两个指针对应待过滤字符串的滑动窗口的左右指针(本质模拟一个可能的敏感词的窗口。一旦出现position位置到达的时候前缀树的指针恰好是敏感词的末尾,说明是敏感词,更新左指针为右指针的下一个位置,输出文本直接添加“3*”即可;一旦中间的一个单词中间就出现treenode=null,说明左指针开始的这个不是敏感词,将左指针对应的字符加入输出的文本)。右指针和左指针同时更新为左指针的下一个位置!!
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 敏感词的替换符
private static final String REPLACEMENT = "***";
// 根节点的初始化
private TrieNode rootNode = new TrieNode();
//初始化:构造敏感词的前缀树(用于后续过滤器的调用)
//这个注解代表这是一个“初始化”的方法,在这个类被注入进来(服务启动之后)之后就会自动初始化
@PostConstruct
public void init() {
try (
//将txt文件存储为输入流
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));//字节缓冲流,加快读取的速度
) {
String keyword;//每次一行读取一个敏感词
while ((keyword = reader.readLine()) != null) {
// 每次将一个敏感词添加到前缀树中去
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
/**
* 过滤敏感词的过滤器
*
* @param text 待过滤的文本(用户的帖子的具体内容)
* @return 过滤后的文本(过滤敏感词的文本)
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
return null;
}
// 指针1(前缀树的判断指针)
TrieNode tempNode = rootNode;
// 指针2(敏感词滑动窗口的左指针)
int begin = 0;
// 指针3(滑动窗口的右指针)
int position = 0;
// 结果(过滤后的文本存放结果)
StringBuilder sb = new StringBuilder();
while(begin < text.length()){
if(position < text.length()) {
Character c = text.charAt(position);
// 跳过符号(防止用户钻漏洞,跳过类似“赌*博”这种中间的符号)
if (isSymbol(c)) {
if (tempNode == rootNode) {
begin++;
sb.append(c);
}
position++;
continue;
}
// 此时是正常的符号了,检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {// 发现敏感词
sb.append(REPLACEMENT);
begin = ++position;
} else { // 检查下一个字符
position++;
}
} else{ // position遍历越界仍未匹配到敏感词
sb.append(text.charAt(begin));
position = ++begin;
tempNode = rootNode;
}
}
return sb.toString();
}
// **********将一个敏感词添加到前缀树中****************
private void addKeyword(String keyword) {
TrieNode tempNode = rootNode;//每次敏感词都是从根节点开始往下(一个敏感词就是一条字符路径)
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);//找一下之前有没挂过这个同样字符的子节点
if (subNode == null) {
// 初始化子节点,并作为当前根节点的子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环(如果已经挂载过这个子节点,就直接指向这个子节点)
// 实际还是按照这个敏感词的顺序在拼接
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
// **************判断是否为符号******************
//isAsciiAlphanumeric(c)判断字符是不是普通的字符
private boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// ***********“前缀树”的节点设置:注意前缀树不是一个二叉树*********************
private class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 存放子节点(key是下级的敏感字符,value是下级节点)的map容器
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
//设置当前节点是否时结束的关键字
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点(根据下级符号来查找子节点)
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
}
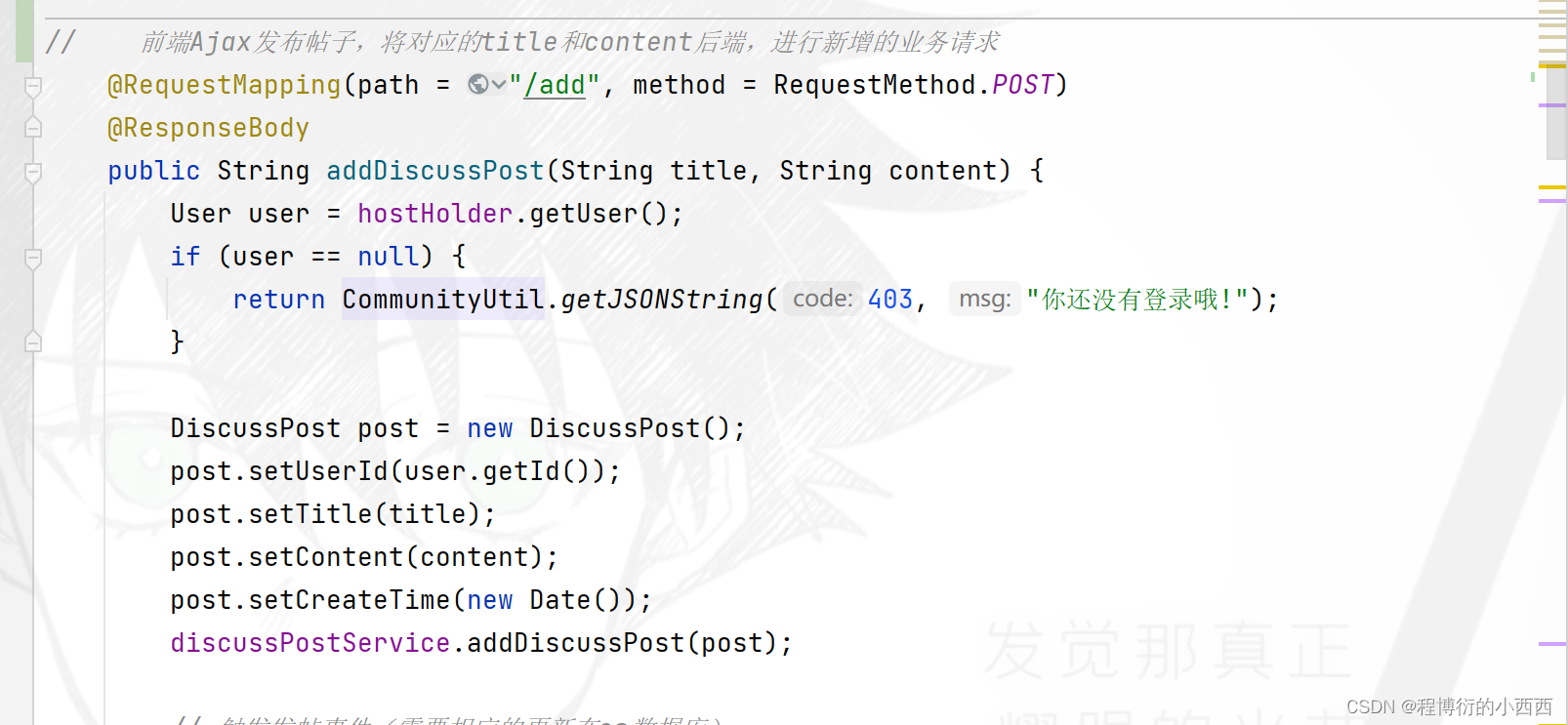
发帖(简单crud操作+敏感词的过滤)
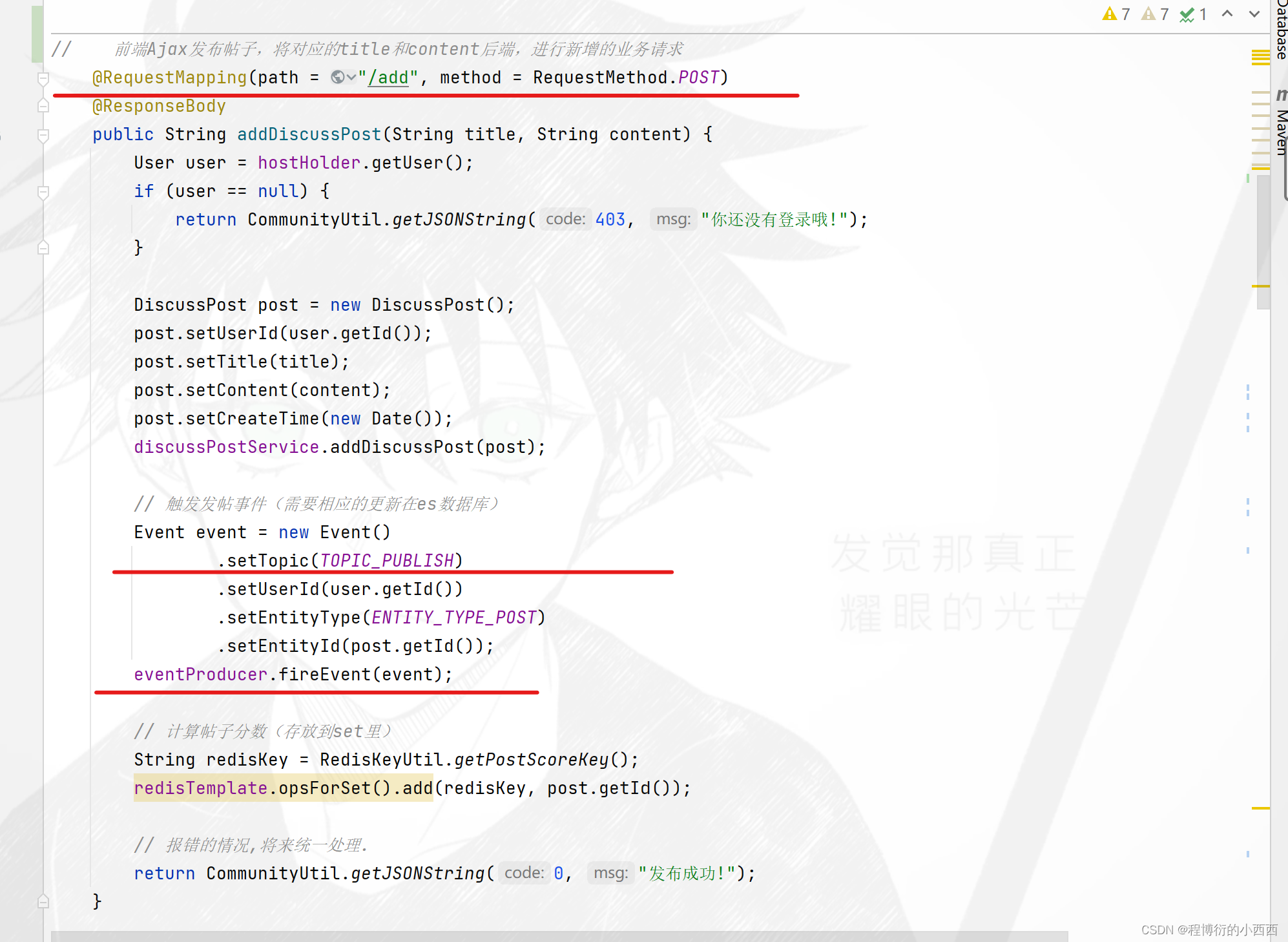
前端Ajax发送异步请求进行数据库的新增帖子,将前端用户的title和content参数传给后端的业务(注意:这个请求还会接收后台处理完的返回的处理结果的信息,进行结果的展示)–这个才是真正的前后端的分离!!!!
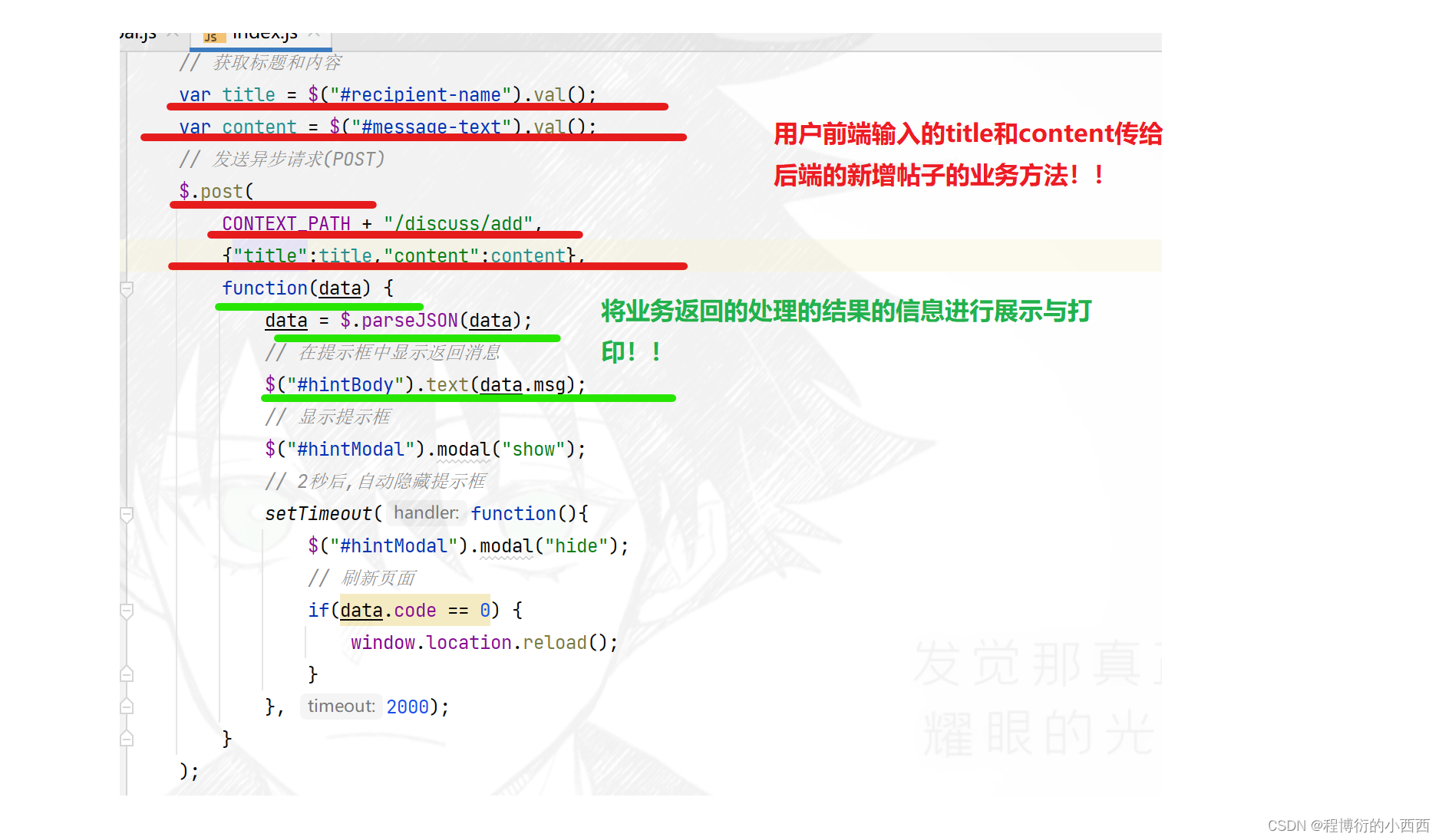

step1:首先判断用户是否登录;
step2:如果没有登陆,直接返回错误的信息给前端(让用户进行登录)----这一步根本不会出现,没有登录压根不显示发帖的按钮;
step3:如果用户登录,从当前线程获取user实体类,此时将重新封装DIscussPost的实体对象(设置上发帖人的userid+title+content+发帖的时间),调用seivice层的新增帖子的业务:1.完成对帖子的标题和内容的敏感词的过滤+2.最后将这条贴在保存到mysql数据库中,返回成功发布的结果的信息给前端

帖子的详情 (数据Map封装麻烦)
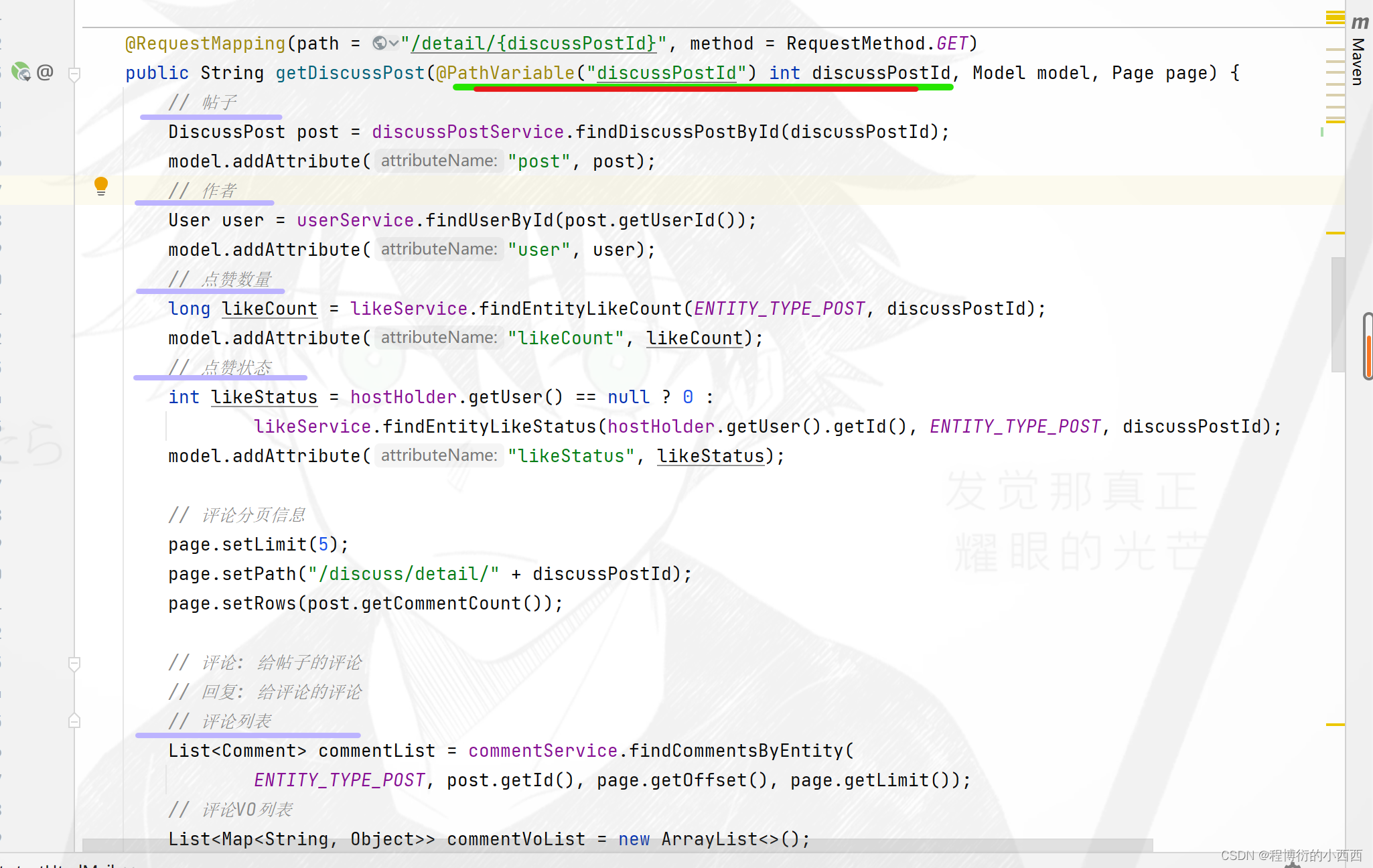
点击帖子的标题可以查看帖子的详情,实现请求后端的业务—拼接的路径上含有帖子id的路径变量

数据封装:
1.根据帖子id查询到的帖子的实体DiscussPost实体;
2.帖子实体对应的发帖人的user实体;
3.点赞数量与当前用户的点赞状态(查询redis中点赞实体的set集合的size和判断userid在不在set集合中);
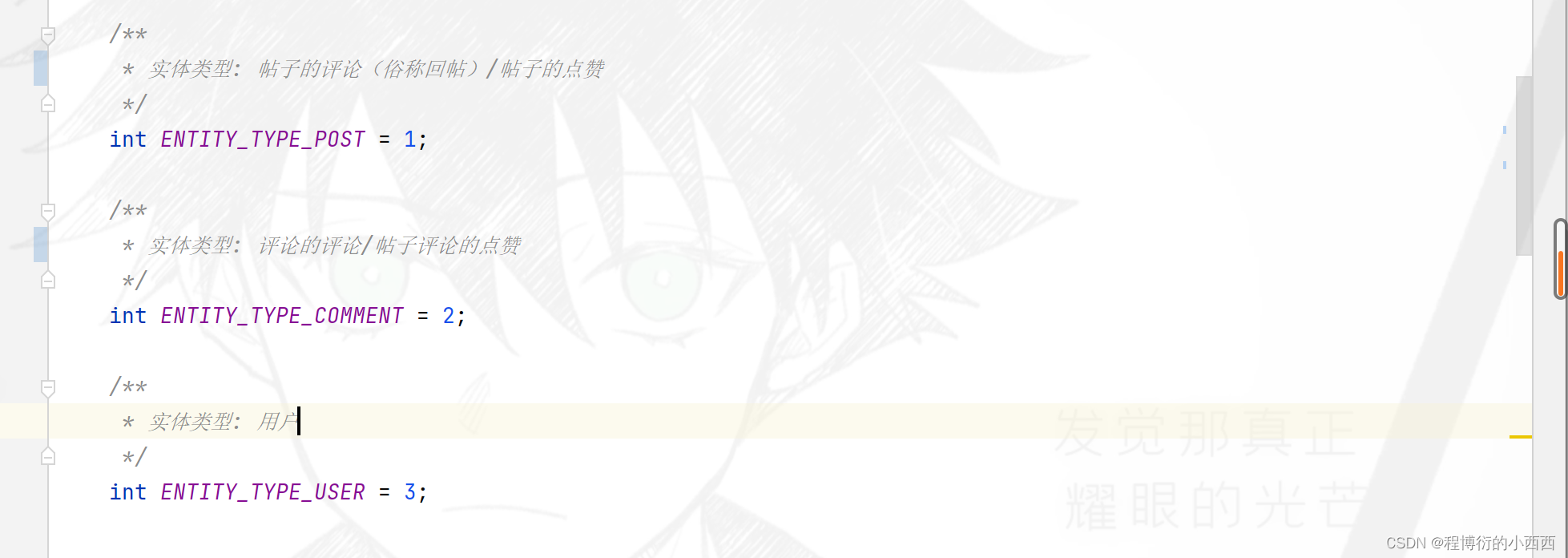
4.大头:封装所有的评论的信息(注意每个评论还要封装对应的点赞数量与当前用户的点赞状态):分为帖子的评论即回帖(entitytype就是帖子的回帖评论,对应的实体Entityid就是帖子Discussspost的id)-----外层的大对象,回帖的评论(entitytype就是评论的评论,对应的实体id的comment子的id;注意这里还要区分是回复给回帖的还是回复给某个特定的用户的targetid)—内层的小对象
相当于有entityType区分回帖还是回帖的评论,利用targetID区分是回帖的评论还是回帖中的评论的回复!!!

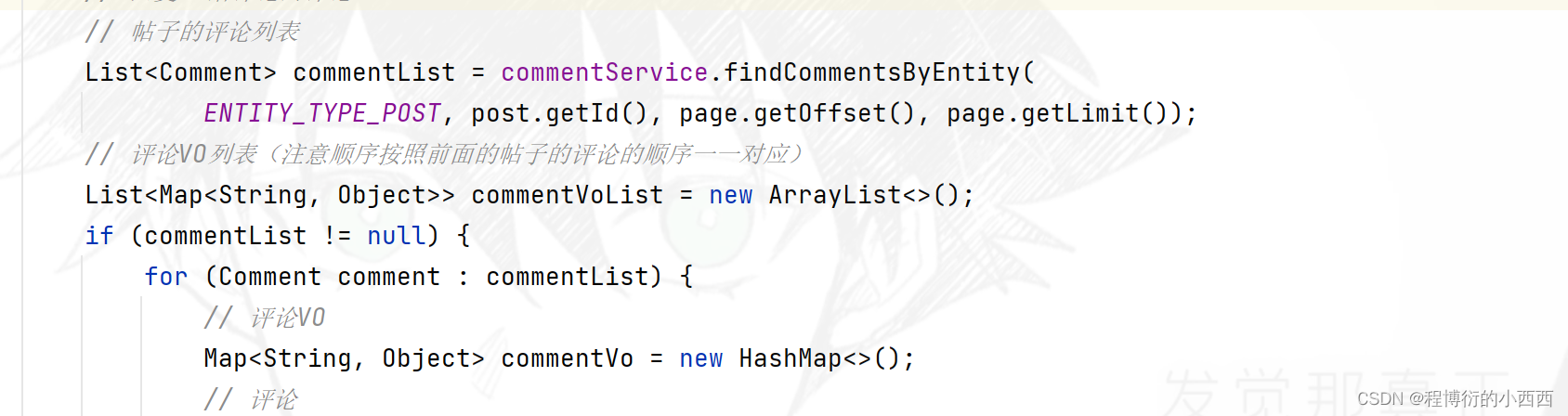
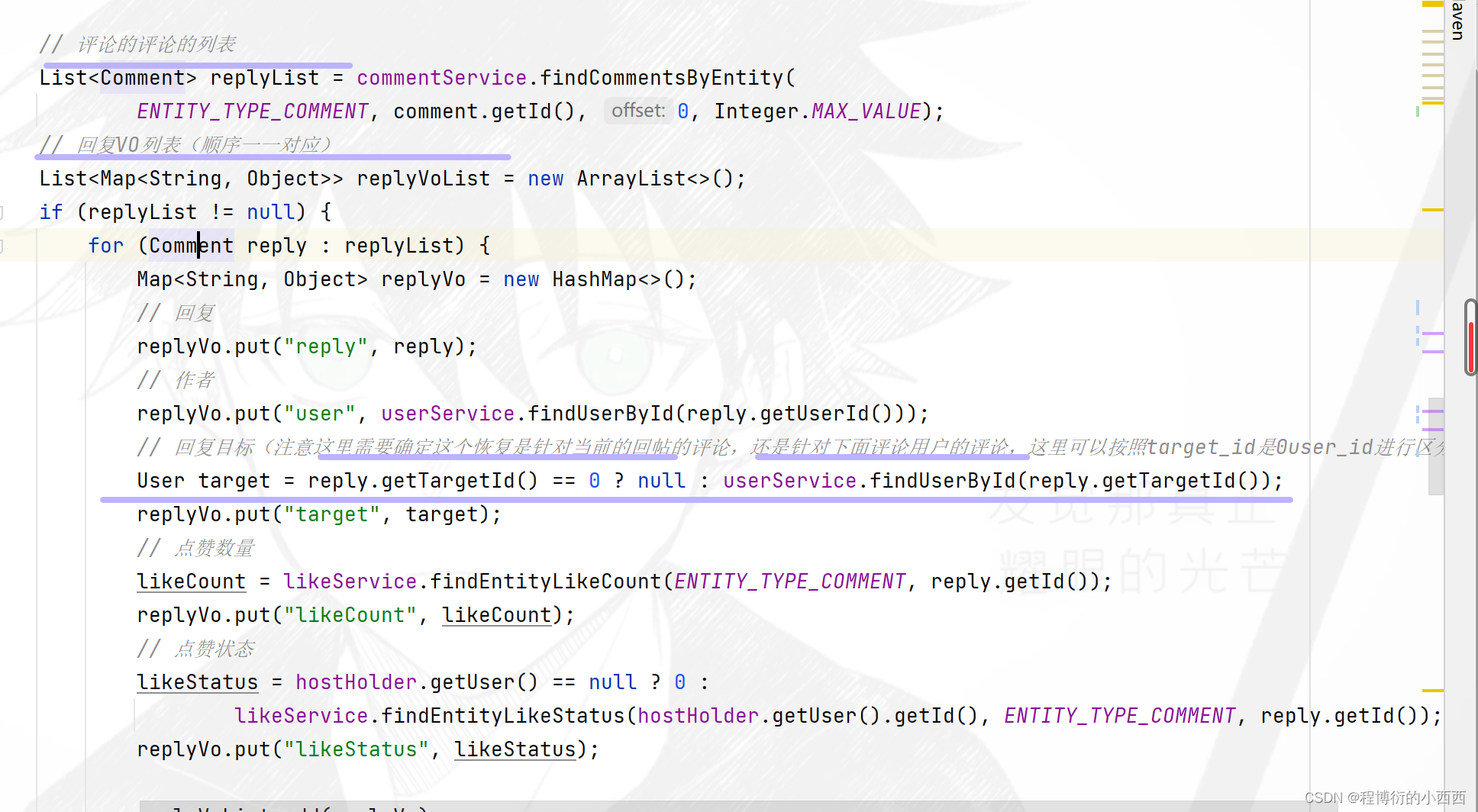

帖子的评论新增(注意有三种评论+注意敏感词的过滤)
针对3种评论主要的区别就是对应表中的三个字段:entity_type(主要是1针对帖子的评论,2针对回帖的评论或者针对某个用户的评论),entity_id就是对应评论的id或者对应帖子的id,target_id只有是对某个人的回复的评论才会出现区别的非0的id(user_id)。
注意复用同一个增加评论的业务的方法的请求,但是前端的隐藏域的字段会提前设置好三个字段的数据,对用户是不可见的
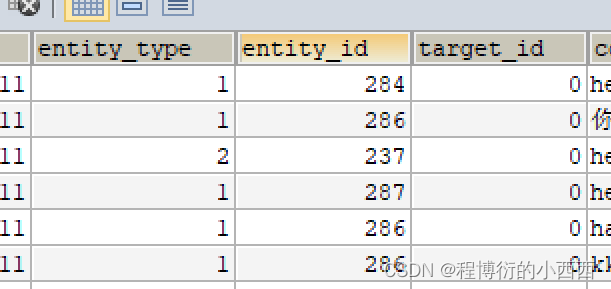
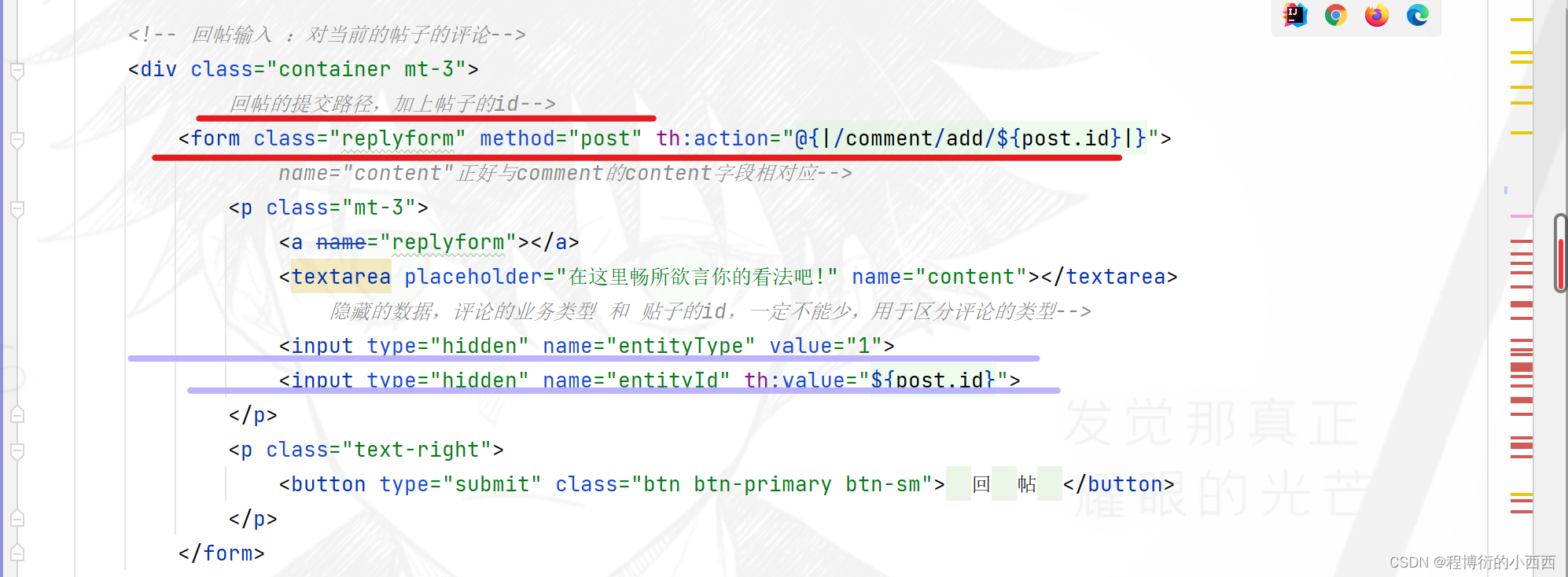
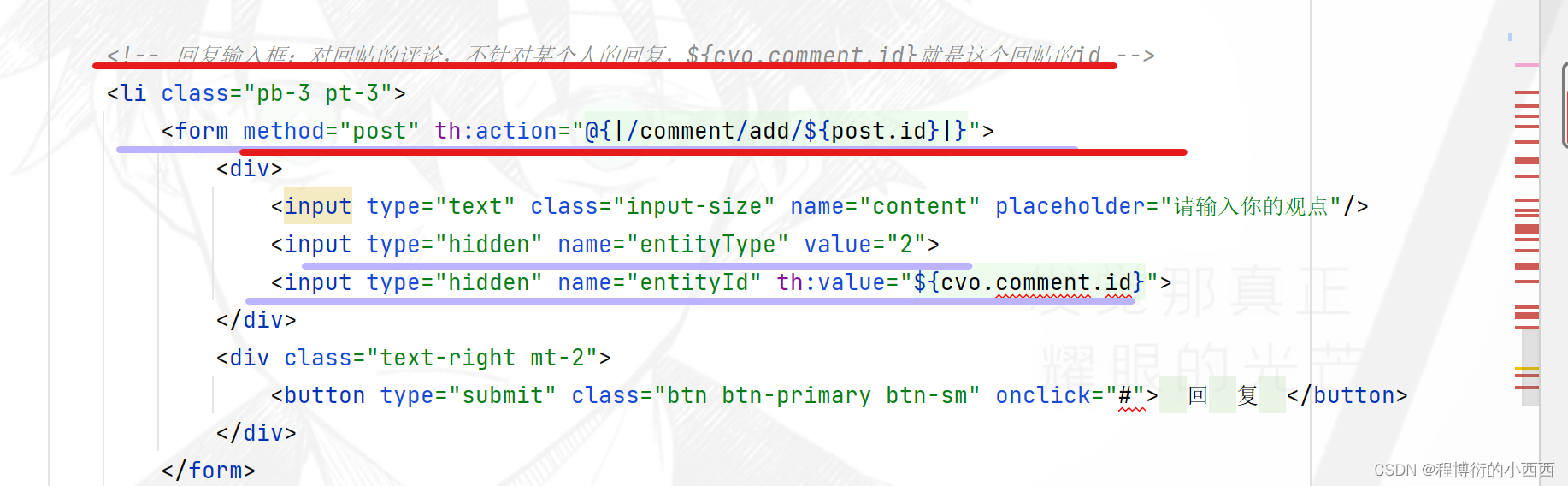
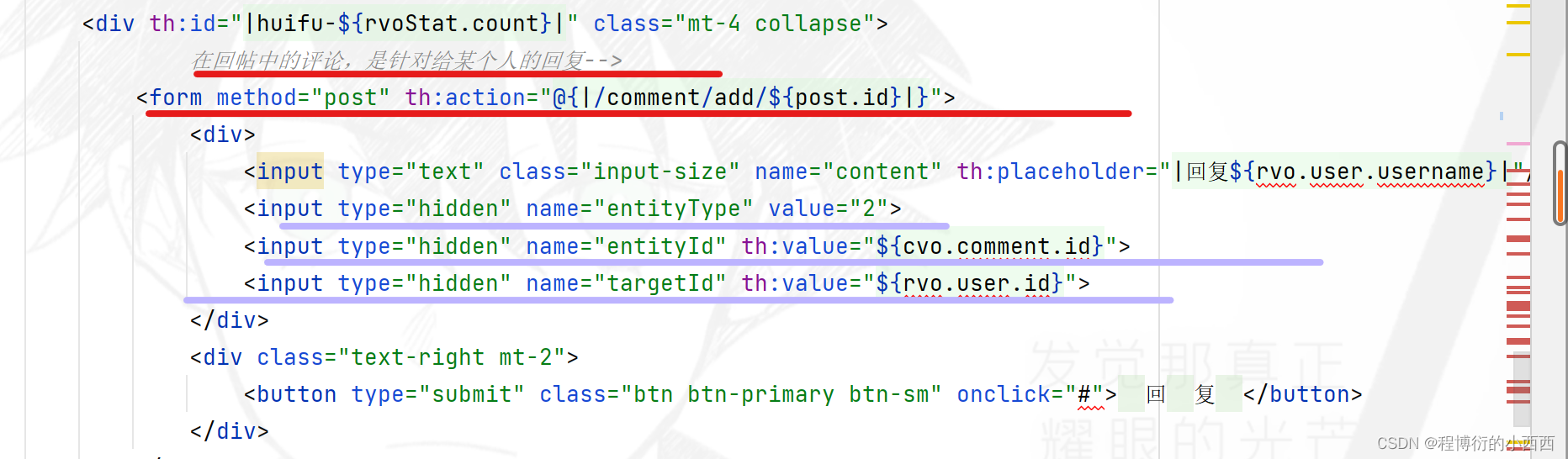
注意:这些评论还是针对一个帖子下面的评论,所以最终的路径变量还是要传入对应的帖子的id,都要提交的数据一定是comment中的content字段的内容,有区别的就是上面所说的三个字段(因为隐藏域传的不同)-----前端自动封装在comment中 (因为我们队输入的字段命名了name,所以可以正确的对应的封装)
step1:注意对comment的基本信息(用户的id–发表评论的用户一定是当前线程的用户,创建的时间+对应的上面的三个字段的信息)的进行封装后;
step2:传入相应的service层的业务方法中,对相应的回复的内容进行敏感词的过滤,最终将评论存入数据库;
step3: 注意如果是对"帖子的评论"(即entity_type=1)需要针对更新对应帖子的评论数量,首先查询comment的表的最新的对应帖子的总的回帖的数量,然后继续调用discussPost的service业务的方法及进行评论的数量的更新----discussPost表的更新(由于涉及到了两个表的查询,需要开启事务的管理)

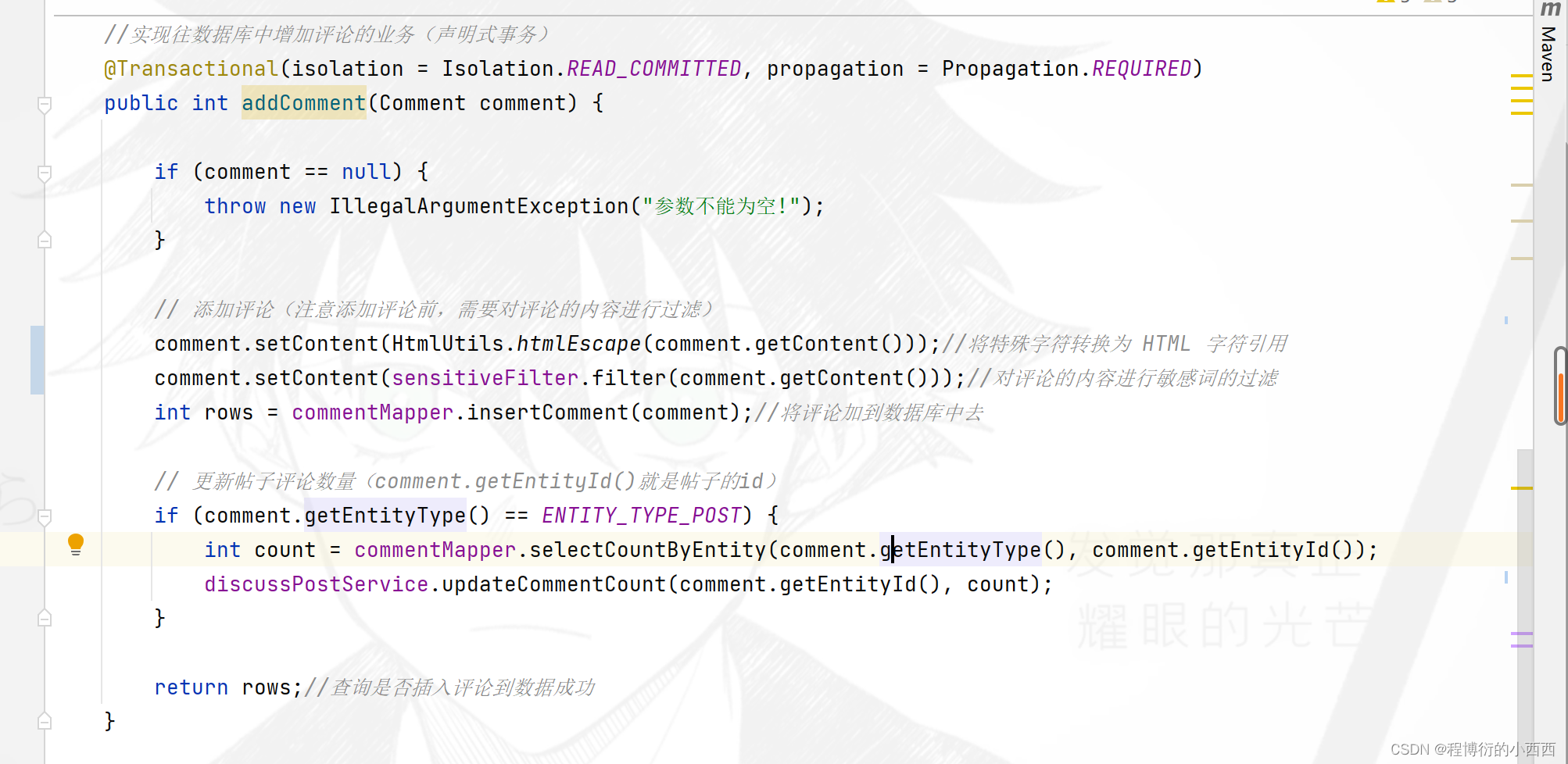
私信功能(sql语句)
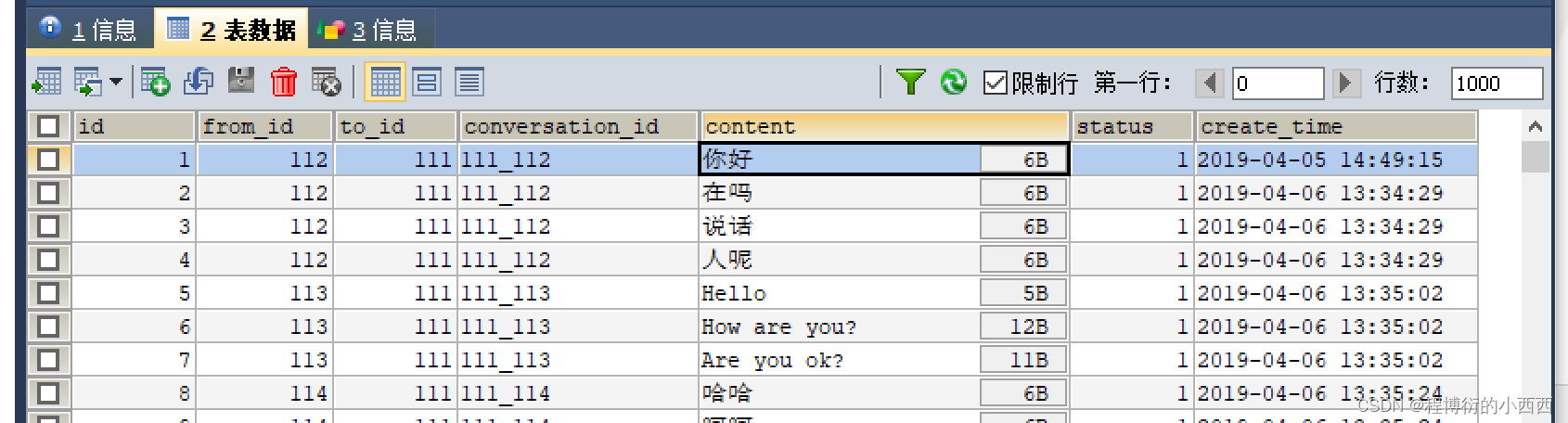
注意这个message的表:两个用户的私信,系统(系统的user_id=1)的通知的信息(评论,点赞,关注引起的系统消息的通知)。本节针对两个用户之间的会话的message进行讨论,conversation_id按照两个会话用户的id拼接的(升序拼接)
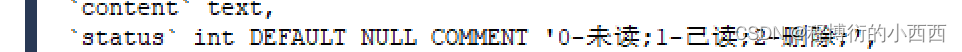
私信列表的展示
首先点击导航栏跳转到消息的列表的页面,默认跳转进来的是私信列表的页面


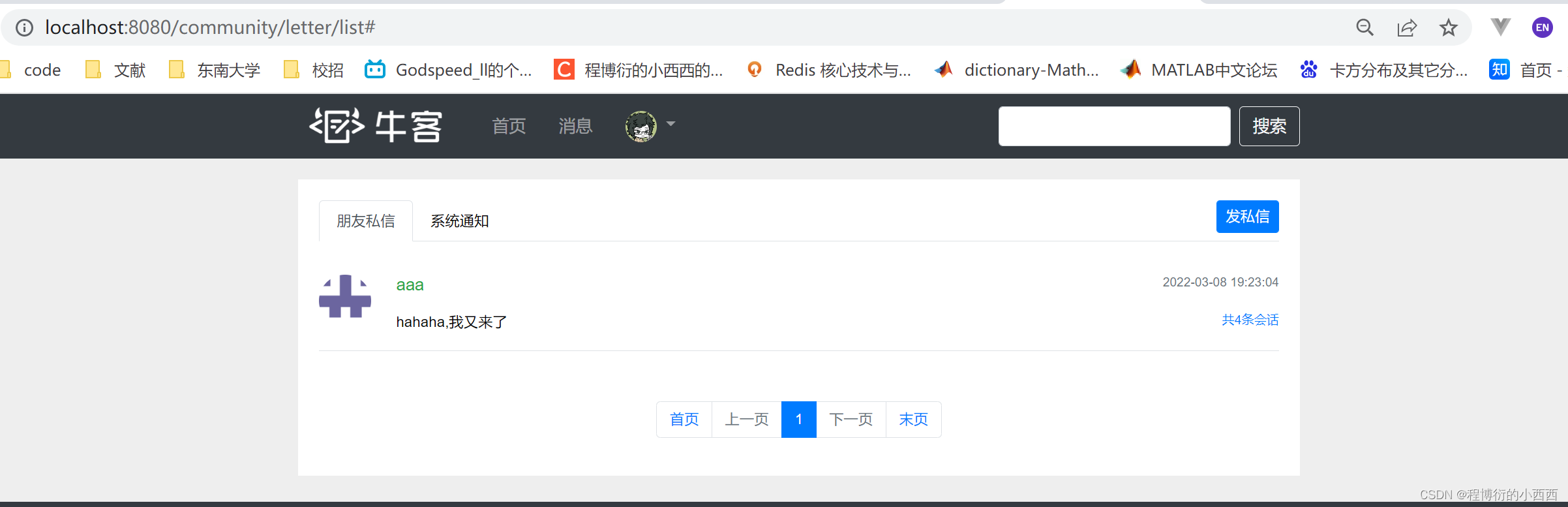
显然这个展示的就是当前线程的登录用户的私信列表的信息,没有登录的用户根本不会有消息的按钮的出现,注意列表私信的时候,只会展示同一个Conversion_id的最新的一条消息,不用查询展示所有的信息!!!
step1: 首先获取当前线程的登录用户的信息,获取用户的user_id;
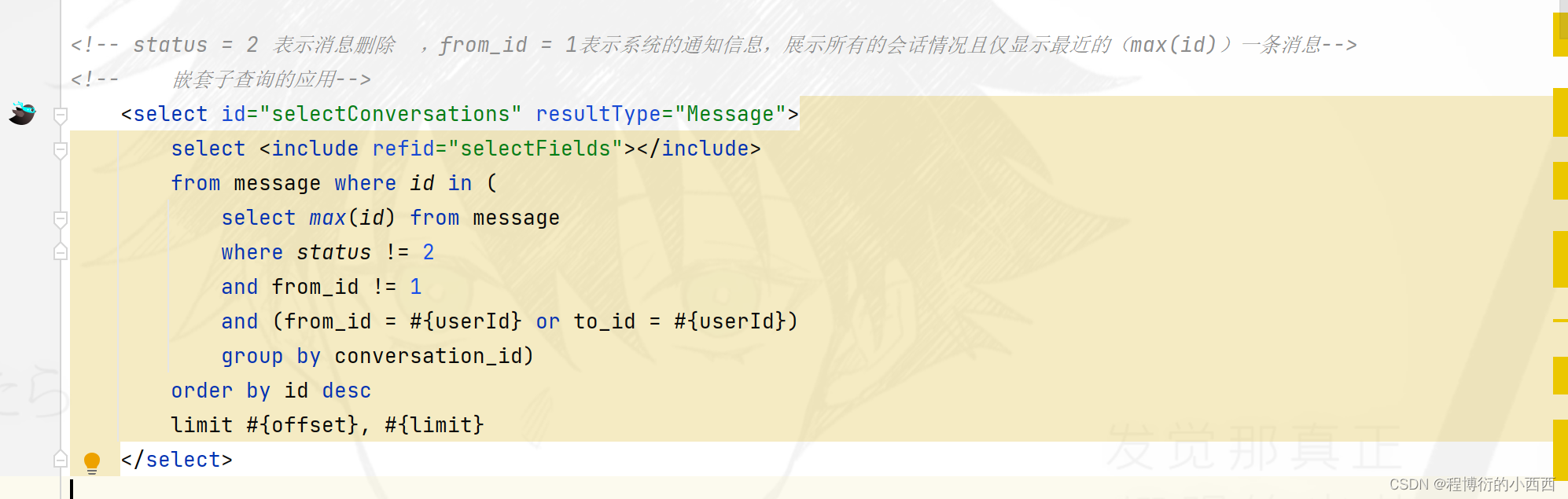
step2(SQL子查询+去重很关键): SQL语句编写查找所有的需要的最新的会话消息的集合,sec1: 首先查出用户id的同一个Conversion_id的最新的一条消息的message的id的集合:所有的message的消息(from_id或者to_id等于user_id的消息的集合)&&按照conversion_id进行分组查询,之后需要对每个分组的消息中挑选出最大的那个id即可(因为message的id是主键自增的,id越大说明消息越新!!!);sec2: 在获得的message的id集合中继续查找具体的message的信息,封装为一个list集合即可。
step3: 针对每一个会话,需要知道对应的另一方的用户id(target_id)----反正不是fromid就是toid,按照当前线程的用户id很快就能判断出来。根据targetid继续查出整个user实体,封装在每一个会话的map集合中,传入前端(前端需要显示用户的头像);
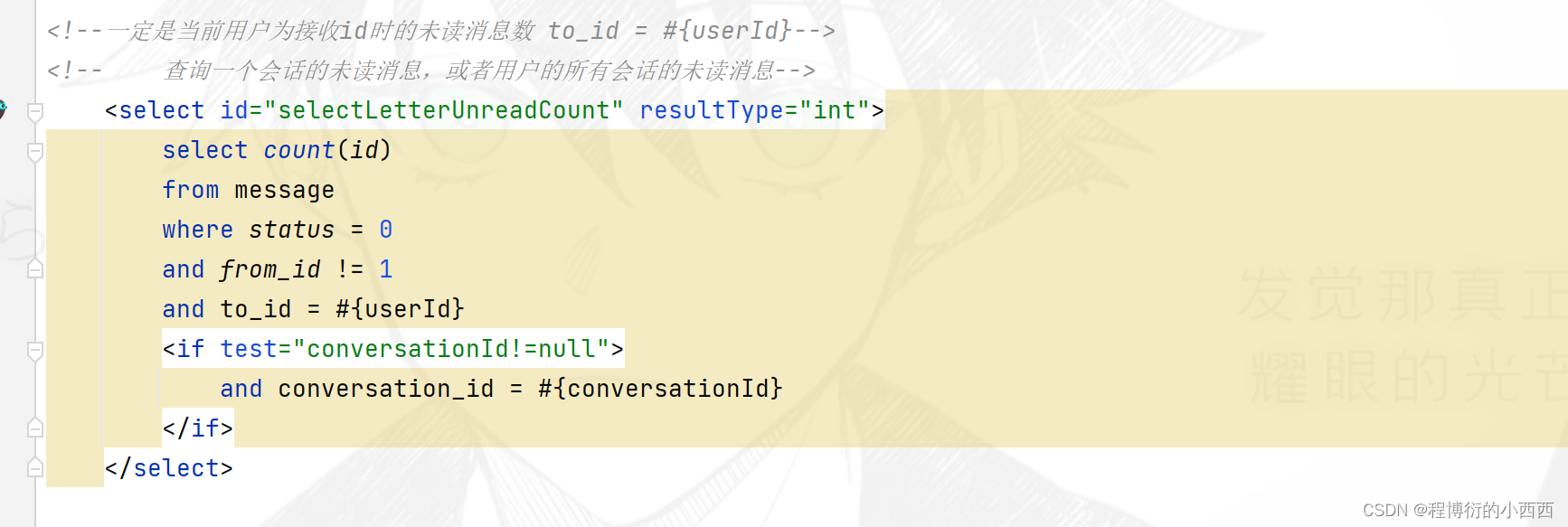
step4: 查询出每个会话的总的通信的会话的条数,以及统计出相应的未读的消息数量(按照conversion_id进行查询就可以了),封装在每一个会话的map集合中,传入前端;
step5: 查询出这个线程用户的总的未读的私信数量,封装在外层map集合中,传入前端
@RequestMapping(path = "/letter/list", method = RequestMethod.GET)
public String getLetterList(Model model, Page page) {
User user = hostHolder.getUser();//获取当前的登录用户
// 分页信息
page.setLimit(5);
page.setPath("/letter/list");
page.setRows(messageService.findConversationCount(user.getId()));
// 会话列表
List<Message> conversationList = messageService.findConversations(
user.getId(), page.getOffset(), page.getLimit());//从数据库中读取的会话集合
List<Map<String, Object>> conversations = new ArrayList<>();//打算给前端的会话集合
if (conversationList != null) {
for (Message message : conversationList) {
Map<String, Object> map = new HashMap<>();
map.put("conversation", message);
map.put("letterCount", messageService.findLetterCount(message.getConversationId()));
map.put("unreadCount", messageService.findLetterUnreadCount(user.getId(), message.getConversationId()));
//显示与当前用户对话的另一个人
int targetId = user.getId() == message.getFromId() ? message.getToId() : message.getFromId();
map.put("target", userService.findUserById(targetId));
conversations.add(map);
}
}
model.addAttribute("conversations", conversations);
// 查询所有的未读消息数量
int letterUnreadCount = messageService.findLetterUnreadCount(user.getId(), null);
model.addAttribute("letterUnreadCount", letterUnreadCount);
return "/site/letter";
}
私信的详情的展示
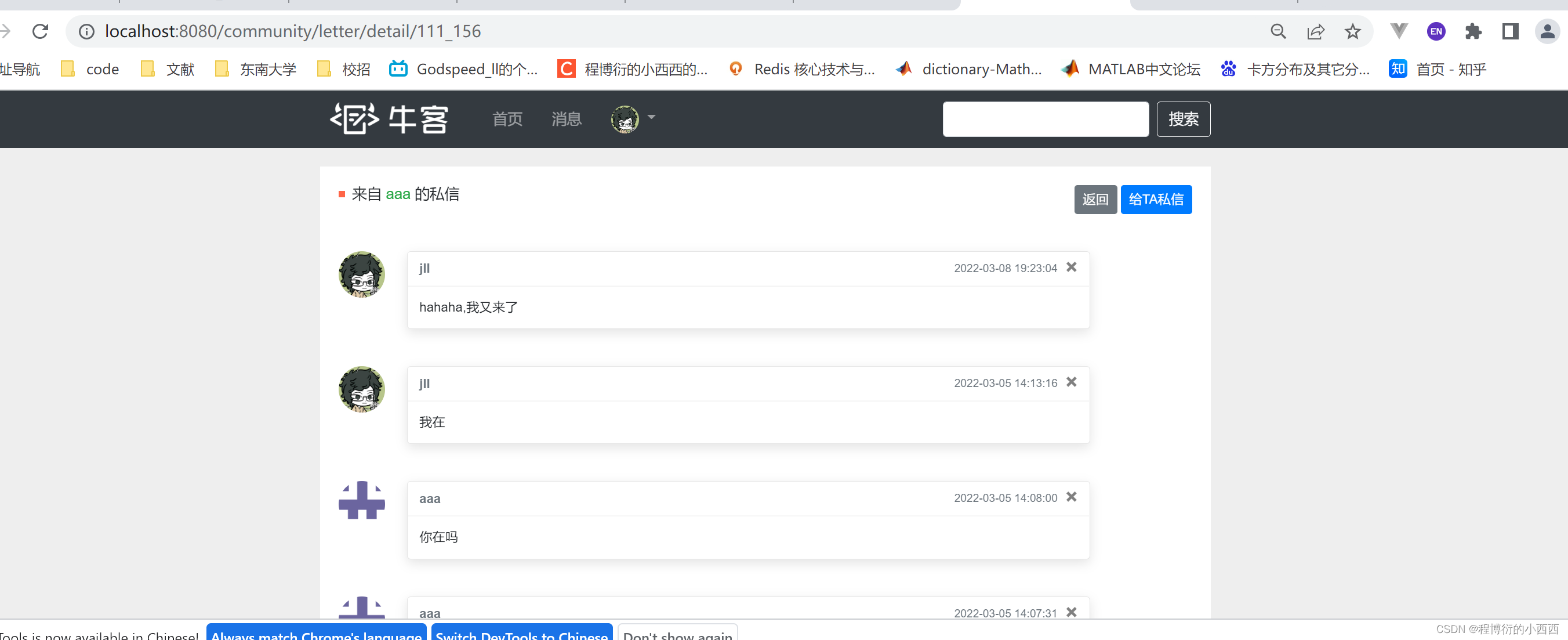
前端点击私信列表的一个会话的最新的消息法内容,进入私信的详情页的业务的方法,进行展示这个会话的所有的童话的消息(显然这个业务的请求路径一定会带上conversion_id来区分展示的消息对话的详情)

具体的操作:
step1: 根据coversion_id查询出所有的会话的消息,对每个消息进行封装一个map集合对象,这个集合中存放了发送方from_id的user实体(展示头像信息和用户的姓名)+消息自身的内容+消息的时间,封装好传入前端。
step2: 封装当前线程的用户通话的另一个用户的信息,用于展示对话的人的姓名,以及供后续给他发私信,继续使用这个用户的信息!!!
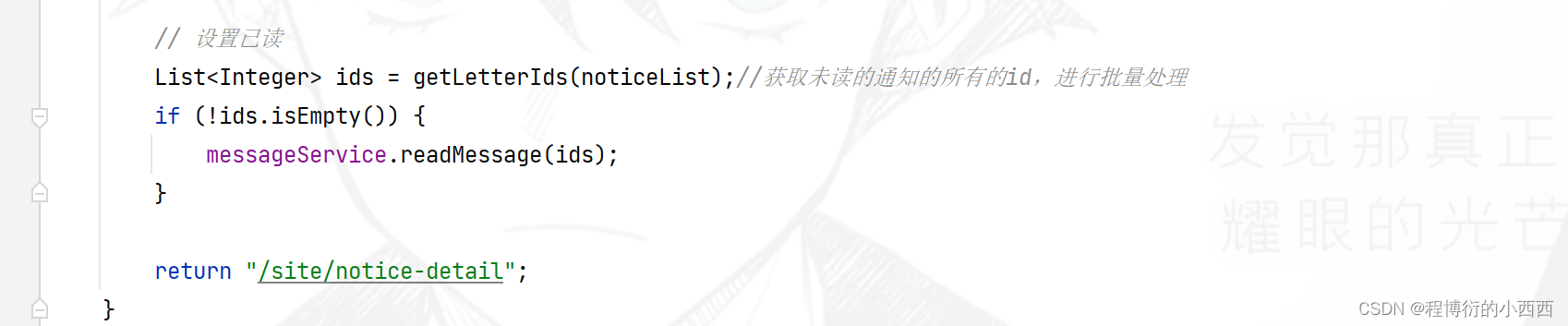
step3(设置已读): 注意,既然查看了消息,就需要将当前的这个会话的所有“未读的消息的状态”设置为“已读的状态”,采用批量更新的方式!!!
发送私信(ajax)–新增message(普通crud)
ajax发送私信,触发新增私信的业务,前端传过来了两个参数:username 和 measage的内容
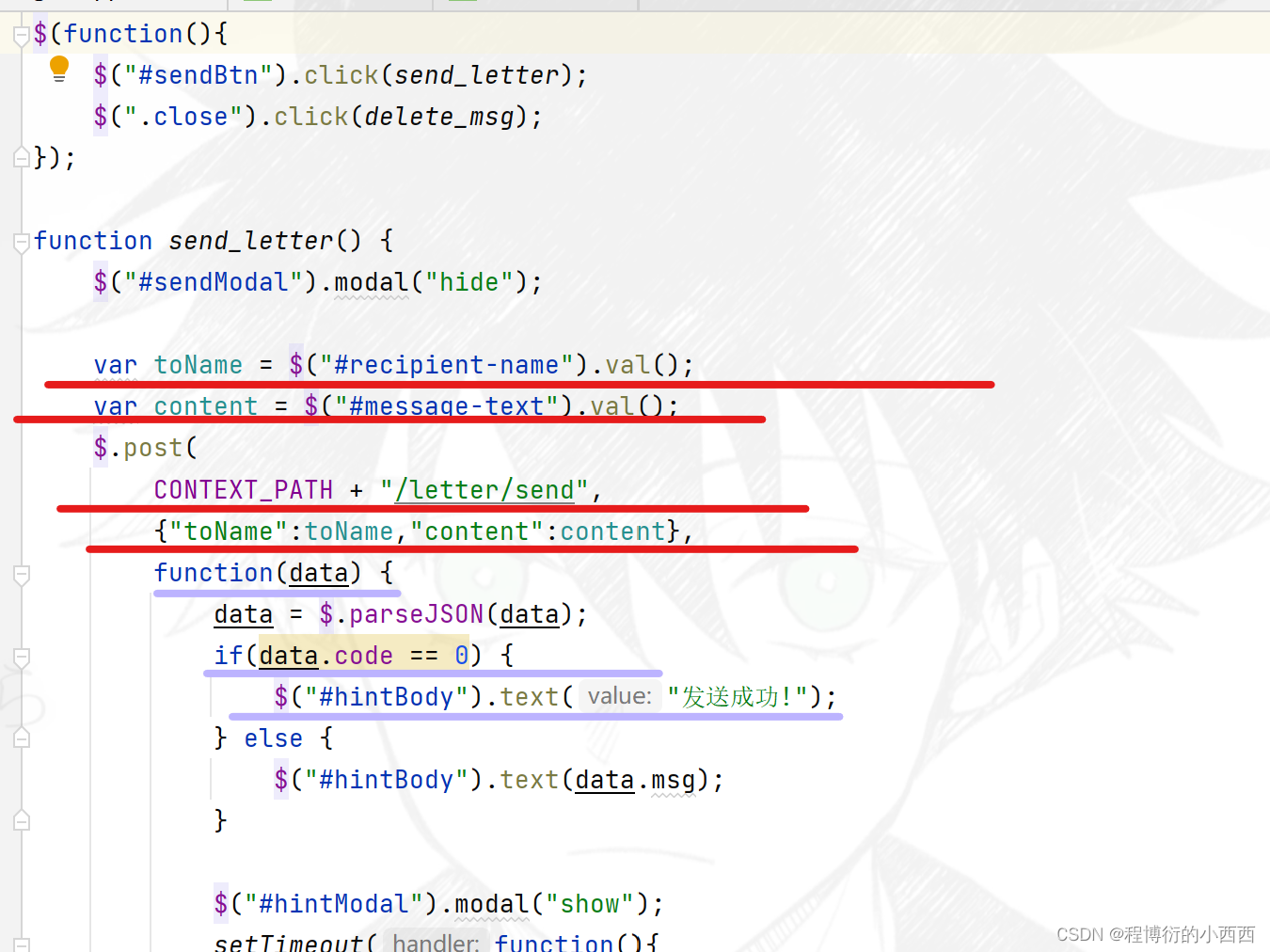
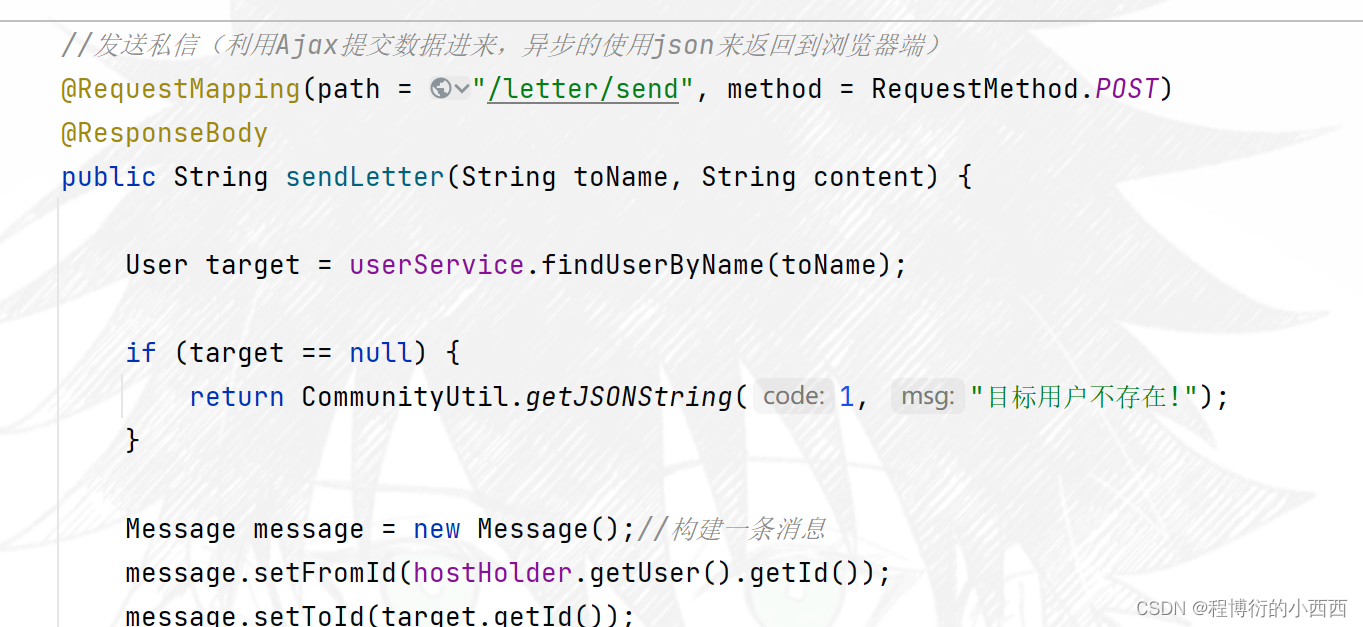
根据username查出发送对象用户的user实体,获取相应的userid,作为toid,当前线程的userid作为fromid,重新封装好一个新的message的对象,并进行敏感词的过滤,最终存入到数据库中
Redis的简单业务:点赞、关注、缓存用户信息
点赞业务
帖子详情页赞的展示
只在帖子详情页能操作点赞的功能,实现对帖子/帖子的评论/对某个用户的点赞操作



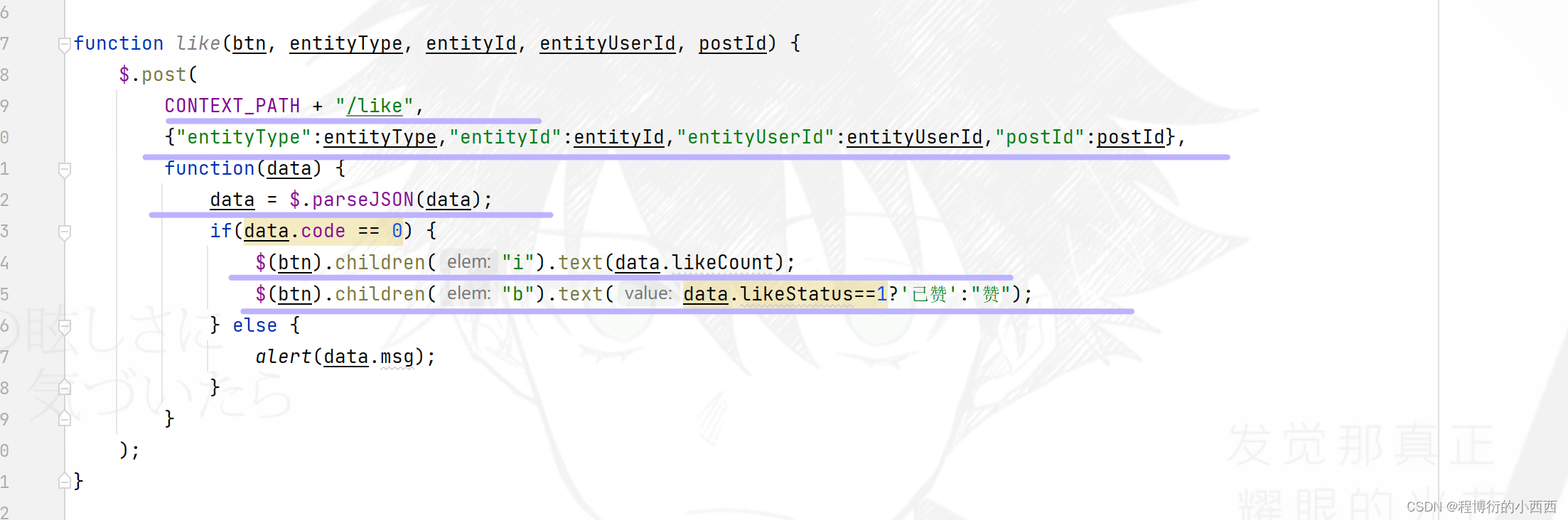
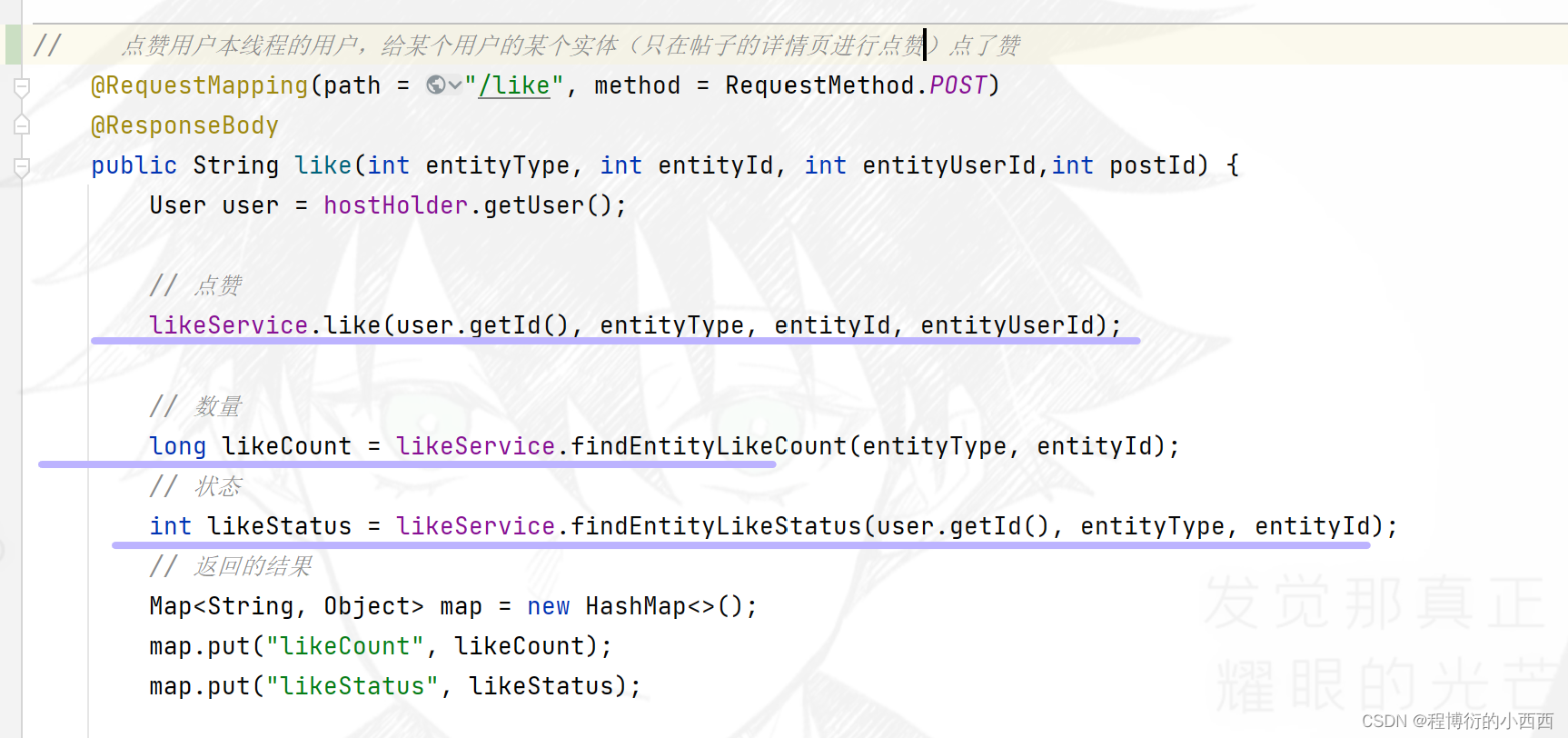
前端点赞(取消赞)的按钮利用ajax进行发送给后台,触发相应的业务(前端自动封装的参数:被点赞的实体的类型(帖子1还是评论2)、实体的id(discusspost_id / comment_id ) 、这个被点赞实体的对应的用户user_id、所在的帖子详情的discussPost_id);
后端处理完业务之后,返回对应实体的总的赞的个数以及当前线程的登录用户点赞的状态
redis数据结构:实体的被点赞结构与用户总赞数结构
两种结构:
对某个实体的点赞:key=like的前缀+实体的类型EntityType+实体对应的id ,value利用的数据结构是set集合(存放了点赞的用户的userid,确保了不会生重复);
某个用户的点赞的总数:key=like前缀+user_id , 对应的value直接存放点赞的个数即可。(用于用户的个人主页展示收获的总的赞的个数)
(对某个实体)点赞/取消赞的逻辑与展示实体赞的个数
ajax进行发送给后台的业务请求,主要分为三步:
step1: 当前用户的点赞触发的redis中数据的变化(被点赞实体的set集合中userID的增减,被点赞实体的用户的总赞数的增减情况);
step2:统计被点赞实体的总的赞的个数(被点赞实体----位于帖子的详情页的展示);
step3: 当前登录用户对这个实体的点赞状态的查询—如果是取消赞触发的业务不需要通知、但如果是如果点赞触发的业务需要系统的通知被点赞实体的用户(被点赞实体----位于帖子的详情页的展示)。
最终将,实体总赞数和用户对实体的点赞状态返回给ajax,让前端进行渲染。
(点赞触发的redis中点赞实体的用户id集合以及被点赞用户的总赞数的业务)主要分为两步,更新redis中实体的赞的个数&&被点赞的实体对应的user的总赞数(两个数据结构开启redis的事务管理):
step1: 拼接redis中的实体的key和用户总赞数的key;
step2: 查询当前用户对帖子的赞的情况(查询实体点赞的set集合中有无当前线程的userid),已赞:此次触发的是取消赞;未赞:此次触发的是点了赞;
step3: 触发“取消赞”—实体的set集合中移除当前userid && 被点赞的实体的user的总赞数减1;
触发“点赞”----实体的set集合中加入当前userid && 被点赞的实体的user的总赞数加1;
使用redis的multi和exec的命令组合!!!!!
// 点赞--- ( userId点赞人的id,entityUserId被点赞人的id)--
public void like(int userId, int entityType, int entityId, int entityUserId) {
//由于有两个业务的交叉使用,所以需要进行"事务的管理"
redisTemplate.execute(new SessionCallback() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
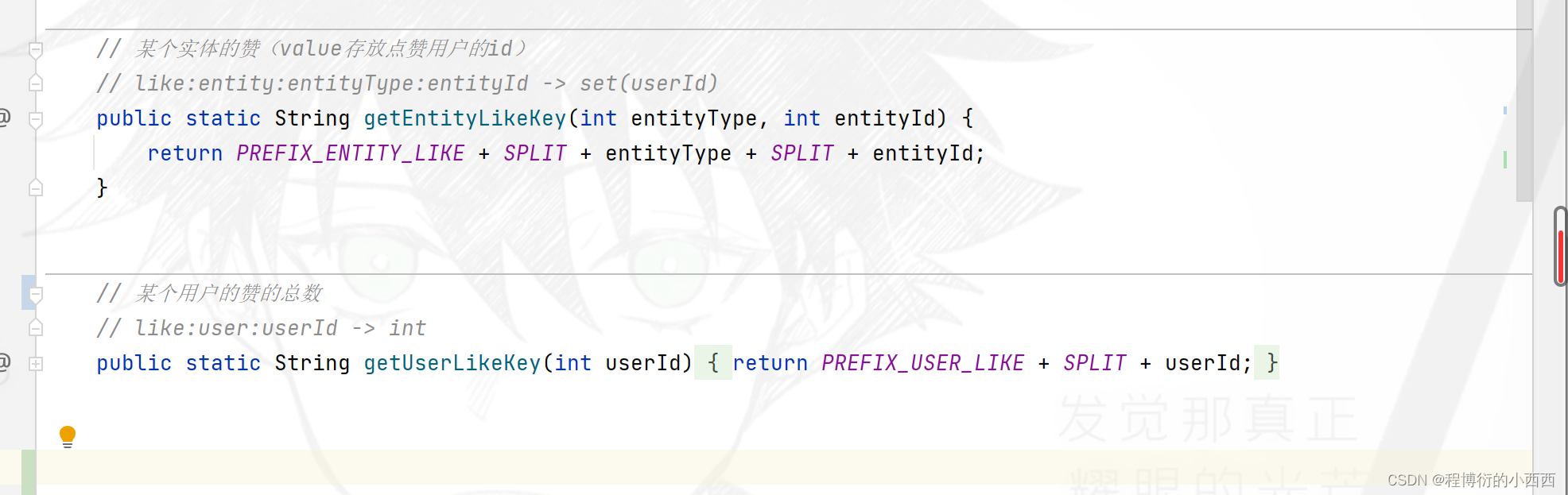
//业务(各种帖子,回帖,评论)实体的赞的key, 统计用户的赞的key
String entityLikeKey = RedisKeyUtil.getEntityLikeKey(entityType, entityId);
String userLikeKey = RedisKeyUtil.getUserLikeKey(entityUserId);
//查询的命令放在“事务的管理”之前或者“事务的管理”的之后
boolean isMember = operations.opsForSet().isMember(entityLikeKey, userId);
operations.multi();//开启事务
if (isMember) {//之前已经赞过了--你又点击了一次,触发为由点赞状态转变为没有点赞的状态
operations.opsForSet().remove(entityLikeKey, userId);
operations.opsForValue().decrement(userLikeKey);
} else {
operations.opsForSet().add(entityLikeKey, userId);
operations.opsForValue().increment(userLikeKey);
}
return operations.exec();//事务提交
}
});
}
( 返回给帖子详情页前端渲染的被点赞实体的总赞数与当前登录用户对帖子的赞的情况)统计赞的情况—查询redis的功能:
step1:实体的总赞数:统计对应set集合的总的size大小;
step2:判断当前线程的登录用户是否点赞,判断set集合是否含有userid。

用户个人主页(总赞数+关注与粉丝的列表)
关注业务
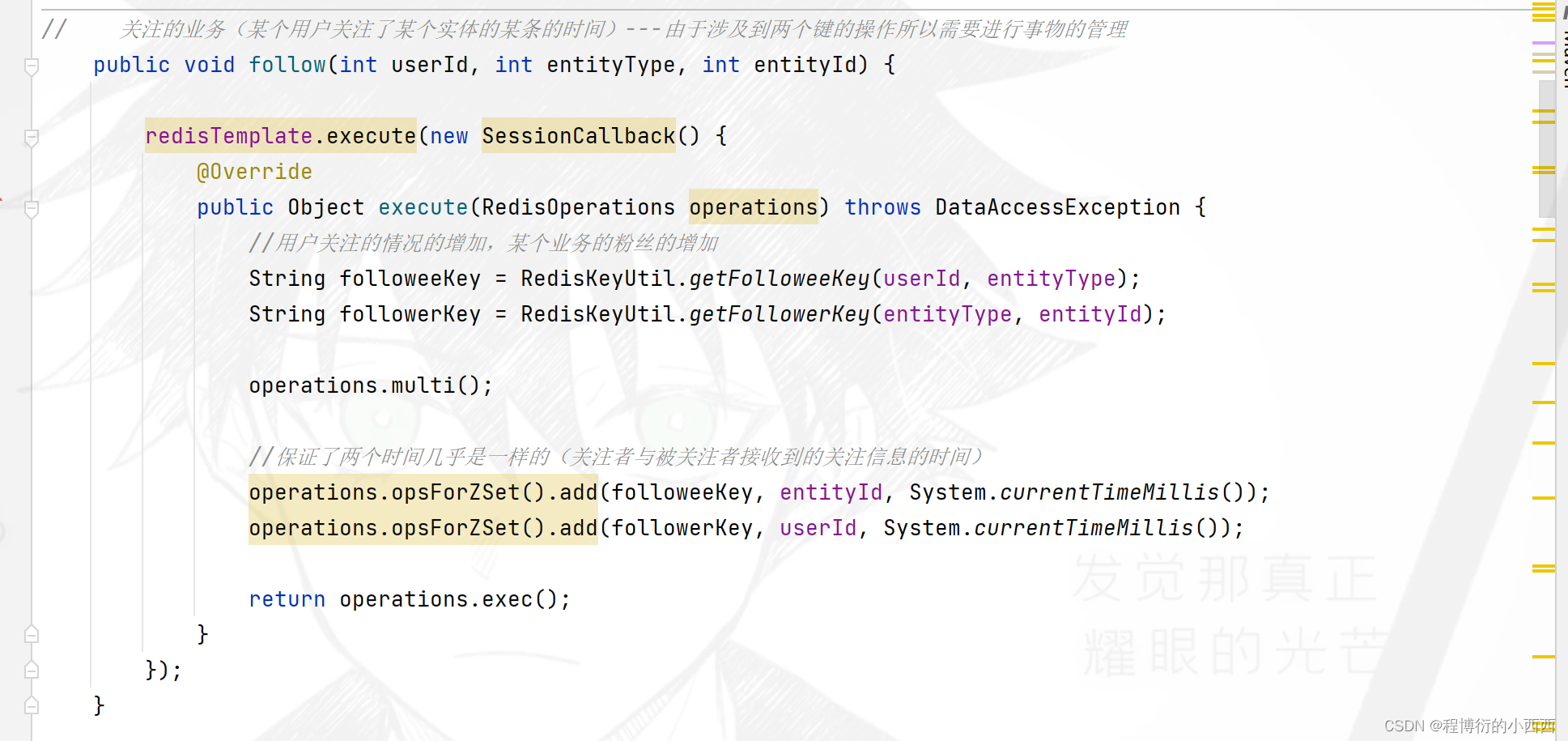
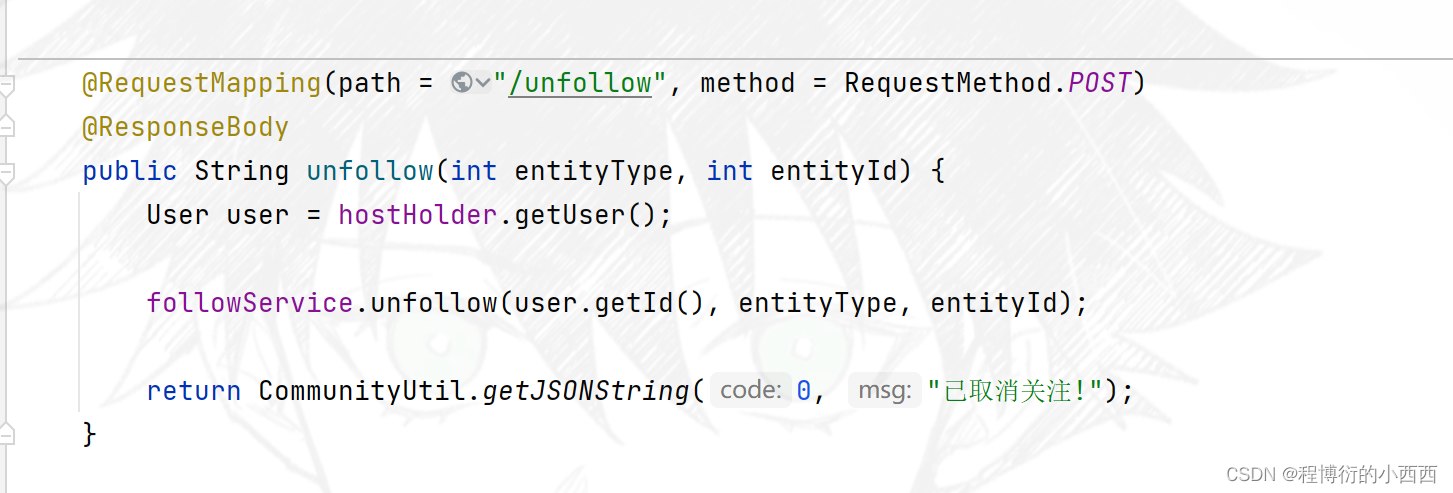
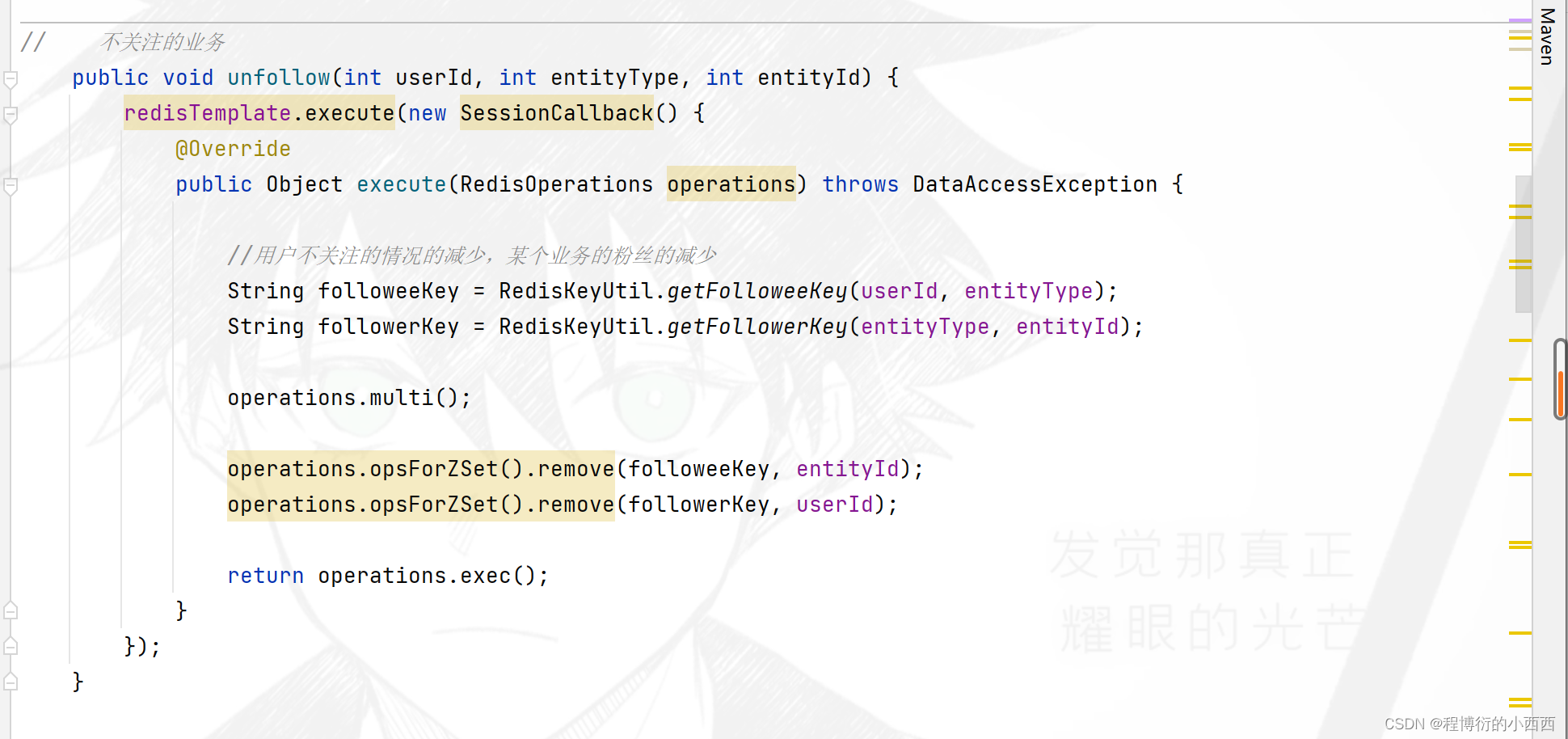
点击用户个人主页的关注或者取消关注,触发的相关的业务
redis的数据结构&&key的设计
user的关注列表(我是追随者):key=followee追随者前缀+userid, value就是zset结构(关注的用户的id, score=关注的时间),实现可以按照score排序的set集合。
user的粉丝:key=follwer前缀+userid, value就是zset结构(粉丝的用户的id, score=被关注的时间)
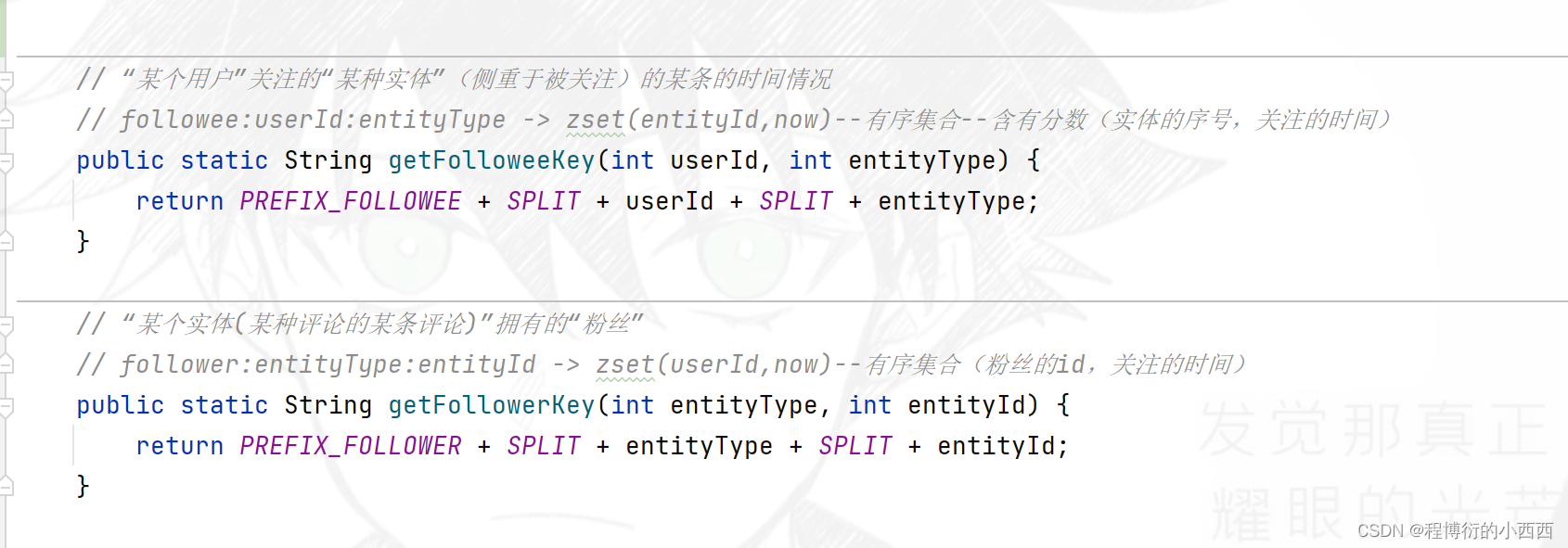
关注与取关的逻辑
使用ajax触发相关的后台的关注与取关业务的实现:(按照–查询这个人的粉丝列表zset集合中是否含有当前登录用户的userid—来实现业务的判断:关注还是取关,传入的参数是关注人或者取关人的userid)

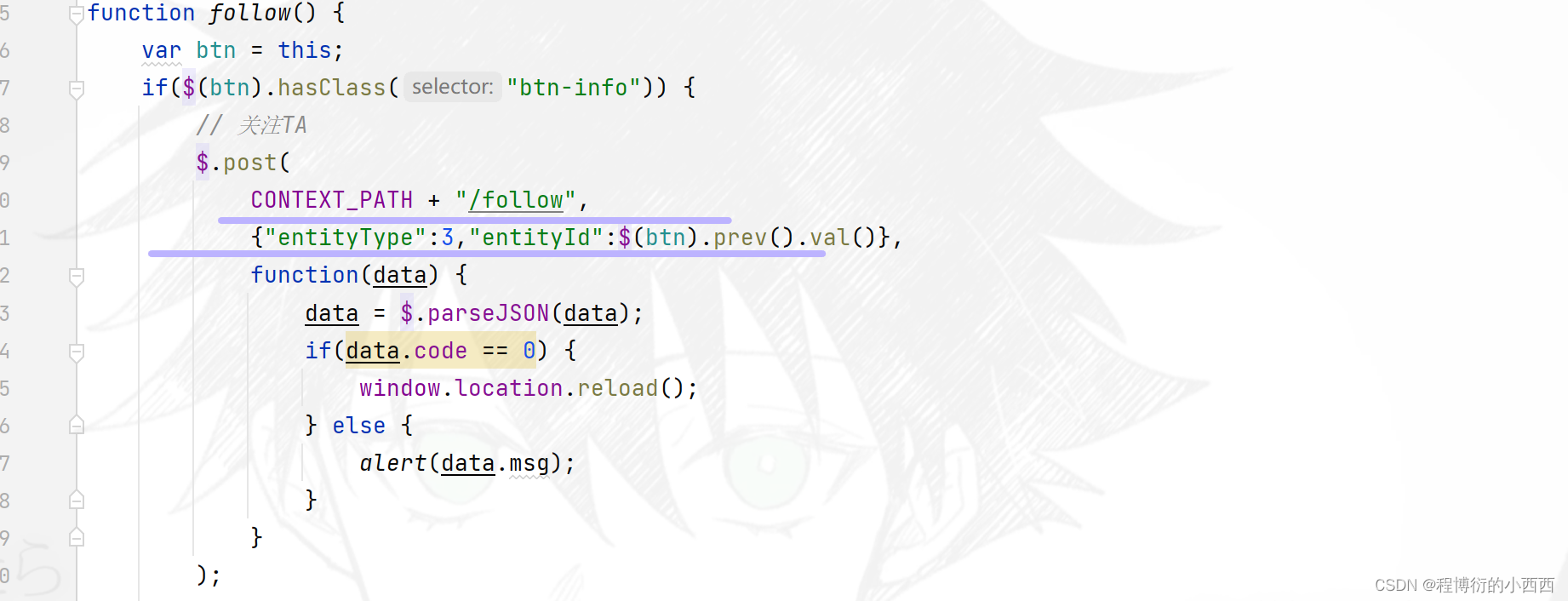
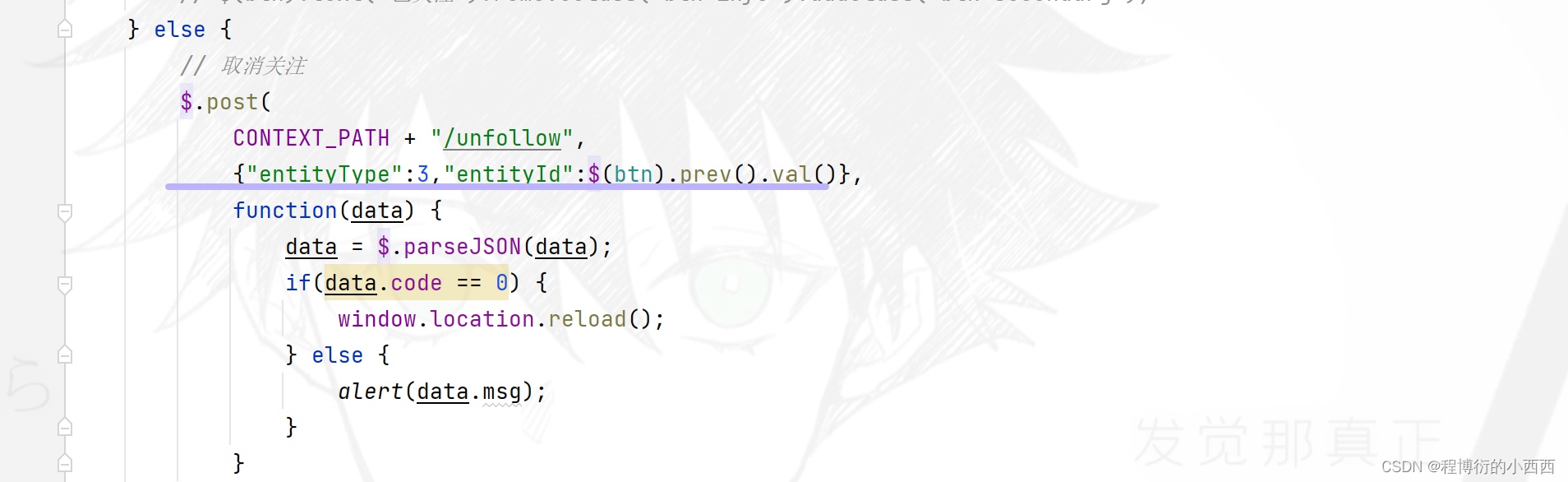
关注与取消关注,会称触发两个数据的变化(需要开启redis的事务管理):
step1:首先,关注的userid对应的关注者的zset集合需要添加上被关注的用户的userid;
step2:其次,被关注者对应的粉丝的zset集合需要添加粉丝的userid。
对应的取消关注,就是移除zset集合中的相关的用户的userid即可!!!
此外:关注某个用户会触发被点赞用户需要被系统通知消息,位于message模块,只不过fromId=1,代表系统。
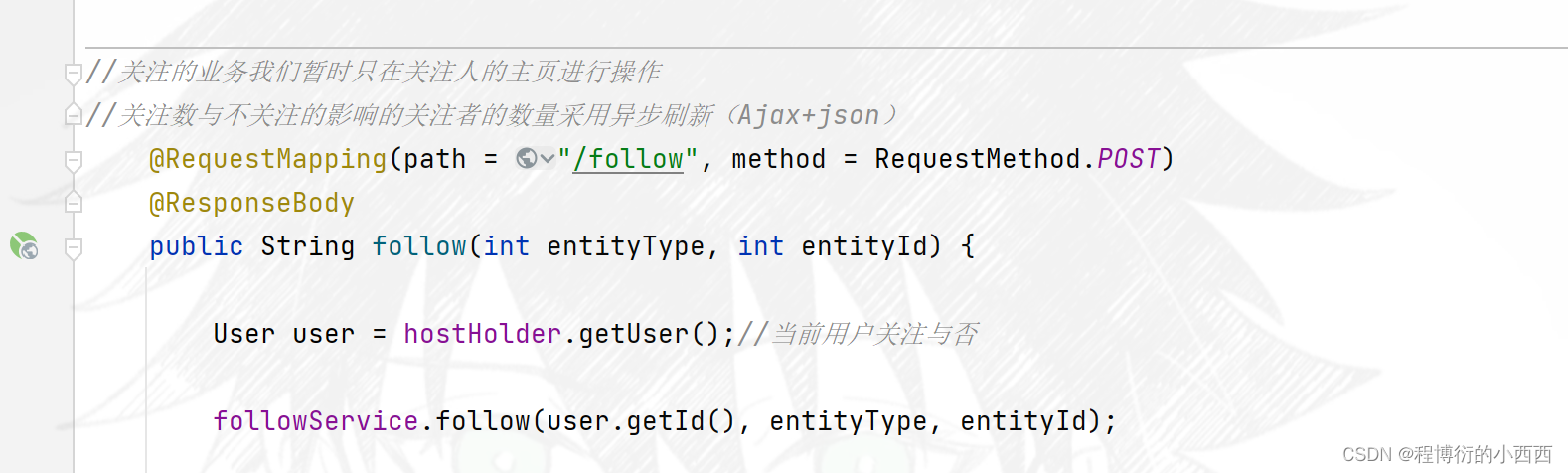
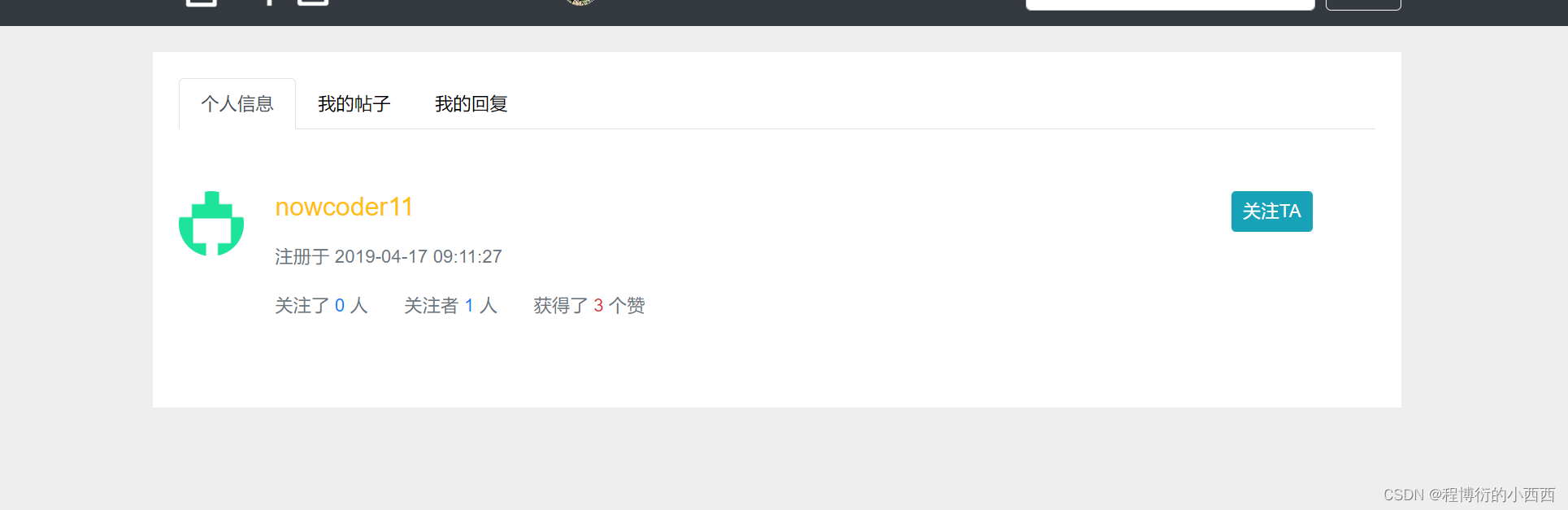
用户个人主页的展示
点击用户的头像,跳转到相应的用户的主页,url的请求路径上的路径变量就是userid

普通的查询redis的功能:统计用户的总赞数与关注者与被关注者的总的个数; 以及展示当前登录的用户是否关注了这个主页的用户,主要是查询这个人的粉丝列表zset集合中是否含有当前登录用户的userid(来显示按钮是“已关注”还是“关注他”)
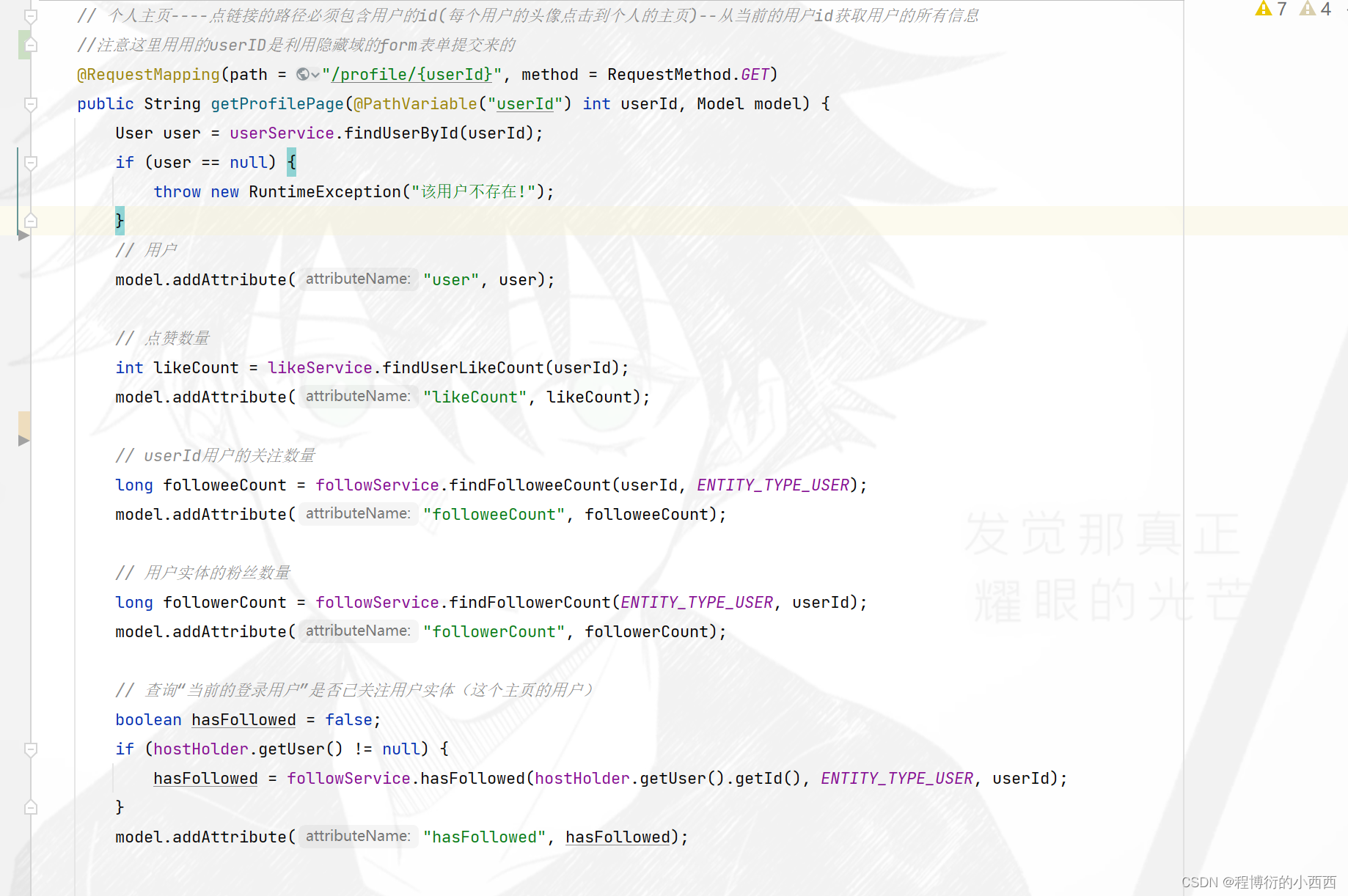
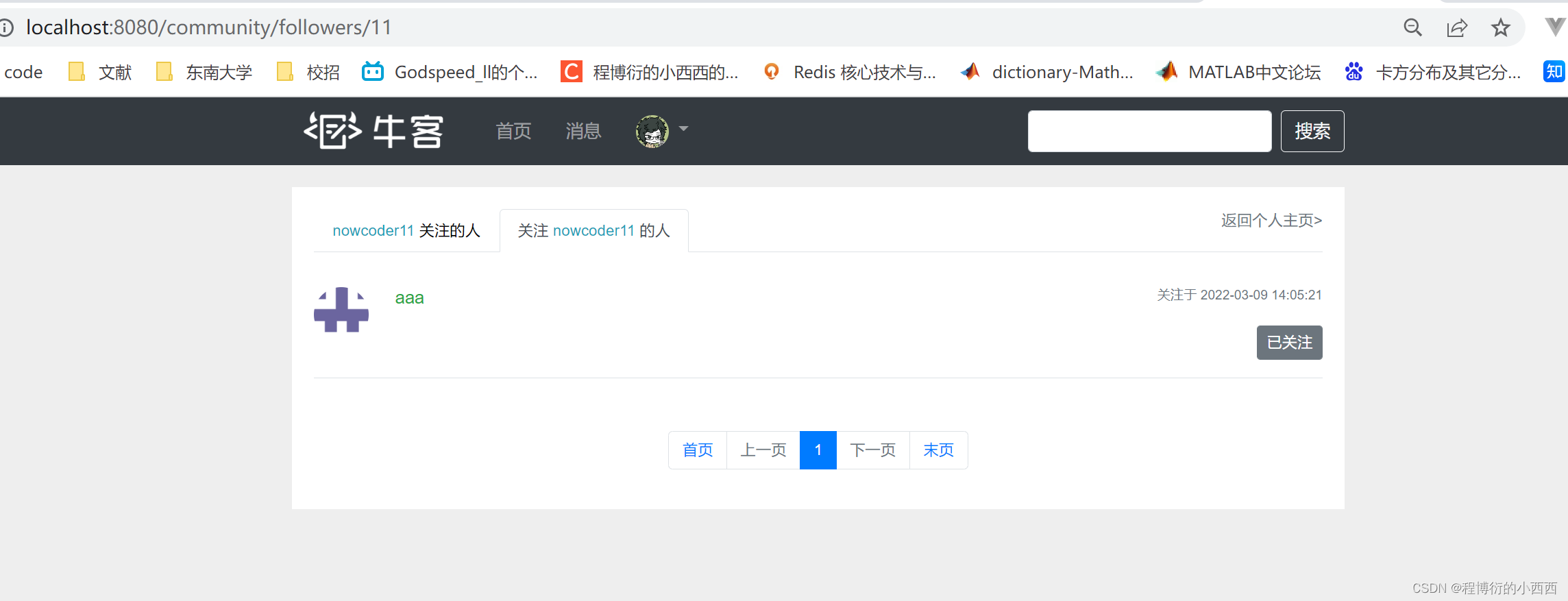
关注列表与粉丝列表的展示
点击用户个人主页的关注列表与粉丝列表,url分别跳转到相应的后端的查询业务,最终跳转到相应的html。(传入后端的参数的路径变量,一定会携带当前个人主页的userid)

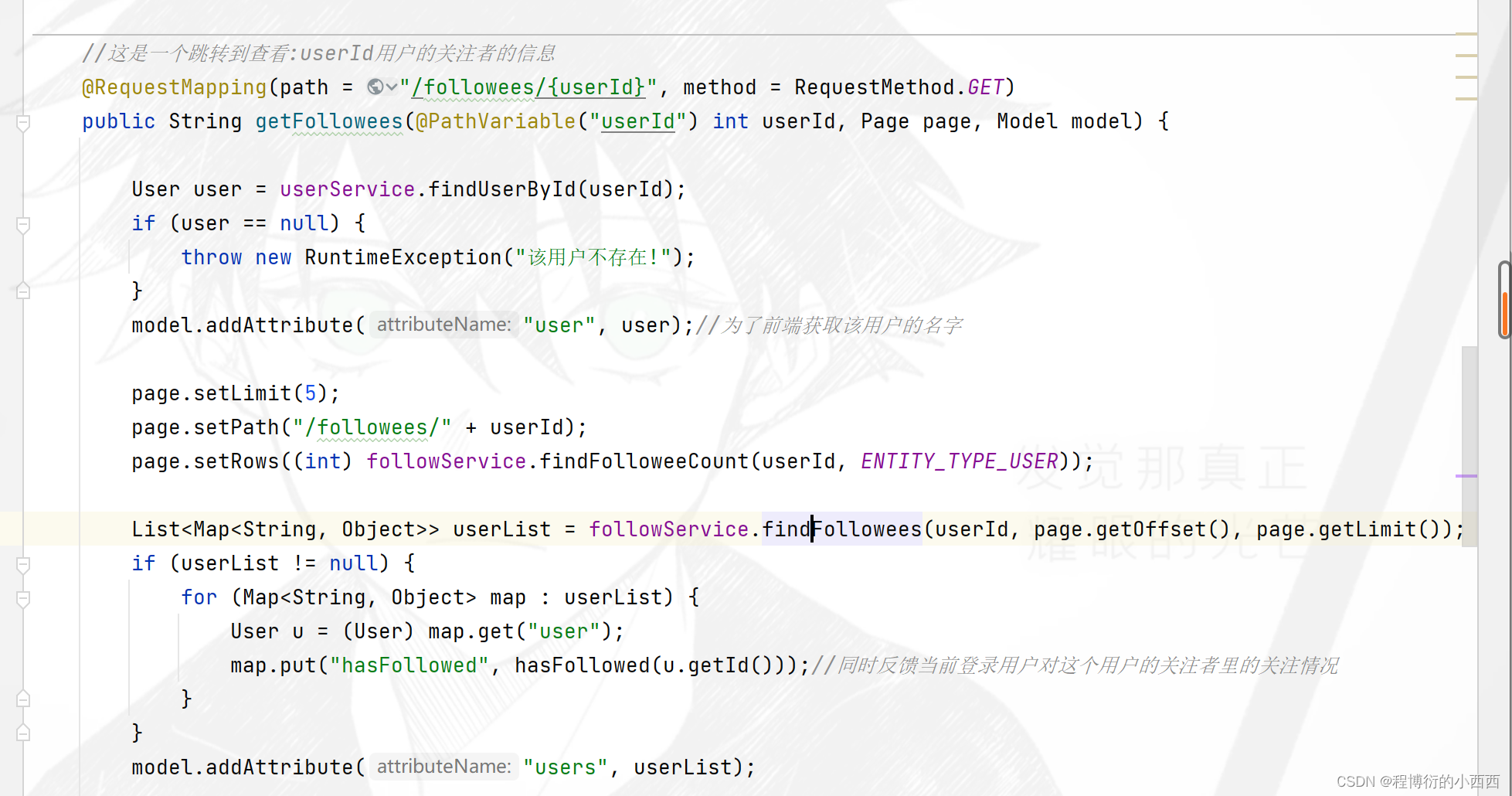
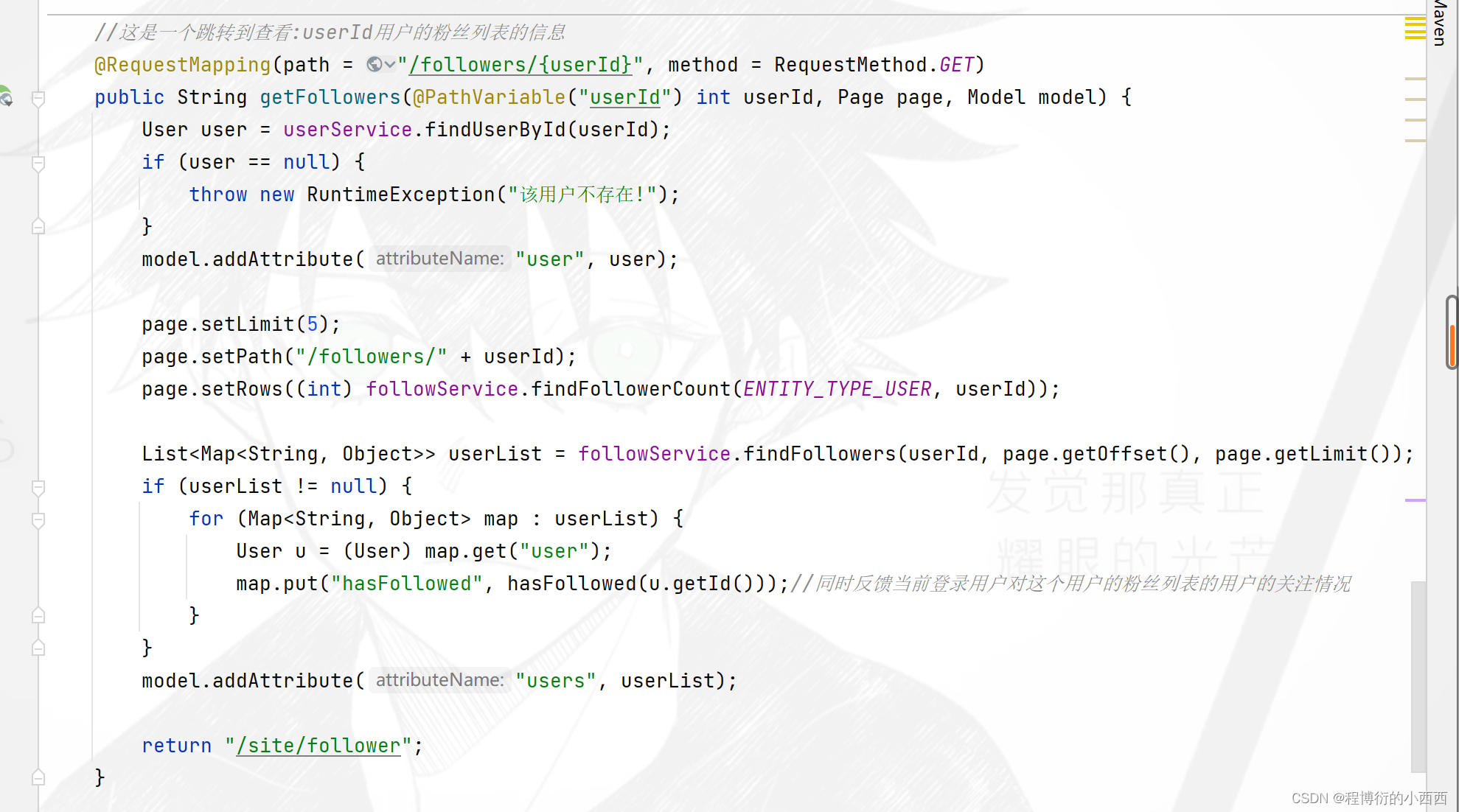
按照用户id查询对应的zset集合,获取所有的关注者与被关注者,并设置好分页参数,最终封装好参数(map集合对应用户user实体+关注与被关注时间)传入前端!!!
注意:这里的分页显示,使用的是对redis的zset集合的分页查询,因为按照分数排序之后是有序的。
此外,对于展示列表的每一个追随者,还要展示当前线程的用户是否关注了它们,即封装得到的每一个追随者需要查询当前线程用户是否关注了它们
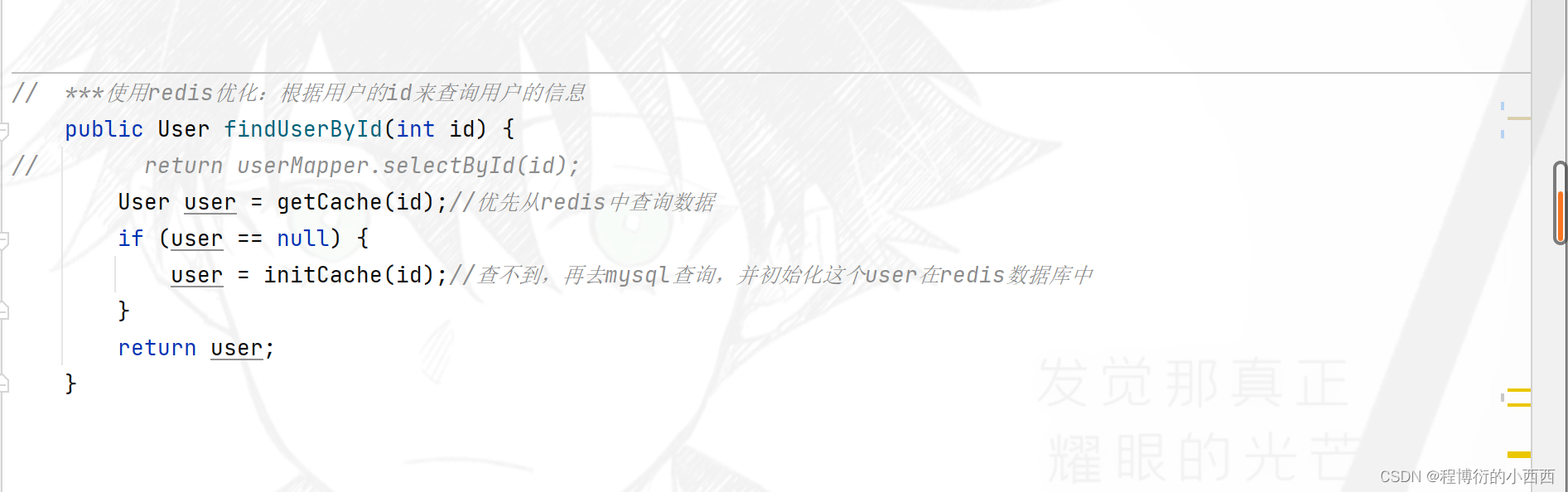
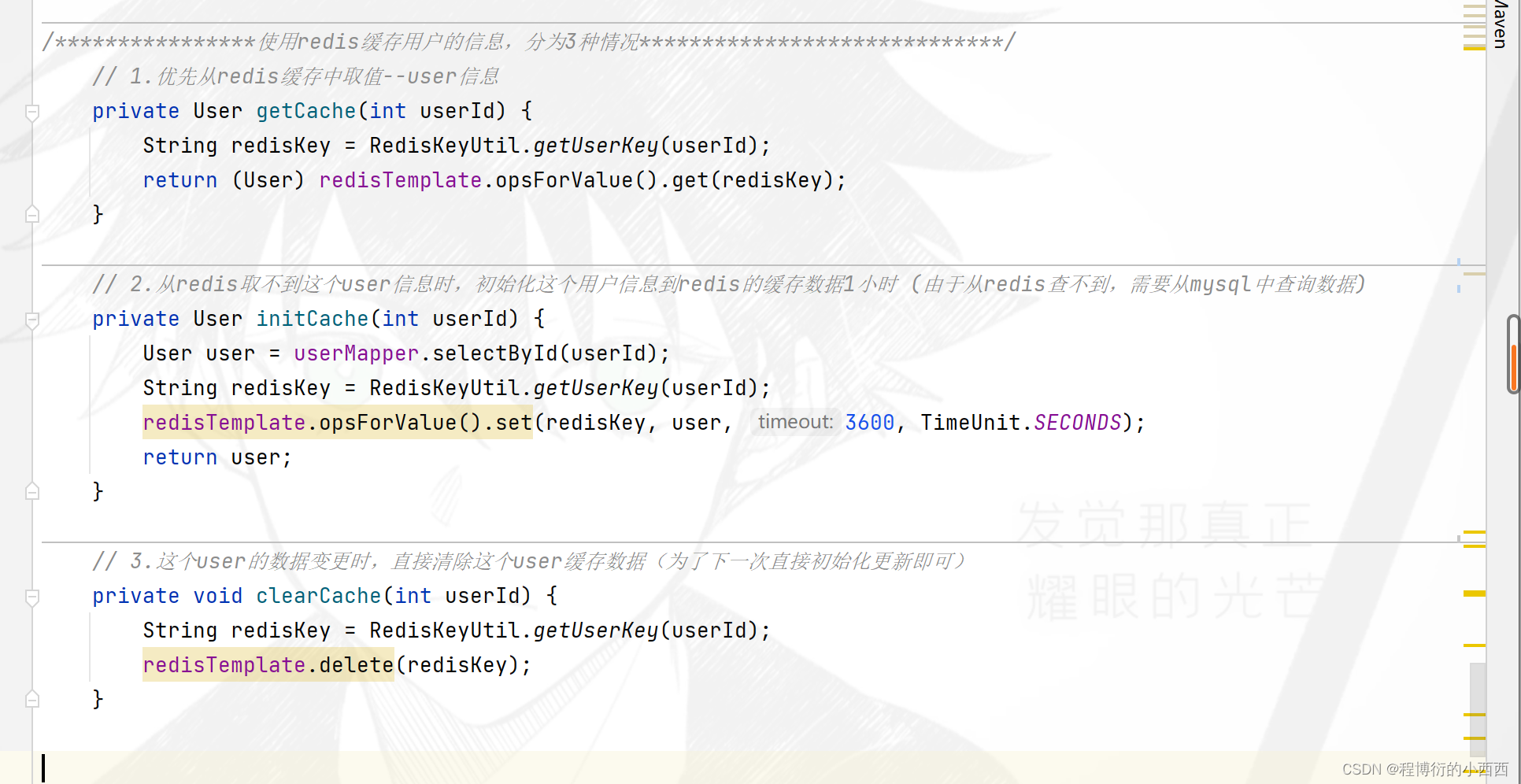
redis缓存用户信息(根据userid查询用户)
根据用户id来查询user实体的信息,使用redis的缓存进行优化
查询用户的时候先从Redis中取(redis有,getcache);没有的话先从数据库中取然后存到redis中(initcache)。用户user需要mysql更新时(修改用户头像信息,用户激活码的状态信息),直接删除Redis中的数据(clearcache)。

redis的查缓存user, 初始化缓存user,清除缓存user的相关业务的封装信息

kafka业务:系统通知(评论、点赞、关注消息)

一旦”评论(comment)点赞(like ) 关注(follow)“后就会触发–系统通知,然后立即封装event对象,并设置好主题,然后由生产者放到
topic对应的分区的消息队列中,之后消费者进行消费事件,将一个个的情况存入message(系统通知+私信)中,然后存入数据库中
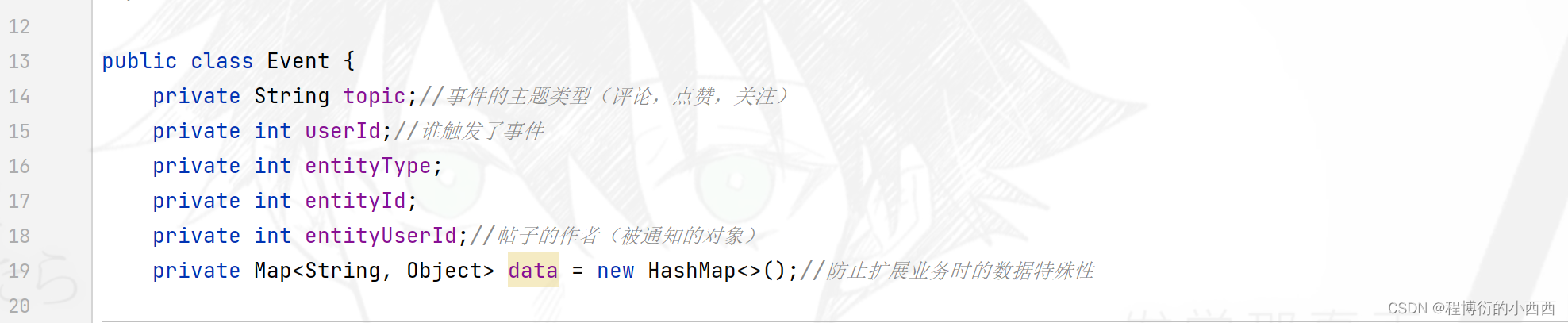
event对象结构
主要是事件的topic主题类型,触发事件的userid,触发的实体类型和id,实体属于的那个用户的userid(消息被通知的对象) +Map集合大对象(用于vo数据传输或者业务拓展的特殊数据结构)
系统通知Message的生成与消费存储
生产者(发送消息)
事件的生产者,主要是用来将触发的事件,生成后发送到指定的主题的消息队列中(显然event对象json序列化存储)。
sec1:新增评论时,触发评论的系统的通知,将评论用户id+帖子的用户id+评论的类型+评论的id+帖子id封装为event对象,进行触发事件的生产+发送到topic分区;
sec2: 点赞时,一旦点赞状态为1,就需要封装好event, 进行触发事件的生产+发送到topic分区;
sec3: 点了关注时,就需要封装好event, 进行触发事件的生产+发送到topic分区。
//生产者是我们主动去调用的对象---相应的对应到三个controller中去调用(评论comment,点赞like,关注follow)
@Component
public class EventProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
// 处理事件
public void fireEvent(Event event) {
// 将事件发布到指定的主题--event.getTopic()--(event以json字符串的形式发出)
kafkaTemplate.send(event.getTopic(), JSONObject.toJSONString(event));
}
}
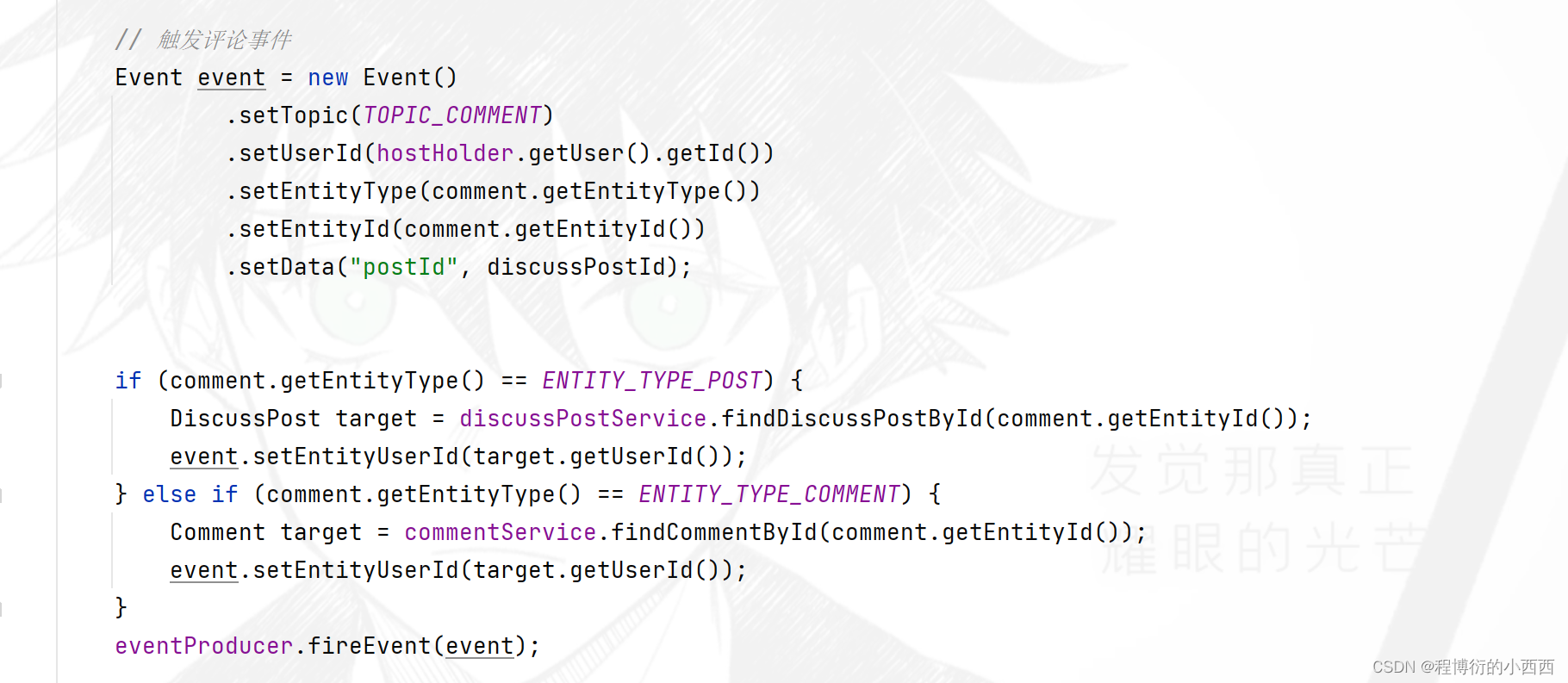
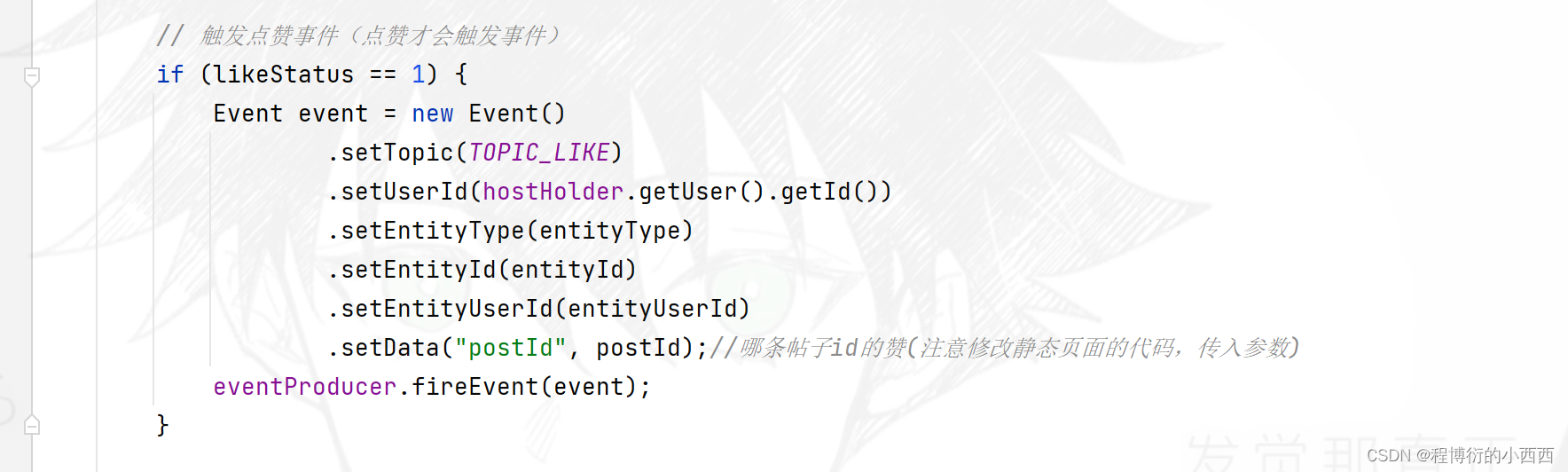
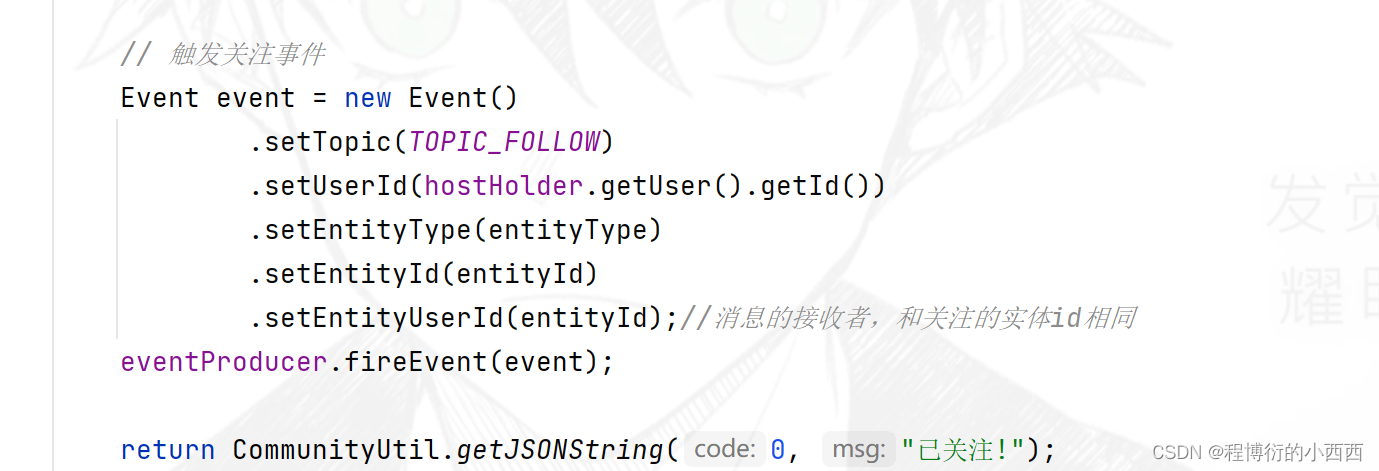
消费者(mesaage的存储)
事件的消费者,主要是用来监听主题中的消息,将event的json串转化为event对象,进而处理相关的系统通知的事件(主要任务:将系统的消息message存入mysql的数据库中)
message对象的存储方式:此时的FromId是系统的id(默认为1),ToId就是被通知的用户的id,此时的conversion_id是设置为了topic主题的名称。
注意此时的消息内容content是构造了一个Map<String,Object>对象:用于后续的前端渲染需要的数据(包括事件的触发者,实体类型,实体的id,拓展的业务数据-----例如:user评论了你的 回复)。。。
注意这个map对象需要jason化后存入到message的content字段,最后将message保存到mysql数据库中)

@KafkaListener(topics = {TOPIC_COMMENT, TOPIC_LIKE, TOPIC_FOLLOW})
public void handleCommentMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
// 发送站内通知
Message message = new Message();
message.setFromId(SYSTEM_USER_ID);
message.setToId(event.getEntityUserId());
message.setConversationId(event.getTopic());
message.setCreateTime(new Date());
Map<String, Object> content = new HashMap<>();
content.put("userId", event.getUserId());
content.put("entityType", event.getEntityType());
content.put("entityId", event.getEntityId());
if (!event.getData().isEmpty()) {
for (Map.Entry<String, Object> entry : event.getData().entrySet()) {
content.put(entry.getKey(), entry.getValue());
}
}
message.setContent(JSONObject.toJSONString(content));
messageService.addMessage(message);
}
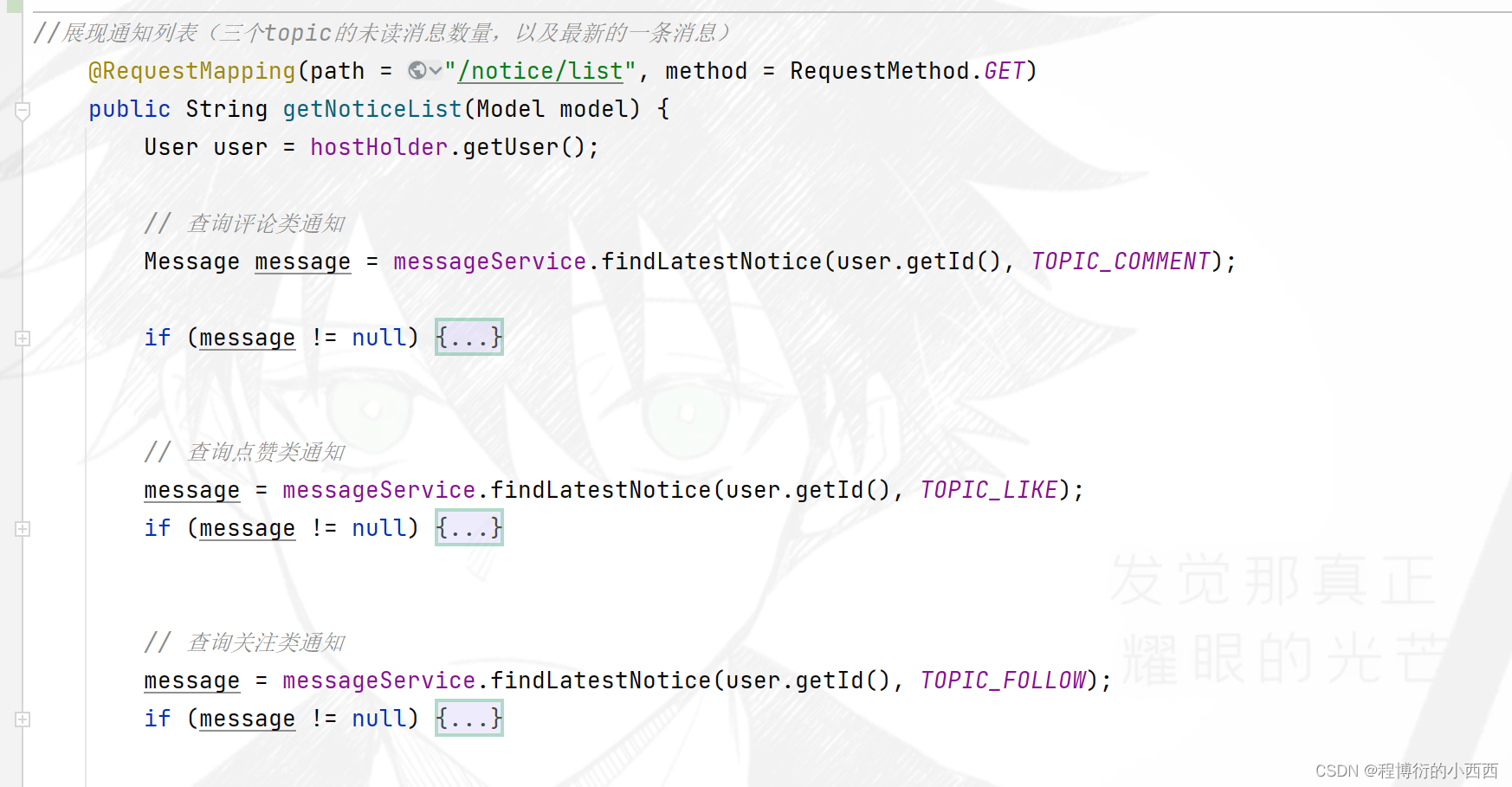
系统通知列表的展示

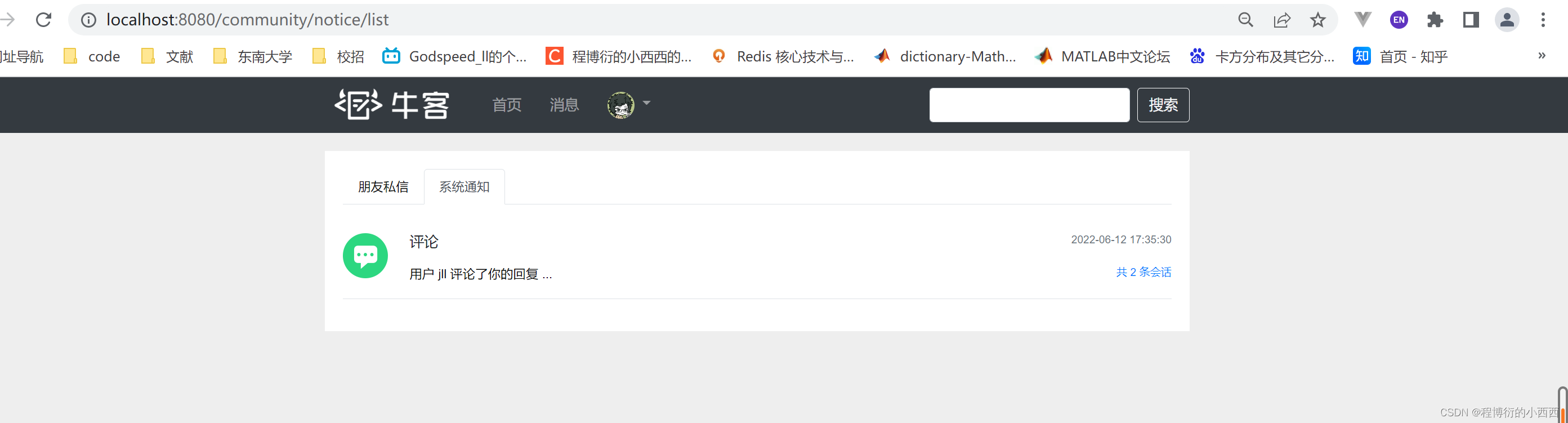
由于系统通知,只有三个会话框(对应三个主题:评论,点赞,关注),所以进行sql查询的时候conversion_id按照主题进行分组的查询挑选分组中最新的一条消息的id,然后查询该message的具体的内容,展示最新未读的那个topic的通知消息!!!
查询对应主题的最新的一条未读的消息(将content中的内容jason字符串转变为Map对象,进行封装到前端的数据)+对应主题的未读的消息条数,封装好传入前端,展示即可!!!
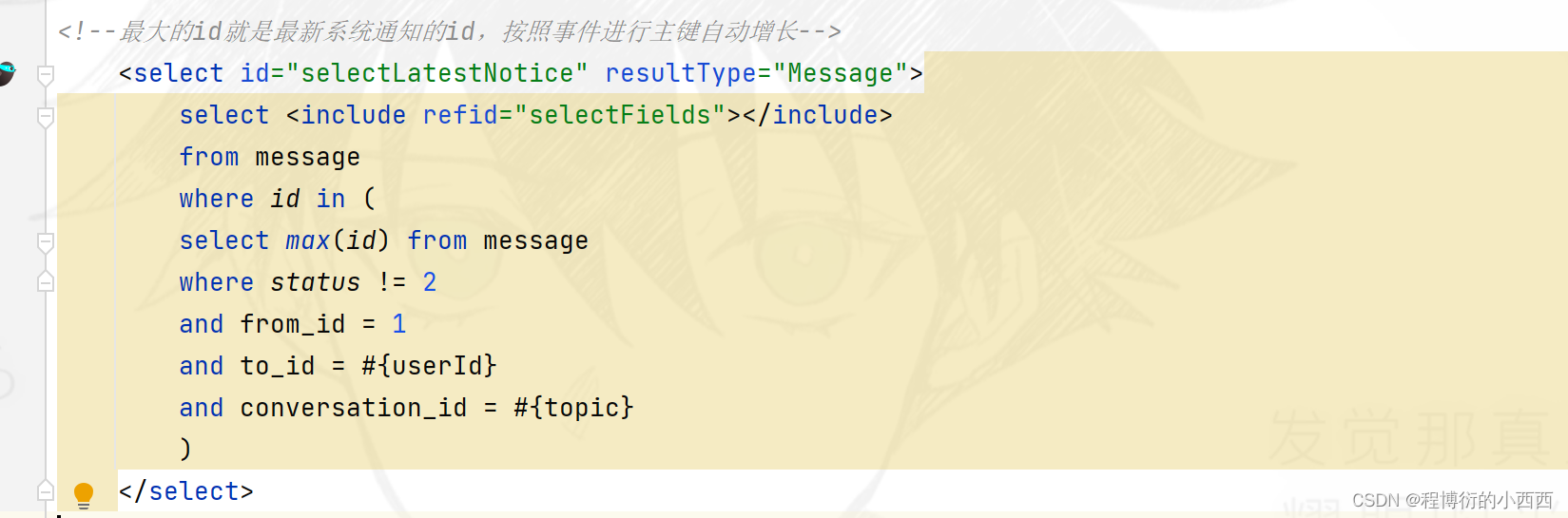
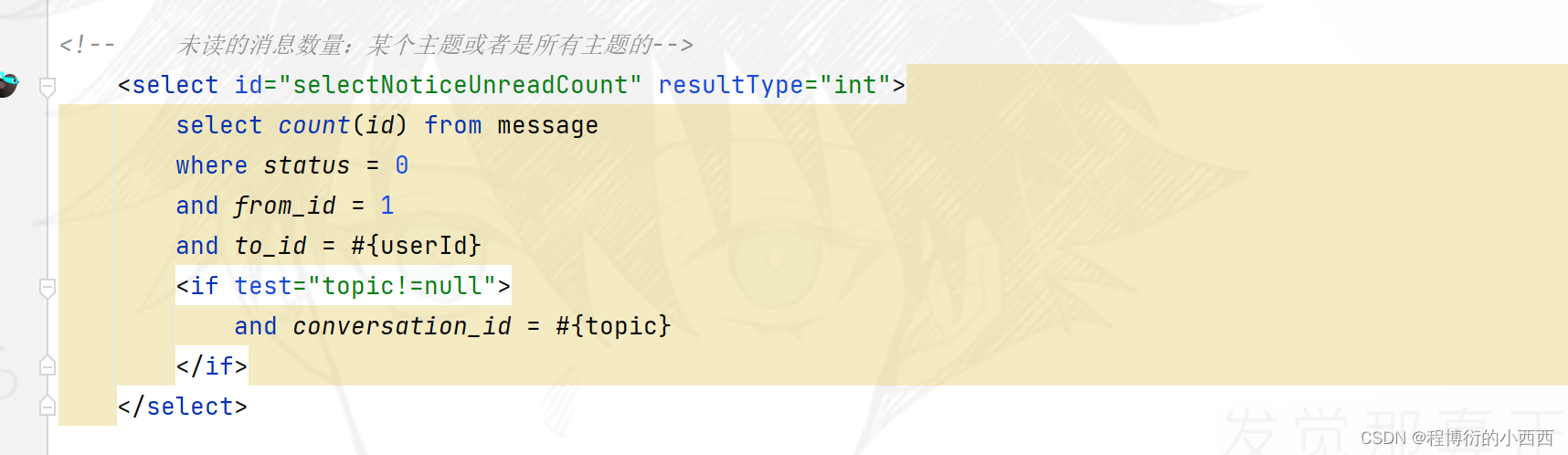
查询系统未读的消息数量,model给前端,放在导航栏上面展示
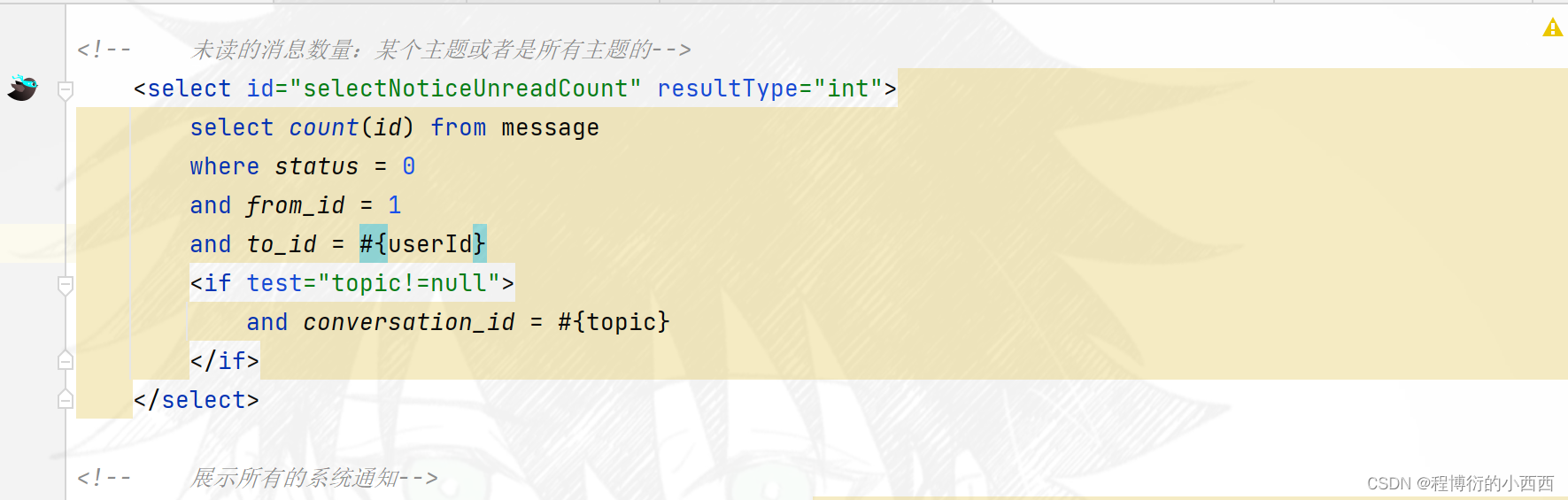

主题通知的详情(comment,like , follow)
点击每个分区的通知列表的最新内容,分别跳转到对应主题通知的详情页面(显然路径中有一个{topic}的路径变量!!!)
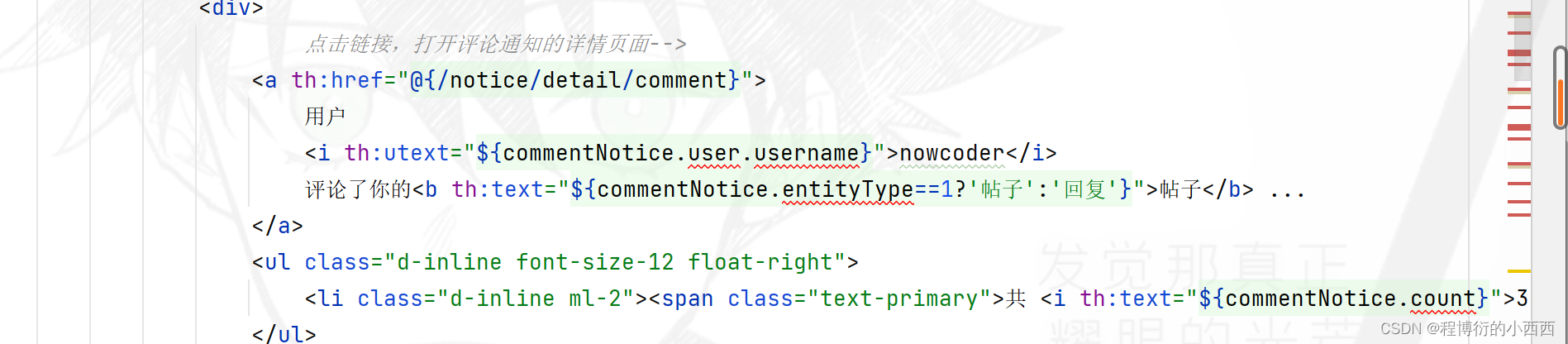

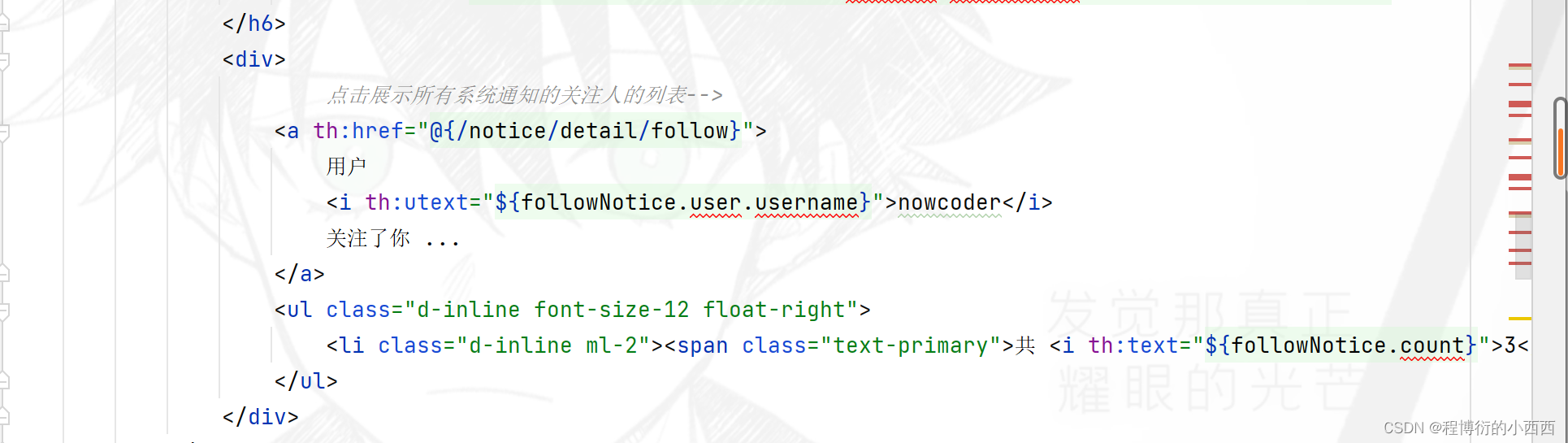
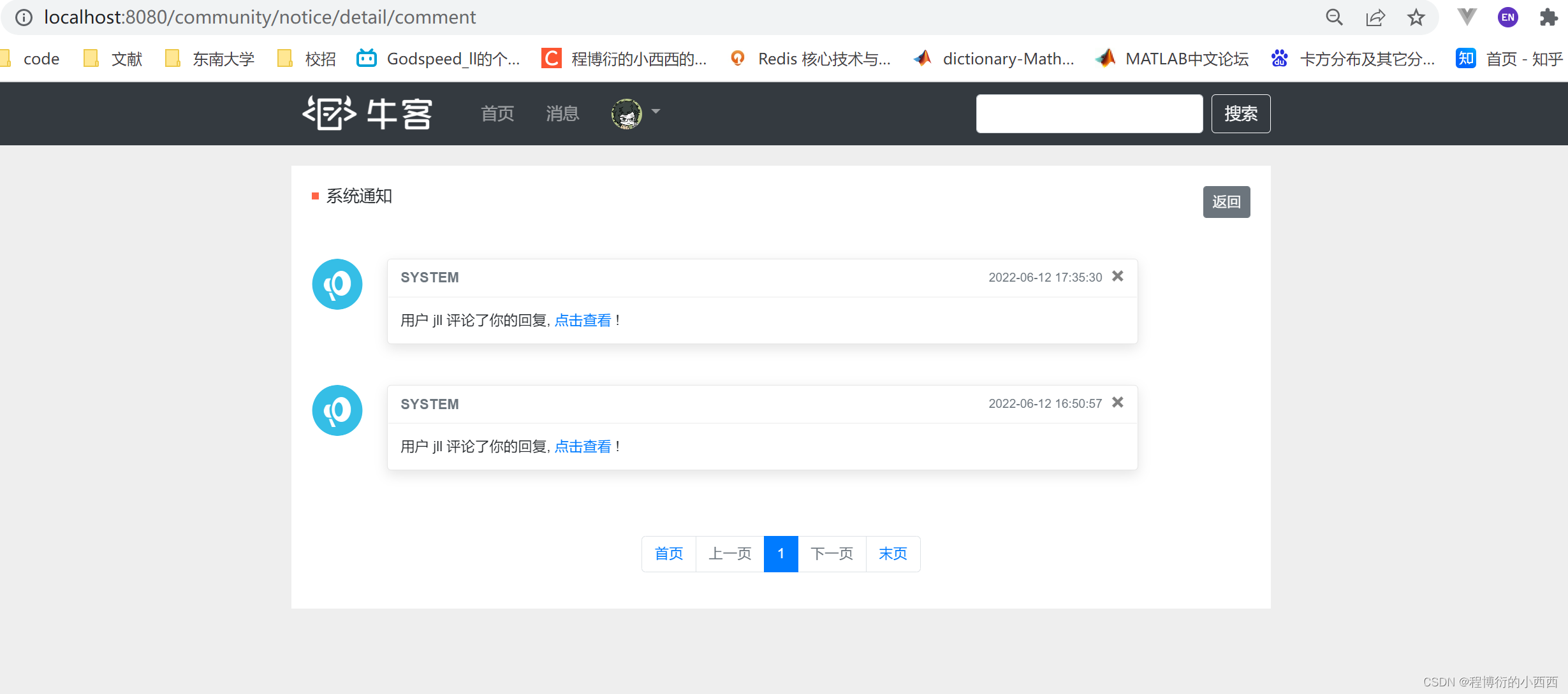
首先查找当前线程的登录用户的对应分区的未读的通知消息,进行封装model到前端;其次,将所有未读的系统消息设置为已读的状态,默认点开消息的详情页,就设置所有未读的消息为已读(批量更新)!!
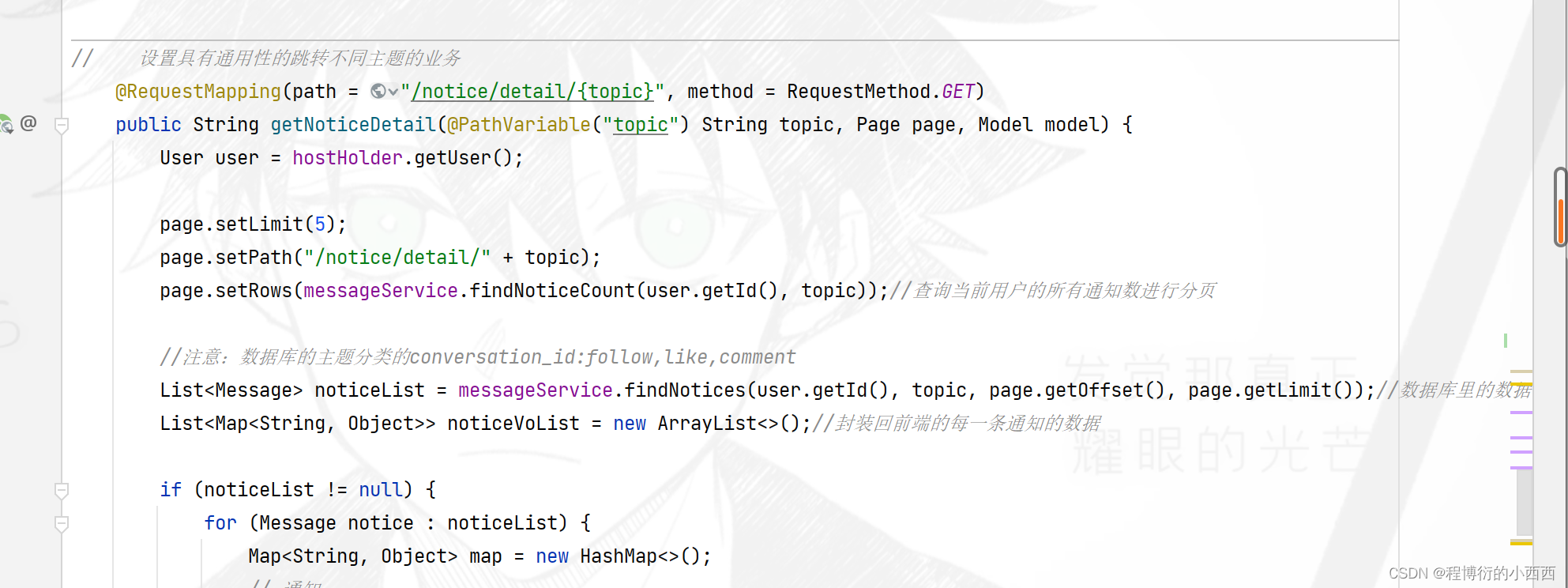
消息拦截器—消息总数实时更新
(注意:牛客网的头部每个html的页面都使用了,所以任何controller业务执行前,都需要查询最新的未读的消息总数,然后渲染在网页的头部)
每次在controller业务之前,都实时的查询最新的未读的消息总数(私信未读sql查询+通知未读sql查询)。注意必须是当前用户登录的情况下,最终将未读的消息总数model到前端,展示在导航栏上面

//利用拦截器“实现所有未读私信+未读通知的总的消息数量”传入到ModelAndView前端显示
@Component
public class MessageInterceptor implements HandlerInterceptor {
@Autowired
private HostHolder hostHolder;
@Autowired
private MessageService messageService;
// 在Controller之前执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
User user = hostHolder.getUser();
if (user != null && modelAndView != null) {
int letterUnreadCount = messageService.findLetterUnreadCount(user.getId(), null);
int noticeUnreadCount = messageService.findNoticeUnreadCount(user.getId(), null);
modelAndView.addObject("allUnreadCount", letterUnreadCount + noticeUnreadCount);
}
}
}
注意拦截器的注册的顺序,确保登录凭证的拦截器位于消息统计的拦截器之前,这样才能在消息拦截器内获取本线程内的登录用户的信息!!!!
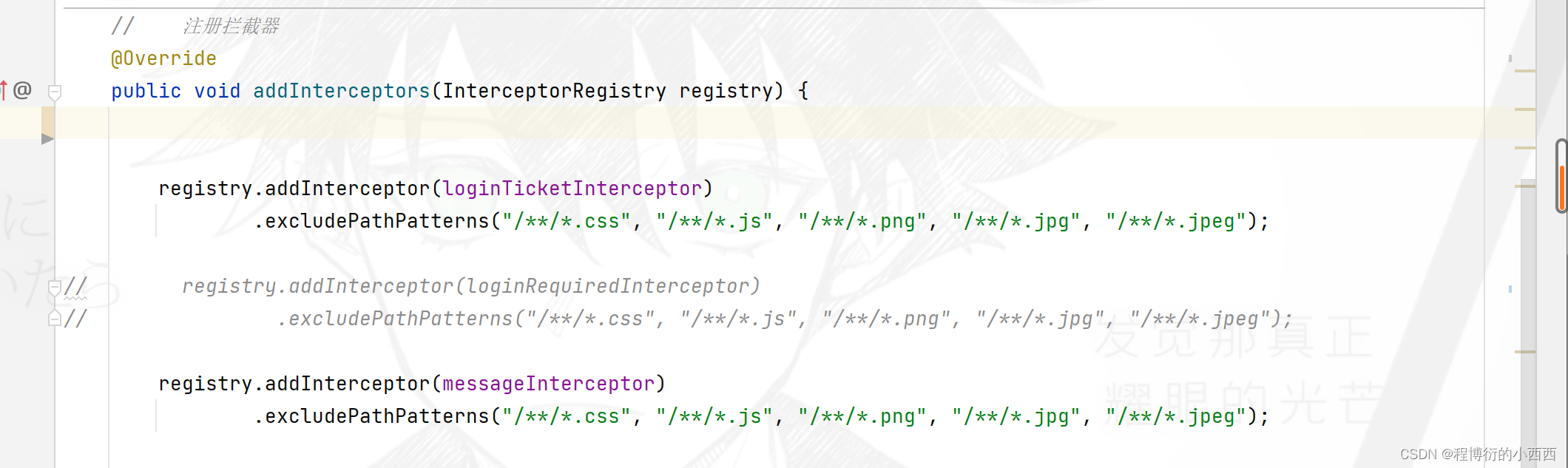
SpringSecurity:置顶、加精、删除权限
认证(登录凭证的拦截器)
controller之前(Threadlocal绑定user信息),相当于完成认证:
在每次controller之前,拦截器首先从cookie中获取用户成功登陆时的ticket的登录凭证的凭证码,从redis中查询具体的登录凭证的对象的具体信息loginTicket(里面封装凭证的过期时间以及有效的状态)
判断1(cookie):cookie的这个ticket是否还存在,可能也已经过期了,毕竟当时是按照remember me的时间设定的过期的时间;
判断2(redis–loginticket):根据从redis获得的loginticket的对象,判断这个登录凭证的状态是否是有效状态&&并且过期的时间点在当前时间的之后,说明这个登录凭证真的是有效的
操作1(ThreadLocal):根据登录凭证中的userid查询出整个的user的实体对象的信息,将这个信息绑定在本地线程ThreadLocal中,实现同一个线程中可以共享用户的数据信息,不用频繁的查用户是否登录;
操作2(SpringSecutiry授权需要认证的token):封装用户名密码的认证令牌—包含用户名+密码+用户的role身份信息,传到SpringSecurity的上下文环境securityContext中,然后将SecurityContext传入到安全上下文环境的持有者SecurityContextHolder中,用于后续的用户de相关的业务的授权从上下文环境获取令牌的信息—然后根据用户的信息进行相应的授权
// 在Controller之前执行
// 注意cookie是通过request传过来的
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 从cookie中获取凭证(我们当时在登录用户时,成功登录的用户将登陆凭证存入了cookie)
String ticket = CookieUtil.getValue(request, "ticket");
if (ticket != null) {
// 查询凭证
LoginTicket loginTicket = userService.findLoginTicket(ticket);
// 检查凭证是否有效:凭证结果非空;状态为0有效(我们推出登录时设置为了1,所以退出登陆后此时不会在当前线程放入用户);
// 并且超时时间晚于当前的时间---才是有效的凭证
if (loginTicket != null && loginTicket.getStatus() == 0 && loginTicket.getExpired().after(new Date())) {
// 根据凭证的用户id来进行查询用户
User user = userService.findUserById(loginTicket.getUserId());
// 在分布式的环境下,使用session存在共享数据的问题
// 在本次请求中持有用户(在多个线程之间隔离存储用户),并存入threadlocal里
hostHolder.setUser(user);
//(使用整套的security的认证与授权时),会出现需要将认证的信息“令牌”传给授权使用,在这里我们自己的认证方法,同样需要手动传入信息
// 构建用户认证的结果,并存入SecurityContext,以便于Security进行授权.
// principal: 主要信息; credentials: 证书; authorities: 权限;
Authentication authentication = new UsernamePasswordAuthenticationToken(
user, user.getPassword(), userService.getAuthorities(user.getId()));
SecurityContextHolder.setContext(new SecurityContextImpl(authentication));//不理解
}
}
return true;
}
授权方式(SpringSecurity+thymeleaf的Security)
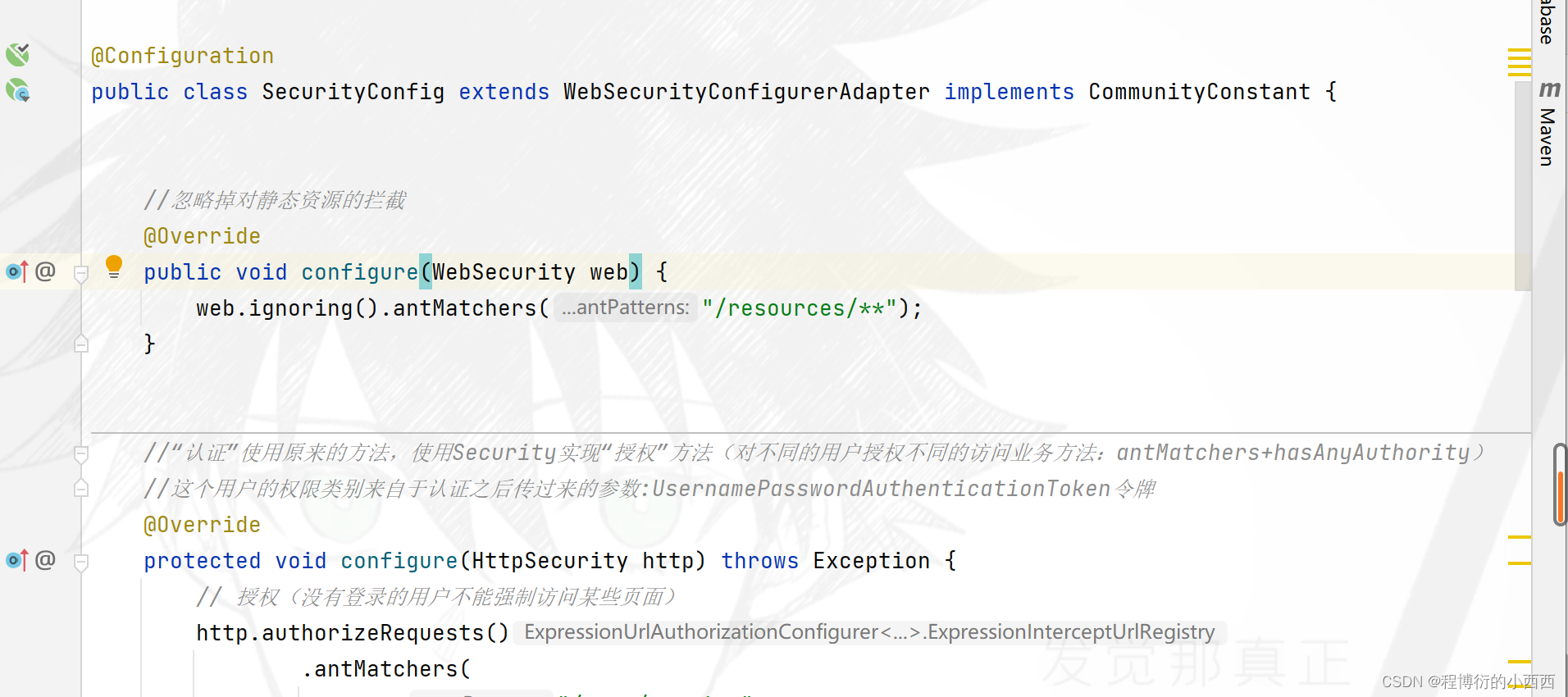
在Security的配置类中(忽略静态资源的访问的权限控制):
配置1(用户登录&&权限匹配器):从SecurityContext的上下文环境中获取Token令牌来 获取用户的
权限信息(在登录拦截器的时候传入了token到SpringSecurity的上下文环境),然后开放相应的业务应用—匹配器用于匹配用户的权限与url业务关系。(管理员和版主可以置顶和加精帖子,只有管理员可以删除帖子和查看网站的访问量!!)
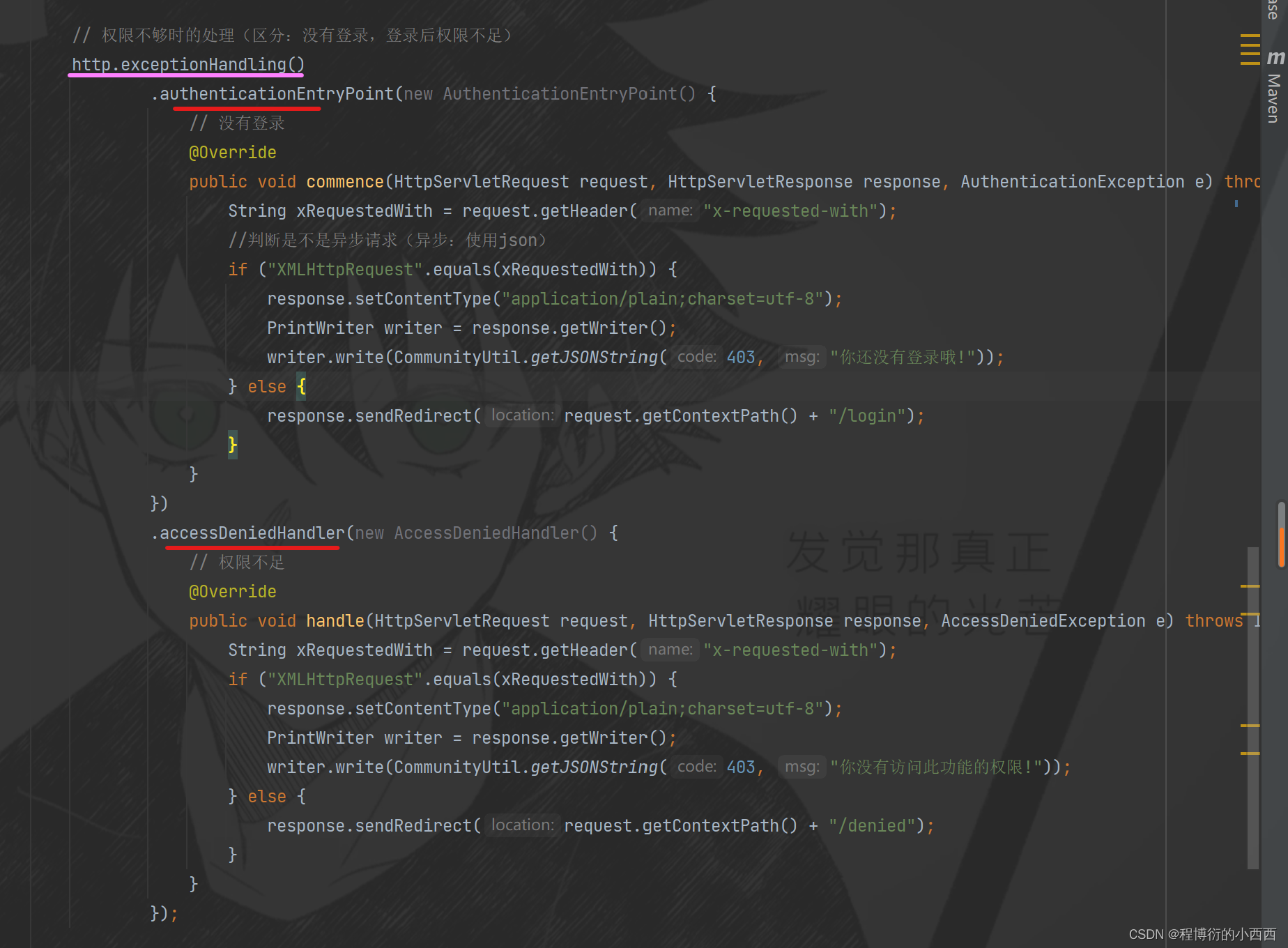
配置2::用户没有登陆时,就重定向到登陆的页面(如果是json的异步请求:返回给ajax的数据就是错误的信息);
配置3:如果权限不足,就重定向到拒绝的页面(如果是json的异步请求:返回给ajax的数据就是错误的信息)

具体的配置类:
//“认证”使用原来的方法,使用Security实现“授权”方法(对不同的用户授权不同的访问业务方法:antMatchers+hasAnyAuthority)
//这个用户的权限类别来自于认证之后传过来的参数:UsernamePasswordAuthenticationToken令牌
@Override
protected void configure(HttpSecurity http) throws Exception {
// 授权(没有登录的用户不能强制访问某些页面)
http.authorizeRequests()
.antMatchers(
"/user/setting",
"/user/upload",
"/discuss/add",
"/comment/add/**",
"/letter/**",
"/notice/**",
"/like",
"/follow",
"/unfollow"
)
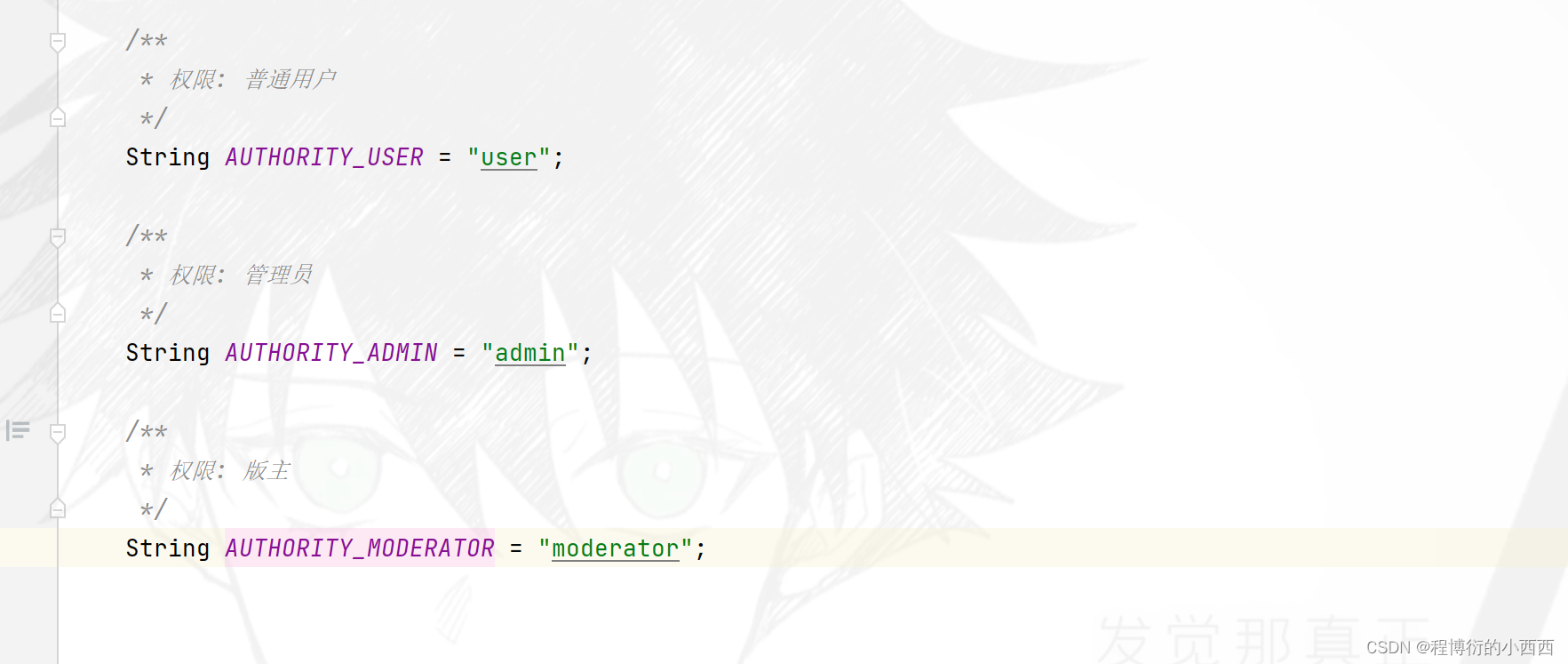
.hasAnyAuthority(
AUTHORITY_USER,
AUTHORITY_ADMIN,
AUTHORITY_MODERATOR
)
.antMatchers(
"/discuss/top",
"/discuss/wonderful"
)
.hasAnyAuthority(
AUTHORITY_MODERATOR
)
.antMatchers(
"/discuss/delete",
"/data/**"
)
.hasAnyAuthority(
AUTHORITY_ADMIN
)
.anyRequest().permitAll()
.and().csrf().disable();//不启动csrf攻击的检查
异常处理:1.没有认证通过(json返回错误信息/重定向至登录页面);2.权限不足(json返回错误信息/重定向至拒绝访问的页面)
置顶、加精(帖子热度)、删除业务(帖子详情页)------简单的Crud
前端使用ajax请求相关的业务,同时相关的置顶加精按钮按照:security的权限进行判断显示(thymleaf和springSecurity的整合,或许也是从上下文环境中拿到的权限信息)


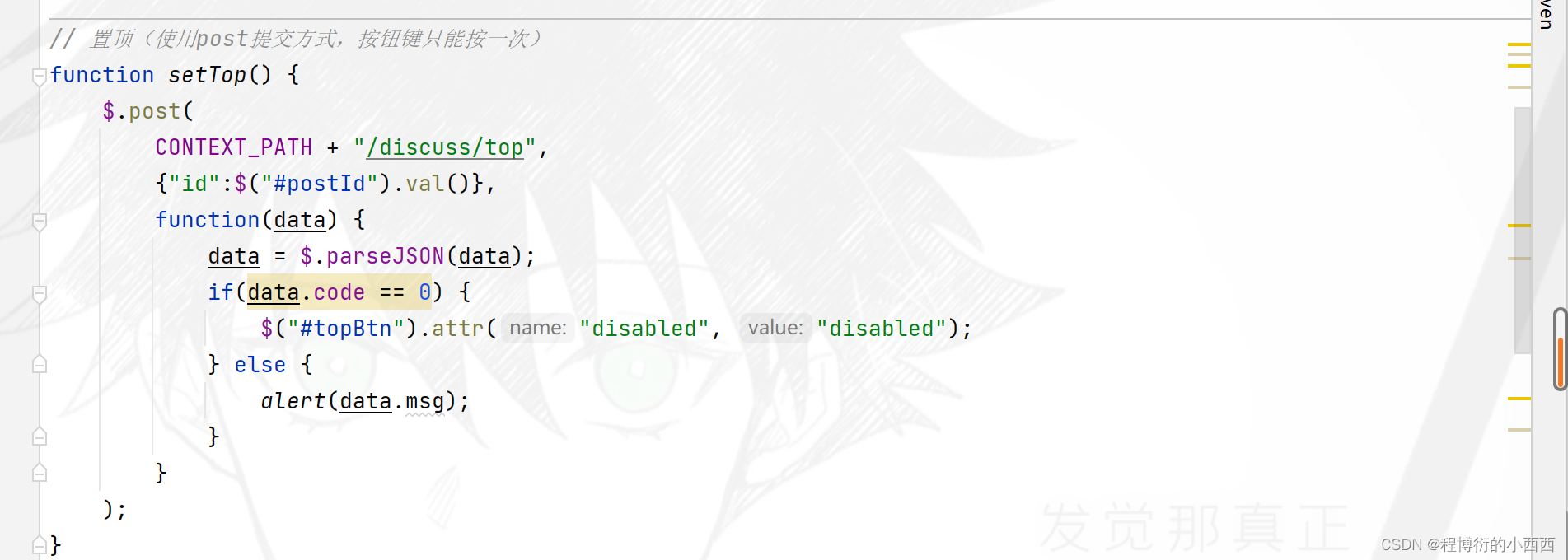
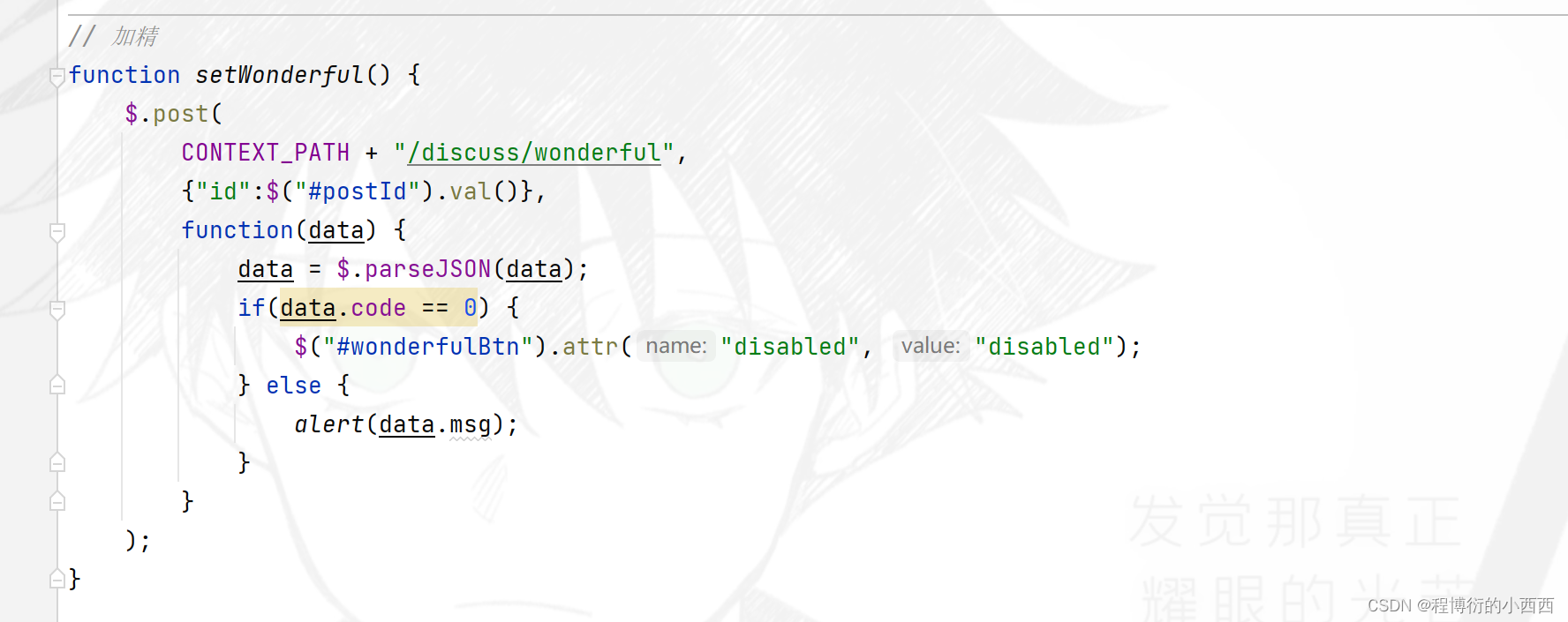
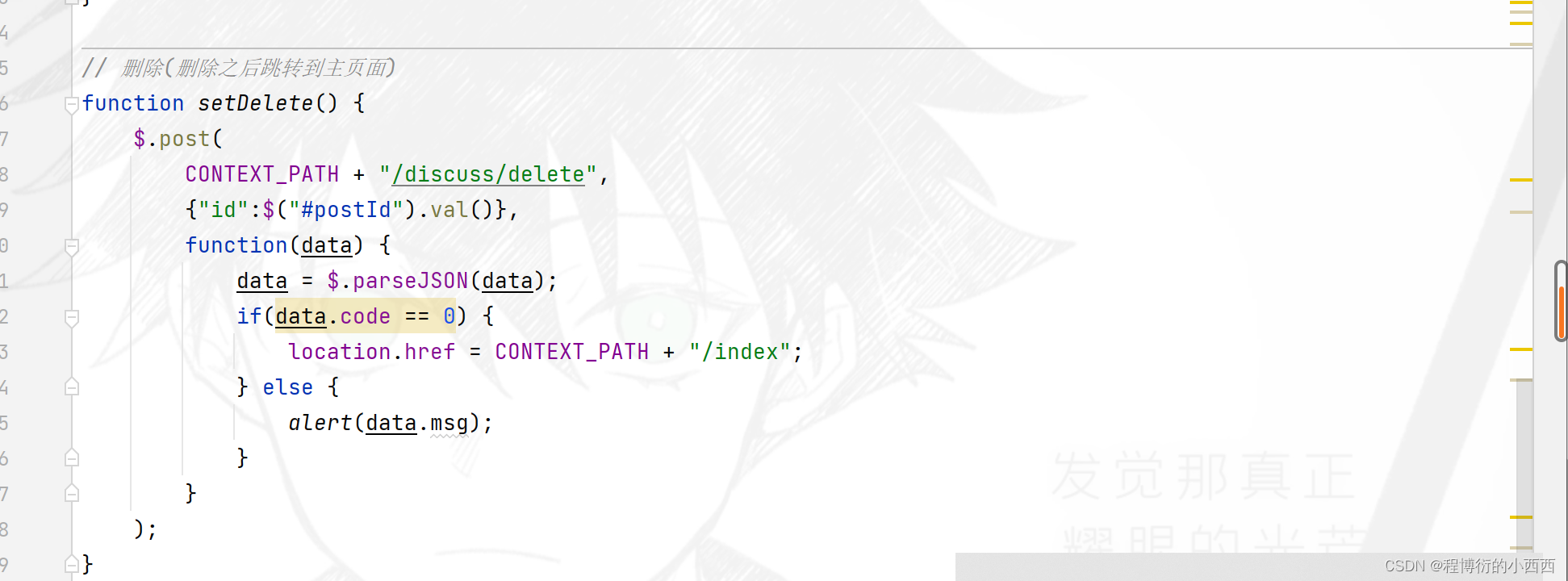
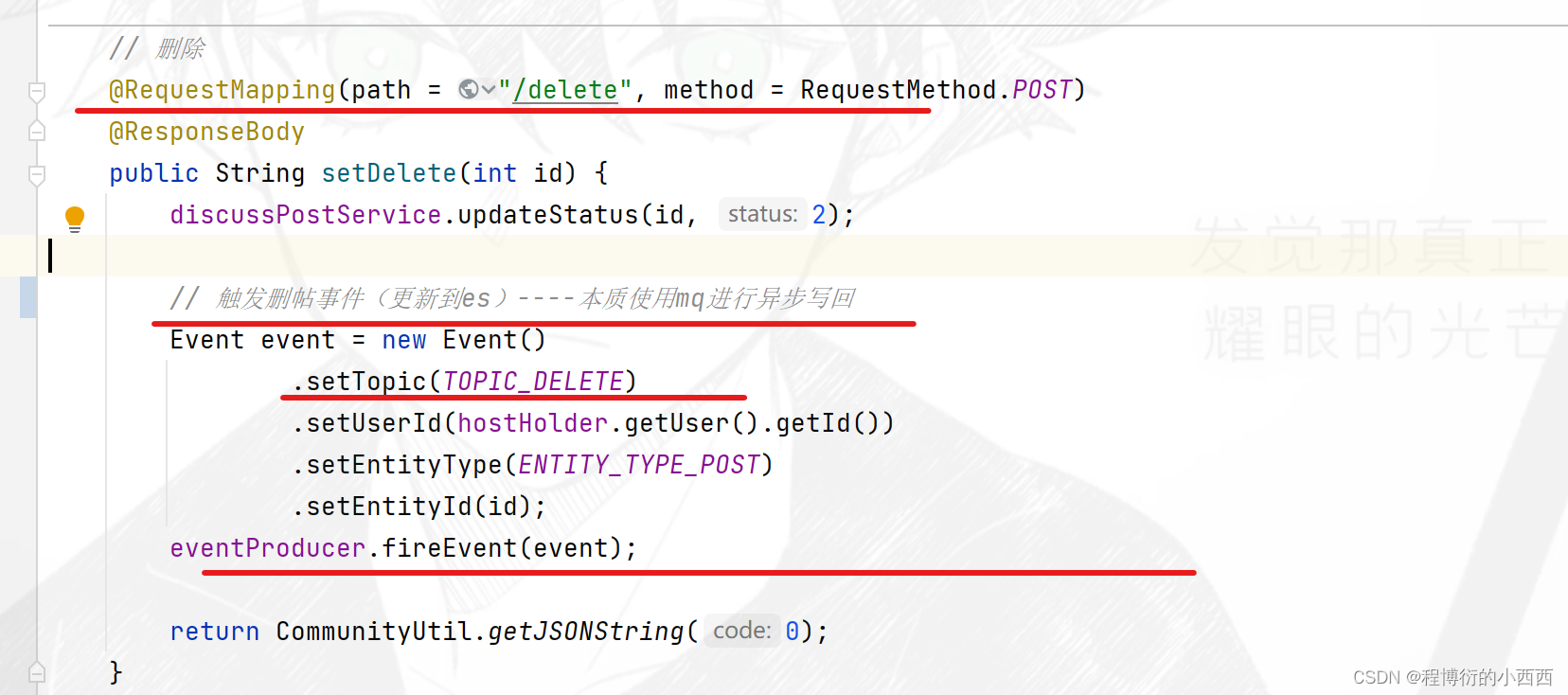
后台进行简单的数据库的帖子的“类型:0-普通; 1-置顶”或者“状态:0-正常; 1-精华; 2-拉黑; ”的更新操作(普通的增删改查罢了),注意帖子的删除属于逻辑删除。
注意:加精的操作可能引发帖子的热度的变化,后续需要再看!!

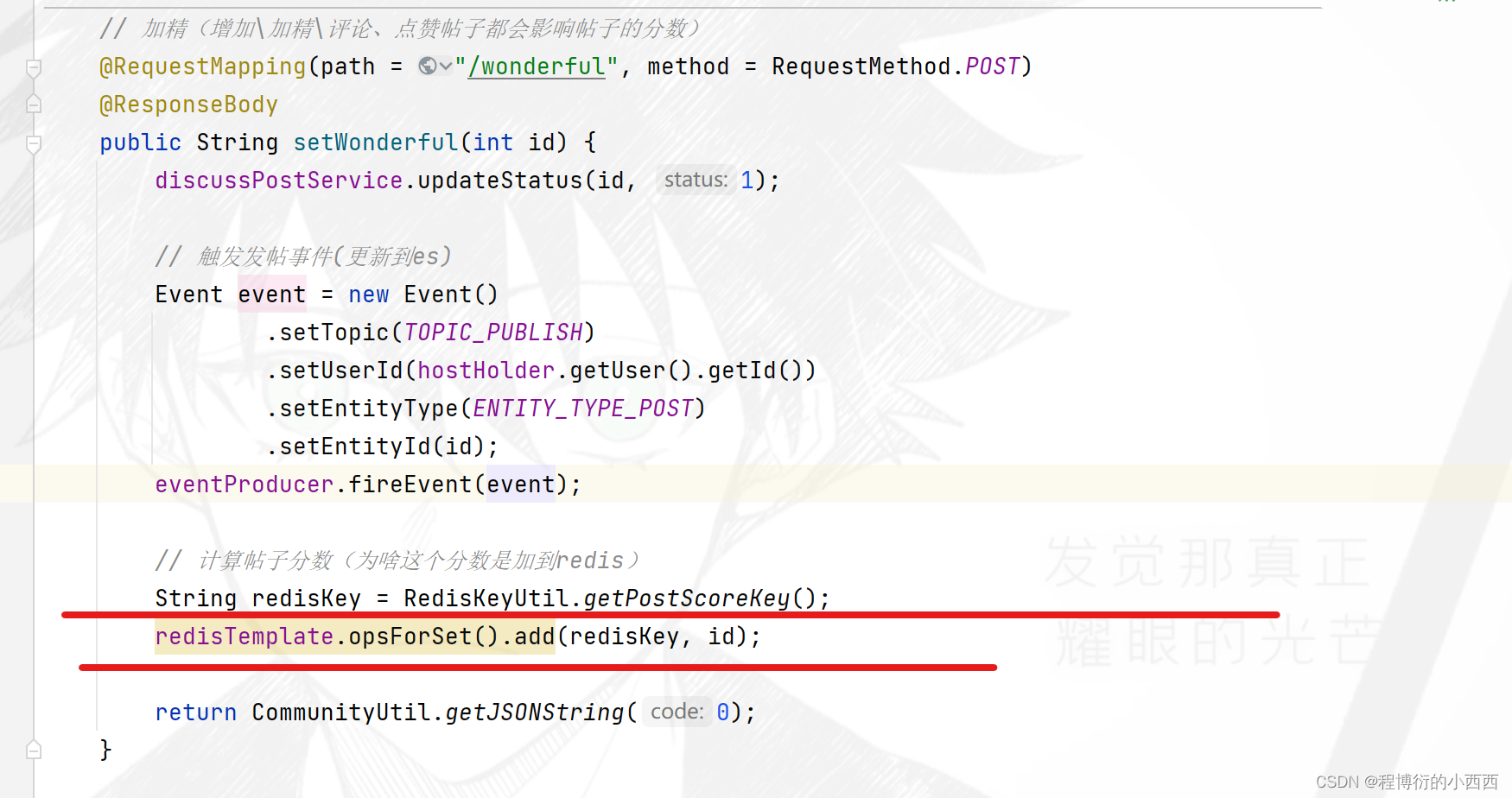

网站数据统计(Redis高级数据类型)—(管路员权限)

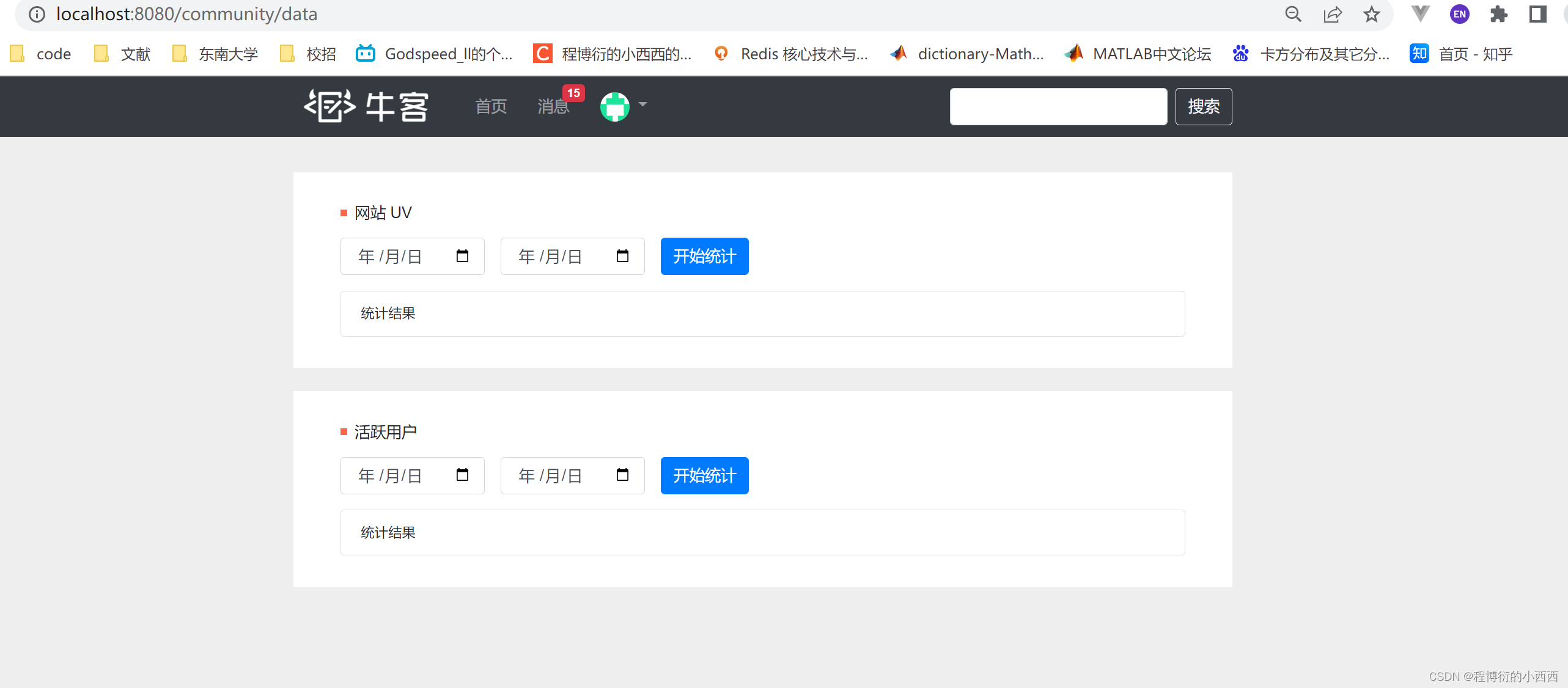
Data的拦截器(用户访问记录–以日为单位)
一旦有ip地址访问网站,就需要记录UV访问量(当日的UVkey加上一个ip);一旦有登录用户进来,就需要统计用户的活跃度(当日的DAUkey加上一个用户的id)
@Component
public class DataInterceptor implements HandlerInterceptor {
@Autowired
private DataService dataService;
@Autowired
private HostHolder hostHolder;
// 在Controller之前执行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 统计UV
String ip = request.getRemoteHost();//获取访问网站的用户ip
dataService.recordUV(ip);
// 统计DAU(只统计登录用户的活跃度)
User user = hostHolder.getUser();
if (user != null) {
dataService.recordDAU(user.getId());
}
return true;
}
}
记录单日ip访问量
方法的重载:单日的区间的key的拼接(注意以日为单位)和区间key的拼接

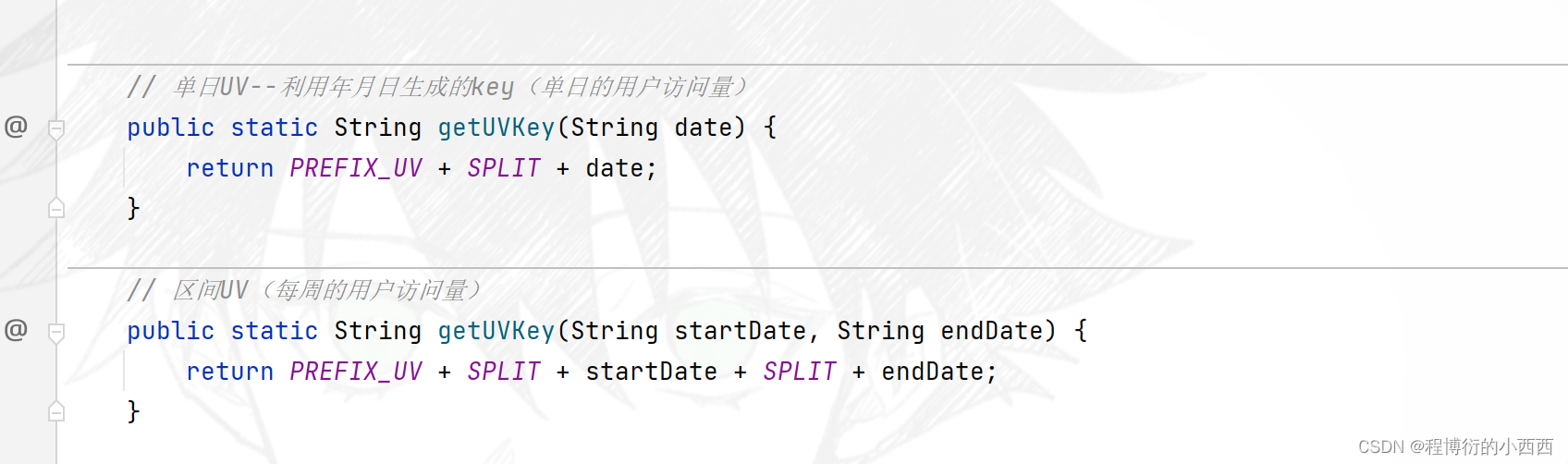
data拦截器获取访问的ip地址,将这个ip地址存入key为当日的UV的键的HyperLogLog()的容器中(类似一个set集合,这里一天是一个HyperLoglog的容器,后续可以合并多天的HyperLoglog的容器为一个新的HyperLoglog的容器)

// 将指定的IP计入UV(用户访问量的键,ForHyperLogLog存放大量的数据)
public void recordUV(String ip) {
String redisKey = RedisKeyUtil.getUVKey(df.format(new Date()));
redisTemplate.opsForHyperLogLog().add(redisKey, ip);
}
记录单日用户活跃度
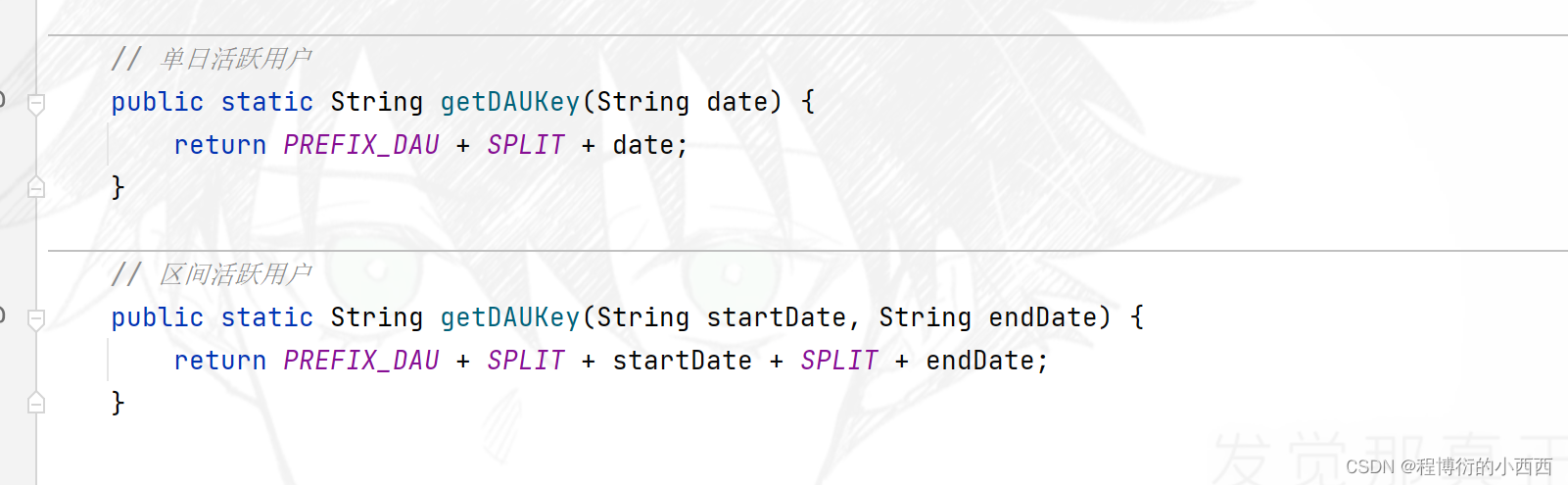
data拦截器获取访问的用户user的实体,将这个Userid存入key为当日的DAU的键的Bitmap()的map容器中,map中的key就是user_id,value对应true(表示登录)-----同理:这里也是一天是一个Bitmap的容器,可以对多天的Bitmap容器进行“或运算”,得到一个新的bitmap的容器结果

根据名字理解:一个bitmap实际上是一个Map(key–某个元素 , value-1bit位-true or false),相当于是某个元素对应的状态—true or false(0 or 1)。相应的我们可以对多个bitmap数组集合进行or运算,判断整体true的情况


统计用户区间访问量(统计ip)
通过HyperLogLoog的并集操作统计时间区间的内的不同ip地址的个数
uv拼接的key
前端传入相应的时间开始与结束时间(提交表单,触发相应的统计业务),统计时间区间内不重复的ip地址,封装结果,充定向回这个data的页面
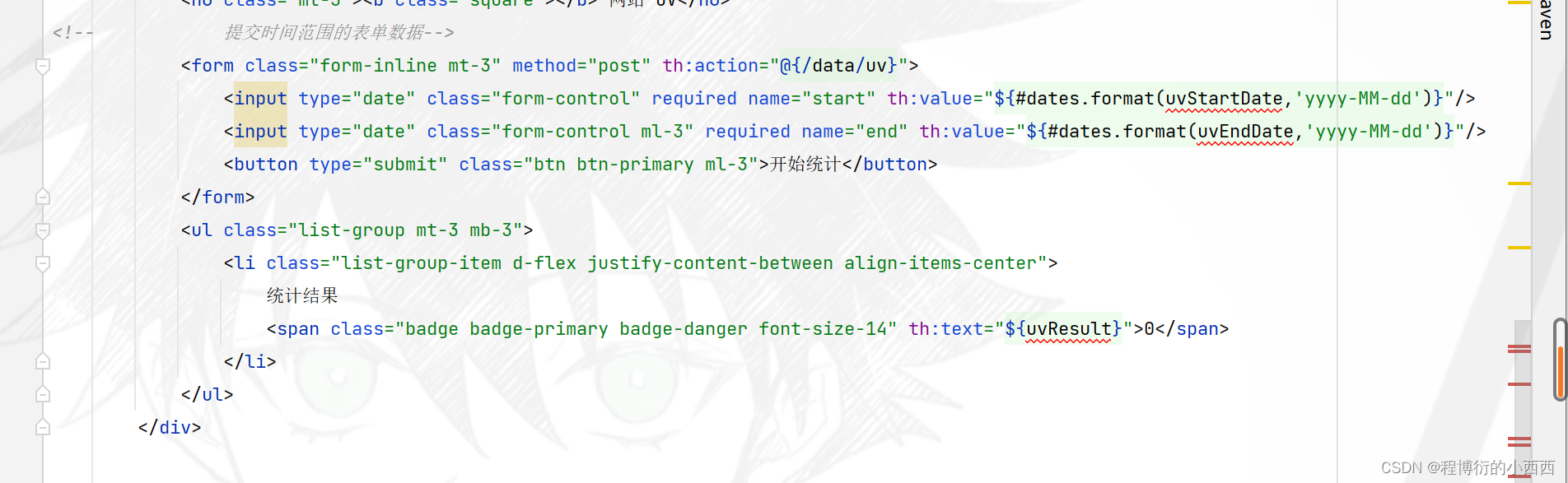
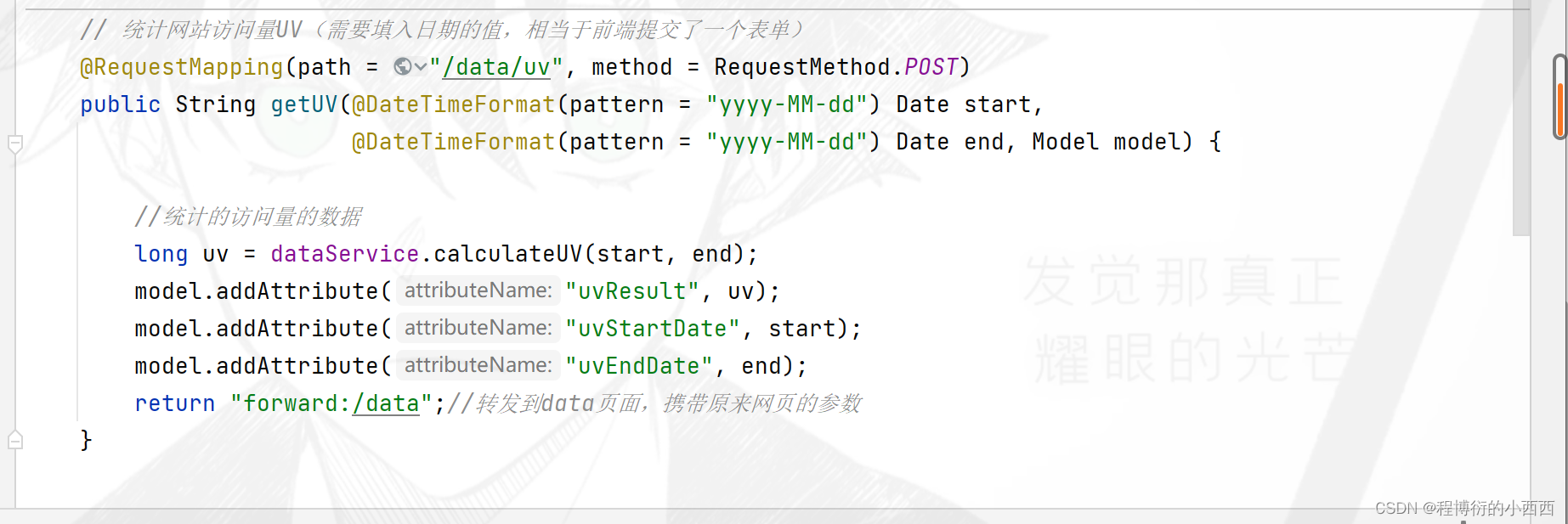
使用hyperloglog的合并统计的功能,相当于合并多个hyperloglog的集合(按照start—end一天一天累计生成对应的单日uv的key)的数据并装入一个新的hyperloglog(key为时间区间)中,最后统计这个新的hyperloglog中不重复ip的个数
// 统计指定日期范围内的UV
public long calculateUV(Date start, Date end) {
if (start == null || end == null) {
throw new IllegalArgumentException("参数不能为空!");
}
// 整理该日期范围内的key(字符串集合)
List<String> keyList = new ArrayList<>();
Calendar calendar = Calendar.getInstance();
calendar.setTime(start);
// 时间小于等于end的时候就循环
while (!calendar.getTime().after(end)) {
String key = RedisKeyUtil.getUVKey(df.format(calendar.getTime()));
keyList.add(key);
calendar.add(Calendar.DATE, 1);//加一天更新
}
// 合并这些数据至“区间访问量的key”
String redisKey = RedisKeyUtil.getUVKey(df.format(start), df.format(end));
redisTemplate.opsForHyperLogLog().union(redisKey, keyList.toArray());
// 返回统计的结果(不精确的数据)
return redisTemplate.opsForHyperLogLog().size(redisKey);
}
统计用户区间活跃度(统计天为单位的用户id)
利用Bitmap的or运算统计时间区间内的不同用户的true的个数。
前端传入相应的时间开始与结束时间(提交表单,触发相应的统计业务),统计时间区间内不重复的user_id,封装结果,充定向回这个data的页面
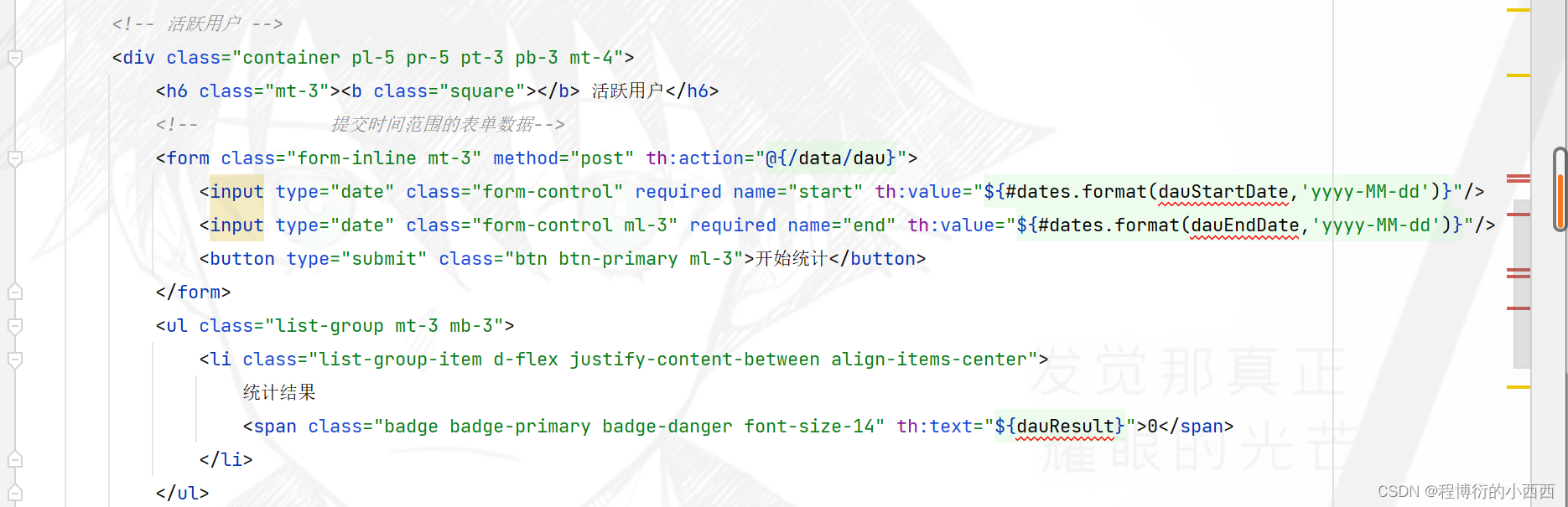
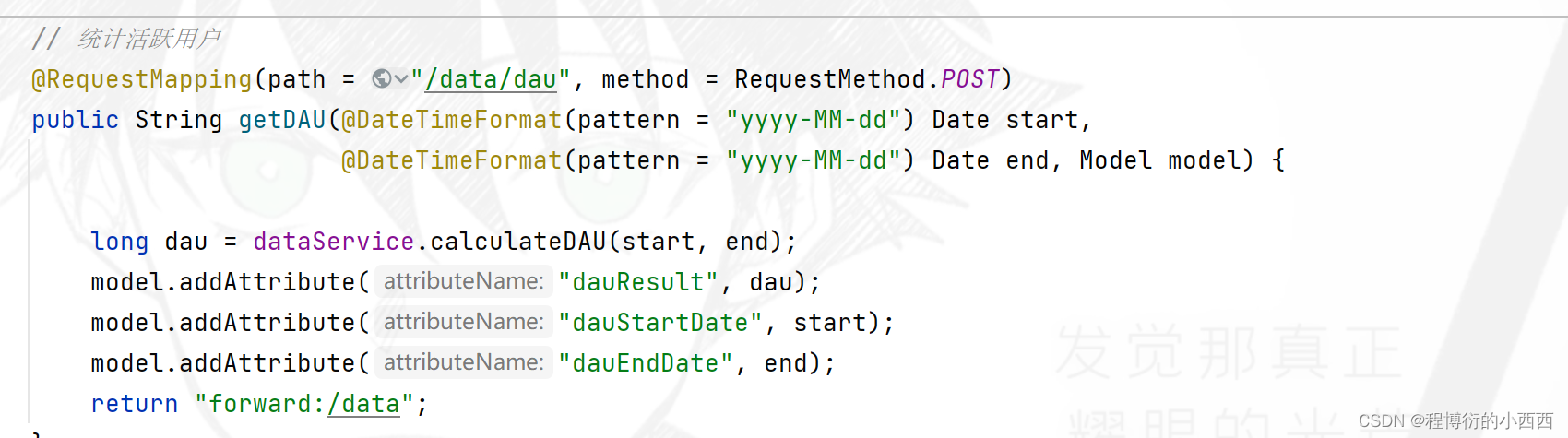
使用bitmap的合并统计的功能,相当于对多个birmap的集合(按照start—end一天一天累计生成对应的单日uv的key)进行or运算的结果 并装入一个新的bitmap中(key为时间区间),最后统计这个新的bitmap中1的个数(实际就是活跃的用户的个数)

// 统计指定日期范围内的DAU
public long calculateDAU(Date start, Date end) {
if (start == null || end == null) {
throw new IllegalArgumentException("参数不能为空!");
}
// 整理该日期范围内的key
//注意bitmap需要的key的类型是byte数组
List<byte[]> keyList = new ArrayList<>();
Calendar calendar = Calendar.getInstance();
calendar.setTime(start);
while (!calendar.getTime().after(end)) {
String key = RedisKeyUtil.getDAUKey(df.format(calendar.getTime()));
keyList.add(key.getBytes());
calendar.add(Calendar.DATE, 1);
}
// 进行OR运算(redis底层连接进行运算)
return (long) redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
//区间的活跃用户(对相同的userid进行运算)
String redisKey = RedisKeyUtil.getDAUKey(df.format(start), df.format(end));
connection.bitOp(RedisStringCommands.BitOperation.OR,
redisKey.getBytes(), keyList.toArray(new byte[0][0]));
return connection.bitCount(redisKey.getBytes());
}
});
}
异步定时任务:帖子热度排行

quartz的相关的配置
配置异步执行的线程池的线程个数:
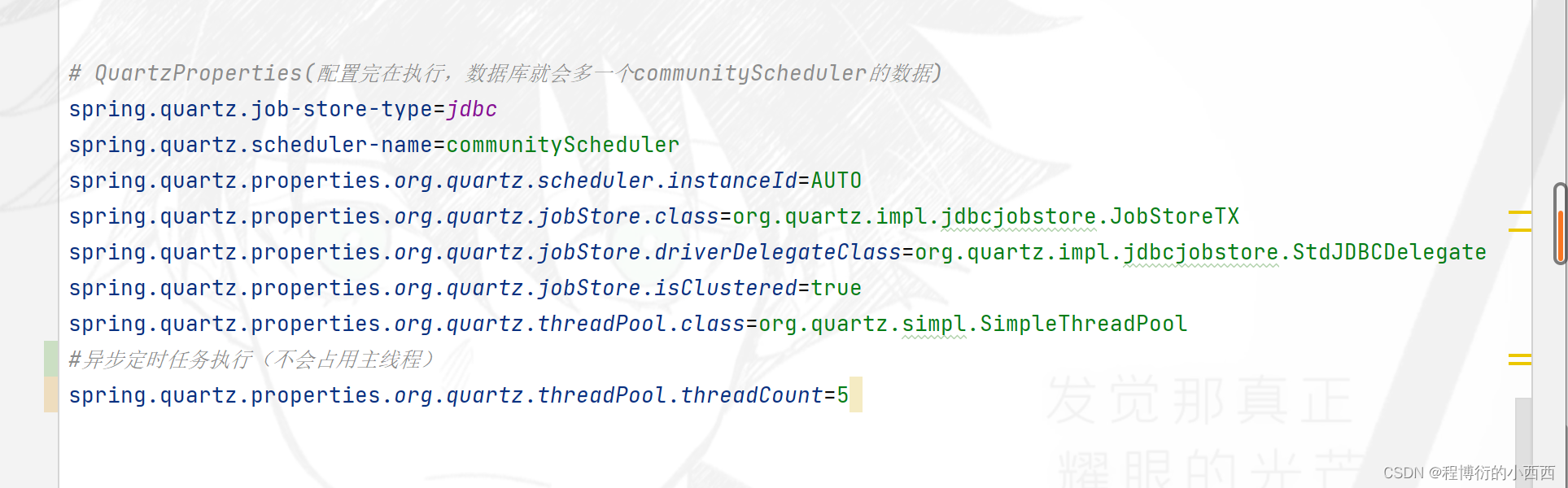
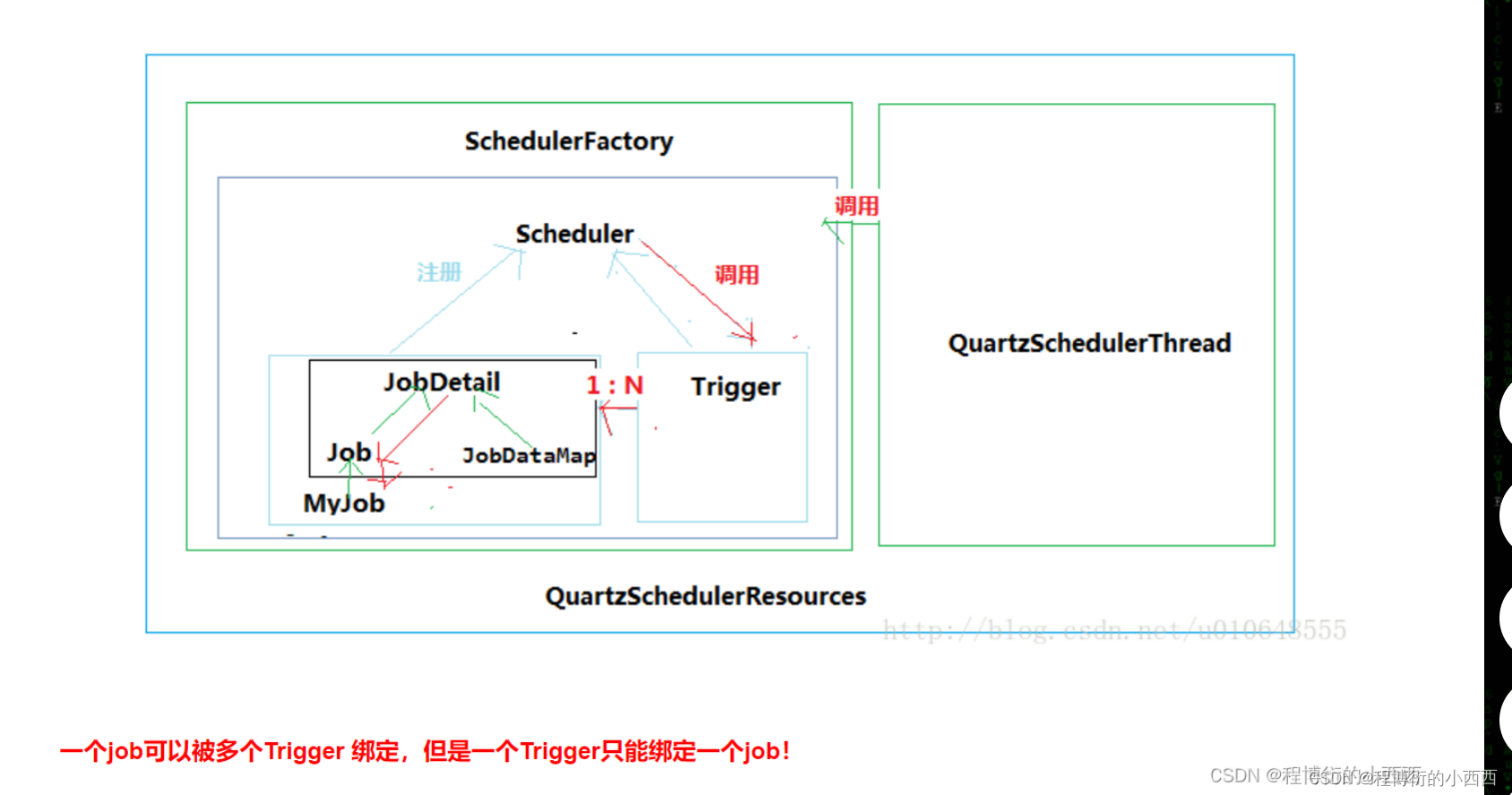
配置Jobdetail定义任务组合持久化信息+绑定相关的job(job被jobdetail进一步包装了),配置Trigger绑定Jobdetail和规定任务调度的时间间隔,注意我们配置了异步线程执行的调度器进行任务的调度(按照trigger规定的时间间隔进行调度)
// 配置 -> 数据库 -> 调用
@Configuration
public class QuartzConfig {
// FactoryBean可简化Bean的实例化过程:
// 1.通过FactoryBean封装Bean的实例化过程.
// 2.将FactoryBean装配到Spring容器里.
// 3.将FactoryBean注入给其他的Bean.
// 4.该Bean得到的是FactoryBean所管理的对象实例.
// 刷新帖子分数任务(配置jobdetail)
@Bean
public JobDetailFactoryBean postScoreRefreshJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(PostScoreRefreshJob.class);
factoryBean.setName("postScoreRefreshJob");
factoryBean.setGroup("communityJobGroup");
factoryBean.setDurability(true);//任务是持久性的
factoryBean.setRequestsRecovery(true);
return factoryBean;
}
// 配置trigger
@Bean
public SimpleTriggerFactoryBean postScoreRefreshTrigger(JobDetail postScoreRefreshJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(postScoreRefreshJobDetail);
factoryBean.setName("postScoreRefreshTrigger");
factoryBean.setGroup("communityTriggerGroup");
factoryBean.setRepeatInterval(1000 * 60 * 5);//配置任务执行的时间间隔:5分钟一次定时任务
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}
}
定时任务:帖子热度更新(5分钟更一次)
帖子分数的计算规则
帖子是否精华、帖子的评论的数量、点赞数量、帖子的创建时间
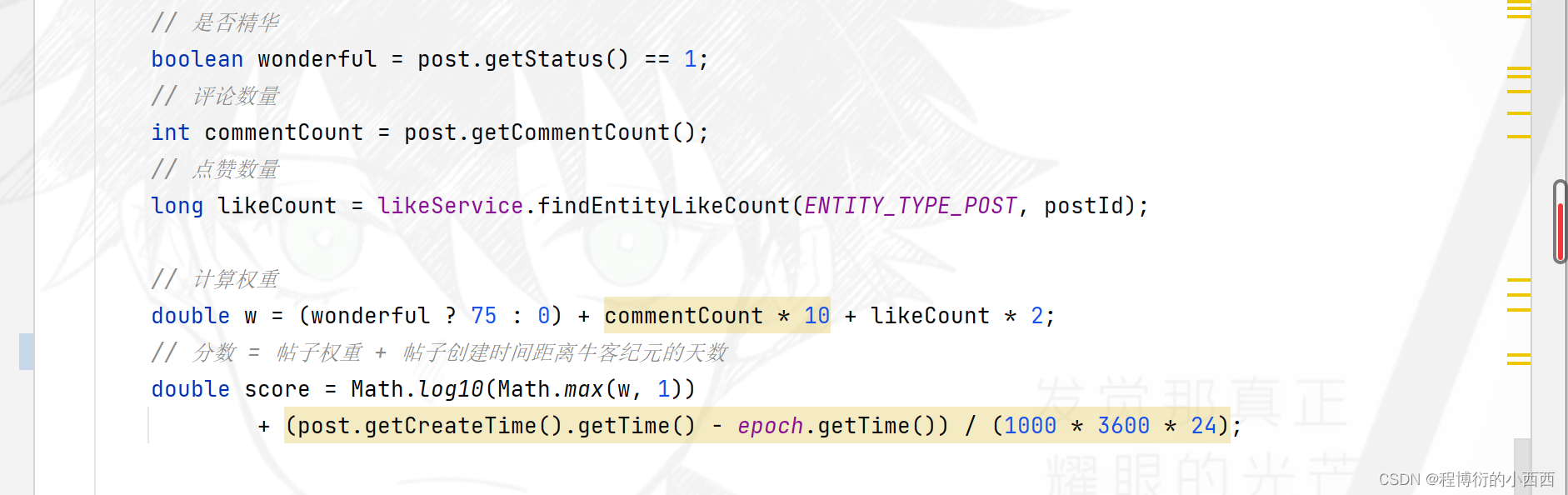
redis中score的数据结构(无序set集合–存放分数变化的帖子的id)
帖子的分数:加精+点赞数+评论数+发帖时间决定
帖子的原本分数是一个高频变化的量----一旦”发帖、评论、点赞、加精“都会影响到帖子分数的变化(但是帖子的热度排行可以进行每5分钟的非实时更新)–所以我们将变化的帖子的id先放到我们的redis缓存中(将分数会有变化的帖子id存放至一个无序的set集合中,暂时不会立即更新帖子的分数至数据库,每隔5分钟计算最新的分数之后,才更新至数据库)-----(频繁的在数据库更新实时的帖子分数不现实),所以我们设置了定时的调度任务

触发帖子更新的业务(精华、评论、点赞、发帖)
一旦(精华、评论—回帖、点赞—帖子、发帖)业务被触发,就需要将分数变化的帖子的id存放到score的无序set集合里
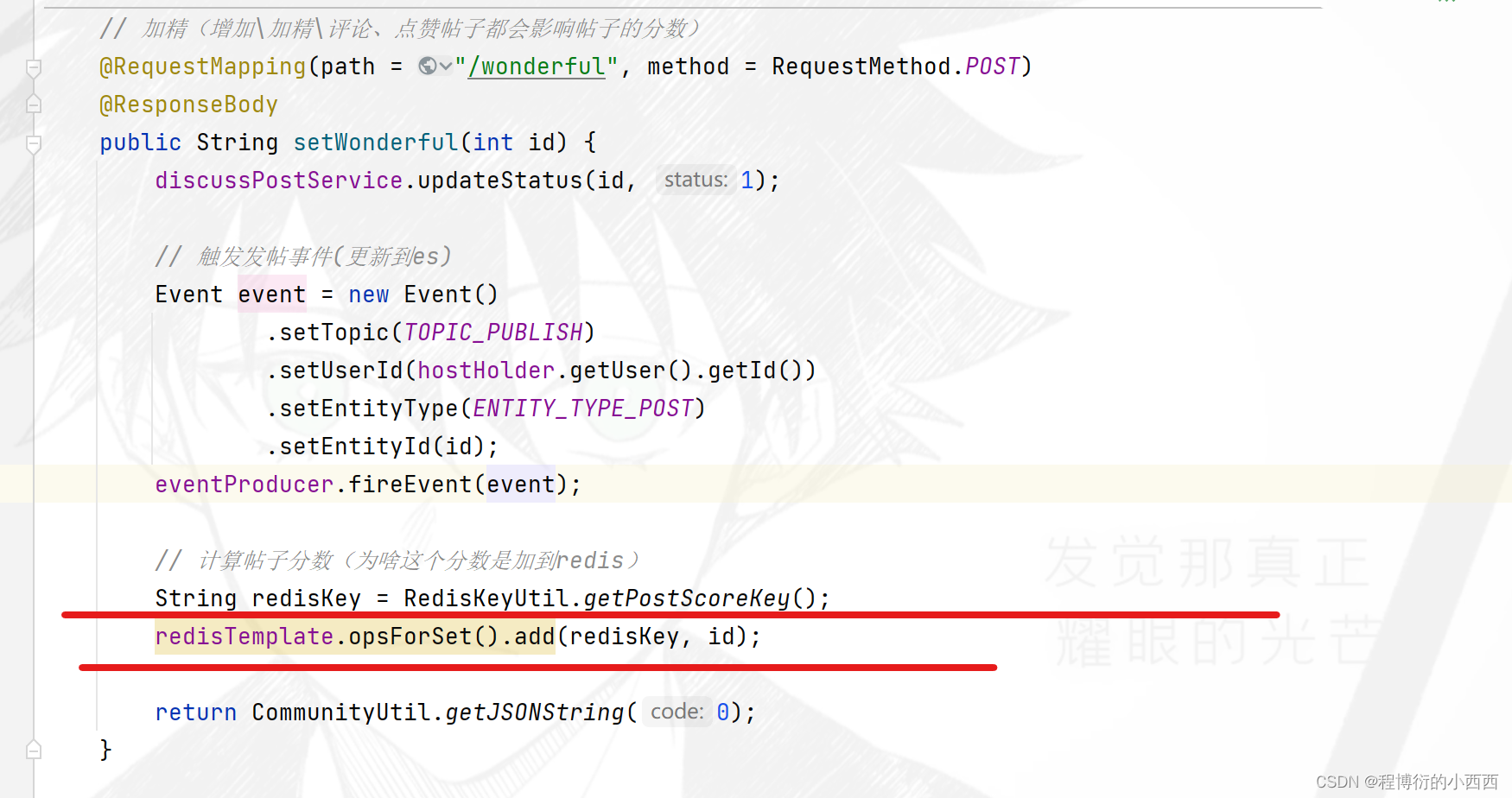
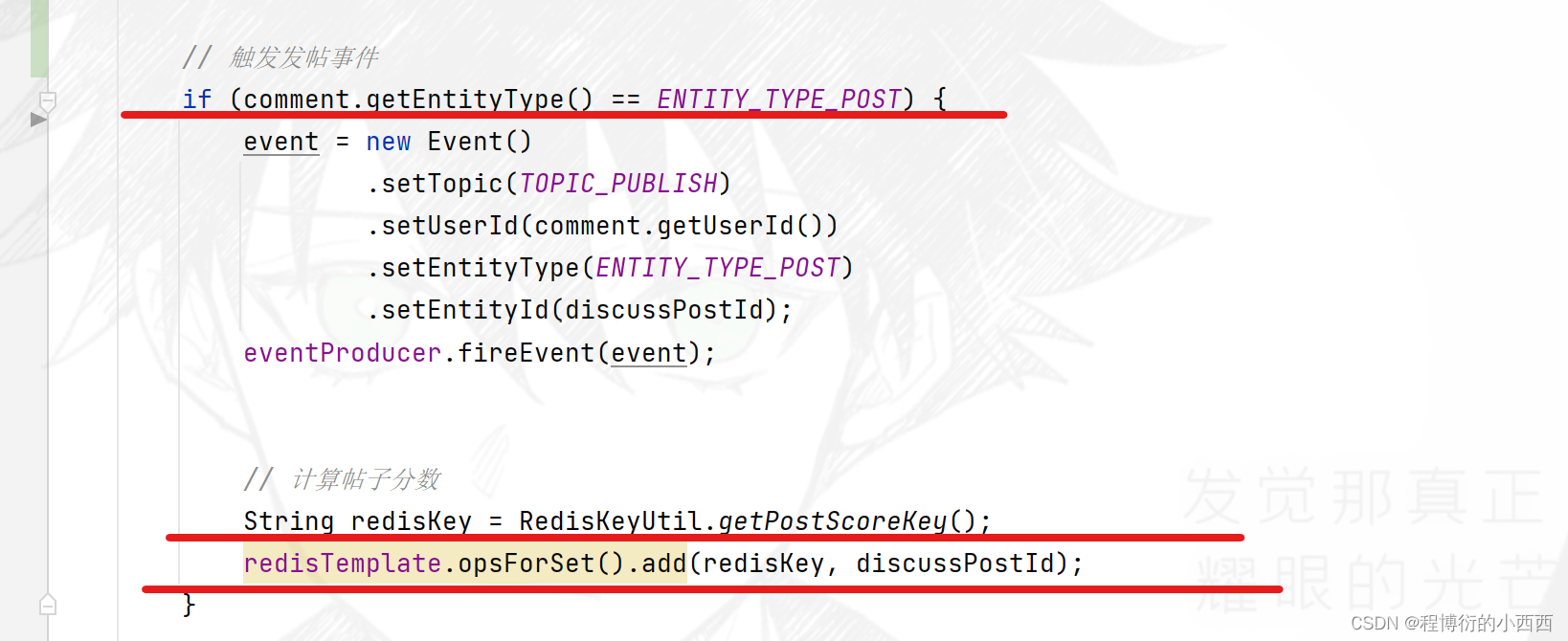
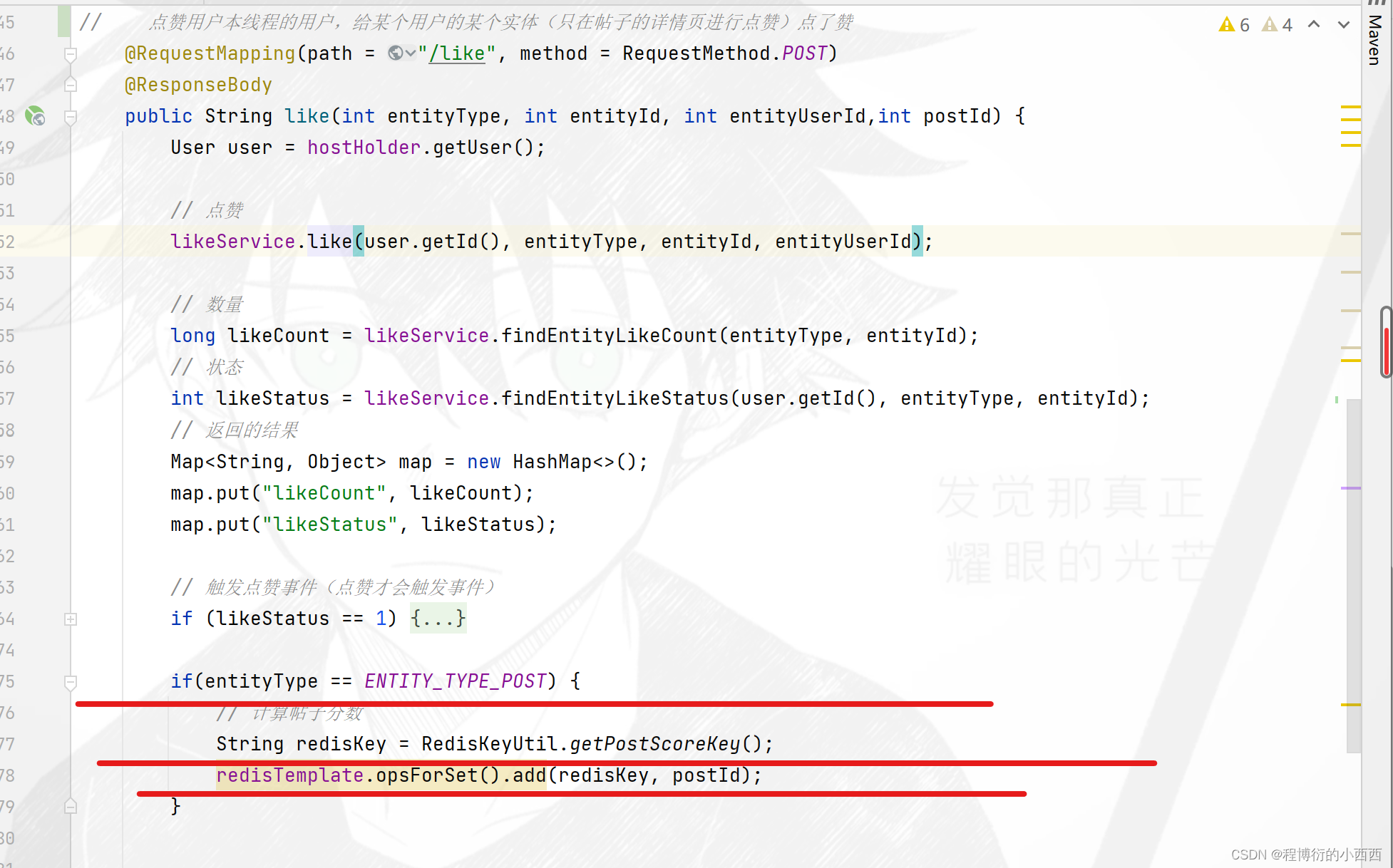
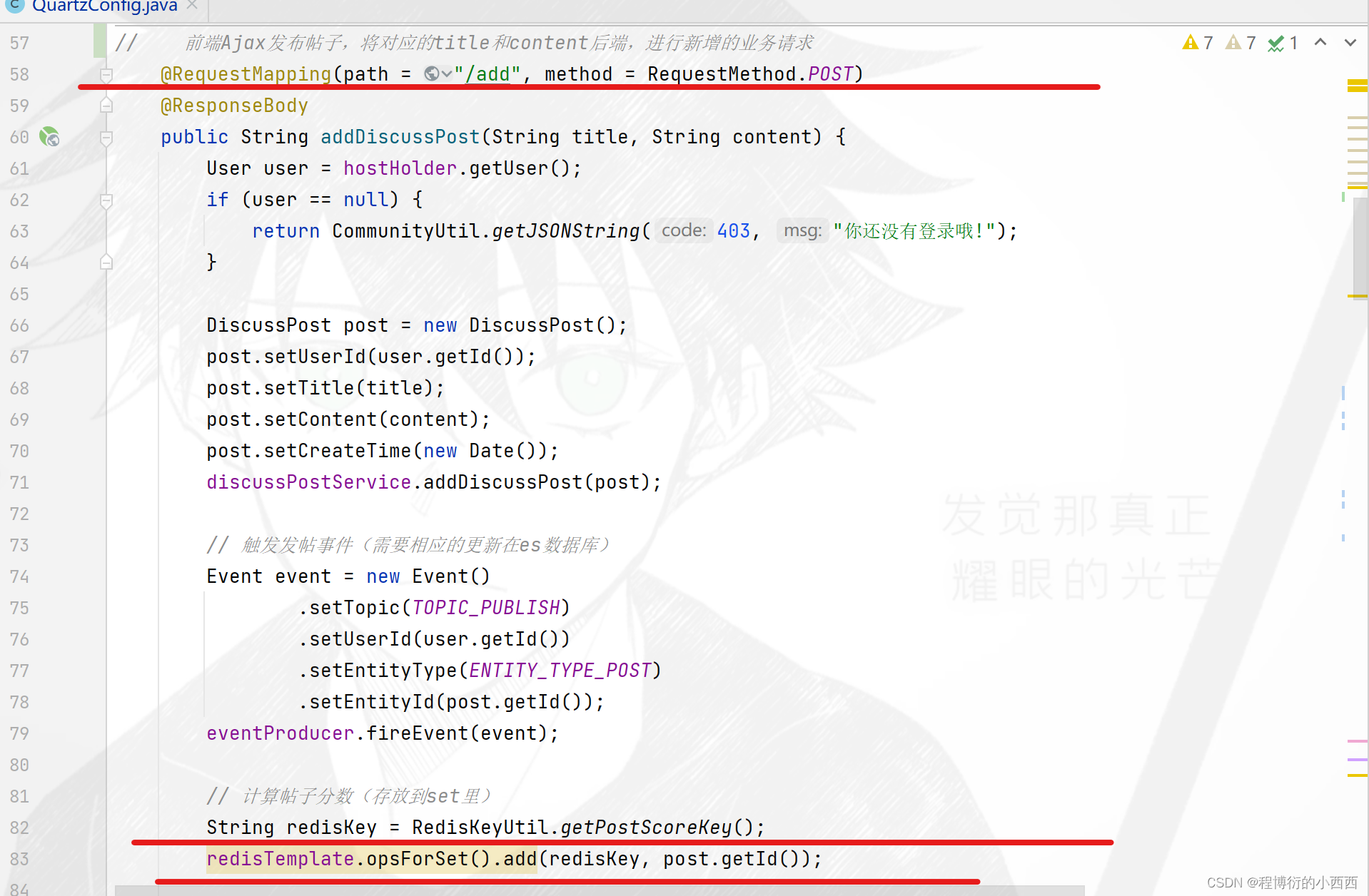
*Job刷新帖子分数的具体逻辑
每隔5分钟(trigger和scheduler)定时任务的执行:
step1: 调度器去检查我们的redis的缓存中的这个set集合里有没有需要更新的帖子分数的帖子的id
step2: refresh的具体工作内容:从无序的set集合里每次”弹出“一个分数变化帖子的id,进行重新计算帖子的分数(查询最新的精华的状态,最新的点赞数,评论数,发帖的时间),并实施更新score至mysql 数据库 和ES(注意保证了搜索引擎的作用)。注意使用set集合的妙处:每次处理完一个帖子的分数更新,这个帖子处理完了,相应的id也就不会占用redis的缓存
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
//获取score的set集合(里面存放了需要重新更新帖子分数的帖子的id)
String redisKey = RedisKeyUtil.getPostScoreKey();
BoundSetOperations operations = redisTemplate.boundSetOps(redisKey);//方便redis数据的操作
if (operations.size() == 0) {
logger.info("[任务取消] 没有需要刷新的帖子!");
return;
}
logger.info("[任务开始]正在刷新帖子分数: " + operations.size());
while (operations.size() > 0) {
//每次弹出一个值,进行计算更新帖子的id,删除了需要更新的帖子id,节省了缓存和重复计算
this.refresh((Integer) operations.pop());
}
logger.info("[任务结束] 帖子分数刷新完毕!");
}
//需要刷新的帖子的分数具体的更新计算方法
private void refresh(int postId) {
DiscussPost post = discussPostService.findDiscussPostById(postId);
if (post == null) {
logger.error("该帖子不存在: id = " + postId);
return;
}
// 是否精华
boolean wonderful = post.getStatus() == 1;
// 评论数量
int commentCount = post.getCommentCount();
// 点赞数量
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, postId);
// 计算权重
double w = (wonderful ? 75 : 0) + commentCount * 10 + likeCount * 2;
// 分数 = 帖子权重 + 帖子创建时间距离牛客纪元的天数
double score = Math.log10(Math.max(w, 1))
+ (post.getCreateTime().getTime() - epoch.getTime()) / (1000 * 3600 * 24);
// 更新帖子分数到mysql数据库
discussPostService.updateScore(postId, score);
// 同步搜索数据(ES数据更新,重新更新对应的帖子)
post.setScore(score);
elasticsearchService.saveDiscussPost(post);
}
帖子按照热度排行(首页)
首页的帖子:默认是按照时间进行排序,如果点击热度的按钮就会实现按照热度进行排序操作,相当于触发了后端的按照热度排序的业务
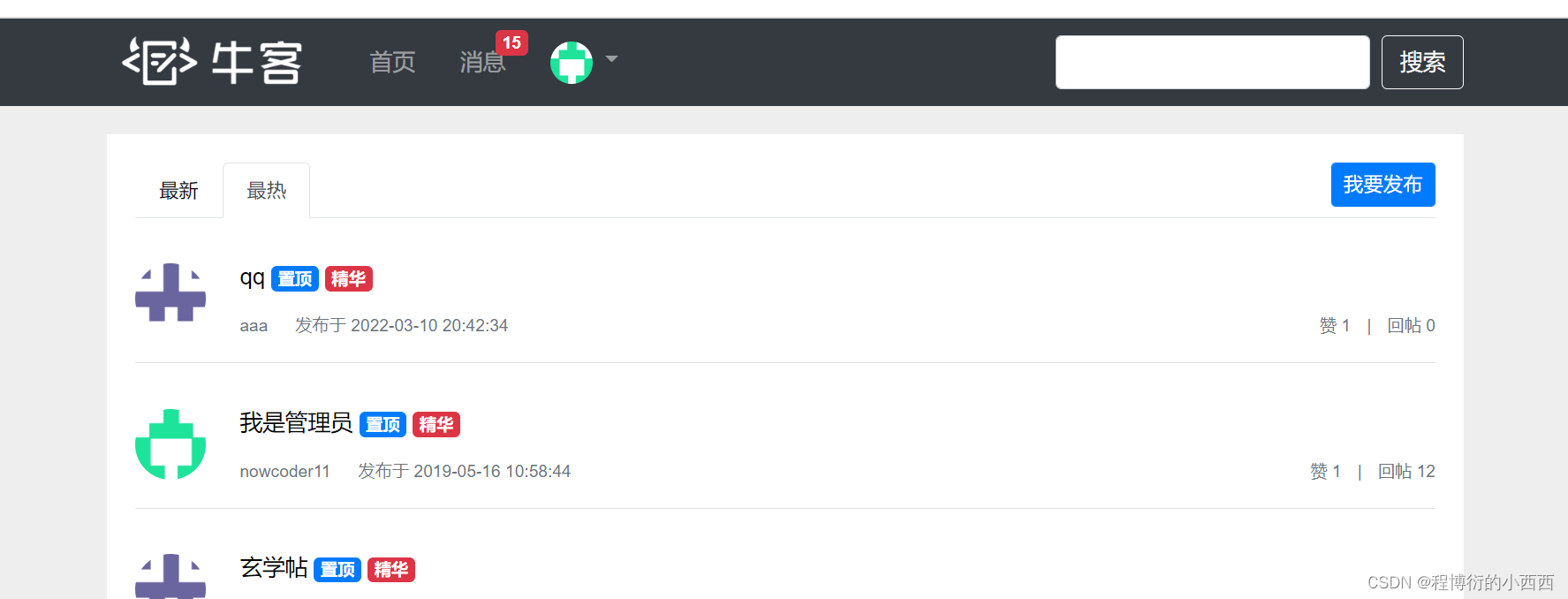
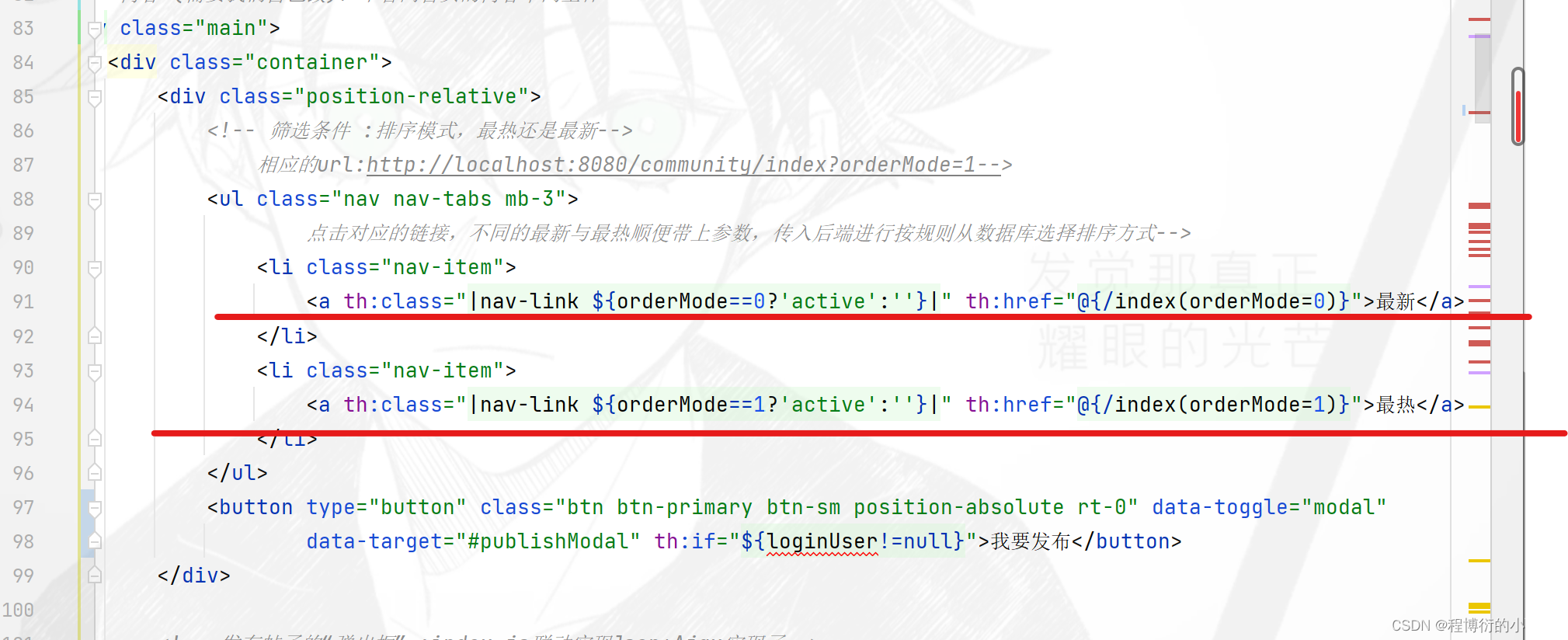
前端按照按钮的状态(在http请求中加上了get的请求参数),实现传递一个ordermode的参数至后端,作为路径变量实现按照热度/最新进行排序
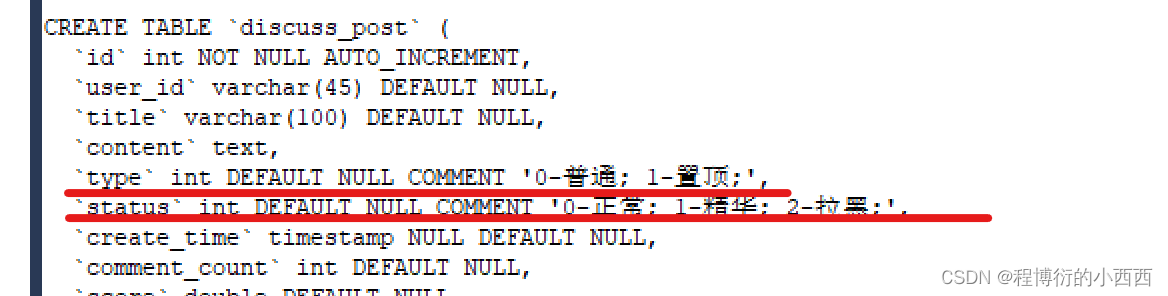
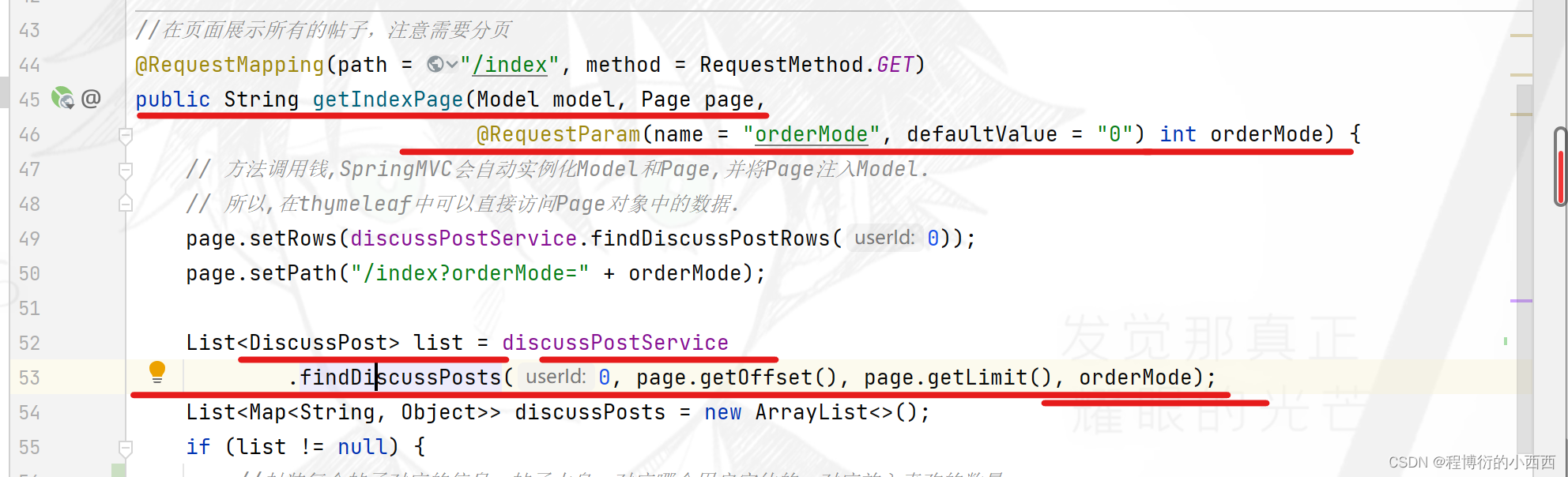
本质按照ordermode实现两种排序的查询方式的sql语句(注意:置顶的还是优先置顶----所以排序的时候还是先按照type字段进行排序(0-普通; 1-置顶;),但是按热度的需要按照score进行排序(score中的加精占了大头),分数相同的再按照时间进行展示)
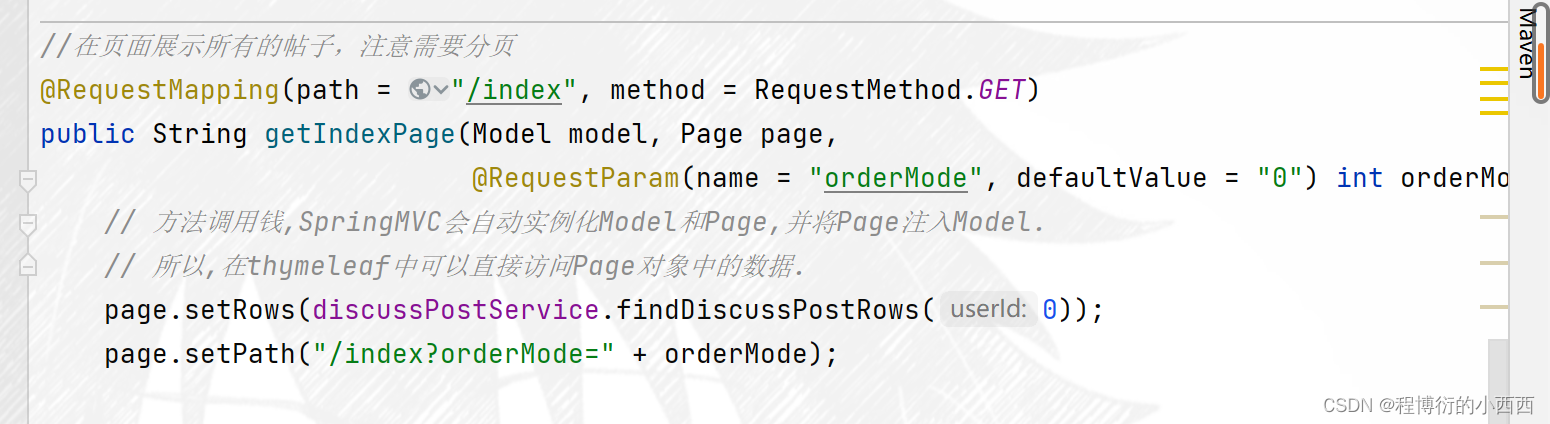
//在页面展示所有的帖子,注意需要分页
@RequestMapping(path = "/index", method = RequestMethod.GET)
public String getIndexPage(Model model, Page page,
@RequestParam(name = "orderMode", defaultValue = "0") int orderMode) {
// 方法调用钱,SpringMVC会自动实例化Model和Page,并将Page注入Model.
// 所以,在thymeleaf中可以直接访问Page对象中的数据.
page.setRows(discussPostService.findDiscussPostRows(0));
page.setPath("/index?orderMode=" + orderMode);
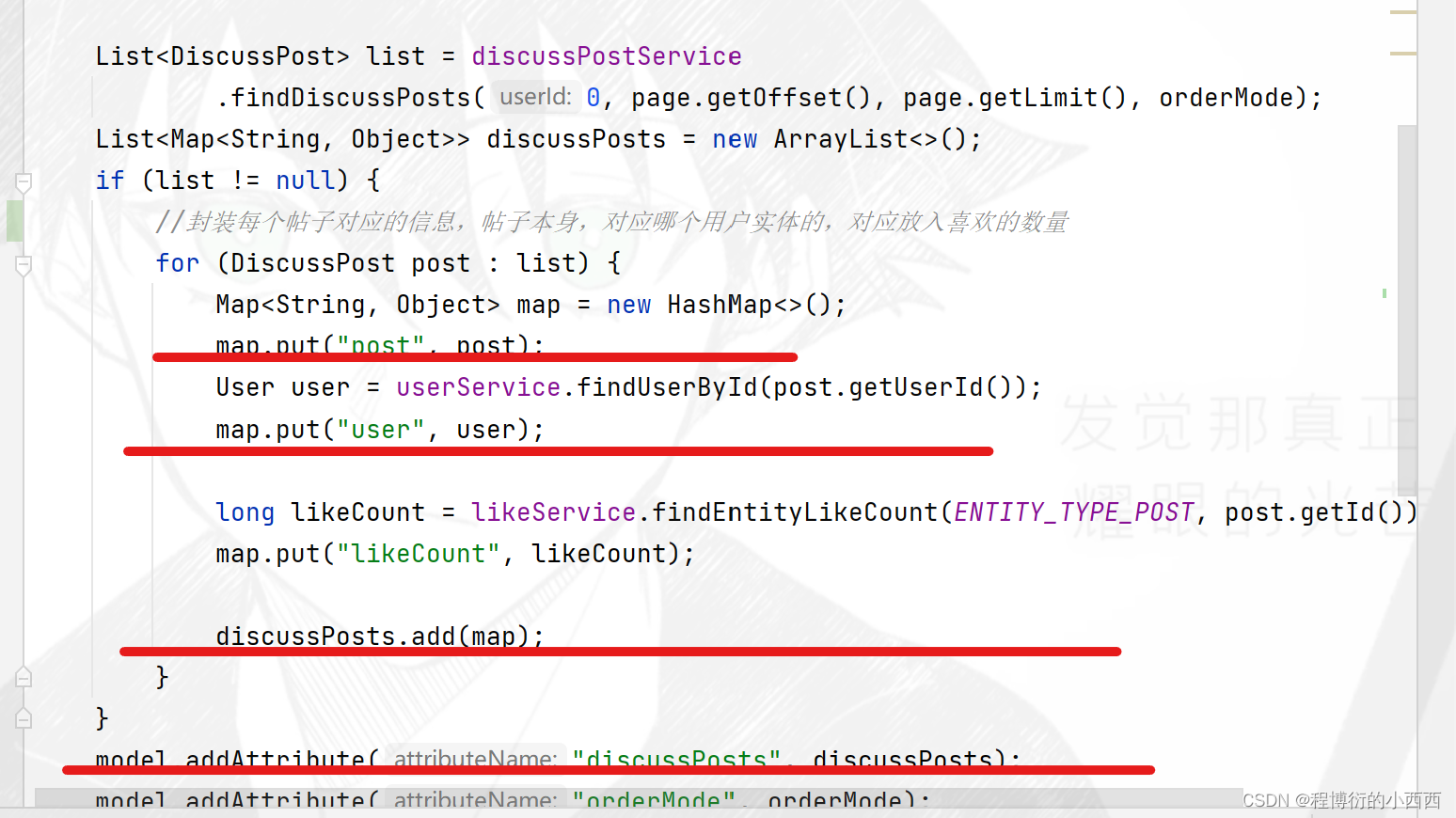
List<DiscussPost> list = discussPostService
.findDiscussPosts(0, page.getOffset(), page.getLimit(), orderMode);
List<Map<String, Object>> discussPosts = new ArrayList<>();
if (list != null) {
//封装每个帖子对应的信息,帖子本身,对应哪个用户实体的,对应放入喜欢的数量
for (DiscussPost post : list) {
Map<String, Object> map = new HashMap<>();
map.put("post", post);
User user = userService.findUserById(post.getUserId());
map.put("user", user);
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, post.getId());
map.put("likeCount", likeCount);
discussPosts.add(map);
}
}
model.addAttribute("discussPosts", discussPosts);
model.addAttribute("orderMode", orderMode);
return "/index";
}
AOP面向切面编程的应用
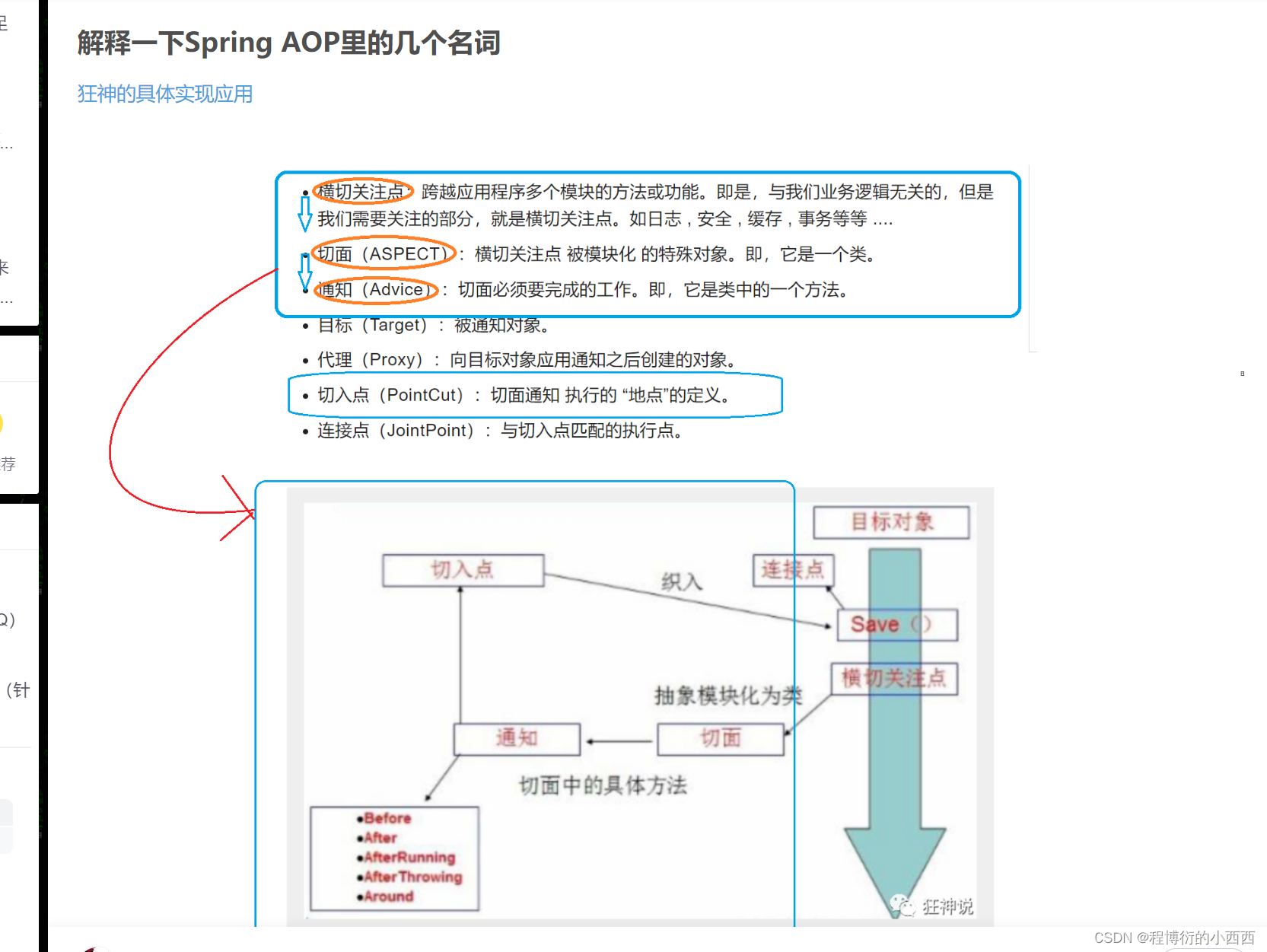
应用1:controller层业务的全局异常处理(业务降级)
本质,这是一个业务出现异常的一个兜底的方法,实现业务的降级处理

注意ControllerAdvice注解不是真正的基于AOP实现的,内部的实现的原理比较复杂


对于@ControllerAdvice(运行时的注解,一旦controller业务出现故障就会拦截),我们比较熟知的用法是结合@ExceptionHandler用于全局异常的处理。@ExceptionHandler的作用主要在于当符合条件的Controller抛出这些异常之后将会对这些异常进行捕获,然后按照其标注的方法的逻辑进行处理。
首先在后台打印日志,记录相应的异常的错误的信息;之后,返回相应的错误页面信息给用户:
case1:对于返回html视图渲染的controller业务,最终返回一个thymeleaf的自己设计的精美的错误页面error.html
case2:对于ajax的异步请求,接收的是data信息,我们直接返回错误的data信息给它就可以了(“服务器异常的信息”)
//只去扫描带有controller注解的方法,去进行统一的处理异常
@ControllerAdvice(annotations = Controller.class)
public class ExceptionAdvice {
private static final Logger logger = LoggerFactory.getLogger(ExceptionAdvice.class);
@ExceptionHandler({Exception.class})
public void handleException(Exception e, HttpServletRequest request, HttpServletResponse response) throws IOException {
logger.error("服务器发生异常: " + e.getMessage());
for (StackTraceElement element : e.getStackTrace()) {
logger.error(element.toString());
}
String xRequestedWith = request.getHeader("x-requested-with");
//判断区分当前的请求:是json请求还是普通的请求
if ("XMLHttpRequest".equals(xRequestedWith)) {
response.setContentType("application/plain;charset=utf-8");
PrintWriter writer = response.getWriter();
writer.write(CommunityUtil.getJSONString(1, "服务器异常!"));
} else {
response.sendRedirect(request.getContextPath() + "/error");
}
}
}
应用2:打印调用service业务的后台日志
构造一个 ServiceLogAspect,在所有的项目的调用service方法时打印日志。
此时只需要将切点pointcut设置为service层的所有方法的所有参数,在切点之前—打印相应service的日志信息(利用获取服务层的类型名和方法名+ request.getRemoteHost(Httprequest 获取调用的主机的ip地址+调用的时间)
@Component
@Aspect
public class ServiceLogAspect {
private static final Logger logger = LoggerFactory.getLogger(ServiceLogAspect.class);
// 切点所在的位置:所有的业务层的方法的所有参数
@Pointcut("execution(* com.newcoder.community.service.*.*(..))")
public void pointcut() {
}
// 在方法执行前织入,进行日志的打印
@Before("pointcut()")
public void before(JoinPoint joinPoint) {
// 用户[1.2.3.4],在[xxx],访问了[com.nowcoder.community.service.xxx()].
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (attributes == null) {
return;
}
HttpServletRequest request = attributes.getRequest();
//获取访问的IP地址
String ip = request.getRemoteHost();
String now = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());
//访问服务层的类型名和方法名
String target = joinPoint.getSignature().getDeclaringTypeName() + "." + joinPoint.getSignature().getName();
logger.info(String.format("用户[%s],在[%s],访问了[%s].", ip, now, target));
}
}
ES 搜索业务(弃)
对帖子的搜索,实现按照帖子的标题和帖子的内容进行索引。显然一旦有增删改查帖子,都需要同步ES和mysql的更新,所以使用kafka,实现帖子的增删改查,触发更新ES的事件的产生,此时消费者消费时间进行更新ES帖子的数据。
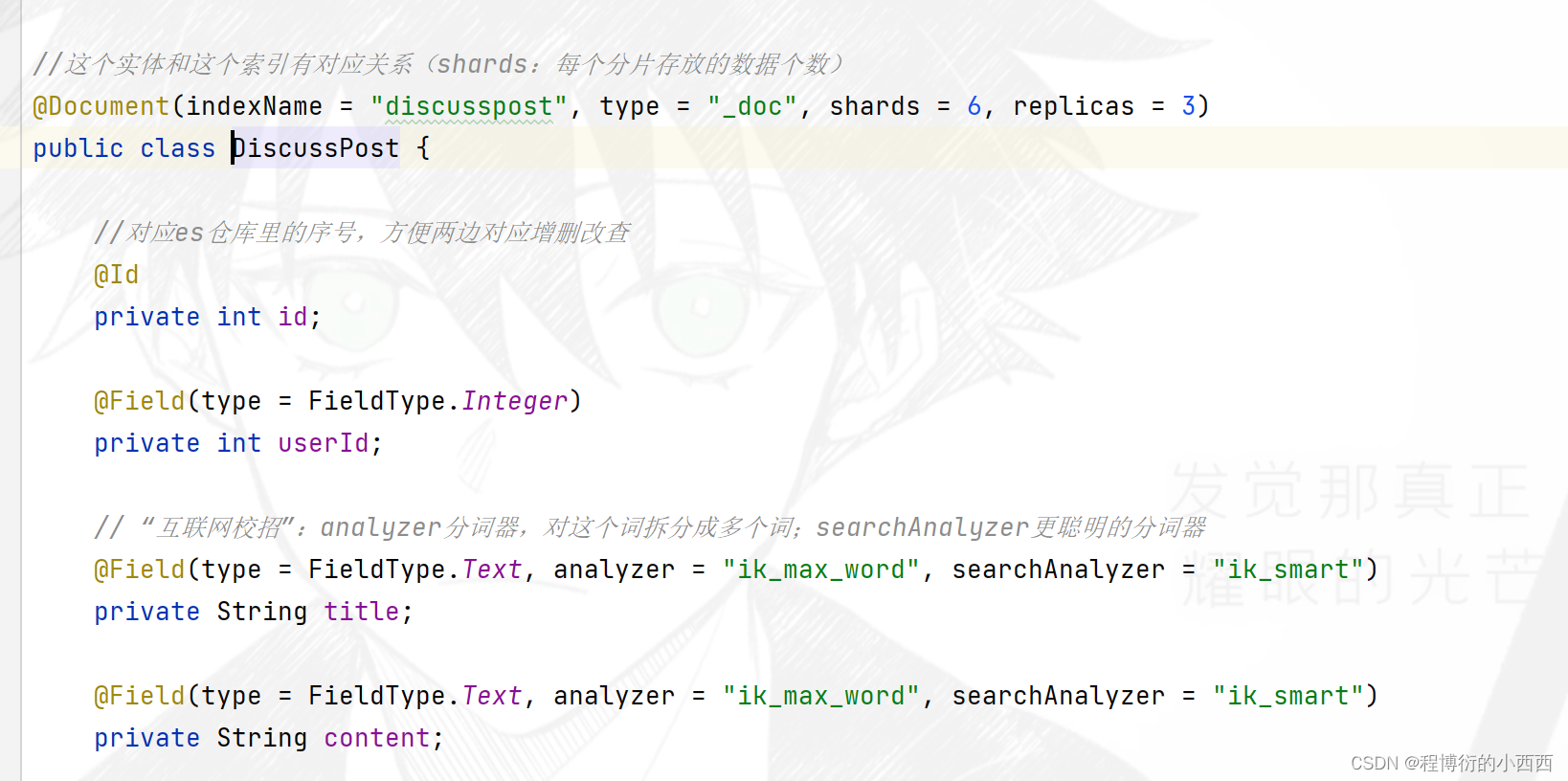
发帖、删帖、更新帖子–ES与mysql的异步更新(Kafka中间件异步更新)
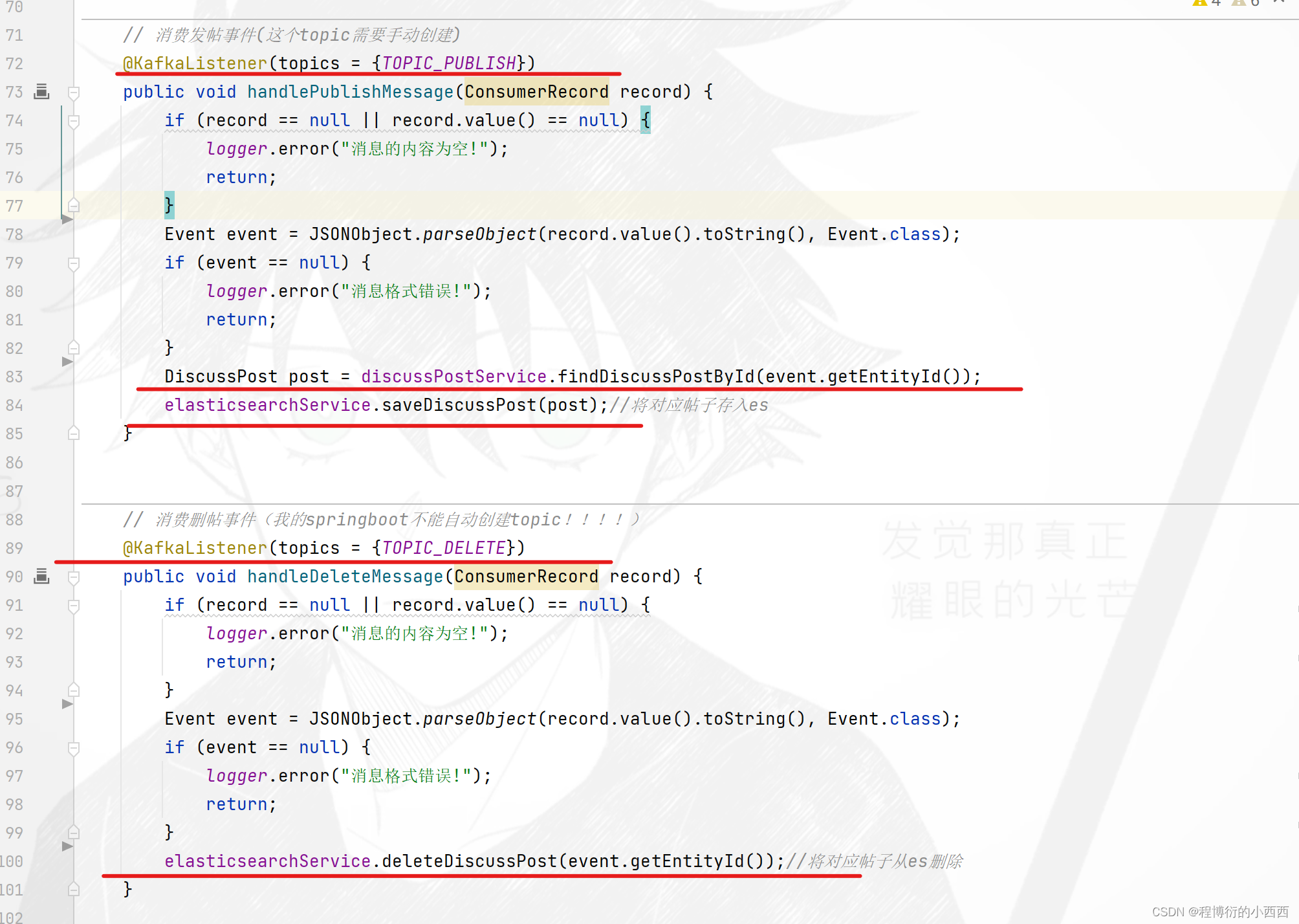















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









