






微信改版,求求大家星标下公众号,
不然后面推送大家可能会看不到
1、前言
2、开始动手动脑
2.1 拆解+明确需求
2.2 安装第三方包
2.3 读取excel数据
2.4 特殊数据数据处理
2.5 其他需求
2.6 完整调用代码
3、后言后语
1、前言
紧接昨天的文章Windows下载安装配置SQL Server、SSMS,使用Python连接读写数据,我们已经安装和配置好了sqlserver,也成功测试了如何利用Python连接、读写数据到数据库。
今天我们正式开始怼需求:有很多Excel,需要批量处理,然后存入不同的数据表中。
2、开始动手动脑
2.1 拆解+明确需求
1) excel数据有哪些需要修改?
有一列数据
DocketDate是excel短时间数值,需要转变成正常的年月日格式;
eg. 44567 --> 2022/1/6部分数据需要按
SOID进行去重复处理,根据DocketDate保留最近的数据;有一列数据需要进行日期格式转换。
eg. 06/Jan/2022 12:27 --> 2022-1-6
主要涉及:日期格式处理、数据去重处理
2) 每一个Excel都对应一个不同数据表吗?表名和Excel附件名称是否一致?
有些Excel对应的是同一个表,有些是单独的
表名和Excel附件名称不一致,不过是有对应关系的
eg. 附件test1 和 test2 对应表 testa,附件test3 对应 testb
主要涉及:数据合并处理
2.2 安装第三方包
pip3 install sqlalchemy pymssql pandas xlrd xlwtsqlalchemy:可以将关系数据库的表结构映射到对象上,然后通过处理对象来处理数据库内容;
pymssql:python连接sqlserver数据库的驱动程序,也可以直接使用其连接数据库后进行读写操作;
pandas:处理各种数据,内置很多数据处理方法,非常方便;
xlrd xlwt:读写excel文件,pandas读写excel会调用他们。
导入包:
import pandas as pd
from datetime import date, timedelta, datetime
import time
import os
from sqlalchemy import create_engine
import pymssql2.3 读取excel数据
读取数据比较简单,直接调用pandas的read_excel函数即可,如果文件有什么特殊格式,比如编码,也可以自定义设置。
# 读取excel数据
def get_excel_data(filepath):
data = pd.read_excel(filepath)
return data2.4 特殊数据数据处理
“1)日期天数转短日期
”
这个有一定难度,excel里直接转很简单,直接选中需要转的数据,然后在开始-数据格式栏选择短日期即可。
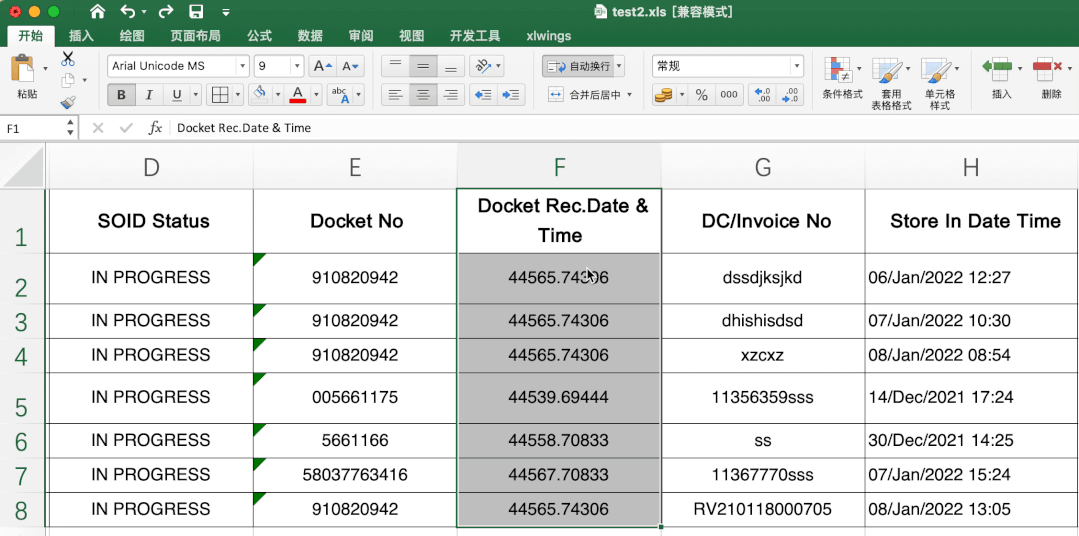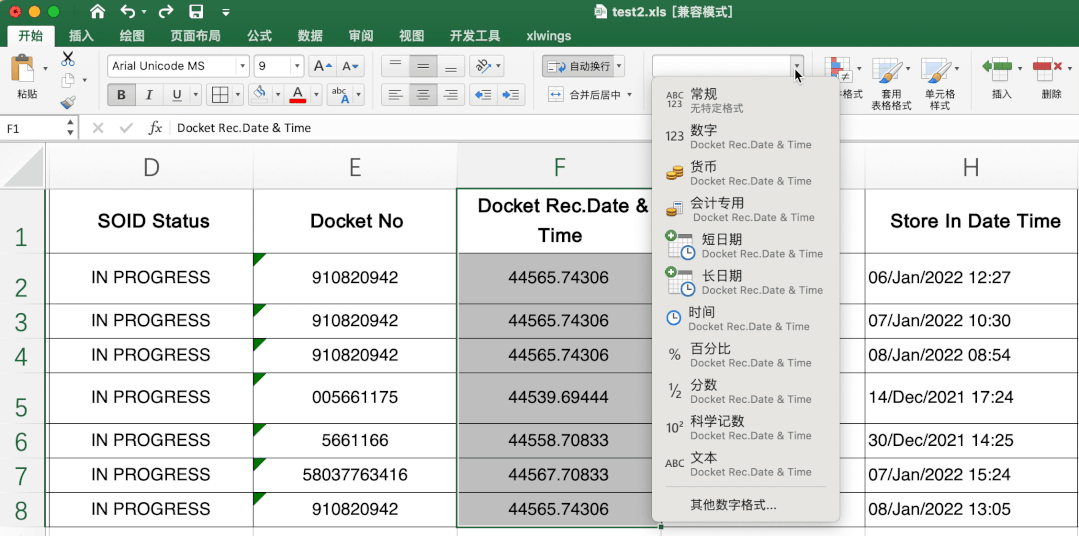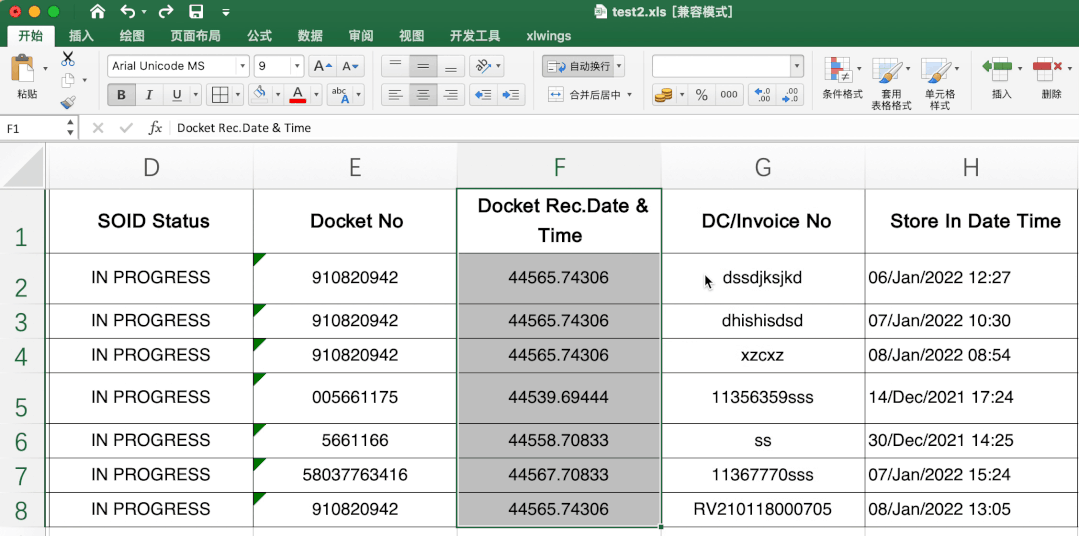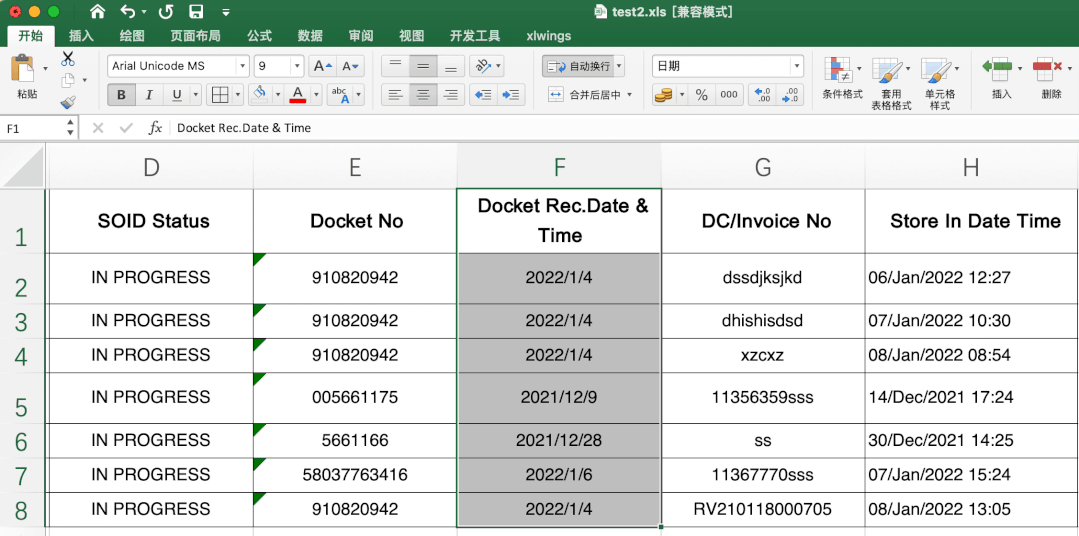
当时第一眼不知道其中的转换规律,搜索了很久,也没发现有类似问题或说明,首先肯定不是时间戳,感觉总有点关系,最后发现是天数,计算出天数计算起始日期就可以解决其他数据转变问题啦。
首先我们要判断空值,然后设置日期天数计算起始时间,利用datetime模块的timedelta函数将时间天数转变成时间差,然后直接与起始日期进行运算即可得出其代表的日期。
# 日期天数转短日期
def days_to_date(days):
# 处理nan值
if pd.isna(days):
return
# 44567 2022/1/6
# 推算出 excel 天数转短日期 是从1899.12.30开始计算
start = date(1899,12,30)
# 将days转换成 timedelta 类型,可以直接与日期进行计算
delta = timedelta(days)
# 开始日期+时间差 得到对应短日期
offset = start + delta
return offset这里比较难想的就是天数计算起始日期,不过想明白后,其实也好算,从excel中我们可以直接将日期天数转成短日期,等式已经有了,只有一个未知数x,我们只需列一个一元一次方程即可解出未知数x。
from datetime import date, timedelta
date_days = 44567
# 将天数转成日期类型时间间隔
delta = timedelta(date_days)
# 结果日期
result = date(2022,1,6)
# 计算未知的起始日期
x = result - delta
print(x)
'''
输出:1899-12-30
'''“2)将日期中的英文转成数字
”
最开始我想的是使用正则匹配,将年月日都在取出来,然后将英文月份转变成数字,后来发现日期里可以直接识别英文的月份。
代码如下,首先将字符串按格式转变成日期类型数据,原数据为06/Jan/2022 12:27(数字日/英文月/数字年 数字小时:数字分钟),按日期格式化符号解释表中对应关系替换即可。
# 官方日期格式转换成常见格式
def date_to_common(time):
# 处理nan值
if pd.isna(time):
return
# 06/Jan/2022 12:27 2022-1-6
# 测试 print(time,':', type(time))
# 将字符串转成日期
time_format = datetime.strptime(time,'%d/%b/%Y %H:%M')
# 转换成指定日期格式
common_date = datetime.strftime(time_format, '%Y-%m-%d')
return common_date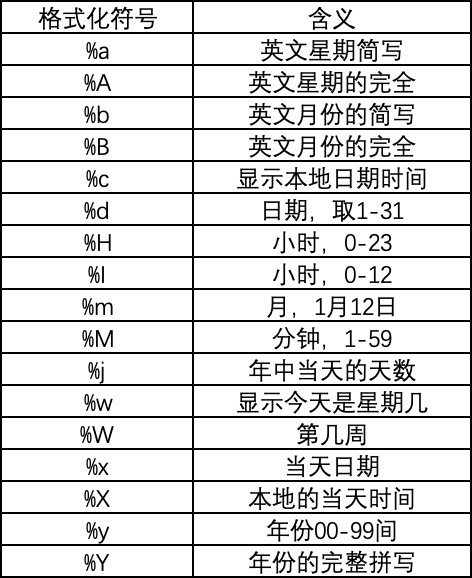
@CSDN-划船的使者
“3)按订单编号SOID去重
”
这里去重复除了按指定列去重外,还需要按日期保留最新数据。
我的想法是,首先调用pandas的sort_values函数将所有数据根据日期列进行升序排序,然后,调用drop_duplicates函数指定按SOID列进行去重,并指定keep值为last,表示重复数据中保留最后一行数据。
代码如下:
# 去除重复值 SOID重复 按日期去除最早的数据
def delete_repeat(data):
# 先按日期列 Docket Rec.Date & Time 排序 默认降序 保证留下的日期是最近的
data.sort_values(by=['Docket Rec.Date & Time'], inplace=True)
# 按 SOID 删除重复行
data.drop_duplicates(subset=['SOID #'], keep='last', inplace=True)
return data2.5 其他需求
“多个Excel数据对应一张数据库的表
”
可以写一个字典,来存储数据库表和对应Excel数据名称,然后一个个存储到对应的数据库表中即可(或者提前处理好数据后,再合并)。
合并同类型Excel表
# 相同表合并数据 传入合并excel列表
def merge_excel(elist, files_path):
data_list = [get_excel_data(files_path+i) for i in elist]
data = pd.concat(data_list)
return data这里传入同一类型Excel文件名列表(elist)和数据存储文件夹绝对/相对路径(files_path)即可,通过文件绝对/相对路径+Excel文件名即可得到Excel数据表文件的绝对/相对路径,再调用get_excel_data函数即可读取出数据。
遍历读取Excel表数据利用了列表推导式,最后利用pandas的concat函数即可将对应数据进行合并。
数据存储到sqlserver
# 初始化数据库连接引擎
# create_engine("数据库类型+数据库驱动://数据库用户名:数据库密码@IP地址:端口/数据库",其他参数)
engine = create_engine("mssql+pymssql://sa:123456@localhost/study?charset=GBK")
# 存储数据
def data_to_sql(data, table_naem, columns):
# 再对数据进行一点处理,选取指定列存入数据库
data1 = data[columns]
# 第一个参数:表名
# 第二个参数:数据库连接引擎
# 第三个参数:是否存储索引
# 第四个参数:如果表存在 就追加数据
t1 = time.time() # 时间戳 单位秒
print('数据插入开始时间:{0}'.format(t1))
data1.to_sql(table_naem, engine, index=False, if_exists='append')
t2 = time.time() # 时间戳 单位秒
print('数据插入结束时间:{0}'.format(t2))
print('成功插入数据%d条,'%len(data1), '耗费时间:%.5f秒。'%(t2-t1))sqlalchemy+pymssql连接sqlserver的时候注意坑:要指定数据库编码,slqserver创建的数据库默认是GBK编码,关于sqlserver安装使用可以查看文章Windows下载安装配置SQL Server、SSMS,使用Python连接读写数据。
2.6 完整调用代码
'''
批量处理所有excel数据
'''
# 数据文件都存储在某个指定目录下,如:
files_path = './data/'
bf_path = './process/'
# 获取当前目录下所有文件名称
# files = os.listdir(files_path)
# files
# 表名:附件excel名
data_dict = {
'testa': ['test1.xls', 'test2.xls'],
'testb': ['test3.xls'],
'testc': ['test4.xls']
}
# 选取附件中的指定列,只存入指定列数据
columns_a = ['S/No', 'SOID #', 'Current MileStone', 'Store In Date Time']
columns_b = ['Received Part Serial No', 'Received Product Category', 'Received Part Desc']
columns_c = ['From Loc', 'Orig Dispoition Code']
columns = [columns_a, columns_b, columns_c]
flag = 0 # 列选择标记
# 遍历字典 合并相关excel 然后处理数据后,存入sql
for k,v in data_dict.items():
table_name = k
data = merge_excel(v, files_path)
# 1、处理数据
if 'SOID #' not in data.columns:
# 不包含要处理的列,则直接简单去重后、存入数据库
data.drop_duplicates(inplace=True)
else:
# 特别处理数据
data = process_data(data)
# 2、存储数据
# 保险起见 本地也存一份
data.to_excel(bf_path+table_name+'.xls')
# 存储到数据库
data_to_sql(data, table_name, columns[flag])
flag+=1本文点赞过20,最近开源本文所有相关数据和代码。
3、后言后语
欢迎大家提需求呀,必须要有:明确的需求(列点)+ 有示例数据(打包发送)。
--xxx-xxxx需求.zip
----数据文件
----需求说明文件
----其他补充文件可以将需求和对应的需求说明+示例数据压缩包文件发送到我的邮箱zjhbrief@163.com。
最近过年在家,时间相对充足,欢迎交流~
坚持 and 努力 :终有所获。
思想很复杂,
实现很有趣,
只要不放弃,
终有成名日。
—《老表打油诗》
点赞 在看 留言 转发 ,四连支持,原创不易。好的,那么下期见,我是爱猫爱技术,更爱思思的老表⁽⁽ଘ( ˙꒳˙ )ଓ⁾⁾
--END--
扫码即可加我微信
付费咨询、代做项目最后推荐一个我的知识星球,具体会分享哪些方面我还没想好,至少可以确定的是:
1、AIGC开源项目复现营内容会放到这里(不少于12个相关开源项目详细部署教程)
2、ChatGPT对接微信、企业微信、钉钉、飞书等实现方法
3、低价服务器,教你云上部署
4、各种资料分享,星球支持提问、发帖、评论,让我们更好的交流
5、现在加入就送一个月GPT3.5私聊服务(加入即可立即领取)
五一期间我会仔细思考小报童、星球内容规划,到时候会涨价到188元,目前早鸟价:88元/年,扫码即可加入。
如果你有加入任何我推荐的知识星球,你都可以先微信私聊我领取一张大额优惠券再加入我的星球。
微信:pythonbrief
















 83
83











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











