







 本文详细介绍了 Puppeteer 库的使用,包括如何启动无头浏览器,管理浏览器实例和页面,以及进行页面导航、设置、元素操作和请求拦截。此外,还探讨了模拟器窗口、脚本注入、请求等待和权限管理等方面,展示了截图、登录自动化等功能。Puppeteer 可用于网页自动化测试、爬虫和生成 PDF 等场景。
本文详细介绍了 Puppeteer 库的使用,包括如何启动无头浏览器,管理浏览器实例和页面,以及进行页面导航、设置、元素操作和请求拦截。此外,还探讨了模拟器窗口、脚本注入、请求等待和权限管理等方面,展示了截图、登录自动化等功能。Puppeteer 可用于网页自动化测试、爬虫和生成 PDF 等场景。
puppeteer
组成结构
puppeteer 可以用于开启一个无界面的 chrom 浏览器(又称无头浏览器)进程,用代码实现操控浏览器的操作
yarn add puppeteer
yarn add puppeteer-core
puppeteer 的 API 仿造了浏览器的结构(透明部分表示这些浏览器结构再 puppeteer 中暂未实现:
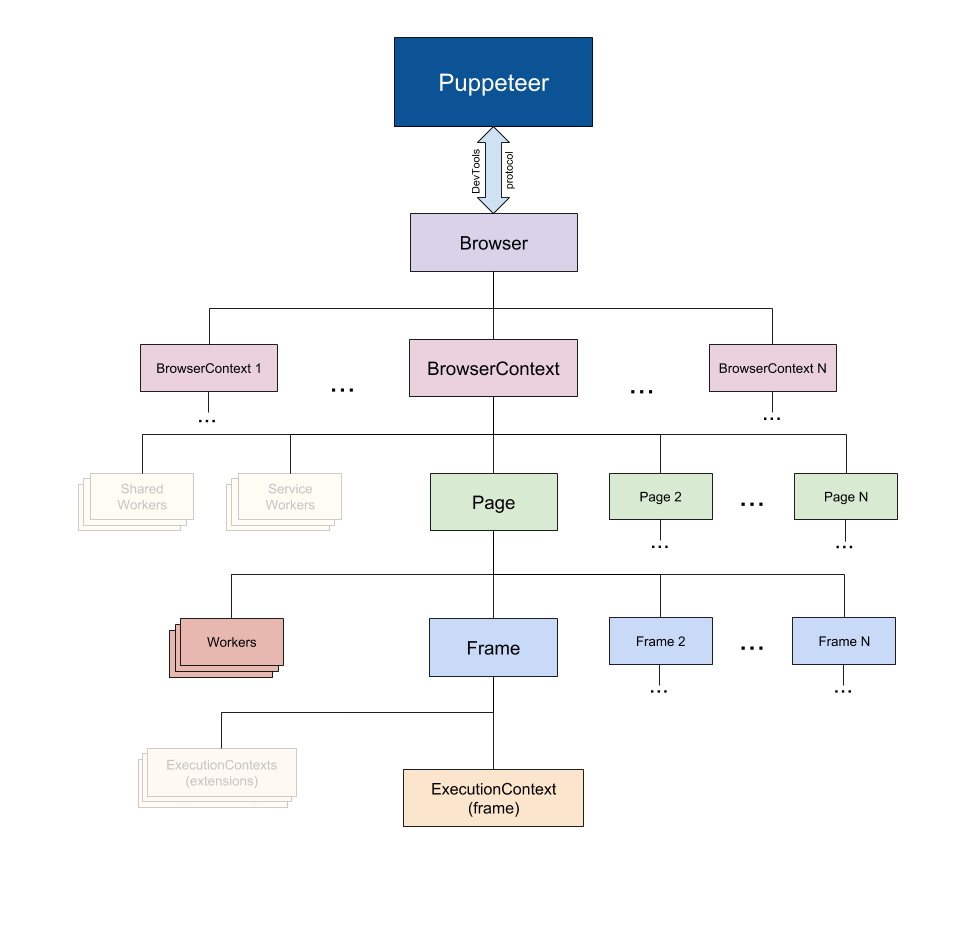
Browser
新建实例
使用 puppeteer.launch(options?) 来创建一个浏览器实例
创建实例后,在页面操作完毕时,需要手动把实例关闭,否则实例会越来越多导致内存泄漏
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch()
// 操作...
await browser.close()
}
init()
为了可视化调试,可以将无头模式关闭和打开每一步代码操作延时
const browser = await puppeteer.launch({
headless: false,
slowMo: 100,
})
可以建立多个实例
const init = async() => {
const browserA = await puppeteer.launch()
const browserB = await puppeteer.launch()
}
init()
连接实例
当已经存在浏览器实例时,就没必要重新建立实例,因此使用 puppeteer.connect(options?) 来连接的浏览器实例
连接的是一个浏览器 websocket 端点链接,该链接可通过 browser.wsEndpoint () 返回
// >现象:打开浏览器,在同一个浏览器中不断打开新的标签页并关闭
const puppeteer = require('puppeteer')
let browserWSEndpoint = ''
const init = async() => {
const browser = await puppeteer.launch()
// 使用puppeteer.connect的方式时就不要关闭浏览器了
browserWSEndpoint = await browser.wsEndpoint()
// ws://127.0.0.1:62989/devtools/browser/4eb19a2a-c019-4e2f-b476-9d9a6182e67d
console.log(browserWSEndpoint)
}
init()
setInterval(async() => {
const browser = await puppeteer.connect({ browserWSEndpoint })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com/')
await page.close()
},5000)
BrowserContext
在创建浏览器实例时,会自动创建一个默认的浏览器上下文,它是最基本的执行环境
不同浏览器上下文的环境中,不会共享 cookies 和 cache
可以使用 browser.createIncognitoBrowserContext() 创建一个新的浏览器上下文
每一个上下文都有一个
_id作为标志,默认上下文的标志为null
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch()
const defaultContext = browser.defaultBrowserContext()
const newContextA = await browser.createIncognitoBrowserContext()
const newContextB = await browser.createIncognitoBrowserContext()
const contexts = await browser.browserContexts()
// 验证上下文
console.log(defaultContext._id) // null
console.log(newContextA._id) // B071B622CF995C82950F273E59F70B34
console.log(newContextB._id) // FBC321F5FEF60814255BEF7CF23E6C37
// 验证上下文数组
console.log(contexts[0] === defaultContext) // true
console.log(contexts[1] === newContextA) // true
console.log(contexts[2] === newContextB) // true
console.log(contexts[3]) // undefined
browser.close()
}
init()
browser.browserContexts() :返回所有打开浏览器的上下文数组
browser.defaultBrowserContext() :返回默认的浏览器上下文
浏览器实例包含了所有的浏览器上下文内容
console.log(browser._defaultContext === defaultContext) // true
console.log(browser._contexts.get(newContextA._id) === newContextA) // true
console.log(browser._contexts.get(newContextB._id) === newContextB) // true
一个浏览器上下文代表的是一个浏览器窗口,即有 n 个实例就会在可视化调试中打开 n 个窗口,但是打开窗口需要有条件,即需要有页面存在,就像打开浏览器一定会有一个初始页面一样
浏览器实例并不代表浏览器窗口,在初始化实例时之所以会打开一个窗口是因为自带了默认上下文和默认页面
// 现象:打开两个浏览器窗口,默认窗口拥有两个标签页(因为默认自带一个),newContextA窗口拥有一个标签页
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const newContextA = await browser.createIncognitoBrowserContext()
const newContextB = await browser.createIncognitoBrowserContext()
const defaultPage = await browser.newPage()
const pageA = await newContextA.newPage()
}
而一个浏览器实例实际上代表的是一个浏览器进程,下面为多个浏览器实例与单个浏览器实例多个上下文的区别
const init = async() => {
const browserA = await puppeteer.launch({ headless: false })
const browserB = await puppeteer.launch({ headless: false })
}
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const newContext = await browser.createIncognitoBrowserContext()
}
Page
页面运行在浏览器上下文中,使用 browserContext.newPage() 去建立一个标签页,就像一个浏览器窗口可以打开多个标签页一样,一个上下文可以建立多个页面
如果使用浏览器实例去创建页面,则会建立在默认上下文中,即
browser.newPage()相当于browser._defaultContext.newPage()的简写
const init = async() => {
const browser = await puppeteer.launch()
const newContextA = await browser.createIncognitoBrowserContext()
const newContextB = await browser.createIncognitoBrowserContext()
const defaultPage = await browser.newPage()
const pageA = await newContextA.newPage()
const pageB = await newContextB.newPage()
console.log(defaultPage.browser() === browser) // true
console.log(pageA.browser() === browser) // true
console.log(pageB.browser() === browser) // true
browser.close()
}
page.browser():返回当前页面所属的浏览器实例
Frame
框架代表一个页面的具体内容,一个页面默认拥有默认框架 mainFrame ,一般而言,浏览器页面级的操作发生在 Page 类,而页面内的操作发生在 Frame
如设置页面 cookie page.setCookie(…cookies) 和查询页面元素 page.mainFrame().$(selector) 的方法继承的是不同的载体,puppeteer 为了使用方便,统一将 page.mainFrame().xxx 可简写为 page.xxx,这样就不需要过多考虑他们的区别,统一都认为是操作页面
ExecutionContext
它代表的是一个 js 执行上下文环境,当将本地的代码注入到页面中去执行时,它将产生作用
使用
<script>方式注入的方式并不算
如使用 page.mainFrame().evaluate(pageFunction, …args?) 注入本地代码,同理可以简写为 page.evaluate
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com/')
const data = 'data'
await page.evaluate(() => {
alert(data)
})
}
上面代码执行时会报错,因为在代码会放在网页中的执行上下文中去执行,而非在本地执行,因此会找不到 data 的变量声明
功能脚本
录制脚本
如果想体验写脚本可以先用一款 chrom 插件 Headless Recorder 来录制操作并转为 puppeteer 脚本来感受一下
页面导航
相关 API:
- page.goto(url, options?) :导航到指定地址
- page.goForward(options?):导航到页面历史的下一个页面
- page.goBack(options?):导航到历史的上一个页面
- page.url():返回当前页面 url
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com')
}
init()
为了调试方便,可以使用本地的网页文件进行调试
const puppeteer = require('puppeteer')
const path = require('path')
const filePrefix = 'file://'
const templatePath = `${filePrefix}${path.resolve(__dirname, './index.html')}`
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto(templatePath)
// 操作...
await page.close()
await browser.close()
}
init()
页面设置
相关 API:
- page.setViewport(viewport):设置页面大小
- page.cookies(…urls?):返回指定页面的 cookies,默认返回当前页面的
- page.setCookie(…cookies):设置 cookies
- page.deleteCookie(…cookies):删除 cookies
- page.setExtraHTTPHeaders(headers):设置为当前页面的所有请求带上自定义请求头
- page.setUserAgent(userAgent):设置用户代理
- page.setGeolocation(options):设置当前页面的访问地理位置
- page.setJavaScriptEnabled(enabled):设置是否禁用页面 js
- page.setRequestInterception(value):设置请求拦截器
- page.setCacheEnabled(enabled?):设置是否开启请求缓存,默认开启
- page.setOfflineMode(enabled):设置是否开启离线模式
注意:一般页面设置会在页面跳转前进行配置
模拟器窗口
可以使用对应的终端模拟器来打开页面,以获取到对应响应式的页面样式和效果
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
// 使用iphone6模拟器打开页面
await page.emulate(puppeteer.devices['iPhone 6'])
await page.goto('https://www.bilibili.com')
}
请求拦截
如果只是为了验网页的部分功能,则无需去加载网页的一些静态资源,这时候可以去使用请求拦截拦掉掉一些
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.setRequestInterception(true) // 启用拦截器
page.on('request', (interceptedRequest) => {
// 将png与jpg图片拦截掉
if (interceptedRequest.url().endsWith('.png') || interceptedRequest.url().endsWith('.jpg')) {
console.log(interceptedRequest.url())
interceptedRequest.abort() // 中断请求
} else {
interceptedRequest.continue()
}
})
await page.goto('https://www.bilibili.com')
}
脚本注入
相关 API:
-
page.evaluate(pageFunction, …args?):将指定方法放在页面中执行
-
page.evaluateHandle(pageFunction, …args):将指定方法放在页面中执行
和
page.evaluate仅返回数据类型不同,该方法返回的是JSHandle类型 -
page.evaluateOnNewDocument(pageFunction, …args?):将指定方法放在页面中执行
该方法会页面任意 script 执行前被调用,因此可以用来修改全局代码属性
-
page.exposeFunction(name, puppeteerFunction):将指定方法挂载到页面的
window对象使用该方法的好处是即使同一页面经过多次导航,也能继续使用暴露的方法
-
page.addScriptTag(options):在页面上建立
<script>标签并引入网络或本地的脚本代码 -
page.addStyleTag(options):在页面上建立
<link>标签并引入网络或本地的样式代码
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com')
await page.evaluate(() => {
alert('在网页上执行的代码')
})
}
init()
如果在注入的脚本中去执行异步操作,则需要通过返回 promise 来阻塞本地代码的后续操作,因为本质上
await阻塞的是 promise,如果不这样操作后果你懂得~
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com')
await page.evaluate(() => {
return new Promise((resolve) => {
setTimeout(() => {
console.log('阻塞了10秒')
resolve()
})
})
})
console.log('在页面阻塞操作完毕后执行')
}
需要注意的是,脚本的执行环境是在网页中,因此应该把注入网页中的代码看做完全独立的一部分,因此需要注意:
- 变量数据无法通过代码中的上下文访问到,注入的方法所需要的数据完全需要从外部传进或在内部声明
- 浏览器无法识别
require或import,无法直接在网页中使用本地的 npm 库文件,需要在网页中建立<script>标签并手动引入库的 cdn 链接,可以在 BootCDN 找到对应包的 cdn 地址
因此要想在页面上使用第三方库需要额外引入
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com')
// 将dayjs引入网页
await page.addScriptTag({
url: 'https://cdn.bootcdn.net/ajax/libs/dayjs/1.10.6/dayjs.min.js'
})
await page.evaluate(() => {
const result = dayjs().format('YYYY年MM月DD日')
alert(result)
})
}
如果无法正常加载 cdn,检查浏览器代理
或者将库的某个方法暴露给 window 对象
需要注意
page.exposeFunction将返回一个 promise 对象,后续操作要使用await去拿到最终数据
const dayjs = require('dayjs')
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://www.bilibili.com')
await page.exposeFunction('format', (rules) => {
return dayjs().format(rules)
})
await page.evaluate(async () => {
const result = await window.format('YYYY年MM月DD日')
alert(result)
})
}
页面元素
相关 API:
-
page.content():返回页面完整的 html 代码
-
page.$(selector):使用
document.querySelector寻找指定元素 -
page.$$(selector):使用
document.querySelectorAll寻找指定元素 -
page.$x(expression):使用 xpath 寻找指定元素
-
page.$eval(selector, pageFunction, …args?):在页面中注入方法,执行
document.querySelector后将结果作为第一个参数传给函数体 -
page.$$eval(selector, pageFunction, …args?):在页面中注入方法,执行
document.querySelectorAll后将结果作为第一个参数传给函数体 -
page.click(selector, options?):点击选择器匹配的元素,有多个元素满足匹配条件仅作用第一个
-
page.tap(selector)::点击选择器匹配的元素,有多个元素满足匹配条件仅作用第一个,该方法主要针对手机端的触摸事件
-
page.focus(selector):给选择器匹配的元素获取焦点,有多个元素满足匹配条件仅作用第一个
-
page.hover(selector):鼠标悬浮于选择器匹配的元素,有多个元素满足匹配条件仅作用第一个
-
page.type(selector, text, options?):输入内容到指定选择器匹配的元素,有多个元素满足匹配条件仅作用第一个
点击跳转
如果点击事件触发了一个页面跳转,为了确保结果正常,需要等待跳转完毕
const [result] = await Promise.all([
page.waitForNavigation(),
page.click('.jump-btn')
])
元素操控
由于 puppeteer 提供的操作元素方法并不多,因此可以将原生 js 注入网页中去操控元素,就不一定需要用到这些方法
如下面代码实现对网页表单的输入和提交
<!-- index.html -->
<div class="container">
<form class="from">
<input class="input-box" type="text" />
<button class="btn" onclick="alert('按钮被点击')">提交</button>
</form>
</div>
const puppeteer = require('puppeteer')
const path = require('path')
const filePrefix = 'file://'
const templatePath = `${filePrefix}${path.resolve(__dirname, './index.html')}`
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto(templatePath)
await page.waitForSelector('.container')
await page.evaluate(() => {
const inptBox = document.querySelector('.input-box')
const btn = document.querySelector('.btn')
inptBox.value = '输入的内容'
btn.click()
})
}
执行等待
相关 API:
-
page.waitForNavigation(options?):等待页面跳转后等待跳转完成条件成立,默认是
load事件触发时 -
page.waitForXPath(xpath, options?):等待 xpath 解析的页面元素出现在页面中
-
page.waitForSelector(selector, options?):等待选择器解析的页面元素出现在页面中
注意该方法和上面方法的出现是指在 dom 中可检索到便触发的意思,可以额外配置成 dom 中不为
display:none或visibility: hidde样式触发,但是无法控制成元素出现在窗口范围内触发 -
page.waitForFunction(pageFunction, options?, …args?):等待放到页面上下文执行的方法返回真值
-
page.waitForRequest(urlOrPredicate, options):等待页面上发起的请求满足判断条件并返回真值
-
page.waitForResponse(urlOrPredicate, options):等待页面上接收的请求响应满足判断条件并返回真值
-
page.waitFor(selectorOrFunctionOrTimeout, options?, …args?):可充当
page.waitForXPath、page.waitForSelector、page.waitForFunction和延时效果用为了不混淆,建议只用来当延时效果用
这些 API 的具体操作都是重复执行函数体,直到返回非假值 ,即如果无法满足条件将会一直阻塞后续代码执行
注意不要手动返回假值,会产生 bug,直接判断返回真值即可
所有的等待方法都会默认等待 30s ,如果该时间段内没有返回真值则会报错,可以另外配置超时时间
注意:除了
page.waitForFunction外,其他的执行上下文都是本地环境,因此可以直接在函数体中继续使用 puppeteer 提供的方法
等待元素
等待元素样式显示触发方法
<!-- index.html -->
<body>
<div class="container"></div>
<script defer>
setTimeout(() => {
const ele = document.querySelector('.container')
ele.classList.add('show')
}, 10000)
</script>
<style>
.container {
display: none;
}
.show {
display: block;
}
</style>
</body>
const puppeteer = require('puppeteer')
const path = require('path')
const filePrefix = 'file://'
const templatePath = `${filePrefix}${path.resolve(__dirname, './index.html')}`
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto(templatePath)
await page.waitForSelector('.container', {
visible: true
}).then(() => {
console.log('container已出现')
})
console.log("等待结束")
}
init()
等待请求
等待具体请求接收响应信息触发方法
请求和响应所传入的参数分别继承 Request 和 Response,可以使用他们的实例方法
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https:www.bilibili.com')
await page.waitForResponse(async (res) => {
if(res.url() === 'https://api.bilibili.com/x/web-interface/nav') {
const result = await res.json()
console.log(result) // { code: -101, message: '账号未登录', ttl: 1, data: { isLogin: false } }
}
})
}
使用场景
截图
一般使用 puppeteer 都是为了用它提供的截图功能:page.screenshot(options?)
默认截图会截取页面大小,即 800 x 600,可以通过更改页面大小来更改截图范围
const puppeteer = require('puppeteer')
const init = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.setViewport({
width: 1024,
height: 768
})
await page.goto('https://www.bilibili.com')
await page.screenshot({
path: `./imgs/${new Date().valueOf()}.png`
})
}
如果需要截取包括滚动条在内的所有网页内容,即长截图,可以直接开启 fullPage 选项
await page.screenshot({
path: `./imgs/${new Date().valueOf()}.png`,
fullPage: true
})
这个方法可以适用于不使用懒加载式加载内容的网页,如果遇到懒加载的网页则会吃瘪,因为这种网页都是为了首屏速度从而判断视口是否进入指定范围才去接着请求内容,而 puppeteer 的截图无法直接判断这点,因此首屏下面的都是占位元素没有实际内容
针对懒加载做出的截图调整思路:打开网站 → 注入脚本控制网页滚动条滚动 → 等待网络请求 → 继续往下滚动 → 重复过程直到网页末尾 → 截图
但是这里存在一个问题,puppeteer 似乎不能很好的在操作页面的过程中去判断新的请求是否已经请求完毕,除非对每个具体的请求做判断,但是这显然是不现实的,因此这里我只能手动加上延时来等待页面请求加载完毕,但是这也是不保险的,只能说,并没有太好的办法,凑合用用差不多得了
这里封装一个自定义截图图片的方法,设计思路如下:
- 可以连接服务器实例或自己创建服务器,可以传入服务器实例配置
- 可以传入参数配置截图参数,可设置截图窗口大小、截图最大高度或者直接截到网页末尾
- 网页无限滚动的机制基本上都是滚动条滚动到一定距离,就会开始加载新数据,因此直接给网页注入脚本控制滚动条滚动
- 判断页面的当前已滚动高度是否小于等于容器高度,如果是则继续滚动,如果否则退出循环并截图
需要注意的是涉及到请求的地方都需要手动加入延时来等待网络请求回来,如更改滚动高度后需要等待,否则无法及时拿到新数据加载后的新的容器高度导致判断错误,具体等待多久视网络情况而定
// screenshot.js
const puppeteer = require('puppeteer')
const path = require('path')
const screenshot = async (url, config={}) => {
let {
viewPort = { width: 1920, height: 1080 },
maxHeight = 1080,
browserWSEndpoint = null,
browserConfig = {},
fullPage = false,
} = config
let browser = null
if (fullPage) {
maxHeight = Infinity // 对于无限滚动,设置该字段可以一直截取下去,覆盖maxHeight字段
}
if (browserWSEndpoint) {
browser = await puppeteer.connect({ browserWSEndpoint }) // 如果存在浏览器实例,则直接连接
} else {
browser = await puppeteer.launch(browserConfig)
}
const page = await browser.newPage()
await page.setViewport(viewPort)
await Promise.all([
page.goto(url),
page.waitForNavigation([
'load',
'domcontentloaded',
'networkidle0'
])
])
const maxTime = Math.ceil(maxHeight / viewPort.height)
const documentHeight = await page.evaluate(async (maxTime, height) => {
for(let i=1; i<maxTime; i++ ) {
const curHeight = i * height
window.scrollTo({
left: 0,
top: curHeight - height,
behavior: 'smooth'
})
// 这里主动延时是等待跳转连接后新的请求加载完毕,否则容器高度更新不及时
await new Promise((resolve) => {
setTimeout(() => {
resolve()
},500)
})
const documentHeight = document.documentElement.scrollHeight // 由于可能加载新元素发生容器高度变化,因此每一次都获取一次容器高度
// 当前视窗理论高度大于总容器高度则判断已到达网页末尾
if(curHeight >= documentHeight) {
return documentHeight
}
}
}, maxTime, viewPort.height)
const imgPath = path.resolve(__dirname, `./imgs/${new Date().valueOf()}.png`)
await page.screenshot({
path: imgPath,
fullPage: fullPage,
clip: fullPage ? null : {
x: 0,
y: 0,
width: viewPort.width,
height: documentHeight || maxHeight // 如果网页没有达到最大高度,则截取网页高度
}
})
await page.close()
await browser.close()
return imgPath
}
module.exports = screenshot
启动代码如下
// app.js
const puppeteer = require('puppeteer')
const screenshot = require('./screenshot')
const initBrowser = async(browserConfig) => {
const browser = await puppeteer.launch(browserConfig)
return await browser.wsEndpoint()
}
const app = async() => {
const browserWSEndpoint = await initBrowser({ headless: false })
const imgPath = await screenshot('https://bilibili.com', {
browserWSEndpoint,
maxHeight: 6000,
})
console.log(imgPath)
}
app()
执行演示如下
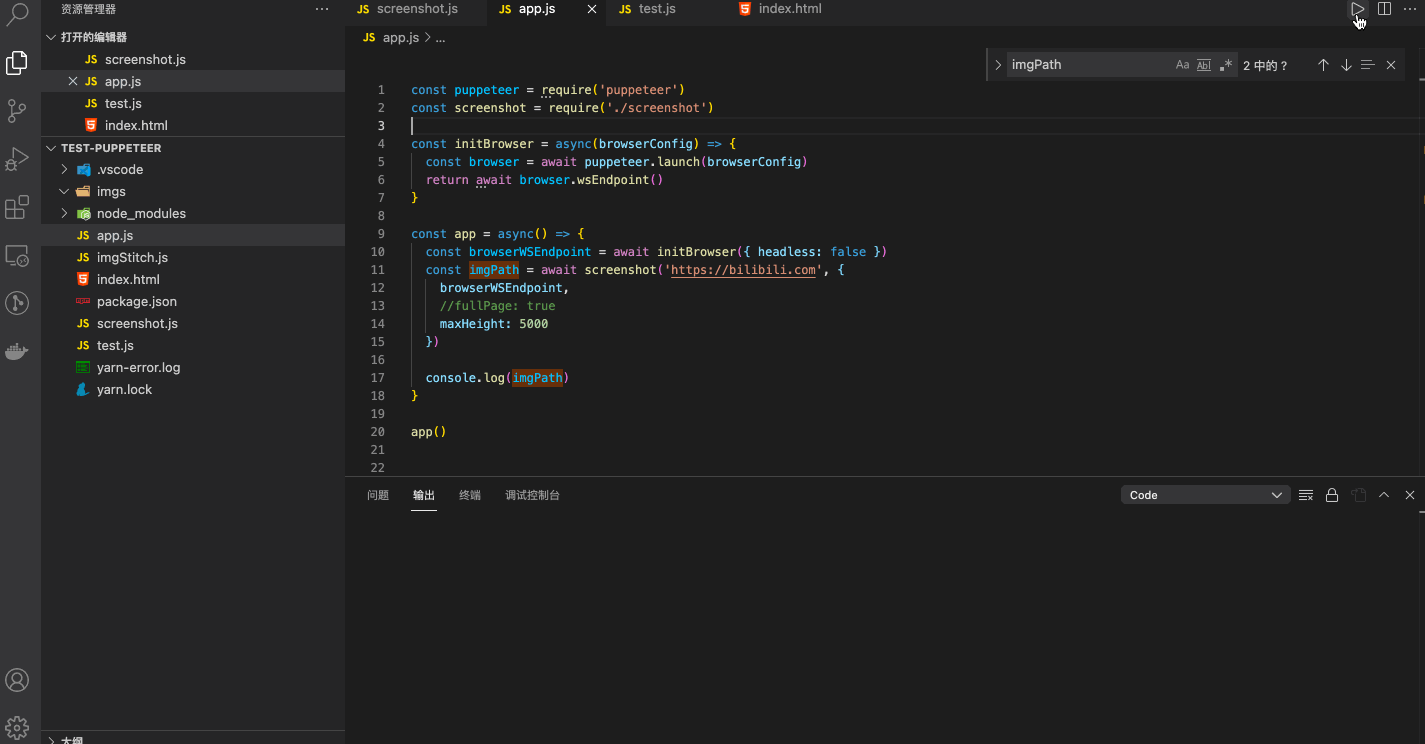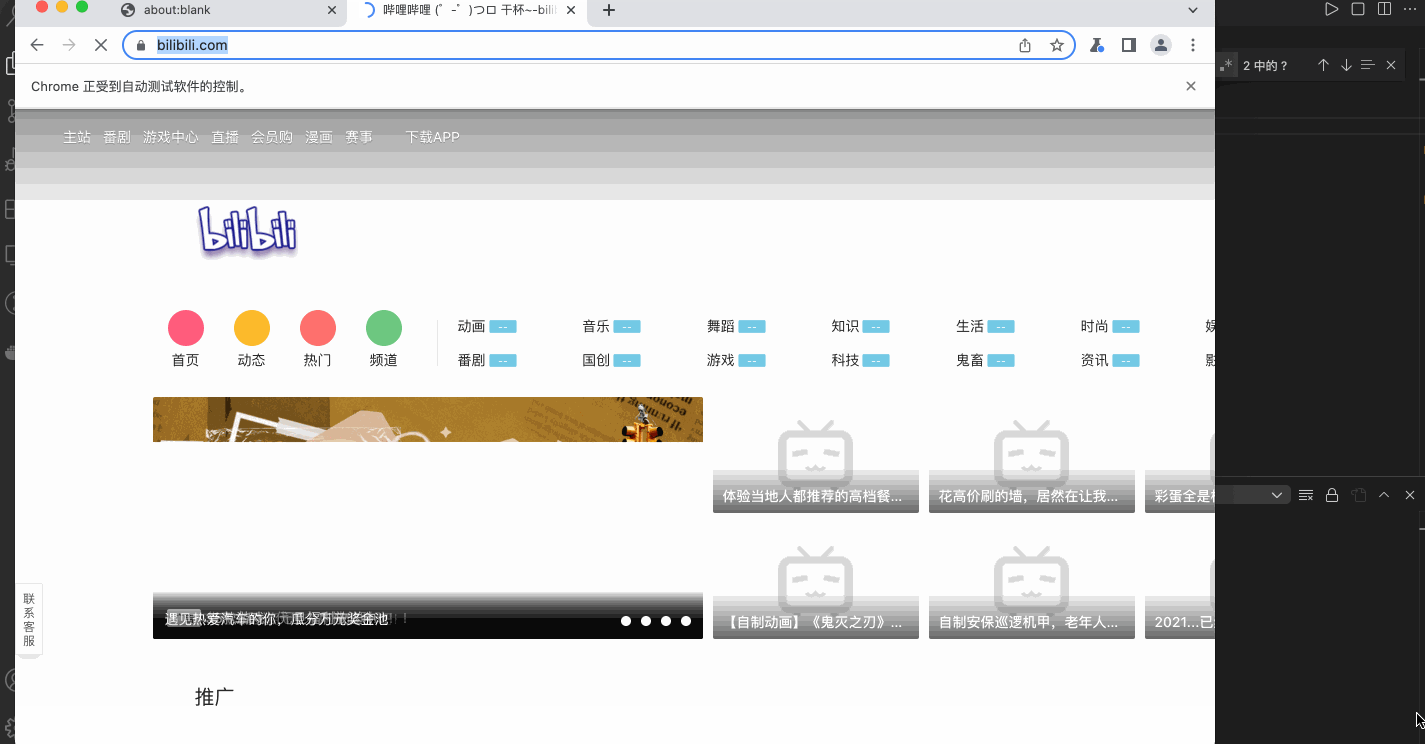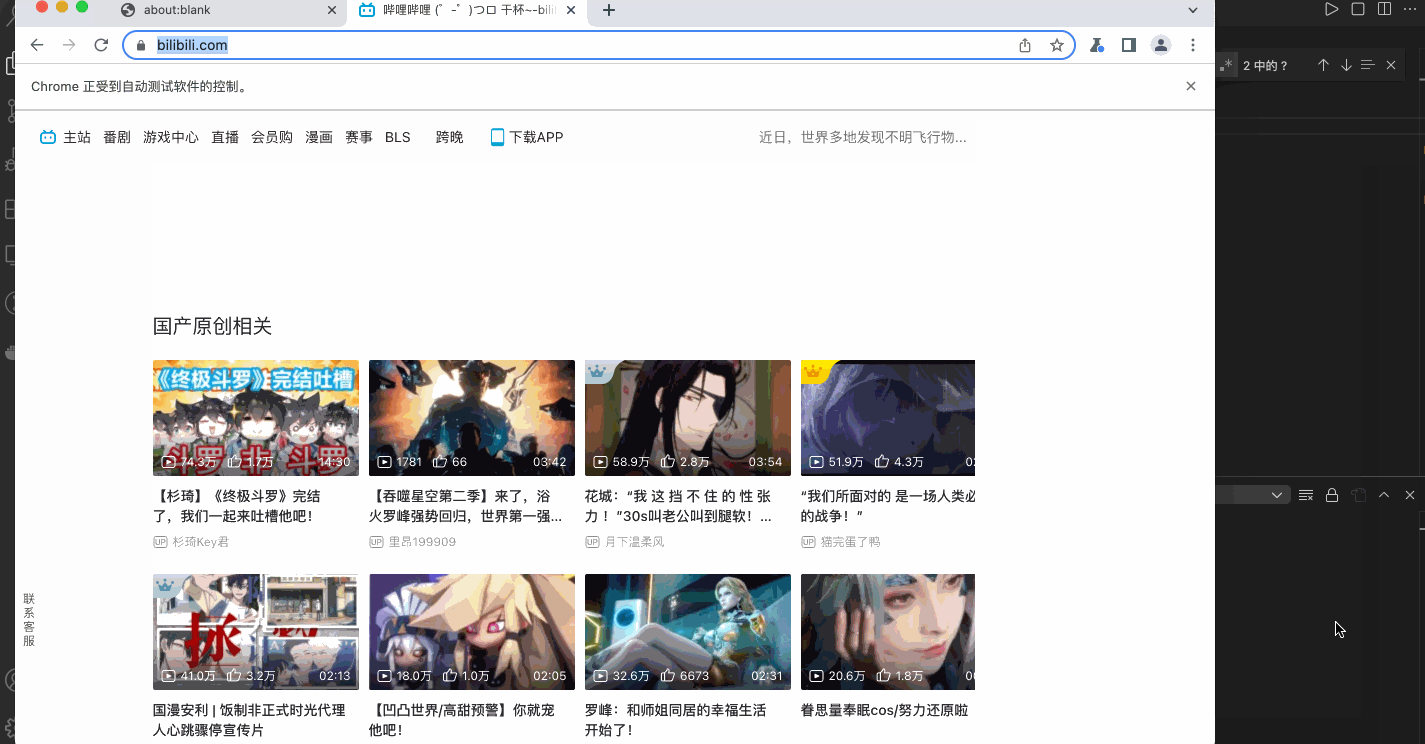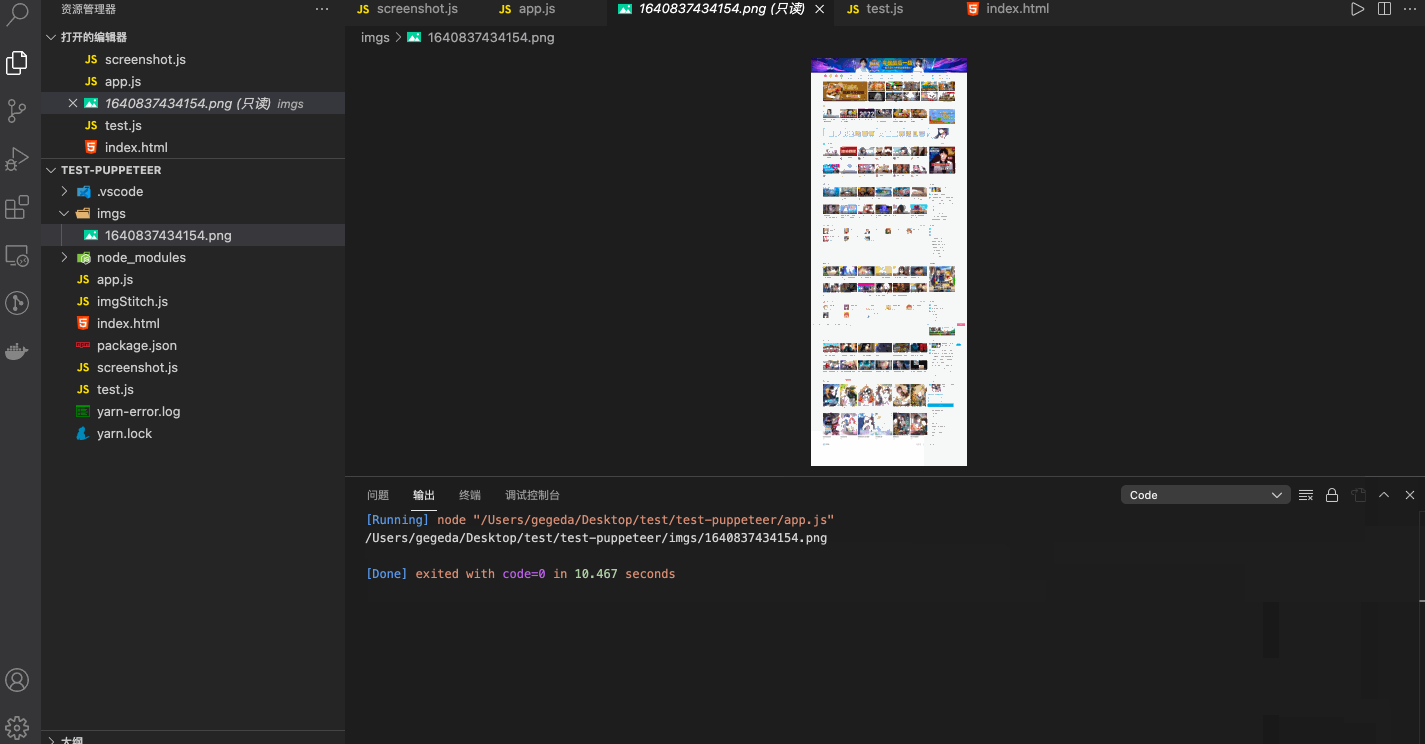
权限
Puppeteer 打开的浏览器不会拥有 cookie 记录,因此如果要访问有用户限制的网站需要登入
如果想要网站自动登入,理论上可以做到打开指定网站并输入账号密码,但是会卡死在验证码的环节上,因为验证码就是为了防止干这个的,这里当然不可能外接个图像算法来分析验证码,因此采用最简单的方式:
首次打开打开网站 → 手动进行登入操作 → 拿到登入后的 cookie 并存储 → 往后打开网站 → 读取对应 cookie → 设置 cookie → 刷新页面使之登入
因此可以封装一个读取和设置 cookie 的方法,设计思路如下:
- 因为第一次登入需要手动登入,因此在完成登入前需要设置一个标志,如果这个标志未完成则一直阻塞后续代码请求,这个需求可以用
page.waitForFunction来实现,如下面的代码设计的是直到在开发窗口手动设置x的值前会一直等待用户登录,即手动登入后需要再手动去开发窗口设置x的值,这个原理可以换成任意网址登录成功后的回调,但是这个回调并不是那么通用于是这里统一使用手动设置的方法 - 登入成功后将拿到的 cookie 保存起来,这里使用写入本地文件模拟,可换成数据库
- 读取 cookie 时如果文件不存在则先创建文件
// login.js
const { writeFile, readFile } = require('fs/promises')
const saveCookie = async (page, website) => {
await page.waitForFunction(() => {
if(window.x) return true
}, { timeout: 0 })
const cookie = await page.cookies()
// 这里统一把所有网站的cookie写入cookies文件夹里
await writeFile(`./cookies/${website}.json`, JSON.stringify(cookie))
}
const getCookie = async (website) => {
const path = `./cookies/${website}.json`
const data = await readFile(`./cookies/${website}.json`, {
flag: 'a+'
})
// 这里可以再加入判断cookie是否过期,如果过期,则也直接return的逻辑
if(!data.toString()) return
return JSON.parse(data.toString())
}
module.exports = { saveCookie, getCookie }
启动代码如下:
const puppeteer = require('puppeteer')
const { saveCookie, getCookie } = require('./login')
const websites = {
juejin: 'juejin'
}
const app = async() => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.setViewport({
width: 1920,
height: 1080
})
await Promise.all([
page.goto('https://juejin.cn/'),
page.waitForNavigation([
'load',
'domcontentloaded',
'networkidle0'
])
])
// 获取指定网站cookie,如果本地文件没有存储,则进行存储
let cookie = await getCookie(websites.juejin)
if(!cookie) {
console.log('需要登入...')
await saveCookie(page, websites.juejin)
cookie = await getCookie(websites.juejin)
}
await page.setCookie(...cookie)
await page.reload()
}
app()
因为要手动登入一次,因为并不能完全做到无头模式,可以先正常启动一次登入,有了数据后再开启无头模式
其他
Puppeteer 还能很多事情,比如网络爬虫、页面测试、生成 pdf 等,但是基本上很多操作都是注入 js 然后在页面上疯狂操作,和 puppeteer 的内容并无太多相关内容,基本都是 js 的网页操作,这里就不多做赘述,想玩的花总能玩的花
比如我想把 puppeteer 接入 QQ 机器人,在我输入命令时,它就会帮我去指定网站截取一张我想要的图,如微博的热点信息,那么实际上就是去访问对应的 网址,然后截图到本地文件,之后用机器人将这张图发送到 QQ 上,这样就能很方便地得知微博实时热点,截图的一大好处是不需要去分析具体的接口再对数据进行具体处理,直接一张图生动又形象
后记
莫得了,总之就是一个比较有意思的库,感兴趣可以玩一玩


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}