







匿名函数
函数没有名字, 这样函数只能在定义的时使用一次(缺点); 优点是简洁明了;
格式 lambda 参数1, 参数2 ... 参数n : 返回值表达式
# 格式 lambda 参数1, 参数2 ... 参数n : 返回值表达式
sums = lambda x, y: x +y;
print(sums(10, 30))
高阶函数
高阶函数: 函数的参数中含有函数作为参数
# 格式 lambda 参数1, 参数2 ... 参数n : 返回值表达式
sums = lambda x, y: x +y;
print(sums(10, 30))
def calFunction(x, y, mode):
if mode == '+':
return x + y
elif mode == '-':
return x - y
elif mode == '*':
return x * y
elif mode == '/':
return x / y
print(calFunction(10, 20, '*'))
# 修改成高阶函数的写法
def calFunc(func, x, y):
return func(x, y)
# 1. 传入正常函数
def add(x, y):
return x + y
def sub(x, y):
return x - y
# 这里传入函数名, 而不是 add() 函数的调用
print(calFunc(add, 20, 10)) # 30
print(calFunc(sub, 20, 10)) # 10
# 2. 传入匿名函数
print(calFunc(lambda x, y: x*y, 10, 50))
系统内置的常用高阶函数
系统高阶函数: python为我们提供的一些高数函数
- map 函数
map(func,interable)该函数使用函数作为自己的一个参数,它可以将 interable(可迭代对象) 中的数据依次传递给 func 函数处理,最后把处理的结果作为新的可迭代对象返回。
例如 [1,2,3,4,5]->[1,4,9,16,25]
# map 函数:
# map(func, *iterables)
# func 是一个函数, iterables可迭代对象
# 作用: func 作用与迭代对象中的每一个元素中, 并返回处理后新的迭代对象
# 返回的是map对象, 需要list进行转换
ls = [i for i in range(10)]
print(ls)
print(list(map(lambda x: x**2, ls)))
def func(x):
return x + 100
print(list(map(func, ls)))
text = "0 23 4 55 6 144 233" # 假设代表图像的像素值
tls = text.split()
print([int(v) for v in tls])
print(list(map(int, text.split())))
- reduce 函数
reduce(func,inteable)函数 例如可以累积操作。func函数必须接受两个参数,reduce会把 fuc 的运行结果做一个参数,然后从 interable 中再依次取出一个数据当作另一个参数
from functools import reduce
ls = [i for i in range(1, 6)]
print(ls) #[1, 2, 3, 4, 5]
print(reduce(lambda x, y: x*y, ls))
print(reduce(lambda x, y: x+y, ls))
- filter函数
filter(func,interable) 根据函数 func 来过滤 interable ,将interable 中的数据传入 func 中,如果函数返回 True 则保留该数据,否则就不保留
# filter
from random import randint
ls = [randint(-50, 50) for _ in range(10)]
print(ls)
# 选择温度大于0的
print(list(filter(lambda x: x > 0, ls)))
# 选出所有偶数
print(list(filter(lambda x:x%2==0, ls)))
- sorted 函数
sorted(interable,key = None, reverse = False) 对数据进行排序,并返回一个新对象 原对象不变。key 可以用来指定排序的规则,它接受的值是一个函数。reverse 是指定排序的顺序(升序或降序),默认为升序
from random import randint
import random
random.seed(111)
score_ls = [randint(10, 100) for _ in range(10)]
print(score_ls)
print(sorted(score_ls))
print("排序后score_ls", score_ls)
print("降序score_ls", sorted(score_ls, reverse=True))
# 复杂排序
text_ls = ['Andrew', 'This', 'a', 'from', 'is', 'string', 'test']
print(sorted(text_ls))
# 1 根据长度排序
print(sorted(text_ls, key=len))
print(sorted(text_ls, key=lambda ele: len(ele), reverse=True))
# 更为复杂的排序类型1
wcs = {'Oh': 2, 'Mister': 3, 'Sun': 5, 'Golden': 2, 'Please': 1, 'shine': 1, 'down': 1, 'on': 1, 'me': 1, 'SunMister': 1, 'Hiding': 1, 'behind': 1, 'a': 1, 'tree': 1}
# 选出出现频率最高的3个单词
# 转换成列表
print(list(wcs.items()))
res = sorted(list(wcs.items()), key=lambda tp: tp[1], reverse=True)
print(res)
print(res[:3])
print([w[0] for w in res[:3]])
# 更为复杂的排序类型2
hero_list = [
{"name": "鲁班七号", 'grade': 13, 'money': 14000, 'kda': 12.1},
{"name": "妲己", 'grade': 12, 'money': 10000, 'kda': 2.1},
{"name": "张飞", 'grade': 10, 'money': 4000, 'kda': 6.1},
{"name": "韩信", 'grade': 15, 'money': 20000, 'kda': 8.1},
{"name": "程咬金", 'grade': 14, 'money': 12000, 'kda': 7.1},
]
# 按照金币进行坚降序排序
hero_list = sorted(hero_list, key= lambda d: d['money'], reverse=True)
for hero in hero_list:
print(hero)

递归
递归是⼀种编程思想,应⽤场景:
- 在我们⽇常开发中,如果要遍历⼀个⽂件夹下⾯所有的⽂件,通常会使⽤递归来实现;
- 在后续的算法课程中,很多算法都离不开递归,例如:快速排序
递归的特点
- 函数内部⾃⼰调⽤⾃⼰
- 必须有终止条件
- 求 1 ~ n 累加和
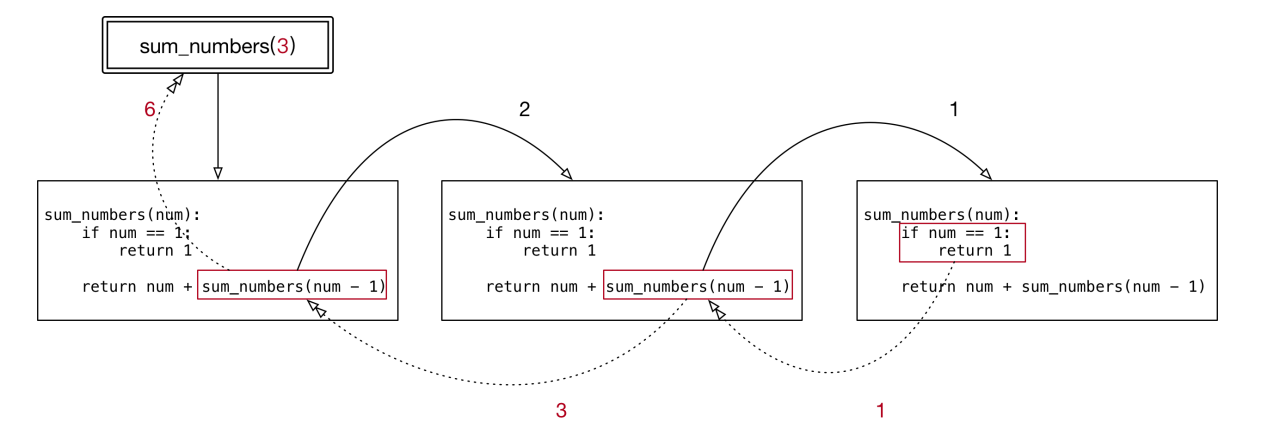
def sum_numbers(num):
if num == 1:
return 1;
return num + sum_numbers(num - 1)
print(sum_numbers(5))
# sum_numbers(5)
# 5 + sum_numbers(4)
# 4 + sum_numbers(3)
# 3 + sum_numbers(2)
# 2 + sum_numbers(1)
# sum_numbers(1) == 1
# 2 + 1
# 3 + 3
# 4 + 6
# 5 + 10
print(sum_numbers(100))
- 斐波那契数列的第n项
# 1, 1, 2, 3, 5, 8, 13
# 1, 2, 3, 4, 5, 6, 7
def fibo(n):
if n in [1, 2]:
return 1
return fibo(n-1) + fibo(n-2)
print(fibo(5))
print(fibo(7))
- 数组求和
#数组求和
print('***'*5)
from random import randint
import random
random.seed(666)
lst = [randint(10, 100) for _ in range(1, 10)]
print(f'数组为:{lst}') #[68, 58, 65, 46, 74, 11, 80, 80, 52]
print('和为:', sum(lst))
def sums(ls, num):
if num == 0:
return ls[0]
return ls[num] + sums(ls, num-1)
二分查找法:前提是数组必须有序
二分查找也是一种在数组中查找数据的算法。和线性查找不同,它只能查找已经排好序的数据。二分查找通过比较数组中间的数据与目标数据的大小,可以得知目标数据是在数组的左边还是右边。因此,比较一次就可以把查找范围缩小一半。重复执行该操作就可以找到目标数据,或得出目标数据不存在的结论
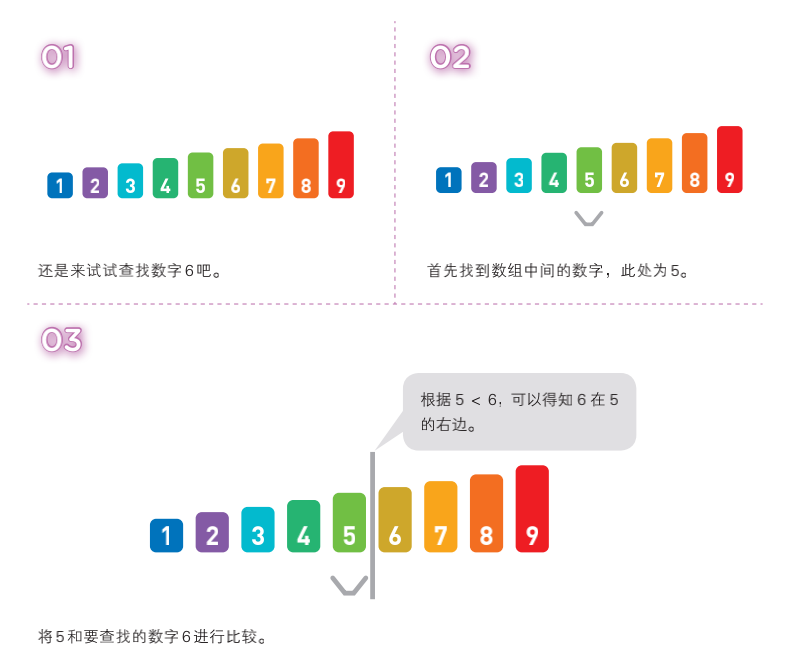
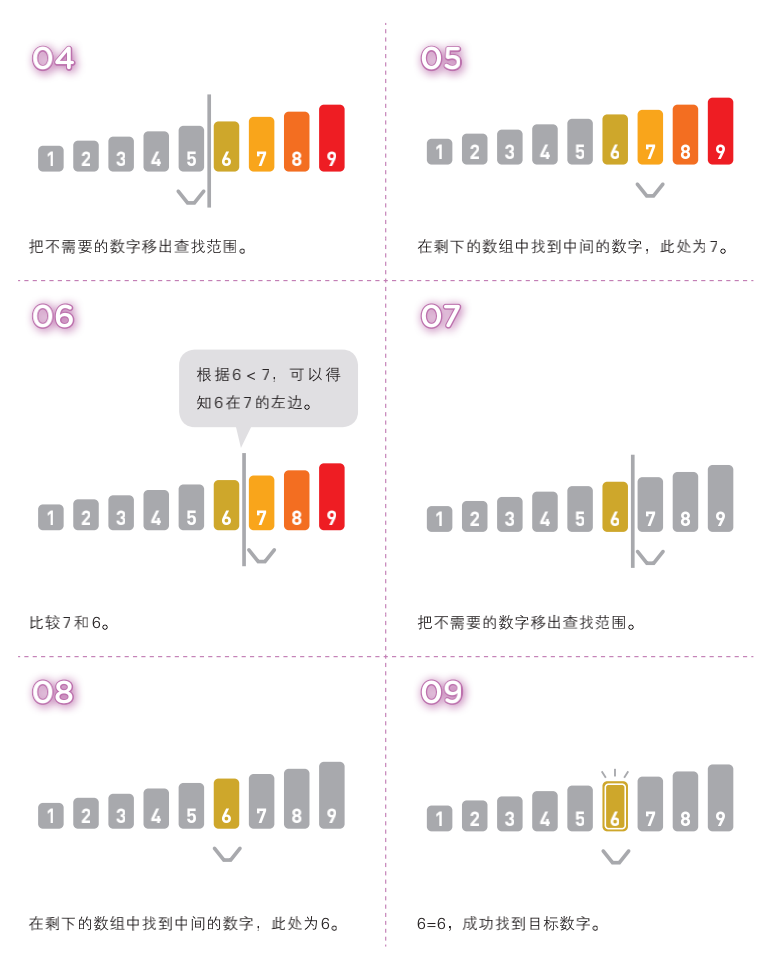
- 二分搜索的递归和非递归实现
非递归
#
from random import randint
import random
random.seed(111)
lst = sorted([randint(10, 100) for _ in range(1, 10)])
print(lst)
# 设计二分搜索函数寻找 目标值 37
def binary_search1(ls:list, target:int)->int:
left, right = 0, len(ls) - 1
while right >= left:
mid = (left+right)//2
if target == ls[mid]:
return mid
elif target > ls[mid]:
left = mid + 1
else:
right = mid - 1
return -1
print(binary_search1(lst, 37))
print(binary_search1(lst, 38))
print(binary_search1(lst, 100))
递归
from random import randint
import random
random.seed(111)
lst = sorted([randint(10, 100) for _ in range(1, 10)])
print(lst)
# 设计二分搜索函数寻找 目标值 37
def bs(ls:list, target:int, left, right)->int:
if right>=left:
mid = (left + right) // 2
if target == ls[mid]:
return mid
elif target > ls[mid]:
return bs(ls, target, mid + 1, right)
else:
return bs(ls, target, left, mid - 1)
else:
return -1
def binary_search(ls:list, target:int)->int:
return bs(ls, target, 0, len(ls)-1)
print(binary_search(lst, 37))
print(binary_search(lst, 38))
print(binary_search(lst, 100))















 752
752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









