










一 概括
简介
ArrayBlockingQueue(数组阻塞队列)类(下文简称数组阻塞队列)是BlockingQueue(阻塞队列)接口的主要实现类之一,也是Executor(执行器)框架常用的实现之一,采用数组的方式实现。数组阻塞队列类的底层数组采用了循环的思想,即当元素以插入/放置到数组的尾部后会从数组的头部重新开始插入/放置(如果头部因为移除/拿取而存在空位的话)。数组阻塞队列类是一个标准的FIFO队列,新元素会从尾部插入/放置(即尾插法),而元素的移除/拿取则会在头部进行。
数组阻塞队列类不允许存null值,或者说BlockingQueue(阻塞队列)接口的所有的实现类都不允许存null值。null被作为poll()及peek()方法作为数组阻塞队列不存在元素的标记值,因此所有的BlockingQueue(阻塞队列)接口实现类都不允许存null值。
数组阻塞队列类不同于我们常规使用的Collection(集)接口的实现类,没有扩容的说法,即其容量会在创建时确定,之后不会再发生改变。如此一来,其内部的实现结构便相对更加简洁。但这就使得我们必须根据业务的实际情况及资源的硬性限制来选择具体的容量…可一个很现实的问题是早期选定的容量又往往很难支持后期的发展…这也算是个令人很头疼的问题了。
数组阻塞队列类只能作为有界队列使用,这一点与LinkedBlockingQueue(链接阻塞队列)类不同。数组阻塞队列类只能作为有界队列使用,这意味着在创建其对象时必须指定容量。了解LinkedBlockingQueue(链接阻塞队列)类的同学应该清楚其无界队列用法实质上就是将LinkedBlockingQueue(链接阻塞队列)类对象的容量赋值为Integer.MAX_VALUE。因为这个容量实在太大了,在实际的运行中基本不可能触达上限,因此被称为无界队列。如此一来,只要我们在创建数组阻塞队列时同样将其容量指定为Integer.MAX_VALUE,那其与所谓的“无界队列”便没有什么本质区别。但话虽如此,实际开发中我们是强烈反对这么做的。不仅仅是因为无界队列容易导致OOM(元素的移除/拿取速率低于元素的插入/放置速率,导致元素堆积从而造成OOM),还因为其本身基于数组实现,一个Integer.MAX_VALUE长度的数组也是非常大的对象。因此在实际的开发中,还是推荐指定容量的有界队列用法,即根据业务的实际场景及资源的硬性限制选择合适的容量大小。
数组阻塞队列类是线程安全的,或者说BlockingQueue(阻塞队列)接口的所有的实现类都是线程安全的(接口的定义中强制要求实现类必须线程安全)。数组阻塞队列类采用“单锁”线程机制来保证线程安全,即使用单个ReentrantLock(可重入锁)类对象来保证整体同步。
数组阻塞队列类支持公平访问策略,即线程按时间顺序对数组阻塞队列进行访问(插入/放置、移除/拿取等),如果在创建时没有显式指定,则数组阻塞队列默认是非公平的。数组阻塞队列类的公平性选择直接依赖于ReentrantLock(可重入锁)类的公平锁机制实现。
数组阻塞队列类的迭代器是弱一致性,即可能迭代到已经从移除的元素及无法迭代到新插入的元素。数组阻塞队列类的迭代器实现非常复杂,或者说其实现思想虽然并不复杂,但是在具体实现中有太多的情况需要具体处理,因此整体代码显得非常凌乱无章,难以理解。该知识点的详细内容会在下文详述。
数组阻塞队列类虽然与BlockingQueue(阻塞队列)接口一样都被纳入Executor(执行器)框架的范畴,但同时也是Collection(集)框架的成员。
结构
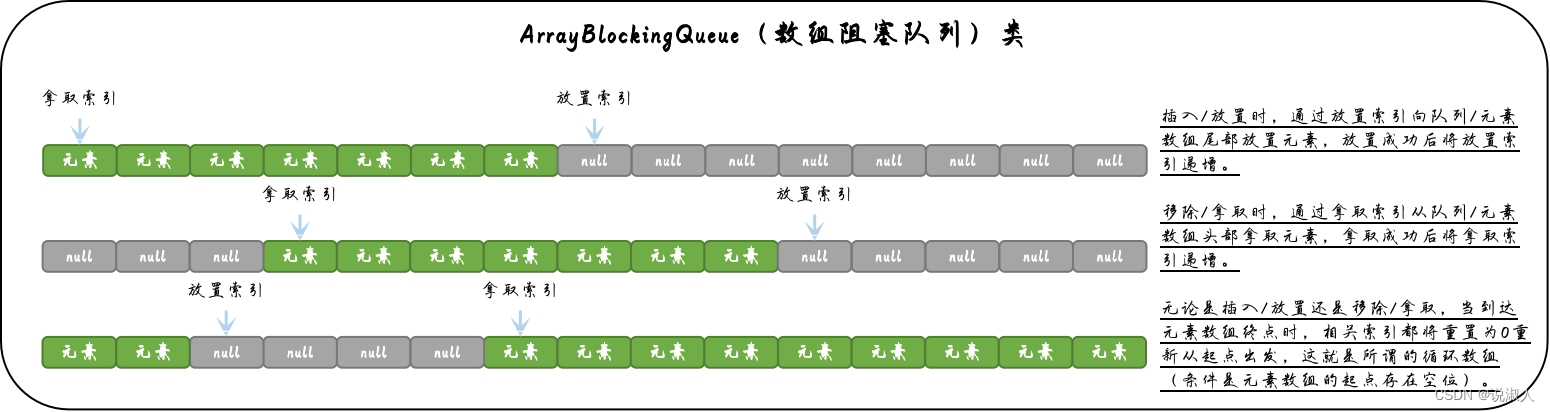
方法的不同形式
方法的不同形式实际上是Queue(队列)接口的定义,BlockingQueue(阻塞队列)接口拓展了该定义,而数组阻塞队列类实现了该定义。所谓方法的不同形式是指方法在保证自身核心操作不变的情况下实现多种不同的回应形式来应对不同场景下的使用要求。例如对于插入/放置,当容量不足时,有些场景希望在失败时抛出异常;而有些场景则希望能直接返回失败的标记值;而有些场景又希望可以等待至有可用空间后成功新增为止…正是因为这些不同场景的存在,方法的不同形式才应运而生,因此一个方法最多(并非所有方法都实现了四种形式)可能有四种不同回应形式。具体四种回应形式如下:
- 异常 —— Queue(队列)接口定义 —— 当不满足操作条件时直接抛出异常;
- 特殊值 —— Queue(队列)接口定义 —— 当不满足操作条件时直接返回失败标记值。例如之所以不允许存null值就是因为null被作为了操作失败时的标记值;
- 阻塞(无限等待) —— BlockingQueue(阻塞队列)接口定义 —— 当不满足操作条件时无限等待,直至满足操作条件后执行;
- 超时(有限等待) —— BlockingQueue(阻塞队列)接口定义 —— 当不满足操作条件时有限等待,如果在指定等待时间之前直至满足操作条件则执行;否则返回失败标记值。
与LinkedBlockingQueue(链接阻塞队列)类的对比
- LinkedBlockingQueue(链接阻塞队列)类是基于链表实现的,而数组阻塞队列类则基于数组实现,这使得在容量较大的情况下数组对象本身也会占用较多内存;
- LinkedBlockingQueue(链接阻塞队列)类支持无界队列用法,而数组阻塞队列类理论上不支持(实际上创建一个容量为Integer.MAX_VALUE的对象也是一样的);
- LinkedBlockingQueue(链接阻塞队列)类的线程访问是非公平的,而数组阻塞队列类支持公平及非公平,这直接依赖于ReentrantLock(可重入锁)类的公平锁机制实现;
- LinkedBlockingQueue(链接阻塞队列)类使用双锁机制保证线程安全(插入/放置与移除/拿取的锁是分离的),而数组阻塞队列类使用的则是常规的单锁线程机制。
二 创建
-
public ArrayBlockingQueue(int capacity) —— 创建指定容量的非公平数组阻塞队列,该构造方法是现实开发中最常用的,需根据业务的实际场景及资源的硬性限制选择合适的容量大小。
-
public ArrayBlockingQueue(int capacity, boolean fair) —— 创建指定容量及访问策略的数组阻塞队列。该方法的特点在于其可以通过fair(公平)参数指定线程是否公平的进行访问(即按时间顺序),而公平性选择是直接通过ReentrantLock(可重入锁)类的公平锁机制实现的。
-
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) —— 创建指定容量及访问策略,并按迭代器顺序包含指定集中所有元素的数组阻塞队列。该方法在实现上也有值得一说的地方。具体源码及注释如下:
/**
* Creates an {@code ArrayBlockingQueue} with the given (fixed) capacity, the specified access policy and initially containing the elements
* of the given collection, added in traversal order of the collection's iterator.
* 创建一个指定容量,指定访问策略及最初包含指定集元素的数据阻塞队列,按集的迭代器遍历顺序加入(队列)。
*
* @param capacity the capacity of this queue 队列的容量
* @param fair if {@code true} then queue accesses for threads blocked on insertion or removal, are processed in FIFO order; if {@code false}
* the access order is unspecified.
* 如果为true则队列线程访问会在插入及移除中阻塞,并按FIFO的顺序执行;如果为false则不指定访问顺序。
* @param c the collection of elements to initially contain 集的元素用于最初包含
* @throws IllegalArgumentException if {@code capacity} is less than {@code c.size()}, or less than 1.
* 非法参数异常:如果容量小于集的大小或者小于1
* @throws NullPointerException if the specified collection or any of its elements are null
* 空指针异常:如果指定集或集中的任意元素为null(阻塞队列的实现类都是不允许存null值的)
*/
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) {
// 设置容量与访问策略。
this(capacity, fair);
// 在锁的保护下,将指定集中的元素加入到队列的元素数组中。
final ReentrantLock lock = this.lock;
lock.lock();
// Lock only for visibility, not mutual exclusion
// 只是为了可见性而加锁,而不是为了互斥。
try {
int i = 0;
try {
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
// 如果在迁移的过程中,发现容量的大小不足以容纳指定集的全部元素,则会抛出非法参数异常。但比较令人惊讶的是作者竟然会使
// 用catch块的方式进行处理,而不是先进行比对。
throw new IllegalArgumentException();
}
// 设置总数与放置索引。
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
我们可以在上述的源码中发现将指定集中的元素存入队列的整个过程是加了锁的,而源码给出的英文注释是“只是为了可见性而加锁,而不是为了互斥”。其中本人对可见性是可以理解的(如果理解没有错的话):如果在过程中没有加锁,就会出现获取不到元素或元素不完整的情况。我们可以很轻松的理解获取不到元素的情况,但为什么会出现元素不完整的问题呢?这是因为在Java中对象的创建不是原子操作,整个过程按顺序大致可分为以下三部分:
- 实例化(分配内存);
- 初始化(执行构造方法);
- 引用赋值(令变量持有对象的引用)。
但现实中由于指令重排序的原因,具体在执行中顺序就可能变成:
- 实例化(分配内存);
- 引用赋值(令变量持有对象的引用);
- 初始化(执行构造方法)。
这就意味着加入到队列(存入元素数组)的元素可能是个不完整的元素,因此整个过程必须在锁的保护下执行。锁的存在虽然无法避免同步块中的指令重排序,但可以避免其重排序到同步块外(这就使得元素的初始化一定会在同步块中完成),因此使得队列创建完成后进行获取的线程获取到的元素一定是完整的。
如果上述我的理解都是对的,那就有一个讲不通的地方就是既然对象的创建不是原子操作,那完全可能存在有线程向一个未执行初始化(或未执行完初始化)的队列保存元素的可能,如此应该是可能存在竞争的,而不是英文注释中说的“没有竞争”,这也是我目前尚未完全理解的地方…当然,也可能是我对可见性的理解本就是错的,希望有懂的同学能在评论区不吝赐教,本人万分感谢。
三 方法
插入/放置
插入/放置是数组阻塞队列类两大最核心也是最常用的方法之一,用于向数组阻塞队列的尾部插入指定元素。由于场景的多样性需求,数组阻塞队列类实现了该类方法的四种形式以供使用。
- public boolean add(E e) —— 新增 —— 向当前数组阻塞队列的尾部插入指定元素。该方法是插入/放置方法“异常”形式的实现,当数组阻塞队列存在剩余容量时插入/放置成功并返回true;否则抛出非法状态异常。
数组阻塞队列类并没有自实现add(E e)方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了插入/放置方法“特殊值”形式的offer(E e)方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现offer(E e)方法后就可以正常调用add(E e)方法。这种代码结构是设计模式的一种,被称为“模板模式”。理论上来说,数组阻塞队列类是完全可以不重写add(E e)方法的,此处重写是为了添加注释的缘故。
/**
* Inserts the specified element at the tail of this queue if it is possible to do so immediately without exceeding the queue's capacity, returning
* {@code true} upon success and throwing an {@code IllegalStateException} if this queue is full.
* 如果没有超过超过队列的容量则直接在队列的尾部插入指定元素,成功后返回true。如果队列已满则抛出非法状态异常。
*
* @param e the element to add 新增的元素
* @return {@code true} (as specified by {@link Collection#add}) 按Collection.add()方法的说明返回true
* @throws IllegalStateException if this queue is full
* 非法状态异常:如果队列已满
* @throws NullPointerException if the specified element is null
* 空指针异常:如果指定元素为null
* @Description: 新增:用于向队列插入/放置一个元素,当队列存在空闲容量时插入成功返回true;否则抛出非法状态异常。该方法是插入/放置
* @Description: 操作“特殊值”形式的实现。
*/
@Override
public boolean add(E e) {
// 该方法直接调用父类(即AbstractQueue抽象类)的同名方法实现,而其的则是通过模板模式调用offer()方法实现的...所以理论上应该可
// 以不用重写该方法,此处由于为了重写注解的原因
return super.add(e);
}
-
public boolean offer(E e) —— 提供 —— 向当前数组阻塞队列的尾部插入指定元素。该方法是插入/放置方法“特殊值”形式的实现,当数组阻塞队列存在剩余容量时插入/放置成功并返回true;否则返回false。
-
public void put(E e) throws InterruptedException —— 放置 —— 向当前数组阻塞队列的尾部插入指定元素。该方法是插入/放置方法“阻塞”形式的实现,当数组阻塞队列存在剩余容量时插入/放置成功;否则等待至存在剩余容量为止。
-
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException —— 提供 —— 向当前数组阻塞队列的尾部插入指定元素。该方法是插入/放置方法“超时”形式的实现,当数组阻塞队列存在剩余容量时插入/放置成功并返回true;否则在指定等待时间内等待至存在剩余容量,超出指定等待时间则返回false。
移除/拿取
移除/拿取是数组阻塞队列类两大最核心也是最常用的方法之一,用于从数组阻塞队列的头部移除并获取元素。移除/拿取方法同样有四种形式的实现。
- public E remove() —— 移除 —— 从当前数组阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“异常”形式的实现,当数组阻塞队列存在元素时移除/拿取并返回头元素;否则抛出无如此元素异常。
数组阻塞队列并没有自实现remove()方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了移除/拿取方法“特殊值”形式的poll()方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现poll()方法后就可以正常调用remove()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/**
* Retrieves and removes the head of this queue. This method differs from {@link #poll poll} only in that it throws an exception if this queue is empty.
* 检索并移除队列的头。该方法不同于poll()方法,如果队列为空时其会抛出一个异常。
* <p>
* This implementation returns the result of <tt>poll</tt> unless the queue is empty.
* 除非队列为空,否则该实现返回poll()的结果。
*
* @return the head of this queue 队列的头(元素)
* @throws NoSuchElementException if this queue is empty
* 无元素异常:如果队列为空
*/
public E remove() {
// 调用poll()方法获取元素。
E x = poll();
if (x != null)
// 如果元素存在,直接返回。
return x;
else
// 如果元素不存在,抛出无元素异常。
throw new NoSuchElementException();
}
-
public E poll() —— 轮询 —— 从当前数组阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“特殊值”形式的实现,当数组阻塞队列存在元素时移除/拿取并返回头元素;否则返回null。
-
public E take() throws InterruptedException —— 拿取 —— 从当前数组阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“阻塞”形式的实现,当数组阻塞队列存在元素时移除/拿取并返回头元素;否则等待至存在元素。
-
public E poll(long timeout, TimeUnit unit) throws InterruptedException —— 轮询 —— 从当前数组阻塞队列的头部移除并获取元素。该方法是移除/拿取方法中“超时”形式的实现,当数组阻塞队列存在元素时移除/拿取并返回头元素;否则在指定等待时间内等待至存在元素,超出指定等待时间则返回null。
检查
检查也是数组阻塞队列的常用方法之一,用于从数组阻塞队列的头部获取元素,但并不会将元素从数组阻塞队列中移除,属于移除/拿取方法的阉割版。检查方法同样具备多形式的实现,但只有“异常”与“特殊值”两种。
- public E element() —— 元素 —— 从当前数组阻塞队列的头部获取元素。该方法是检查方法中“异常”形式的实现,当数组阻塞队列存在元素时返回头元素;否则抛出无如此元素异常。
数组阻塞队列并没有自实现element()方法,而是直接使用了父类AbstractQueue(抽象队列)抽象类的实现(具体源码如下)。在实现中其调用了检查方法“特殊值”形式的peek()方法来达成目的,使得所有AbstractQueue(抽象队列)抽象类的子类只需实现peek()方法后就可以正常调用element()方法。这种代码结构是设计模式的一种,被称为“模板模式”。
/**
* Retrieves, but does not remove, the head of this queue. This method differs from {@link #peek peek} only in that it throws an exception if this
* queue is empty.
* 检索,但不移除队列的头(元素)。该方法不同于peek()方法,如果队列为空时其会抛出一个异常。
* <p>
* This implementation returns the result of <tt>peek</tt> unless the queue is empty.
* 除非队列为空,否则该实现返回peek()的结果。
*
* @return the head of this queue 队列的头(元素)
* @throws NoSuchElementException if this queue is empty
* 无元素异常:如果队列为空
* @Description: 元素:用于返回队列的头元素(但不移除)。当队列中不存在元素时抛出无元素异常。
*/
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
- public E peek() —— 窥视 —— 从当前数组阻塞队列的头部获取元素。该方法是头部检查方法中“特殊值”形式的实现,当数组阻塞队列存在元素时返回头元素;否则返回null。
迁移
迁移也是数组阻塞队列的常用方法之一,用于将数组阻塞队列中的元素迁移至指定集中,迁移后的元素不再存在于数组阻塞队列中。为了避免迁移过程中元素丢失问题,实现往往会先将元素加入指定集中后再将元素从数组阻塞队列中移除。
- public int drainTo(Collection<? super E> c) —— 流失 —— 将当前数组阻塞队列中的所有元素迁移至指定集中,并返回迁移的元素总数。
- public int drainTo(Collection<? super E> c, int maxElements) —— 流失 —— 将当前数组阻塞队列中的最多指定数量的元素迁移至指定集中,并返回迁移的元素总数。
内部移除
内部移除的原始方法定义源自Collection(集)接口的remove(Object o)方法,用于将集中指定元素的首个单例(迭代器顺序)移除。由于指定元素可能处于集中的任意位置(不一定是头/尾),因此被称为内部移除。内部移除在队列中并不是常用的方法:一是其不符合队列FIFO的数据操作方式;二是各类队列为了提高性能可能会使用各种优化策略,而remove(Object o)方法往往无法适配这些策略,导致性能较/极差。
- public boolean remove(Object o) —— 移除 —— 从当前数组阻塞队列中移除指定元素的首个单例,移除成功返回true;否则返回false。
其它
除了上述提及的主要方法之外,数组阻塞队列还有一些常用方法如下所示:
- public int size() —— 大小 —— 获取当前数组阻塞队列中的元素总数。
- public int remainingCapacity() —— 剩余容量 —— 获取当前数组阻塞队列的剩余容量。
- public Object[] toArray() —— 转化数组 —— 获取一个按迭代器顺序包含当前数组阻塞队列中所有元素的数组。
- public T[] toArray(T[] a) —— 转化数组 —— 获取一个按迭代器顺序包含当前数组阻塞队列中所有元素的泛型数组。如果参数泛型数组长度足以容纳所有元素,则令之承载所有元素后返回。并且如果参数泛型数组的长度大于当前数组阻塞队列的元素总数,则将已承载所有元素的参数泛型数组的size索引位置设置为null,表示从当前数组阻塞队列中承载的元素到此为止。当然,该方案只对不允许保存null元素的集有效。如果参数泛型数组的长度不足以承载所有元素,则重分配一个相同泛型且长度与当前数组阻塞队列元素总数相同的新泛型数组以承接所有元素后返回。
- public void clear() —— 清理 —— 移除当前数组阻塞队列中的所有元素。
事实上,由于数组阻塞队列是Collection(集)接口的实现类,因此其也实现了其定义的所有方法。但由于这些方法的执行效率不高,并且与数组阻塞队列的主流使用方式并不兼容,因此一般情况下是不推荐使用的,有兴趣的可以去查看源码实现。
四 弱一致性迭代器
数组阻塞队列类自身实现了弱一致性的迭代器。所谓弱一致性,即数据最终会达成一致,但可能存在延迟。具体表现在迭代器中即是迭代得到已移除的元素或迭代不到新插入的元素。大致表现如下:
| 迭代者(即执行迭代的线程) | 移除者 | |
|---|---|---|
| T01 | 实例化迭代器,获取头元素A及其索引并保存快照,以备迭代 | |
| T02 | 移除/拿取元素A | |
| T03 | 迭代获取元素A ,并获取后继元素B及其索引并保存快照,以备迭代 | |
| T04 | 迭代获取元素B,并获取后继元素C及其索引并保存快照,以备迭代 | |
| T05 | 内部移除元素C | |
| T06 | 迭代获取元素C,并获取后继元素D及其索引并保存快照,以备迭代 |
上述表格中重点标红的两句是实现弱一致性的关键。可以发现,无论是移除/拿取还是内部移除都不会影响迭代器的正常迭代。这是因为数组阻塞队列类为了实现弱一致性迭代器做了两步关键的操作:
-
迭代器保存了下次迭代元素的快照:由于迭代器保存了下次迭代元素的快照,因此即使下次迭代时元素实际已从数组阻塞队列中移除,迭代器也依然可以返回迭代元素。与之相应的是如果迭代器已判断下次迭代的元素为null,则即使插入了新元素也无法被迭代,因为迭代器已经判定迭代完整结束。如此一来就实现了弱一致性“可能迭代到已移除的元素或迭代不到新插入的元素”的特点,不过这也会导致移除元素在迭代器中长期保存的问题并且无法解决。幸运的是该问题的发生概率不高,并且也只会导致少许对象被延迟回收或浪费少量存储空间,因此并不会产生较大的负面影响。
-
迭代器同时保存了下个索引(下个迭代元素对应的索引)及游标(下下个迭代元素对应的索引)两个索引来确保后续迭代元素的定位,以保证迭代器在各类移除(移除/拿取、内部移除)产生的场景中可以正常迭代。
事实上,数组阻塞队列类的迭代器是非常复杂的,因为其必须兼容各类移除造成的影响。而追究其根本原因,在于数组阻塞队列类是基于循环数组实现的,元素的定位依赖于索引,而元素的移除可能会导致迭代器中保存的索引无效,并且由于无效的场景并不相同,故而就必须针对性的进行调整,导致数组阻塞队列类的迭代器源码非常的庞大且繁杂。因此,学习迭代器的核心主旨就在于理清“迭代器如何调整因为各项移除而导致无效的索引”。迭代器的大致结构如下:

- 上个索引:保存上次迭代的元素索引,以实现迭代器的remove()方法。当迭代器未迭代或元素被迭代移除后为NONE(-1),当元素被移除/拿取或内部移除后为REMOVED(-2);
- 上个元素:保存上次迭代的元素快照,非常规字段,只在hasNext()方法返回false时生效(即不存在下个迭代元素时使用);
- 下个索引:保存下次迭代的元素索引。当不存在可下次迭代的元素是为NONE(-1),当元素被移除后为REMOVED(-2);
- 下个元素:保存下次迭代的元素快照,以实现迭代器的next()方法,并保证迭代器的弱一致性;
- 游标:保存下下次迭代的元素索引。当不存在可下下次迭代的元素时为NONE(-1)。
迭代器链
在提及索引调整之前,需要先明了两个概念:一是迭代器链;二是分离迭代器。所谓的迭代器链,是数组阻塞队列类自实现的本质为链表(没有实现List(列表)接口)的内部类,作用是作为数组阻塞队列与各个迭代器联系的桥梁。
一般来说,迭代器虽然可以迭代Collection(集)接口对象的元素,但是Collection(集)接口对象本身并不能访问迭代器。说的通俗一点,就是迭代器持有着Collection(集)接口对象的引用,但Collection(集)接口对象并没有持有迭代器的引用。因此,数组阻塞队列如果想对迭代器进行调整,首要条件就是建立两者之间的关联,而迭代器链起的就是这个作用。迭代器链除了以链表的形式保存了所有的未分离迭代器外,还保存了诸多用于对迭代器进行调整的必要条件,其大致结构如下:

数组阻塞队列会通过持有一个迭代器链来间接持有所有未分离迭代器的引用,以达成调整迭代器链的先决条件。需要特别说明的是,迭代器链内部实现的Node(节点)类继承自WeakReference(弱引用)类,这意味着节点本身也是WeakReference(弱引用)类对象,而其所指对象即为迭代器。这就使得如果迭代器失去了除节点以外的外部引用则就会被GC回收,从而令节点的迭代器为null,变为一个无效节点(迭代器为null的节点是无效节点的一种,除此以外迭代器为分离迭代器的节点也是无效节点),并进而清除。无效节点的清除机制如下:
- 数组阻塞队列对迭代器批量调整时会清除全部无效节点(批量调整会遍历整个迭代器链,因此可以顺势判断/分离迭代器并清除掉全部的无效节点);
- 数组阻塞队列为空时,将把迭代器链中所有节点的迭代器分离并清除;
- 当新的未分离迭代器创建时触发算法清除以清除部分/全部的无效节点(数组阻塞队列为空时创建的迭代器是分离迭代器,不会加入迭代器链,也不会触发算法清除);
- 当迭代器由于自身方法(hasNext()、next()及remove()等)调用而被切换成分离迭代器时会触发算法清除以清除部分/全部的无效节点。
所谓无效节点的算法清除即根据指定的清除算法清除部分无效节点,具体的清除效果根据无效节点的数量而定。清除算法的逻辑并不复杂,其会从指定的节点(上次算法清除遍历到的最后一个有效节点,如果是首次算法清除,或者上次算法清除完整的遍历了整个迭代器链,则为头节点)向后遍历指定的距离(4或16,可通过参数调节,触发算法清除的方法不同,传入的值也不同)。如果在过程中发现了无效节点,则将之清除并再次向后遍历指定的距离(固定16,只有首次遍历的距离可以通过参数调节),直至在过程中没有发现无效节点或完整遍历整个迭代器链结束(从迭代器链内部的某个节点开始的清除即使遍历到了尾节点也不能算遍历结束,因为在起点前方的节点并没有被遍历到。对于这种情况会从头节点继续遍历,直至在指定距离中没有发现无效节点或再次遍历到尾节点为止)。基于这种算法下,如果无效节点的数量足够多,理论上也能达到全部清除的效果。
分离迭代器
所谓分离迭代器是指不会再受数组阻塞队列数据变化影响的迭代器。正因如此,分离迭代器无需再受数组阻塞队列的调节,因此一旦迭代器被切换为分离迭代器,则其所在的节点就变为了无效节点。数组阻塞队列不会调整无效节点的迭代器,只会将无效节点从迭代器链中清除。
什么样的迭代器才满足分离的条件呢?从最标准的角度来说,即游标/下个索引/上个索引都小于0。这些条件代表的含义如下:
游标
NONE(-1):元素数组中已没有可作为(或因为弱一致性不能作为)迭代器下下次迭代的元素;
下个索引
NONE(-1):元素数组中已没有可作为迭代器下次迭代的元素;
REMOVED(-2):被选中的作为下次迭代的元素被移除/拿取或内部移除;
上个索引
NONE(-1):迭代器还没有进行迭代或迭代得到的上个索引对应的元素被迭代移除;
REMOVED(-2):迭代得到的上个索引对应的元素被移除/拿取或内部移除。
一旦迭代器满足上述条件,意味着其已经没有可迭代的元素,且无法执行迭代移除操作(迭代器调用remove()方法会将上个索引在元素数组中对应的元素移除,这会导致元素数组的变化,并进而影响到其它未分离迭代器)。这就使得数组阻塞队列无法对该迭代器造成影响,迭代器也再无法对数组阻塞队列造成变动,两者从原先的联动关系变成了各自“分离”的状态。在这种情况下,迭代器就可以被分离了,被分离(本质是状态值的改变)后的迭代器就被称为分离迭代器。需要提及的是分离后的迭代器并非是无用的,如果其依然保存着下个元素,则依然可以再调用next()方法进行一次迭代。
数组阻塞队列在三种特殊情况下会强制分离迭代器:一是迭代器长时间未迭代;二是数组阻塞队列变为空;三是迭代器hasNext()方法首次返回false。这三种强制分离迭代器的特殊情况主要是基于性能上的考量。事实上,虽然没有具体明言,但迭代器源码的种种实现可以看出数组阻塞队列是推荐将迭代器分离的,因为这可以减少具体调整的迭代器数量,有助于提高迭代器调整的整体性能。而对于因为强制分离而导致的有异于正常迭代的情况,由于弱一致性的设计,也是可以被接受的(反正都是弱一致性了,中间出现一些莫名其妙的情况也不奇怪)。
长时间未迭代的迭代器会被强制分离。强制分离时迭代器的各项索引会被赋值为特殊值,且[上个项]被置null,但[下个项]会保留,因此可以再执行一次迭代。所谓长时间其实是笼统的说法,它可能短到只有几毫秒也可能真的很长,这取决于数组阻塞队列元素的更迭速率。对于长时间更精确的规则是:在迭代器今/前两次方法执行期间数组阻塞队列的[takeIndex @ 拿取索引]被重置了至少两次。在该条规则下,可以保证迭代器上次方法执行时存在于数组阻塞队列中的元素已被全部移除。
[拿取索引]是数组阻塞队列用于记录头元素在元素数组中所在位置的索引,而所谓重置是指[拿取索引]从元素数组尾部跳转至头部的行为。如果[拿取索引]被重置了0次,则元素可能没有/部分/全部被移除;如果重置了1次,则可能部分/全部被移除;而如果重置了2次及以上,则元素必然全部被移除,这种情况下我们判定该迭代器已经长时间未迭代。
具体流程是:每当[拿取索引]重置时,数组阻塞队列会更新迭代器链中用于记录[拿取索引]的重置次数的[cycles @ 循环]。随后遍历迭代器链,将[循环]与每个有效节点迭代器保存的[循环]快照[prevCycles @ 先前循环]进行比对。满足规则的迭代器会被判定为长期未使用,从而被强制分离并被顺势回收。如果没有该机制,则无论迭代器被闲置多久,只要调整时元素数组中还存在元素,就不会被分离。
数组阻塞队列变为空时会强制分离所有未分离迭代器。具体操作是:当数组阻塞队列的最后元素被移除时(无论是哪类移除)会触发遍历迭代器链,将所有迭代器强制分离并回收。
迭代器的hasNext()方法首次返回false时迭代器会被强制分离。当迭代器hasNext()方法首次返回false时,可以确定的是迭代器已经没有可迭代元素,故而可知此时其[游标]及[下个索引]都为NONE(-1:无),且[下个项]为null,仅有[上个返回]还可能记录着迭代器上次迭代返回的元素在元素数组中的索引(如果没有被移除的话)。如此看来,此时的迭代器并不符合分离条件。因为迭代移除会导致数组阻塞队列发生变化,并进而影响到所有未分离迭代器。简单的说,就是该迭代器与数组阻塞队列依然处于联动状态。但事实上,一个已经完成所有迭代的迭代器存在意义已经不大了。就像上文中说的,其除了还可以进行一次迭代移除外没有任何其它作用。而remove()方法也并非常用操作,无法预知其何时执行,甚至是否会执行。如果假设迭代器始终不执行迭代移除(事实上这应该是常态),则该迭代器就将长期保持未分离状态,直至被其它机制强制分离或因为失去外部引用而被GC回收。但在此之前,其将一直存在于迭代器链中。显然,将如此迭代器存于迭代器链中并不明智,因此数组阻塞队列会将确认已完整迭代的迭代器强制分离。分离后的迭代器会保留[上个返回],以使得证迭代移除依然可以继续执行。
因完成迭代而被强制分离的迭代器无法保证迭代移除的正常执行。之所以无法保证因为无法得到[上个返回]在元素数组上对应的元素是否已被移除或因为其它元素的移除而变动了位置。正常情况下上述变化可以通过对[上个返回]进行判断得知,但由于此时迭代器已被强制分离,因此数组阻塞队列不会再将这些变化调整到该迭代器中。数组阻塞队列类对该情况进行了一定弥补设计:当迭代器的hasNext()方法首次返回false时,会将[上个返回]在元素数组中对应的元素保存在[上个项]中。而当迭代器执行迭代分离时,会先通过 == 判断[上个项]与[上个返回]在元素数组中对应的元素的地址是否相同,是则说明未被移除,允许执行迭代移除;否则说明已被移除,不允许执行迭代移除。但实际上这种弥补设计是不严谨的,虽然确实可以起到一定效果,但也有太多种可能令其失效,这包含但不限于“待移除元素因为其它元素的内部移除而变动了位置”及“被移除的是其它与待移除元素相同的元素(对象被加入多次或是被装箱的基础类型)”等。因此因完成迭代而被强制分离的迭代器无法保证迭代移除的正常执行,具体代码示例如下:
/**
* 主方法
*
* @param args 参数集
*/
public static void main(String[] args) {
ArrayBlockingQueue<Integer> arrayBlockingQueue = new ArrayBlockingQueue<>(5);
arrayBlockingQueue.add(1);
arrayBlockingQueue.add(2);
arrayBlockingQueue.add(3);
arrayBlockingQueue.add(4);
arrayBlockingQueue.add(5);
Iterator<Integer> iterator = arrayBlockingQueue.iterator();
while (iterator.hasNext()) {
iterator.next();
}
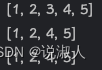
// 内部移除元素3,使得元素5的实际索引由4变为3,但迭代器中的快照索引依然为4。
System.out.println(arrayBlockingQueue);
arrayBlockingQueue.remove(3);
// 迭代移除上个迭代元素5。
System.out.println(arrayBlockingQueue);
iterator.remove();
// 元素5没有被迭代移除。
System.out.println(arrayBlockingQueue);
}
在说完了迭代器链与分离迭代器后,接下来就是我们真正的重点 —— 迭代器调整。虽然涉及的场景众多,但导致迭代器的调整原因只有一个 —— 移除。而具体的调整方式又可以基本分为批量/单体两类,即一次性调整所有的未分离迭代器或只调整其中的一个。一般来说,批量调整是由队列操作引起的,而单体调整则由迭代器操作引起。下文中会分别讲述“头部移除调整”、“内部移除调整”及“迭代移除调整”三类移除调整的详细过程。
头部移除调整
头部移除是数组阻塞队列类最常用的移除操作。该操作并不会对迭代器造成直接影响,也就是说头部移除并不会触发迭代器的批量调整,而是等到迭代器执行各项方法时自行单体调整,因此迭代器的两次操作间可能发生多次头部移除。如此设计是因为头部移除使用非常频繁,如果每次调用都进行批量调整将严重影响性能,因此不可以采用批量调整方案。
在正式进行头部移除调整之前,需要先进行定位操作。想要知道迭代器中的各项索引应该如何调整,必须先知道移除元素在元素数组中的索引(下文简称移除索引)对于其而言的先后位置,从而执行不同的调整规则。这一点并没有想象中那么简单,由于数组阻塞队列类循环数组的设计,有时虽然移除索引在物理上位于某索引的前方位置,但在逻辑上其实位于该索引的后方位置。不过也没有想象中那么复杂,因为这其中的关键在于计算迭代器今/前两次操作期间[拿取索引]前进的距离,而这则是可以通过公式轻易得到的…具体规则如下:
迭代器今/前两次操作期间[拿取索引]前进的距离 = [拿取索引]基于[先前拿取索引]前进的距离 = ([循环] - [先前循环]) * 数组长度 + ([拿取索引] - [先前拿取索引])
([循环] - [先前循环]) —— 表示[拿取索引]在今/前两次操作期间被重置的次数。由于重置次数大于等于2的迭代器会被判定为长时间未使用而被强制分离,因此一个可被调整的迭代器该值必然为0/1;
([循环] - [先前循环]) * 数组长度 —— 表示[拿取索引]在今/前两次操作期间在前进了“([循环] - [先前循环]) * 数组长度”个数组槽的距离;
([拿取索引] - [先前拿取索引]) —— 表示[拿取索引]在今/前两次操作期间前进(正数)/不动(0)/倒退(倒退)了“([拿取索引] - [先前拿取索引])”个数组槽的距离。
对于头部移除造成的迭代器索引无效的问题处理起来是最简单的,因为头部移除不会像内部移除一样导致元素的整体迁移,因此我们需要做的就是判断各个索引是否依然处于元素数组的元素段(即存有元素的范围)中。数组阻塞队列会类比上方公式计算出各索引基于[先前拿取索引]的距离。如果发现“各索引基于[先前拿取索引]的距离”小于“[拿取索引]基于[先前拿取索引]前进的距离”,则说明各索引已经不处于元素数组的元素段中。可以发现该操作的本质实际上就是判断各索引与[拿取索引]哪个距离[先前拿取索引]更远,距离更近的索引自然不在距离更远的索引的后方范围中。判断结束后不合法的索引需要按以下规则进行调整,而当调整完成,如果发现各索引都小于0,则说明该迭代器满足分离条件,遂将之分离。
游标
数组阻塞队列存在元素:赋值为头元素在元素数组中的索引,表示下次遍历会从队列的头部重新开始遍历;
数组阻塞队列不存在元素:赋值为NONE(-1),表示已没有可迭代的下下个元素;
下个索引
无条件:赋值为REMOVED(-2),表示原下个索引在元素数组中对应的元素已被移除;
上个索引
无条件:赋值为REMOVED(-2),表示原上个索引在元素数组中对应的元素已被移除。
内部移除调整
相对于头部移除,内部移除就复杂许多。内部移除会产生两种情况:一是指定移除的元素刚好是头元素。这种情况等价于头部移除调整,调整方式也与上文相同;二是真正意义上的内部移除,即移除元素位于元素数组的内部。这种情况最大的特点就是为了保证元素数组中元素的连贯性,必须将移除元素的所有后后元素前移。这就使得移除元素的位置不同,对迭代器造成的影响也不同。并且由于无法后期追踪内部移除的索引变化情况,该场景无法使用迭代器单体调整方案,故而只能在每次内部移除发生时实时使用批量方式进行调整。但如此会导致内部移除方法的性能较差,不过该方法本身也不推荐使用,因此影响倒也不大。
内部移除调整同样要进行定位,并且定位规则也与头部移除调整相同,都是比较与[先前拿取索引]的距离,只不过将[拿取索引]替换为了移除索引而已。而当“各索引与[先前拿取索引]的距离”小于/等于/大于“移除索引与[先前拿取索引]的距离”时,则意味着各索引位于移除索引位置的前方/中方/后方。值得一说的是:当各索引位于移除索引位置的前方时,可能存在各索引已经不处于元素数组中元素段中的情况。因为[拿取索引]在逻辑上必然位于移除索引之前,但各索引可能比[拿取索引]更前。对于这种情况内部移除不会做任何调整,而是等到各迭代器方法执行时各自单体调整。
游标
位于移除元素索引位置前方:无调整;
位于移除元素索引位置:如果移除的是最后元素,赋值为NONE(-1),表示已没有可迭代的下下个元素;否则无调整;
位于移除元素索引位置后方:递减;
下个索引
位于移除元素位置前方:无调整;
位于移除元素位置:赋值为REMOVED(-2),表示原下个索引在元素数组中对应的元素已被移除;
位于移除元素位置后方:递减;
上个索引
位于移除元素位置前方:无调整;
位于移除元素位置:赋值为REMOVED(-2),表示原上个索引在元素数组中对应的元素已被移除;
位于移除元素位置后方:递减。
迭代移除调整
迭代移除相对上述两者而言比较特殊,因为其同时占有批量与单体两类特性。迭代移除指的是迭代器的remove()方法,从这一点上看应该属于单体调整。但迭代移除又确实会导致数组阻塞队列数据的变化,产生一次等同于内部移除的操作,进而影响所有的迭代器(包括自身),如此来看就又属于批量调整。由于上文已经详述了内部移除的调整措施,故而此处不再讲述迭代移除造成的内部移除,只讲述其对迭代器的直接影响。具体如下:
游标
无条件:无调整;
下个索引
无条件:无调整;
上个索引
无条件:赋值为NONE(-1)。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











