







基础任务
- 背景问题:近期相关研究指出,在处理特定文本分析任务时,语言模型的表现有时会遇到挑战,例如在分析单词内部的具体字母数量时可能会出现错误。
- 任务要求:利用对提示词的精确设计,引导语言模型正确回答出“strawberry”中有几个字母“r”。完成正确的问答交互并提交截图作为完成凭证。
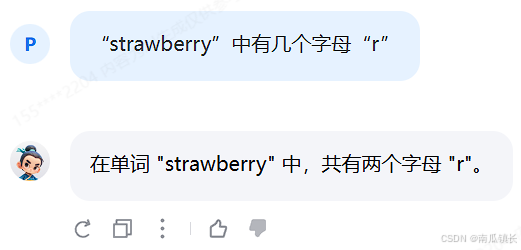
在没有提示词的情况下,书生浦语大概率会认为“strawberry”中有两个r,如图
想法是设定一个工作流,让大模型逐个字母确认,防止它“信口拈来”。
经过不断地调试,我最终试出了一组成功率极高的提示词。
# 任务描述:
计算英语单词中特定字母的个数
## 工作流:
1. 将单词拆分为字母并编号
2. 指出其中特定字母的编号
3. 统计指出的编号个数
## 示例:
### 示例输入:
请问"pop"中的字母"p"出现了多少次?
### 示例输出:
提问单词:pop
单词拆分:1.p 2.o 3.p
字母"p"的编号: 1, 3
字母"p"出现了 2次。
# 限制:
确保单词拆分后与提问的单词保持一致,不得修改提问单词
# 指令:
理解上述工作流后,请说“请告诉我要处理的英语单词”
这组提示词对比我初期的尝试,成功防止大模型在计数中途将单词拼错的问题,并且能保障在默认设定有一定温度的情况下保持输出格式和输出结果稳定,同时提示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









