







01. 记忆组件的持久化
在LangChain框架中,记忆组件(Memory)默认不具备持久化存储能力。为实现对话历史的长期保存,可采用分层存储方案:通过chat_memory模块实现对话记录的持久化存储,同时结合外部数据库系统对汇总信息、摘要等衍生数据进行管理。
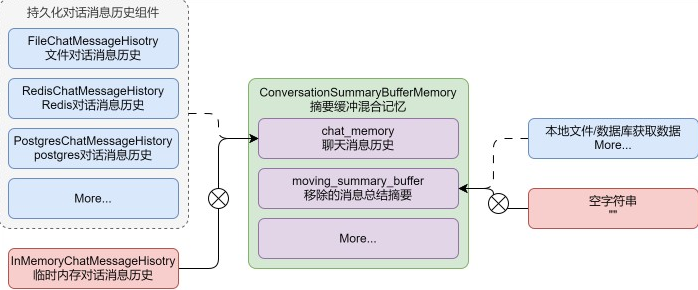
以ConversationSummaryBufferMemory组件为例,其持久化实施包含两个技术要点:
- 选择支持持久化的chat_memory实现(如基于数据库的存储方案)
- 建立外部存储机制(文件系统或数据库)来维护moving_summary_buffer字段的动态更新
通过这种分层存储机制,既能保障原始对话记录的完整性,又能实现摘要信息的动态维护,最终完成记忆组件的全生命周期持久化管理。
LangChain架构显著特性在于其强大的第三方集成能力,当前支持包括Postgres、Redis、Kafka、MongoDB、SQLite等在内的近50种异构数据存储方案作为对话消息历史载体。该生态图谱呈现三个关键设计优势:
-
多协议支持体系
通过ChatMessageHistory组件的标准化接口,可无缝对接SQL/NoSQL数据库、消息中间件、内存数据库等不同技术栈,覆盖从轻量级嵌入式存储到分布式集群的多样化部署场景 -
运行时无缝衔接
ChatMessageHistory严格遵循Runnable可运行协议规范,支持:
- 与LCEL(LangChain Expression Language)声明式编程范式深度集成
- 在异步执行管道中实现零损耗数据传输
- 基于检查点机制的流程状态持久化
- 热插拔式扩展
开发者可根据业务需求自由切换存储后端,仅需配置对应的连接参数即可完成组件替换,这种模块化设计显著降低了系统迁移的技术风险
LangChain 第三方记忆组件官网:Memory | 🦜️🔗 LangChain
国内APIkey中转平台:一步API(注册即送1美金额度)
02. 实现有记忆功能的聊天机器人API
在Flask框架中,由于每个请求处理结束后相关线程/协程资源会被自动释放,无法像命令行交互程序那样将对话记忆暂存于内存。因此需要引入中间存储层来持久化对话历史,可采用文件、数据库或独立进程等外部存储介质。
当前开发策略分为两个阶段:
- 初级实现:使用本地文件存储最近3轮对话,建立基础记忆功能
- 进阶扩展:待掌握RAG和工具回调技术后,将整体迁移至PostgreSQL数据库,实现包含配置参数、完整聊天记录等数据的统一管理
更新后的聊天机器人的运行流程图如下: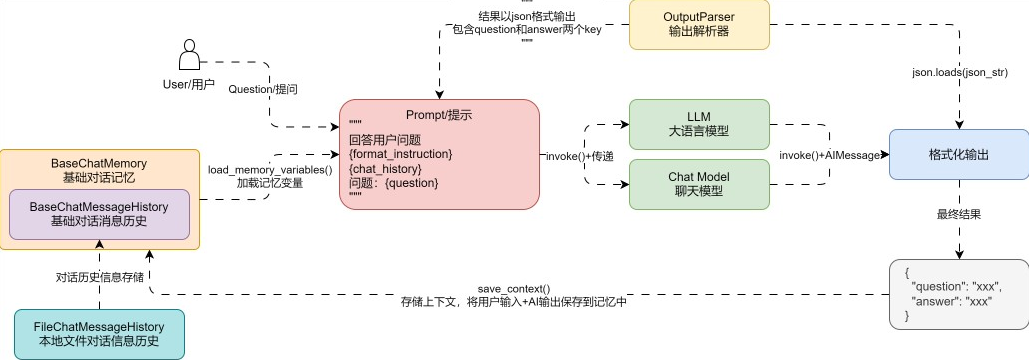
实现代码:
def debug(self, app_id: UUID):
# 1.提取从接口中获取的输入
req = CompletionReq()
if not req.validate():
return validate_error_json(req.errors)
# 2.创建prompt与memory
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个强大的聊天机器人,能根据用户的提问回复对应的问题"),
MessagesPlaceholder("history"),
("human", "{query}"),
])
memory = ConversationBufferWindowMemory(
k=3,
input_key="query",
output_key="output",
return_messages=True,
chat_memory=FileChatMessageHistory("./storage/memory/chat_history.txt"),
)
# 3.构建llm应用
llm = ChatOpenAI(model="gpt-3.5-turbo-16k")
# 4.创建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 5.调用链生成内容
chain_input = {"query": req.query.data}
content = chain.invoke(chain_input)
# 6.存储链状态
memory.save_context(chain_input, {"output": content})
return success_json({"content": content})


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









