







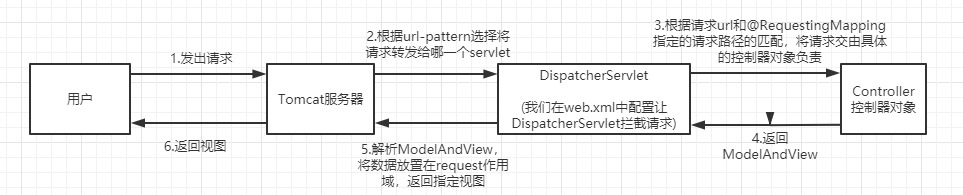
1.SpringMVC的执行流程:
1. Tomcat服务器启动
<load-on-startup>标签用于指定在服务器启动时加载该servlet以及加载顺序
<load-on-startup>1</load-on-startup>我们让DispatcherServlet随服务器启动而创建,由于DispatcherServlet是一个servlet,在创建时会执行其init()方法
在init()方法中,读取配置文件,创建了SpringMVC容器,描述性代码如下:
//读取配置文件 创建容器 实例化控制器对象
WebApplicationContext ctx = new ClassPathXmlApplicationContext("springmvc.xml");
// 将容器对象放入ServletContext中
getServletContext().setAttribute(key,ctx);
我们在配置文件中声明了组件扫描器
<!--声明组件扫描器-->
<context:component-scan base-package="com.zzt.Controller"/>于是在容器创建时,就会将扫描到的那些组件类实例化,并将实例化对象放入容器中。
2.SpringMVC的请求处理流程
我们以01的代码为例,简单展示一下SpringMVC的请求处理流程:
2.配置视图解析器
在01中,我们初步构建了一个SpringMVC的项目,但是这个项目存在一个问题。对于web项目,webapp下的所有页面用户是有权访问的,如果用户知道了请求最后返回的页面,就可以直接访问,但是这种访问没有意义,甚至有时候存在危害:

然而用户是没有权利直接访问WEB-INF下的文件,因此我们一般会将页面放置在WEB-INF下,这又导致了新的问题,我们的框架如果将请求转发过去呢?
此时我们需要修改视图路径,这样就保证了我们无法从外部直接访问:
modelAndView.setViewName("/WEB-INF/view/show.jsp");那么视图解析器是个什么玩意儿?我们可能会把很多页面都放在/WEB-INF/view/目录下,但是每个视图都要写一遍实在太麻烦;也有可能我们的页面都采用.jsp。换句话说,所有的视图都符合/WEB-INF/view/xx.jsp,那么实际上用于区分页面的就是xx部分,剩下的相同的前缀(/WEB-INF/view/)和后缀(.jsp)我们可以固定,直接拼接出页面的路径即可。
<!--配置视图解析器-->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/view/"/>
<property name="suffix" value=".jsp"/>
</bean>当我们配置了视图解析器之后,我们就无需指定全路径,只需要指定视图的逻辑名,视图解析器会帮我们拼凑出完整的视图路径:prefix + 逻辑名 + suffix。
modelAndView.setViewName("show");















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









