







hadoop 集群 3.2 搭建过程其实很简单。
- hadoop 官网地址:https://hadoop.apache.org/releases.html
选择自己想要的版本,我第一次搭建用的是2.7.5,虽然也搭建出来了,但是在web管理页面没有看到文件管理的相关按钮:
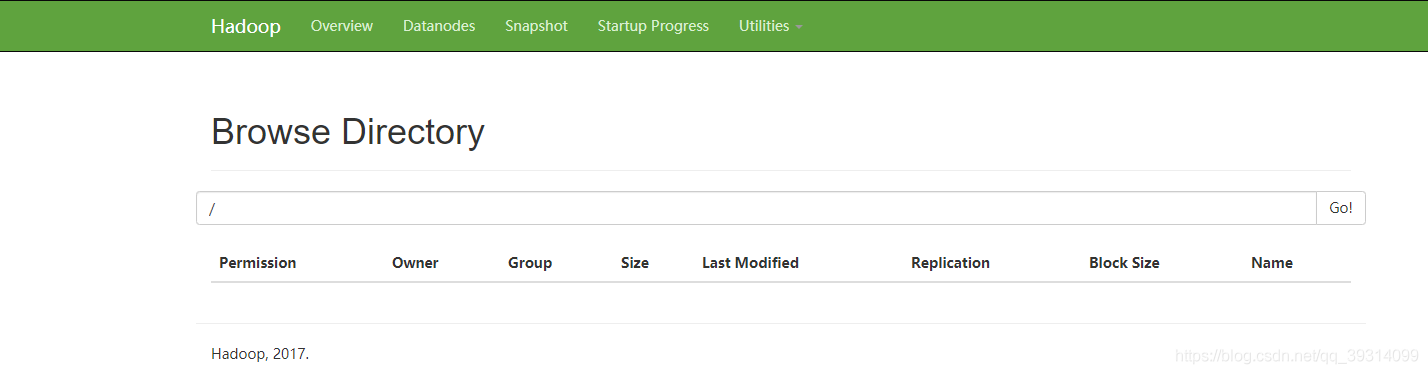
自我感觉不完美,后来看同事的集群,页面访问是有相关按钮的:

所以仔细对比了下配置文件,并未发现有什么异同,唯一不同的是版本不同,他用的是3.0版本,而我是2.7.5,索性重新装一个高版本的试下,下面是过程:
我的集群是三台机器:
| hostname | ip | 主节点namenode | 从节点datanode |
| CentOS121 | 192.168.18.121 | true | true |
| CentOS122 | 192.168.18.122 | false | true |
| CentOS123 | 192.168.18.123 | false | true |
(基础知识不再科普,有需要自行查阅资料)
首先声明:我并不会关闭防火墙,防火墙的存在是为了保护系统,我觉得开着还是有必要的。
准备工作(三台机器都需要做):
- 防火墙:大多数的教程都是先关闭防火墙,其实不关闭也是可以实现的,新建一个防火墙富规则即可,使三台机器相互信任。
在CentOS121上需要如此配置,信任另外两台机器(另外两台同理): firewall-cmd --permanent --add-rich-rule='rule family=ipv4 source address=192.168.18.122/24 accept' firewall-cmd --permanent --add-rich-rule='rule family=ipv4 source address=192.168.18.123/24 accept' 如此可实现内部通信畅通,无需再关闭防火墙。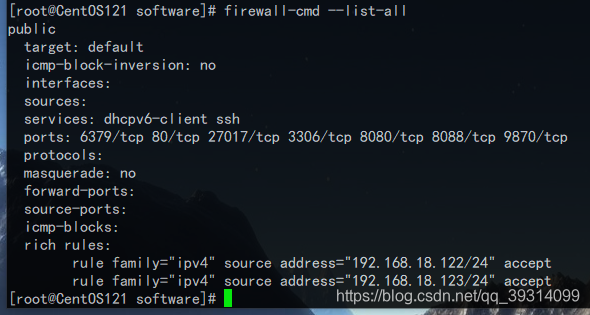
-
hostname(修改后需重启机器):
vim /etc/hostname
-
ssh免密登录:参见我另一篇博客:https://blog.csdn.net/qq_39314099/article/details/103503870
- 开放namenode网页web访问端口:9870(2.7.5版本是50070)
firewall-cmd --zone=public --add-port=9870/tcp --permanent
firewall-cmd --reload- 另外,java环境需要提前配好。
将下载后的压缩包上传到linux中,或者用wget直接下载也可。
然后解压,我的目录是/usr/local/software/hadoop。
然后配置环境变量,关于环境变量我认为放在/etc/profile.d/下是比较合适的,新建一个自己的sh脚本文件:
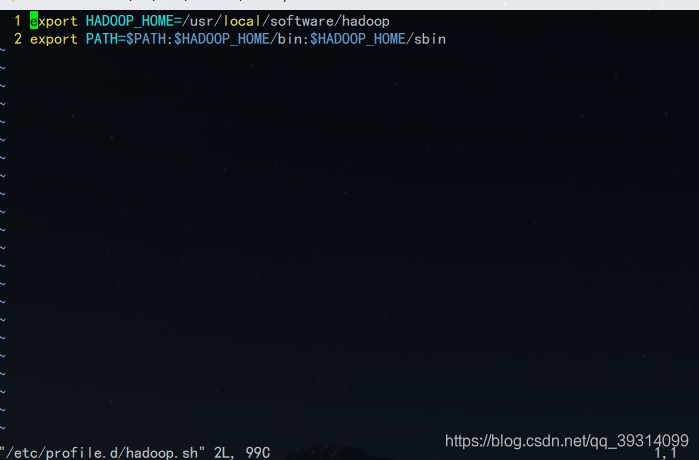
然后使配置文件生效,
source /etc/profile如果此处操作成功,可以查看hadoop版本:
hadoop version
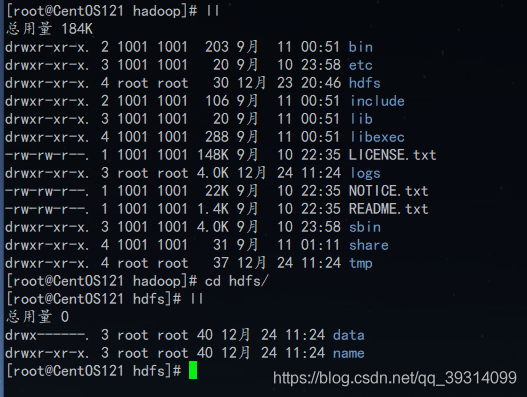
- 首先在hadoop安装目录下建立几个文件夹:
假设当前在hadoop安装目录下:
mkdir tmp 用来存储临时文件
mkdir -p hdfs/name 作为namenode的数据目录
mkdir hdfs/data 作为datanode的数据目录最终的结构是这样的:
- 接下来配置核心的几个配置文件:
|
|
|
|
|
|
进入hadoop安装目录下,进入hadoop目录下的etc/hadoop目录,这五个文件都存放于这个目录下。
- core-site.xml:核心配置文件中指定默认文件系统和临时文件目录。
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://CentOS121:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/software/hadoop/tmp</value> </property> </configuration> - hdfs-site.xml:关于hdfs存储系统相关配置。
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>CentOS121:50090</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/software/hadoop/hdfs/name</value> <final>true</final> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/software/hadoop/hdfs/data</value> <final>true</final> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> </configuration>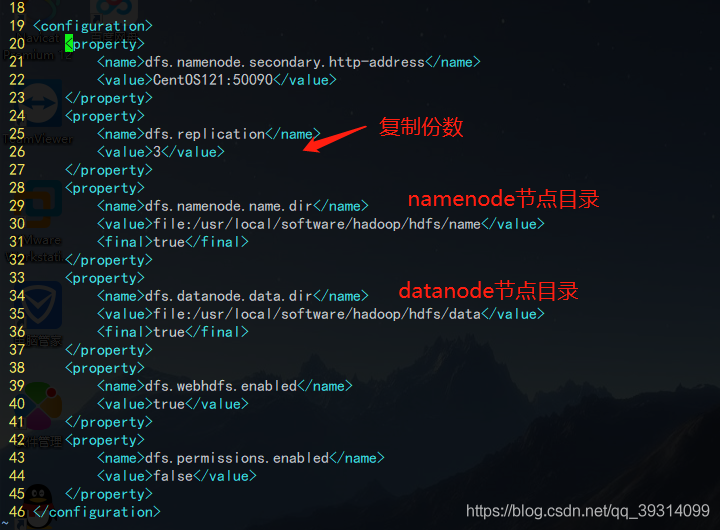
-
mapred-site.xml:MapReduce的相关配置项。
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>CentOS121:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>CentOS121:19888</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/software/hadoop/etc/hadoop, /usr/local/software/hadoop/share/hadoop/common/*, /usr/local/software/hadoop/share/hadoop/common/lib/*, /usr/local/software/hadoop/share/hadoop/hdfs/*, /usr/local/software/hadoop/share/hadoop/hdfs/lib/*, /usr/local/software/hadoop/share/hadoop/mapreduce/*, /usr/local/software/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/software/hadoop/share/hadoop/yarn/*, /usr/local/software/hadoop/share/hadoop/yarn/lib/* </value> </property> </configuration>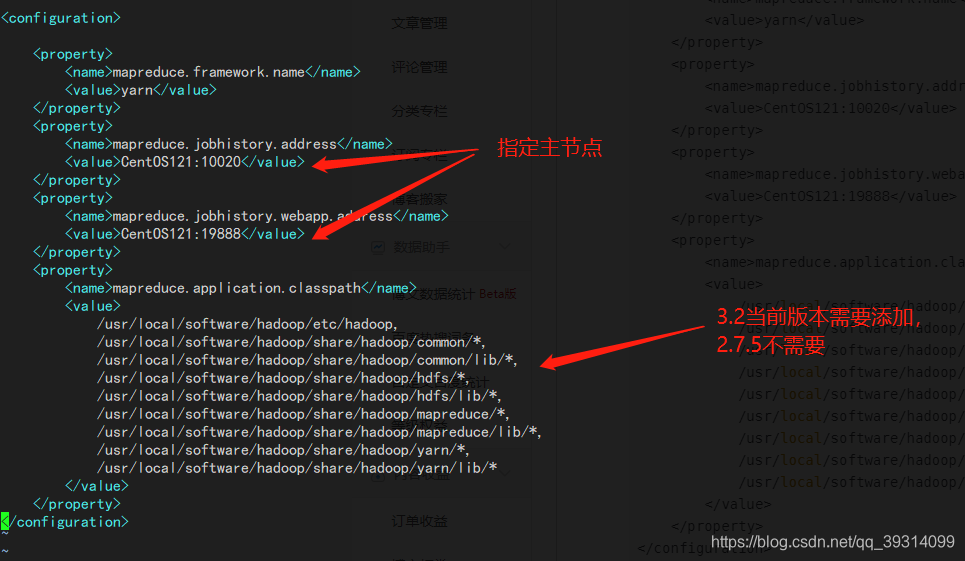
-
yarn-site.xml:yarn相关配置。
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>CentOS121:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>CentOS121:8030</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>CentOS121:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>CentOS121:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>CentOS121:8088</value> </property> </configuration>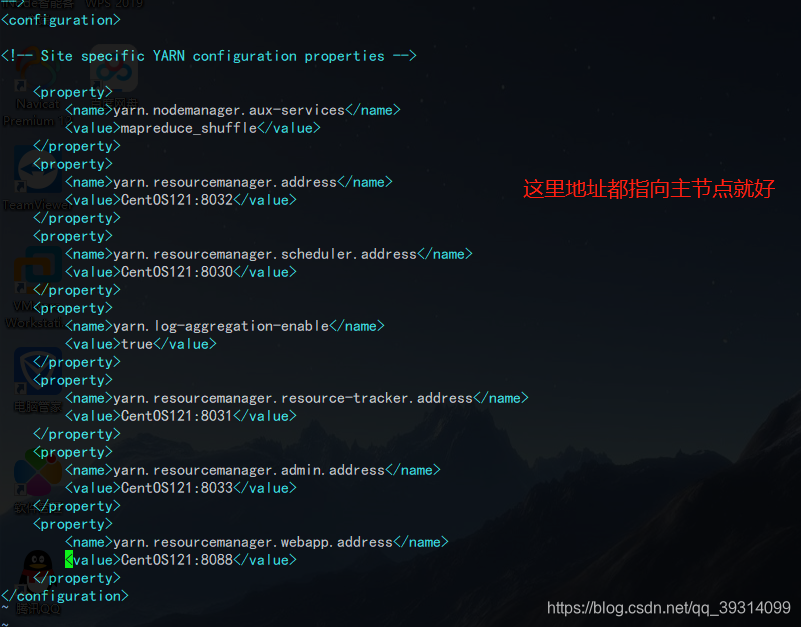
-
workers(2.7.5版本为slaves):用以指定datanode从节点。
CentOS121 CentOS122 CentOS123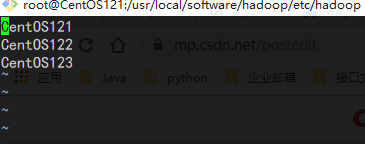
-
hadoop-env.sh:(3.2需要配置,2.7.5只需要配置java_home)
# java_home若已配过,这里可以直接引用,否则应配置完整jdk路径 export JAVA_HOME=${JAVA_HOME} # 安装用的是root用户,所以这里都设置为root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root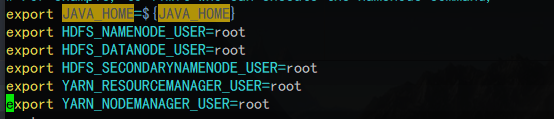
配置完成,然后将整个hadoop文件夹分发到另外两个机器上,用scp命令即可:
scp -r hadoop/ CentOS122:/usr/local/software/
scp -r hadoop/ CentOS123:/usr/local/software/
然后将环境变量等配置好- 接下来格式化namenode:
hdfs namenode -format这个操作需要在主节点进行。成功的话会看到成功格式化的日志:
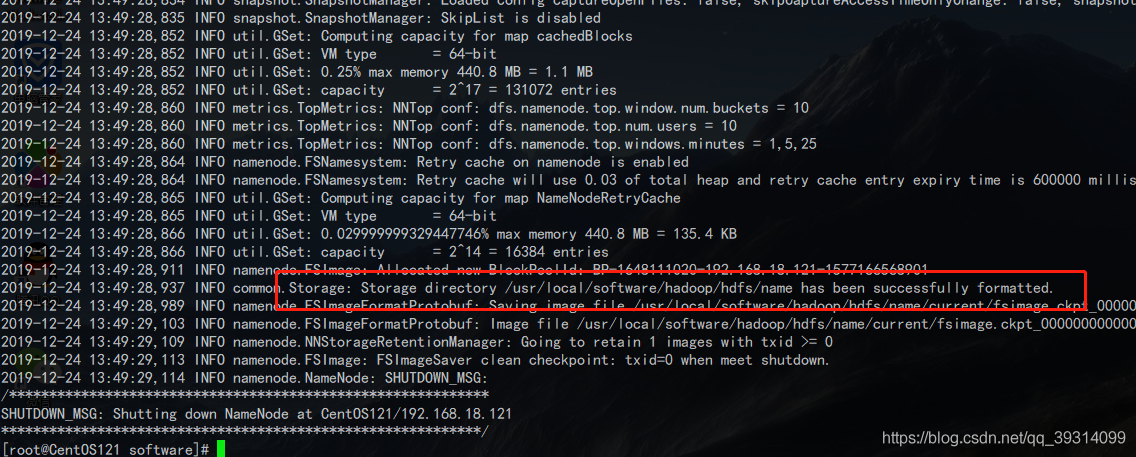
-
启动hadoop,可以单独启动,也可以用hadoop提供的脚本一次性都启动:
hadoop/sbin/start-all.sh启动成功的话可以看到如下日志,分别用 jps 命令查看三个机器:
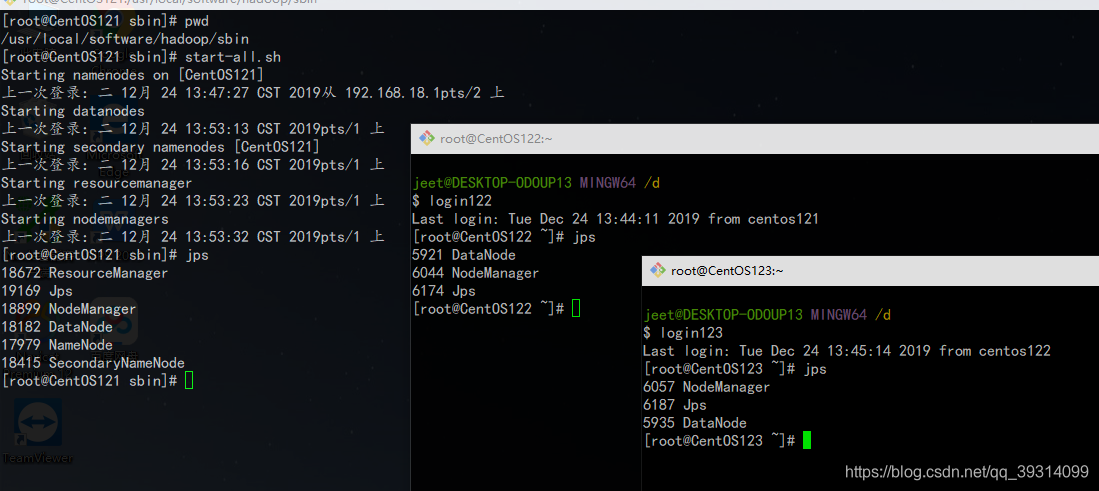
-
验证:访问页面。访问namenode主节点端口为9870,

-
访问yarn管理界面:这里也可以看到三个节点成功起来了。
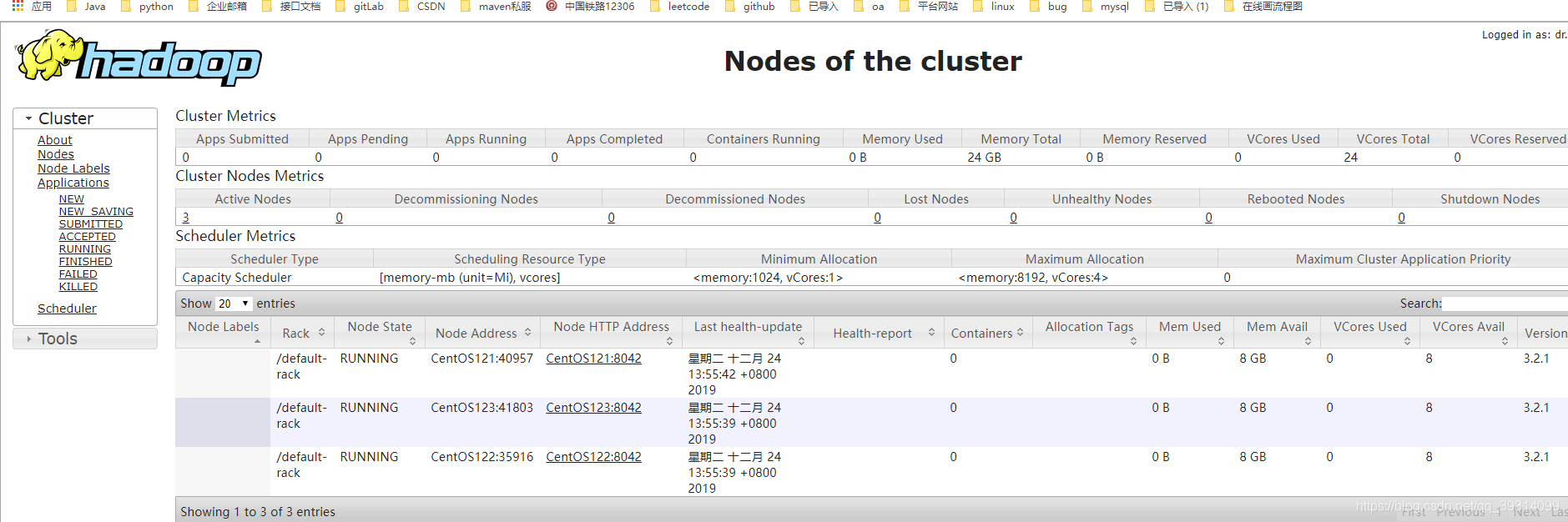
接下来看看hdfs文件系统,并用python连接。
简单的一个写入csv文件,并读取的过程:
# -*- coding: utf-8 -*-
import pandas as pd
import hdfs
_author_ = 'luwt'
_date_ = '2019/12/18 18:20'
hdfs_user = 'root'
hdfs_addr = 'http://192.168.18.121:9870'
client = hdfs.InsecureClient(hdfs_addr, user=hdfs_user)
df = pd.read_csv("D:\\Data.csv")
print(df)
hdfs_path = '/test/a.csv'
client.write(hdfs_path, df.to_csv(index=False), overwrite=True, encoding='utf-8')
read = client.read(hdfs_path, encoding='utf-8')
with read as reader:
for row in reader:
print(row)运行成功:
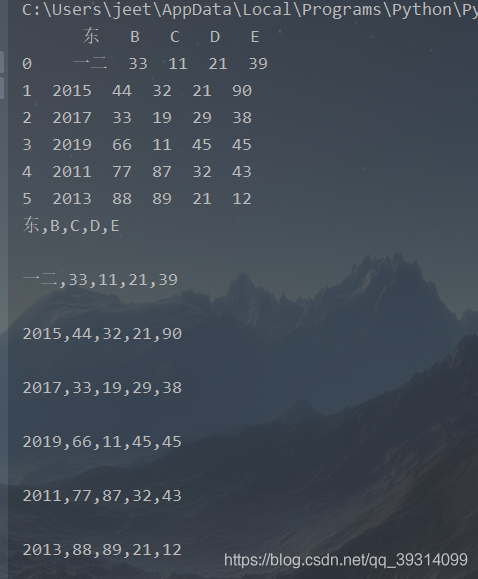
接着查看web页面:

大功告成。














 3073
3073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









