







安装grafana
**
拉取镜像grafana镜像 docker pull grafana/grafana
启动grafana:`
version: '3'
services:
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
ports:
- 3000:3000
privileged: true
environment:
- TZ=Asia/Shanghai
volumes:
# - /opt/grafana/defaults.ini:/etc/grafana/grafana.ini
- /data/grafana:/var/lib/grafana
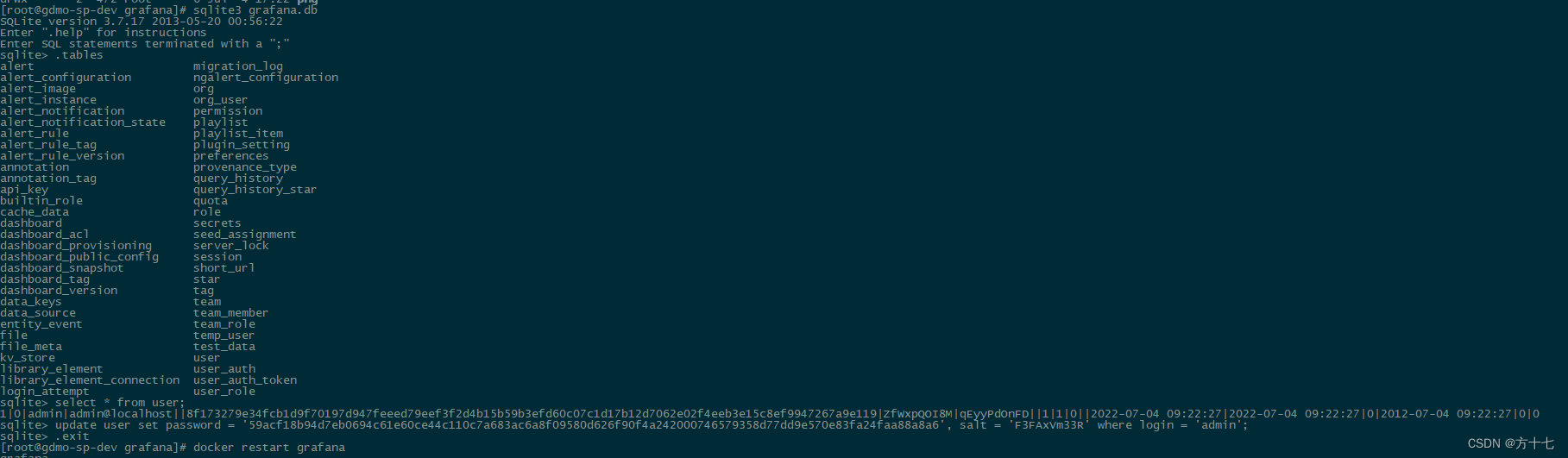
要是忘记grafana密码,可以这样操作:
sqlite3 /usr/local/docker/grafana
.tables
select * from user;
update user set password = '59acf18b94d7eb0694c61e60ce44c110c7a683ac6a8f09580d626f90f4a242000746579358d77dd9e570e83fa24faa88a8a6', salt = 'F3FAxVm33R' where login = 'admin';
docker restart grafana

验证一下:ip+端口(我这里就是172.25.10.89:3000)
(注意:打开grafana页面,默认用户名密码都是admin,初次登录会要求修改默认的登录密码)
1.添加prometheus数据源:
2.选择Prometheus

3.填写数据源设置项:url处填写Prometheus服务所在的ip地址,此处我们将prometheus服务与grafana安装在同一台机器上(ip+端口)
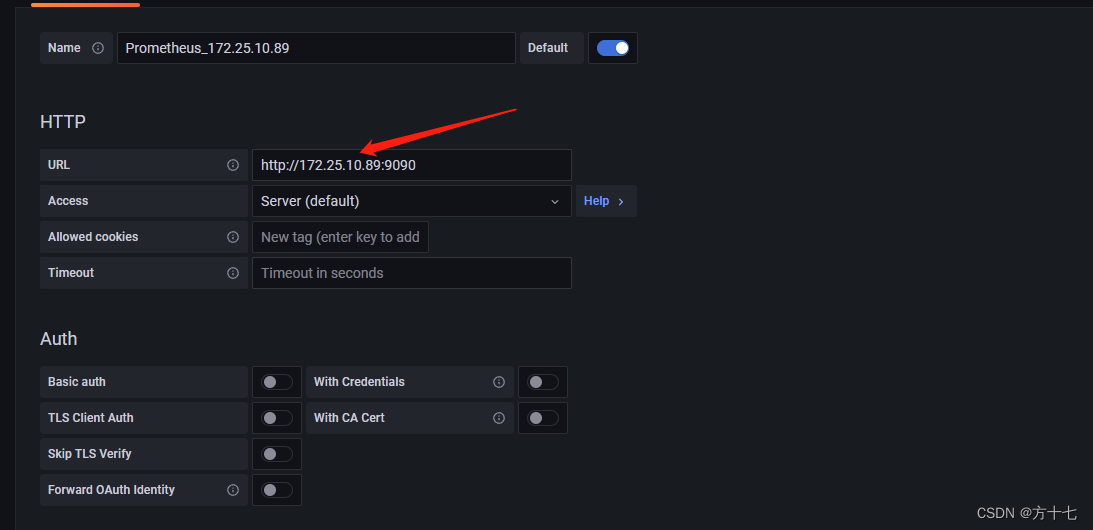
这边有个注意事项如下:
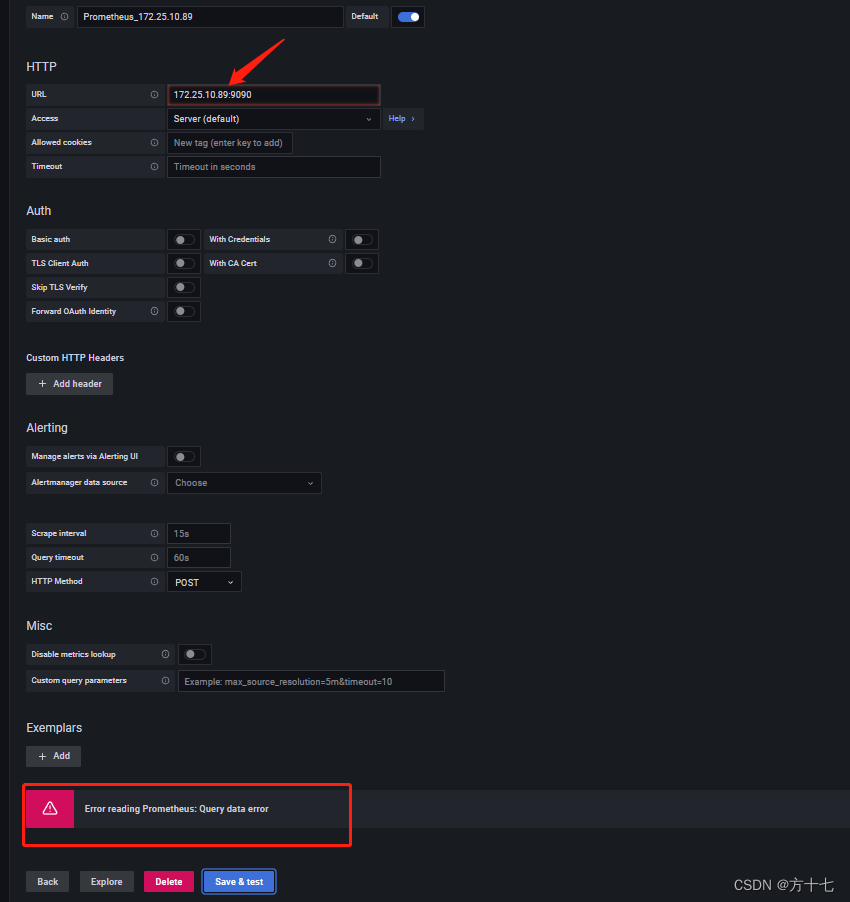
直接就是ip:端口号可能会校验不通过出现报错Error reading Prometheus: Query data error,
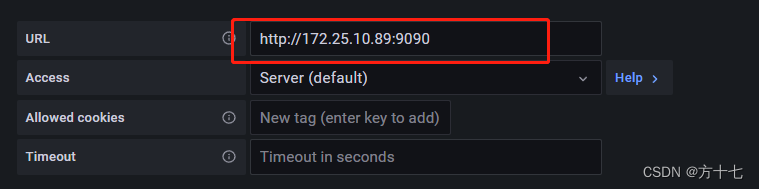
解决办法就是前面加上http://ip:端口号
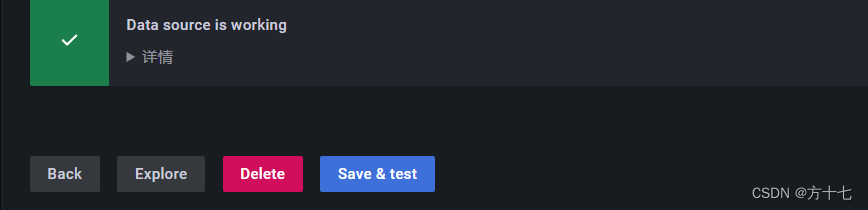
这样数据查询就是通过,出现如下界面:
4.Dashboards页面选择“Prometheus 2.0 Stats”,点击Dashboards选项卡,选择Prometheus 2.0 Stats,然后再import进去就可以了。

5.查看监控,点击grafana图标,切换到grafana主页面,然后点击Home,选择我们刚才添加的Prometheus 2.0 Stats,即可看到监控数据。
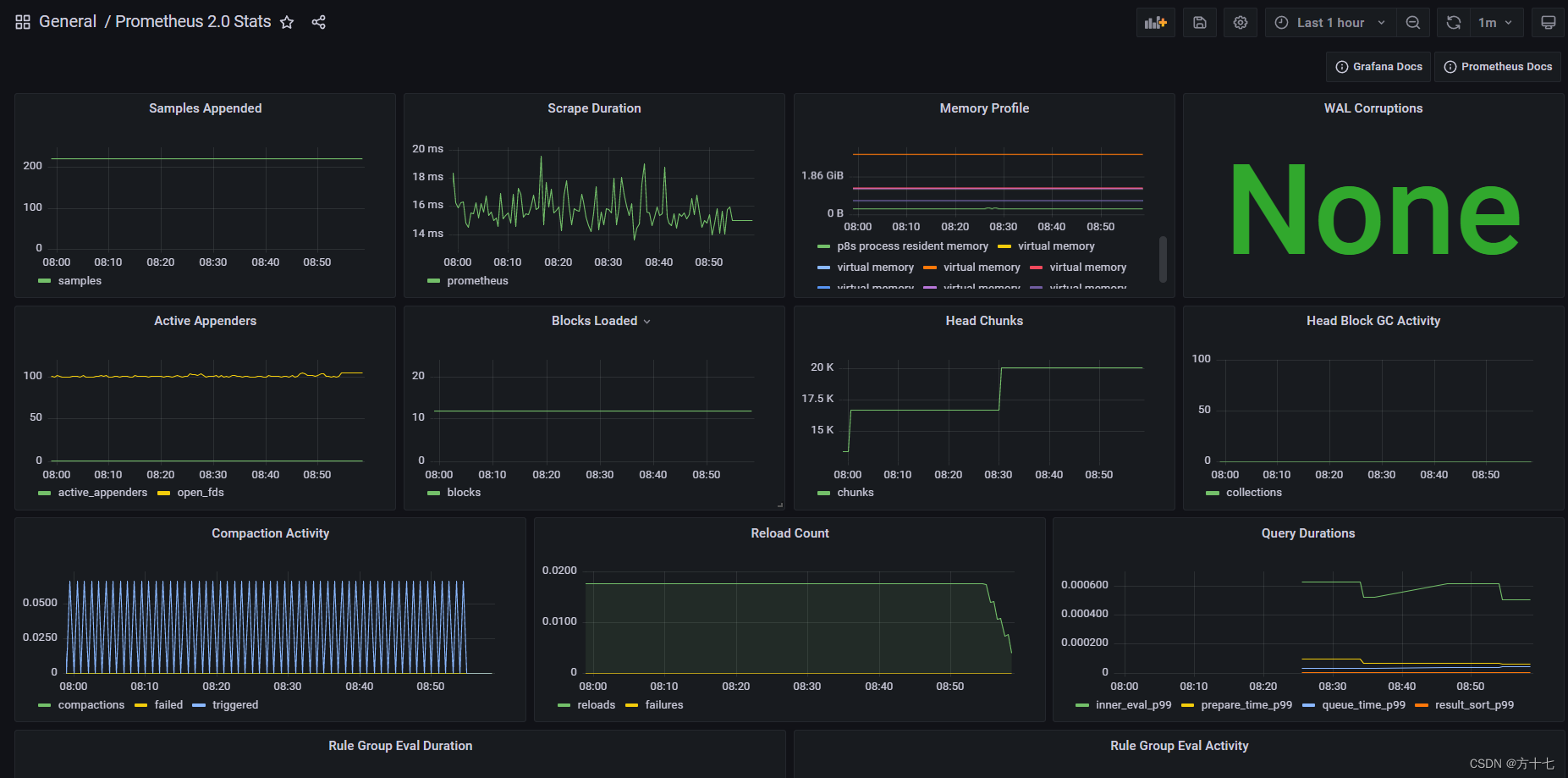
到这里web界面的监控就部署完成了。
**
安装alertmanager
**
prometheus的告警方式有好几种方式,在这里选择邮箱的告警方式,出现bug会及时发送邮件告知。
拉取镜像:docker pull prom/alertmanager
启动alertmanager:docker run -d --name alertmanger -p 9093:9093 -v /usr/local/docker/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml --restart=always prom/alertmanager
验证一下:ip+端口号
在 cd /usr/local/docker/下面执行如下命令:
mkdir alertmanager
cd alertmanager/
touch alertmanager.yml
mkidr rules
touch node-up.yml
1.运行alertmanager容器并编写alertmanager.yml
#global:全局配置。设置报警策略,报警渠道等;
#route:分发策略;
#receivers:接收者,指定谁来接收你发送的这些信息;
#inhibit_rules:抑制策略。当存在于另一组匹配的警报,抑制规则将禁用于一组匹配的警报
# 一个inhibition规则是在与另一组匹配器匹配的警报存在的条件下,使匹配一组匹配器的警报失效的规则。两个警报必须具有一组相同的标签。
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
# 定义路由树信息
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 10s # 在发送新警报前的等待时间
repeat_interval: 1m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称
# 定义警报接收者信息
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxx@163.com'
send_resolved: true # 这行的作用是,当容器恢复正常后,也会发送一份邮件
# 全局配置项
global:
resolve_timeout: 5m #处理超时时间,默认为5min
smtp_smarthost: 'smtp.126.com:25' # 邮箱smtp服务器代理
smtp_from: 'xxxx@163.com' # 发送邮箱名称
smtp_auth_username: 'xxxxxx@163.com' # 邮箱名称
smtp_auth_password: 'xxxxxx@' # 邮箱密码或授权码
2.设置alertmanager报警规则
node-up.yml
groups:
-name: node-up #设置报警的名称
rules:
- alert: node-up
expr: up{job="prometheus"} == 0 #该job必须和Prometheus的配置文件中job_name完全一致
for: 2m # 满足告警条件持续时间多久后,才会发送告警
labels:
severity: 1 #一级警告
team: node
annotations: # 解析项,详细解释告警信息
summary: "{{ $labels.instance }} has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
3.关联到prometheus
改动----> alertmanager:ip+端口号 ;报警规则文件路径映射
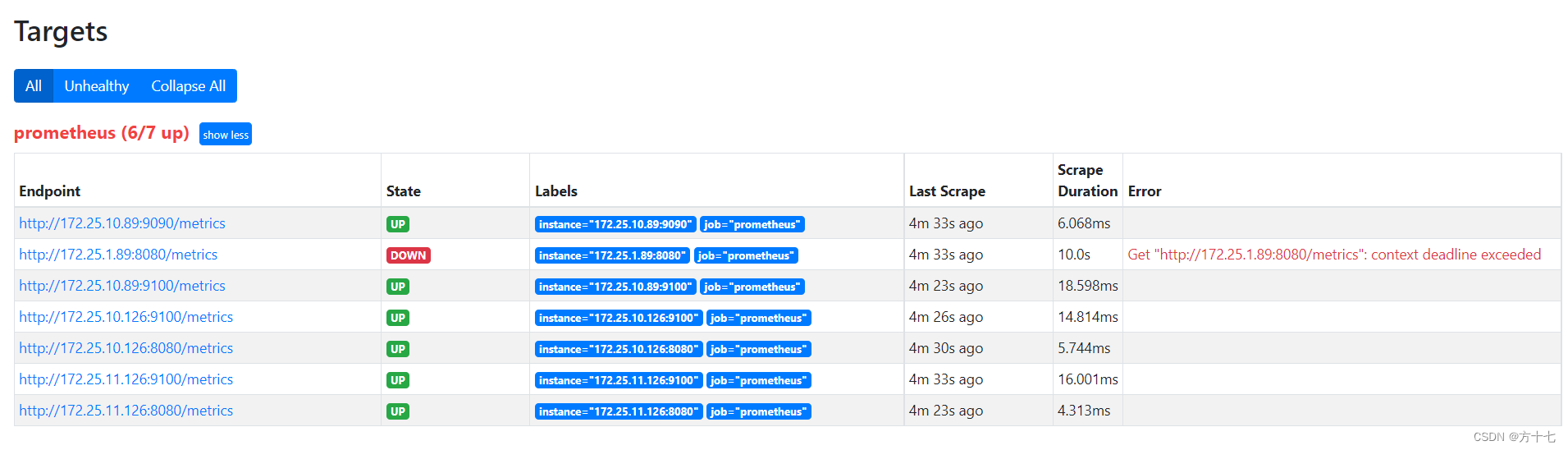
至此,如果prometheus页面中的target有down掉的容器,那么就会给你的邮箱发送报警信息。当容器正常后,它还会给你反馈。
**
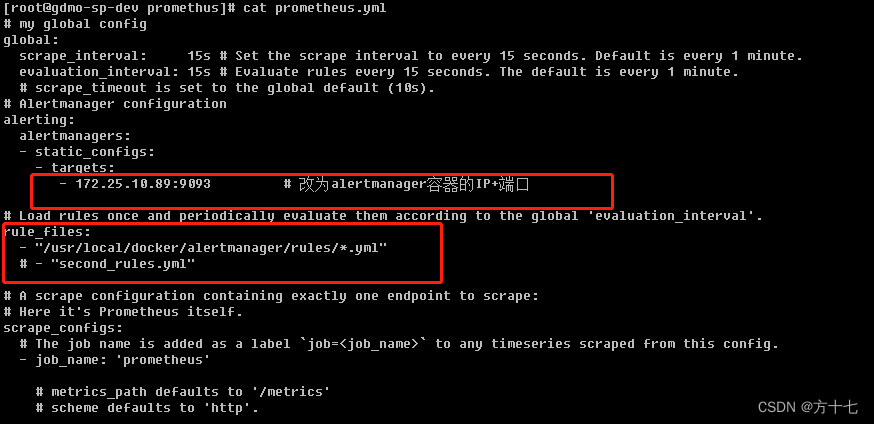
模拟触发告警机制:
**
手动修改prometheus.yml文件导致机器down,如下图:


















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











