







文章目录
1 redis 存储结构
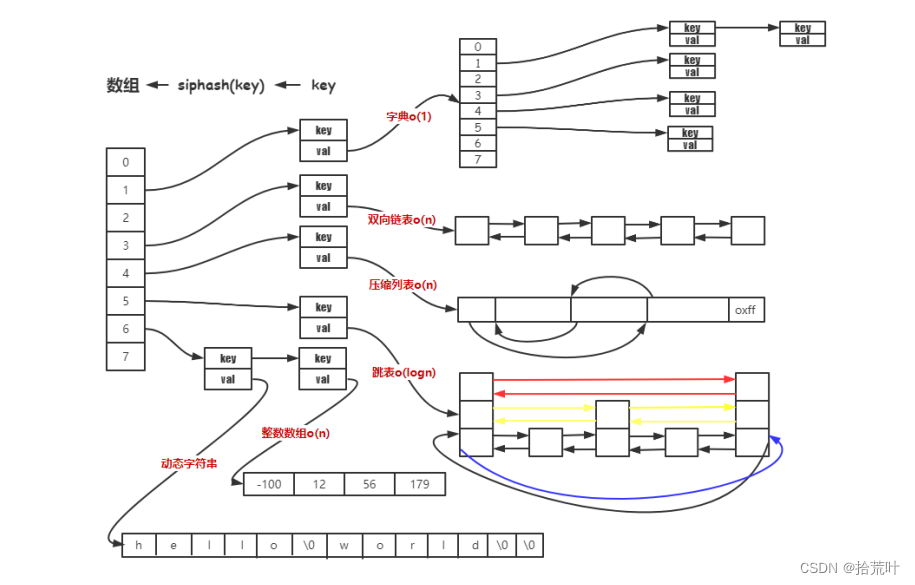
1.1 redis 存储结构大致框架
1.3 部分的redis源码展示说明
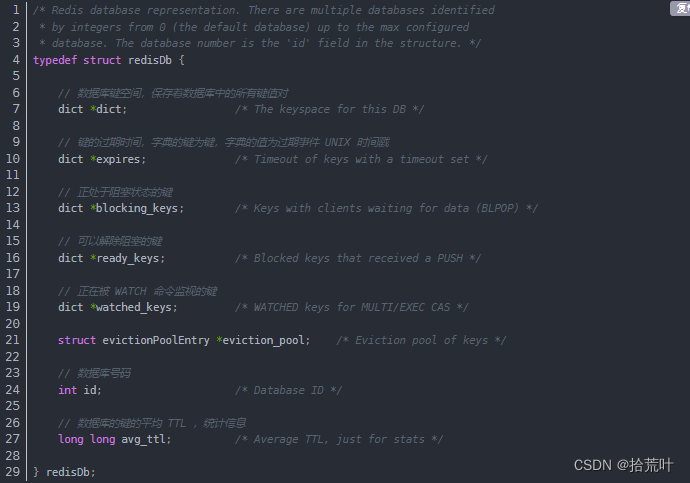
redis中数据库的结构定义

16个数据库由一个数据库对象指针管理,在redis-server的时候,dbnum默认值是16
2 redis 存储转换

此图已经概括了redis中五种数据类型的全部底层数据结构的划分和存储转换
3 redis的底层数据结构描述
3.1 string
3.1.1 int
字符串长度小于等于20 ,并且能够转成整数。
string 数据类型有一个位图的功能,但是存储位图数据用的是raw 或者是embstr,原因是因为 raw 和embstr 是sds动态字符串,能够节约内存。当然int 是4个字节也是可以用作32位的位图,但是其大小固定比较单一。
3.1.2 raw
raw 也是string的底层数据结构,当字符串的长度大于44时,底层使用raw结构,需要分配两次内存空间(分别为 Redis Object 和 SDS 分配空间)。
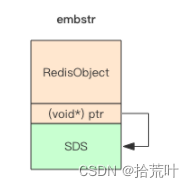
3.1.3 embstr
当字符串长度小于44时,底层使用
只分配一次内存空间(因为 Redis Object 和 SDS 是连续的)。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
struct __attribute__ ((__packed__)) hisdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
当字节数小于44时,分配的大小一直都是64个字节
sizeof(struct redisObject) = 16;
sizeof(hisdshdr8) = 3;
还有一个\0 一个字节
64 - sizeof(struct redisObject) - sizeof(hisdshdr8) -sizeof(“\0”) =44;
因此44 作为raw和embstr的分界点。
3.2 list
3.2.1 quicklist 双向链表
这个不做多个解释
3.2.2 ziplist 压缩列表
这个在list只是间接的使用
ziplist压缩列表详情
ziplist存储是连续的内存空间,可以做压缩。当设计计算时,ziplist明显会比双向链表的指针检索慢,因此ziplist是牺牲时间换取空间的结构。list的底层采取的是压缩列表加双向链表的存储结构,quicklist 为了存储更多的数据,会对每个 quicklistNode 节点进行压缩,这样就可以有效的存储更多的消息队列或者文章的数据了。
当实现为双向链表时,节点会有pre和next指针,每一个指针占8个字节。而ziplist的entry中,用previous_entry_length保存上一个entry的长度,当上一个entry长度小于等于263字节时,previous_entry_length只占一个字节;大于263字节时,previous_entry_length占5个字节,并且ziplist存储是连续的内存空间,可以做压缩。当设计计算时,ziplist明显会比双向链表的指针检索慢,因此ziplist是牺牲时间换取空间的结构
列表的典型使用场景有以下两个:
消息队列:列表类型可以使用 rpush 实现先进先出的功能,同时又可以使用 lpop 轻松的弹出(查询并删除)第一个元素,所以列表类型可以用来实现消息队列;
文章列表:对于博客站点来说,当用户和文章都越来越多时,为了加快程序的响应速度,我们可以把用户自己的文章存入到 List 中,因为 List 是有序的结构,所以这样又可以完美的实现分页功能,从而加速了程序的响应速度。
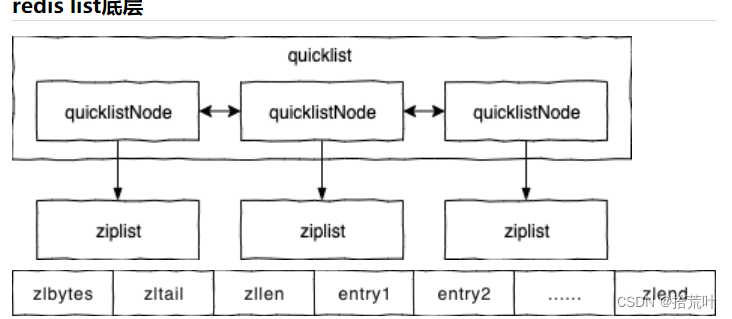 zlbytes:压缩列表字节长度,占 4 字节;
zlbytes:压缩列表字节长度,占 4 字节;
zltail:压缩列表尾元素相对于起始元素地址的偏移量,占 4 字节;
zllen:压缩列表的元素个数;
entryX:压缩列表存储的所有元素,可以是字节数组或者是整数;
zlend:压缩列表的结尾,占 1 字节。
3.3 hash
3.3.1 dict(字典)
typedef struct dict {
dictEntry **table;
dictType *type;
unsigned long size;
unsigned long sizemask;
unsigned long used;
void *privdata;
} dict;
table :hash指针数组
type: 所以dictType通过函数指针的方式,将不同数据类型的操作都封装起来。从面相对象的角度来看,可以把dictType当成dict中各种数据类型相关操作的interface,各个数据类型只需要实现其对应的数据操作就行
size:hash 数组的大小 通常是2的n次方
sizemask:size-1 一般用作&
used:已经存储的数据个数
其中dictEntry就是对dict中每对key-value的封装,除了具体的key-value,其还包含一些其他信息,具体如下:
typedef struct dictEntry {
void *key;
union { // dictEntry在不同用途时存储不同的数据
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // hash冲突时开链,单链表的next指针
} dictEntry;
3.3.2 压缩列表
上面已经讲过。当hash的数据结构中字节数量大于等于512时且字符串长度小于等于64,hash的数据类型才会用压缩列表这个数据结构。
3.4 set
3.4.1 insert 整形数组
元素都为整数且节点数量小于等于512时用整形数组
3.4.2 dict 字典
元素有一个不为整数 或者节点数量大于512 用dict
3.5 zset
3.5.1 skiplist 跳表(后期会专门出一篇博客介绍跳表结构)
节点数量大于128 或者字符串长度大于一64
3.5.2 ziplist
节点数量小于128且字符串长度小于64
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









