







Flink是什么
Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算,同时是一款流批一体的数据处理引擎。
Flink分布式环境搭建
下载地址:http://archive.apache.org/dist/flink/
使用的版本是flink-1.9.1-bin-scala_2.11.tgz 。
Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。对于 Local 模式来说,JobManager 和 TaskManager 会共用一个 JVM 来完成 Workload。如果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者 Yarn Cluster。
系统要求:Java 1.8.x或者更高即可,分布式模式需要配置ssh免密码登录。
1. Local
解压 flink-1.9.1-bin-scala_2.11.tgz
添加进环境变量
启动bin/start-cluster.sh
停止bin/stop-cluster.sh
5. 访问web界面
然后在浏览器中访问默认8081端口即可http://:8081
2. Standalone Cluster
在解压,配置环境变量的基础上
Flink配置
在conf/flink-conf.yaml文件中:
jobmanager.rpc.address: bigdata01 # jobManager通信地址
taskmanager.numberOfTaskSlots: 4 # taskManager的slot个数
rest.port: 8081
jobmanager.archive.fs.dir: hdfs://ns1/flink/jobs/
historyserver.web.address: bigdata02
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://ns1/flink/jobs/
historyserver.archive.fs.refresh-interval: 10000
其次,修改conf/master文件
bigdata01:8081
最后,修改conf/slaves,添加work二节点的ip/host
一般情况下,JobManager只需要配置一个,Worker可配置一个或多个。

最后,scp拷贝上述的flink安装目录到各个节点中,尽量保证在相同目录中。
启动Flink
启动集群:
在JobManager节点上启动,bin/start-cluster.sh
同样,要想进行暂停操作,bin/stop-cluster.sh。
单节点启动方式JobManager/TaskManager
添加JobManager
bin/jobmanager.sh (start cluster)|stop|stop-all
添加TaskManager
bin/taskmanager.sh start|stop|stop-all
eg. flink-1.1.2]# bin/taskmanager.sh start
3. Standalone HA
首先,我们需要知道Flink有两种部署的模式,分别是Standalone以及Yarn Cluster模式。对于Standalone来说,Flink必须依赖于Zookeeper来实现 JobManager的HA(Zookeeper已经成为了大部分开源框架HA必不可少的模块)。在 Zookeeper的帮助下,一个Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于Standby状态。当工作中的 JobManager失去连接后(如宕机或 Crash),Zookeeper会从Standby中选举新的 JobManager 来接管Flink集群。
对于Yarn Cluster模式来说,Flink 就要依靠Yarn本身来对JobManager做HA了。其实这里完全是Yarn的机制。对于Yarn Cluster模式来说,JobManager和 TaskManager都是被Yarn启动在Yarn的Container中。此时的JobManager,其实应该称之为Flink Application Master。也就说它的故障恢复,就完全依靠着Yarn 中的ResourceManager(和MapReduce的AppMaster 一样)。
安装过程
在standalone的基础之上修改修改配置文件flink-conf.yaml、masters。
- flink-conf.yaml
high-availability: zookeeper
high-availability.storageDir: hdfs://ns1/flink/ha/
high-availability.zookeeper.quorum: bigdata01:2181,bigdata02:2181,bigdata03:2181
high-availability.zookeeper.path.root: /flink-ha ## 新增
high-availability.cluster-id: /ha-cluster ## 新增
- masters
bigdata01:8081
bigdata02:8081 - 同步资源
(三)启动失败解决
4. Flink On Yarn
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的Workload。因此Flink也支持在Yarn上面运行。首先,让我们通过下图了解下Yarn 和Flink的关系。

第一:有两种方式进行Flink On Yarn的配置。
(一)内存集中管理模式(不建议)
在Yarn中初始化一个Flink集群,开辟指定的资源,之后我们提交的Flink Job都在这个Flink yarn-session中,也就是说不管提交多少个job,这些job都会共用开始时在yarn中申请的资源。这个Flink集群会常驻在Yarn集群中,除非手动停止。
- 步骤一:执行$FLINK_HOME/bin/yarn-session.sh 开启资源
$FLINK_HOME/bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 -d
参数解释:
-n 2 表示指定两个容器
-jm 1024 表示jobmanager 1024M内存
-tm 1024表示taskmanager 1024M内存
-d 任务后台运行
-nm,–name YARN上为一个自定义的应用设置一个名字
-q,–query 显示yarn中可用的资源 (内存, cpu核数)
-z,–zookeeperNamespace 针对HA模式在zookeeper上创建NameSpace
-id,–applicationId YARN集群上的任务id,附着到一个后台运行的yarn session中
启动成功

查看web页面:http://bigdata02:8081,因为此时jobManager是Yarn中的一个进程,所以每次启动yarn-session.sh的时候,地址都会发生变化。
yarn cluster集群信息:
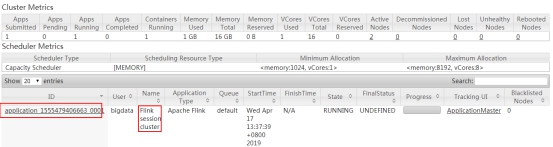
步骤二:运行flink-job
bin/flink run examples/batch/WordCount.jar -input hdfs://ns1/data/hello -output hdfs://ns1/out/wordcount/

HA验证:
杀死bigdata02的YarnSessionClusterEntrypoint,会在bigdata03上面自动启动一个新的YarnSessionClusterEntrypoint进程来作为JobManager。
(二)内存Job管理模式
在Yarn中,每次提交job都会创建一个新的Flink集群,任务之间相互独立,互不影响并且方便管理。任务执行完成之后创建的集群也会消失。
第二种模式其实也分为两个部分,依然是开辟资源和提交任务,但是在Job模式下,这两步都合成一个命令了。
[bigdata@bigdata01 flink]$ bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 examples/batch/WordCount.jar -input hdfs://ns1/data/hello -output hdfs://ns1/out/result-wc.txt















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









