








Spring IOC 一系列文章下来,我们已经了解了整个spring IOC 核心refresh 方法的全部内容,这个方法名我是每篇文章都有提到,一定要记住。本次就聊一下IOC 的最后一个知识点:循环依赖的问题。
什么是循环依赖?
很多小伙伴都在各种渠道听到过“循环依赖”这个词,也应该有一定了解,但是我这里还是要重新在具体描述一下循环依赖的概念。
循环依赖是指:在spring IOC 容器初始化的时候,记住是初始化,不是实例化,上篇文章IOC流程解析-实例化和初始化 就已近说过了spring 对于bean 的实例化和初始化是分开的,一定要记住这里是指初始化,也就是为bean 对象属性赋值的是时候,如果目前初始化的对象A,其中有一个属性对象B,那么这里就会先去加载注册对象B,但是如果B中又有属性对象A,但是A目前还在初始化过程,这样就会形成了循环依赖。
简单描述就是:A 对象加载B 对象的时候,B 对象反过来需要加载A 对象。甚至可以再加多个中间对象,比如加一个C 对象,那么这就是A 对象加载B 对象的时候,B 对象需要加载C 对象,而C 对象又需要加载A 对象。只要形成加载循环,那么就会存在循环依赖的问题。
Spring是如何解决循环依赖的
这里就开始本次文章的重点,Spring 是如何解决循环依赖的,关于这点刚刚不是也说了嘛,循环的形成一定是初始化对象的时候,那么我们就还需要回到上篇文章说的doCreateBean 方法中去看。
先说一下Spring 解决循环依赖的结论,带着结论去看会更容易一点,结论只有两点:
- 解决循环依赖,需要将实例化和初始化过程分离,也就说如果是构造器注入的话,是无法解决循环依赖的
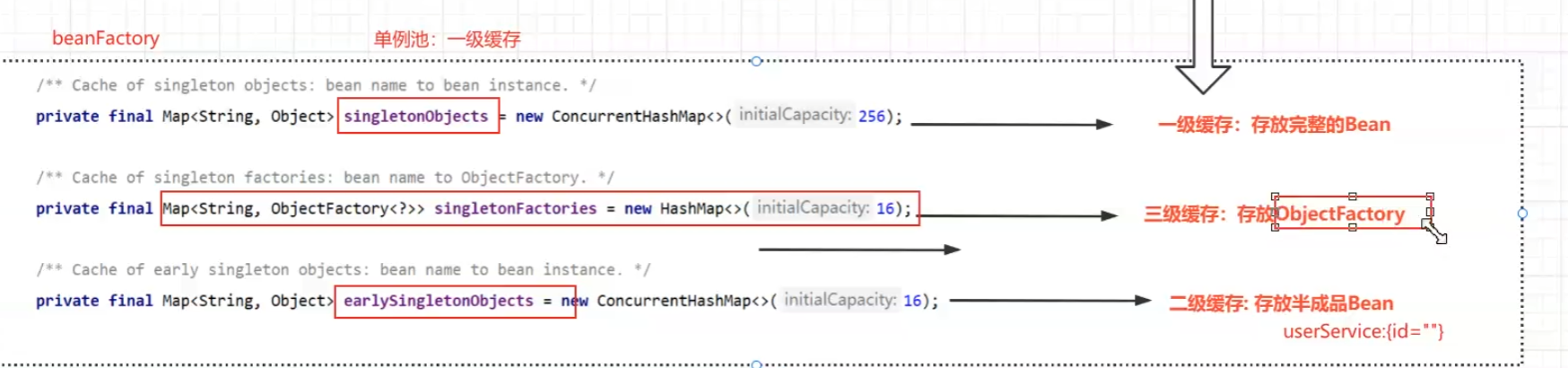
- 利用一、二、三级缓存去解决。为什么不用一个或者两个缓存解决呢,因为一个解决不了(一级缓存是单例池,也就说这个缓存是不可避免的,只用单例池缓存是无法解决循环依赖的),两个无法做到最优。
那么问题又来了,什么是一、二、三级缓存呢,看图。有一点需要记住,这里是BeanFactory 中。
获取完整对象的方法-doCreateBean方法
doCreateBean 方法我们之前已经解析过了,下面的内容我们就直接定位具体到具体的方法调用就行,不再重复流程,有不懂的小伙伴可以看上篇文章。
实例化后的缓存添加
直接定位到缓存添加的内容。
首先这里就会获取当前对象的配置信息,然后判断是否需要添加缓存,这基本上没有都是默认配置,都能通过判断,直接调用addSingletonFactory 方法,注意这里有一个入参是我们上篇文章说的函数方法,也就是ObjecFactory 函数接口的调用,跟上篇文章说的doCreate 调用一样,真正的调用时机是由addSingletonFactory 方法内容决定的。
// 7.判断是否需要提早曝光实例:单例 && 允许循环依赖 && 当前bean正在创建中
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 8.提前曝光beanName的ObjectFactory,设置三级缓存,用于解决循环引用
// xximpl implements ObjecFactory{ getObject(){getEarlyBeanReference(beanName, mbd, bean)} }
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
// ===> 8.1 getEarlyBeanReference:
// 应用后置处理器SmartInstantiationAwareBeanPostProcessor,允许返回指定bean的早期引用,若没有则直接返回bean
}
继续跟进addSingletonFactory 方法。
这里就是将入参的函数方法添加到三级缓存中,然后清除一下二级缓存。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 1.如果beanName不存在于singletonObjects缓存
if (!this.singletonObjects.containsKey(beanName)) {
// 2.将beanName和singletonFactory注册到singletonFactories缓存(三级缓存)(beanName -> 该beanName的单例工厂)
this.singletonFactories.put(beanName, singletonFactory);
// 3.移除earlySingletonObjects缓存中的beanName(beanName -> beanName的早期单例对象)
this.earlySingletonObjects.remove(beanName);
// 4.将beanName注册到registeredSingletons缓存(已经注册的单例集合)
this.registeredSingletons.add(beanName);
}
}
}
对象属性注入的流程
还是直接定位到其初始化内容中的属性填充方法-populateBean 方法中。为了下面方便阅读理解,我们代指第一个对象为A 对象、A 中需要注入的对象为B 对象。
然后我们直接找到最里层的调用resolveValueIfNecessary 方法中。这里在上篇文章就知道会判断需要注入属性的类型,然后再调用具体的赋值方法,上篇文章这后面我们就没有详细看了,现在我们定位到注入对象的判断中,跟进其resolveReference 方法中。
// 1. RuntimeBeanReference类型(ref:bean引用)
if (value instanceof RuntimeBeanReference) {
RuntimeBeanReference ref = (RuntimeBeanReference) value;
return resolveReference(argName, ref);
}
跟进resolveReference 方法。
这里就可以发现,对象的注入,其实还是调用beanFactory 的getBean 方法,又是跟之前一样的流程,getBean -> doGetBean -> createBean -> doCreateBean,注意目前这个getBean 的是B 对象,而B 对象在一级缓存,也就是单例池中是没有对应实例的,所以还是会走到这里,等于就是又会回到resolveReference 方法中,本次getBean 的就是A 对象了,这样才是形成了循环依赖。
resolvedName = String.valueOf(doEvaluate(ref.getBeanName()));
bean = this.beanFactory.getBean(resolvedName);
总结一下:对于A 对象中注入B 对象,就是A 对象初始化内容中属性注入的时候,调用getBean 获取B 对象的实例,然后注入回A 对象,也就是又调用getBean 获取A 对象的实例。
从三级缓存中获取依赖注入的半成品对象-getSingleton 方法
这里我们再次回到doGetBean 方法中,直接看到其第一步,从缓存中获取对象实例的方法getSingleton 方法,注意这个getBean 的是由B对象调用获取的A对象,也就是已经套了两次娃了。
跟进getSingleton 方法。
首先是从一级缓存中获取对象实例,如果没有其实例,那么久会走判断是否该对象真正创建中。
注意前两次我们这里都没有走进,因为getBean(A) 的时候A 对象是第一次走进来,所以没有进,而A 对象调用getBean(B) 的时候,B 对象也是第一次走进来,还是没有进判断,只有这个B 对象再次调用getBean(A) 的时候,A 对象就是已经在创建中了,所以判断通过。
这里判断当前Bean 是否正在被创建的依据就是,上篇文章说的doCreateBean 在被调用之前添加singletonsCurrentlyInCreation 集合。
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 1.从单例对象缓存(1级缓存)中获取beanName对应的单例对象
Object singletonObject = this.singletonObjects.get(beanName);
// 2.如果单例对象缓存(1级缓存)中没有,并且该beanName对应的单例bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
然后继续看下代码,这里会再次判断单例对象为空,并该对象允许循环引用,也就是支持循环依赖的解决,这个不配置的情况下,都是true。
// 4.如果在早期单例对象缓存中(二级缓存)也没有,并且允许创建早期单例对象引用
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
继续,再从一级缓存获取,如果没有,再去二级缓存中获取,这里相当于一个重试机制,都没有的情况下,才会去获取三级缓存中存储的函数方法(这个所谓的函数方法,一般情况下都称之为:Lambda表达式)
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
// 6.从单例工厂缓存中(一级缓存)获取beanName的单例工厂
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// 再次从二级缓存中获取,重复校验
singletonObject = this.earlySingletonObjects.get(beanName);
// 为null
if (singletonObject == null) {
// 6.再从单例工厂缓存中(三级缓存)获取beanName的单例工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
当获取到Lambda 表达式后,就是具体getObject 调用了,然后将返回的实例对象存入二级缓存,注意这里是二级缓存,因为当前对象还是不完整对象,不能放入一级缓存中,并将三级缓存储的lambda 表达式移除。最后还要将得到的对象返回,再次重申,这里得到的是不完整的A 对象。
if (singletonFactory != null) {
// 7.如果存在单例对象工厂,则通过工厂创建一个单例对象
singletonObject = singletonFactory.getObject();
// 8.将通过单例对象工厂创建的单例对象,放到早期单例对象缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
// 9.移除该beanName对应的单例对象工厂,因为该单例工厂已经创建了一个实例对象,并且放到earlySingletonObjects缓存了,
// 因此,后续获取beanName的单例对象,可以通过earlySingletonObjects缓存拿到,不需要在用到该单例工厂
this.singletonFactories.remove(beanName);
}
return singletonObject;
三级存储的lambda表达式对应的生成不完整对象的方法-getEarlyBeanReference方法
这里还是得看上面节点:”实例化后的缓存添加“的内容,找打lambda 表达式对应的方法getEarlyBeanReference 方法。
跟进该方法。
这段代码的内容,可以说是非常的简单,因为在当前对象没有代理的情况下,是不进入第一个判断的,也就是说这里返回的,就是当时存储的A 对象,就是那个刚刚实例化完成后,没有经过初始化的A 对象。
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 1.如果bean不为空 && mbd不是合成 && 存在InstantiationAwareBeanPostProcessors
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// 2.应用所有SmartInstantiationAwareBeanPostProcessor,调用getEarlyBeanReference方法
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 3.允许SmartInstantiationAwareBeanPostProcessor返回指定bean的早期引用
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
// 4.返回要作为bean引用公开的对象,如果没有SmartInstantiationAwareBeanPostProcessor修改,则返回的是入参的bean对象本身
return exposedObject;
}
这样返回后就能在B 对象调用的getBean(A) 的时候,将仅仅只实例化的A 注入到B 对象当中,这个B 对象就能初始化完成了,同时也会返回到A 对象调用的getBean(B) 的内容中了,这样A 对象也就能初始化完成了。
这里有小伙伴就要问了,那B 对象中的A 对象属性不就是只有仅仅实例化的A 对象嘛,不然这里A 对象是放入了单例池当中,当A 注册单例池完成之后,B 对象中的A 对象属性是指向了完成后的A 对象,而不是指向实例化的A 对象。
还有小伙伴说二级缓存没有用,三级缓存就能搞定,是三级缓存是可以搞定,但是想一想,如果B 对象注入A 对象完成之后,再次注入一个C 对象,而C 对象又要注入A 对象,这样是不是就不用再走三级缓存了,而且目前我们是没有走lambda 表达式中的代理模式的,如果有的话,就是又会生成一个代理对象,所以三级缓存中存储的相当于是一个工厂,二级缓存存储的才是不完整对象。
就此Spring 就解决了循环依赖的问题。
总结
还是那句话Spring 解决循环依赖,就是靠的实例化和初始化分离,以及一、二、三级缓存,如果只存在两个缓存也能解决问题,但是会非常的复杂,又是判断对象是否是完整对象,还有判断代理对象重复加载之类的,三个缓存同时存在才是最优的解决方案。
就此Spring IOC 的内容算是已经全部完结了,主要就是核心方法的理解,一定要自己跟代码,不跟代码别人说再多,该不会还是不会。
最后祝各位小伙伴入坑快乐。
附录Spring 源码分析系列文章
| 时间 | 文章 |
|---|---|
| 2022-03-09 | Spring的基本概念和IOC流程的简述 |
| 2022-03-11 | IOC流程解析-BeanFactory的创建 |
| 2022-03-14 | IOC流程解析-BeanFactoyPostProcessor和BeanPostProcessor |
| 2022-03-15 | IOC流程解析-实例化和初始化 |
| 2022-03-17 | IOC流程解析-循环依赖 |















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









