







 本文介绍如何利用Apache POI库在Java中批量读取Word、Excel、PPT和TXT文件的内容及作者信息,包括配置Maven依赖、处理不同文件类型,并通过示例代码展示具体实现。
本文介绍如何利用Apache POI库在Java中批量读取Word、Excel、PPT和TXT文件的内容及作者信息,包括配置Maven依赖、处理不同文件类型,并通过示例代码展示具体实现。
Java使用POI提取word, Excel, PPt, txt的文本内容及文件属性中的作者
新公司实习的第一个任务,在网上查了一些博客后接触到了poi,它为Java提供API对Microsoft Office文件进行读写操作的功能。
可以在apache官网下载jar包http://poi.apache.org/download.html

查看API文档http://poi.apache.org/components/index.html
1、新建普通的maven项目
poi的jar包较多,于是选用maven仓库导入,先建一个普通的maven项目
然后next,再起项目名就可以了
2、在pom.xml里添加poi的依赖
在标签组里添加
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
3、提取word文本和作者
一开始只知道查看别人博客给出代码,但很多都跟自己需要的不一样,而且不完整、导包环境不一样等,总是不满意,搜索很花时间而且效果也不太好,于是试着直接去参考官网上给出的example
http://poi.apache.org/components/document/quick-guide.html
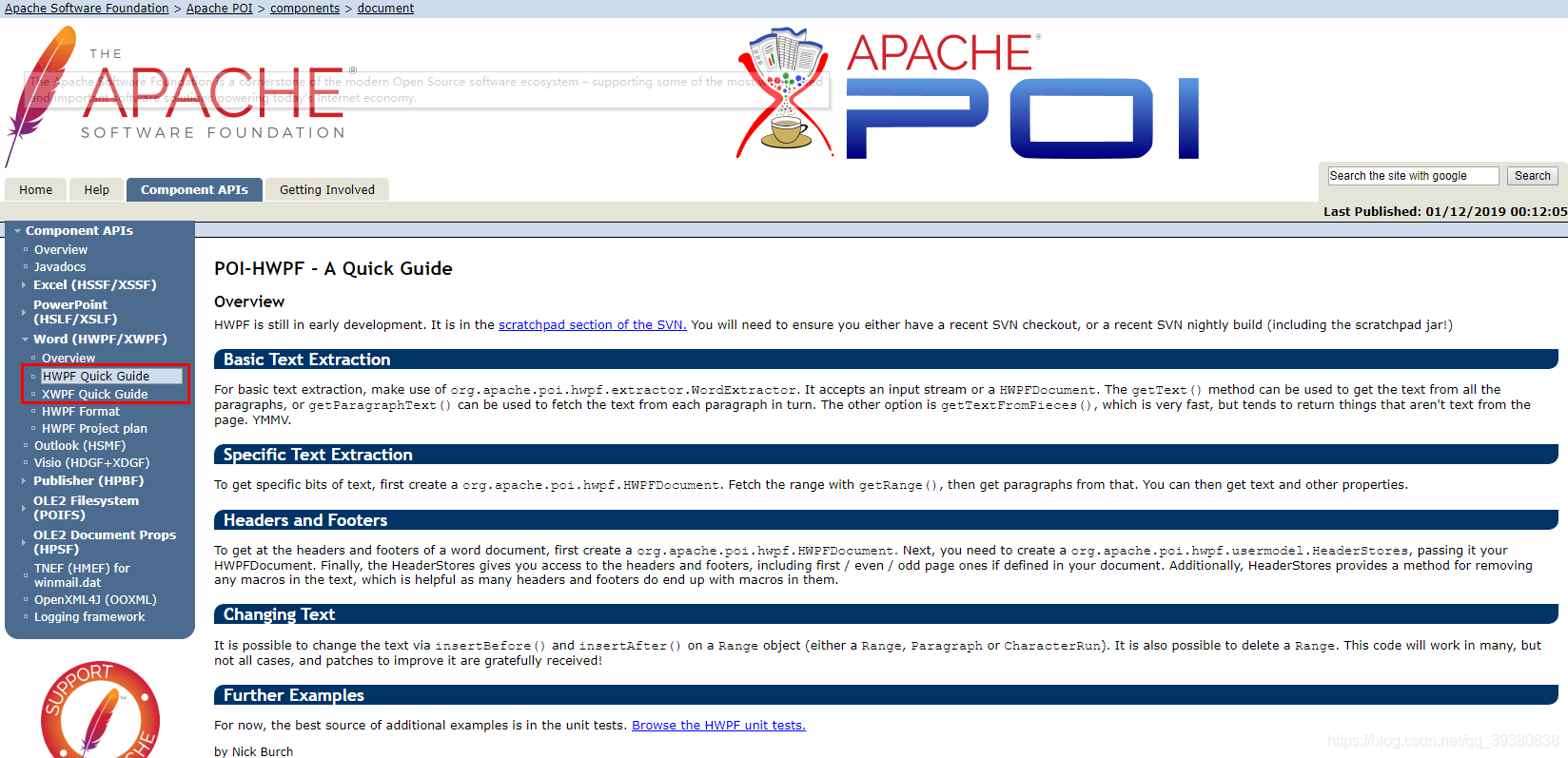
HWPF对应.doc类型的文件,XWPF对应.docx类型的文件,Excel、PPt也是类似的
import com.google.common.base.CharMatcher;
import com.google.common.collect.Lists;
import com.google.gson.Gson;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.extractor.WordExtractor;;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Arrays;
import java.util.List;
public class WordUtil {
public static String readWordFile(String path) {
List<String> contextList = Lists.newArrayList();
InputStream inputStream = null;
try {
inputStream = new FileInputStream(new File(path));
if (path.endsWith(".doc")) {
HWPFDocument document = new HWPFDocument(inputStream);
System.out.println("作者:"+document.getSummaryInformation().getAuthor());
WordExtractor extractor = new WordExtractor(document);
String[] contextArray = extractor.getParagraphText();
Arrays.asList(contextArray).forEach(context -> contextList.add(CharMatcher.whitespace().removeFrom(context)));
extractor.close();
document.close();
} else if (path.endsWith(".docx")) {
XWPFDocument document = new XWPFDocument(inputStream).getXWPFDocument();
System.out.println("作者:"+document.getProperties().getCoreProperties().getCreator());
List<XWPFParagraph> paragraphList = document.getParagraphs();
paragraphList.forEach(paragraph -> contextList.add(CharMatcher.whitespace().removeFrom(paragraph.getParagraphText())));
document.close();
} else {
//LOGGER.debug("此文件{}不是word文件", path);
return "此文件不是Word文件"+path;
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
//LOGGER.debug("读取word文件失败");
System.out.println("读取Word文件失败");
}
}
return new Gson().toJson(contextList);
}
}
使用了Google的Guava工具类去做集合和字符串操作,前提是在pom.xml里加上它的依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>24.0-jre</version>
</dependency>
使用了Google的gson把集合类转换成JSON类型(又好像是JavaBean类型),同样要添加依赖
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.2.4</version>
</dependency>
在代码中可以看到,使用了getSummaryInformation()去获得文档的摘要信息,再从摘要信息中获取需要的作者信息。
一开始不知道怎么使用poi获取作者信息,以为只要使用jdk的方法就能获取文件属性,但发现只能获取文件的基本属性,比如
Path testPath = Paths.get("E:\\test\\test1.xls");
FileOwnerAttributeView ownerView = Files.getFileAttributeView(testPath, FileOwnerAttributeView.class);
System.out.println("文件所有者:" + ownerView.getOwner());
BasicFileAttributes attrs = Files.readAttributes(testPath, BasicFileAttributes.class);
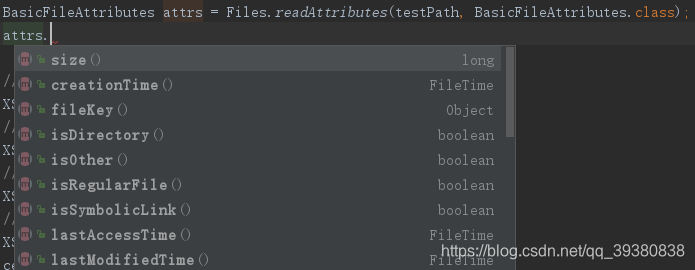
这些类和方法参考了Oracle上有关IO流的jdk文档
https://docs.oracle.com/javase/tutorial/essential/io/fileio.html
https://docs.oracle.com/javase/8/docs/api/java/nio/file/Files.html#getAttribute-java.nio.file.Path-java.lang.String-java.nio.file.LinkOption…-
然后又发现一个类似poi可以操作office文件的工具,Spire
https://www.e-iceblue.com/Download/doc-for-java-free.html
先添加依赖
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc.free</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
读取文档属性
Document doc = new Document("E:\\test\\test1.doc");
//读取内置文档属性
System.out.println("作者: " + doc.getBuiltinDocumentProperties().getAuthor());
但是没有看到java的XLS包,而且使用依赖导Presentation包时maven总是找不到对应的包,于是放弃了。想到同样是操作office类型的,那poi自己肯定也有类似获取文件属性的方法,就找到了如上代码中的,其他Office类型也类似。
4、提取Excel文本和作者
看到个好刘逼好想详细的POI Excel操作博客:https://www.cnblogs.com/huajiezh/p/5467821.html
import com.google.common.collect.Lists;
import com.google.gson.Gson;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class ExcelUtil {
public static String readExcelFile(String path){
List<List<String>> rowlist = Lists.newArrayList();
InputStream inputStream = null;
String str = "";
Workbook workbook = null;
try {
//获取文件输入流
inputStream = new FileInputStream(new File(path));
//获取Excel工作簿对象
if (path.endsWith(".xls")) {
workbook = new HSSFWorkbook(inputStream);
System.out.println("作者:" + ((HSSFWorkbook) workbook).getSummaryInformation().getAuthor());
}else if (path.endsWith(".xlsx")) {
workbook = new XSSFWorkbook(inputStream);
System.out.println("作者:" + ((XSSFWorkbook) workbook).getProperties().getCoreProperties().getCreator());
}
else {
//LOGGER.debug("此文件{}不是word文件", path);
return "此文件不是Excel文件" + path;
}
//得到Excel工作表对象
for (Sheet sheet : workbook ) {
for (Row row : sheet) {
//首行(即表头)不读取
if (row.getRowNum() == 0) {
continue;
}
List<String> cellList = Lists.newArrayList();
for (Cell cell : row) {
switch (cell.getCellTypeEnum()) {
case STRING:
cellList.add(cell.getRichStringCellValue().getString());
break;
case NUMERIC:
if (DateUtil.isCellDateFormatted(cell)) {
cellList.add(""+cell.getDateCellValue());
} else {
cellList.add(""+cell.getNumericCellValue());
}
break;
case BOOLEAN:
cellList.add(""+cell.getBooleanCellValue());
break;
case FORMULA:
cellList.add(cell.getCellFormula());
break;
case BLANK:
cellList.add("");
break;
default:
cellList.add("");
}
}
if (cellList.size() > 0)
rowlist.add(cellList);
}
}
Gson gson = new Gson();
str = gson.toJson(rowlist);
//关闭流
workbook.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (inputStream != null) try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
//LOGGER.debug("读取word文件失败");
System.out.println("读取Excel文件失败");
}
}
return str;
}
}
5、提取PPt文本和作者
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import com.google.common.collect.Lists;
import com.google.gson.Gson;
import org.apache.poi.hslf.usermodel.HSLFSlideShow;
import org.apache.poi.sl.usermodel.Shape;
import org.apache.poi.sl.usermodel.Slide;
import org.apache.poi.sl.usermodel.SlideShow;
import org.apache.poi.sl.usermodel.TextShape;
import org.apache.poi.xslf.usermodel.XMLSlideShow;
public class PPtUtil {
//直接抽取幻灯片的全部内容
public static String readPPtFile(String path) {
List<String> textList = Lists.newArrayList();
InputStream inputStream = null;
SlideShow ppt = null;
try {
//获取文件输入流
inputStream = new FileInputStream(new File(path));
if (path.endsWith(".ppt")) {
ppt = new HSLFSlideShow(inputStream);
System.out.println("作者:" + ((HSLFSlideShow)ppt).getSlideShowImpl().getSummaryInformation().getAuthor());
}else if (path.endsWith(".pptx")) {
ppt = new XMLSlideShow(inputStream);
System.out.println("作者:" + ((XMLSlideShow)ppt).getProperties().getCoreProperties().getCreator());
}
else {
//LOGGER.debug("此文件{}不是word文件", path);
return "此文件不是PPt文件" + path;
}
// get slides
List<Slide> slides = ppt.getSlides();
for (Slide slide : slides) {
List<Shape> shapes = slide.getShapes();
for (Shape sh : shapes) {
//如果是一个文本框
if (sh instanceof TextShape) {
TextShape shape = (TextShape) sh;
textList.add(shape.getText());
}
}
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (inputStream != null) try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
//LOGGER.debug("读取word文件失败");
System.out.println("读取PPt文件失败");
}
}
return new Gson().toJson(textList);
}
}
6、提取Txt文本和作者
import com.google.common.collect.Lists;
import com.google.gson.Gson;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.List;
public class TxtUtil {
public static String readTxtFile(String path) {
List<String> txtList = Lists.newArrayList();
FileReader fileReader = null;
BufferedReader bufferedReader = null;
try {
if (path.endsWith(".txt")) {
fileReader = new FileReader(path);
bufferedReader = new BufferedReader(fileReader);
String s = "";
while ((s = bufferedReader.readLine()) != null) {
txtList.add(s);
}
} else {
return "此文件不是Txt文件" + path;
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fileReader != null && bufferedReader != null) try {
fileReader.close();
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
//LOGGER.debug("读取word文件失败");
System.out.println("读取Txt文件失败");
}
}
return new Gson().toJson(txtList);
}
}
7、测试类
import poiUtils.ExcelUtil;
import poiUtils.PPtUtil;
import poiUtils.TxtUtil;
import poiUtils.WordUtil;
public class App
{
public static void main(String[] args ){
System.out.println("E:\\test\\test1.doc:"+new WordUtil().readWordFile("E:\\test\\test1.doc"));
System.out.println("E:\\test\\test1.docx:"+new WordUtil().readWordFile("E:\\test\\test1.docx"));
System.out.println("E:\\test\\test1.xls:"+new ExcelUtil().readExcelFile("E:\\test\\test1.xls"));
System.out.println("E:\\test\\test1.xlsx:"+new ExcelUtil().readExcelFile("E:\\test\\test1.xlsx"));
System.out.println("E:\\test\\test1.ppt:"+new PPtUtil().readPPtFile("E:\\test\\test1.ppt"));
System.out.println("E:\\test\\test1.pptx:"+new PPtUtil().readPPtFile("E:\\test\\test1.pptx"));
System.out.println("E:\\test\\test1.txt:"+new TxtUtil().readTxtFile("E:\\test\\test1.txt"));
}
}
输出结果:
作者:ying
E:\test\test1.doc:["文档内容","第一段","第二段"]
作者:ying
E:\test\test1.docx:["文档内容","第一段","第二段"]
作者:ying
E:\test\test1.xls:[["小王","男","19.0","Mon Nov 08 00:00:00 CST 1999","true"],["大王","女","20.0","Wed Nov 04 00:00:00 CST 1998","false"]]
作者:ying
E:\test\test1.xlsx:[["小王","男","19.0","Mon Nov 08 00:00:00 CST 1999","true"],["大王","女","20.0","Wed Nov 04 00:00:00 CST 1998","false"]]
作者:ying
E:\test\test1.ppt:["这个标题","这个内容"]
作者:ying
E:\test\test1.pptx:["这个标题","这个内容"]
E:\test\test1.txt:["txt内容","第二行","第三行"]

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









