






DolphinScheduler3.1.7
DolphinScheduler简介
Apache DolphinScheduler 是一个分布式易扩展的可视化DAG工作流任务调度开源系统。适用于企业级场景,提供了一个可视化操作任务、工作流和全生命周期数据处理过程的解决方案。
Apache DolphinScheduler 旨在解决复杂的大数据任务依赖关系,并为应用程序提供数据和各种 OPS 编排中的关系。 解决数据研发ETL依赖错综复杂,无法监控任务健康状态的问题。
DolphinScheduler 以 DAG(Directed Acyclic Graph,DAG)流式方式组装任务,可以及时监控任务的执行状态,支持重试、指定节点恢复失败、暂停、恢复、终止任务等操作。
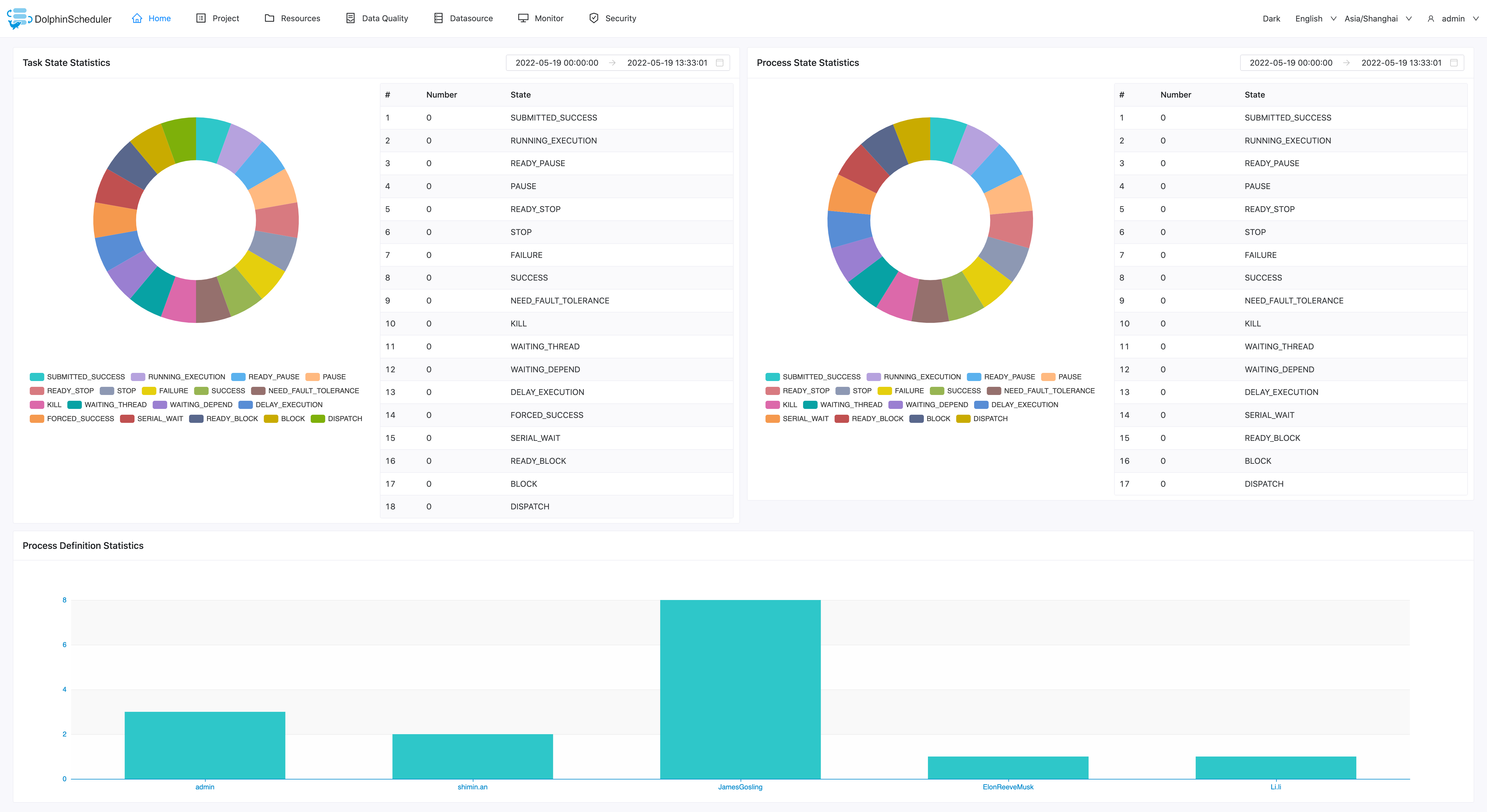
首页
Apache DolphinScheduler 首页可让您查看用户所有项目的任务状态统计、工作流状态统计和项目统计。 这是观察整个系统状态以及深入各个进程以检查任务和任务日志的每个状态的最佳方式。
项目管理
项目
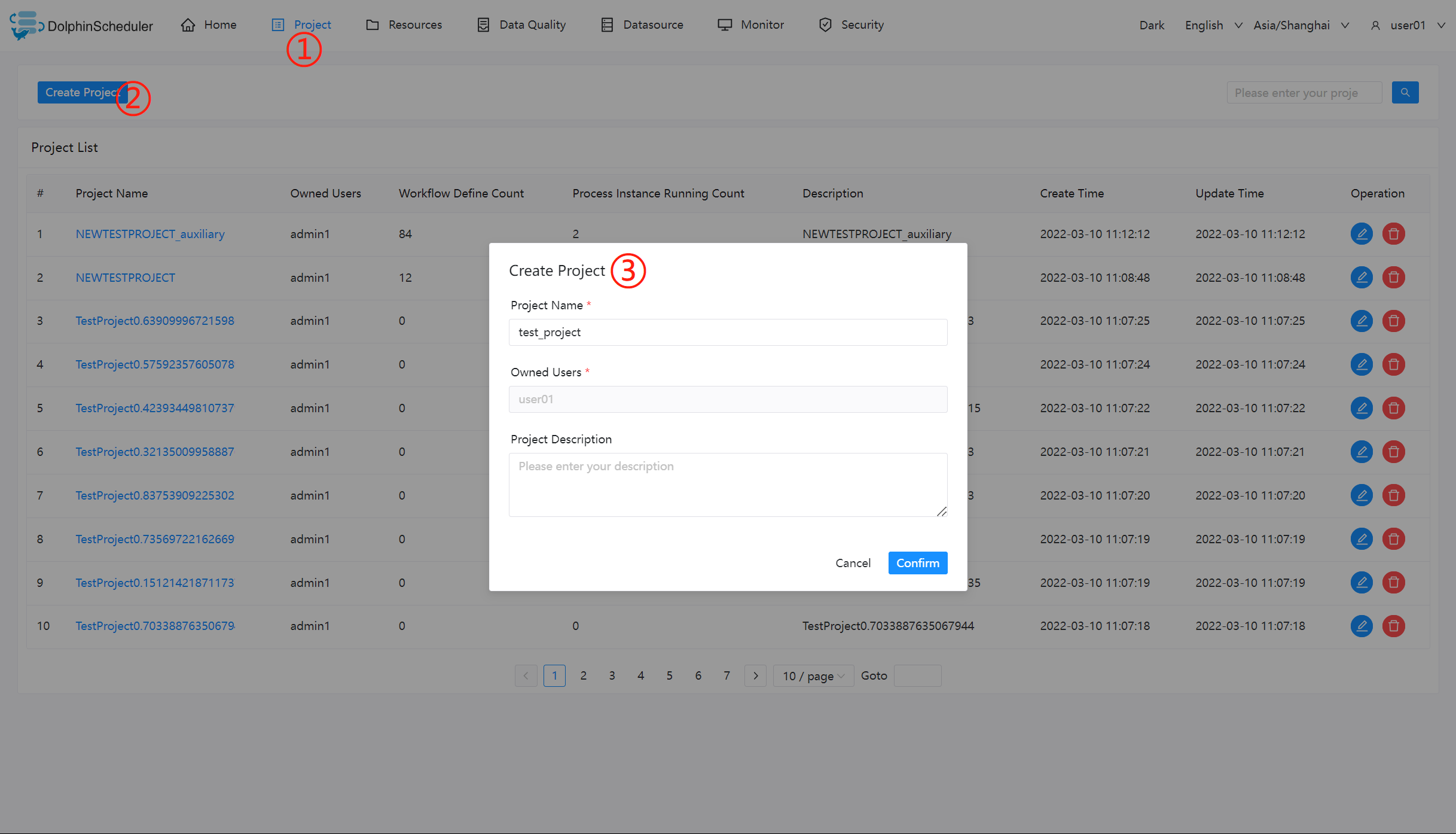
创建项目
点击"项目管理"进入项目管理页面,点击“创建项目”按钮,输入项目名称,项目描述,点击“提交”,创建新的项目。
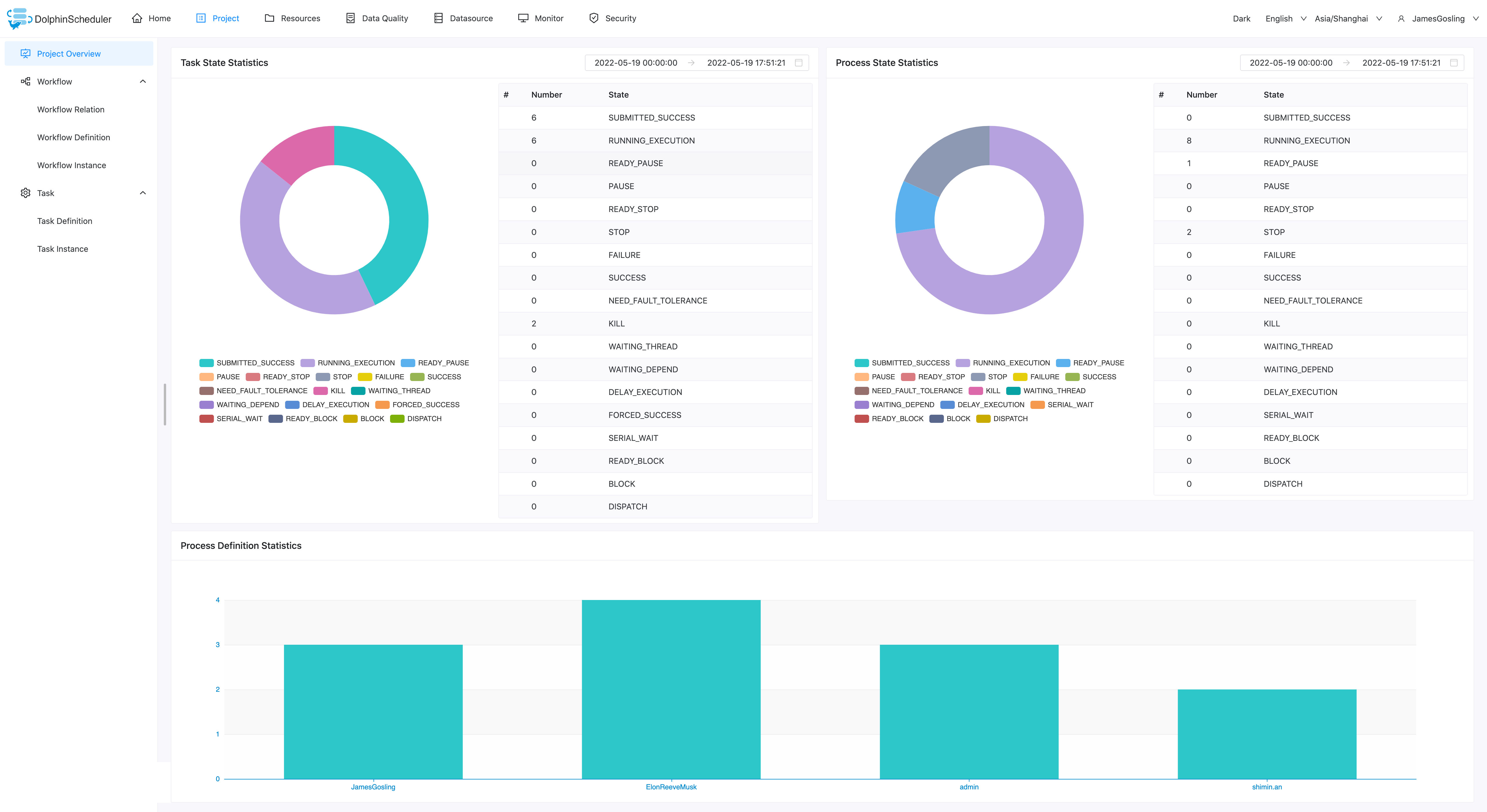
项目概览
在项目管理页面点击项目名称链接,进入项目首页,如下图所示,项目首页包含该项目的任务状态统计、流程状态统计、工作流定义统计。这几个指标的说明如下
- 任务状态统计:在指定时间范围内,统计任务实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
- 流程状态统计:在指定时间范围内,统计工作流实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
- 工作流定义统计:统计用户创建的工作流定义及管理员授予该用户的工作流定义
工作流
工作流定义
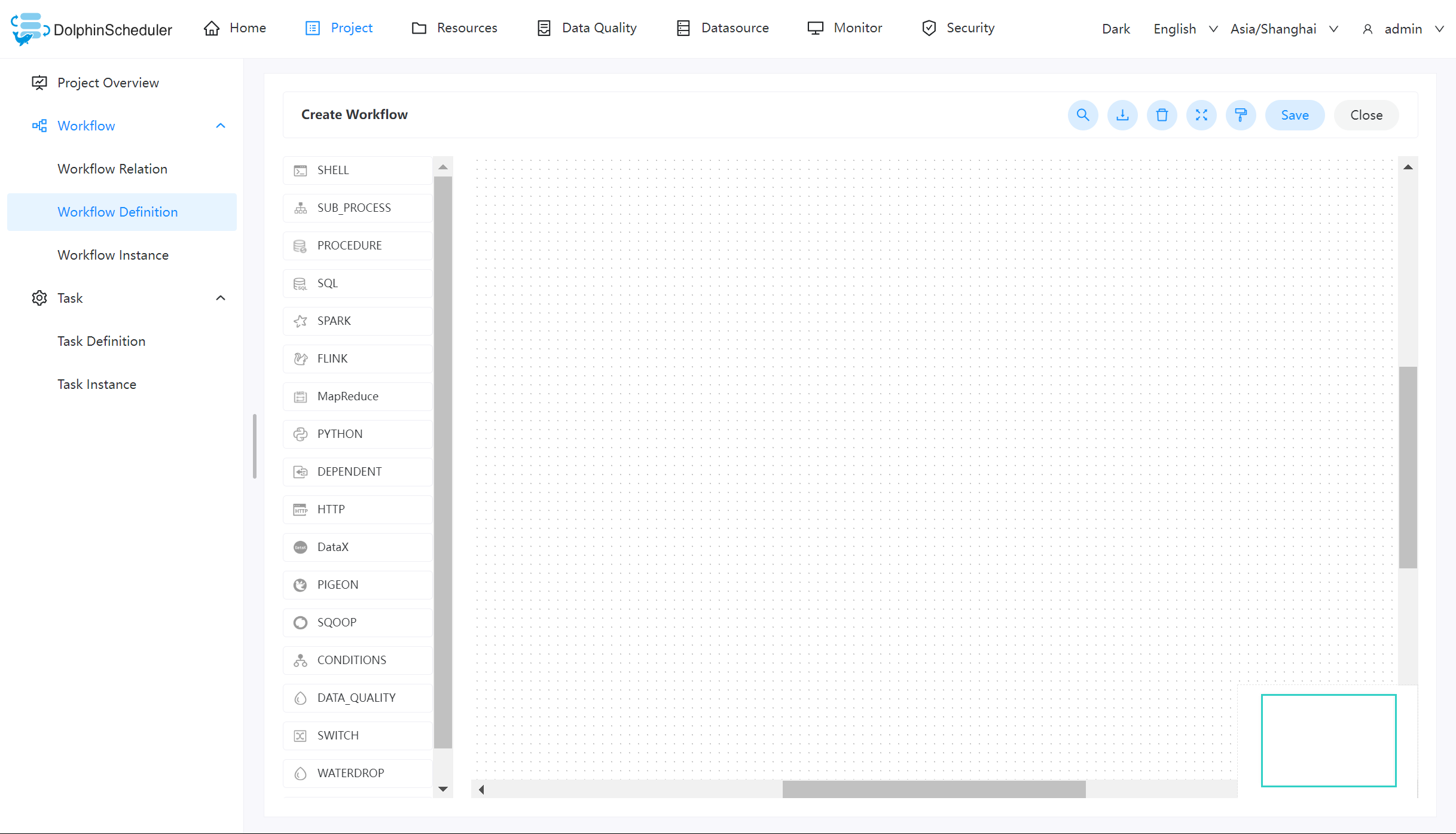
创建工作流定义
-
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击“创建工作流”按钮,进入工作流DAG编辑页面,如下图所示:
-
工具栏中拖拽
 到画板中,新增一个Shell任务,如下图所示:
到画板中,新增一个Shell任务,如下图所示: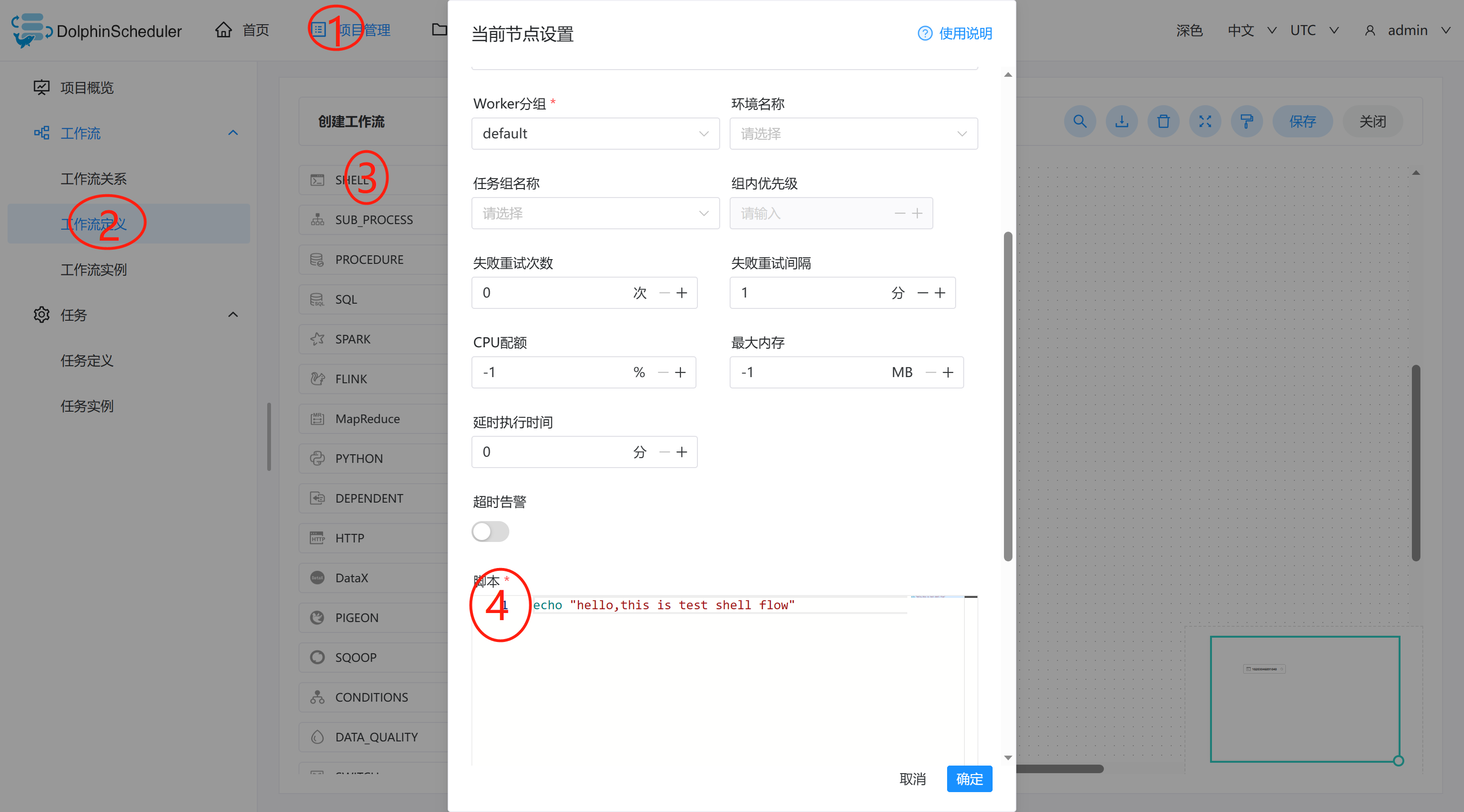
-
添加 Shell 任务的参数设置:
- 填写“节点名称”,“描述”,“脚本”字段;
- “运行标志”勾选“正常”,若勾选“禁止执行”,运行工作流不会执行该任务;
- 选择“任务优先级”:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行;
- 超时告警(非必选):勾选超时告警、超时失败,填写“超时时长”,当任务执行时间超过超时时长,会发送告警邮件并且任务超时失败;
- 资源(非必选):资源文件是资源中心->文件管理页面创建或上传的文件,如文件名为
test.sh,脚本中调用资源命令为sh test.sh。注意调用需要使用资源的全路径; - 自定义参数(非必填);
- 点击"确认添加"按钮,保存任务设置。
-
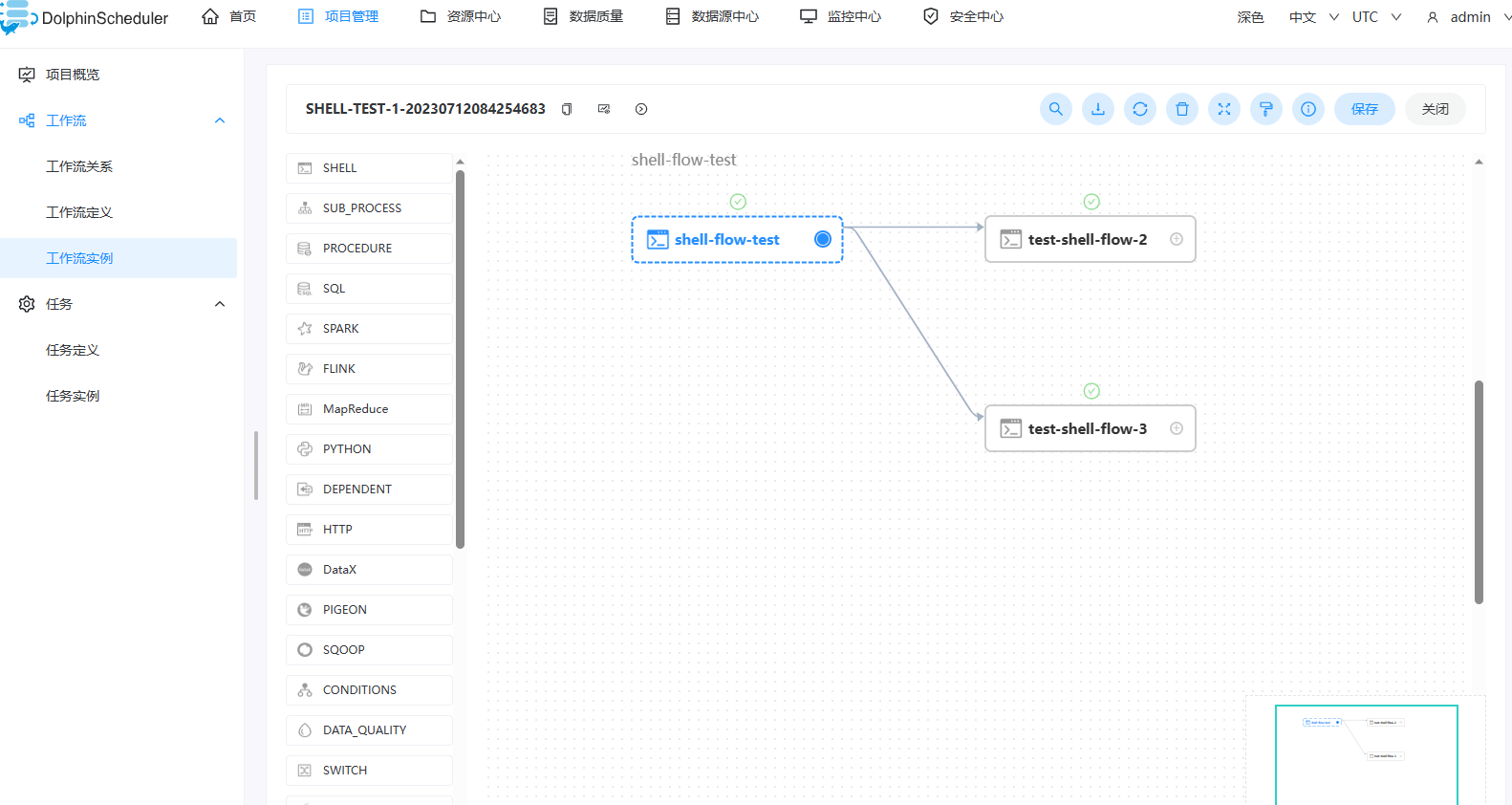
配置任务之间的依赖关系: 点击任务节点的右侧加号连接任务;如下图所示,任务 test-shell-flow-2和任务 test-shell-flow-3 并行执行,当任务 shell-flow-test 执行完,任务 test-shell-flow-2、test-shell-flow-3会同时执行。
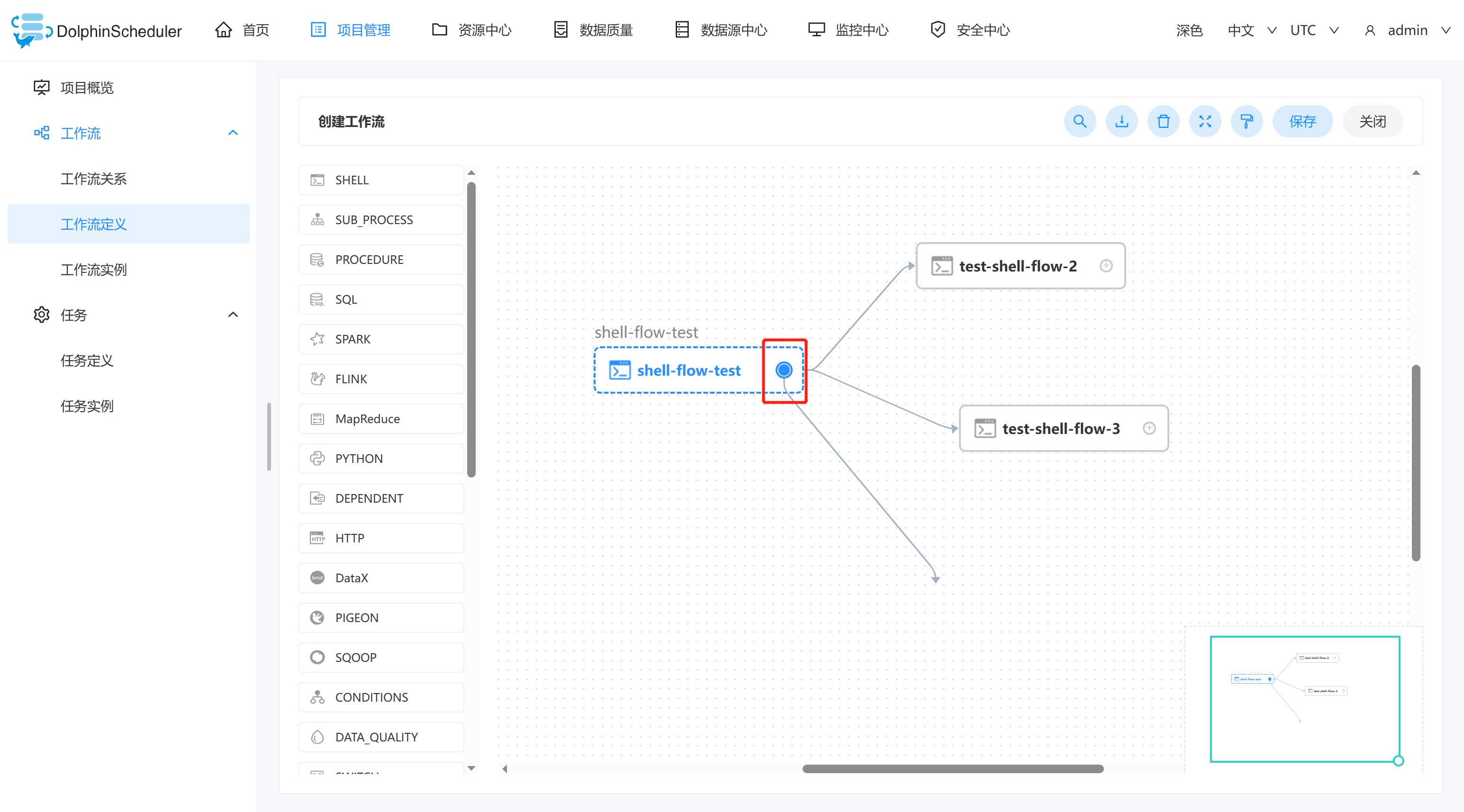
-
删除依赖关系: 点击右上角"箭头"图标
 ,选中连接线,点击右上角"删除"图标
,选中连接线,点击右上角"删除"图标 ,删除任务间的依赖关系。
,删除任务间的依赖关系。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8zcKY5RV-1690178677361)(images/image-20230712143433154.png)]
-
查找依赖关系: 点击右上角"箭头"图标
,选中连接线,点击右上角"查找"图标,可以检索工作流。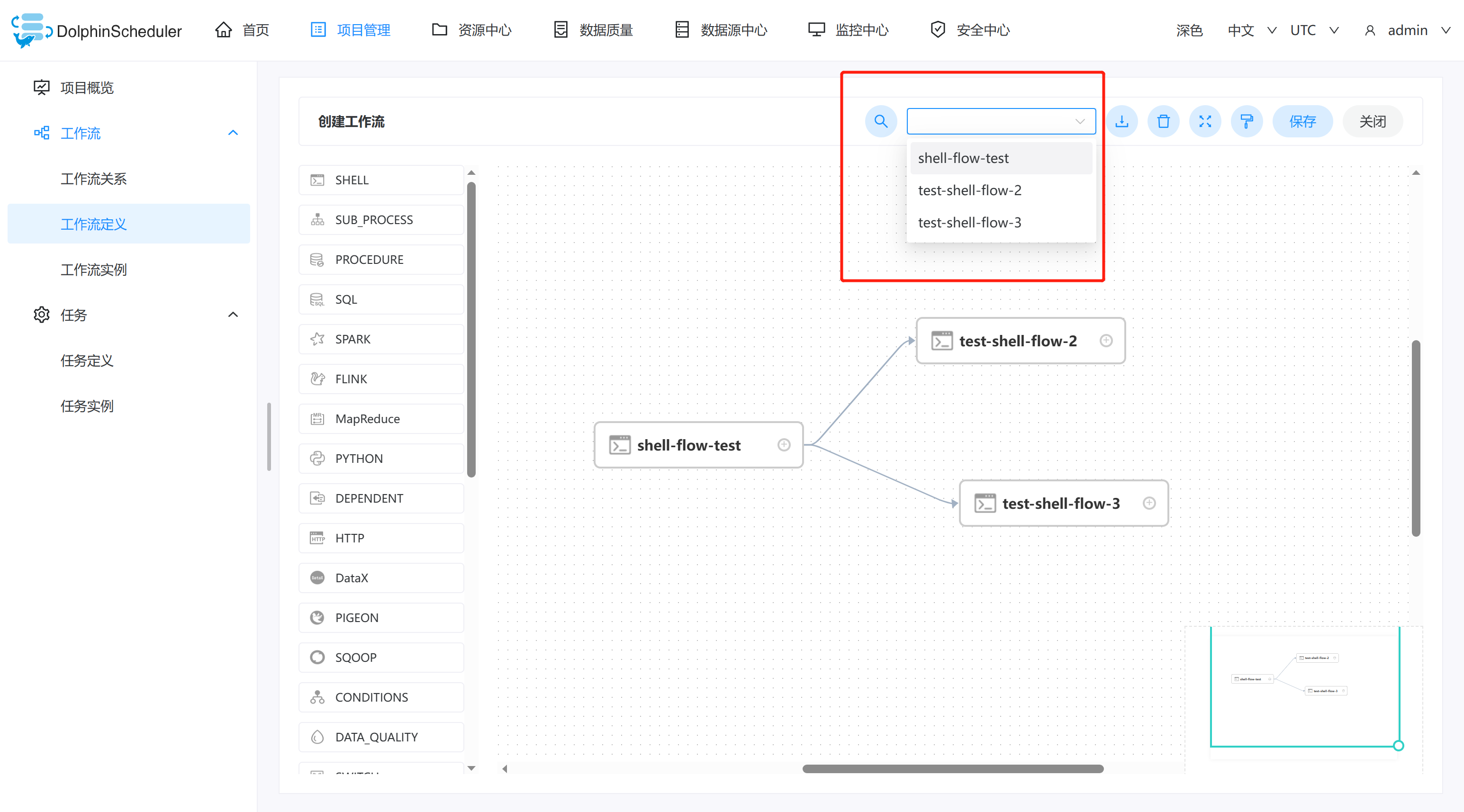
-
下载任务DAG: 点击右上角"箭头"图标
,选中连接线,点击右上角"下载"图标,下载任务流DAG图片。
-
**查看任务流版本信息:**可以查看到任务流的版本信息,以及版本控制。
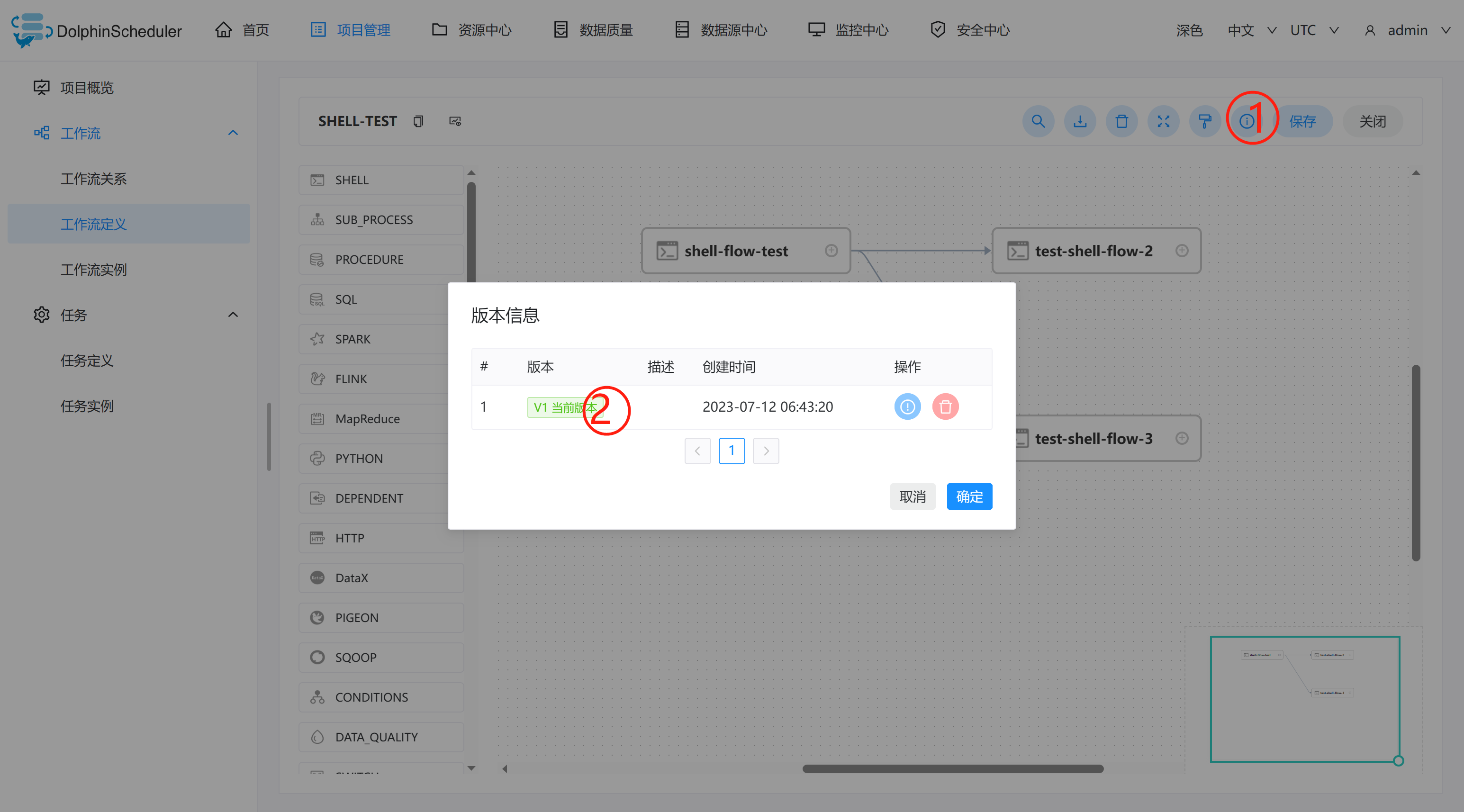
-
保存工作流定义: 点击”保存“按钮,弹出"设置DAG图名称"弹框,如下图所示,输入工作流定义名称,工作流定义描述,设置全局参数(选填,参考全局参数),点击"添加"按钮,工作流定义创建成功。
其他类型任务,请参考 任务节点类型和参数设置。
-
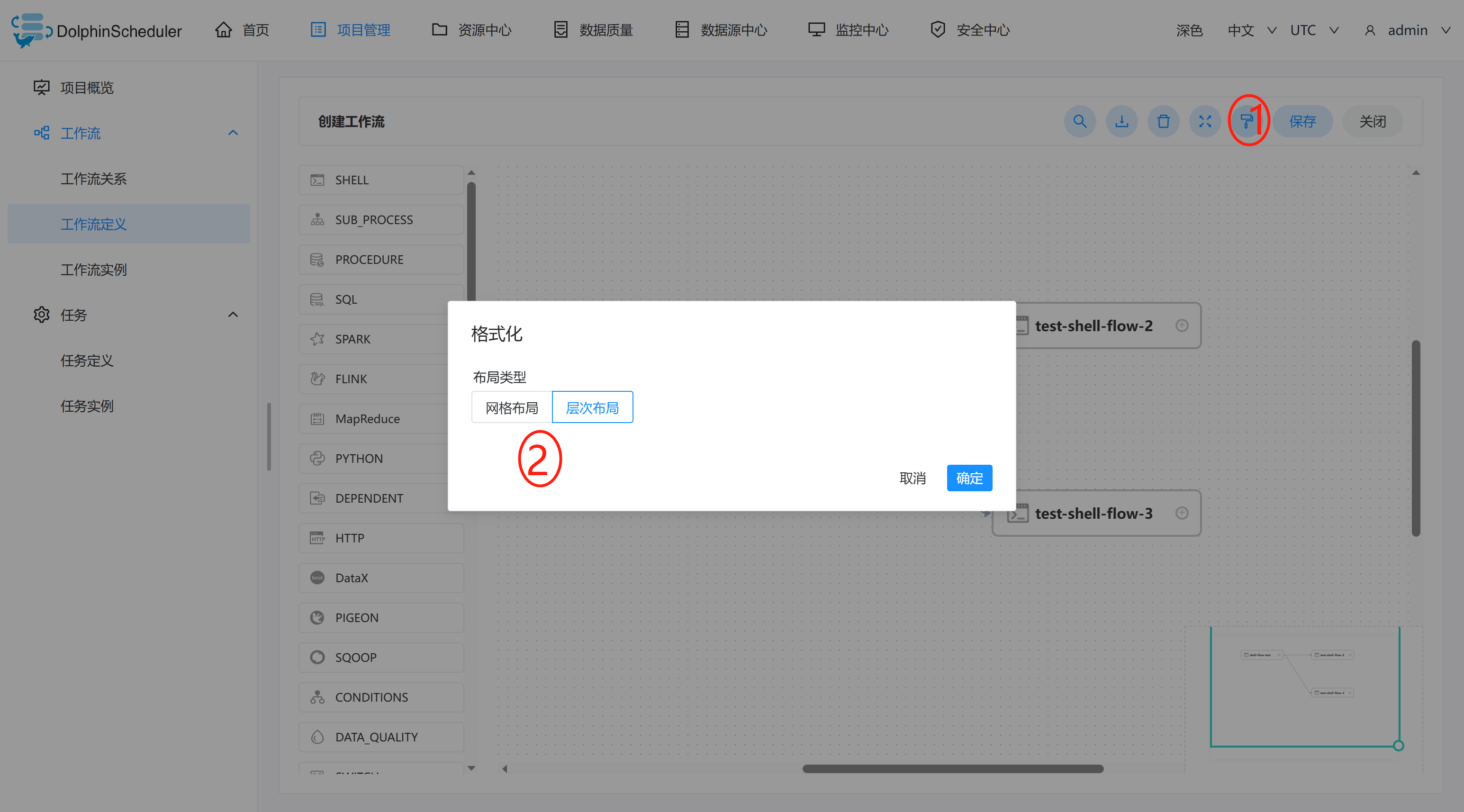
格式化DAG图层,可以更改画布布局。
-
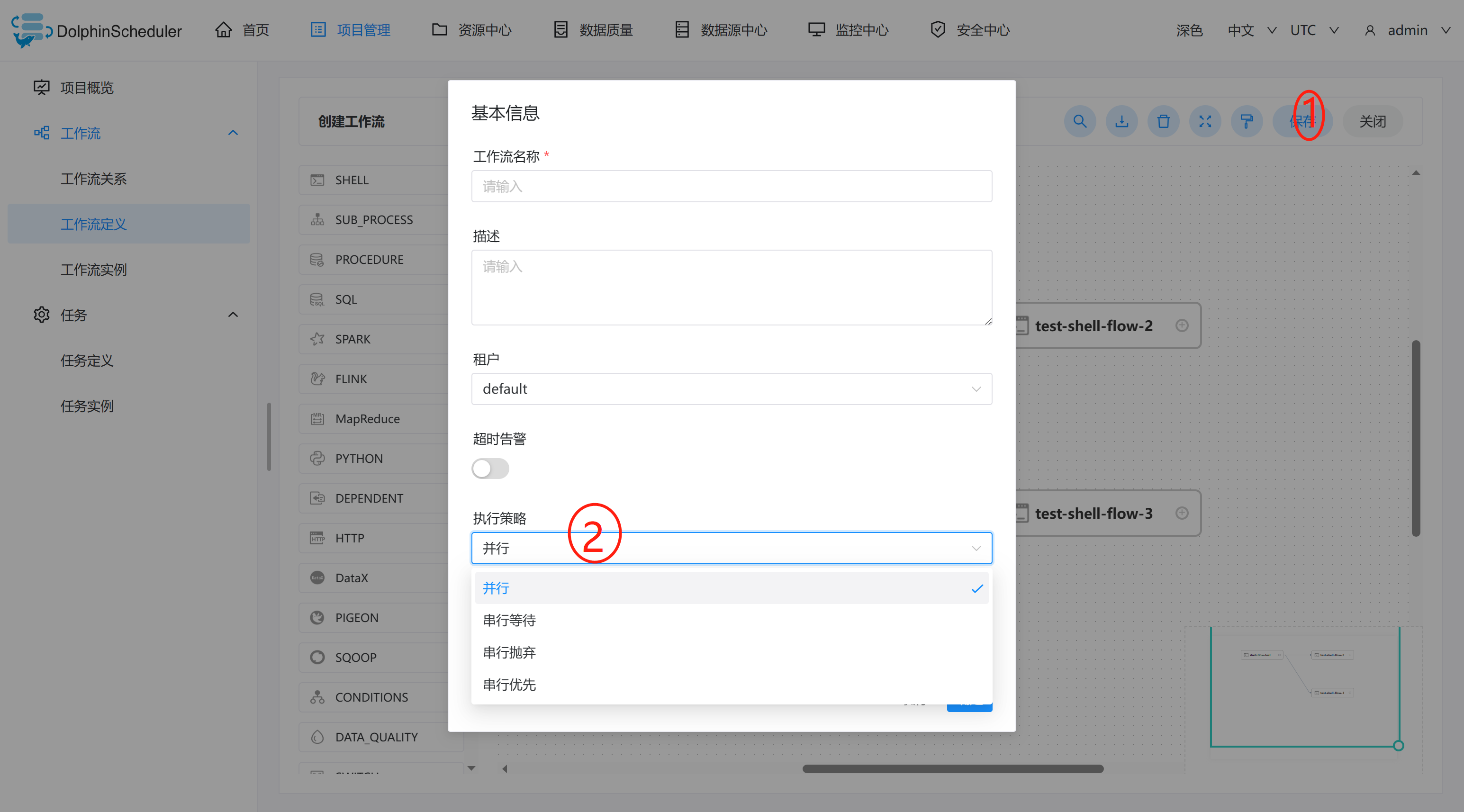
执行策略
-
并行:如果对于同一个工作流定义,同时有多个工作流实例,则并行执行工作流实例。 -
串行等待:如果对于同一个工作流定义,同时有多个工作流实例,则串行执行工作流实例。 -
串行抛弃:如果对于同一个工作流定义,同时有多个工作流实例,则抛弃后生成的工作流实例并杀掉正在跑的实例。 -
串行优先:如果对于同一个工作流定义,同时有多个工作流实例,则按照优先级串行执行工作流实例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gRQyXWZu-1690178677368)(images/image-20230712144309277.png)]
工作流定义操作功能
点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示:

工作流定义列表的操作功能如下:
- 编辑: 只能编辑"下线"的工作流定义。工作流DAG编辑同创建工作流定义。
- 上线: 工作流状态为"下线"时,上线工作流,只有"上线"状态的工作流能运行,但不能编辑。
- 下线: 工作流状态为"上线"时,下线工作流,下线状态的工作流可以编辑,但不能运行。
- 运行: 只有上线的工作流能运行。运行操作步骤见运行工作流
- 定时: 只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为"下线",需在定时管理页面上线定时才生效。定时操作步骤见工作流定时
- 定时管理: 定时管理页面可编辑、上线/下线、删除定时。
- 删除: 删除工作流定义。在同一个项目中,只能删除自己创建的工作流定义,其他用户的工作流定义不能进行删除,如果需要删除请联系创建用户或者管理员。
- 下载: 下载工作流定义到本地。
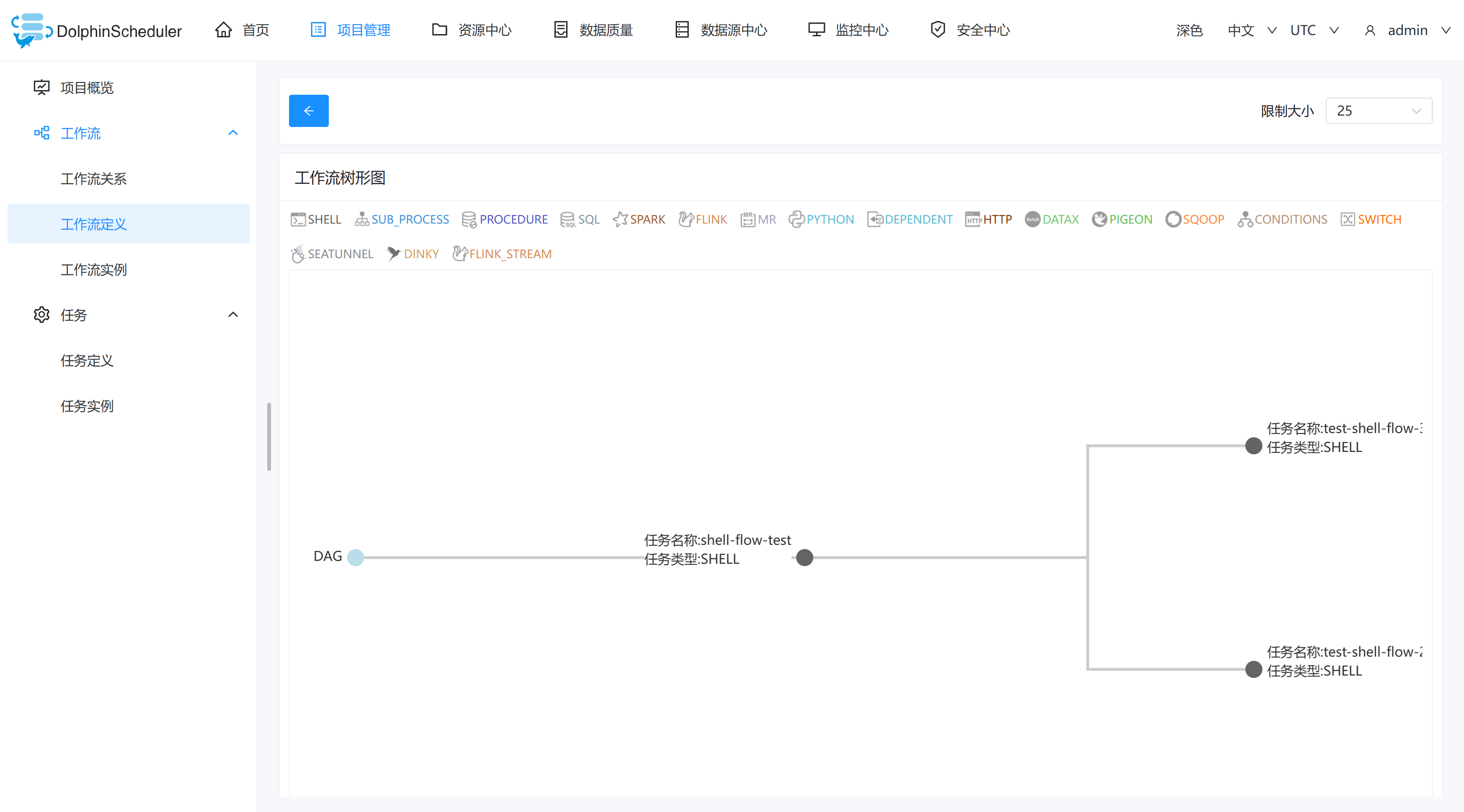
- 树形图: 以树形结构展示任务节点的类型及任务状态,如下图所示:
运行工作流
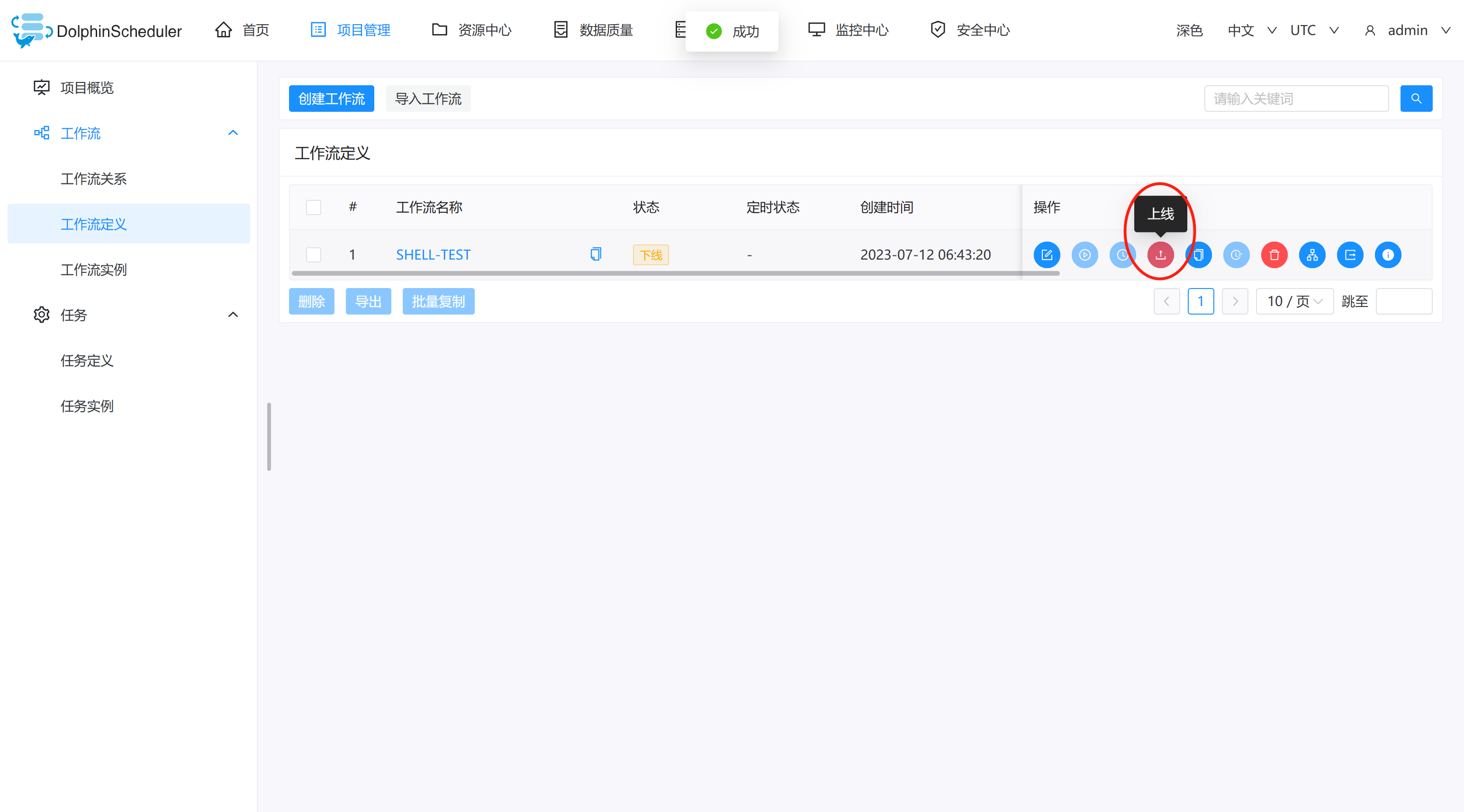
- 点击项目管理->工作流->工作流定义,进入工作流定义页面,如下图所示,点击"上线"按钮,上线工作流。
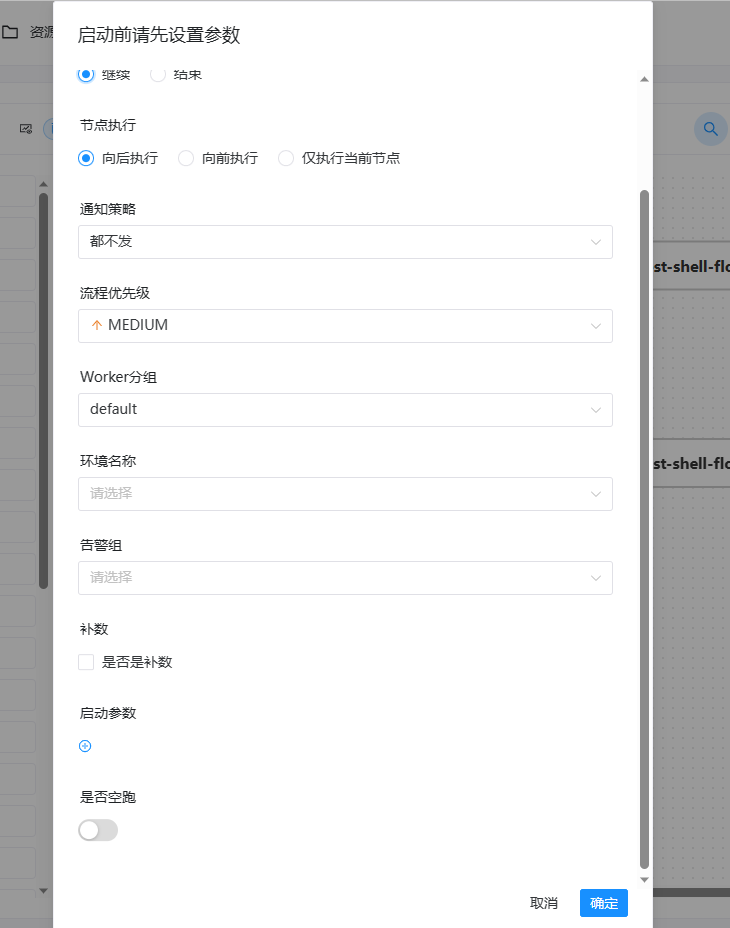
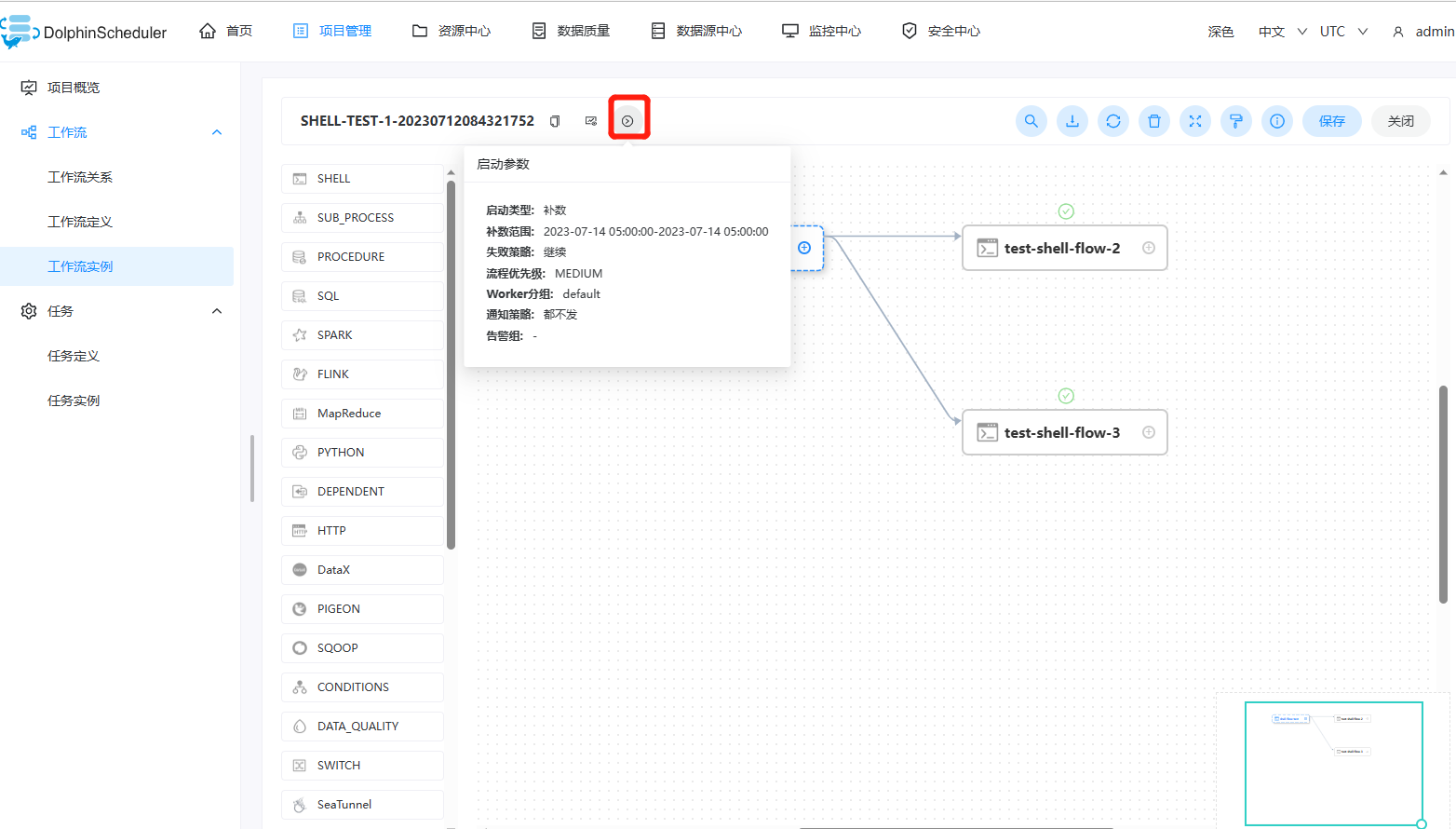
- 点击”运行“按钮,弹出启动参数设置弹框,如下图所示,设置启动参数,点击弹框中的"运行"按钮,工作流开始运行,工作流实例页面生成一条工作流实例。

工作流运行参数说明:
-
失败策略:当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。”继续“表示:某一任务失败后,其他任务节点正常执行;”结束“表示:终止所有正在执行的任务,并终止整个流程。
-
通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
-
流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
-
Worker 分组:该流程只能在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。
-
通知组:选择通知策略||超时报警||发生容错时,会发送流程信息或邮件到通知组里的所有成员。
-
启动参数: 在启动新的流程实例时,设置或覆盖全局参数的值。
-
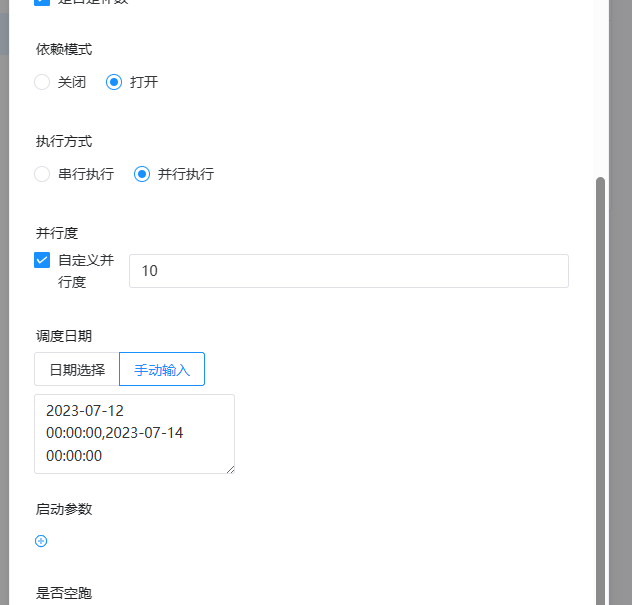
补数:指运行指定日期范围内的工作流定义,根据补数策略生成对应的工作流实例,补数策略包括串行补数、并行补数 2 种模式。
日期可以通过页面选择或者手动输入,日期范围是左关右关区间(startDate <= N <= endDate)
- 串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,依次生成多条流程实例;点击运行工作流,选择串行补数模式:例如从7月 9号到7月10号依次执行,依次在流程实例页面生成两条流程实例。
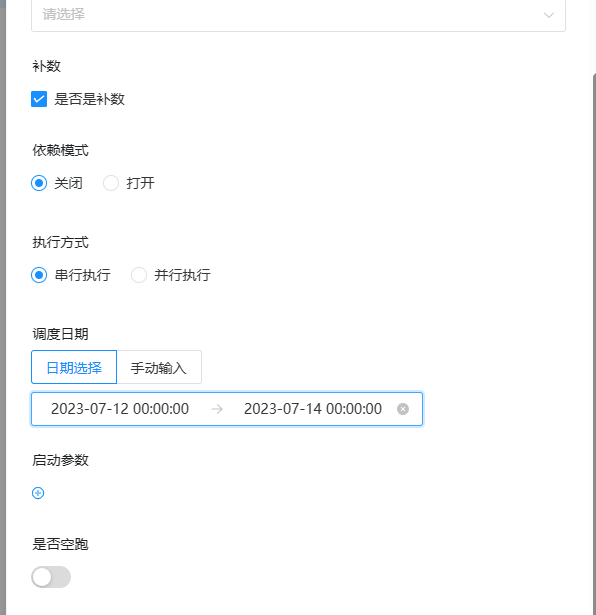
- 并行补数: 指定时间范围内,同时进行多天的补数,同时生成多条流程实例。手动输入日期:手动输入以逗号分割日期格式为
yyyy-MM-dd HH:mm:ss的日期。点击运行工作流,选择并行补数模式:例如同时执行7月9号到7月10号的工作流定义,同时在流程实例页面生成两条流程实例(执行策略为串行时流程实例按照策略执行)。 - 并行度:是指在并行补数的模式下,最多并行执行的实例数。
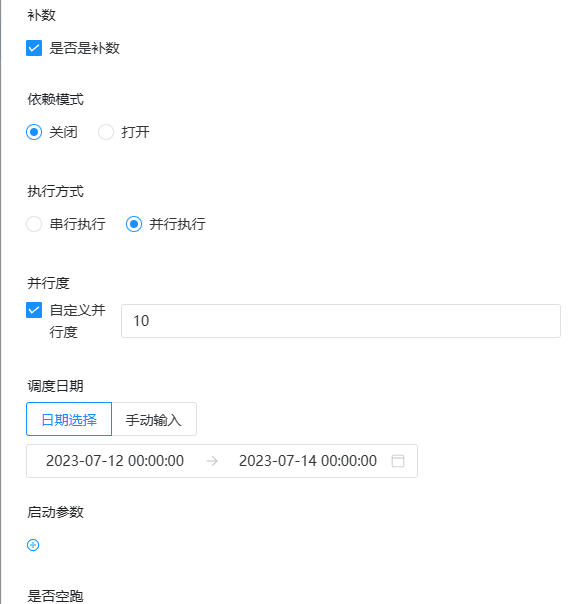
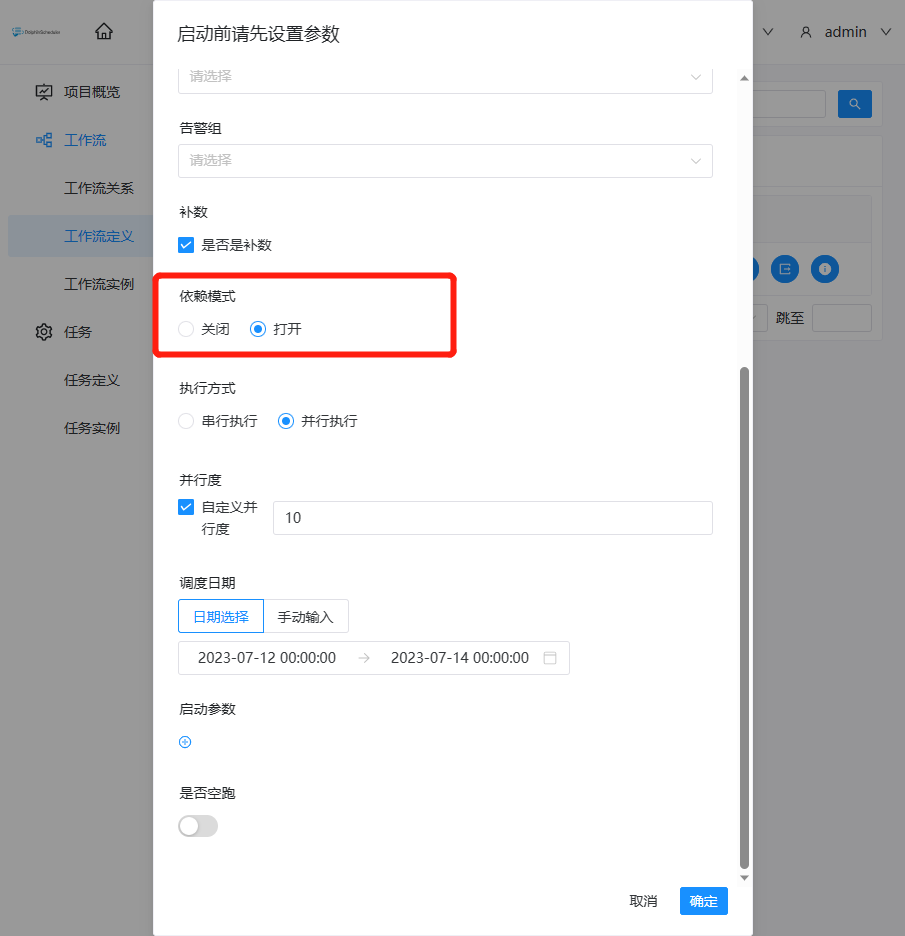
- 依赖模式:是否触发下游依赖节点依赖到当前工作流的工作流实例的补数(要求当前补数的工作流实例的定时状态为已上线,只会触发下游直接依赖到当前工作流的补数)。
-
日期选择:
- 通过页面选择日期:
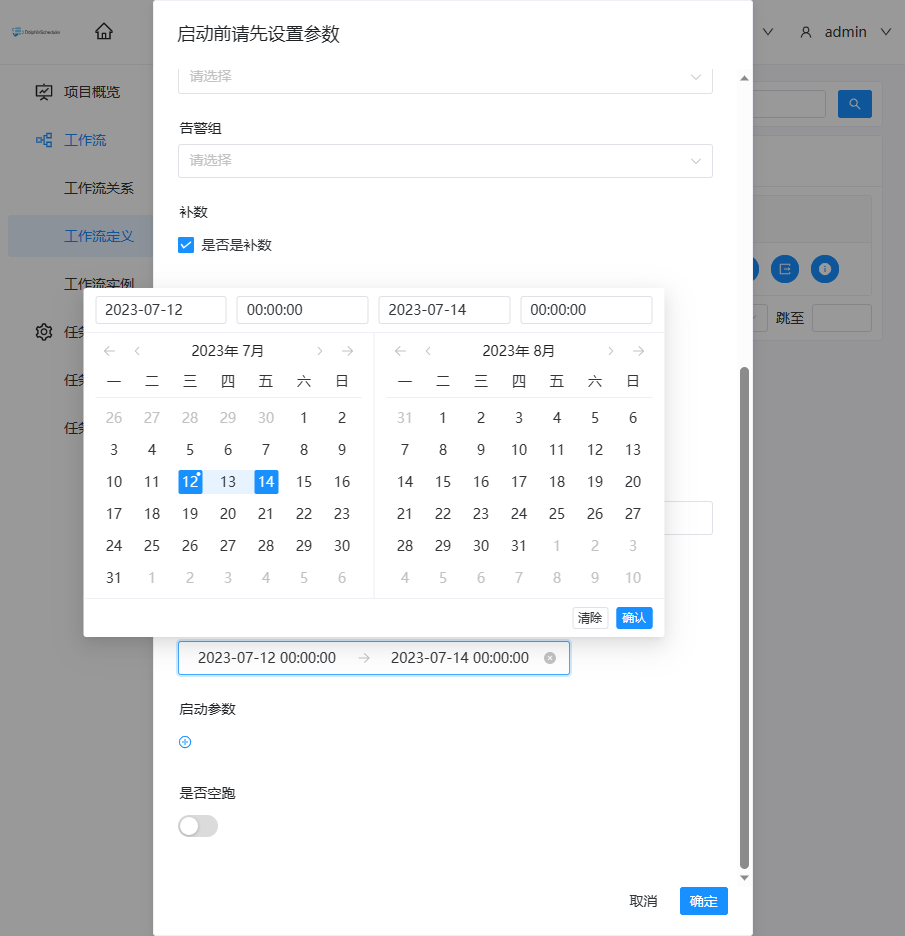
- 手动输入:格式为yyyy-MM-dd HH:mm:ss,多个逗号分割,例如2023-07-12 00:00:00,2023-07-14 00:00:00
-
补数与定时配置的关系:
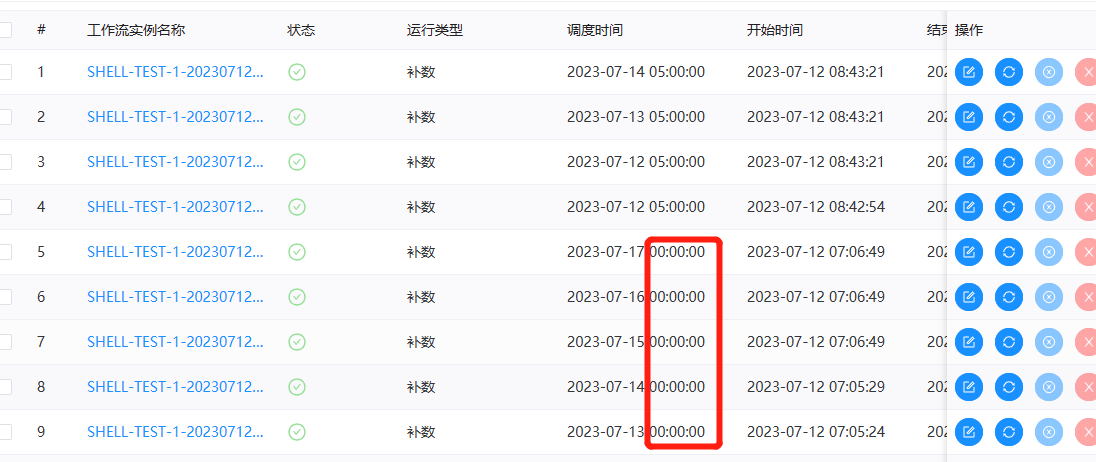
未配置定时或已配置定时并定时状态下线:根据所选的时间范围结合定时默认配置(每天0点)进行补数,比如该工作流调度日期为7月7号到7月10号,流程实例为:
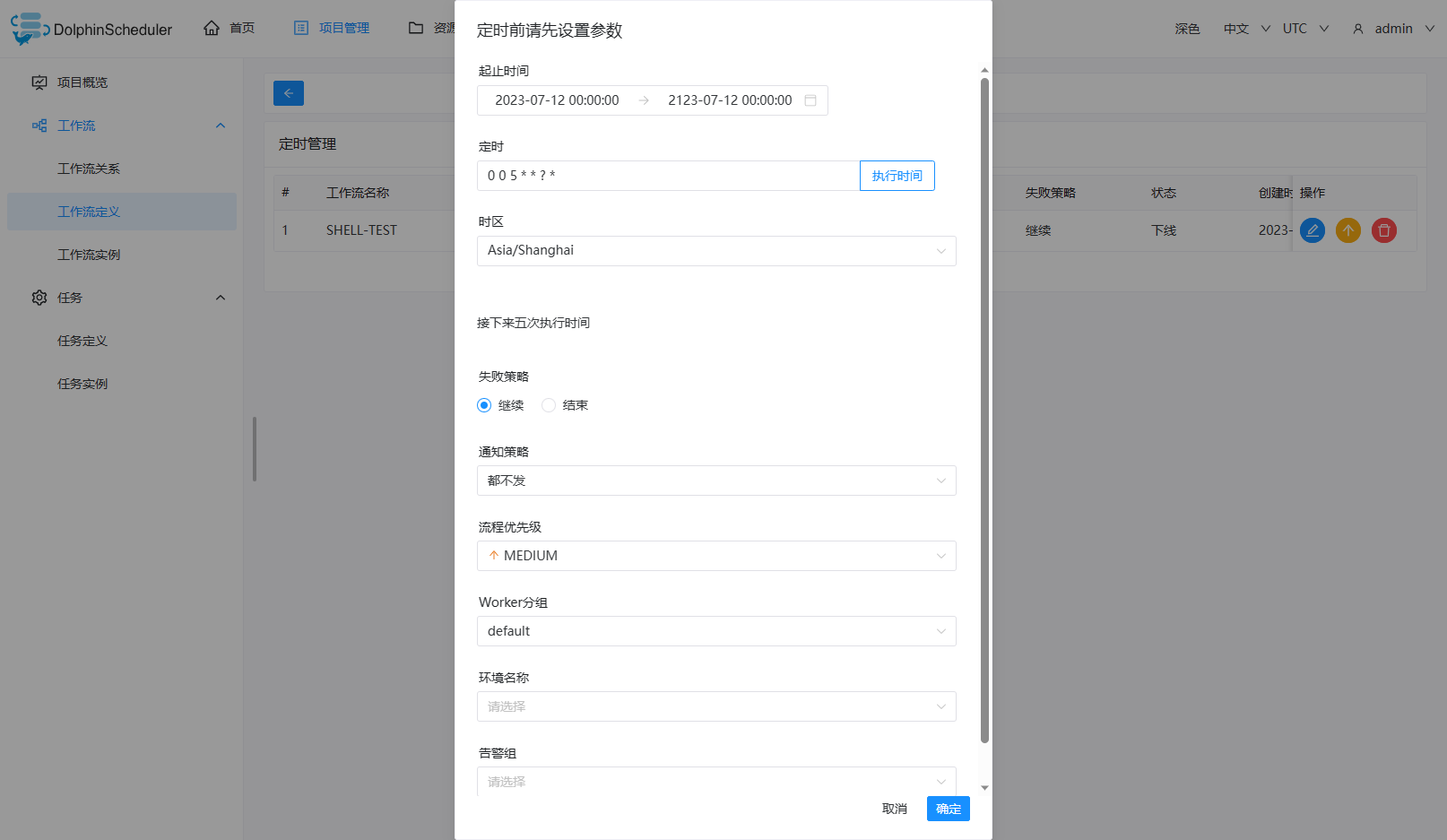
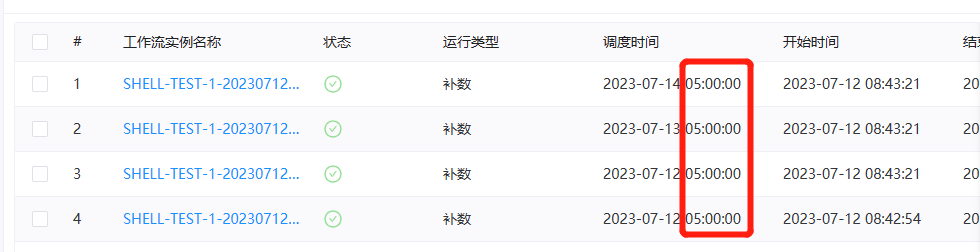
已配置定时并定时状态上线:根据所选的时间范围结合定时配置进行补数,比如该工作流调度日期为7月7号到7月10号,配置了定时(每日凌晨5点运行),流程实例为:
单独运行任务
- 右键选中任务,点击"启动"按钮(只有已上线的任务才能点击运行)
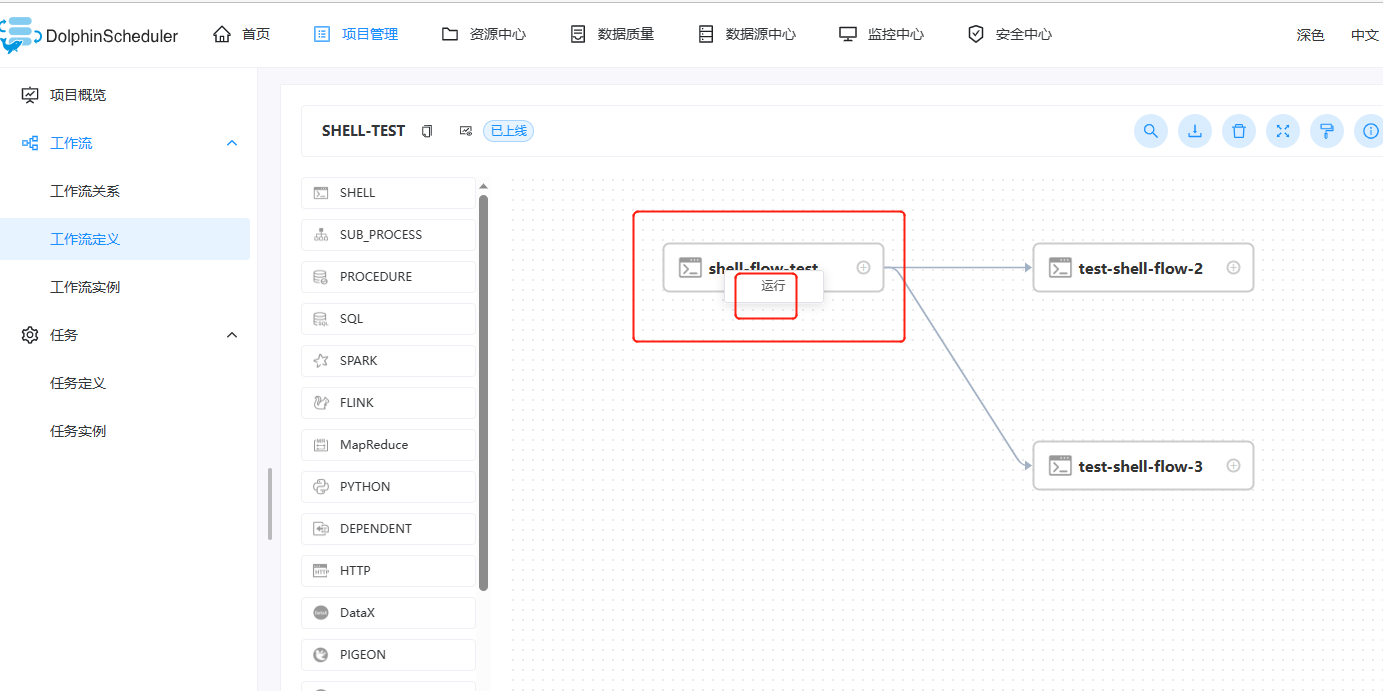
- 弹出启动参数设置弹框,参数说明同运行工作流
工作流定时
-
创建定时:点击项目管理->工作流->工作流定义,进入工作流定义页面,上线工作流,点击"定时"按钮
 ,弹出定时参数设置弹框,如下图所示:
,弹出定时参数设置弹框,如下图所示: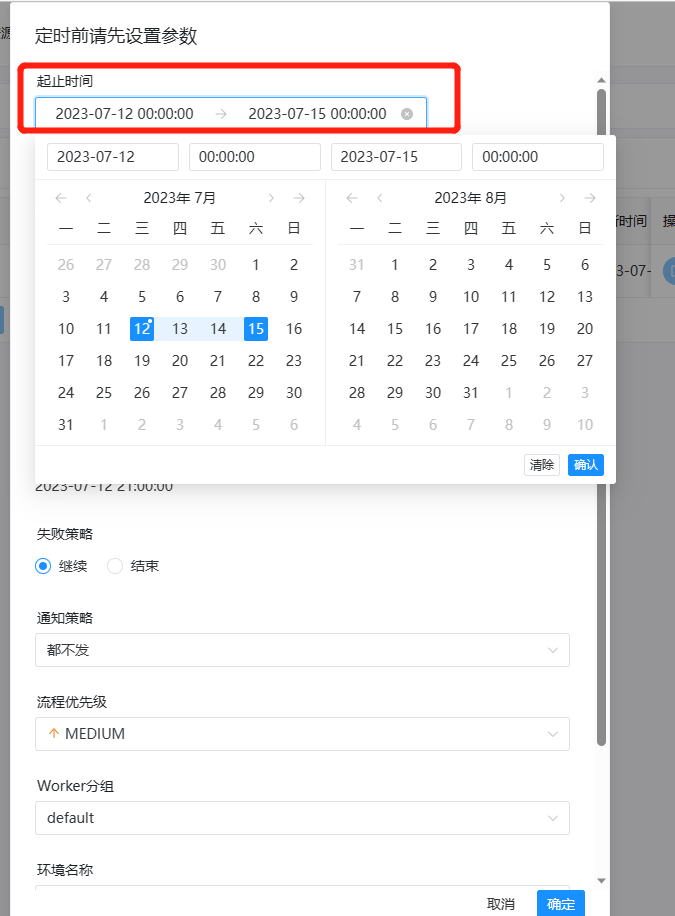
-
选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例。
-
添加一个每隔 5 分钟执行一次的定时,如下图所示:
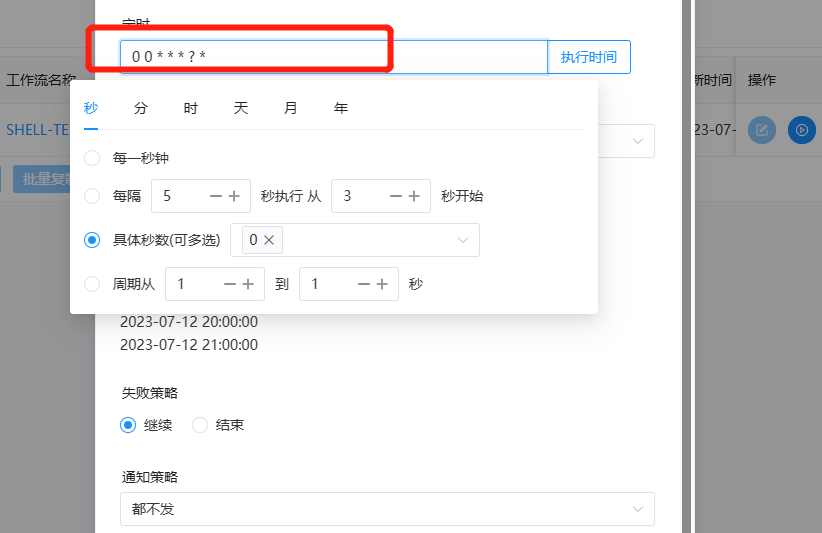
-
失败策略、通知策略、流程优先级、Worker 分组、通知组、收件人、抄送人同工作流运行参数。
-
点击"创建"按钮,创建定时成功,此时定时状态为"下线",定时需上线才生效。
-
定时上线:点击"定时管理"按钮
 ,进入定时管理页面,点击"上线"按钮,定时状态变为"上线",如下图所示,工作流定时生效。
,进入定时管理页面,点击"上线"按钮,定时状态变为"上线",如下图所示,工作流定时生效。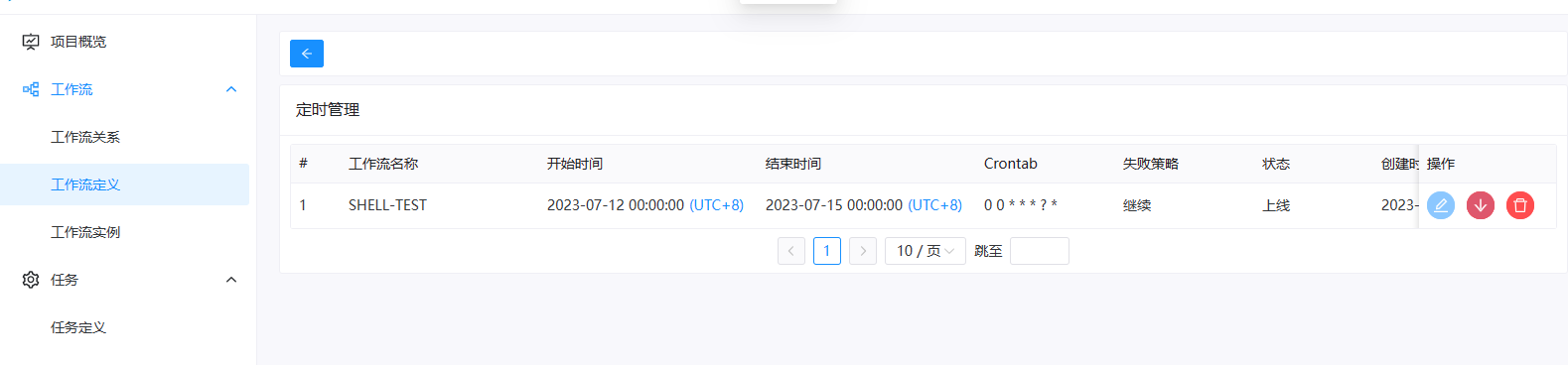
导入工作流
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击"导入工作流"按钮,导入本地工作流文件,工作流定义列表显示导入的工作流,状态为下线。
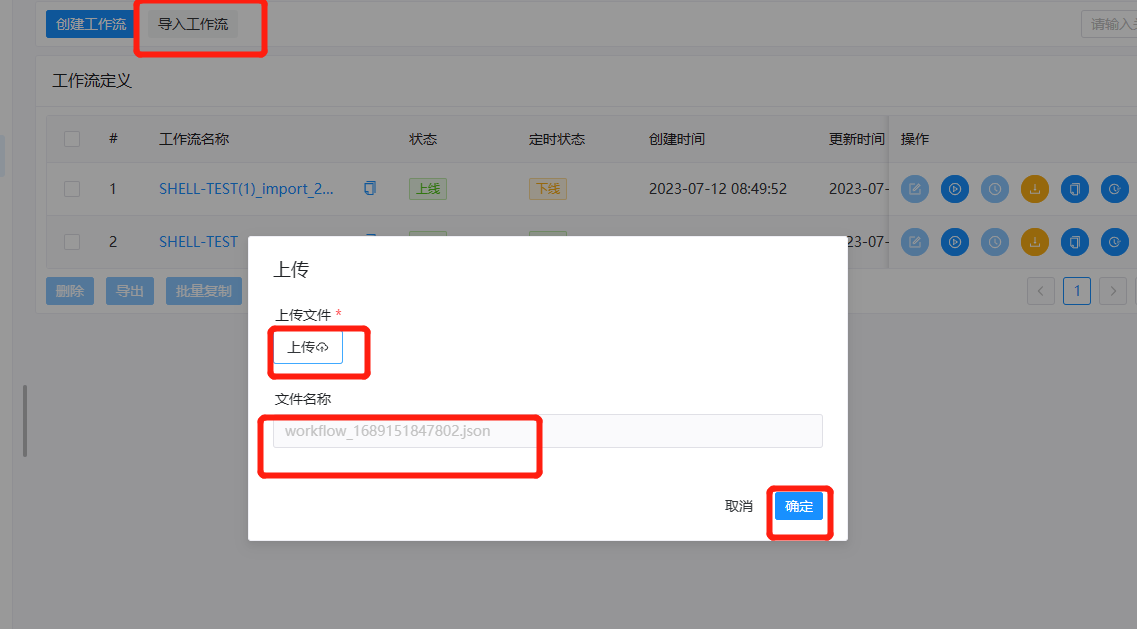
工作流实例
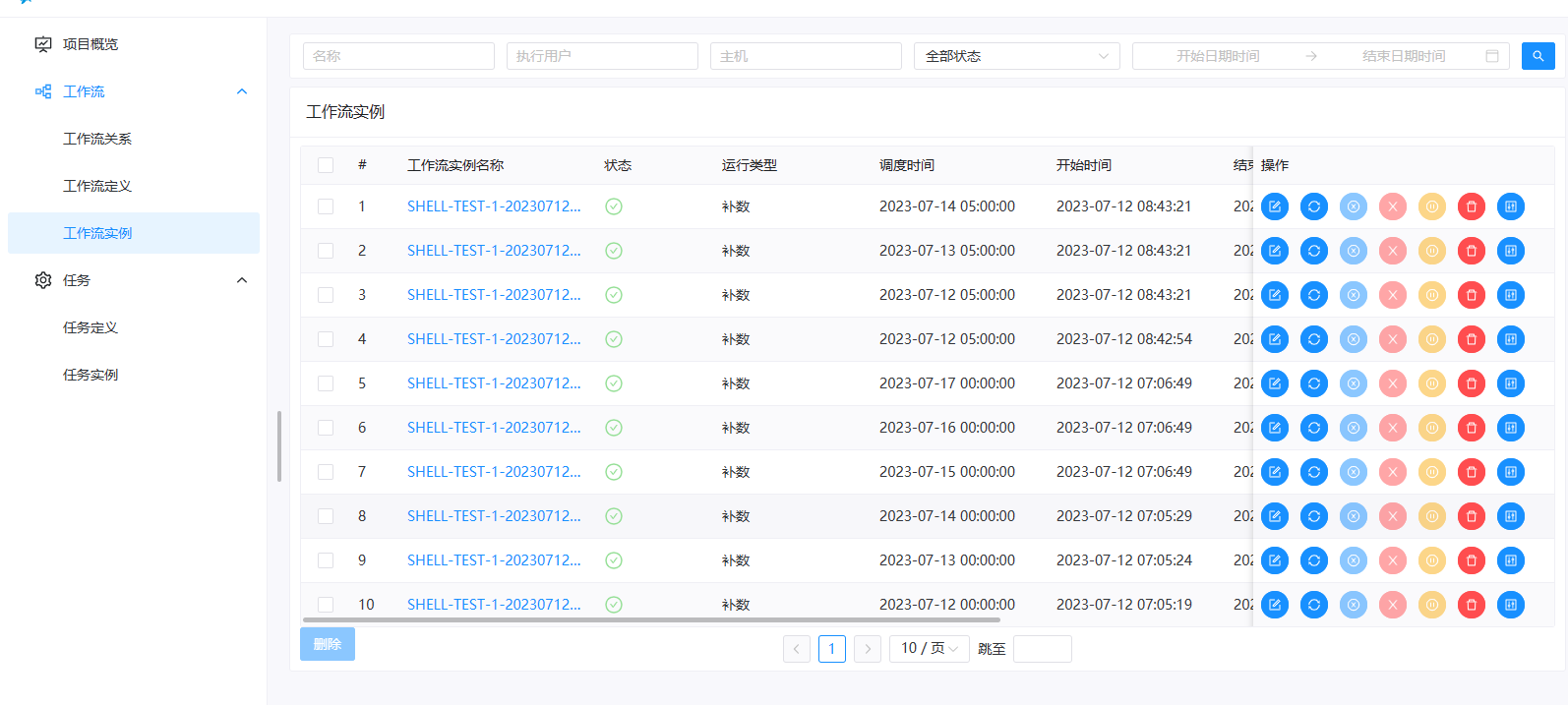
查看工作流实例
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:
- 点击工作流名称,进入DAG查看页面,查看任务执行状态,如下图所示。
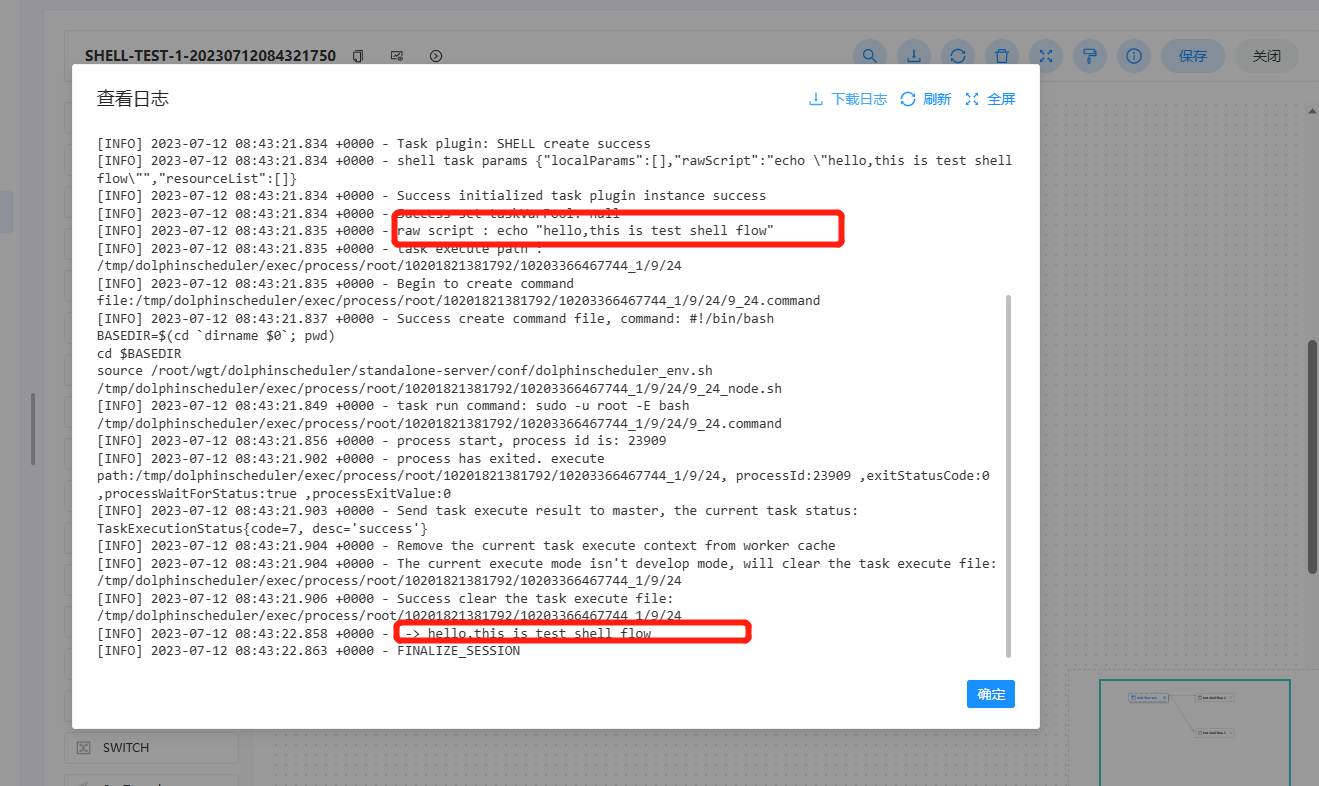
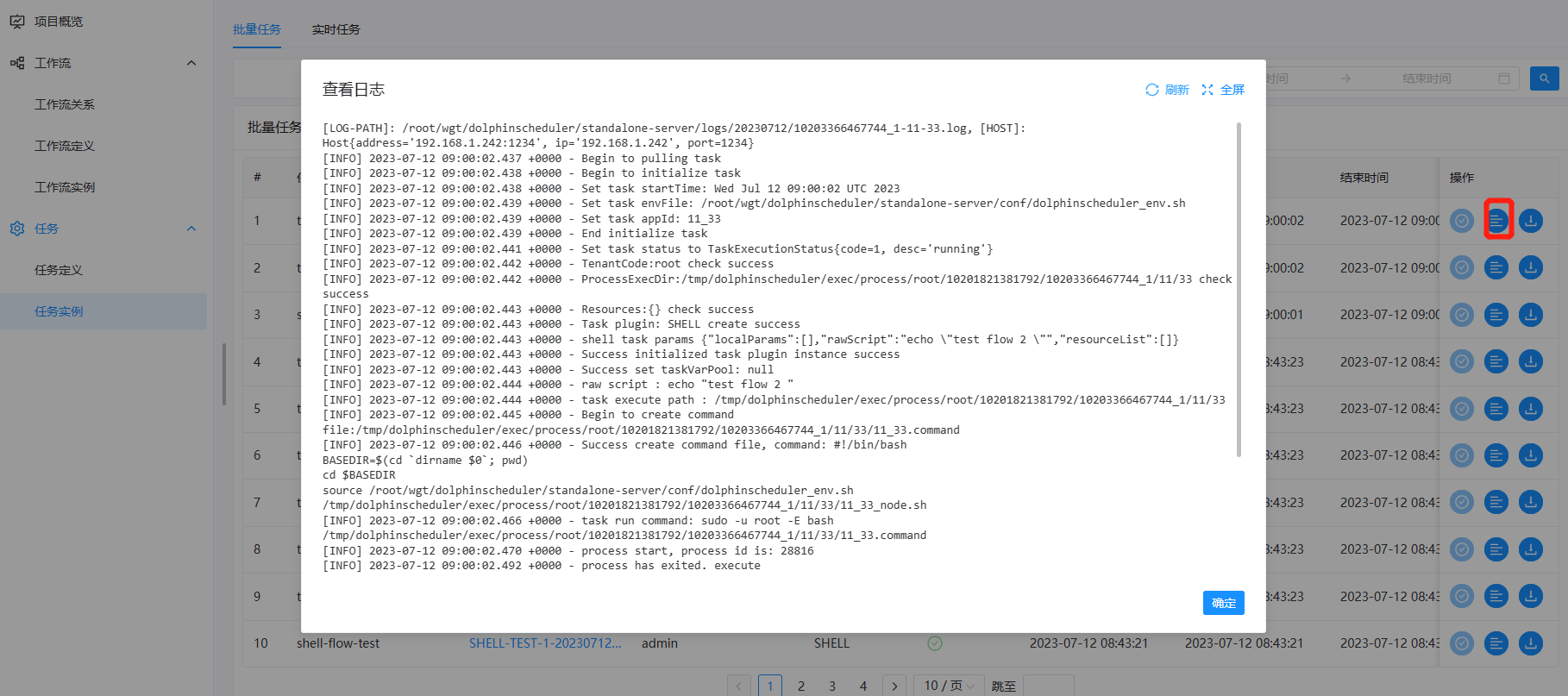
查看任务日志
- 进入工作流实例页面,点击工作流名称,进入DAG查看页面,双击任务节点,如下图所示:

- 点击"查看日志",弹出日志弹框,如下图所示,任务实例页面也可查看任务日志,参考任务查看日志。
查看任务历史记录
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
- 双击任务节点,如下图所示,点击"查看历史",跳转到任务实例页面,并展示该工作流实例运行的任务实例列表
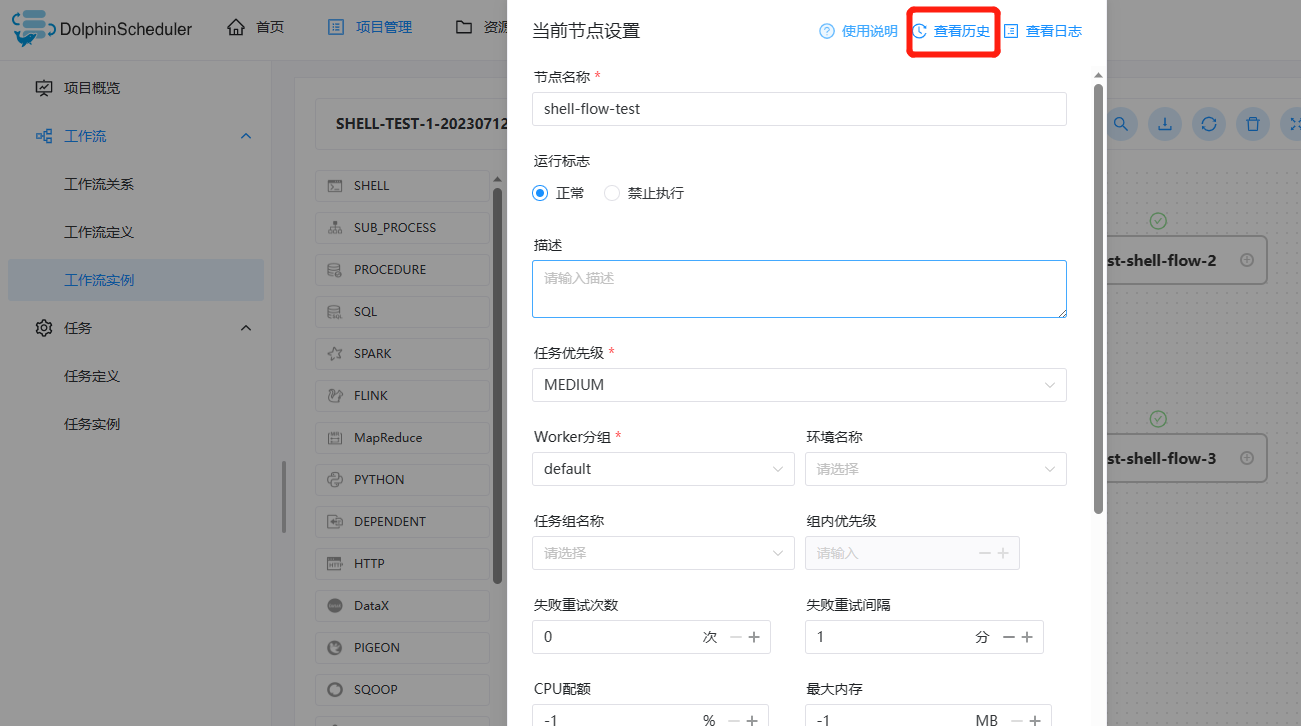
查看运行参数
- 点击项目管理->工作流->工作流实例,进入工作流实例页面,点击工作流名称,进入工作流 DAG 页面;
- 点击左上角图标
 ,查看工作流实例的启动参数;点击图标
,查看工作流实例的启动参数;点击图标 ,查看工作流实例的全局参数和局部参数,如下图所示:
,查看工作流实例的全局参数和局部参数,如下图所示:
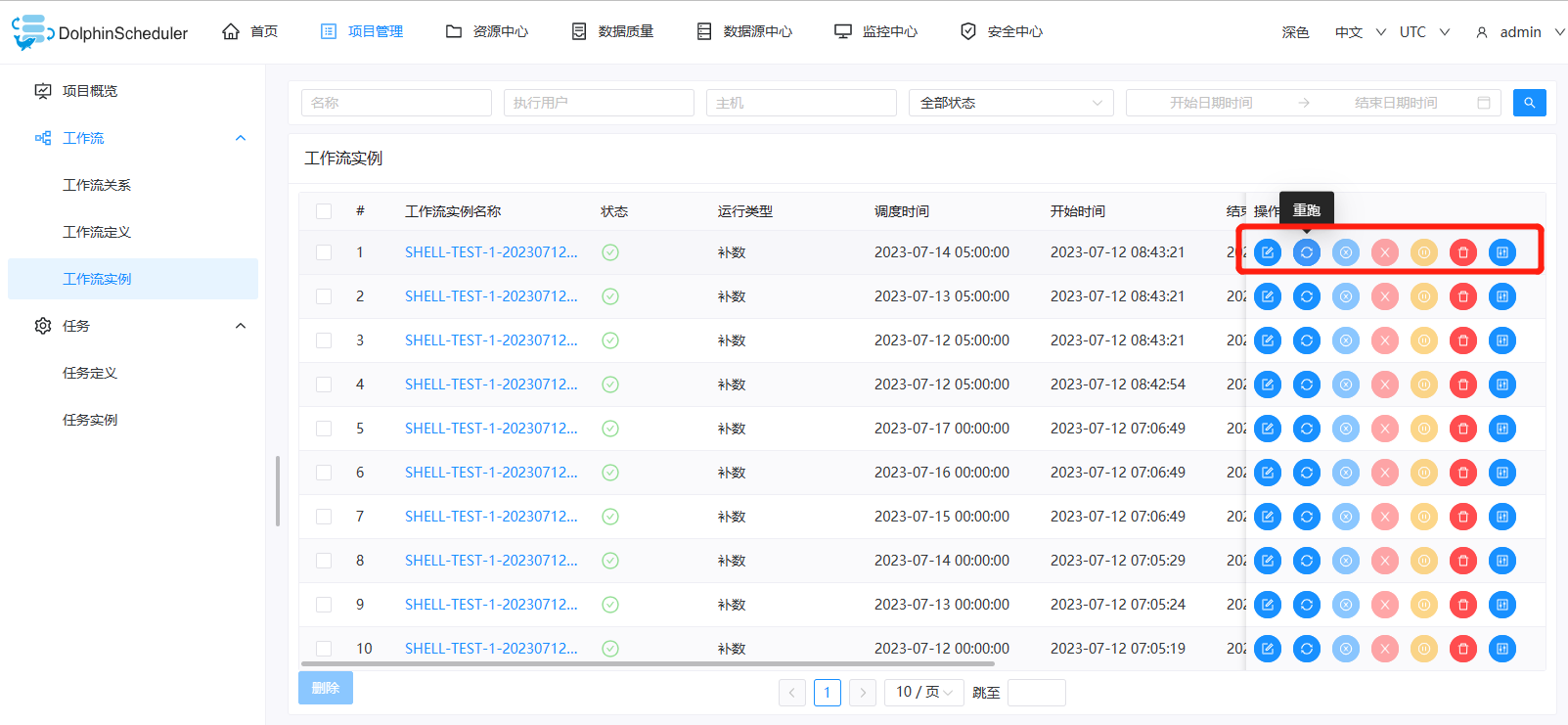
工作流实例操作功能
点击项目管理->工作流->工作流实例,进入工作流实例页面,如下图所示:
-
编辑: 只能编辑 成功/失败/停止 状态的流程。点击"编辑"按钮或工作流实例名称进入 DAG 编辑页面,编辑后点击"保存"按钮,弹出保存 DAG 弹框,如下图所示,修改流程定义信息,在弹框中勾选"是否更新工作流定义",保存后则将实例修改的信息更新到工作流定义;若不勾选,则不更新工作流定义。
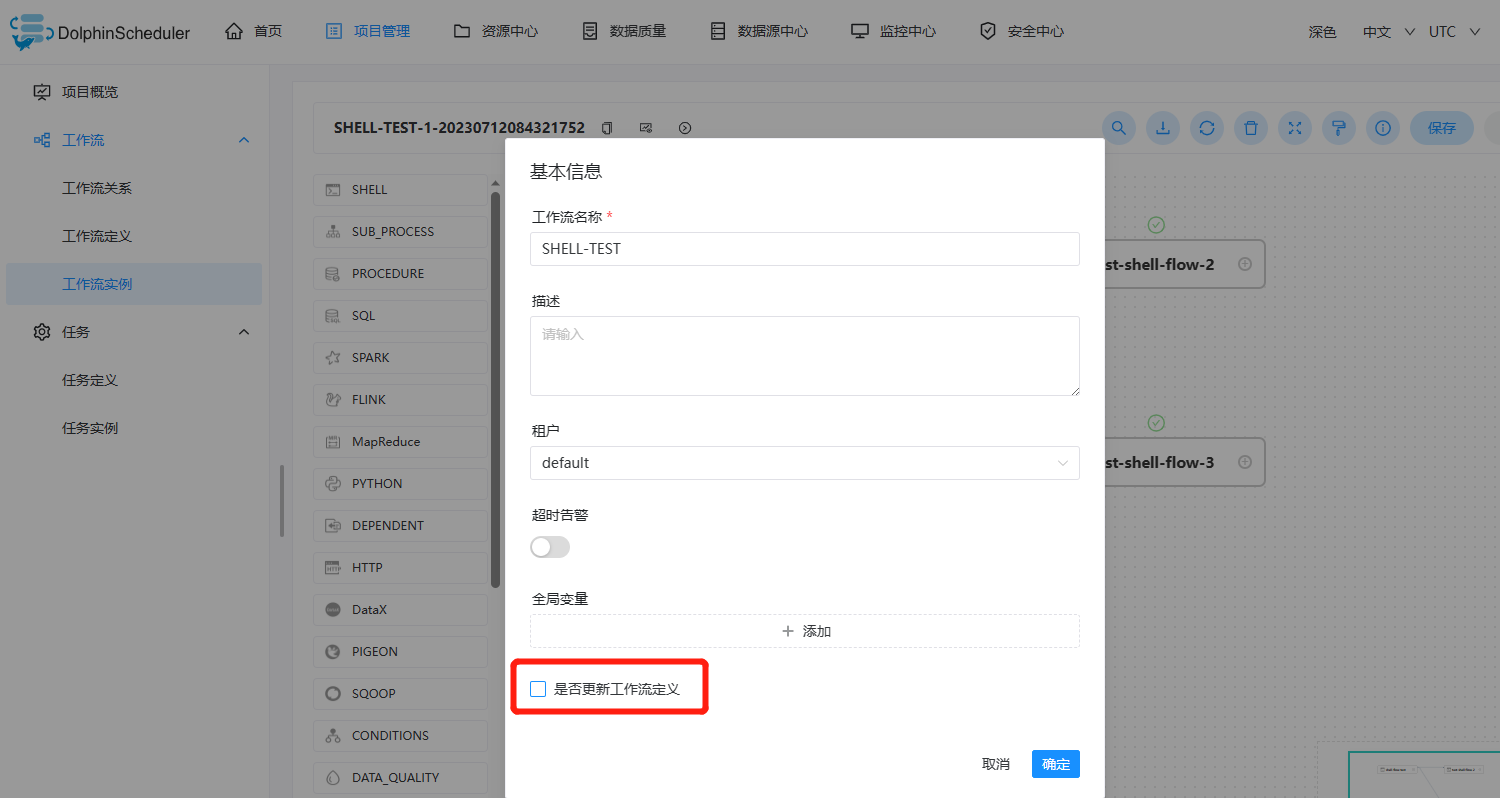
-
重跑: 重新执行已经终止的流程。
-
恢复失败: 针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行。
-
停止: 对正在运行的流程进行停止操作,后台会先
killworker 进程,再执行kill -9操作 -
暂停: 对正在运行的流程进行暂停操作,系统状态变为等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务。
-
恢复暂停: 对暂停的流程恢复,直接从暂停的节点开始运行
-
删除: 删除工作流实例及工作流实例下的任务实例
-
甘特图: Gantt 图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间.
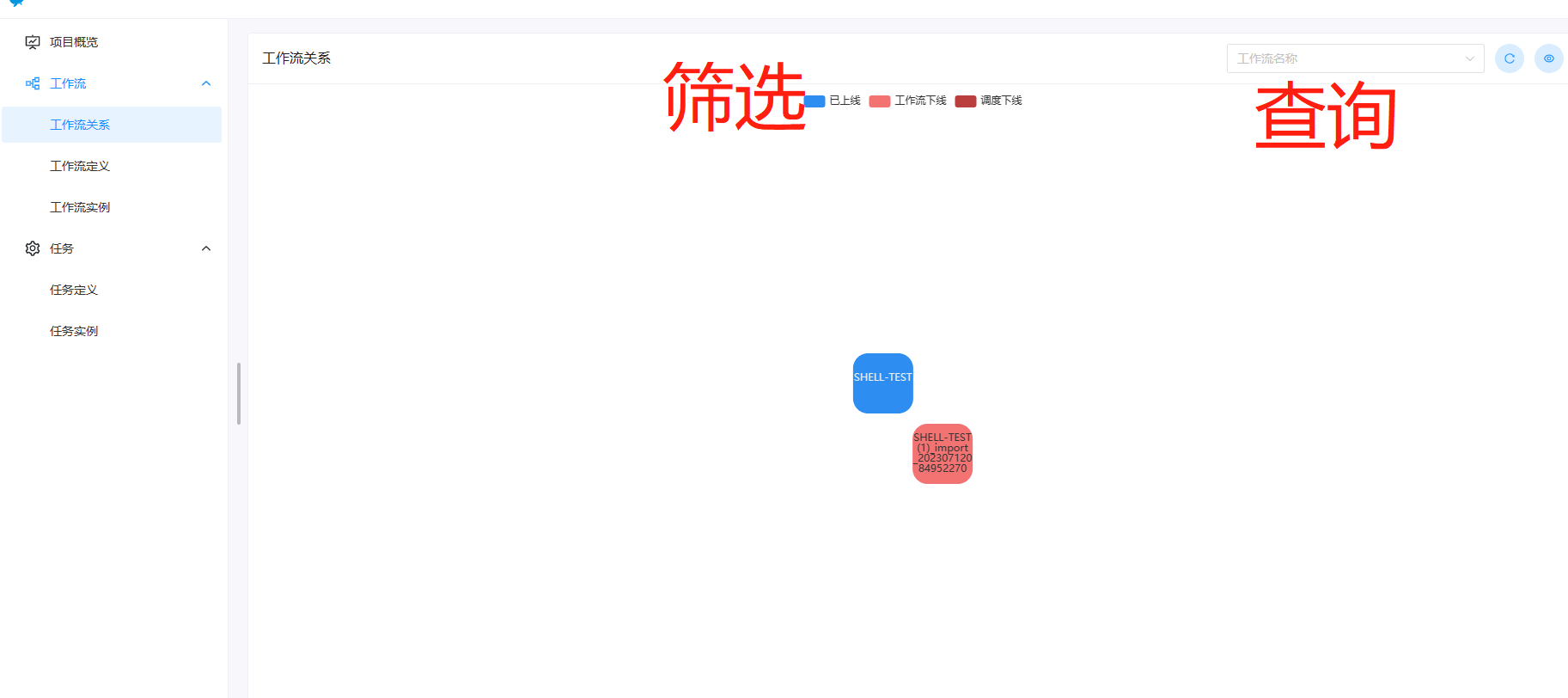
工作流关系
任务
任务定义
批量任务定义
批量任务定义允许您在基于任务级别而不是在工作流中操作修改任务。
单击特定的工作流,然后编辑任务的定义。
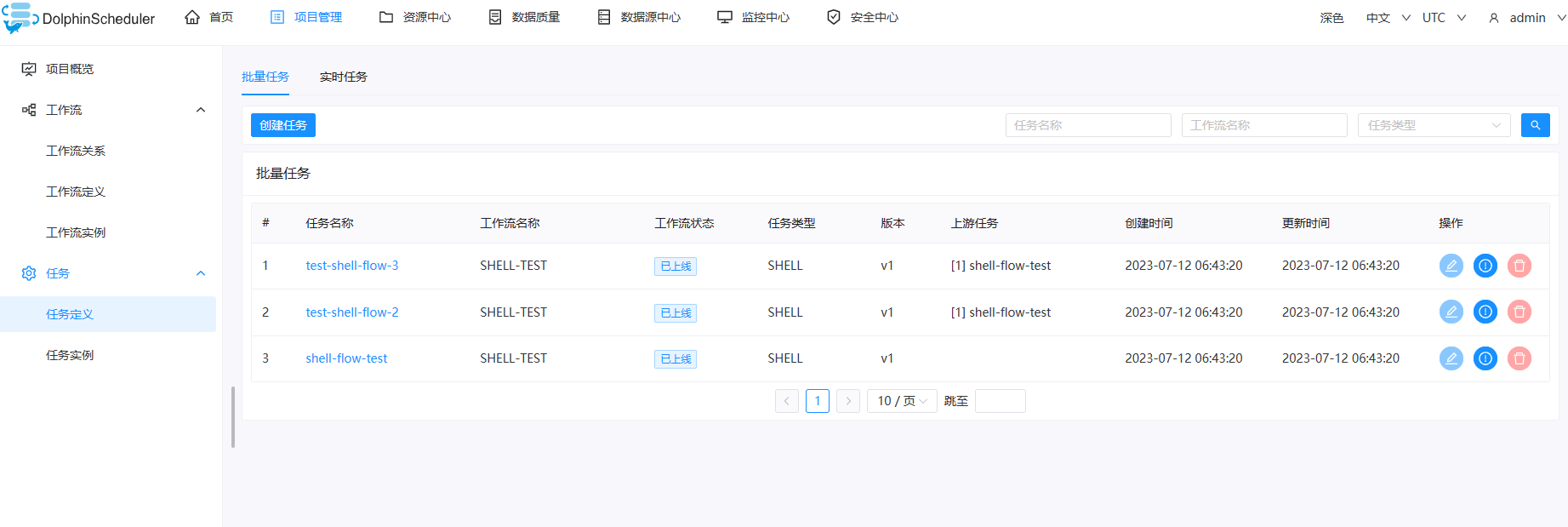
在该视图中,您可以通过单击 操作 列中的相关按钮来进行创建、查询、更新、删除任务定义。最令人兴奋的是您可以通过通配符进行全部任务查询,当您只
记得任务名称但忘记它属于哪个工作流时是非常有用的。也支持通过任务名称结合使用 任务类型 或 工作流程名称 进行查询。
任务实例
批量任务实例
- 点击项目管理->工作流->任务实例,进入任务实例页面,如下图所示,点击工作流实例名称,可跳转到工作流实例DAG图查看任务状态。
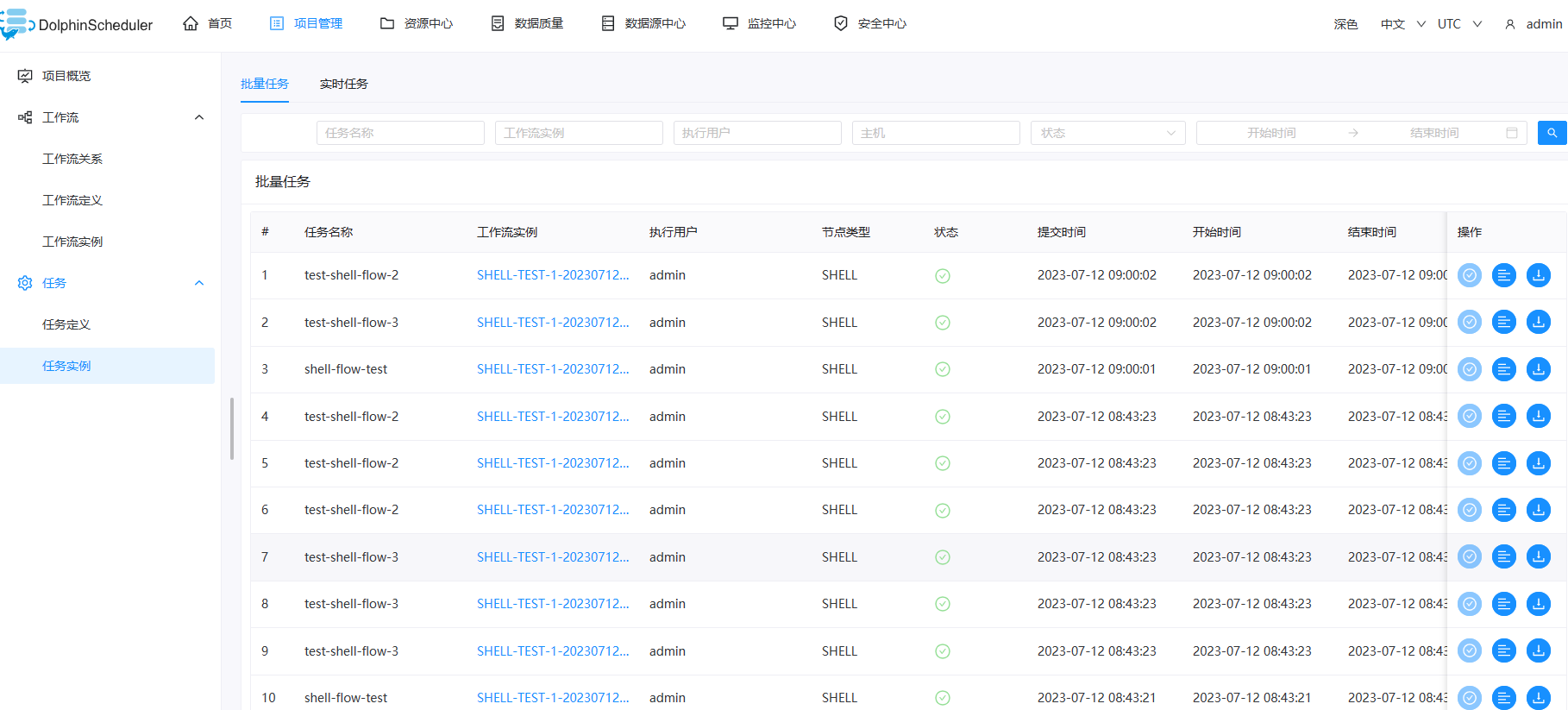
- 查看日志:点击操作列中的“查看日志”按钮,可以查看任务执行的日志情况。
资源中心
文件管理
当在调度过程中需要使用到第三方的 jar 或者用户需要自定义脚本的情况,可以通过在该页面完成相关操作。可创建的文件类型包括:txt/log/sh/conf/py/java 等。并且可以对文件进行编辑、重命名、下载和删除等操作。
注意:
- 当您以
admin身份等入并操作文件时,需要先给admin设置租户
基础操作
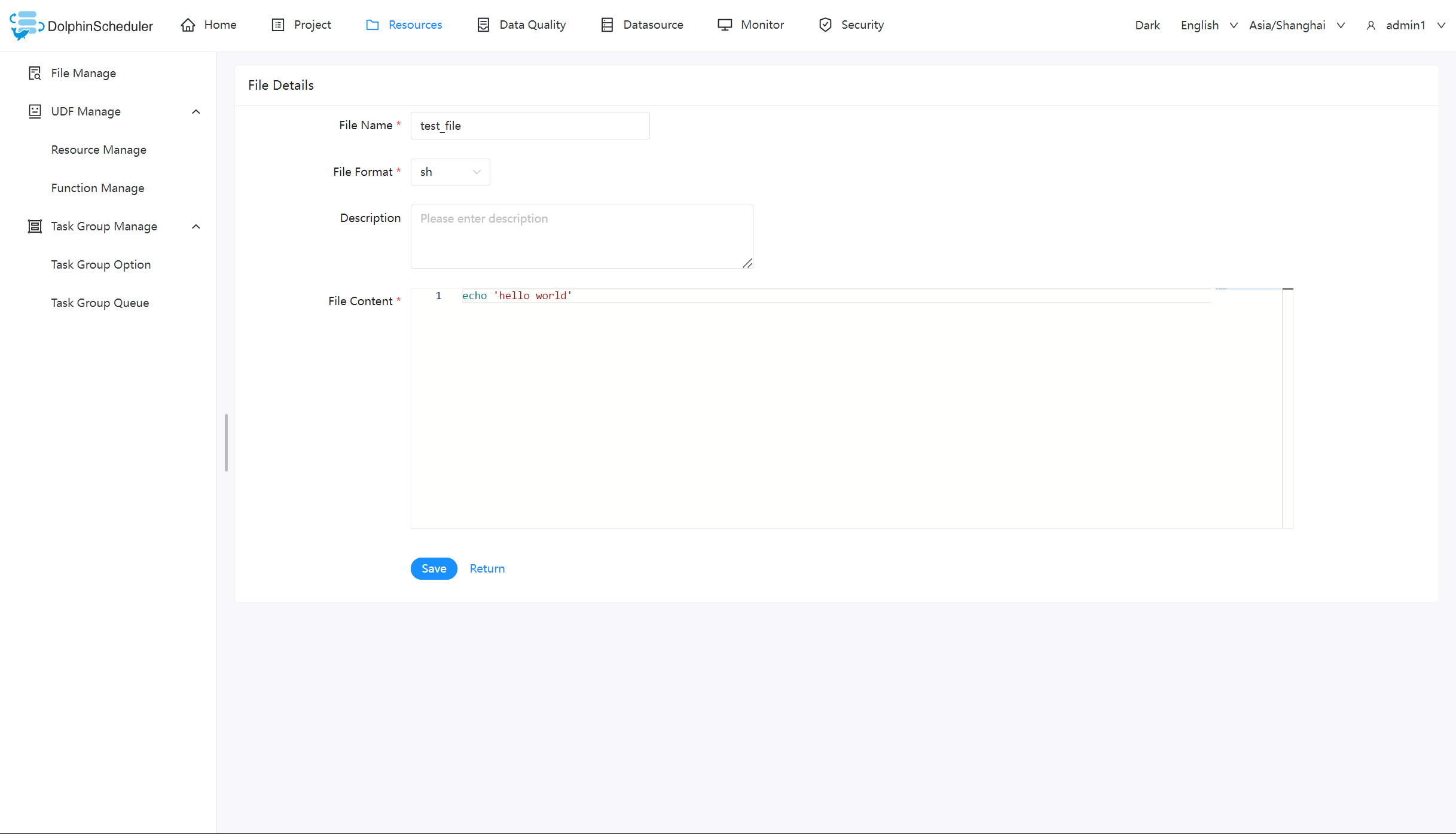
创建文件
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
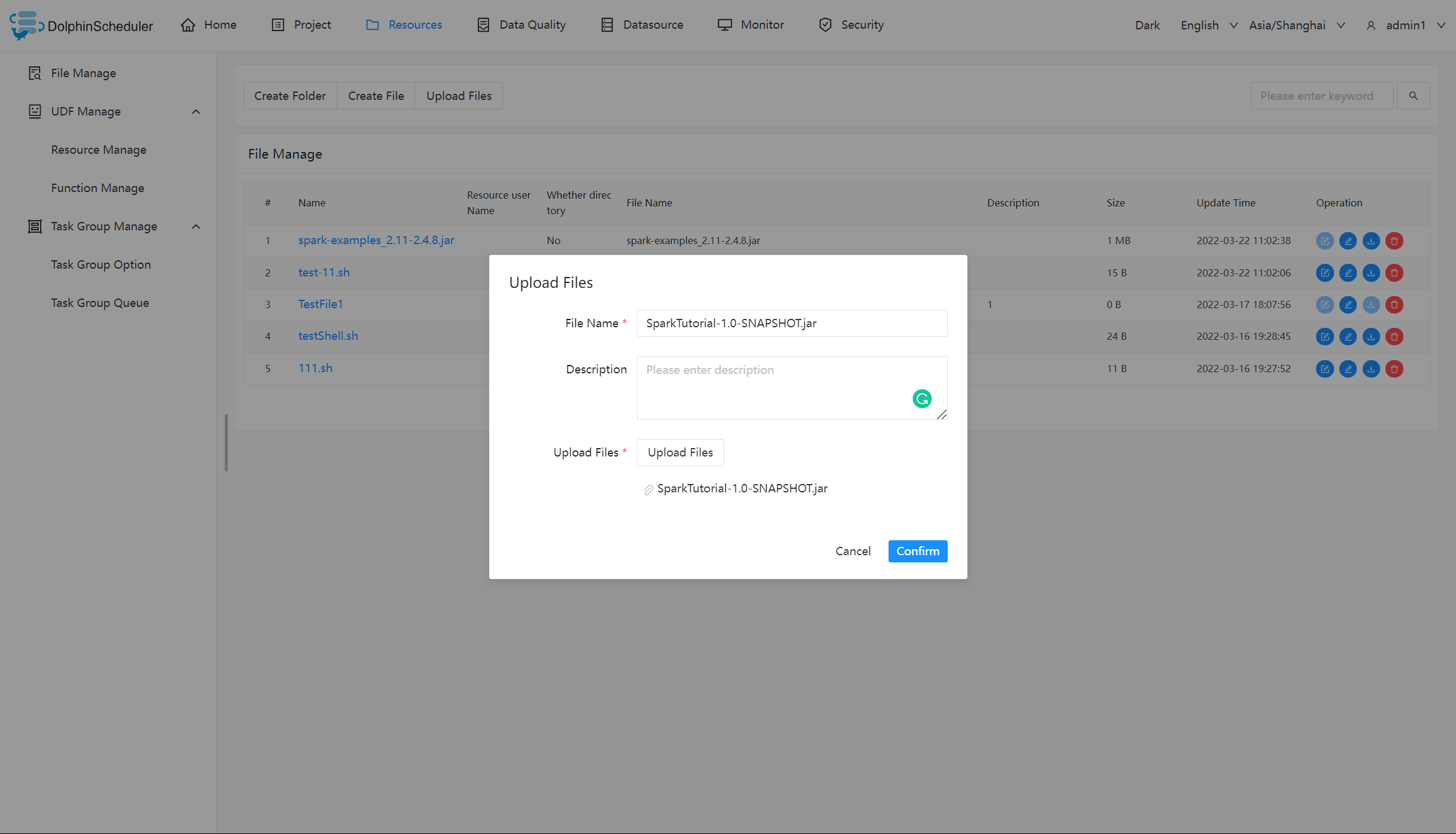
上传文件
上传文件:点击"上传文件"按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
文件查看
对可查看的文件类型,点击文件名称,可查看文件详情
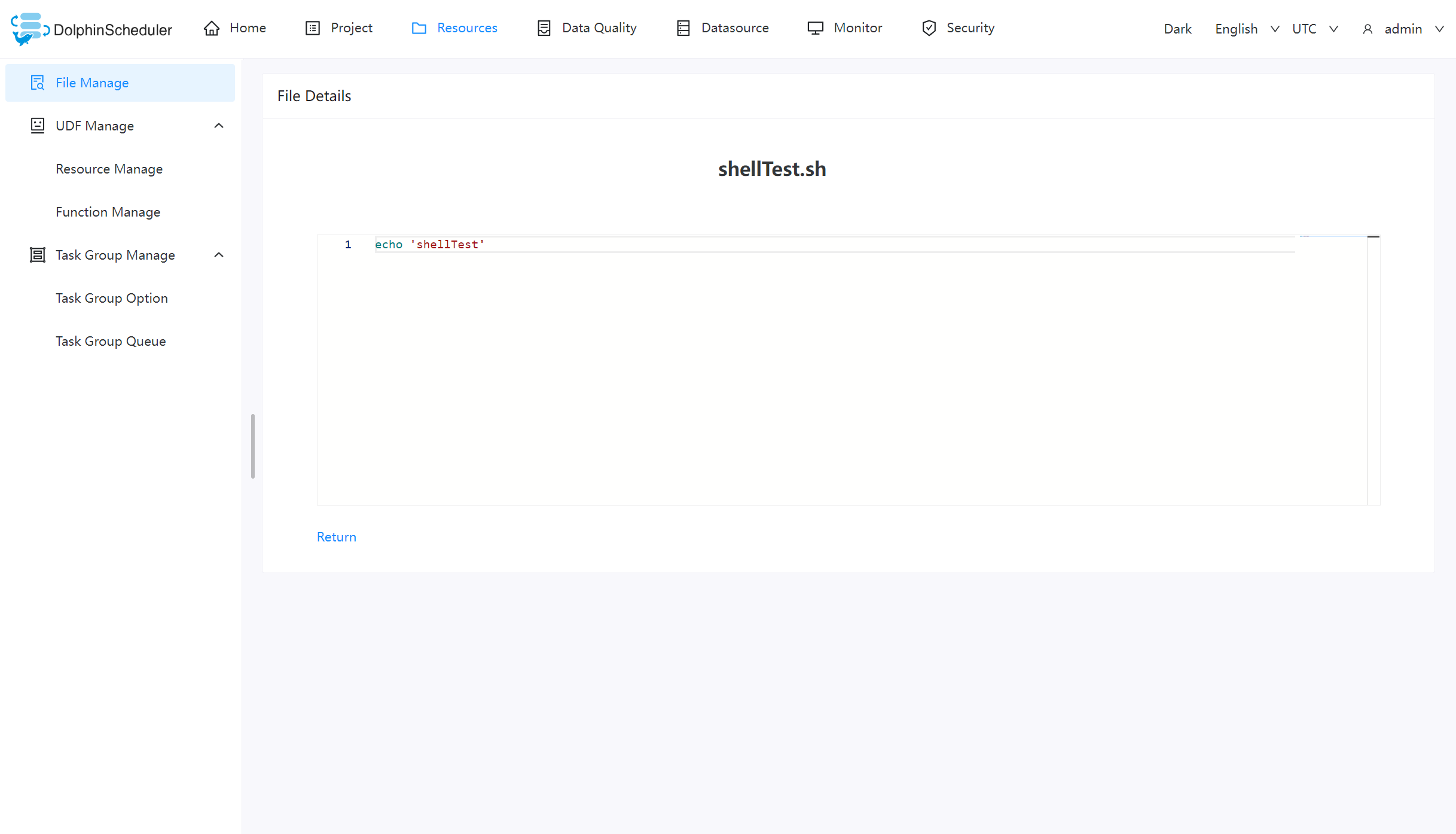
下载文件
点击文件列表的"下载"按钮下载文件或者在文件详情中点击右上角"下载"按钮下载文件
文件重命名
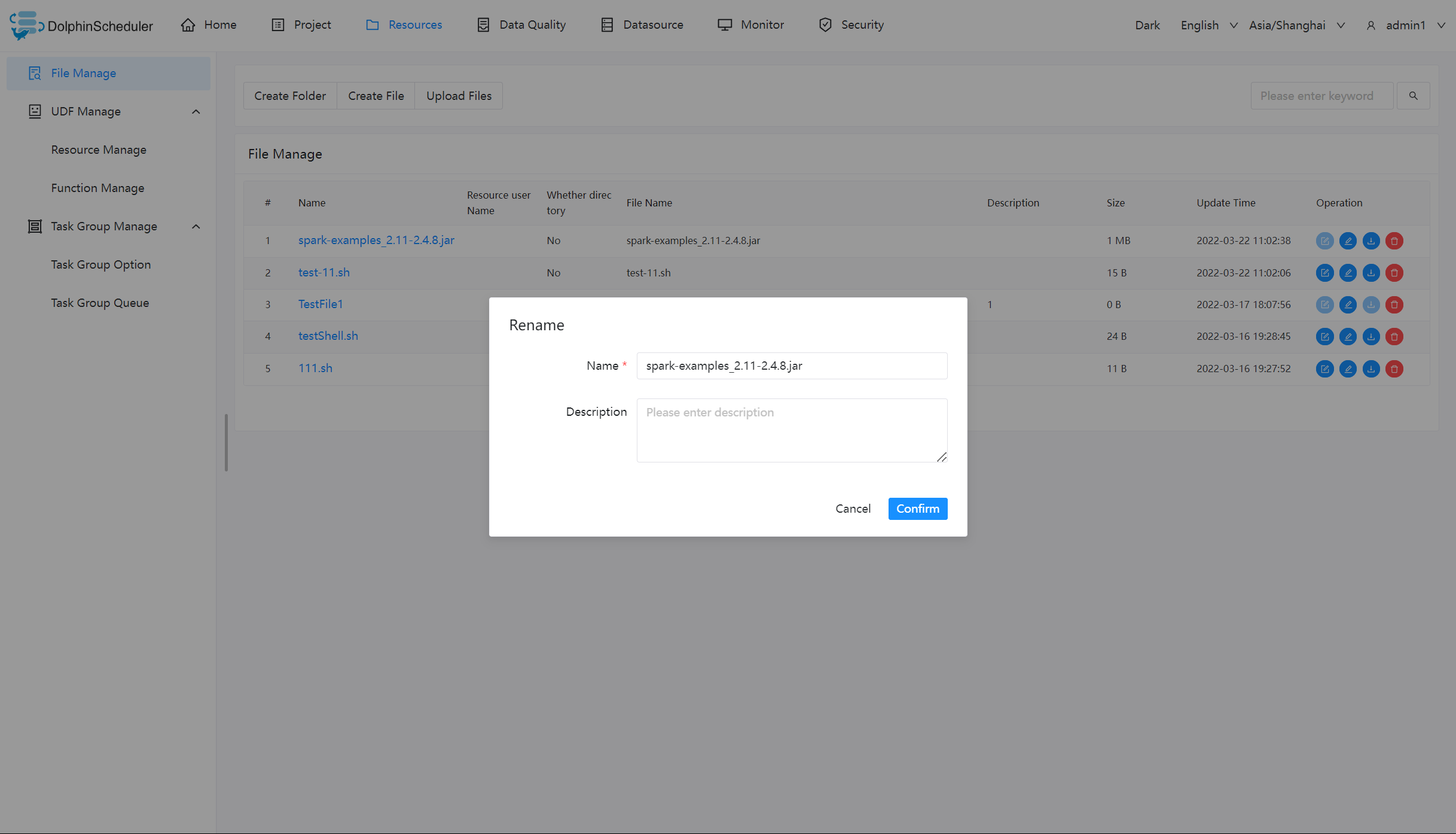
删除文件
文件列表->点击"删除"按钮,删除指定文件
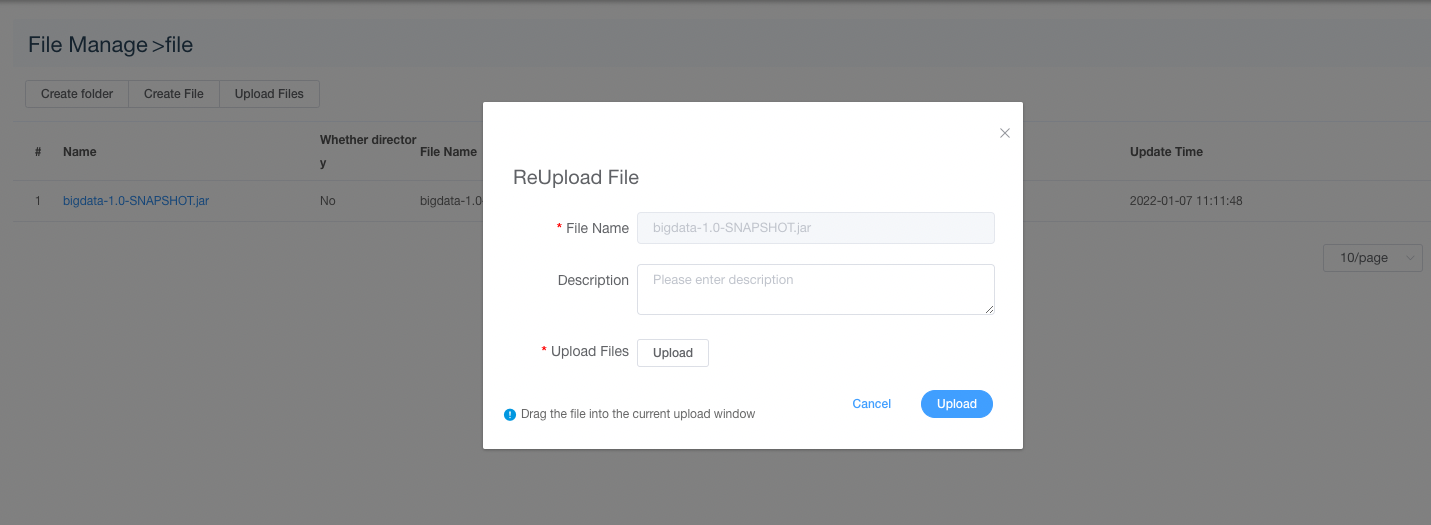
重新上传文件
点击文件列表中的”重新上传文件“按钮进行重新上传文件,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
注意:上传、创建、重命名文件时,文件名和源文件名(上传时)均不能带有
.以及/特殊符号。
任务样例
该样例主要通过一个简单的 shell 脚本,来演示如何在工作流定义中使用资源中心的文件。像 MR、Spark 等任务需要用到 jar 包,也是同理。
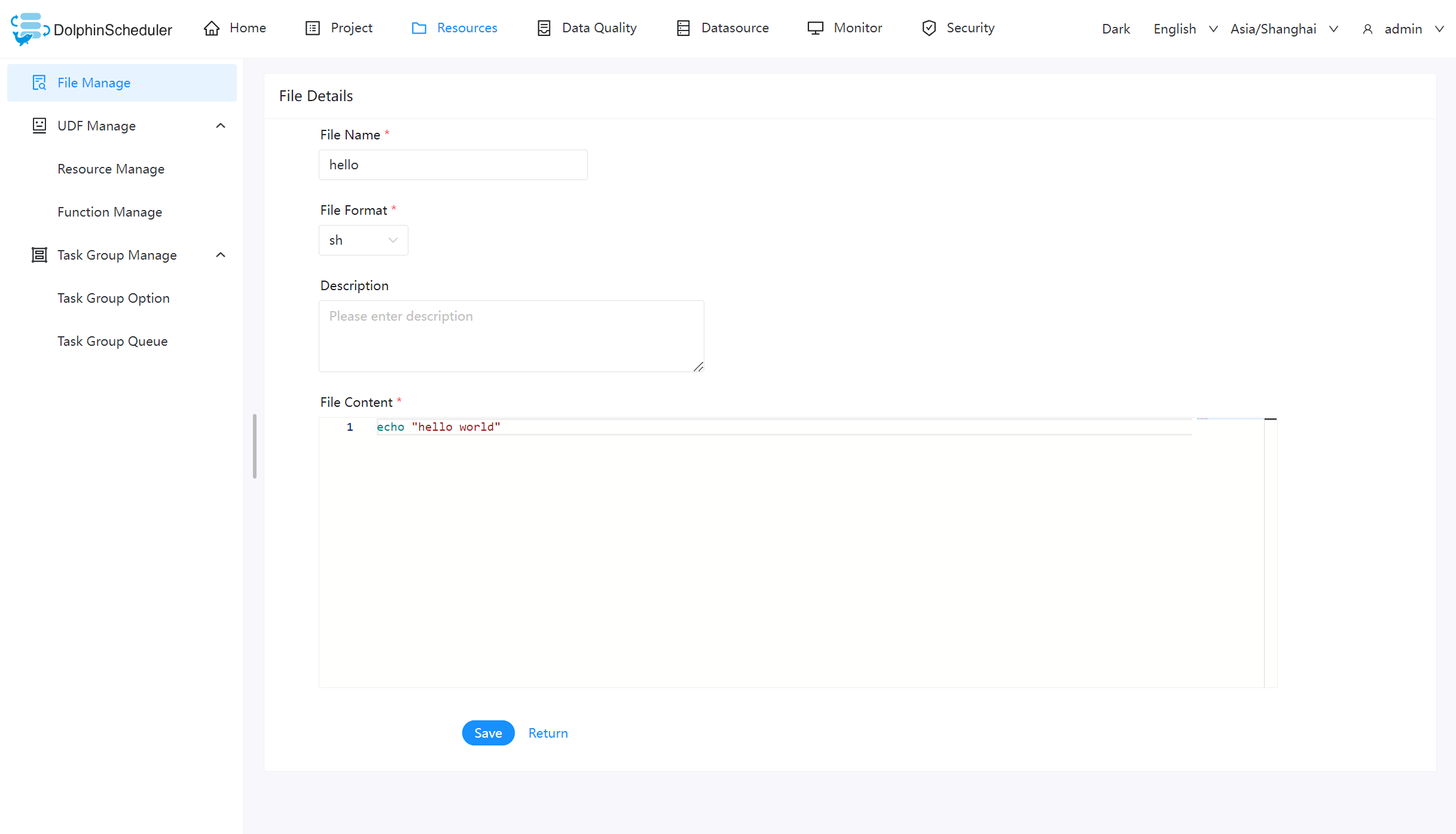
创建 shell 文件
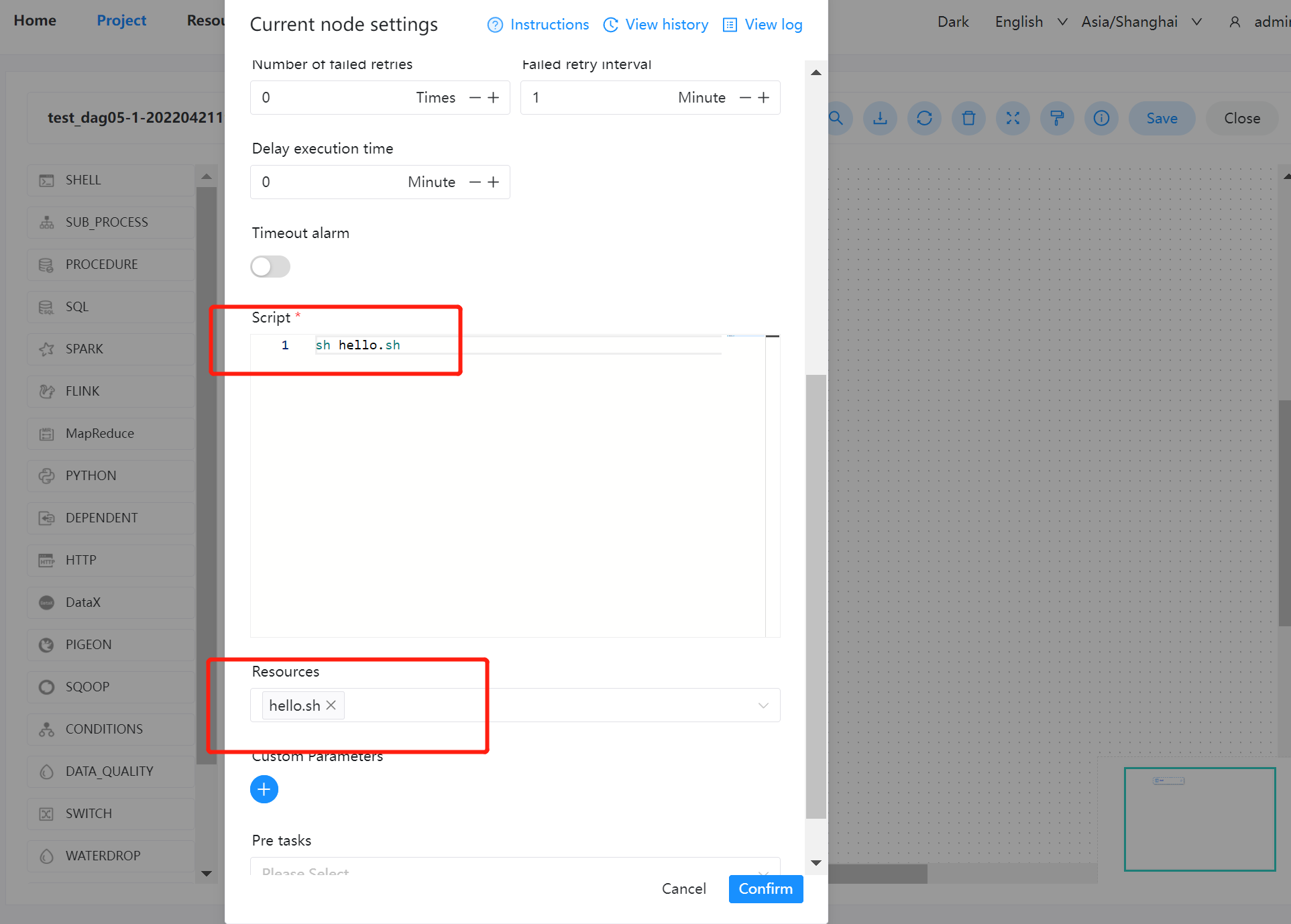
创建一个 shell 文件,输出 “hello world”。
创建工作流执行文件
在项目管理的工作流定义模块,创建一个新的工作流,使用 shell 任务。
- 脚本:
sh hello.sh - 资源:选择
hello.sh
注意:脚本中选择资源文件时文件名称需要保持和所选择资源全路径一致:
例如:资源路径为/resource/hello.sh则脚本中调用需要使用/resource/hello.sh全路径
查看结果
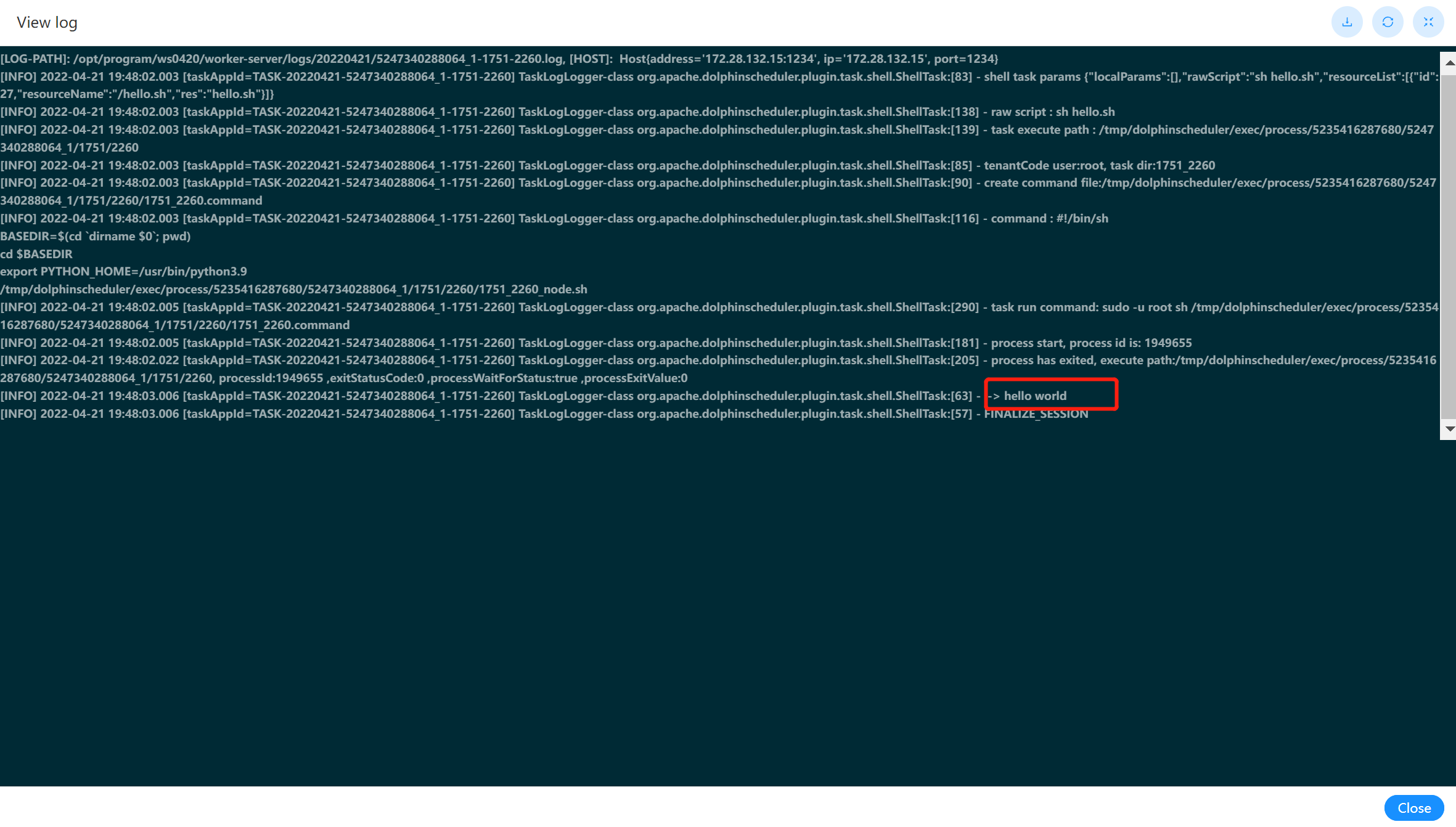
可以在工作流实例中,查看该节点运行的日志结果。如下图:
UDF 管理
- 资源管理和文件管理功能类似,不同之处是资源管理是上传的 UDF 函数,文件管理上传的是用户程序,脚本及配置文件。
- 主要包括以下操作:重命名、下载、删除等。
- 上传 UDF 资源
和上传文件相同。
函数管理
-
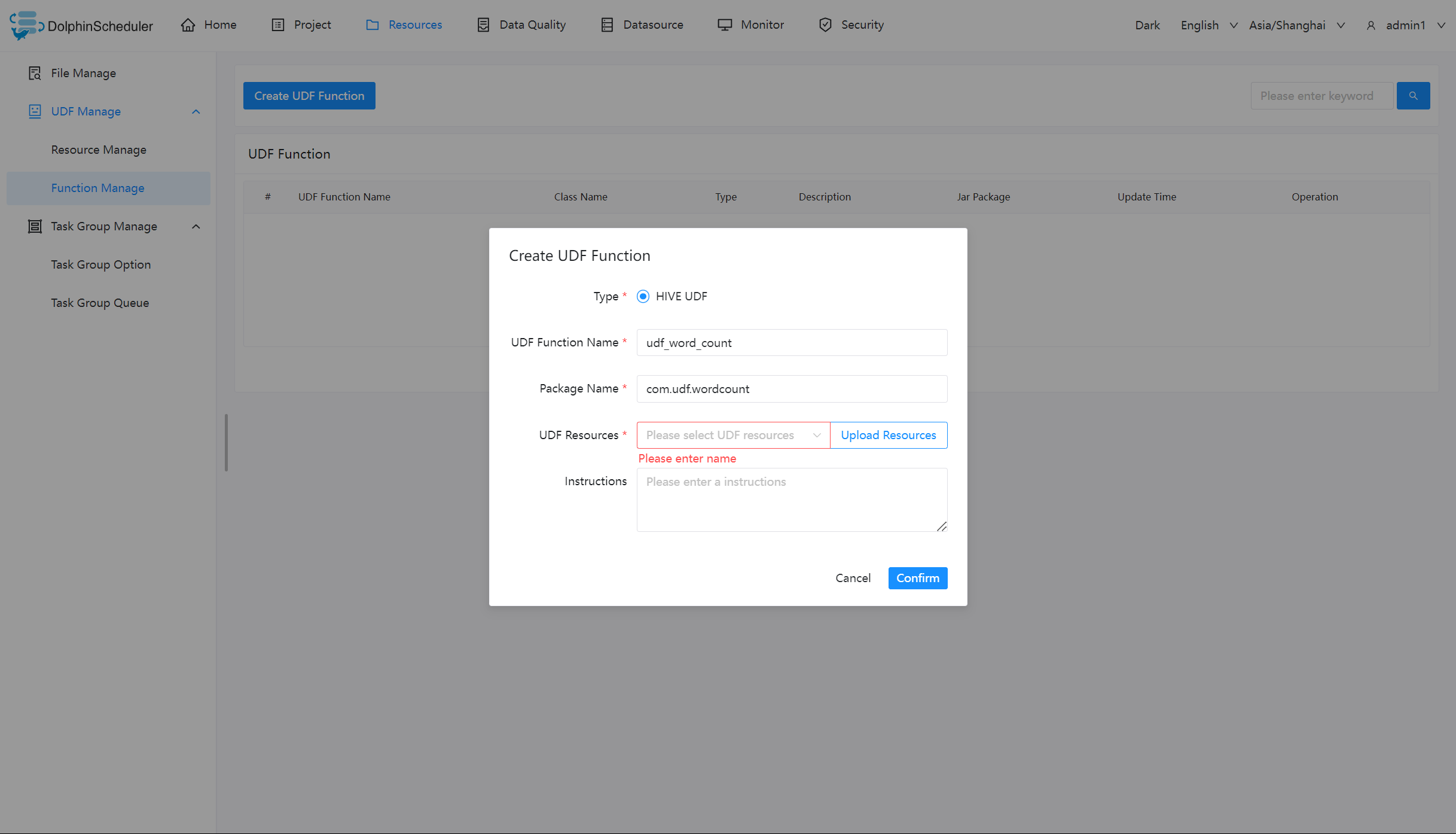
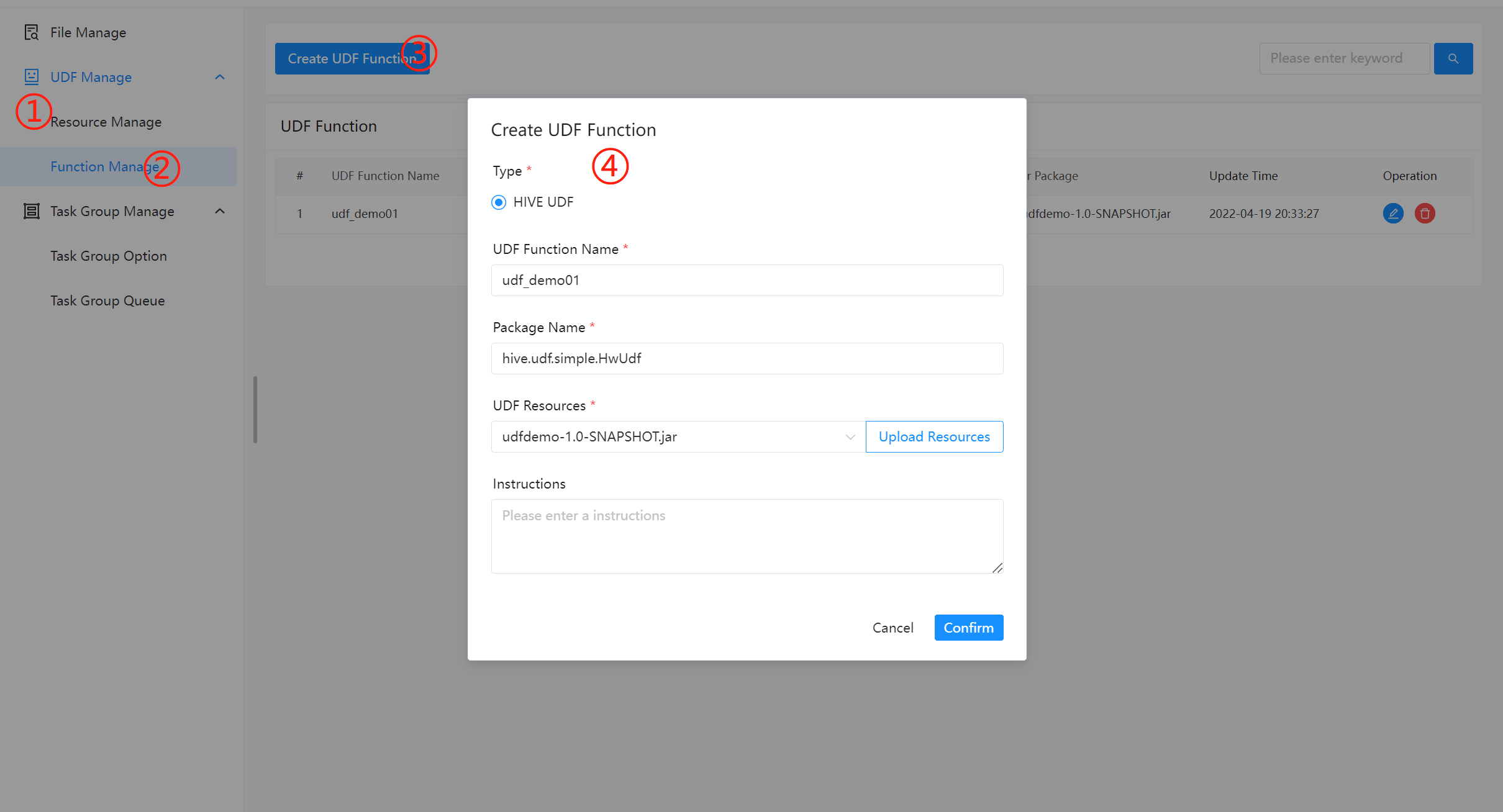
创建 UDF 函数
点击“创建 UDF 函数”,输入 UDF 函数参数,选择udf资源,点击“提交”,创建 UDF 函数。
目前只支持 HIVE 的临时 UDF 函数
- UDF 函数名称:输入 UDF 函数时的名称
- 包名类名:输入 UDF 函数的全路径
- UDF 资源:设置创建的 UDF 对应的资源文件
任务样例
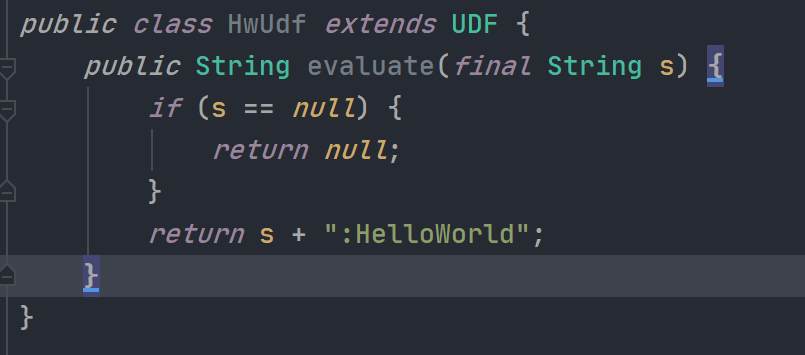
编写 UDF 函数
用户可以根据实际生产需求,自定义想要的 UDF 函数。这里编写一个在任意字符串的末尾添加 “HelloWorld” 的函数。如下图所示:
配置 UDF 函数
配置 UDF 函数前,需要先通过资源管理上传所需的函数 jar 包。然后进入函数管理,配置相关信息即可。如下图所示:
使用 UDF 函数
在使用 UDF 函数过程中,用户只需关注具体的函数编写,通过资源中心上传配置完成即可。系统会自动配置 create function 语句,参考如下:SqlTask
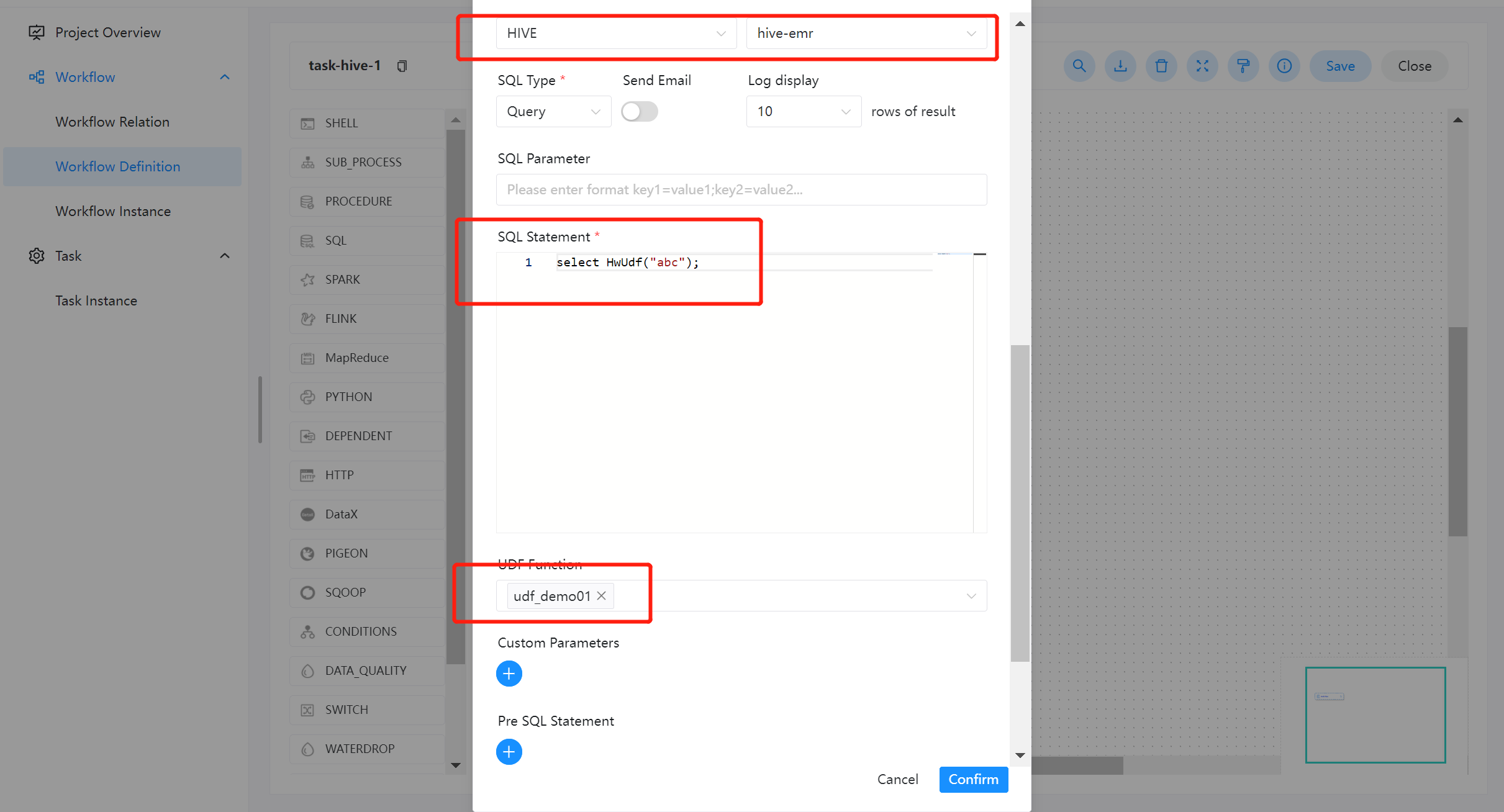
进入工作流定义一个 SQL 节点,数据源类型选择为 HIVE,数据源实例类型为 HIVE/IMPALA。
- SQL 语句:
select HwUdf("abc");该函数与内置函数使用方式一样,直接使用函数名称即可访问。 - UDF 函数:选择资源中心所配置的即可。
任务组管理
任务组主要用于控制任务实例并发,旨在控制其他资源的压力(也可以控制 Hadoop 集群压力,不过集群会有队列管控)。您可在新建任务定义时,可配置对应的任务组,并配置任务在任务组内运行的优先级。
任务组配置
新建任务组
用户点击【资源中心】-【任务组管理】-【任务组配置】-新建任务组
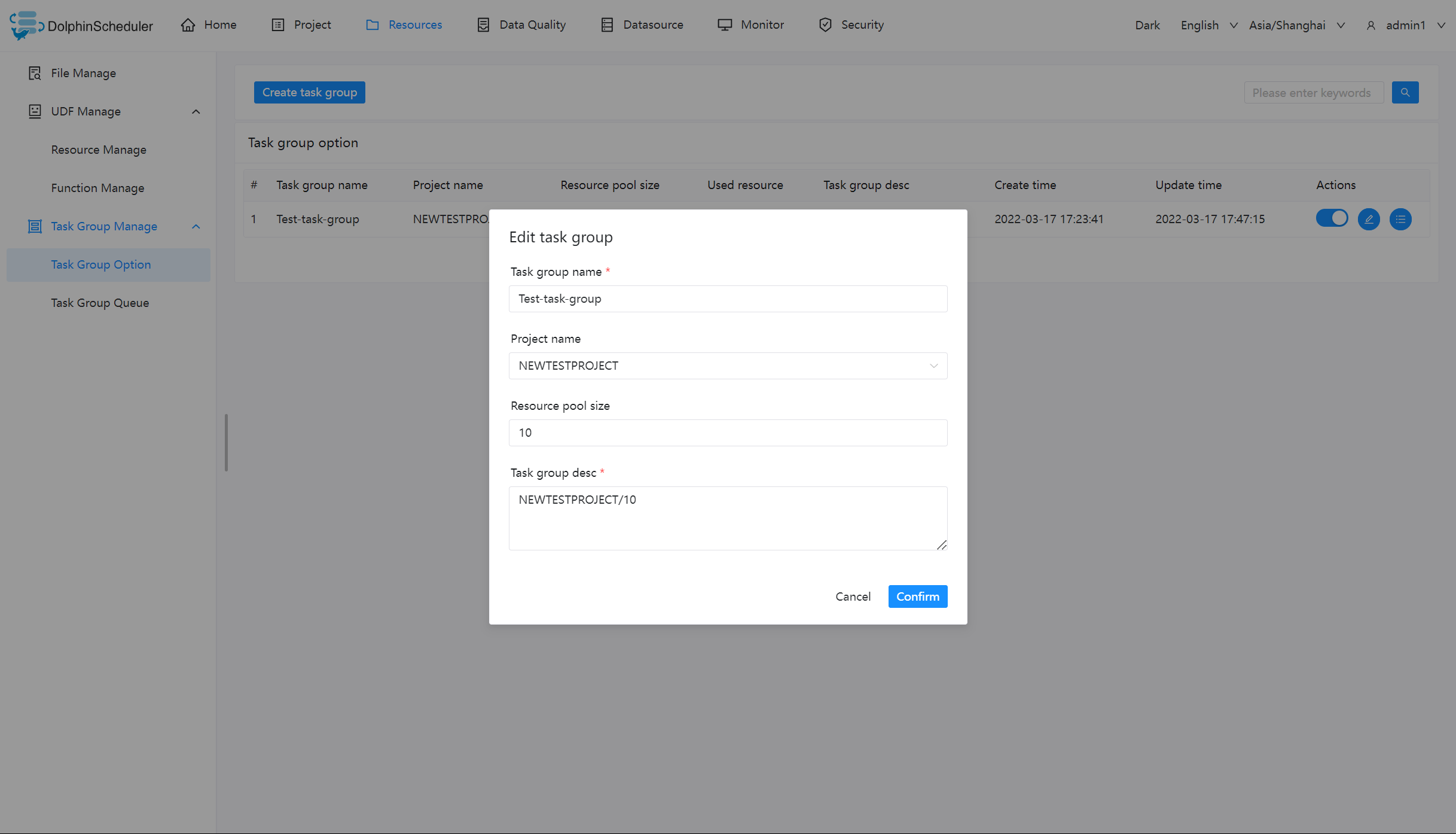
您需要输入图片中信息,其中
【任务组名称】:任务组在被使用时显示的名称
【项目名称】:任务组作用的项目,该项为非必选项,如果不选择,则整个系统所有项目均可使用该任务组。
【资源容量】:允许任务实例并发的最大数量
查看任务组队列
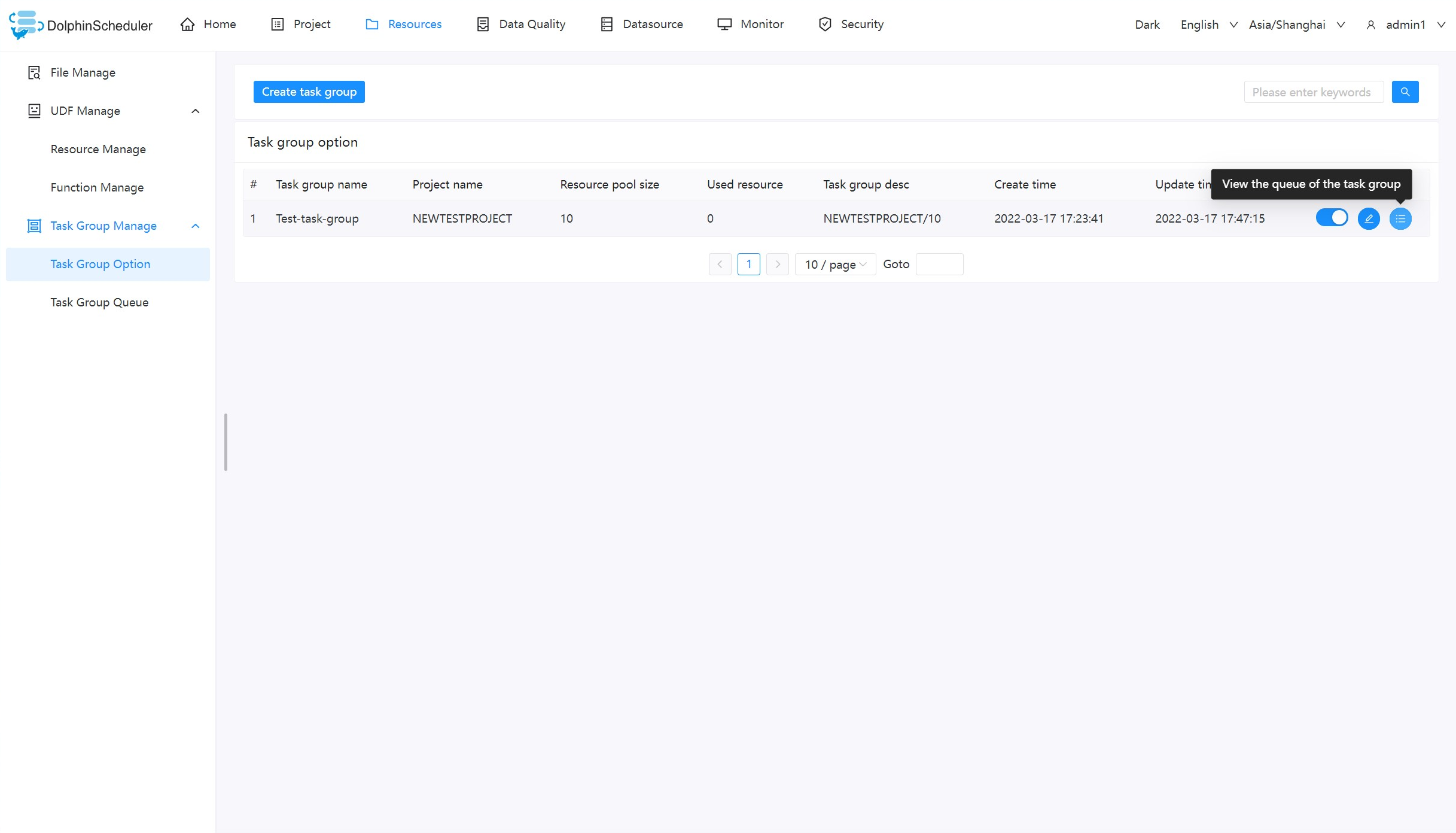
点击按钮查看任务组使用信息
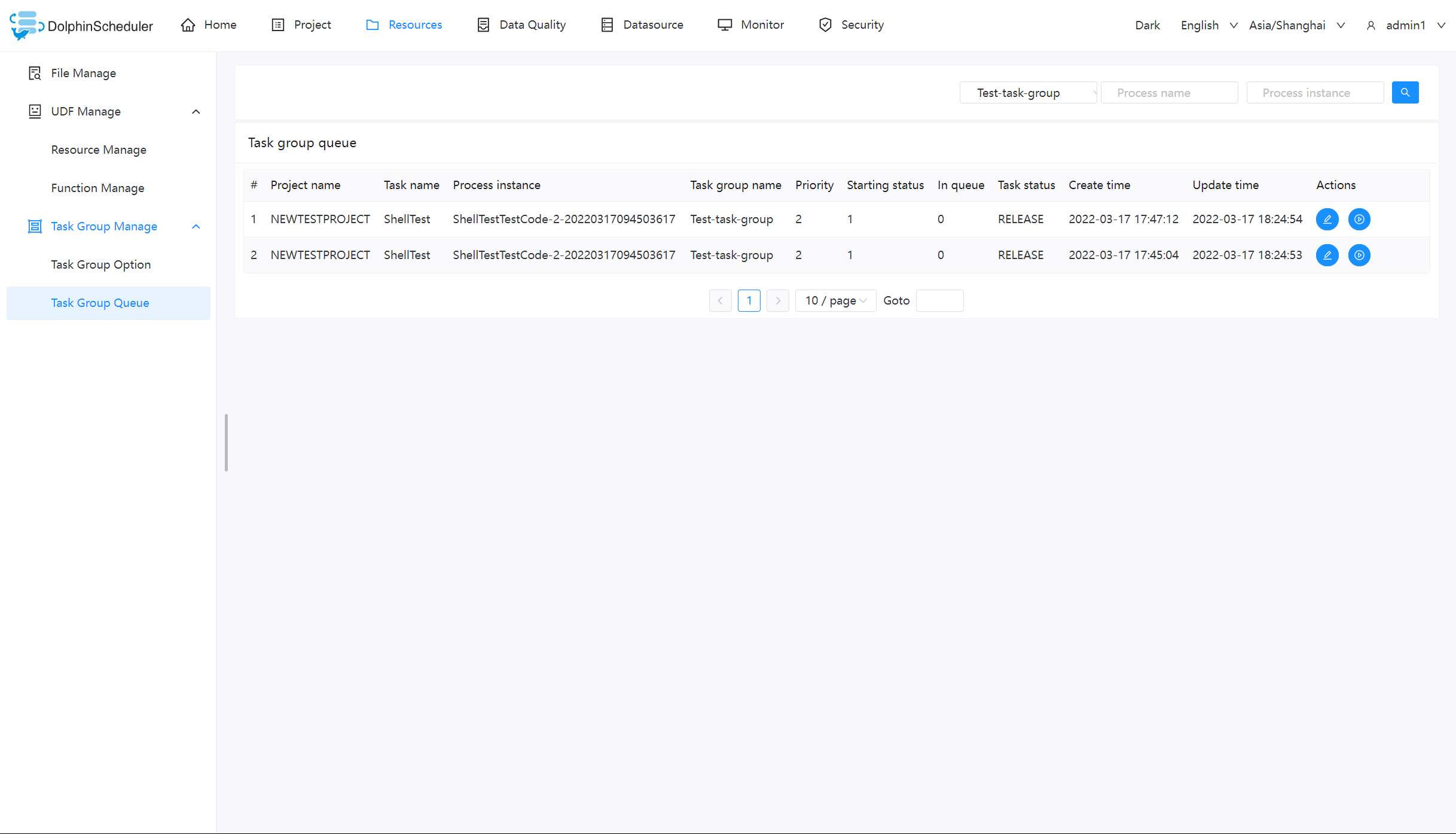
任务组的使用
注:任务组的使用适用于由 worker 执行的任务,例如【switch】节点、【condition】节点、【sub_process】等由 master 负责执行的节点类型不受任务组控制。
我们以 shell 节点为例:
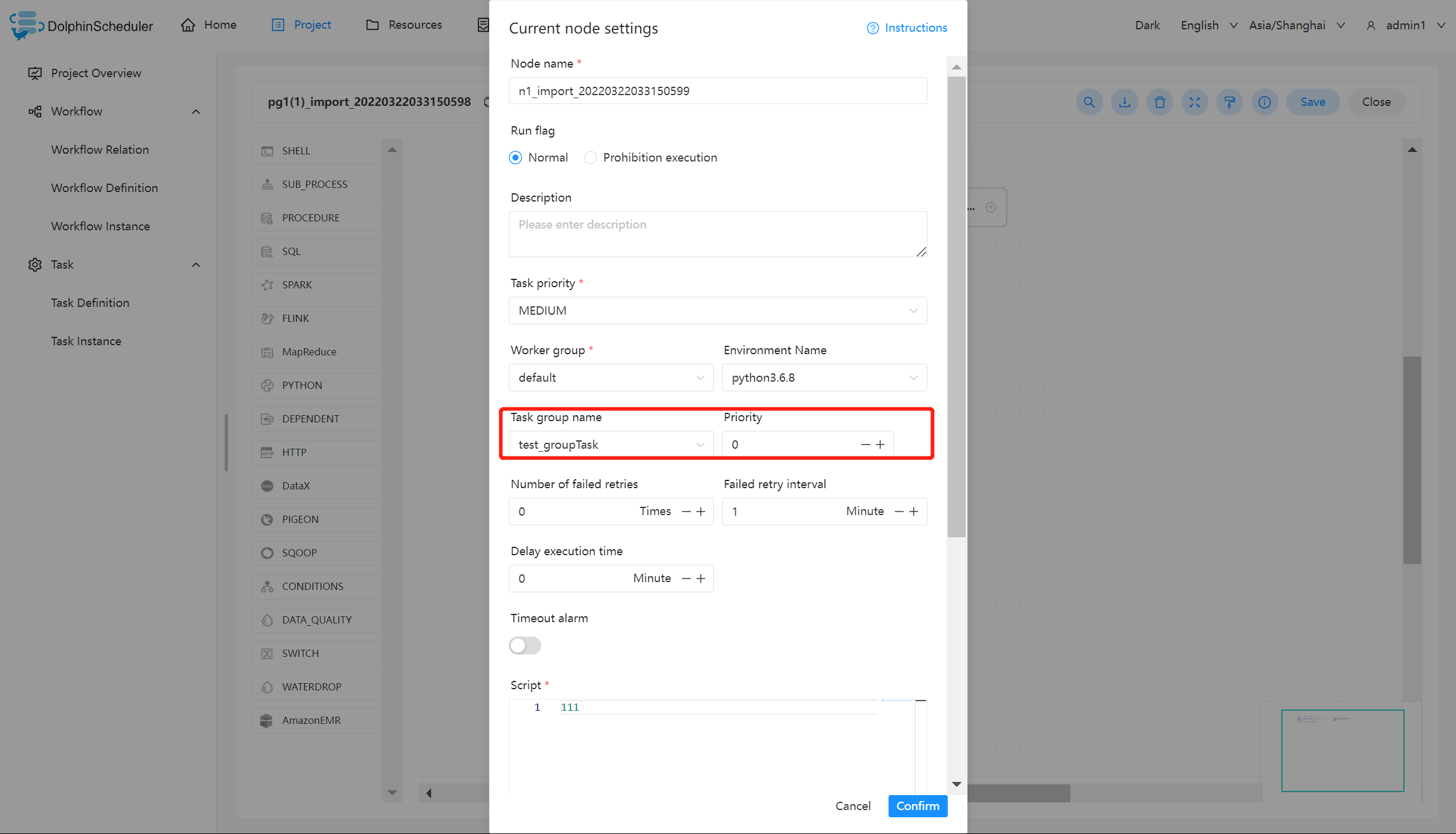
关于任务组的配置,您需要做的只需要配置红色框内的部分,其中:
【任务组名称】:任务组配置页面显示的任务组名称,这里只能看到该项目有权限的任务组(新建任务组时选择了该项目),或作用在全局的任务组(新建任务组时没有选择项目)
【组内优先级】:在出现等待资源时,优先级高的任务会最先被 master 分发给 worker 执行,该部分数值越大,优先级越高。
任务组的实现逻辑
获取任务组资源:
Master 在分发任务时判断该任务是否配置了任务组,如果任务没有配置,则正常抛给 worker 运行;如果配置了任务组,在抛给 worker 执行之前检查任务组资源池剩余大小是否满足当前任务运行,如果满足资源池 -1,继续运行;如果不满足则退出任务分发,等待其他任务结束唤醒。
释放与唤醒:
当获取到任务组资源的任务结束运行后,会释放任务组资源,释放后会检查当前任务组是否有任务等待,如果有则标记优先级最好的任务可以运行,并新建一个可以执行的event。该event中存储着被标记可以获取资源的任务id,随后在获取任务组资源然后运行。
数据质量
任务类型介绍
数据质量任务是用于检查数据在集成、处理过程中的数据准确性。本版本的数据质量任务包括单表检查、单表自定义SQL检查、多表准确性以及两表值比对。数据质量任务的运行环境为Spark2.4.0,其他版本尚未进行过验证,用户可自行验证。
- 数据质量任务的执行逻辑如下:
用户在界面定义任务,用户输入值保存在
TaskParam中 运行任务时,Master会解析TaskParam,封装DataQualityTask所需要的参数下发至Worker。 Worker运行数据质量任务,数据质量任务在运行结束之后将统计结果写入到指定的存储引擎中,当前数据质量任务结果存储在dolphinscheduler的t_ds_dq_execute_result表中Worker发送任务结果给Master,Master收到TaskResponse之后会判断任务类型是否为DataQualityTask,如果是的话会根据taskInstanceId从t_ds_dq_execute_result中读取相应的结果,然后根据用户配置好的检查方式,操作符和阈值进行结果判断,如果结果为失败的话,会根据用户配置好的的失败策略进行相应的操作,告警或者中断
注意事项
添加配置信息:<server-name>/conf/common.properties
data-quality.jar.name=dolphinscheduler-data-quality-dev-SNAPSHOT.jar
- 这里的
data-quality.jar.name请根据实际打包的名称来填写。 - 如果单独打包
data-quality的话,记得修改包名和data-quality.jar.name一致。 - 如果是老版本升级使用,运行之前需要先执行
SQL更新脚本进行数据库初始化。 - 当前
dolphinscheduler-data-quality-dev-SNAPSHOT.jar是瘦包,不包含任何JDBC驱动。 如果有JDBC驱动需要,可以在节点设置选项参数处设置--jars参数, 如:--jars /lib/jars/mysql-connector-java-8.0.16.jar。 - 当前只测试了
MySQL、PostgreSQL和HIVE数据源,其他数据源暂时未测试过。 Spark需要配置好读取Hive元数据,Spark不是采用JDBC的方式读取Hive。
检查逻辑详解
-
校验公式:[校验方式][操作符][阈值],如果结果为真,则表明数据不符合期望,执行失败策略
-
校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
-
操作符:=、>、>=、<、<=、!=
-
期望值类型
- 固定值
- 日均值
- 周均值
- 月均值
- 最近7天均值
- 最近30天均值
- 源表总行数
- 目标表总行数
-
例子
- 校验方式为:[Expected-Actual][期望值-实际值]
- [操作符]:>
- [阈值]:0
- 期望值类型:固定值=9。
假设实际值为10,操作符为 >, 期望值为9,那么结果 10 -9 > 0 为真,那就意味列为空的行数据已经超过阈值,任务被判定为失败
单表检查之空值检查
检查介绍
空值检查的目标是检查出指定列为空的行数,可将为空的行数与总行数或者指定阈值进行比较,如果大于某个阈值则判定为失败
- 计算指定列为空的SQL语句如下:
SELECT COUNT(*) AS miss FROM ${src_table} WHERE (${src_field} is null or ${src_field} = '') AND (${src_filter})
-
计算表总行数的SQL如下:
SELECT COUNT(*) AS total FROM ${src_table} WHERE (${src_filter})
界面操作指南
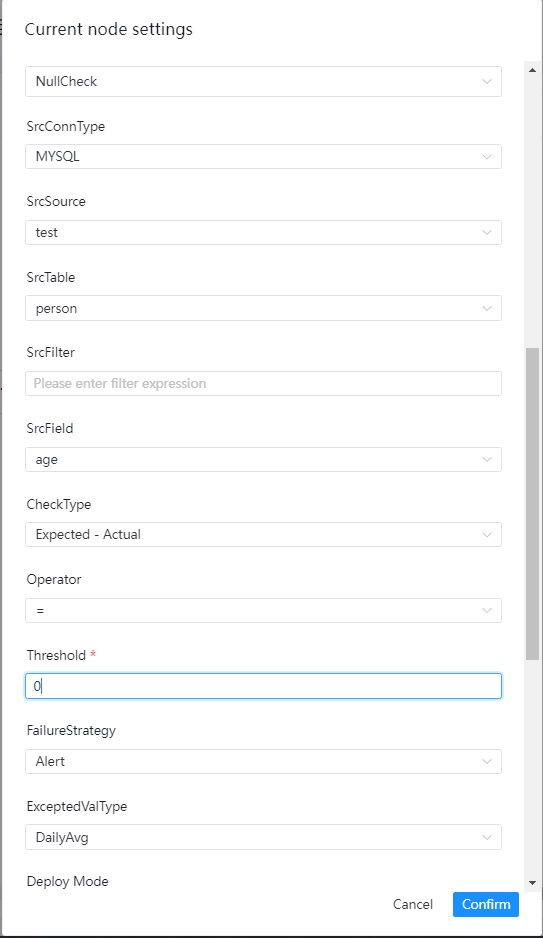
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之及时性检查
检查介绍
及时性检查用于检查数据是否在预期时间内处理完成,可指定开始时间、结束时间来界定时间范围,如果在该时间范围内的数据量没有达到设定的阈值,那么会判断该检查任务为失败
界面操作指南
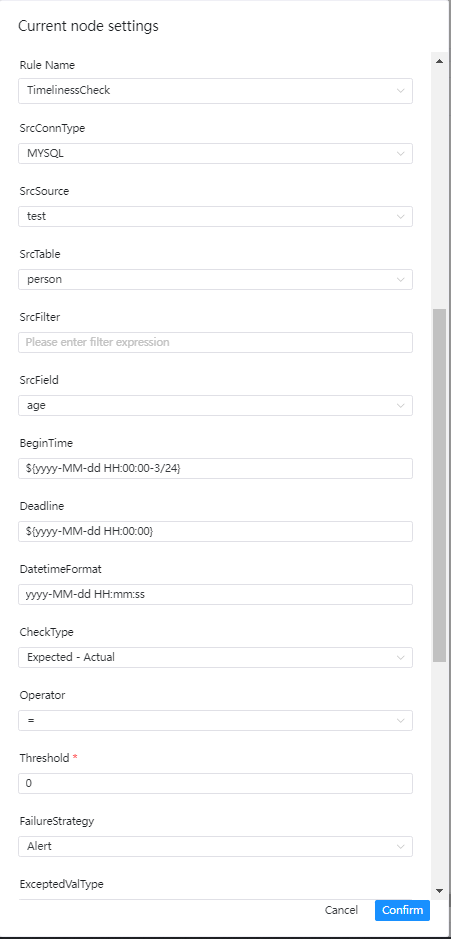
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 起始时间:某个时间范围的开始时间
- 结束时间:某个时间范围的结束时间
- 时间格式:设置对应的时间格式
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之字段长度校验
检查介绍
字段长度校验的目标是检查所选字段的长度是否满足预期,如果有存在不满足要求的数据,并且行数超过阈值则会判断任务为失败
界面操作指南
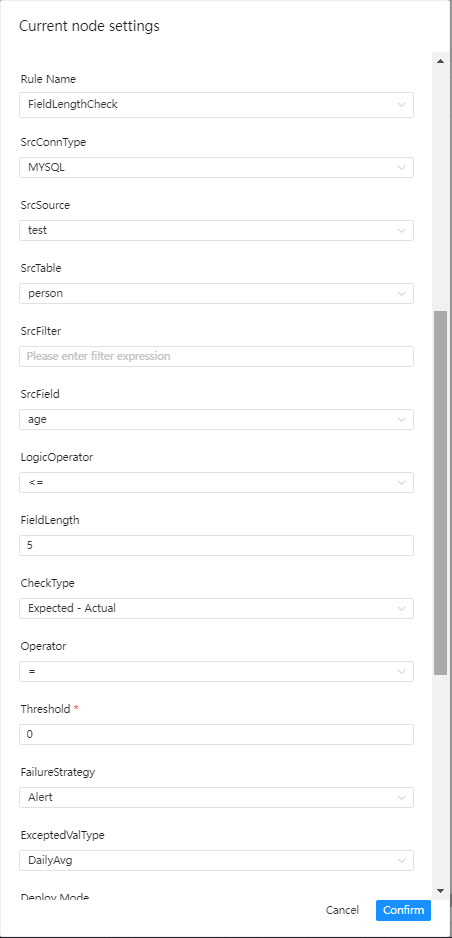
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 逻辑操作符:=,>、>=、<、<=、!=
- 字段长度限制:如标题
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之唯一性校验
检查介绍
唯一性校验的目标是检查字段是否存在重复的情况,一般用于检验primary key是否有重复,如果存在重复且达到阈值,则会判断检查任务为失败
界面操作指南
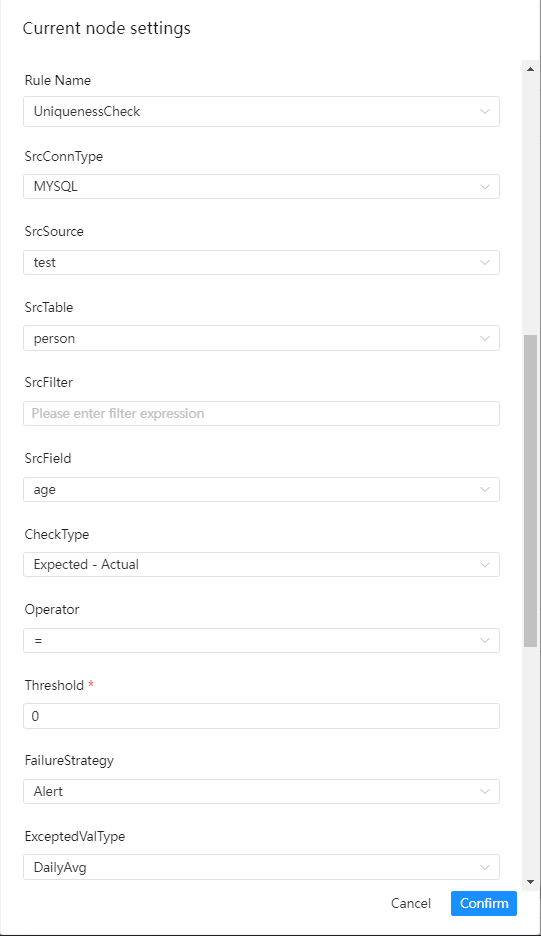
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之正则表达式校验
检查介绍
正则表达式校验的目标是检查某字段的值的格式是否符合要求,例如时间格式、邮箱格式、身份证格式等等,如果存在不符合格式的数据并超过阈值,则会判断任务为失败
界面操作指南
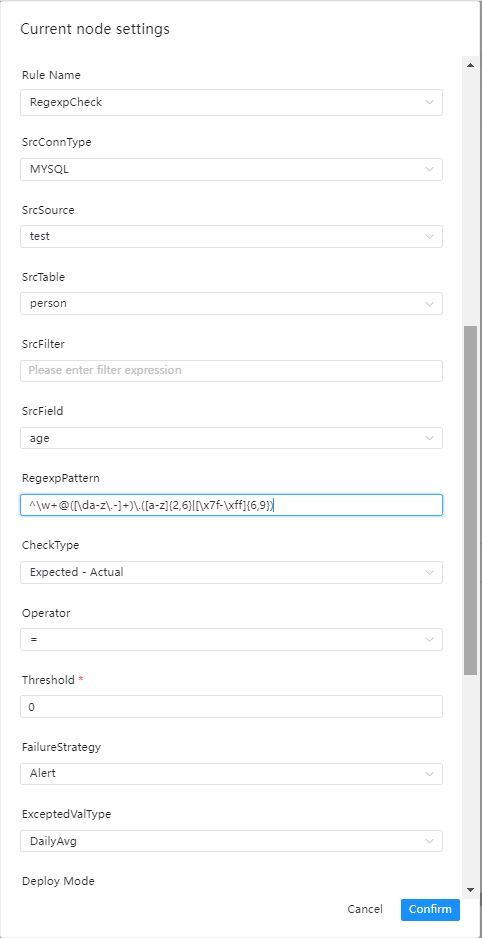
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 正则表达式:如标题
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之枚举值校验
检查介绍
枚举值校验的目标是检查某字段的值是否在枚举值的范围内,如果存在不在枚举值范围里的数据并超过阈值,则会判断任务为失败
界面操作指南
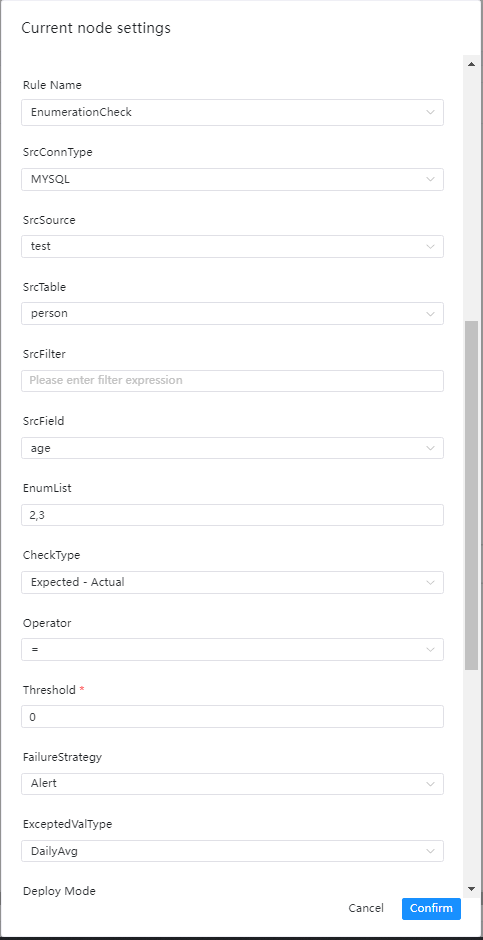
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源表过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 枚举值列表:用英文逗号,隔开
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之表行数校验
检查介绍
表行数校验的目标是检查表的行数是否达到预期的值,如果行数未达标,则会判断任务为失败
界面操作指南
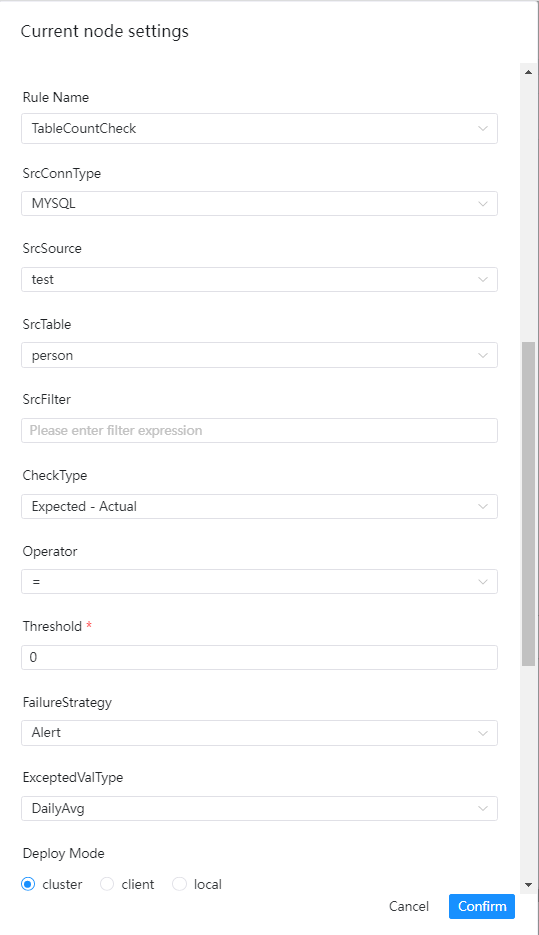
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 源表检查列:下拉选择检查列名
- 校验方式:
- [Expected-Actual][期望值-实际值]
- [Actual-Expected][实际值-期望值]
- [Actual/Expected][实际值/期望值]x100%
- [(Expected-Actual)/Expected][(期望值-实际值)/期望值]x100%
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
单表检查之自定义SQL检查
检查介绍
界面操作指南
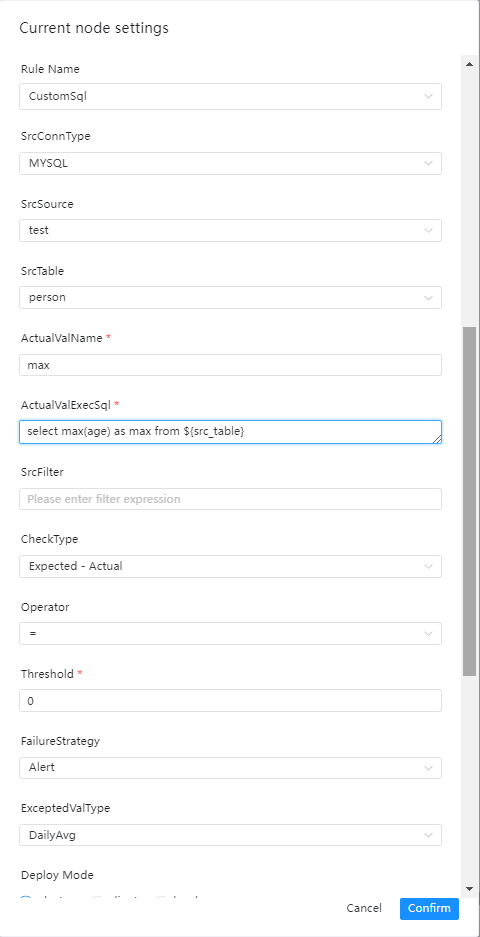
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择要验证数据所在表
- 实际值名:为统计值计算SQL中的别名,如max_num
- 实际值计算SQL: 用于输出实际值的SQL、
- 注意点:该SQL必须为统计SQL,例如统计行数,计算最大值、最小值等
- select max(a) as max_num from ${src_table},表名必须这么填
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 校验方式:
- 校验操作符:=,>、>=、<、<=、!=
- 阈值:公式中用于比较的值
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型
多表检查之准确性检查
检查介绍
准确性检查是通过比较两个表之间所选字段的数据记录的准确性差异,例子如下
- 表test1
| c1 | c2 |
|---|---|
| a | 1 |
| b | 2 |
- 表test2
| c21 | c22 |
|---|---|
| a | 1 |
| b | 3 |
如果对比c1和c21中的数据,则表test1和test2完全一致。 如果对比c2和c22则表test1和表test2中的数据则存在不一致了。
界面操作指南
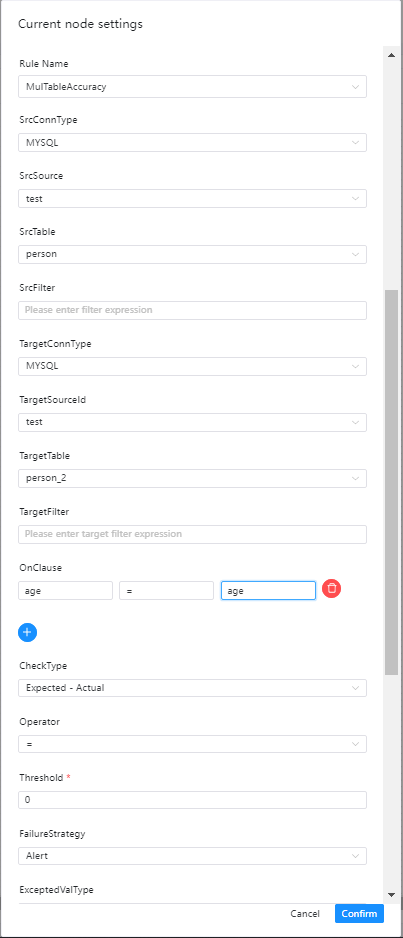
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:下拉选择要验证数据所在表
- 源过滤条件:如标题,统计表总行数的时候也会用到,选填
- 目标数据类型:选择MySQL、PostgreSQL等
- 目标数据源:源数据类型下对应的数据源
- 目标数据表:下拉选择要验证数据所在表
- 目标过滤条件:如标题,统计表总行数的时候也会用到,选填
- 检查列:
- 分别填写 源数据列,操作符,目标数据列
- 校验方式:选择想要的校验方式
- 操作符:=,>、>=、<、<=、!=
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
- 期望值类型:在下拉菜单中选择所要的类型,这里只适合选择SrcTableTotalRow、TargetTableTotalRow和固定值
两表检查之值比对
检查介绍
两表值比对允许用户对两张表自定义不同的SQL统计出相应的值进行比对,例如针对源表A统计出某一列的金额总值sum1,针对目标表统计出某一列的金额总值sum2,将sum1和sum2进行比较来判定检查结果
界面操作指南
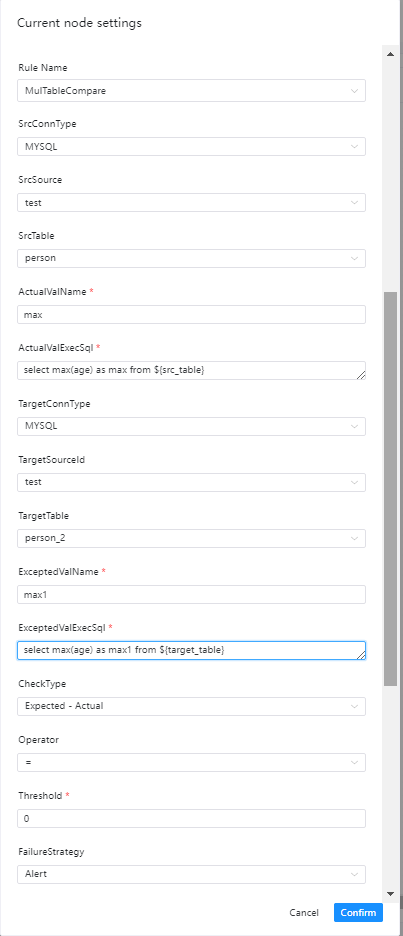
- 源数据类型:选择MySQL、PostgreSQL等
- 源数据源:源数据类型下对应的数据源
- 源数据表:要验证数据所在表
- 实际值名:为实际值计算SQL中的别名,如max_age1
- 实际值计算SQL: 用于输出实际值的SQL、
- 注意点:该SQL必须为统计SQL,例如统计行数,计算最大值、最小值等
- select max(age) as max_age1 from ${src_table} 表名必须这么填
- 目标数据类型:选择MySQL、PostgreSQL等
- 目标数据源:源数据类型下对应的数据源
- 目标数据表:要验证数据所在表
- 期望值名:为期望值计算SQL中的别名,如max_age2
- 期望值计算SQL: 用于输出期望值的SQL、
- 注意点:该SQL必须为统计SQL,例如统计行数,计算最大值、最小值等
- select max(age) as max_age2 from ${target_table} 表名必须这么填
- 校验方式:选择想要的校验方式
- 操作符:=,>、>=、<、<=、!=
- 失败策略
- 告警:数据质量任务失败了,DolphinScheduler任务结果为成功,发送告警
- 阻断:数据质量任务失败了,DolphinScheduler任务结果为失败,发送告警
任务结果查看
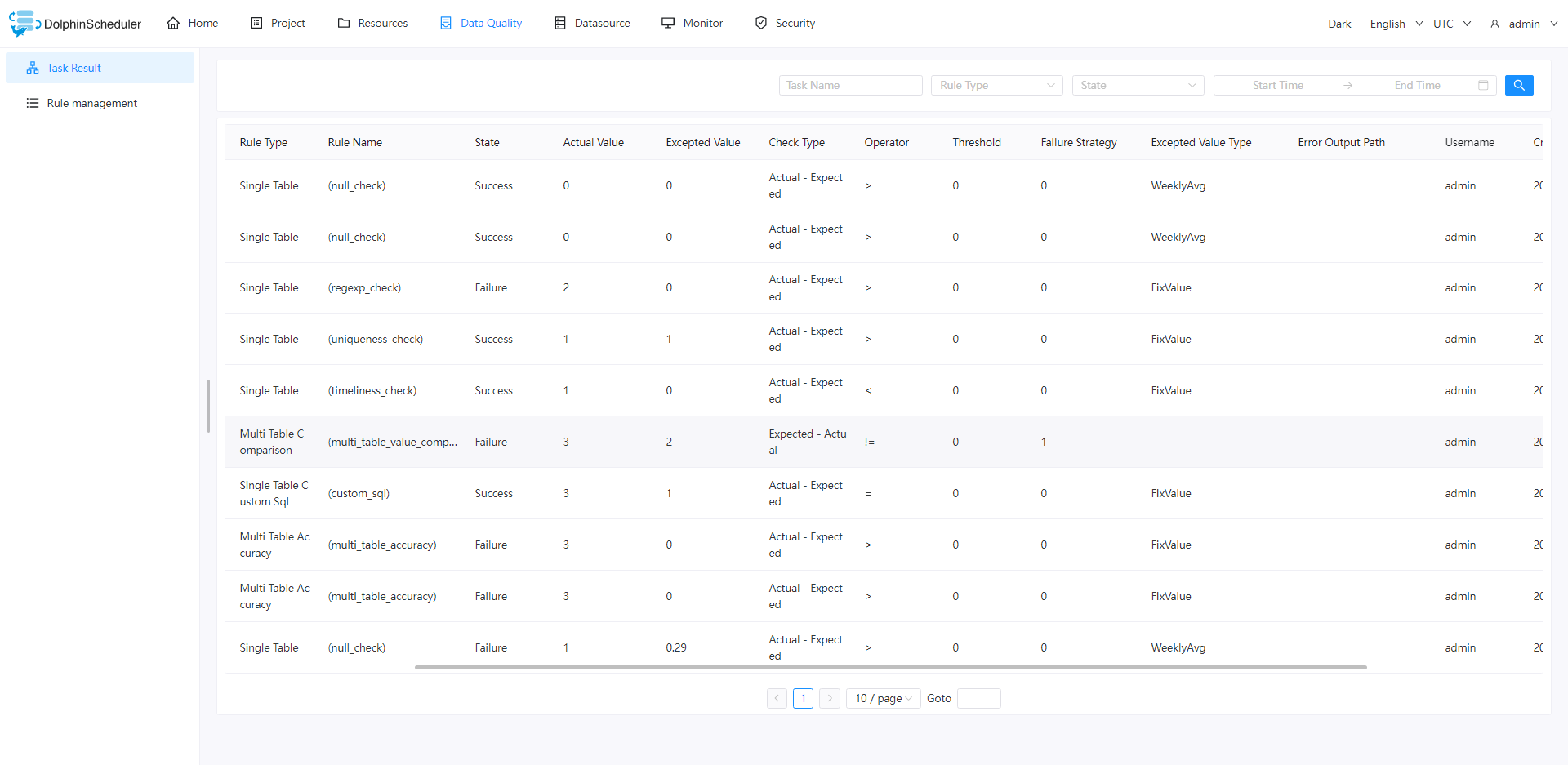
规则查看
规则列表

规则详情
数据源中心
数据源配置示例:
MySQL 数据源
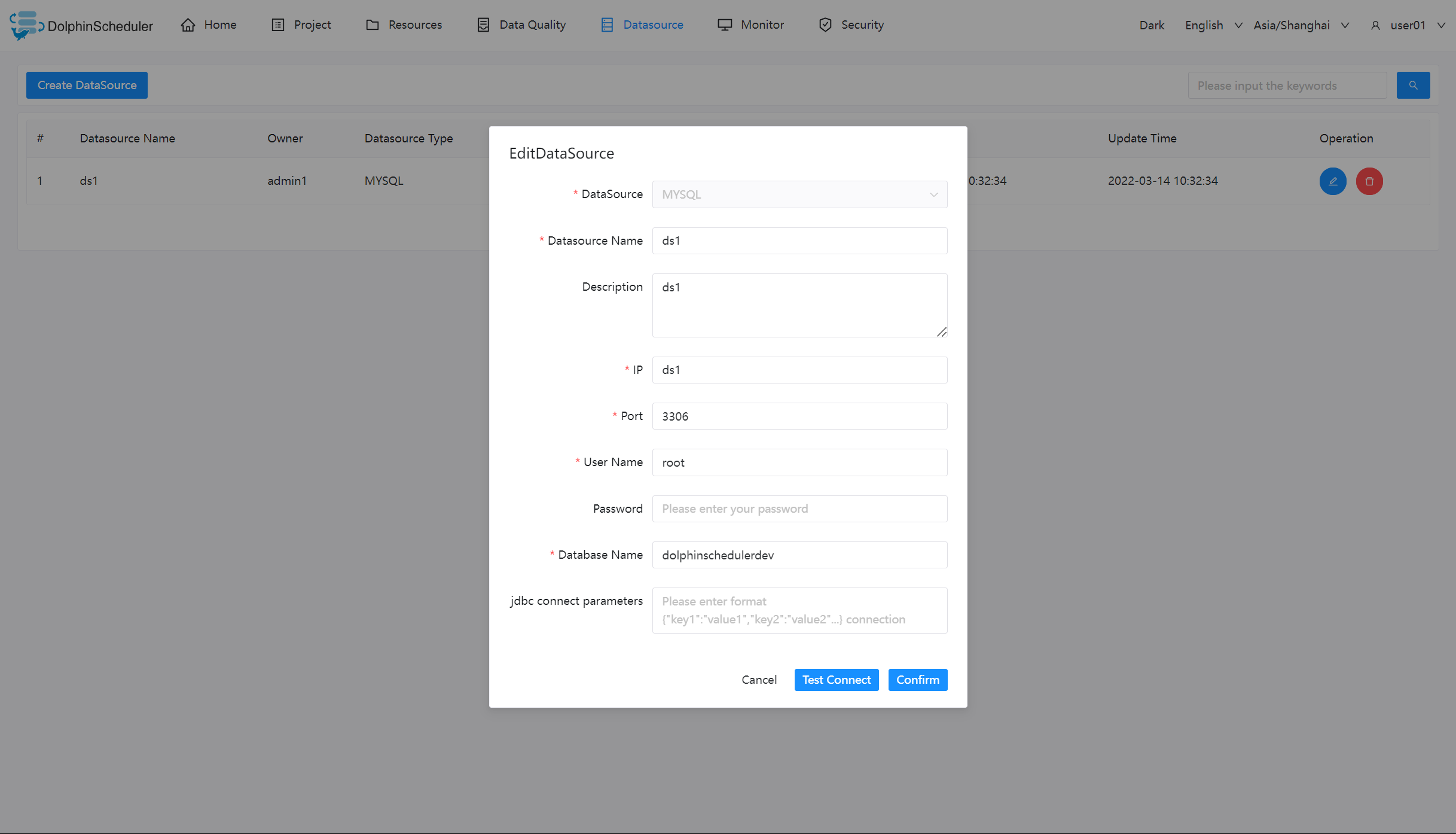
- 数据源:选择 MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP 主机名:输入连接 MySQL 的 IP
- 端口:输入连接 MySQL 的端口
- 用户名:设置连接 MySQL 的用户名
- 密码:设置连接 MySQL 的密码
- 数据库名:输入连接 MySQL 的数据库名称
- Jdbc 连接参数:用于 MySQL 连接的参数设置,以 JSON 形式填写
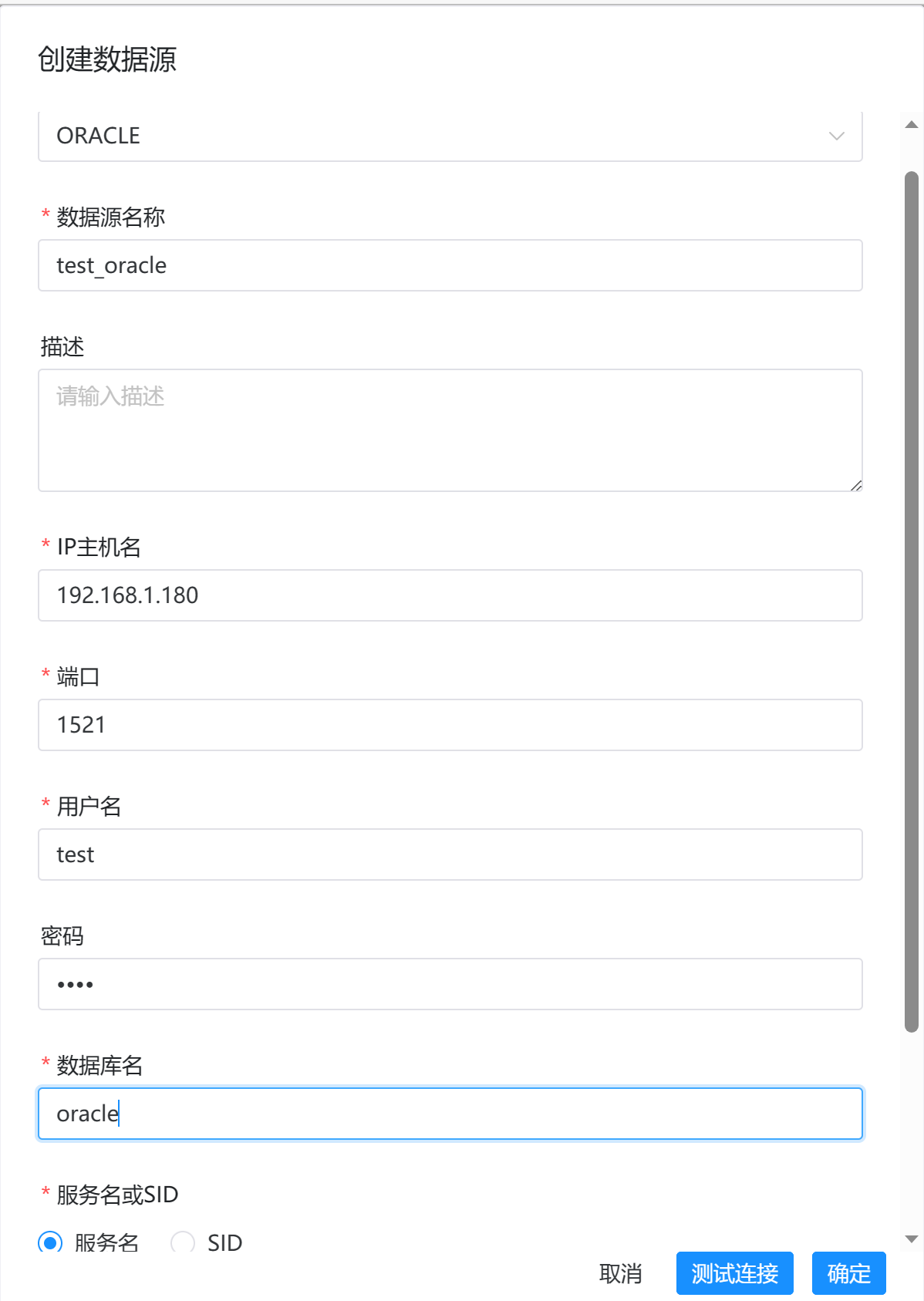
Oracle数据源
监控中心
服务管理
Master
面板中显示了master的CPU、内存、磁盘、负载情况

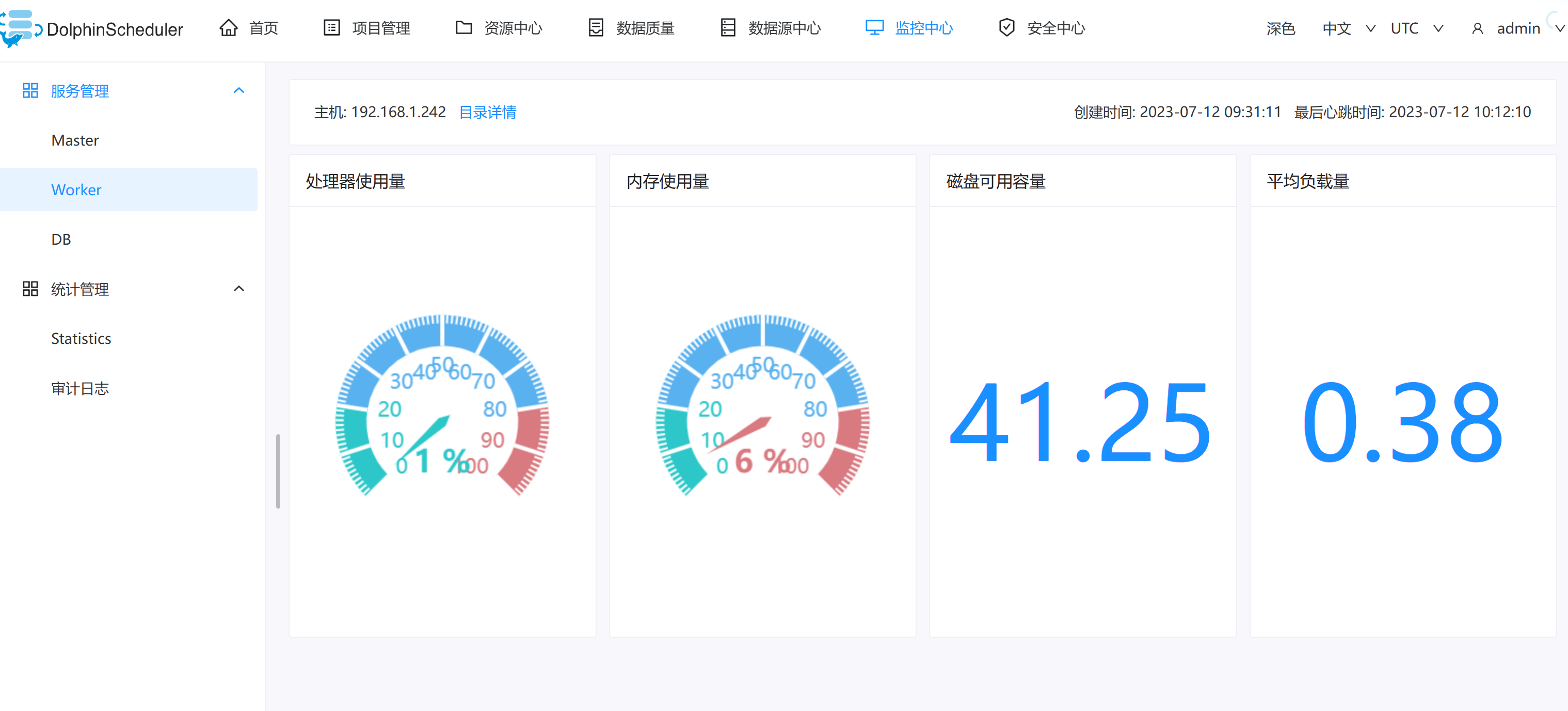
worker
- 主要是 worker 的相关信息。
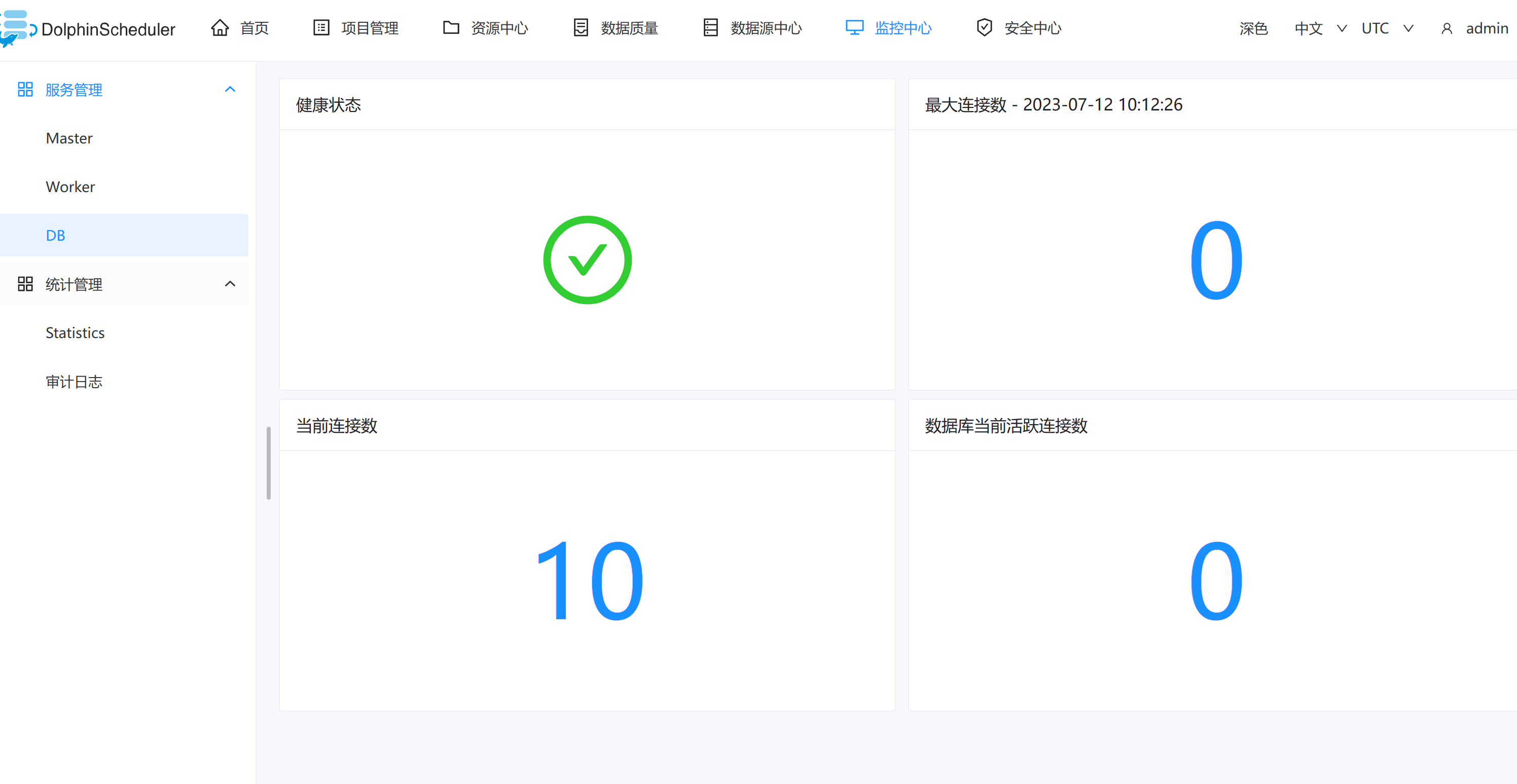
Database
- 主要是 DB 的健康状况
统计管理
Statistics
- 待执行命令数:统计 t_ds_command 表的数据
- 执行失败的命令数:统计 t_ds_error_command 表的数据
- 待运行任务数:统计 Zookeeper 中 task_queue 的数据
- 待杀死任务数:统计 Zookeeper 中 task_kill 的数据

审计日志
审计日志的记录提供了有关谁访问了系统,以及他或她在给定时间段内执行了哪些操作的信息,他对于维护安全都很有用。
安全中心(权限系统)
- 安全中心只有管理员账户才有权限操作,分别有队列管理、租户管理、用户管理、告警组管理、worker分组管理、令牌管理等功能,在用户管理模块可以对资源、数据源、项目等授权
- 管理员登录,默认用户名/密码:admin/dolphinscheduler123
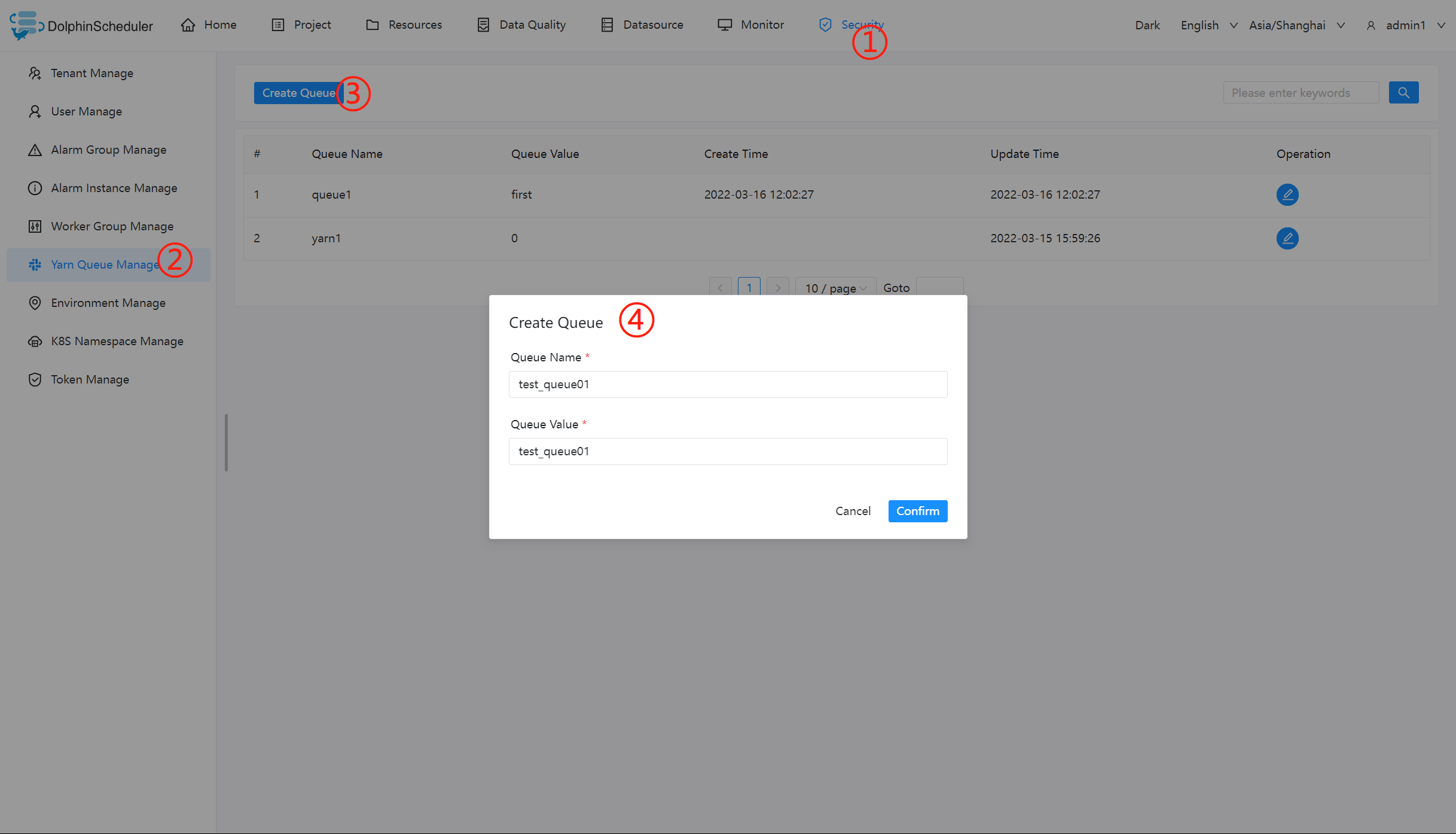
创建队列
- 队列是在执行 spark、mapreduce 等程序,需要用到“队列”参数时使用的。
- 管理员进入安全中心 -> 队列管理页面,点击“创建队列”按钮,创建队列。
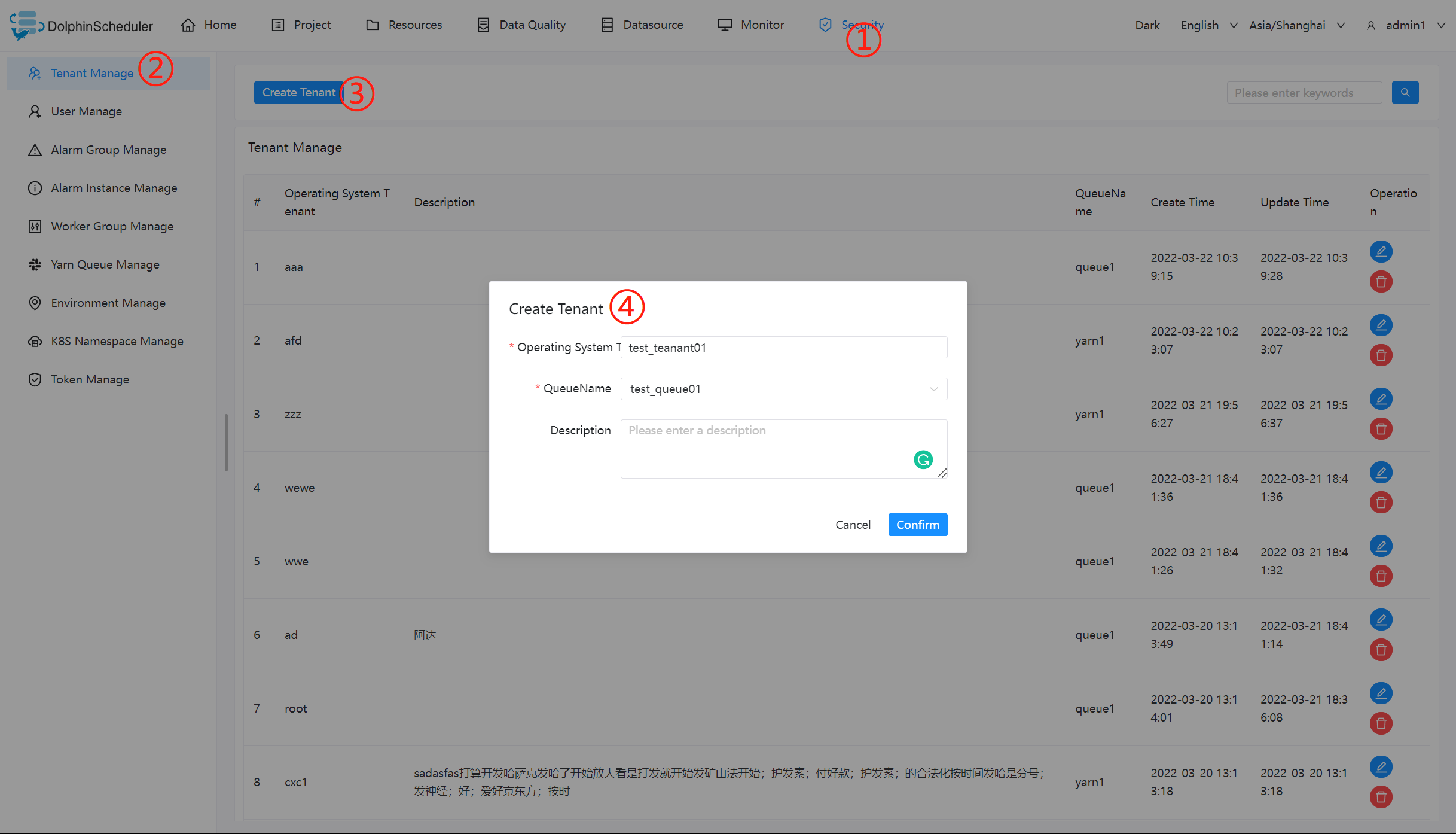
添加租户
- 租户对应的是 Linux 的用户,用于 worker 提交作业所使用的用户。如果 linux 没有这个用户,则会导致任务运行失败。你可以通过修改
worker.properties配置文件中参数worker.tenant.auto.create=true实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true参数会要求 worker 可以免密运行sudo命令 - 租户编码:租户编码是 Linux上 的用户,唯一,不能重复
- 管理员进入安全中心->租户管理页面,点击“创建租户”按钮,创建租户。
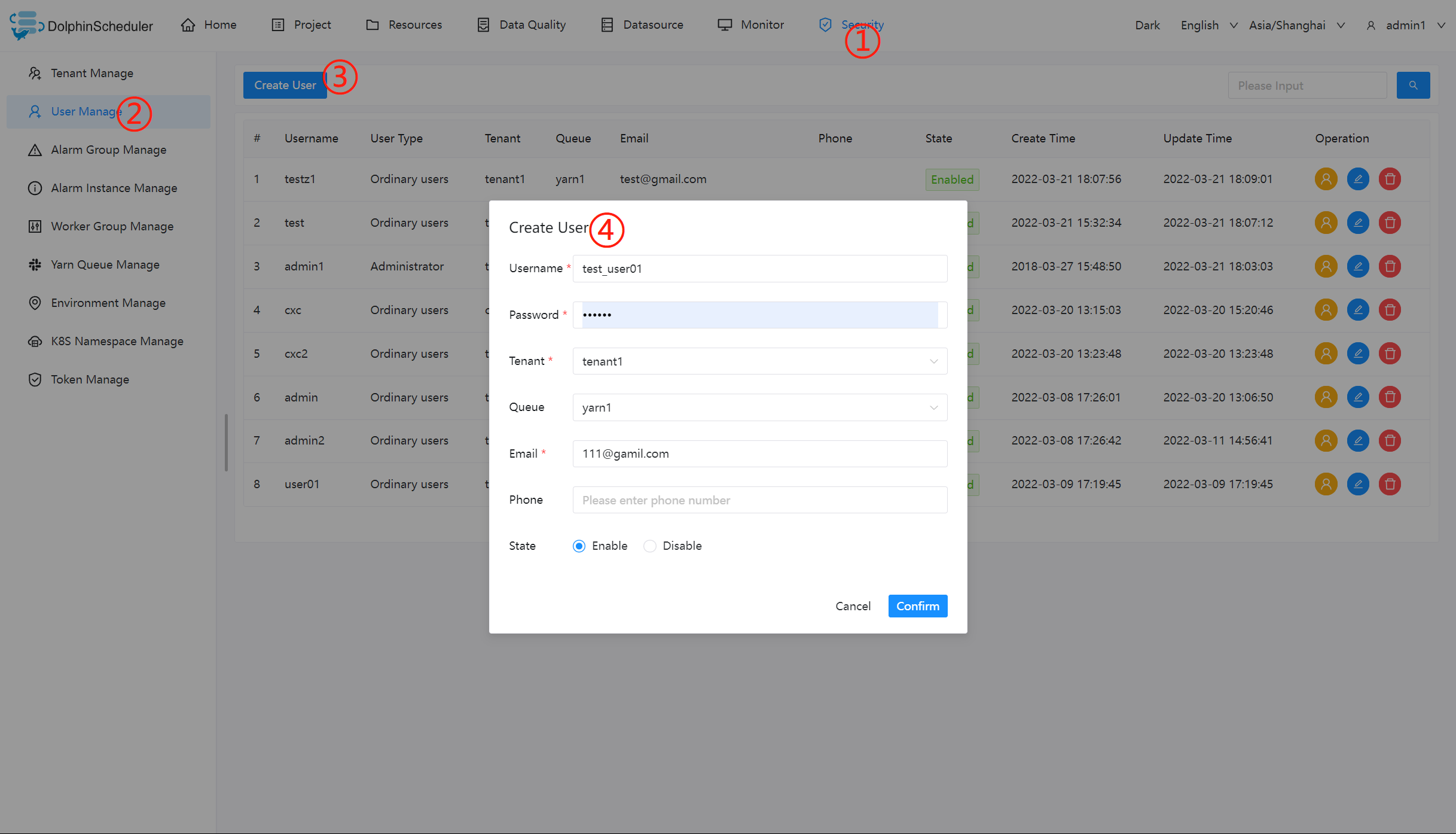
创建普通用户
- 用户分为管理员用户和普通用户
- 管理员有授权和用户管理等权限,没有创建项目和工作流定义的操作的权限。
- 普通用户可以创建项目和对工作流定义的创建,编辑,执行等操作。
- 注意:如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下。
- 进入安全中心->用户管理页面,点击“创建用户”按钮,创建用户。
编辑用户信息
- 管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息。
- 普通用户登录后,点击用户名下拉框中的用户信息,进入用户信息页面,点击"编辑"按钮,编辑用户信息。
修改用户密码
- 管理员进入安全中心->用户管理页面,点击"编辑"按钮,编辑用户信息时,输入新密码修改用户密码。
- 普通用户登录后,点击用户名下拉框中的用户信息,进入修改密码页面,输入密码并确认密码后点击"编辑"按钮,则修改密码成功。
创建告警组
- 告警组是在启动时设置的参数,在流程结束以后会将流程的状态和其他信息以邮件形式发送给告警组。
- 管理员进入安全中心->告警组管理页面,点击“创建告警组”按钮,创建告警组。
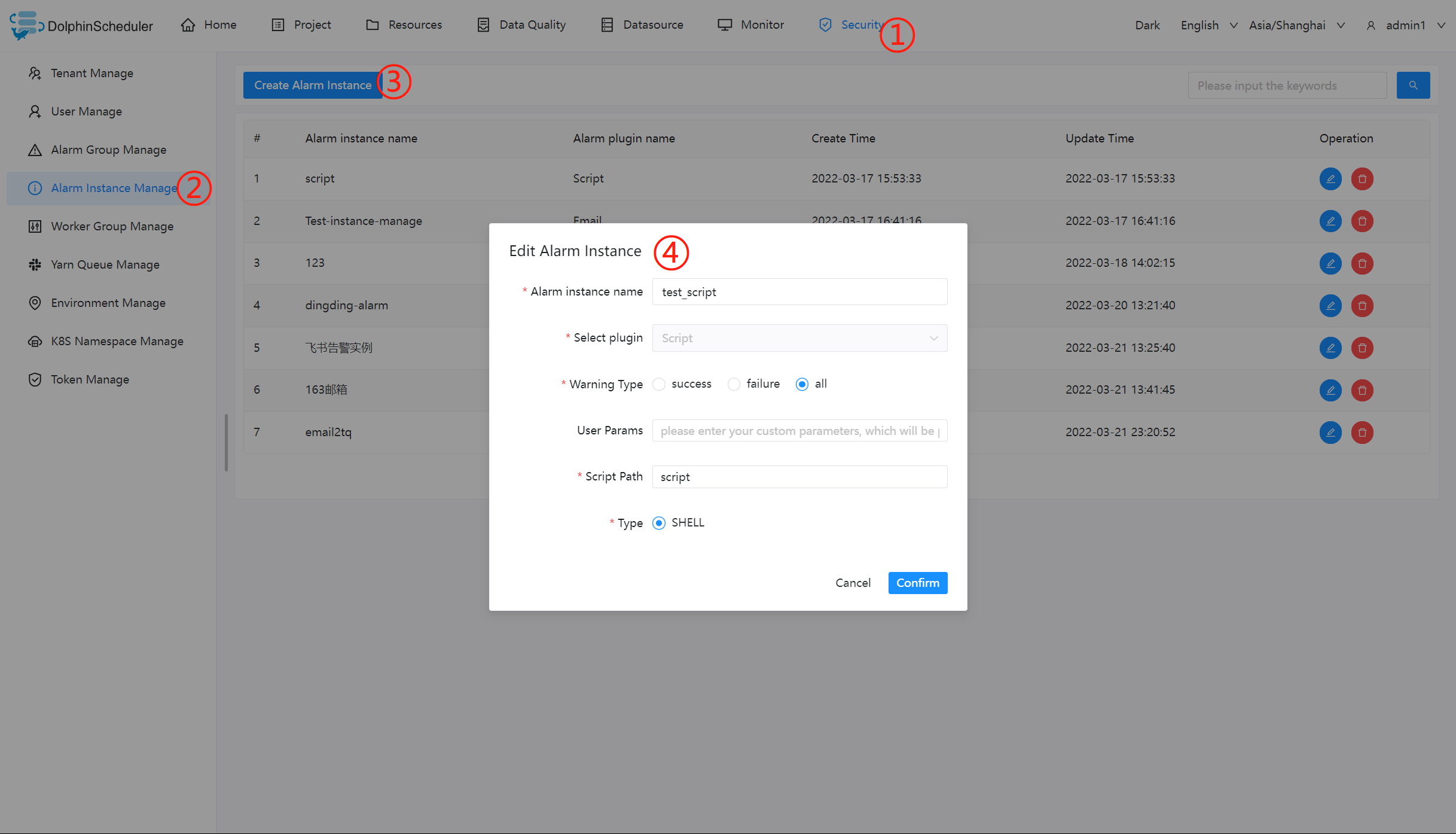
令牌管理
由于后端接口有登录检查,令牌管理提供了一种可以通过调用接口的方式对系统进行各种操作。
- 管理员进入安全中心->令牌管理页面,点击“创建令牌”按钮,选择失效时间与用户,点击"生成令牌"按钮,点击"提交"按钮,则选择用户的token创建成功。
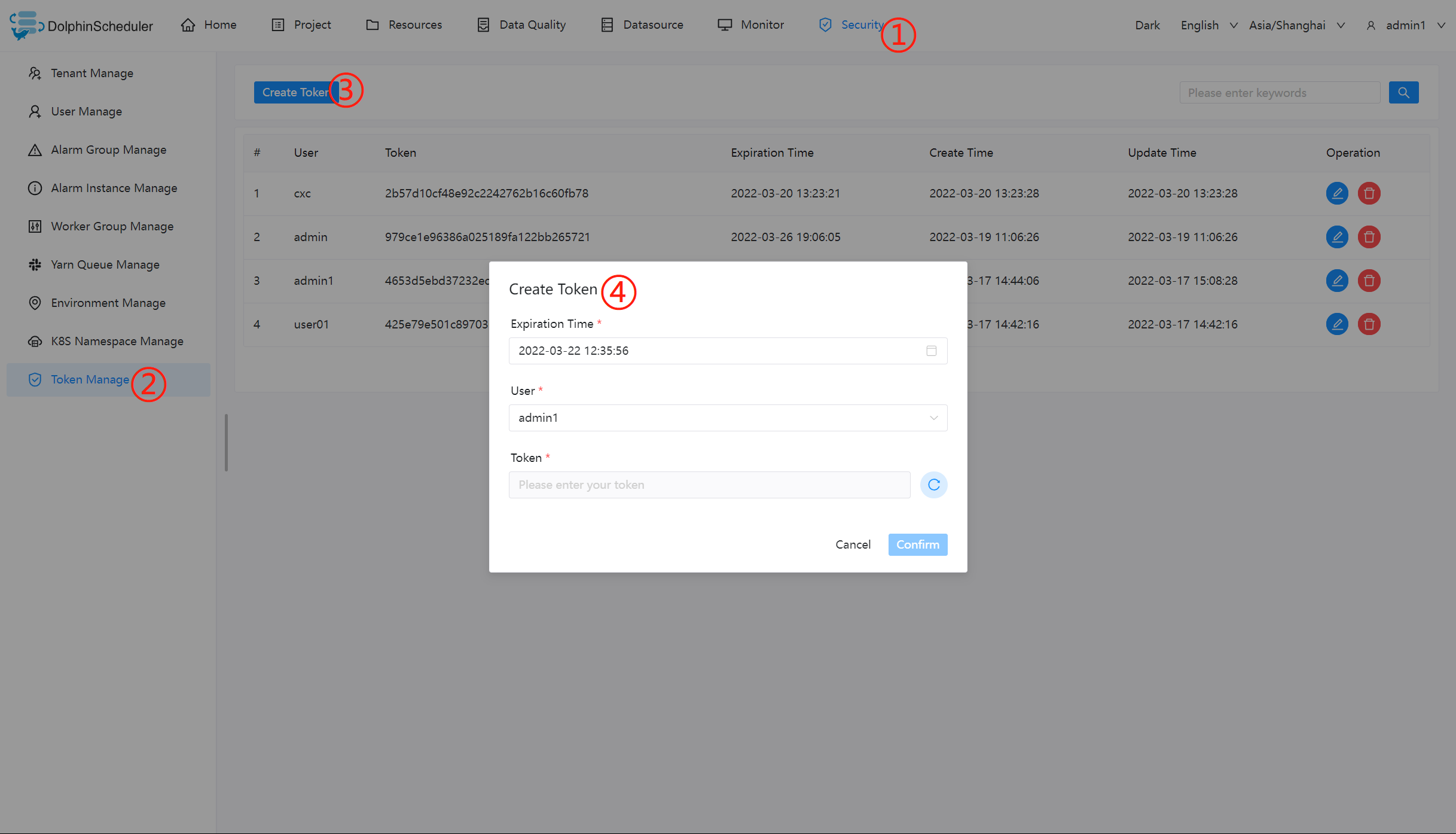
-
普通用户登录后,点击用户名下拉框中的用户信息,进入令牌管理页面,选择失效时间,点击"生成令牌"按钮,点击"提交"按钮,则该用户创建 token 成功。
-
调用示例:
/**
* test token
*/
public void doPOSTParam()throws Exception{
// create HttpClient
CloseableHttpClient httpclient = HttpClients.createDefault();
// create http post request
HttpPost httpPost = new HttpPost("http://127.0.0.1:12345/escheduler/projects/create");
httpPost.setHeader("token", "123");
// set parameters
List<NameValuePair> parameters = new ArrayList<NameValuePair>();
parameters.add(new BasicNameValuePair("projectName", "qzw"));
parameters.add(new BasicNameValuePair("desc", "qzw"));
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(parameters);
httpPost.setEntity(formEntity);
CloseableHttpResponse response = null;
try {
// execute
response = httpclient.execute(httpPost);
// response status code 200
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
} finally {
if (response != null) {
response.close();
}
httpclient.close();
}
}
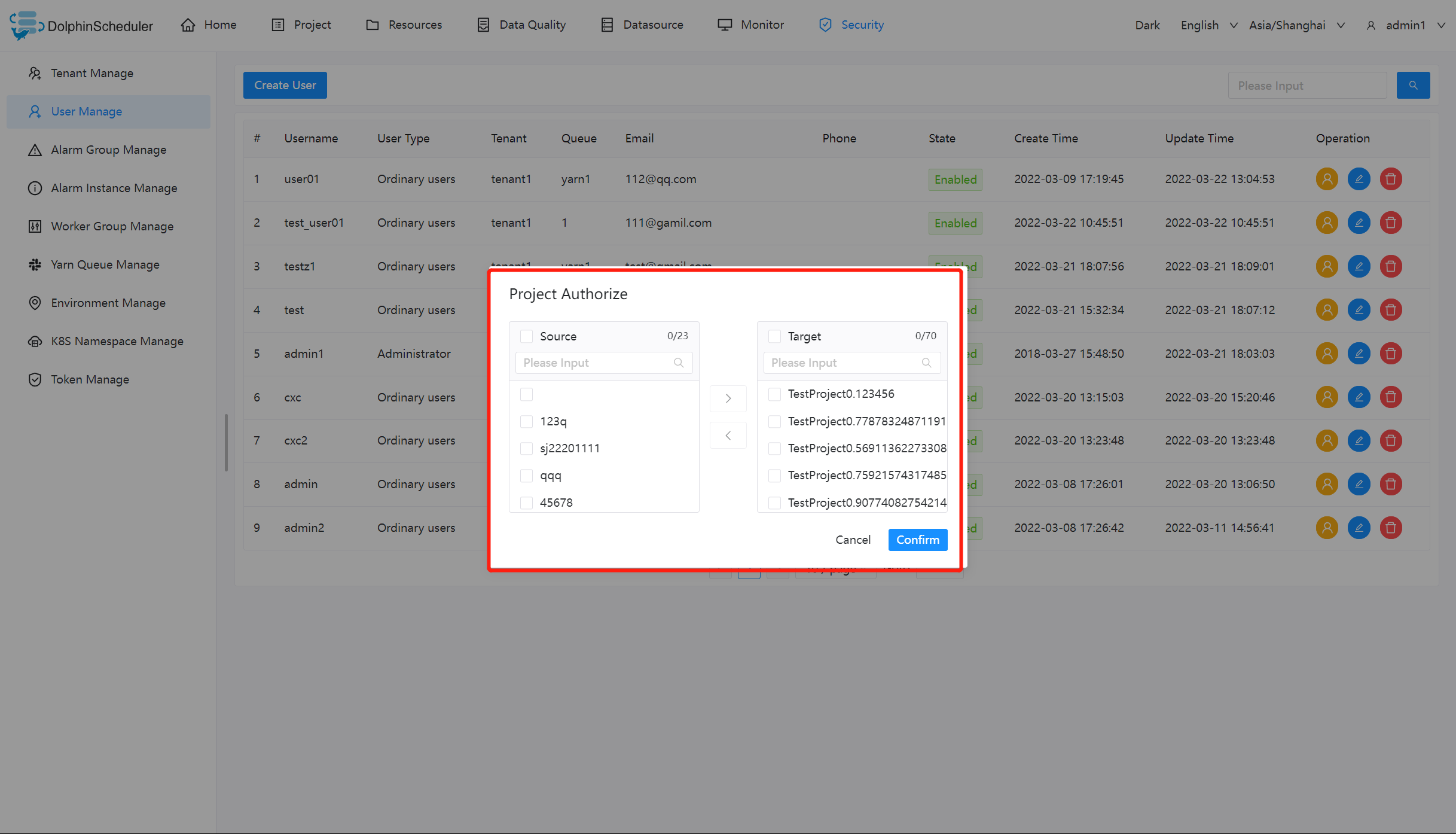
授予权限
- 授予权限包括项目权限,资源权限,数据源权限,UDF函数权限,k8s命名空间。
- 管理员可以对普通用户进行非其创建的项目、资源、数据源、UDF函数、k8s命名空间。因为项目、资源、数据源、UDF函数、k8s命名空间授权方式都是一样的,所以以项目授权为例介绍。
- 注意:对于用户自己创建的项目,该用户拥有所有的权限。则项目列表和已选项目列表中不会显示。
- 管理员进入安全中心->用户管理页面,点击需授权用户的“授权”按钮,如下图所示:

- 选择项目,进行项目授权。
- 资源、数据源、UDF 函数授权同项目授权。
Worker 分组
每个 worker 节点都会归属于自己的 worker 分组,默认分组为 default。
在任务执行时,可以将任务分配给指定 worker 分组,最终由该组中的 worker 节点执行该任务。
新增 / 更新 worker 分组
- 打开要设置分组的 worker 节点上的
worker-server/conf/application.yaml配置文件. 修改worker配置下的groups参数. groups参数的值为 worker 节点对应的分组名称,默认为default。- 如果该 worker 节点对应多个分组,则用连字符列出,示范如下:
worker:
......
groups:
- default
- group1
- group2
......
- 也可以在运行中添加 worker 所属的 worker 分组而忽略
application.yaml中的配置。修改步骤为安全中心->worker分组管理-> 点击创建worker分组-> 输入分组名称和worker地址-> 点击确定
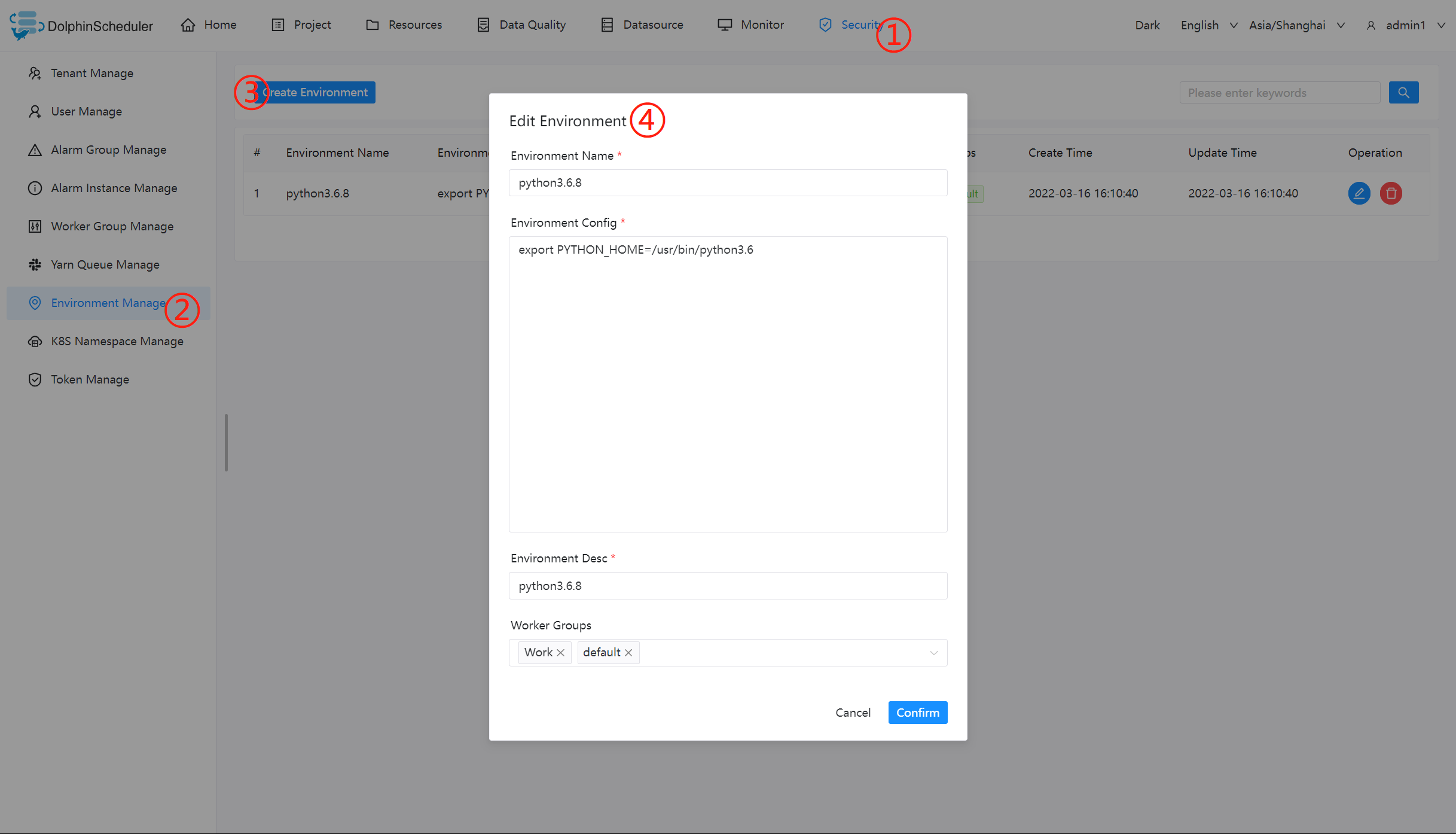
环境管理
-
在线配置 worker 运行环境,一个 worker 可以指定多个环境,每个环境等价于 dolphinscheduler_env.sh 文件.
-
默认环境为dolphinscheduler_env.sh文件.
-
在任务执行时,可以将任务分配给指定 worker 分组,根据 worker 分组选择对应的环境,最终由该组中的 worker 节点执行环境后执行该任务.
创建/更新 环境
- 环境配置等价于dolphinscheduler_env.sh文件内配置
使用环境
- 在工作流定义中创建任务节点选择 worker 分组和 worker 分组对应的环境,任务执行时 worker 会先执行环境在执行任务.
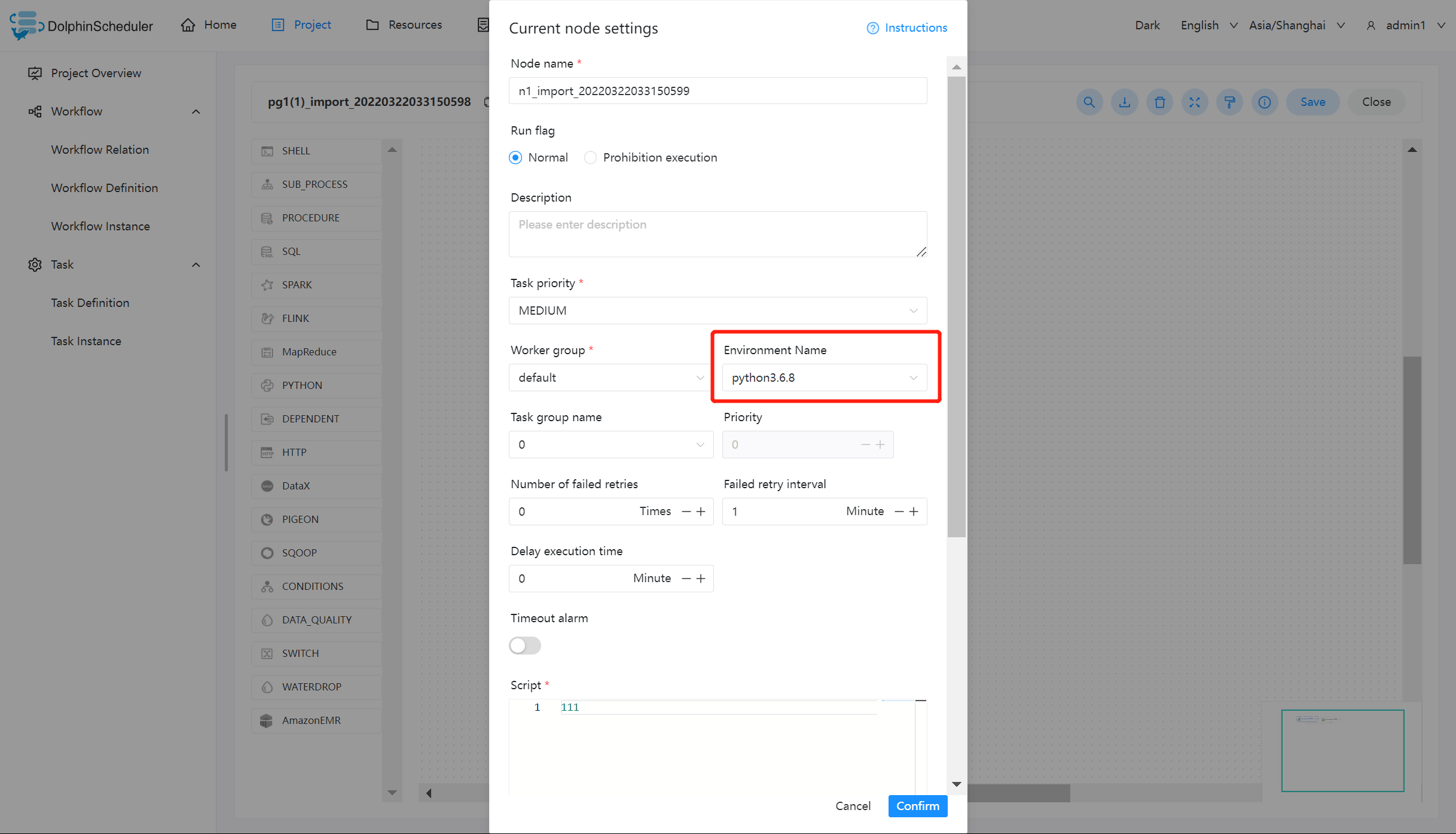
注意: 当无法在任务定义或工作流运行对话框中使用你想要使用的环境时,请检查您已经选择worker,并且您要使用的环境已经关联到您选择的worker中
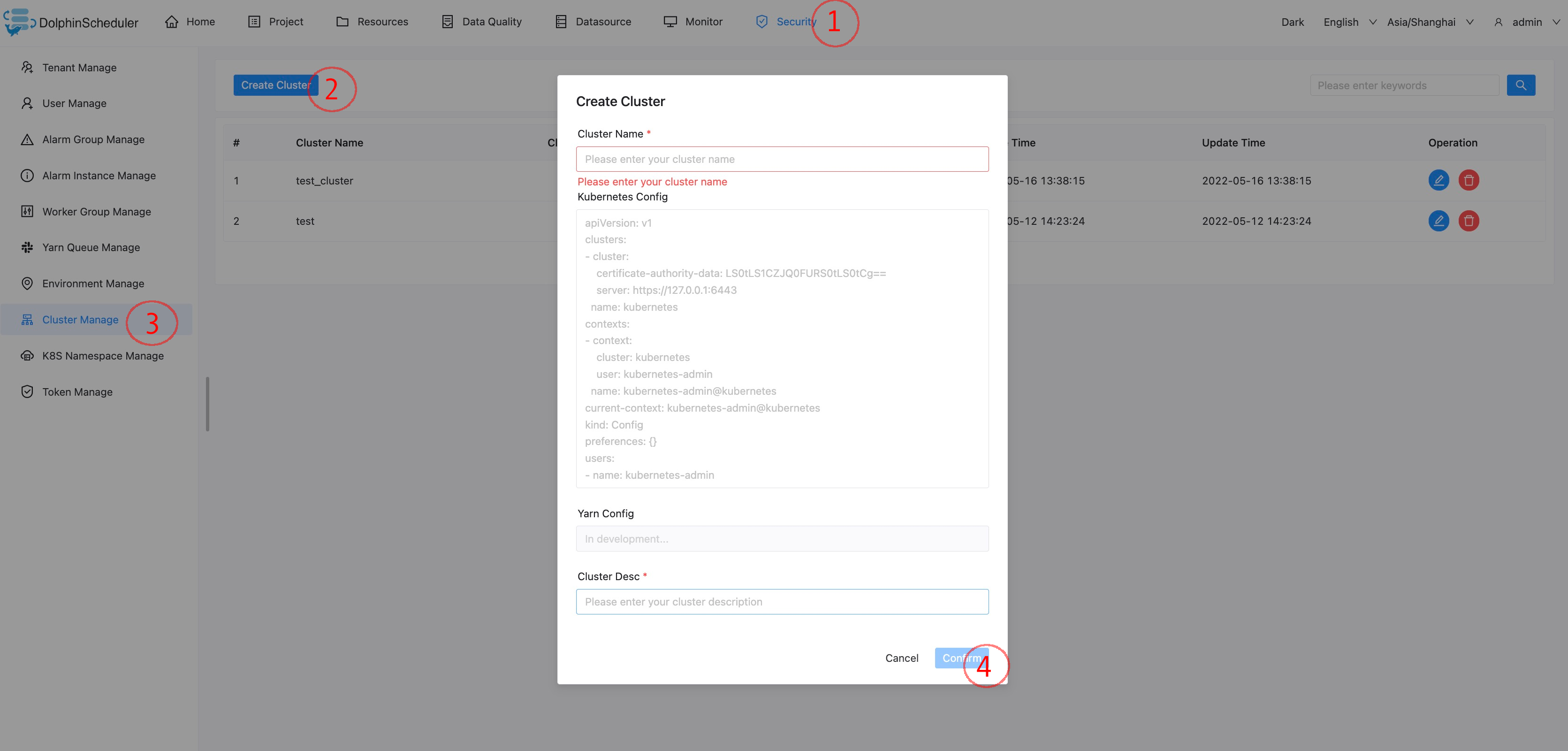
集群管理
创建/更新 集群
- 每个工作流可以绑定零到若干个集群用来支持多集群,目前先用于k8s。
使用集群
- 创建和授权后,k8s命名空间和工作流会增加关联集群的功能。每一个集群会有独立的工作流和任务实例独立运行。














 2427
2427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









