







 马斯克公开了Twitter的部分代码,主要涉及推荐算法,包括用户时间线推文的构建。代码库分为两个部分,涵盖了数据处理、特征工程和推荐服务。推荐机制涉及用户、推文和社交网络数据,利用GraphJet、SimClusters等工具进行社交图分析和特征提取。推荐过程包括召回、粗排、精排和混排阶段,结合各种特征和机器学习模型优化用户体验。
马斯克公开了Twitter的部分代码,主要涉及推荐算法,包括用户时间线推文的构建。代码库分为两个部分,涵盖了数据处理、特征工程和推荐服务。推荐机制涉及用户、推文和社交网络数据,利用GraphJet、SimClusters等工具进行社交图分析和特征提取。推荐过程包括召回、粗排、精排和混排阶段,结合各种特征和机器学习模型优化用户体验。
马斯克最近开源了部分 Twitter的代码,主要有两个仓库,
- main repo(https://github.com/twitter/the-algorithm/)
- ml repo(https://github.com/twitter/the-algorithm-ml)
- 官方介绍:https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
此次发布的大部分代码是推荐算法,包括给用户在时间线上推文的机制等等。并且看起来这个github会持续更新,本篇文章也尝试理一下这部分的推荐机制。
时间线推文(For You timeline)的整体框架如下图所示,
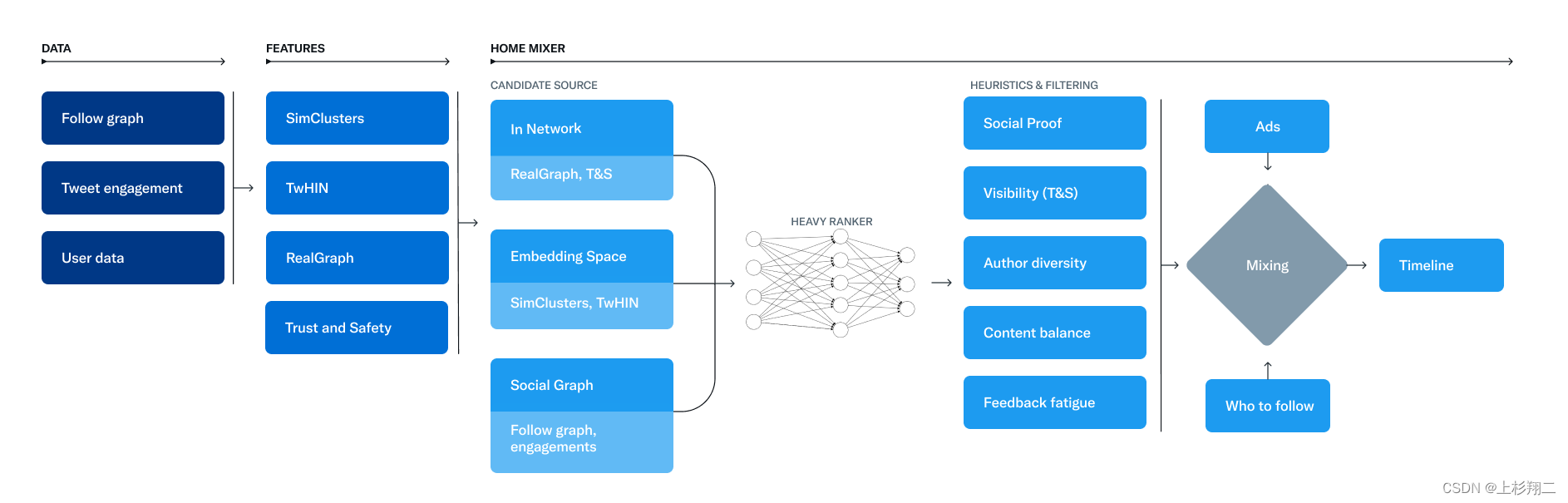
其主要分为三个模块:
- DATA。数据部分主要是三大块:用户、推文、社交网络。
- FEATRUE。特征部分除了计算用户和推文的特征外,社交图中的社区发现特征等十分重要,另外还有一些信用和安全的特征。
- HOME MIXER。执行推荐的整个服务,基于scala,执行推文召回、粗/精排序、重/混排。
最后实现Timeline、Who to follow、Ads的三个任务,即给用户推文、推用户、推广告。
下面分别简要介绍一下各个模块。
DATA
在推特这种社交属性明显的场景中,数据几乎就是由用户之间的互动、用户和推文之间的互动所构成的。因此DATA部分分为Follow graph、Tweet engagement、User data。
- Follow graph。社交图,也是推特场景中十分重要的数据。
- Tweet engagement。Engagement单词的本意是「约定、婚约」,在行销领域中常被用于表示企业品牌、消费者和企业之间的关系,延伸到社交平台中的含义变为「互动」。如facebook中的互动主要包括:获赞、评论、分享、点击次数等。而在twitter中主要是点击、转发、点赞和关注等。
- User data。用户画像,包含用户的一些基础数据。
FEATRUES
FEATRUES指特征工程,包括embedding嵌入、社交图特征如聚类和社区发现、用户信用和违规检测等,这些特征后续可以用于召回、排序、安全等等具体模块(具体可见下一节的HOME MIXER)。
特征主要分为:GraphJet、SimClusters、TwHIN、RealGraph、TweepGred、Trust&Safety。
-
社交特征。GraphJet是社交图特征。通过分析用户已经关注的人或具有相似兴趣的人,如关注的人所浏览的内容,即社交图中的二跳关系U2U2I。因此为了实现高效动态图构造和游走,Twitter内部自研了GraphJet图引擎(VLDB 2016)。
-
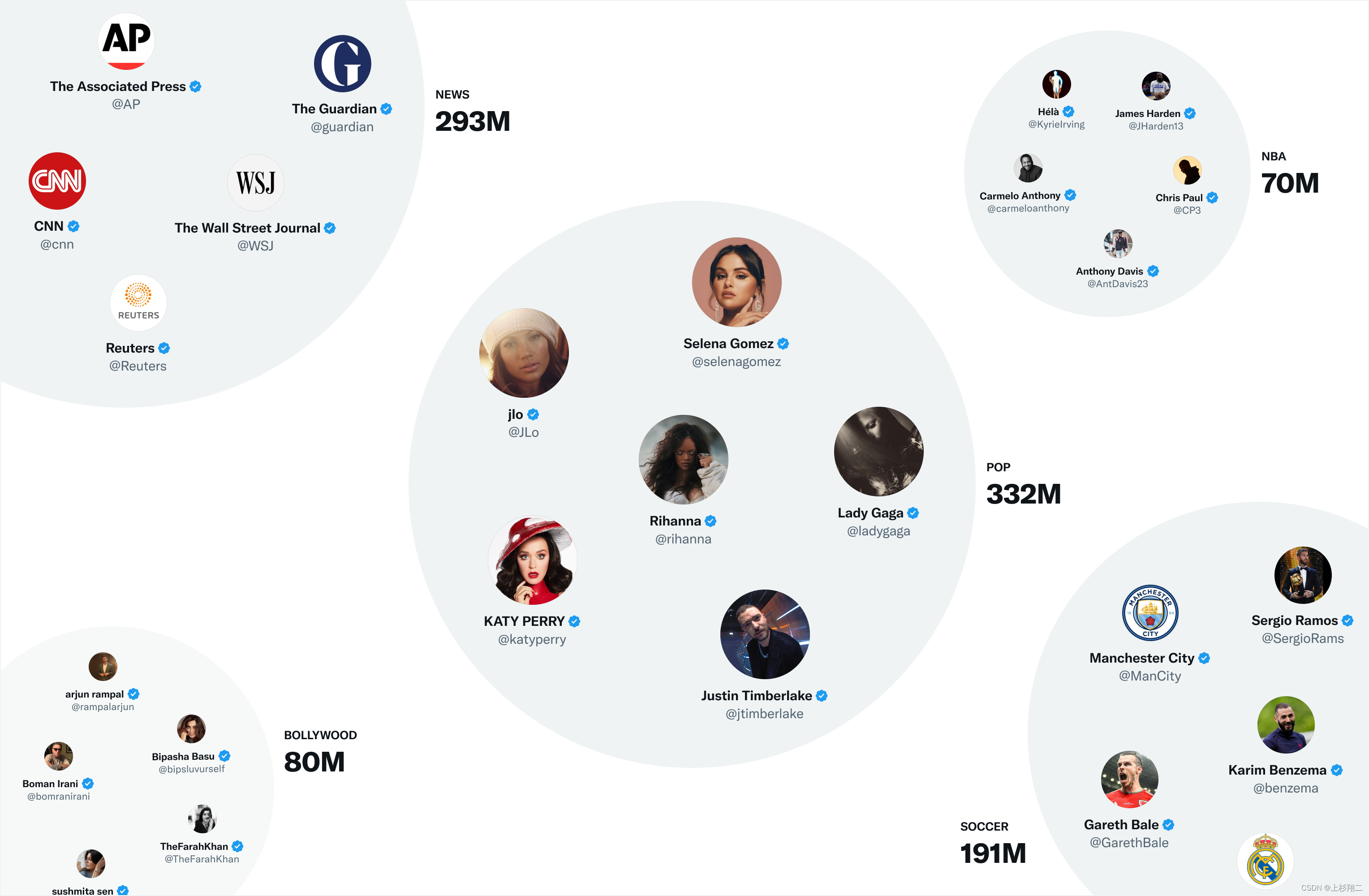
嵌入特征。目标得到user embedding和item embedding,主要分为稀疏嵌入和稠密嵌入两种,前者通过聚类、后者基于图学习。具体是两种算法:
-
- SimClusters(稀疏),做社区检测和稀疏嵌入,如上图所示。其根据流行度和用户行为将推文、用户划分到不同空间(聚类),发表于KDD 2020,共有14.5w个社区、每3周更新一次。
-
- TwHIN(稠密),基于图学习做稠密嵌入,如下图所示。该异构图包括四种类型的实体(user、tweet、advertiser、ad),和七种不同的互动关系(follows、authors、favorites、replies、retweets、promotes、clicks),通过该异构图得到的稠密特征可以在具体模块中负责图召回、排序等。
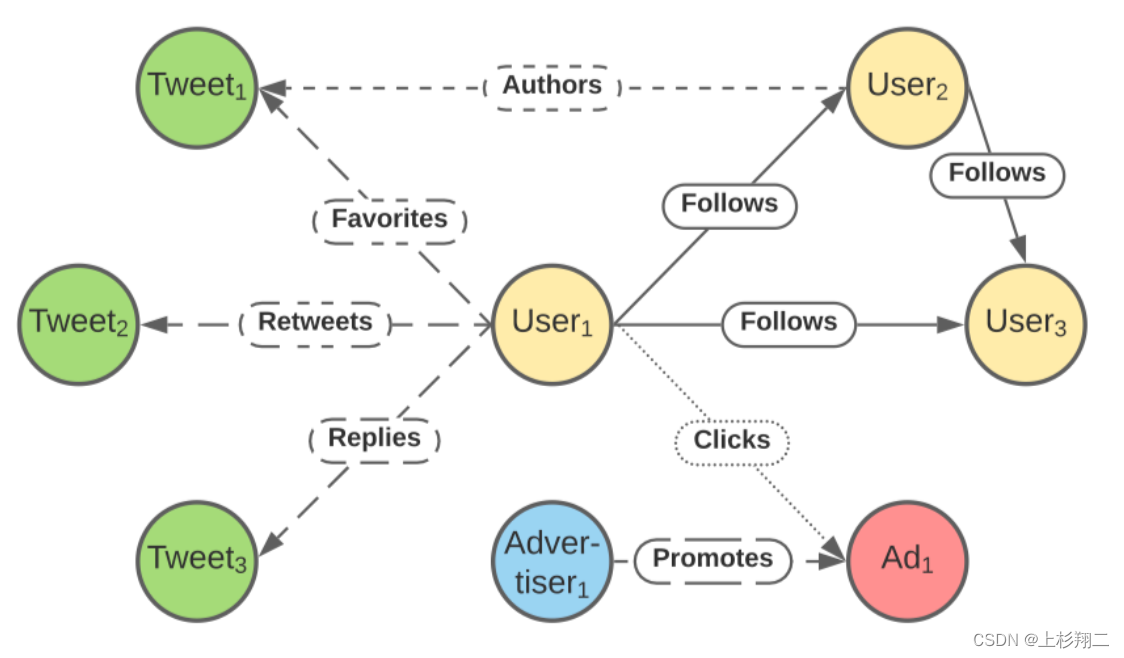
- TwHIN(稠密),基于图学习做稠密嵌入,如下图所示。该异构图包括四种类型的实体(user、tweet、advertiser、ad),和七种不同的互动关系(follows、authors、favorites、replies、retweets、promotes、clicks),通过该异构图得到的稠密特征可以在具体模块中负责图召回、排序等。
-
RealGraph用于偏好预测,主要进行边预测,即用户是否互动。这个特征主要用于粗排模块中,作为LR粗排的一个辅助,具体在粗排模型中进行介绍。
-
TweepGred用于信用预测,基于pagerank评价用户的声誉。
-
Trust&Safety用于检测不可信和不安全等违规内容。
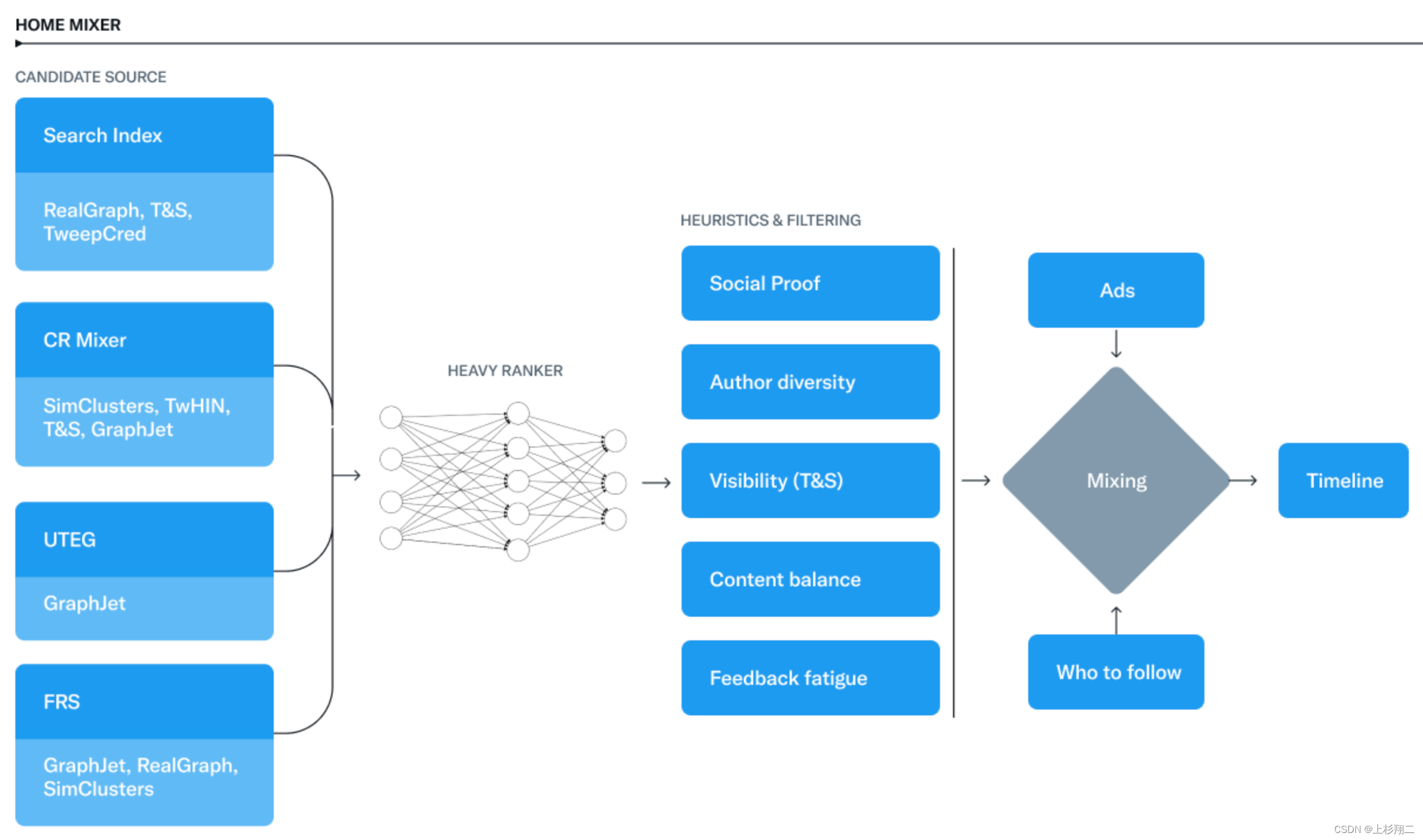
HOME MIXER
HOME MIXER是推特推荐的核心服务(Scala框架),其分为Candidate Source、Heavy Ranker、Heuristics & Filtering三个大块(分别对应召回、粗/精排、重/混排),其中每一小块内有多种小组件,如上图所示。
Candidate Source(即召回)。目的是从不同的源(量级亿万)召回一些最新、质量高的推文,主要是利用社交图召回,有两个召回路,一路是已经关注的社交圈(in-network),和待探索的社交圈(out-of-network),理论比例是各50%出现在用户的时间流推文中,实际上这个比例会根据用户的兴趣而适配。
召回模块的各小组件主要有如下,其中Search Index是社交图内的,CR Mixer,UTEG和FRS是社交图网络外的内容。
- Search Index (in-network)。使用Real Graph(用户是否互动),Trust&Safety(是否安全),TweepGred(是否可信)的特征。基于推文搜索系统 (Earlybird) 查找某个用户已经过关注人的所有推文。
- UTEG (in-network)。UTEG是user-tweet-entity-graph的缩写,使用GraphJet特征(社交图特征)做协同过滤进行推文。
- CR Mixer (out-of-network)。用于社交网络外的内容召回,使用SimClusters、TwHIN、Trust&Safety和GraphJet特征,可以看到都是社区检测的相关特征。
- FRS (out-of-network)。也用于社交网络外的内容召回,FRS是follow-recommendation-service的缩写,因此它是一个给用户推荐关注的服务(Who-To-Follow ),使用GraphJet、RealGraph、SimClusters等社区发现的特征。
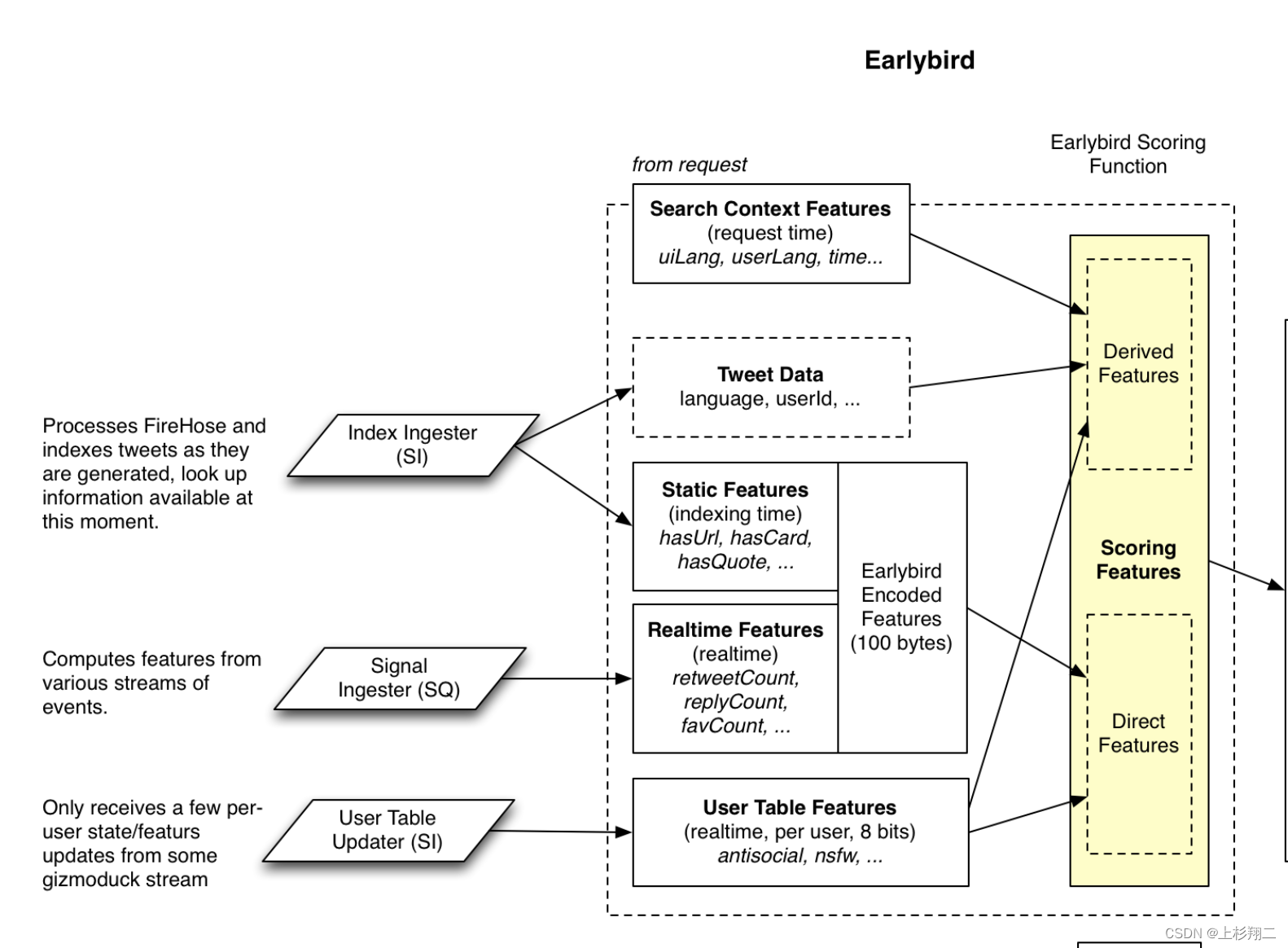
Heavy Ranker(即粗/精排)。Candidate Source中的两路召回in-network、out-network得到的推文,会先进粗排再进精排。
负责粗排有两个模型,第一个是LR模型,预测用户和推文有互动的概率,如上图所示,具体特征有
- search context features。搜索上下文时间,包括用户语言,时间等等。
- tweet data。推文的特征,包括推文所用语言,用户id等。
- static features。评价推文的静态文本质量,如是否有url等等。
- realtime features。实时推文被转发、回复、关注等等。
- user table features。用户的信誉、粉丝数目等等。
不同特征会有不同的权重,如点击的权重为1,点赞的权重为2等,如下表所示。
INDEX_BY_LABEL = {
"is_clicked": 1,
"is_favorited": 2,
"is_open_linked": 3,
"is_photo_expanded": 4,
"is_profile_clicked": 5,
"is_replied": 6,
"is_retweeted": 7,
"is_video_playback_50": 8
}
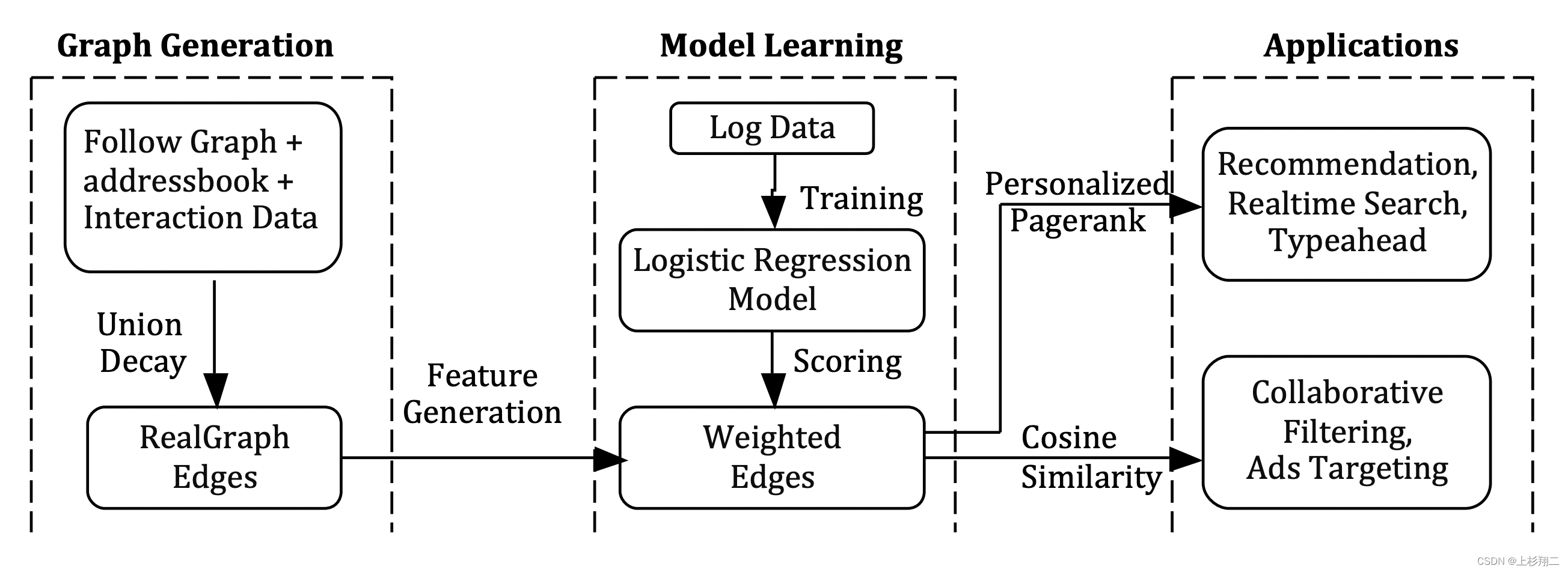
第二个粗排模型是基于RealGraph: User Interaction Prediction at Twitter,如上图所示,本质是个链接预测任务,去预测用户和用户交互的概率。包括图构成、模型训练和应用。
- Graph Generation。RealGraph是一个有向带权同构图,节点是用户、边是用户与用户的交互关系(follow graph、addressbook、interaction data)。
- Model Learning。基于边特征,仍然使用使用逻辑回归模型来训练。
- Application。预测用户之间的交互概率,交互概率越高,就会推该用户更多的推文。
过粗排模型后,两路召回会各自排出750条推文,然后将共1500的数量进精排。
精排
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









