







Kafka之三:Kafka集群工作流程
文章目录
Kafka之一:Kafka简述
Kafka之二:Kafka集群的安装
Kafka之四:Kafka与Streaming集成
一、工作流程分析
1. producer写入流程

- a. producer先从zookeeper的 "/brokers/…/state"节点找到该partition的leader
- b. producer将消息发送给该leader
- c. leader将消息写入本地log
- d. followers从leader pull消息,写入本地log后向leader发送ACK
- e. leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
2. 分区(Partition)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:

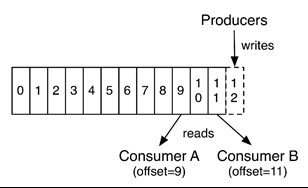
我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
(1)分区的原因
- a. 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
- b. 可以提高并发,因为可以以Partition为单位读写了。
(2)分区的原则
- a. 指定了patition,则直接使用;
- b. 未指定patition但指定key,通过对key的value进行hash出一个patition;
- c. patition和key都未指定,使用轮询选出一个patition。
DefaultPartitioner类
public int partition(St 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3119
3119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









