







 本文介绍了如何在IDEA中配置maven,以便使用Kafka作为Spark Streaming的数据源。详细阐述了两个程序的实现过程,包括代码示例、集群启动、任务提交以及可能遇到的错误和解决方案,特别是针对缺少jar包的问题提供了处理方法。
本文介绍了如何在IDEA中配置maven,以便使用Kafka作为Spark Streaming的数据源。详细阐述了两个程序的实现过程,包括代码示例、集群启动、任务提交以及可能遇到的错误和解决方案,特别是针对缺少jar包的问题提供了处理方法。
Kafka之四:Kafka与Streaming集成
Kafka之一:Kafka简述
Kafka之二:Kafka集群的安装
Kafka之三:Kafka集群工作流程
- spark官网
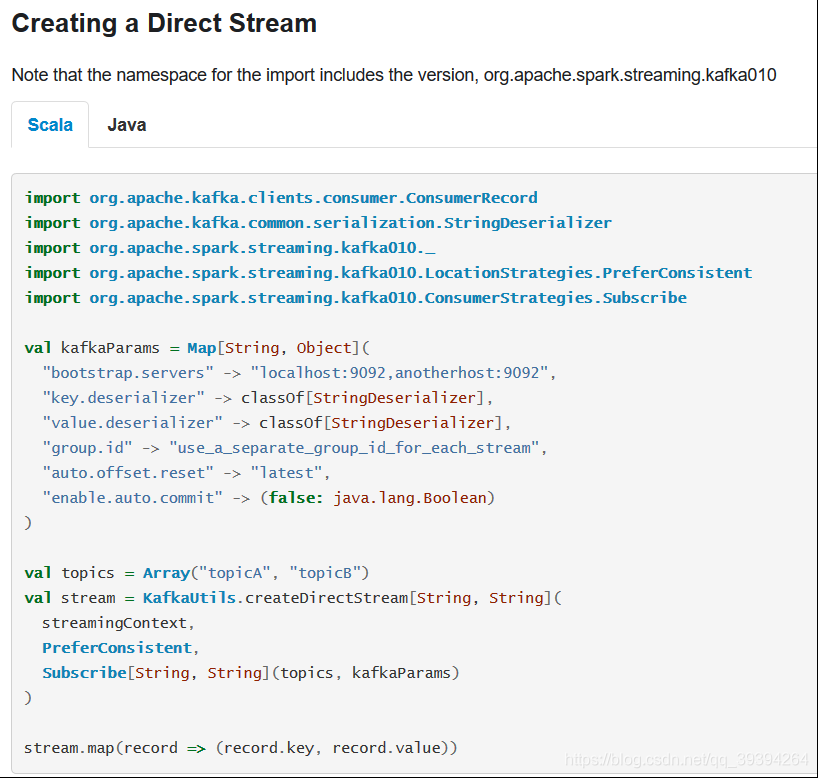
- Kafka作为spark Streaming的一种输入源,当Kafka和Streaming集成时充当消费者角色。(请了解Kafka命令操作)
1. 修改IEDA的maven配置

按照官网配置修改maven配置文件pom.xml

org.apache.spark
spark-streaming-kafka-0-10_2.11
2.1.1
2. 程序一
(1) 官网实例:
package com.spark.kafka
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, S 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









