







首先我们来介绍一下入手的途径:
短期区别,我们追溯源码,如果要寻根溯源,可能还得追溯到数据结构上来。这里只是追溯到源码。有兴趣的粉丝也可以从数据结构视角出发。又是一场新颖的观点、下面开始我们从源码角度出发来剖析ArrayList与LinkedList 的区别,主要从以下角度去看:
- 阅读和介绍源码的类介绍
- 剖析类的继承,实现,以及重载和重写
- 剖析类的属性(变量),特征(方法)
- 根据属性,特征确认类的试用场景
第一步 我们可以先来看一下API的介绍
一、ArrayList如下
compact1, compact2, compact3
java.util
Class ArrayList<E>
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractList<E>
java.util.ArrayList<E>
All Implemented Interfaces:
Serializable , Cloneable , Iterable <E>, Collection <E>,
List <E>, RandomAccess
已知直接子类:
AttributeList , RoleList , RoleUnresolvedList
public class ArrayList<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
可调整大小的数组的实现List接口。实现所有可选列表操作,并允许
所有元素,包括null 。除了实现List 接口之外,该类还提供了一些方
法来操纵内部使用的存储列表的数组的大小。 (这个类是大致相当于
Vector,不同之处在于它是不同步的)。
该size,isEmpty,get,set,iterator和listIterator操作在固
定时间内运行。 add操作以摊余常数运行,即添加n个元素需要O(n)
个时间。 所有其他操作都以线性时间运行(粗略地说)。 与
LinkedList实施相比,常数因子较低。
每个ArrayList实例都有一个容量 。 容量是用于存储列表中的元素的
数组的大小。它总是至少与列表大小一样大。当元素添加到ArrayList
时,其容量会自动增长。 没有规定增长政策的细节,除了添加元素具
有不变的摊销时间成本。
应用程序可以添加大量使用ensureCapacity操作元件的前增大
ArrayList实例的容量。 这可能会减少增量重新分配的数量。
请注意,此实现不同步。 如果多个线程同时访问884457282749实例,
并且至少有一个线程在结构上修改列表,则必须在外部进行同步。
(结构修改是添加或删除一个或多个元素的任何操作,或明确调整后台
数组的大小;仅设置元素的值不是结构修改。)这通常是通过在一些自
然地封装了列表。 如果没有这样的对象存在,列表应该使用
Collections.synchronizedList方法“包装”。 这最好在创建时
完成,以防止意外的不同步访问列表:
List list = Collections.synchronizedList
(new ArrayList(...));
The iterators returned by this class's个 iterator
和listIterator方法是快速失败的 :如果列表在任何时间从结构上
修改创建迭代器之后,以任何方式除非通过迭代器自身remove种
或add方法,迭代器都将抛出一
ConcurrentModificationException。 因此,面对并发修改,迭代
器将快速而干净地失败,而不是在未来未确定的时间冒着任意的
非确定性行为。
请注意,迭代器的故障快速行为无法保证,因为一般来说,在不同步
并发修改的情况下,无法做出任何硬性保证。 失败快速迭代器尽力投
入ConcurrentModificationException 。 因此,编写依赖于此
异常的程序的正确性将是错误的:迭代器的故障快速行为应仅用于检
测错误。
二、LinkedList如下
compact1, compact2, compact3
java.util
Class LinkedList<E>
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractList<E>
java.util.AbstractSequentialList<E>
java.util.LinkedList<E>
参数类型
E - 在这个集合中保存的元素的类型
All Implemented Interfaces:
Serializable , Cloneable , Iterable <E>, Collection <E>,
Deque<E>, List <E>, Queue <E>
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable双链表实现List
和Deque接口。 实现所有可选列表操作,并允许所有元素(包括null )。
所有的操作都能像双向列表一样预期。 索引到列表中的操作将从开始或结
束遍历列表,以更接近指定的索引为准。
请注意,此实现不同步。 如果多个线程同时访问链接列表,并且至少有个线
程在结构上修改列表,则必须在外部进行同步。(结构修改是添加或删 除一
个或多个元素的任何操作;仅设置元素的值不是结构修改。)这通常通过在自
然封装列表的对象上进行同步来实现。 如果没有这样的对象存在, 列表应
该使用Collections.synchronizedList方法“包装”。 这最好在创建时完成,以
防止意外的不同步访问列表:
List list = Collections.synchronizedList(new LinkedList(...));
这个类的iterator和listIterator方法返回的迭代器是故障快速的 :
如果列表在迭代器创建之后的任何时间被结构化地修改,除了
通过迭代器自己的remove或add方法之外,迭代器将会抛出一个ConcurrentModificationException 。
因此,面对并发修改,迭代器将快速而干净地失败,而不是在未来
未确定的时间冒着任意的非确定性行为。
请注意,迭代器的故障快速行为无法保证,因为一般来说,在不同步并发修
改的情况下,无法做出任何硬性保证。 失败快速迭代器尽力投入
ConcurrentModificationException 。 因此,编写依赖于此异常的
程序的正确性将是错误的:迭代器的故障快速行为应仅用于检测错误。
以上素材来源于jdk1.8中文API.
从以上类介绍不难看出。
public class ArrayList<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, Serializable
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable
从这里可以看出来两个点不同了
一.继承的父类不同点:
ArrayList 继承自AbstractList
LinkedList继承自AbstractSequentialList
再延伸一下继承关系。那我们追溯一下上层父类可以看到。
//ArrayList的父类 AbstractList
compact1, compact2, compact3
java.util
Class AbstractList<E>
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractList<E>
All Implemented Interfaces:
Iterable <E>, Collection <E>, List <E>
已知直接子类:
AbstractSequentialList , ArrayList , Vector
//LinkedList的父类 AbstractSequentialList
compact1, compact2, compact3
java.util
Class AbstractSequentialList<E>
java.lang.Object
java.util.AbstractCollection<E>
java.util.AbstractList<E>
java.util.AbstractSequentialList<E>
All Implemented Interfaces:
Iterable <E>, Collection <E>, List <E>
已知直接子类:
LinkedList
AbstractSequentialList , ArrayList , Vector
同时作为AbstractList的子类。
AbstractSequentialList 作为LinkedList的父类。
可以看出继承关系虽然有共同的族系。然后辈分不同。
有兴趣的粉丝也可以深入去阅读以及深入剖析整个集合体系的源码。回归今天的主题接着介绍 ArrayList与LinkedList 的区别
二.实现接口不同点:
ArrayList实现了 List<E>, RandomAccess, Cloneable, Serializable
LinkedList实现了List<E>, Deque<E>, Cloneable, Serializable
抛开相同实现接口我们可以看到
ArrayList实现了 RandomAcces
LinkedList实现了Deque<E>
我们看下RandomAcces,Deque两者的来自JDK1.8API的介绍:
RandomAcces:
public interface RandomAccess
List实现使用的标记接口,表明它们支持快速(通常为恒定时间)随机访问。 此接口的主要目的是允许通用算法更改其行为,以便在应用于随机访问列表或顺序访问列表时提供良好的性能。
当施加到顺序访问列表(如LinkedList),用于操纵随机接入列表(如ArrayList)最好算法可以产生二次行为。 鼓励通用列表算法在应用如果应用于顺序访问列表之前提供较差性能的算法,并且如果需要改变其行为以确保可接受的性能,则检查给定列表是否为instanceof此接口。
人们认识到,随机访问和顺序访问之间的区别通常是模糊的。 例如,一些List实现提供渐近的线性访问时间,如果它们在实践中获得巨大但是恒定的访问时间。 这样的一个List实现应该通常实现这个接口。 根据经验, List实现应实现此接口,如果对于类的典型实例,此循环:
for (int i=0, n=list.size(); i < n; i++)
list.get(i);
比这个循环运行得更快:
for (Iterator i=list.iterator(); i.hasNext(); )
i.next();
循环1比循环2运行更快。
由此可以总结出来,RandomAccess实现是为了表明它们支持快速(通常为恒定时间)随机访问。接口的主要目的是允许通用算法更改其行为,以便在应用于随机访问列表或顺序访问列表时提供良好的性能。
另外从AbstractSequentialList介绍也可以知道,对于随机访问数据(如数组), AbstractList应优先于此类(AbstractSequentialList)。而LinkedList作为AbstractSequentialList的子类也具备了父类的特性。
==>实现接口RandomAccess适用场景为快速(通常为恒定时间)随机访问。
接下里我们继续阅读Deque
支持两端元素插入和移除的线性集合。 名称deque是“双端队列”的缩写,通常发音为“deck”。 大多数Deque实现对它们可能包含的元素的数量没有固定的限制,但是该接口支持容量限制的deques以及没有固定大小限制的deques。
该界面定义了访问deque两端元素的方法。 提供了插入,移除和检查元素的方法。 这些方法中的每一种存在两种形式:如果操作失败,则会抛出异常,另一种方法返回一个特殊值( null或false ,具体取决于操作)。 插入操作的后一种形式专门设计用于容量限制的Deque实现; 在大多数实现中,插入操作不能失败。
上述十二种方法总结在下表中:
Summary of Deque methods First Element (Head) Last Element (Tail) Throws exception Special value Throws exception Special value Insert addFirst(e) offerFirst(e) addLast(e) offerLast(e) Remove removeFirst() pollFirst() removeLast() pollLast() Examine getFirst() peekFirst() getLast() peekLast()
此接口扩展了Queue接口。 当使用deque作为队列时,FIFO(先进先出)行为的结果。 元素将添加到deque的末尾,并从头开始删除。 从Queue接口Deque方法正好等同于下表所示的Deque方法:
Comparison of Queue and Deque methods Queue Method Equivalent Deque Method add(e) addLast(e) offer(e) offerLast(e) remove() removeFirst() poll() pollFirst() element() getFirst() peek() peekFirst()
Deques也可以用作LIFO(先进先出)堆栈。 这个接口应该优先于传统的Stack类。 当一个deque作为一个堆栈时,元素从deque的开头被推出并弹出。 堆栈方法正好等同于下表所示的Deque方法:
Comparison of Stack and Deque methods Stack Method Equivalent Deque Method push(e) addFirst(e) pop() removeFirst() peek() peekFirst()
请注意,当使用deque作为队列或堆栈时, peek方法同样适用; 在任何一种情况下,元素都是从德甲开始绘出的。
该界面提供了两种方法去除内部元素, removeFirstOccurrence和removeLastOccurrence 。
与List接口不同,此接口不支持索引访问元素。
虽然Deque实现不是严格要求禁止插入空元素,但是强烈建议他们这样做。 强烈鼓励任何允许空元素的任何Deque实现的用户不能利用插入空值的能力。 这是因为null被用作特殊的返回值通过各种方法来表示deque是空的。
Deque实现通常不定义基于元素的equals和hashCode方法的版本,而是从类别Object继承基于身份的版本。
==>Deque支持两端元素插入和移除的线性集合。 名称deque是“双端队列”的缩写
由两者的父类以及实现的接口构造出其独特的形式存在。
从继承关系上来看,ArrayList至少称得上LinkedList的叔伯。
然而各自的特性却不能确定的是,不代表你是我叔叔就一定
比我强大。后面还有不同的老师教学。LinkedList也有适合自己的使用场景。
ArrayList有老师RandomAccess
LinkedList也有老师Deque
可以推论出来:
ArrayList支持随机访问
LinkedList支持两端元素插入和移除的线性集合
那这两种推论具体在哪里体现,以及怎么体现的呢?
因为尽管网上有很多关于ArrayList和LinkedList区别的不同,但都是别人总结出来的,若是被面试官问到其体现说不上来,就不好了。
我们可以来看一下。看源码来佐证一下,我们的推论,
这里不得不推及 继承和实现的区别了。
或者说,我们去试着重新手写一下 ArrayList和LinkedList构成实现,
会不会对于ArrayList和LinkedList更加清晰呢。
当然前期我们无法做到去根据其属性和特征就能完善好这两个类
的构造实现。我们可以去推论。一定可以加深我们对java抽象封装继承多态思想的理解。由于时间的原因,笔者之前也是没有自己阅读过ArrayList和LinkedList源码以及API的介绍。今天就不去从0到1重新手写ArrayList和LinkedList。感兴趣的粉丝可以去尝试手写。这也是一种自我提升的方向。
回归正题:
ArrayList支持随机访问
LinkedList支持两端元素插入和移除的线性集合
那这两种推论具体在哪里体现,以及怎么体现的呢?
LinkedList为何不适用随机访问,是因为ArrayList支持随机访问那LinkedList就不支持了吗?如果是从哪里可以看出来呢?
再次看源码:
ArrayList,LinkedList都有
get(int index)
返回此列表中指定位置的元素。
那么我们在深入去看同样是get(int index)两者又有何不同的具体实现?
//ArrayList
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
//LinkedList
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
以下两行代码我们可以知道这是查询前的检查,可以说都有检查步骤。这个不去细看具体检查步骤实现了。有检查就当是同样的行为 ,我们来看不同:
rangeCheck(index);
checkElementIndex(index);
最后的返回值调用的方法就出现了各自不同的实现了
ArrayList的elementData方法这不是数组索引嘛
linkedList的node方法做了,里面居然在循环。
在大批量数据存储的情况下,从这个方法上来看就可以看出
ArrayList的elementData方法linkedList的node方法在大批量数据
效率大多数时要快。
==ArrayList适合随机访问成立【业务场景随机访问】
==LinkedList的getFirst()getLast()方法获取值依然很有效率。
适合双端操作。【业务场景双端操作】
//ArrayList
elementData(index)
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
//linkedList
node(index).item;
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
ArrayList为何不适用添加删除,是因为LinkedList支持随机访问那ArrayList就不支持了吗?如果是从哪里可以看出来呢?
依然看源码:
//ArrayList
public boolean add(E e) {
//初始化容量+1
ensureCapacityInternal(size + 1); // Increments modCount!!
//容量最大值赋值
elementData[size++] = e;
return true;
}
//LinkedList
public boolean add(E e) {
//直接调用方法
linkLast(e);
return true;
}
根据上面的两个add方法好像看不出来什么区别?
那我们换个角度去看:
添加是只有一种方法添加吗?或者说添加两者之间是否存在独特的添加方法,以独特方法出现造成了适用添加的业务场景呢?
我们对比ArrayList和LinkedList中的已知添加方法
ArrayList
boolean add(E e) :将指定的元素追加到此列表的末尾
void add(int index, E element) :
在此列表中的指定位置插入指定的元素。
boolean addAll(Collection<? extends E> c)
按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
boolean addAll(int index, Collection<? extends E> c)
将指定集合中的所有元素插入到此列表中,从指定的位置开始。

LinkedList
boolean add(E e)
将指定的元素追加到此列表的末尾。
void add(int index, E element)
在此列表中的指定位置插入指定的元素。
boolean addAll(Collection<? extends E> c)
按照指定集合的迭代器返回的顺序将指定集合中的所有元素追加到此列表的末尾。
boolean addAll(int index, Collection<? extends E> c)
将指定集合中的所有元素插入到此列表中,从指定的位置开始
void addFirst(E e)
在该列表开头插入指定的元素。
void addLast(E e)
将指定的元素追加到此列表的末尾。
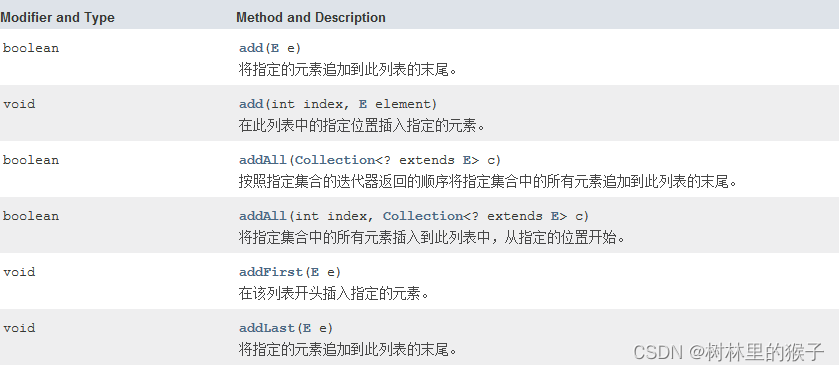
方法上就LinkedList比ArrayList多了两个区别方法
addFirst
addLast
大批量数据新增的时候,是否调用这两个方法比ArrayList中的Add方法要快呢?
如果能,是否佐证了LinkedList更适合添加操作的业务场景。
当然我们可以试用循环来定性这一点,但是具体体现在哪一行代码呢?这个才是今天的关键,也是我们以后碰到问题寻根溯源可以推敲的点面之一。问题越清晰,才能更好去处理他。
重点看
ArrayList add
public boolean add(E e) {
//初始化容量+1
ensureCapacityInternal(size + 1); // Increments modCount!!
//容量最大值赋值
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
由此可见ArrayList的add方法的复杂性add方法内部就调用7次以上。
再看LinkedList的 add addFirst addLast三个方法。
public boolean add(E e) {
//直接调用方法
linkLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
代码结构和处理上就简单多了。判断+赋值。
相比于ArrayList除了添加元素内容还要处理初始化容量,扩容等等问题。这样就可以理解了LinkedList更适合做添加的业务场景了。
那怎么佐证删除呢,同样我们整理源代码进行比较
ArrayList的删除方法
E remove(int index)
删除该列表中指定位置的元素。
boolean remove(Object o)
从列表中删除指定元素的第一个出现(如果存在)。
boolean removeAll(Collection<?> c)
从此列表中删除指定集合中包含的所有元素。
boolean removeIf(Predicate<? super E> filter)
删除满足给定谓词的此集合的所有元素。
protected void removeRange(int fromIndex, int toIndex)
从这个列表中删除所有索引在 fromIndex (含)和 toIndex之间的元素。
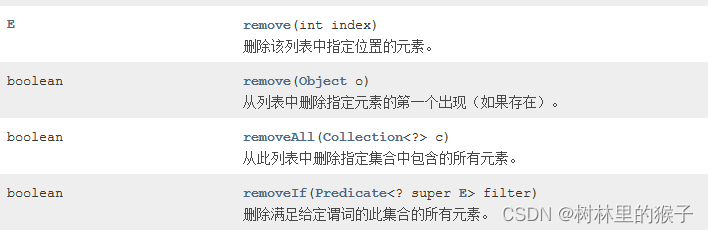
LinkedList的删除方法
E poll()
检索并删除此列表的头(第一个元素)。
E pollFirst()
检索并删除此列表的第一个元素,如果此列表为空,则返回 null 。
E pollLast()
检索并删除此列表的最后一个元素,如果此列表为空,则返回 null 。
E pop()
从此列表表示的堆栈中弹出一个元素。
void push(E e)
将元素推送到由此列表表示的堆栈上。
E remove()
检索并删除此列表的头(第一个元素)。
E remove(int index)
删除该列表中指定位置的元素。
boolean remove(Object o)
从列表中删除指定元素的第一个出现(如果存在)。
E removeFirst()
从此列表中删除并返回第一个元素。
boolean removeFirstOccurrence(Object o)
删除此列表中指定元素的第一个出现(从头到尾遍历列表时)。
E removeLast()
从此列表中删除并返回最后一个元素。
boolean removeLastOccurrence(Object o)
删除此列表中指定元素的最后一次出现(从头到尾遍历列表时)。
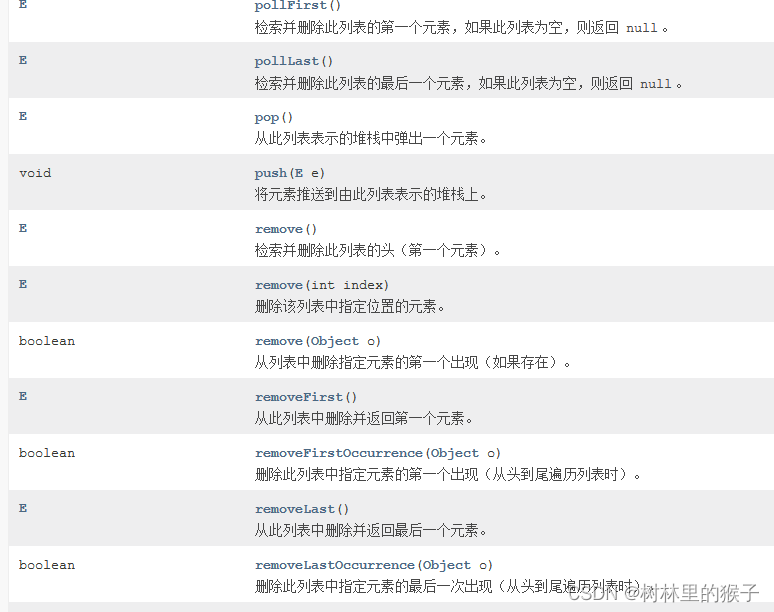
这种情况下我们先比较常见的方法如remove方法
ArrayList 删除方法
//ArrayList还是需要调用其他方法
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy
(elementData, index+1, elementData,index,numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
LinkedList删除方法
// LinkedList remove索引删除方式 依然是判断赋值一套
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
//不管是第一个还是最后一个都是判断赋值
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
由此可以总结出来了,ArrayList在做删除处理的操作也是需要调用其他方法,而LinkedList则是判断赋值这个处理。这个跟添加是相似的。由此也作为佐证,LinkedList比ArrayList更适合添加删除的业务场景
最后总结:
ArrayList与LinkedList区别:
1.继承自不同的父类:
ArrayList:AbstractList
LinkedList :AbstractSequentialList
2.实现接口特有差别:
ArrayList实现了RandomAccess
LinkedList实现了Deque接口
3.支持的业务场景不同:
ArrayList更适合随机访问
LinkedList更适合添加删除
4.底层结构不同:
ArrayList底层是数组
LinkedList是链表
目前笔者对于java的理解还是很浅显的,欢迎各位大神在评论区补充修正!
















 6456
6456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









