




 博客介绍了NoSQL,指出关系数据库缺点,阐述NoSQL优点与适用场景。介绍NoSQL五大分类,如键值存储数据库、列存储数据库等的适用与不适用场景。还讲解高性能缓存架构,包括缓存策略、方式,以及缓存误用情况和解决办法。
博客介绍了NoSQL,指出关系数据库缺点,阐述NoSQL优点与适用场景。介绍NoSQL五大分类,如键值存储数据库、列存储数据库等的适用与不适用场景。还讲解高性能缓存架构,包括缓存策略、方式,以及缓存误用情况和解决办法。
从公众号转载,关注微信公众号掌握更多技术动态

---------------------------------------------------------------
一、NOSQL简介
1.关系数据库存在如下缺点
(1)关系数据库存储的是行记录,无法存储数据结构
以微博的关注关系为例,“我关注的人”是一个用户 ID 列表,使用关系数据库存储只能将列表拆成多行,然后再查询出来组装,无法直接存储一个列表。
(2)关系数据库的 schema 扩展很不方便
关系数据库的表结构 schema 是强约束,操作不存在的列会报错,业务变化时扩充列也比较麻烦,需要执行 DDL(data definition language,如 CREATE、ALTER、DROP 等)语句修改,而且修改时可能会长时间锁表(例如,MySQL 可能将表锁住 1 个小时)。
(3)无法应对每秒上万次的读写请求
硬盘IO此时也将变为性能瓶颈(由于表之间关联关系导致的)。同时大数据场景下 I/O 较高如果对一些大量数据的表进行统计之类的运算,关系数据库的 I/O 会很高,因为即使只针对其中某一列进行运算,关系数据库也会将整行数据从存储设备读入内存,所以大数据查询SQL效率极低。
(4)关系数据库的全文搜索功能比较弱
关系数据库的全文搜索只能使用 like 进行整表扫描匹配,性能非常低,在互联网这种搜索复杂的场景下无法满足业务要求。
2.什么是NOSQL
NoSQL != No SQL,而是 NoSQL = Not Only SQL。非关系型数据库,存储的数据不需要固定的模式,无须多余操作就可以横向扩展,虽然NOSQL可以解决关系型数据库的问题,但是同时它也牺牲了ACID中的一点或者几点。
3.NoSQL数据库的优点
-
海量数据下,读写性能优异,存储和访问的需求效率高
-
数据模型灵活,什么样的数据类型都可以(不需要像sql一样在建表的时候定义字段的数据类型)
-
数据间无关系,易于扩展,实时更改数据库
4.适用场景
高并发的操作是不建议有关联查询的,互联网公司用数据字段的冗余避免关联查询。分布式项目跨数据库、服务器进行表关联查询是十分不推荐的。
文件存储格式为BSON(一种JSON的扩展)BSON(Binary Serialized document Format)存储形式是指:存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各种复杂的文件类型。
SQL数据库适合那些需求确定和对数据完整性要求严格的项目。NoSQL数据库适用于那些对速度和可扩展性比较看重的那些不相关的,不确定和不断发展的需求。简单来说就是:
-
SQL是精确的。它最适合于具有精确标准的定义明确的项目。典型的使用场景是在线商店和银行系统。
-
NoSQL是多变的。它最适合于具有不确定需求的数据。典型的使用场景是社交网络,客户管理和网络分析系统。
很少有项目能够很好的适用于一种数据库。如果你对数据的需求比较小或是非标准化的数据任何一种数据库都是可以的。你比我更了解你的项目,我不建议你将SQL上的数据移植到NoSQL上反之亦然,除非它能够提供非常可观的收益。当然选择权在于你自己。在项目的一开始就要考虑好使用它们的利弊,这样才不会导致选择错误。
二、NoSql的五大分类
1.键值(Key-Value)存储数据库(解决关系数据库无法存储数据结构的问题)
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。例如:Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB。Redis 是 K-V 存储的典型代表,它是一款开源(基于 BSD 许可)的高性能 K-V 缓存和存储系统。Redis 的 Value 是具体的数据结构,包括 string、hash、list、set、sorted set、bitmap 和 hyperloglog,所以常常被称为数据结构服务器。
(1)不适用场景
-
取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径。
-
需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
-
事务的支持。Redis 的事务只能保证隔离性和一致性(I 和 C),无法保证原子性和持久性(A 和 D)。虽然 Redis 并没有严格遵循 ACID 原则,但实际上大部分业务也不需要严格遵循 ACID 原则。以上面的微博关注操作为例,即使系统没有将 A 加入 B 的粉丝列表,其实业务影响也非常小,因此我们在设计方案时,需要根据业务特性和要求来确定是否可以用 Redis,而不能因为 Redis 不遵循 ACID 原则就直接放弃。
(2)适用的场景
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
缓存:缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多。
排行榜:很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
计数器:什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。
分布式会话:集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
分布式锁:在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。
社交网络:点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。
最新列表:Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。
消息系统:消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
2.列存储数据库(解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表)
列式数据库就是按照列来存储数据的数据库,与之对应的传统关系数据库被称为“行式数据库”,因为关系数据库是按照行来存储数据的。
(1)适用的场景
业务同时读取多个列时效率高,因为这些列都是按行存储在一起的,一次磁盘操作就能够把一行数据中的各个列都读取到内存中。
能够一次性完成对一行中的多个列的写操作,保证了针对行数据写操作的原子性和一致性;否则如果采用列存储,可能会出现某次写操作,有的列成功了,有的列失败了,导致数据不一致。
行式存储的优势是在特定的业务场景下才能体现,如果不存在这样的业务场景,那么行式存储的优势也将不复存在,甚至成为劣势,典型的场景就是海量数据进行统计。例如,计算某个城市体重超重的人员数据,实际上只需要读取每个人的体重这一列并进行统计即可,而行式存储即使最终只使用一列,也会将所有行数据都读取出来。如果单行用户信息有 1KB,其中体重只有 4 个字节,行式存储还是会将整行 1KB 数据全部读取到内存中,这是明显的浪费。而如果采用列式存储,每个用户只需要读取 4 字节的体重数据即可,I/O 将大大减少。
除了节省 I/O,列式存储还具备更高的存储压缩比,能够节省更多的存储空间。普通的行式数据库一般压缩率在 3:1 到 5:1 左右,而列式数据库的压缩率一般在 8:1 到 30:1 左右,因为单个列的数据相似度相比行来说更高,能够达到更高的压缩率。
同样,如果场景发生变化,列式存储的优势又会变成劣势。典型的场景是需要频繁地更新多个列。因为列式存储将不同列存储在磁盘上不连续的空间,导致更新多个列时磁盘是随机写操作;而行式存储时同一行多个列都存储在连续的空间,一次磁盘写操作就可以完成,列式存储的随机写效率要远远低于行式存储的写效率。此外,列式存储高压缩率在更新场景下也会成为劣势,因为更新时需要将存储数据解压后更新,然后再压缩,最后写入磁盘。
基于上述列式存储的优缺点,一般将列式存储应用在离线的大数据分析和统计场景中,因为这种场景主要是针对部分列单列进行操作,且数据写入后就无须再更新删除(比如日志和博客文章等)
-
数据压缩比较有优势
-
任何列都可以做索引
-
查询时只有涉及到的列会被读取
(2)不适用场景
-
如果需要ACID事务。Vassandra就不支持事务。
-
原型设计。如果我们分析Cassandra的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
-
每次查询时,都需要对查询到的列进行数据重新组装
-
插入/更新操作比较困难
(3)列式存储查询过程
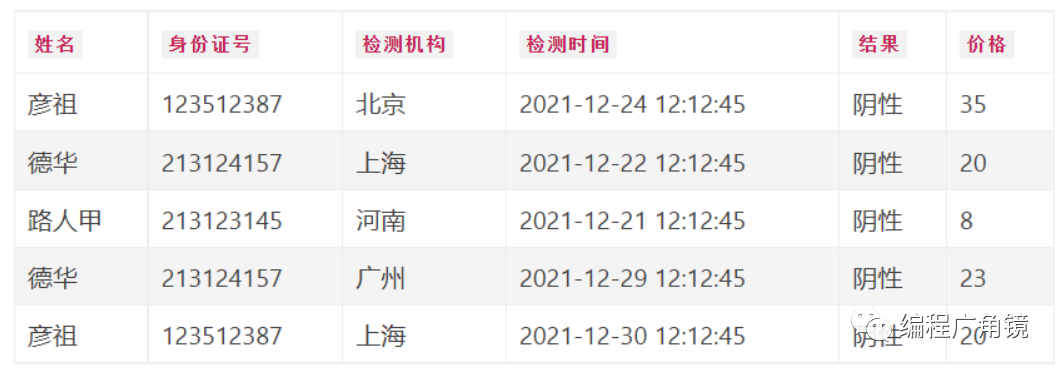
-
在列存储中,对于同样的核酸记录表,存储的物理结构如下:

在列式存储中,会把每一列存储到一起,如姓名列,是把所有记录中的姓名这列的值使用连续空间存放到一起
而对于各个列之间,是没有必要使用连续空间存放到一起的,所以很多列式数据库都使用了分布式存储的方式,存储各个列
①数据压缩
-
很多列式数据库都是通过字典表的方式进行数据压缩,因为是把每一列存放到一起的,所以很容易通过对于每一列进行去重,来构建一个字典表,例如:对于姓名列,这列的所有数据如下:
彦祖|德华|路人甲|德华|彦祖
对这列值去重以后,构建一张姓名列字典表,构建算法忽略,就使用自增id的方式,如下:
| id | 姓名列 | |-----|-----| |1| 彦祖 | |2| 德华 | |3| 路人甲 |
-
这样构建字典表,对于列存储的物理存储结构,就可以执行存储字典表中的id,而不用存储具体的值(而且重复值可以用相同的id替代),有了字典表以后姓名列存储如下:
1|2|3|2|1
-
同样对于价格列,这列的所有数据如下:
35|20|8|23|20
对这列值去重以后,构建一张价格列字典表,构建算法忽略,就使用自增id的方式,如下:
| id | 价格列 | |-----|-----| |1| 35 | |2| 20 | |3| 8 | |4|23|
-
有了字典表以后价格列存储如下:
1|2|3|4|2
②查询执行流程
select * from 核酸记录表 where 姓名=彦祖 and 价格=20
对于该sql,执行过程如下:
1.对于where 姓名=彦祖 首先查询姓名字典表,查询到彦祖的id=1

2.通过查询到彦祖的id,对于性名列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









