






视频链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
1. LLM发展
LLM是近年来人工智能领域的一个重要发展方向。大型语言模型的历史可以追溯到2017年,当时OpenAI推出了GPT-1(Generative Pre-trained Transformer)模型,这是一个基于Transformer架构的语言生成模型,在多个自然语言处理任务上取得了突破性进展。之后,研究人员不断改进和扩大语言模型的规模和能力。2019年,GPT-2模型推出,模型参数增加到1.5亿。2020年,GPT-3模型发布,参数增至1760亿,在多种语言理解和生成任务上均展现出优异的性能。
2. 专用模型和通用模型
大模型的发展背景与通用人工智能的目标息息相关。早期的人工智能研究主要集中在专用模型上,即针对特定的任务或应用场景开发专门的模型。这种方法虽然在某些任务上可以取得优秀的性能,但存在局限性:需要为每个任务单独开发模型,缺乏灵活性和迁移能力。
然而,人工智能研究的最终目标是实现通用人工智能(AGI)——一种能够广泛应用于各种任务和领域的智能系统。为此,研究者们转向了一种新的范式:通用大模型的开发。
通用大模型是指参数量巨大、覆盖广泛的通用模型,这些模型通过海量的训练数据积累了丰富的知识和能力,能够适用于多种不同的任务和模态。相比之前的专用模型,大模型具有更强的迁移学习能力,可以通过少量的细化训练在特定任务上发挥出色的性能。
专用模型(Specialized Models):
- 这类模型针对特定的任务或应用场景进行定制和优化,比如人脸识别、图像分类、目标检测模型等。
- 专用模型通常拥有较小的参数量和数据集,训练目标明确,在特定任务上能够发挥出色的性能。
- 这类模型的优势在于高效、可解释性强,可以更好地适应特定需求。但缺点是通用性和迁移能力较弱。
通用大模型(General Large Models):
- 这类模型具有广泛的知识覆盖和强大的学习能力,一个模型对应多种任务、多种模态。具有非常高的通用性。
- 代表有GPT-3、BERT、InstructGPT等大型语言模型。
- 通用大模型的训练数据极其庞大,包括网页、书籍、新闻等海量文本,因此具有强大的知识积累和推理能力。
- 这类模型擅长于迁移学习,可以通过微调在特定任务上发挥优秀的性能。但也存在可解释性相对较弱的问题。
3. 书生浦语大模型学习
为什么是书生浦语大模型?
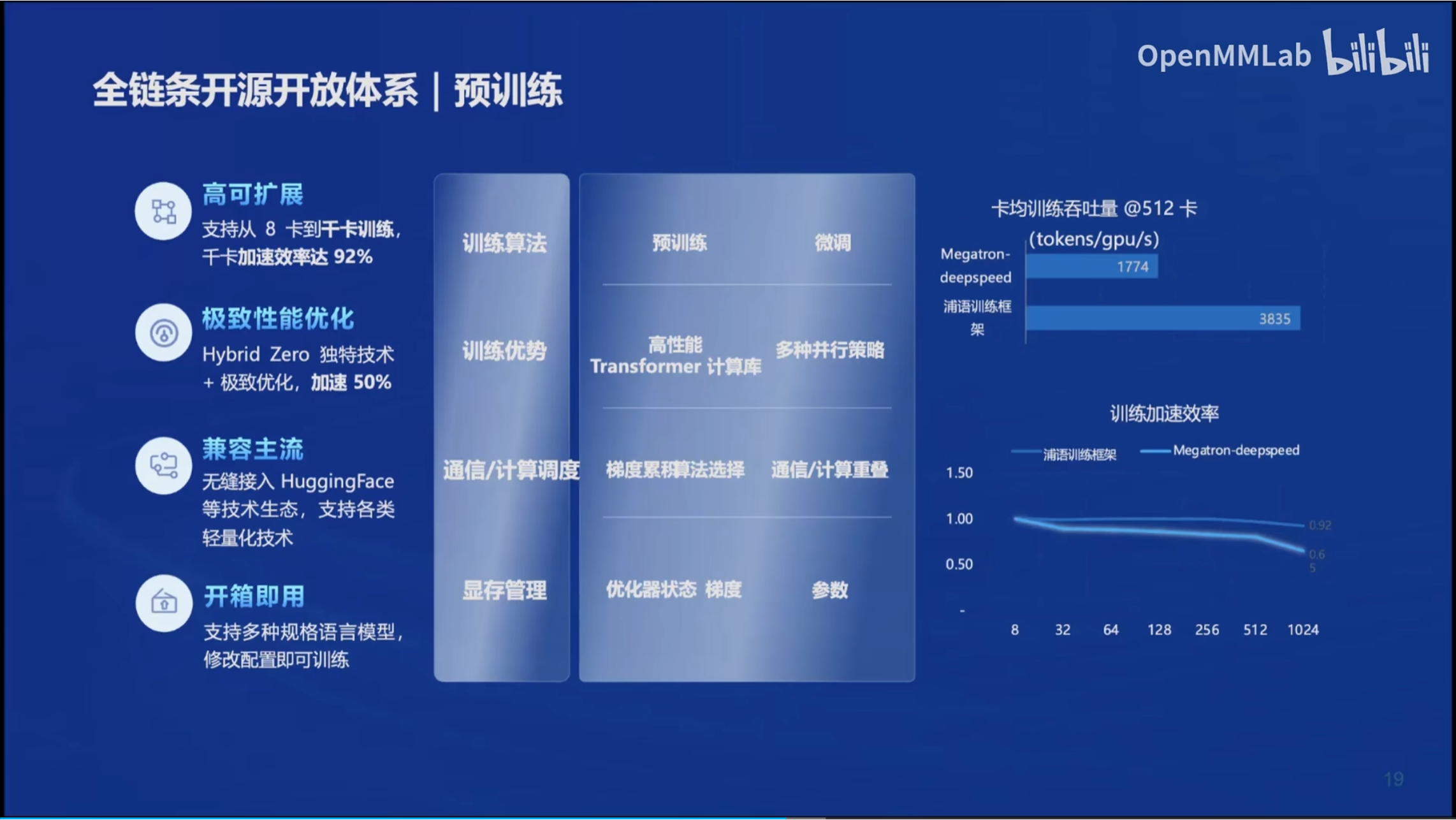
1. 工具链极其完善!支持开源精神!

2. 性能强!
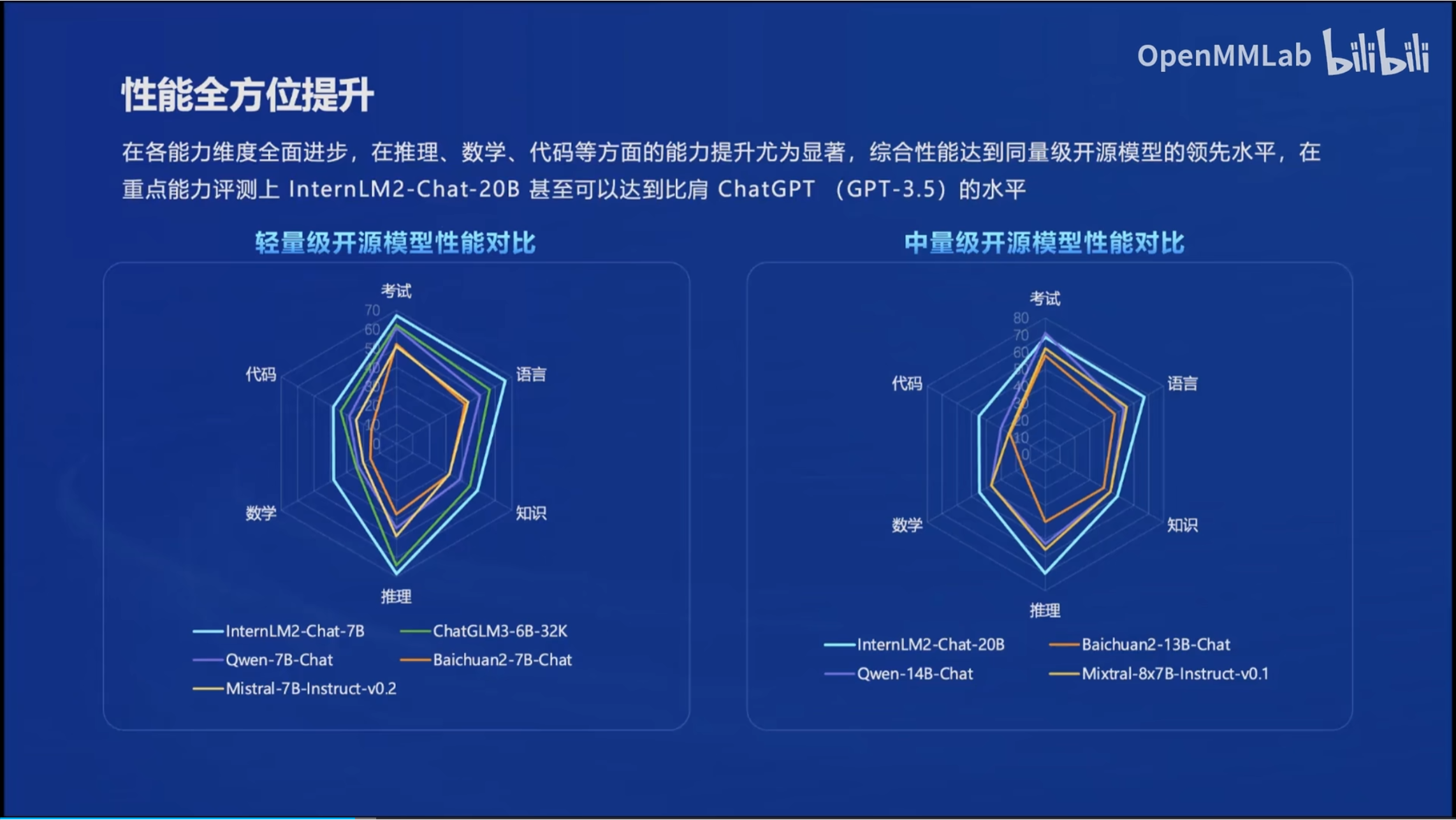
3. 数据集都开放,谁能不爱?

4. 兼容性强,支持HuggingFace!
















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











