







Scala总结(中篇)
接Scala总结(上篇)
补充和复习
0.1 练习
- 题目1:如果想把一个任意的数字A通过转换后得到它的2倍,那么这个转换的函数应该如何声明和使用
def fun1(A: Double) = {
2 * A
}
val result1 = fun1(10)
println(result1) //20.0
- 题目2:如果上一题想将数字A转换为任意数据B(不局限为数字),转换规则自己定义,该如何声明
//定义函数,转换的规则通过匿名函数的方式定义
def fun2 (A : Double ,f : (Double) => Any ) = {
f(A)
}
//调用函数,并使用匿名函数进行传递参数
val result2 = fun2(10, (m: Double) => {"age is :" + m})
println(result2) // age is :10.0
- 题目3:如果函数调用: test(10,20,c)的计算结果由参数c来决定,这个参数c你会如何声明
def fun3 (i : Int , j : Int , f : (Int,Int) => Any)= {
f(i,j)
}
val result3 = fun3(10,20, _ + _ )
println(result3) //30
- 题目4:如果设计一个用于过滤的函数,你会如何做?
// 要求:对传递的包含多个单词的字符串参数,根据指定的规则对word进行过滤
// 例子:“hello world scala spark” => 首写字母为s => “scala, spark”
def fun4(s: String, f: (String) => Boolean) = {
val strings = s.split(" ")
var result = ""
for (word <- strings) {
if (f(word)) {
result += ", " + word
}
}
result.substring(2)
}
val result4 = fun4("hello world scala spark", (s: String) => {s.startsWith("s") })
println(result4) //scala, spark
0.2 知识点补充
-
- for()循环中的i为什么声明为val还能重复改变值

解析:i是val类型,应该是不可变,但是可以循环给i进行赋值,通过反编译发现,i 只是一个普通变量,是可变的

-
- 匿名函数后面的代码不执行
解析:通过反编译工具发现,当匿名函数没有使用变量来接收的,那么编译时会将匿名函数及其后续所有的代码包装给一个匿名函数,又因为这个匿名函数没有被调用,所以匿名函数后面的代码不执行。
-
- 循环反向操作
for ( i <- 5 to 1 by -1 ) { println(i) //5 4 3 2 1 } //加上负的步长就可以了
0.3 线程中wait 和 sleep的区别
-- 本质区别:wait()是成员方法,sleep()是静态方法
在IDEA中,静态方式显示为斜体字。
--成员方法:和对象有关。
--静态方法:和对象无关,与类有关,所以对象调用sleep()方式,并不会使当前对象的线程进行休眠,而是正在执行的类的线程(main)休眠。
验证:如果理解上面的话呢?
如下代码中说明
-- 既然在main方法中不能将指定线程休眠,那sleep一般怎么用呢
1. 一般写在run()方法中,因为之所以会有线程,就是多个线程操作同一资源,只要在资源操作的run()方法中使用sleep比较有意义。
2. 如果是想交替使用线程,那么使用wait + notify 结合使用
3. 如果是等待线程的结果,那么就使用join的方式
public class Thread_Test {
public static void main(String[] args) {
Window1 w = new Window1();
Thread t1 = new Thread(w);
Thread t2 = new Thread(w);
Thread t3 = new Thread(w);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
/*
验证方式如下:
1) 未加上 t1.sleep(500)代码时,窗口1.2.3均有售票
2) 加上t1.sleep(500)代码时,只有窗口1售票
原因是:当加上如上代码以后,mian线程出现了休眠,则导致t2.start()和t3.start(),代码没有执行,即t2
线程和t3线程没有启动,此时则只有t1线程被启动,所以当main线程休眠时间结束以后,t2和t3线程被启动,但是此时t1已经将100张票已经售完。
*/
t1.start();
try {
t1.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
t2.start();
t3.start();
}
}
class Window1 implements Runnable {
private int ticket = 100;
public void run() {
while (true) {
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "售票,票号为:" + ticket);
ticket--;
} else {
break;
}
}
}
}

0.4 双亲委派机制
--双亲委派机制:类加载时有三个加载器
1. 应用类加载器: 加载环境变量classpath下的类
2. 扩展类加载器: 加载jdk扩展的类库
3. 启动类加载器: 加载jdk自带的rt.jar
-- 自定义类加载的过程:
见如下图:
过程1 --> 过程2 --> 过程3 --> 过程4
过程 1: 应用类加载器将自定义类委派给扩展类加载器;
过程 2: 扩展类加载器将被委派的类再委派给启动类加载;
过程 3: 启动类加载器确认rt.jar中是否有被委派的类,如果有,那么就直接加载到内存中,假如没有,那委派给扩展类加载器进行加载
过程 4: 扩展类加载器确认jdk自带的类库中是否有被委派的类,如果有,那么就直接加载到内存中,假如没有,那委派给应用类加载器加载这个类
最后,如果经过委派以后,类没有被加载,则就由应用类加载器进行加载。
-- 加载器文件的路径,见图片路径
1. 应用类加载器: 加载环境变量classpath下的类
2. 扩展类加载器: D:\03_developer_tools\Java\jdk1.8.0_141\jre\classes
3. 启动类加载器: D:\03_developer_tools\Java\jdk1.8.0_141\jre\lib\ext



05.下划线的作用
1. 下划线可以作为标识符使用
2. 下划线可以将函数作为整体使用
3. 下划线在匿名函数中可以代替参数使用
4. 下划线在导类时可以代替java中的星号
5. 下划线可以将指定类在编译时隐藏
6. 下划线可以对类的属性进行默认初始化
7. 如果匿名函数的参数不参与逻辑处理,可以使用下划线省略
8. 下划线在模式匹配中可以表示其他的值
9. 下划线在泛型中可以表示任意类型
六 、 函数式编程
6.4 函数高阶用途 – 地狱班
6.4.3 函数作为返回值
--函数作为返回值
嵌套函数的方式
此时返回函数的方式有两种:
1)使用"函数名_"方式;
2)不使用下划线,显示声明返回值类型,与需返回的函数类型保持一致。
//方式1:使用"函数名_"方式;
def fun1() = {
def fun2() = {
println("scala")
}
fun2 _
}
//方式2:不使用下划线,显示声明返回值类型,与需返回的函数保持一致
def fun3(): () => Unit = {
def fun4() = {
println("scala")
}
fun4
}
fun3()()
6.4.4 闭包
内存的两个问题:
--问题1:new 一个对象会存放在内存中什么地方?
三个地方:
1. 堆空间
2. 栈空间
会不会进入栈空间,有一个机制:逃逸分析,如果这个对象执行完成以后就释放了,不会被引用和调用,即这个对象不会跳出当前定义的作用域,不被外界所用,那么就可以在栈空间。
3. 堆外空间
假设操作系统的1/64的空间作为内存,内存中的1/4作为java虚拟机的内存,剩余3/4为操作系统的内存,那么用户就可以找操作系统借一部分内存进行使用,这部分内存是人工可控的。
-- 问题2:GC(垃圾回收器),怎么理解?
优点:由java虚拟机自动完成内存的释放
缺点:人工不能参与
GC有一个守护进程,在内存空间的时候,进行内存垃圾的清理,这样对gc执行释放内存的时间不可控的。
假设:此时内存为10个G,剩余1个G可用,用户有一个2G的数据需要加载,则需要java虚拟机释放1G以上的资源给这个任务,但是GC并不会立马就释放。
-- 内存栈和堆知识点
1. java执行方法时,会将方法加载到内存的栈空间中,存在压栈、栈帧、栈顶、弹栈的概念。
2. 方法的执行:每次会执行栈顶的方法,方法执行结束后就会弹栈,如果方法没有执行完成,有新方法进栈后,则会将当前栈顶的方法向下 压"压栈",新进的方法充当栈顶的位置,依次类推。
3. 栈帧,就是栈的深度,长度的概念,每个方法加载到栈空间,都是有指针指向它。
4. 逐级压栈,逐级弹栈。
-- 问题1 : 什么是闭包
函数使用外部变量时,当外部变量失效时,会将这个变量包含到当前的函数,形成闭合的使用效果,改变了变量的生命周期。
关键点:
1)外部变量:不在本函数中的变量。
2)被使用:虽然函数引用了到外部变量,但是函数没有被使用,不会有闭包的效果。
3)变量的生命周期:只要当变量的生命周期结束以后再进行调用时,此时才会出现变量的生命周期出现改变,不然就不会有闭包
-- 问题2 : 如何查看是否是闭包
1. scala2.12版本中,反编译后,发现编译器重新声明了内部函数的参数,将使用外部变量作为内部函数的参数使用。
2. 早期Scala版本(2.11),闭包会被编译为匿名函数类,如果使用外部变量,会将外部变量作为类的属性。
早期Scala版本(2.11), 即使没有使用外部的变量,也会有闭包的效果,只是没有包含外部变量。
-- 问题3 : 闭包有什么作用
在spark中,有一个功能:判断闭包:使用类名是否为匿名函数的方式进行判断
-- 问题4 : 什么时候会有闭包
1. 匿名函数会有闭包的情况
2. 将函数赋值给一个变量时会有闭包的情况
3. 嵌套函数,内部函数使用到了外部函数的变量,则会有闭包的情况
def fun10(i: Int) = {
def fun11(j: Int) = {
i + j
}
fun11 _
}
//调用fun10函数,返回了fun11函数。并将函数赋值给一个变量intToInt1
val intToInt1 = fun10(10)
//这就是一个典型的情况,此时调用函数fun11,但是函数中有两个变量i和j,但是我们只传入了一个形参参数j,但是能够计算出结果,说明i也已经加载到了fun11函数中
val i = intToInt1(10)
println(i) // 20
6.4.5 函数柯里化
--函数的柯里化
-- 1.作用:
a、用来"简化嵌套函数"的开发
b、将复杂的参数逻辑简单化,可以支撑更多的语法
-- 2. 什么是柯里化:
a、柯里化是一个人名字,没有什么实际的含义
b、"实际就是多个形参列表"
// 嵌套函数
def fun12(i: Int) = {
def fun13(j: Int) = {
i * j
}
fun13 _
}
println(fun12(10)(12)) //120
//使用函数的柯里化
def fun14(i: Int)(j: Int) = {
i * j
}
println(fun14(10)(12)) //120
6.4.6 控制抽象
-- 控制抽象
-- 1. 什么是控制抽象
将一段代码或逻辑作为一个参数传入给函数。
-- 2. 控制抽象有什么用
在写框架的时候用的特别多。
-- 3. 怎么使用控制抽象
案例:以中断函数为例进行借鉴
总结中断函数:
1) breakable是一个函数,用来捕捉异常
2) 参数列表中如果有多行逻辑,可以采用大括号进行代替
3) 支持代码逻辑作为参数传递给函数使用
4) 如果函数想要传递代码逻辑,那么类型声明需要声明为:
"参数名 : => 返回值类型"
5) 因为参数类型中没有声明小括号,所以调用这个参数时也不能使用小括号
def fun15(op: => Unit) = {
try {
//变量,执行形参时,不需要加()
op
println("op执行成功")
} catch {
case ex: Exception => println("op逻辑执行失败,原因是:" + ex.getMessage)
}
}
fun15 {
Breaks.breakable {
for (i <- 1 to 5) {
if (i == 3) {
Breaks.break()
}
println(i)
}
}
println("scala , java ")
}
6.4.7 递归
--递归函数
-- 1. 为什么要再讲递归函数呢?
递归函数的条件:
a、方法执行的过程中,调用自己
b、存在退出递归的逻辑,否则方法调用时报StackOverFlowError异常
c、方法调用时,传递的参数之间存在规律
d、"scala 中递归方法需要声明返回值类型"
-- 2. 当前的递归存在什么问题呢?
当每次被调用递归函数时,方法并没有执行结束,而是需要等下次调用递归函数的返回结果时,调用的次数一旦超过栈空间的指针数 量,导致栈空间不足,报StackOverFlowError异常.
-- 3. 解决方案:
1) 加大栈空间的内存
2) 尾递归
-- 4. 什么是尾递归?
递归的方法不依赖于外部的变量,每次调用时都能执行完成。
达到这种效果原因:编译器碰见尾递归时,会自动转换为while循环
"实现方式":使用一个变量来接收每次递归的结果并作为参数再传递到递归函数中
"尾递归达到一定次数也会产生栈溢出错误"
//声明一个递归函数,计算累计和
def fun16(num: Int): Double = {
if (num <= 1) {
1
} else {
num + fun16(num - 1)
}
}
//调用函数,报错,StackOverFlowError
val result = fun16(1000)
println("结果=" + result)
// 使用尾递归声明递归函数
var flag = true
def fun17(i: Int, result: Int): Any = {
if (i < 1) {
println("输入的数据无效,输入值需 >= 1 ")
flag = false
} else if (i == 1) {
result
} else {
fun17(i - 1, i + result)
}
}
//调用函数,能够正常运行
val result1 = fun17(10000000, 0)
if (flag) {
println("结果是:" + result1)
}
6.4.8 惰性函数
--惰性函数:
-- 1. 实现原理
lazy延迟加载功能是编译器在编译时产生大量的方法进行调用所实现的。
-- 2. 使用场景
如创建了大量对象在内存中,但是不立即使用,如等1个小时以后再用,则在这1小时内存被占着,别的操作也不能使用被占用的内存
-- 3. 使用方式
在变量前增加lazy关键字,则用到数据时再进行加载。
def fun19(i: Int) = {
println("zhangsan")
i
}
lazy val m = fun19(10)
println("=================")
println(m)
//运行结果:先执行的打印===========
=================
zhangsan
10
七、 面向对象编程
scala面向对象的思想和java基本上是一致的。
7.1包 -package
- java中的包
-- 包
--1. 声明包(起名):域名反写 + 项目名称 + 模块名 + 程序类型名称
a、什么是域名:www.baidu.com --> baidu.com是域名,www不是域名,所以域名反写为:com.baidu
b、程序类型名称:比如util(工具)、core(核心)、test(测试)等包
c、但是在实际的使用过程中,我们基本上是不太关注包名,所以怎么简单怎么来,导致我们在看别人的代码时就会出现下面这种包名:" c.a.b.s.bean.JavaUser06"
-- 2. 包的作用
2.1 管理类:将声明的类分门别类的管理起来
-- 我们现在通过类名也可以看出来类的作用,所以管理类的作用就没那么重要,如下:
service.UserService => UserService
bean.JavaUser06 => BeanJavaUser06
2.2 区分类 :依靠包名进行区分,也没那么重要了,如Date
java.sql.Date => SQLDate
java.util.Date => UtilDate
2.3 类的访问权限:因为我们不能很好的使用4种管理权限,基本就是public private,所以也就没那么重要了;
2.4 编译类:类的源码程序应该和所在的包名保持一致 --> 这是java的限制
-- 3. 总结:Java语法中,package包语法的作用没有那么强大。所以Scala语言对package语法进行了功能的补充,更加强大。
- Scala中的包
-- 1. package和源码文件的物理路径没有关系
a、scala会按照package的声明编译指定路径的class
b、当前类编译后会在最后的package所在的包中生成class文件
-- 2. package关键字可以多次声明
a、识别时是自上而下的层级关系。
-- 3. package可以使用层级结构
a、在package包名的后面增加大括号,设定作用域范围以及层级关系
b、子包可以直接访问父包中的内容,无需import导入 -- 在同一源码文件中才有效
-- 4. 包也可以当成对象来使用
a、package中为了和java兼容,默认不能声明属性和函数(方法),声明类是可以的。
b、scala提供了一种特殊的对象声明方式: 包对象,"可以将一个包中共通性的方法或属性在包对象中声明。"
c、一个包只能创建一个包对象;
d、在包对象中的方法、属性和类可以被包中所有的类使用。
7.2 导入 - import
- java中的导入
--1. 导类,不是导包
--2. import static 静态导入,导入类的静态属性和静态方法
- java语法中import操作功能比较单一。但是不能舍弃
- Scala语言在java语法基础上进行扩展。
- scala中的导入
-- 1. import 可以声明在任意的位置
import java.sql.Date
val date = new Date()
-- 2. java中默认导入java.lang包中的类
scala中默认导入的类:
2.1 java.lang包中所有的类
2.2 scala包中的类
2.3 Predef (类似于java中静态导入)
-- 3. Scala中的import可以导包
import java.sql
val date = new sql.Date();
-- 4. 导入一个包中所有的类
a、scala中使用"下划线"代替java中的星号
import java.util.*; -- java方式
b、上面这种方式会将util包下所有的类加载到方法区吗?
不会,方法区的空间也是有限的,编译器会根据在类中使用了哪个类,会将导包的类进行转换,加载使用到的类。
import java.util._ -- scala中使用下划线代替java中星号,表示当前包下的所有类都要
-- 5. 可以在一行中导入同一个包的多个类。使用一对{}花括号,将需要导入的类写在里面
import java.util.{ArrayList, HashMap}
new ArrayList()
new HashMap()
-- 6. 使用import关键字将包中的类隐藏掉
import java.sql.{Date=>_, Array=>_, _}
-- 7. 使用import关键字将指定类起别名
方式一:
import java.util.{Date=>UtilDate}
new UtilDate()
方式二:
type UtilDate = java.util.Date
val a : UtilDate = new UtilDate()
-- 8. Scala默认import是按照包的相对路径进行导入的。
a、委派机制 - 没起作用。
b、不想使用相对路径,那么可以采用特殊的路径(root)访问,则从最顶层开始查找
println(new _root_.java.util.HashMap())
-- 9. import 可以导入对象。
a、该对象只能是使用"val"声明的
b、样式如下
val user = new user
import user._
login()
test()
7.3 类 -class
-- scala中 class 与object在编译时的区别
--1. 编译时情况:
1. object 在编译时会产生两个类文件,一个是当前类的文件, 还有一个是单例的类文件
如:Scala05_Class.class, Scala05_Class$.class
2. class 在编译时只会产生当前类的class文件
如:Scala05_Class.class
-- 2. 修饰区别
1. object:用于修饰伴随着普通的类所产生的一个单例对象,用于模仿java中的静态语法,object中的方法和属性都可以通过类名直接访问,类似于静态语法;
2. class: 用于修饰普通的类。
-- 3. 汇总:后来我们统一将“相同名称”的class,object声明的类做了区分:
1. 使用class声明的类:伴生类
2. 使用object声明的类:伴生对象
-- scala中 class 与 object 在使用上的区别
--1. 声明的方式:
1. class: 如果需要通过对象访问属性或方法,那么就使用"class"声明
2. object: 如果需要通过类名就可以直接访问属性或方法,那么就使用"object"声明
--2. 构建对象
1. class: 需要使用new的方式,由于构造方法无参的原因,小括号可以省略;
2. object: 可以直接使用类名,但是获取的是"伴生对象",不能使用new
-- 3. 调用方法
1. class: 使用class声明的类无法通过类名直接访问方法或属性,必须构建对象
2. object: 使用object声明的类可以通过类名直接访问属性或方法。
-- 多态声明
1. Scala中class可以继承(extends)父类
2. 多态 : 一个对象在不同场合下所表示的不同的状态。
-- 多态使用
1. Scala当省略类型,编译器会自动将构建对象的类型进行推断。
2. 如果需要使用多态操作,那么必须显示声明类型。
-- java中class 与 scala中class的区别
--java中
1. 只能有一个public的类;
2. public声明的类名需要和文件名称保持一致;
3. 一个文件可以有多个类;
-- scala中
1. 类名与文件名可以不一致;
2. class可以声明在很多位置;
3. 一个文件可以有多个公共的类。
- IDEA中,scala不同类型的文件对应不同的图标

- 图标1:表示这个文件中只有伴生对象和伴生类
- 图标2:表示这个文件中只有伴生类
- 图标3:表示文件内容很复杂
- 图标4:表示这个文件中只有伴生对象
- 图标5:表示这个文件中是包对象
7.4 属性
-- 属性
--说明
1. 在类中声明属性就等同于在类中声明局部变量的感觉,可以使用var,val声明;
2. 可以通过对象在外部访问;
3. "变量需要显示的初始化"。
-- 属性的初始化:
1. 如果想要像java中类的属性初始化一样,需要采用特殊的符号:"下划线";
2. 如果属性使用"val"来声明。那么初始值"不能使用下划线",需要显示的赋值;
3. 使用val声明的属性也不能改。
-- 属性 Scala类中声明的属性,不仅仅只有属性,还有其他的内容
从如下的源码和反编译可知:
1. 类中声明的属性,都编译为private权限的属性
a、"val"声明的属性:属性会被直接使用final修饰
private final int age = 10;
b、"var"声明的属性:属性只是一个普通的私用变量
private String name;
2. 使用var声明的属性:"提供属性set和get方法"
a、有类似于java中bean对象的get方法,用于返回属性的值
public String name() { return this.name }
b、有类似于java中bean对象的set方法, 用于设定属性的值
public void name_$eq(String x$1) { this.name = x$1; }
3. 使用val声明的属性:"只提供属性get方法",不可变的属性
a、只有类似于java中bean对象的get方法,用于返回属性的值
public int age() { return this.age; }
4. 在使用属性时:
a、因为属性为私有的,所以给属性赋值,其实等同于调用属性的set方法
person.name="zhangsan" --反编译--> person.name_$eq("zhangsan");
b、因为属性为私有的,所以获取属性值,其实等同于调用属性的get方法
val name = person.name --反编译--> String name = person.name();
- 源码
object Scala_Variable {
def main(args: Array[String]): Unit = {
val person = new Person
}
class Person {
val age = 10
var name: String = _
}
}
- 反编译代码
public final class Scala_Variable{
public static void main(String[] paramArrayOfString) { Scala_Variable$.MODULE$.main(paramArrayOfString);
}
public static class Person
{
private String name;
private final int age = 10;
public int age() { return this.age; }
public String name() { return this.name; }
public void name_$eq(String x$1) { this.name = x$1; }
}
}
-- scala 与java的bean的结合
--java Bean规范:
要求属性的set/get方法起名必须以set,get开头,原因是在框架中,会动态获取属性, 反射调用属性的get方法获取属性值。
--Scala编译生成属性的set,get方法并没有遵循bean规范,这样在很多框架中无法使用。
如果想要scala中的属性符合bean规范,可以采用特殊的注解:"@BeanProperty"
//源码:
@BeanProperty
var name: String = _
//反编译:发现生成满足JavaBean的set和get方法,但方法体内还是调用未加注解前类似java的set和get方法
public String getName() { return name(); }
public void setName(String x$1) { name_$eq(x$1); }
7.5 权限修饰符(重点)
- java中的四种权限符
1. private : 私有权限, "同类"
2. (default) : 包权限, "同类,同包"
3. protected : 受保护权限, "同类,同包,子类"
4. public : 公共权限, "任意的地方"
-- 但是你真的了解这四种权限吗?
1. 声明一个类,那么这个类直接或间接继承于Object类,同时继承object类的方法。
object类的方法权限有:public 、 private 、 protected 三种。
2. 什么是访问权限?
权力与限制
3. 确认是否具有访问权限,屡清楚这两个的关系:
a、方法的提供者
b、方法的调用者
4. user.clone(); --> 点不是调用关系,而是从属关系
- 案例1:
package com.atguigu;
public class java_object {
public static void main(String[] args) {
User05 user = new User05();
user.clone();
}
}
class User05 {
private String name ;
}
/*
深层解析:
1. user.clone(); 是java_object类在main方法中调用了user对象的clone()方法
2. a、方法的提供者: 因为Usero5未重写Clone()方法,所以该方法来自于父类object,java.lang.Object
b、方法的调用者: com.atguigu.java_object
3. clone()权限:protected,所以是同类、同包、子类可以调用
4. com.atguigu.java_object 与 java.lang.Object 不是子父类的关系
*/
"如何理解不是子父类的关系呢?"
1. 每个类都会将其父类所有的属性和方法加载到自己的类中;
2. 现在com.atguigu.java_object访问User05中的父类(object),那他们两个就不是父子类的关系。
3. 是java_object类在main方法中调用了user对象的clone()方法 //这是关键

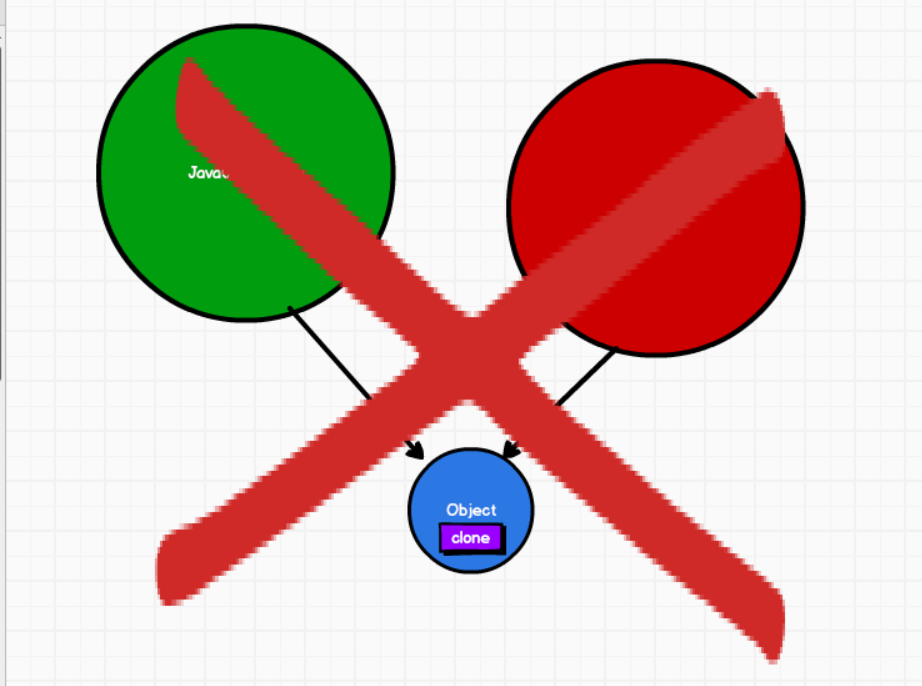
- scala的权限
Scala : 4种访问权限
private : 私有权限 "同类"
private[包名] : 包私有权限,"同类,同包"
protected : 受保护权限,"同类,子类"
(default) : 公共权限, "任意的地方", scala中没有public关键字
--1. private : 同类
a、如果属性声明为private,那么编译器生成set,get方法时,也会使用private进行修饰。
b、使用@BeanProperty注解后,属性不能声明为private
--2. private[包名] :同类,同包
a、中括号中的包名可以向上使用
b、必须在当前包的作用域范围内
--3. protected : 同类,子类
--4. (default) : 公共的
Scala中的源码文件中可以声明多个公共类
7.6 方法
-- 方法: 其实就是类中声明的函数
1. 默认方法
a、java.lang.Object的方法
user.toString
user.hashCode()
b、scala中提供的方法
user.asInstanceOf[User]
user.isInstanceOf[User]
获取对象的类型信息(方法区内存)
val clazz: Class[_ <: User] = user.getClass
val clazz: Class[User] = classOf[User]
c、Predef中的方法
2. 自定义方法
-- 方法 - apply(应用)
1. 作用:apply主要作用用于构建对象;
2. 使用场景:当类的构造方法为私有时,使用new"等同于调用对象的构造方法构建对象"的方式就行不通,那么就可以使用apply的方式;
3. 实现原理:一般用于object伴生对象中构建对象,伴生对象可以访问伴生类的"私有"属性和方法;
4. 细节:
a、Scala会自动识别apply方法,所以调用伴生对象的apply方法时,apply方法名可以省略;
b、如果不使用new来构建对象,那么等同于调用伴生对象的apply方法;
c、如果将伴生对象不使用小括号,那么等同于将伴生对象赋值给变量,而不是调用apply方法;
d、apply方法如果想要被编译器自动识别,那么不能省略小括号;
e、apply方法主要用于构建对象,但是这个构建对象不一定是当前类的对象;
f、apply方法可以重载。
-- 方法的重载
1. 概念: 多个方法名称相同,但是参数列表( 参数个数,参数类型,参数顺序 )不相同的方法之间构成重载
2. 应用
数值类型,在重载的方法中会提升精度。
引用类型,在重载的方法如果找不到对应的类型。会从类树往上查找
-- 方法的重写
1. 方法的重写一定要存在父子类。
2. 子类重写父类的方法,子类重写父类相同方法的逻辑
3. 子类重写方法与父类的方法要求:方法名一致,参数列表保持一致,异常范围"子类抛出的异常不能比父类大",访问权限"子类的访问权限不能比父类低"
如下内容,其实就是虚方法调用的原则,对于"成员方法"来说:"编译看左边,运行看右边,但是对于属性来说,运行和编译都看左边。"
4. 既然父类和子类有相同的方法,形成了方法的重写。
5. 那么在调用时,无法确定到底执行哪一个方法,那么需要遵循 动态绑定机制
6. 动态绑定机制 :程序"执行"过程,如果调用了对象的"成员""方法"时, 会将方法和对象的实际内存进行绑定,然后调用。
7. 动态绑定机制和属性无关
//方法的重载
package com.atguigu.Scala_chapter01.scala_chapter06_add
/**
* @Description
**
* @author lianzhipeng
* @create 2020-05-26 0:10:07
*/
object Scala_Method1 {
def main(args: Array[String]): Unit = {
val user = test.apply()
val b : Byte = 10
user.Method(b)
}
}
object test{
def apply(): test = new test()
}
class test {
// def Method ( b : Byte) ={
// println("bbbb")
// }
def Method ( b : Char) ={
println("CCCC")
}
def Method ( b : Int) ={
println("iiii")
}
// def Method ( b : Short) ={
// println("SSSS")
// }
}
package com.atguigu;
/**
* @author lianzhipeng
* @Description
* @create 2020-05-26 0:29:52
*/
public class Java_Method {
public static void main(String[] args) {
Student student = new Student();
//情况1:
System.out.println(student.sum());//40
//情况2:
Person student1 = new Student();
System.out.println(student1.sum());//40
int i = student1.i;
System.out.println(i); // 10
//情况3:注释子类重写的方法,再执行情况2的代码,结果为20
}
}
class Person {
int i = 10 ;
public int sum(){
return i + 10 ;
}
}
class Student extends Person {
int i = 20 ;
// public int sum(){
// return i + 20 ;
// }
}
7.7 构造方法
-- 构造方法
1. 使用new关键字创建的对象其实等同于调用类的构造方法。
2. Scala是一个完全面向对象的语言。
3. Scala还是一个完全面向函数的语言。
4. Scala中类其实也是一个函数,类名其实就是函数名,"类名后面可以增加括号",表示函数参数列表
5. 这个类名所代表的函数其实就是构造方法,构造函数
6. 构造方法执行时,会完成类的主体内容的初始化。
7. 如果在类名的后面增加private关键字,表示主构造方法私有化,无法在外部使用
-- Scala构造方法只有一个吗?
--不是。scala中提供了2种不同类型的构造方法
1. 主构造方法:在类名后加一对小括号的构造方法,可以完成类的初始化
2. 辅助构造方法:为了完成类初始化的辅助功能而提供的构造方法
1.声明方式为:"def this() = {}"
2.在使用辅助构造方法时,必须直接或间接地调用主构造方法
3.辅助构造方法也存在重载的概念
4.辅助构造方法间接调用主构造函数时,"需要保证调用的其他辅助构造函数已经声明过"。
package com.atguigu.Scala_chapter01.scala_chapter06_add
/**
* @Description
**
* @author lianzhipeng
* @create 2020-05-26 1:04:52
*/
object Scala_Construct {
def main(args: Array[String]): Unit = {
val person = new Person ("scala")
val person1 = new Person()
val person2 = new Person("scala",10)
}
}
class Person (name :String) {
def this() = {
this("scala")
}
def this (name: String,age:Int) ={
this()
}
}
-- 构造方法之参数
1. 给构造方法增加参数的目的是什么?
从外部将数据传递到对象的属性中
// java : public User( String name ) { this.username = name }
2. Scala中一般构造方法的参数用于属性的初始化,所以为了减少数据的冗余
可以使用关键字var,val将构造参数当成类的属性来用。
"var可读可写,val可读不可写"
3. 辅助构造方法的参数不能作为属性
package com.atguigu.Scala_chapter01.scala_chapter06_add
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-26 1:04:52
*/
object Scala_Construct {
def main(args: Array[String]): Unit = {
// val person = new Person("scala")
// println(person.age)
// val person1 = new Person()
val person2 = new emp("scala", 10)
println(person2.age) //10
val emp = new emp()
println(emp.name) //java
println(emp.age) //20
val emp1 = new emp("hadoop")
println(emp1.name) //hadoop
}
}
class emp(val name: String, var age: Int) {
def this() = {
this("java", 20)
}
def this(name: String) = {
this(name, 30)
}
}
-- 如果父类有构造方法,怎么办?
构建子类对象时,应该首先构建父类对象,如果父类的构造方法有参
那么子类在构建父类对象也应该传递参数。
-- Scala中如何向父类的构造方法中传参?
在父类名称的后面加括号就可以传参了
package com.atguigu.Scala_chapter01.scala_chapter06_add
/**
* @Description
* *
* @author lianzhipeng
* @create 2020-05-26 1:04:52
*/
object Scala_Construct {
def main(args: Array[String]): Unit = {
val worker = new Worker("java",30)
println(worker.age)
println(worker.str)
}
}
class Creature ( var name : String ,val age : Int){
}
//方式1
//class Worker extends Creature ("java",20){
//
//}
//方式2
class Worker (var str :String , var num :Int) extends Creature (str , num){
}
7.8 创建对象的方法
-- 方式1: new
-- 方式2: apply
-- 方式3: classof
-- 方式4: clone 【这种方式的类需要实现cloneable接口】
-- 方式5: 反序列化
- 代码实现
package com.atguigu.Scala_chapter01.scala_review2
/**
* @Description
**
* @author lianzhipeng
* @create 2020-05-26 18:13:10
*/
object Scala1_CreateObject extends Cloneable{
def main(args: Array[String]): Unit = {
//创建对象的方法
//方式1 :new
val user = new User1
println(user)
//方式2 : apply
val user1 = User1()
println(user1)
//方式3 : classof
val uclass: Class[User1] = classOf[User1]
val user2: User1 = uclass.newInstance()
println(user2)
//方式4 :clone
val value = clone()
println(value)
//方式5 : 反序列化
}
}
class User1{
val age = 10
}
object User1 {
def apply(): User1 = new User1()
}
7.9 创建单例模式
总结:声明在object中的属性和方法类似java中的静态方法和静态属性,类加载的时候就会被加载。
步骤:
-- java中懒汉式
第一步:私有化构造器
第二步:创建一个私有化的静态属性,并new对象
第三步:创建一个公共的静态方法,返回静态属性
-- scala中
object类中{}的内容只会在初始化的时候加载一次,所以将构建的对象语句放在{}中,并声明为val.
object Scala2_SingObject {
def main(args: Array[String]): Unit = {
//调用获取对象的方法,获取两个对象
val singObject: User2 = User2.singObject
val singObject1: User2 = User2.singObject
//判断这两个对象的地址值是否相等
println(singObject eq singObject1) //true
}
}
class User2 {
}
object User2{
//创建一个单例对象,并设置为不可变的
val user = new User2
//创建一个方法,供外部进行调用,返回一个单例对象
def singObject ={
user
}
}
7.10 抽象类
-- 抽象类、抽象方法、抽象属性
--1. 抽象的理解:抽象的对象一般理解为不完整的对象
抽象类 : 不完整的类
抽象方法 :不完整的方法
只有声明而没有实现的方法
无需使用abstract关键字修饰
抽象属性:不完整的属性,只声明而没有初始化的属性
--2. 抽象类、抽象方法、抽象属性之间的关系
抽象类可以没有抽象方法和抽象属性,有抽象方法或抽象属性的类一定是抽象类
--3. 抽象类的说明
a、抽象类无法直接构造对象,可通过子类构造对象
b、抽象类使用"abstract"修饰。
c、抽象类中可以有完整的方法和完整的属性。
--4. 抽象类与其子类
a、子类只有实现抽象类中的所有抽象方法和抽象属性,才能实例化,否则还是抽象类。
--5. 实现抽象方式的说明
a、如果子类重写父类的"完整方法",需要显示增加override关键字来修饰
b、如果子类重写父类的"抽象方法",需要直接补充完整即可, 或采用override关键字修饰
--6. 实现抽象属性的说明
a、子类重写父类的"完整属性",那么需要增加override关键字修饰,"被重写的属性必须是val声明的"
b、子类重写父类的"抽象属性",那么需要将属性补充完整即可
关于抽象属性的说明:
a、抽象属性在编译时,不会产生类的属性,而是产生属性的set,get方法,并且方法为抽象的。
b、重写抽象属性,那么等同于普通属性的声明:属性,set,get方法。
"问题:为什么子类重写父类完整的属性只能是val,不能是var"
-- 回答:如果采用var声明的属性可以被重写,会产生歧义
解析: 1. Scala中类的属性在编译时,会自动生成私有属性和对应的set,get方法。
2. 详情见下图分析

7.11 特质
7.11.1java中接口和抽象类说明
-- java中:
-- 抽象类:将子类共通的内容给抽取出来,放置在父类中
a、父类不能直接构建对象,必须通过子类来创建
b、抽象类一般在"父子继承"和"方法重写"的时候用的比较多。
-- 接口 :和类不一样,不是一个体系,所以可以多继承
a、将接口理解为规范和规则。如果一个类符合指定的规则,就应该实现接口
7.11.2 特质基本介绍
1. Scala中没有接口的概念,也就没有interface关键字。
2. Scala可以将"多个类中相同的特征"从类里剥离出来,形成特殊的语法结构,称之为“特质”
3. 如果一个类,符合这个特征,那么就可以将这个特征(特质)混入到类中
7.11.3 特质的使用方式
1. 使用"trait"声明;
2. 特质中可以声明抽象方法、抽象属性、以及完整的方法和属性;
3. 特质既可以看做java中的接口,也可以看做java中的抽象类;
4. 如果一个类符合特质,那么可以将特质“混入”到类中, 采用extends关键字,如果这个类将抽象部分全部补全,那么可以实例化,否则属于抽象类。
-- 总结:
1. "trait"关键字 可以声明特质
2. 将trait理解为interface :特质之间可以多继承
3. 将trait理解为抽象类 : 特质也可以继承其他类,也可以被其他类继承,并采用with混入其他的特质
4. 子类继承特质,如果重写特质中的具体方法,需要使用override
5. java中所有的接口在Scala中都当成特质来使用
// 声明特质
trait Operate {
// 抽象方法 - 不完整方法
def oper():Unit
}
class MySQL extends Operate {
def oper():Unit = {
println("执行mysql数据操作...")
}
}
特质的应用:动态扩展功能,遵循 OCP 开发原则
1. 特质中不仅仅有抽象方法,还可以有具体方法
2. 如果对象声明后想要扩展功能,怎么办?
3. 特质 (混入with)
object Scala4_trait {
def main(args: Array[String]): Unit = {
//构建对象,并使用with “混入”特质2,则拥有特质2所有的属性和方法,如果特质2中也还有抽象方法,那么也需要进行实现
val user = new User4() with MySQL
user.select
}
}
//特质1:
trait Operator {
//抽象方法
def test () : Unit
}
//特质2:
trait MySQL {
//完整方法
def select = {
println("执行mysql的数据库操作")
}
}
//类“混入”特质1,并实现了特质1中的抽象方法
class User4 extends Operator {
override def test(): Unit = {
println("zzzz")
}
}
7.11.4 特质的初始化顺序
object Scala5_trait {
def main(args: Array[String]): Unit = {
new SubUser35()
// aaaaa
// bbbbb
// ddddd ==> parent class
// ccccc ==> trait
// eeeee ==> child class
}
}
trait Parent35 {
println("aaaaa")
}
trait Test35 extends Parent35 {
println("bbbbb")
}
trait SubTest35 extends Parent35 {
println("ccccc")
}
class User35 extends Test35 {
println("ddddd")
}
class SubUser35 extends User35 with SubTest35{
println("eeeee")
}

7.11.5 特质功能执行的顺序
1. 类混入多个特质的时候,功能的执行顺序"从右向左"
2. 特质中的super其实有特殊的含义,表示的"不是父特质,而是上级特质"。
3. 如果想要改变执行顺序,需要指定特质的类型
object Scala5_trait {
def main(args: Array[String]): Unit = {
new MySQL37().operData() //向日志中向数据库中操作数据
}
}
trait Operate37 {
def operData(): Unit = {
println("操作数据")
}
}
trait DB37 extends Operate37 {
override def operData(): Unit = {
print("向数据库中")
super.operData()
}
}
trait Log37 extends Operate37 {
override def operData(): Unit = {
print("向日志中")
//super[Operate37].operData()
super.operData()
}
}
class MySQL37 extends DB37 with Log37 {
}
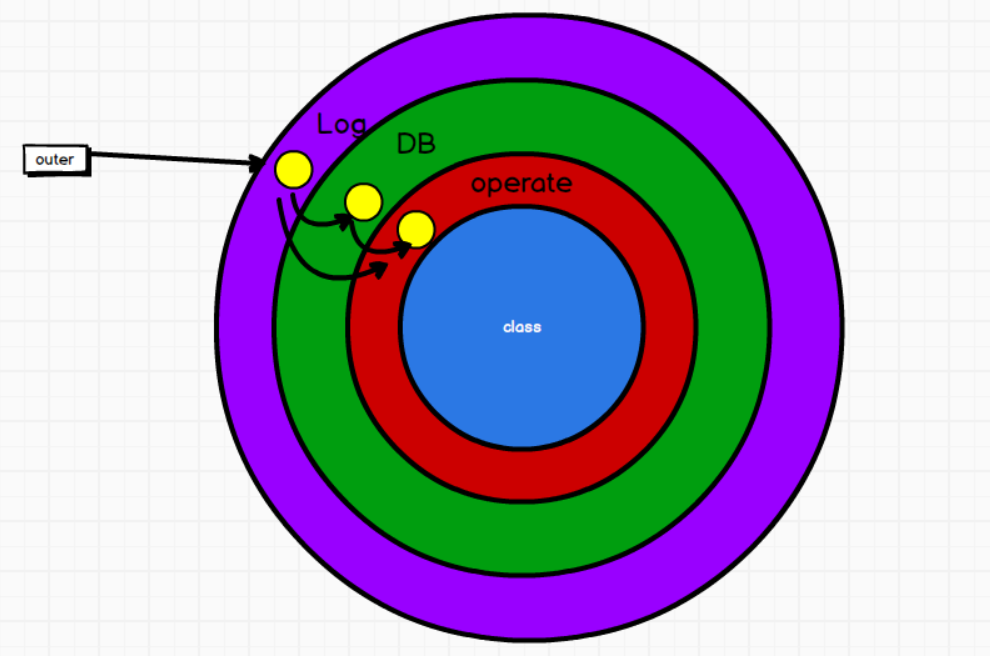
7.12 拓展
- 枚举类
object Scala7_Trait {
def main(args: Array[String]): Unit = {
println(User7.RED) //red
println(User7.YELLOW) //yellow
println(User7.BLUE) //blue
println(User7.BLUE.id) //3
}
}
object User7 extends Enumeration {
val RED = Value(1, "red")
val YELLOW = Value(2, "yellow")
val BLUE = Value(3, "blue")
}
- 应用类
//在没有main方法中,通过继承App特质,使程序也可以执行
//在APP特质中有main方法,因为是继承了app特质,所以当前类则具有了main主方法
object Scala6_app extends App {
println("xxxx")
println("yyyy")
}
")
}
class SubUser35 extends User35 with SubTest35{
println(“eeeee”)
}
[外链图片转存中...(img-rNxlBsJ4-1600441971975)]
#### 7.11.5 特质功能执行的顺序
```sql
1. 类混入多个特质的时候,功能的执行顺序"从右向左"
2. 特质中的super其实有特殊的含义,表示的"不是父特质,而是上级特质"。
3. 如果想要改变执行顺序,需要指定特质的类型
object Scala5_trait {
def main(args: Array[String]): Unit = {
new MySQL37().operData() //向日志中向数据库中操作数据
}
}
trait Operate37 {
def operData(): Unit = {
println("操作数据")
}
}
trait DB37 extends Operate37 {
override def operData(): Unit = {
print("向数据库中")
super.operData()
}
}
trait Log37 extends Operate37 {
override def operData(): Unit = {
print("向日志中")
//super[Operate37].operData()
super.operData()
}
}
class MySQL37 extends DB37 with Log37 {
}
7.12 拓展
- 枚举类
object Scala7_Trait {
def main(args: Array[String]): Unit = {
println(User7.RED) //red
println(User7.YELLOW) //yellow
println(User7.BLUE) //blue
println(User7.BLUE.id) //3
}
}
object User7 extends Enumeration {
val RED = Value(1, "red")
val YELLOW = Value(2, "yellow")
val BLUE = Value(3, "blue")
}
- 应用类
//在没有main方法中,通过继承App特质,使程序也可以执行
//在APP特质中有main方法,因为是继承了app特质,所以当前类则具有了main主方法
object Scala6_app extends App {
println("xxxx")
println("yyyy")
}















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









