







基本概念
参考:https://zhuanlan.zhihu.com/p/379422670
Program slicing技术:用于提取与某变量强相关的代码部分。
例如,原始程序代码为:

它所要完成的功能很简单:首先读取一个数值n,然后分别计算从1到n的和(sum),以及从1到n的乘积(prod),最后再针对这两个数值执行写操作。
如果我们只关心最后的write和prod,应该如何执行切片操作呢?
此时就可以指定程序中的位置10和变量prod来作为切片标准<10, {prod}>,并以此执行程序切片来得到如下结果:

不难看出,经过程序切片后只保留了与prod强相关的代码部分,而其他无关代码行都被移除了。
软件开发人员在调试程序时经常会遇见这样的情形:他们在发现程序某处的某个变量的值发生了错误之后,需要去寻找所有可能引发了这个错误的程序语句——这也是程序切片的最初的应用场景。
分类
不需要运行程序就可以完成的切片技术称为静态切片,而需要在程序运行时进行的切片技术称为动态切片。例如,我们可以考虑在程序的编译阶段执行静态切片—编译过程中既可以看到所有程序代码,同时还能够借助编译器得到代码间的某些依赖分析,因而是执行静态切片的一个好时机。
从实现的角度来看,程序切片则可以细分为如下几种经典类型:
静态切片技术(Static Slicing);
动态切片技术(Dynamic Slicing);
分解切片技术(Decomposition Slicing);
条件切片技术(Conditioned Slicing)。
angr实现的Backward Program Slice
参考:https://blog.csdn.net/doudoudouzoule/article/details/80263141
基于CFG、CDG、DDG生成某个statement对应的program slice。
angr给出的官方参考:
>>> import angr
# Load the project
>>> b = angr.Project("examples/fauxware/fauxware", load_options={"auto_load_libs": Fal
se})
# Generate a CFG first. In order to generate data dependence graph afterwards,
# you’ll have to keep all input states by specifying keep_stat=True. Feel free
# to provide more parameters (for example, context_sensitivity_level)for CFG
# recovery based on your needs.
>>> cfg = b.analyses.CFGAccurate(context_sensitivity_level=2, keep_state=True)
# Generate the control dependence graph
>>> cdg = b.analyses.CDG(cfg)
# Build the data dependence graph. It might take a while. Be patient!
>>> ddg = b.analyses.DDG(cfg)
# See where we wanna go... let’s go to the exit() call, which is modeled as a
# SimProcedure.
>>> target_func = cfg.kb.functions.function(name="exit")
# We need the CFGNode instance
>>> target_node = cfg.get_any_node(target_func.addr)
# Let’s get a BackwardSlice out of them!
# `targets` is a list of objects, where each one is either a CodeLocation
# object, or a tuple of CFGNode instance and a statement ID. Setting statement
# ID to -1 means the very beginning of that CFGNode. A SimProcedure does not
# have any statement, so you should always specify -1 for it.
>>> bs = b.analyses.BackwardSlice(cfg, cdg=cdg, ddg=ddg, targets=[ (target_node, -1) ]
) #
Here is our awesome program slice!
>>> print bs
- 先加载一个二进制文件,然后执行CFGAccurate算法,获取一个CFG;
- 执行CDG获取程序的控制依赖图CDG;
- 执行DDG获取程序的数据依赖图DDG;
- 获取目标点targets,即,反向切片的起始点,最后生成的切片的结束点;
- 传入CFG,CDG,DDG以及targets,执行反向切片。
其中CDG与DDG是可选的,也就是可以不提供控制依赖图和数据依赖图。因为某些程序的数据依赖图DDG是生成不出来的。
后向切片的实现:后向遍历CFG,并根据最初提供的依赖图(CDG和DDG)标记所有受污染的语句。
当我们到达入口点时,或者当没有未解决的依赖关系时,遍历就会终止。
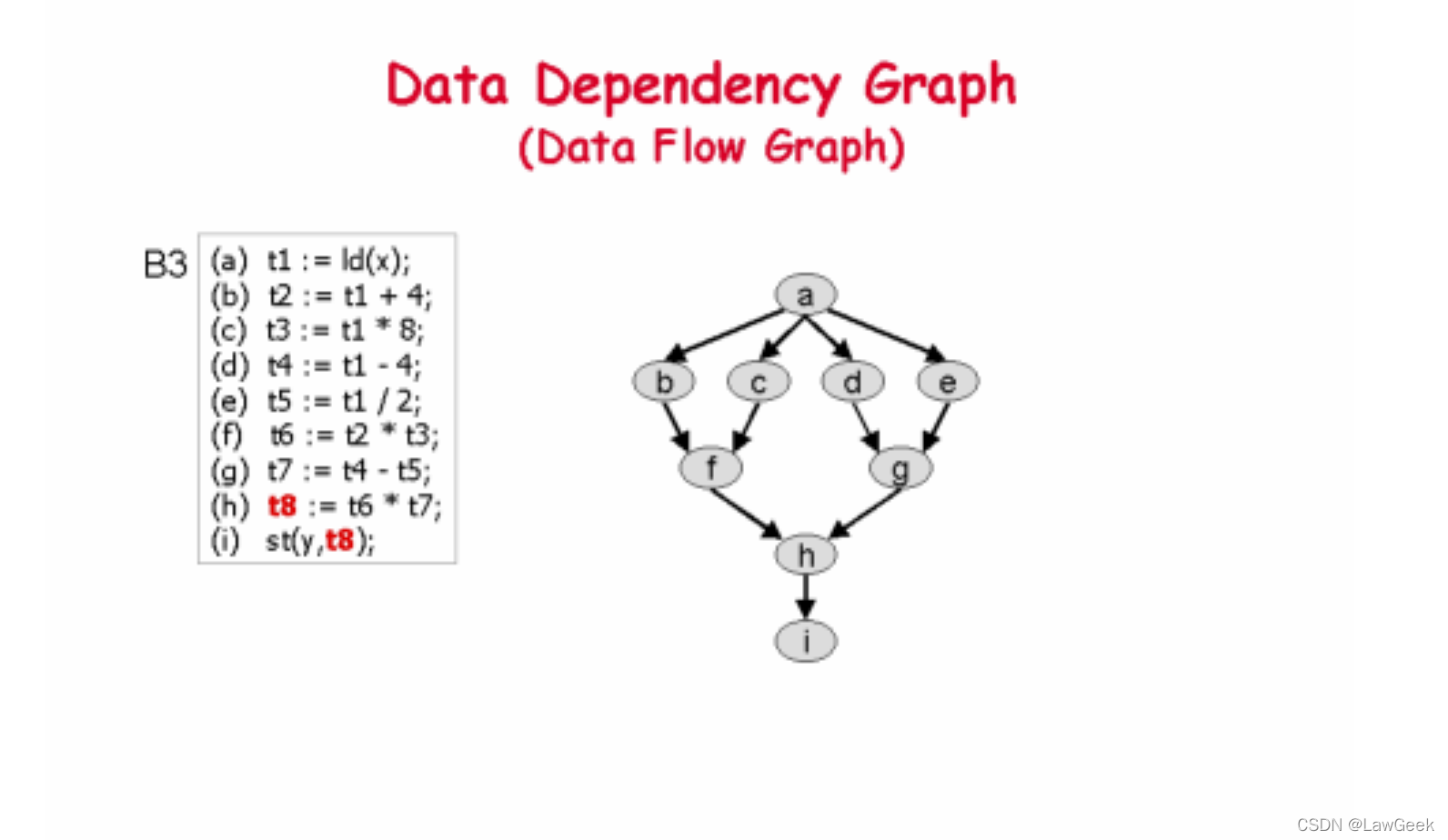
这里的DDG(data dependence graph)就是Data Flow Graph?
angr介绍
https://zhuanlan.zhihu.com/p/25192237
DDG相关
DDG的概念
参考:https://webdocs.cs.ualberta.ca/~amaral/courses/429/webslides/Topic8-ILP-dynamic/sld004.htm
参考:http://xuebao.jlu.edu.cn/gxb/article/2017/1671-5497-47-6-1894.html
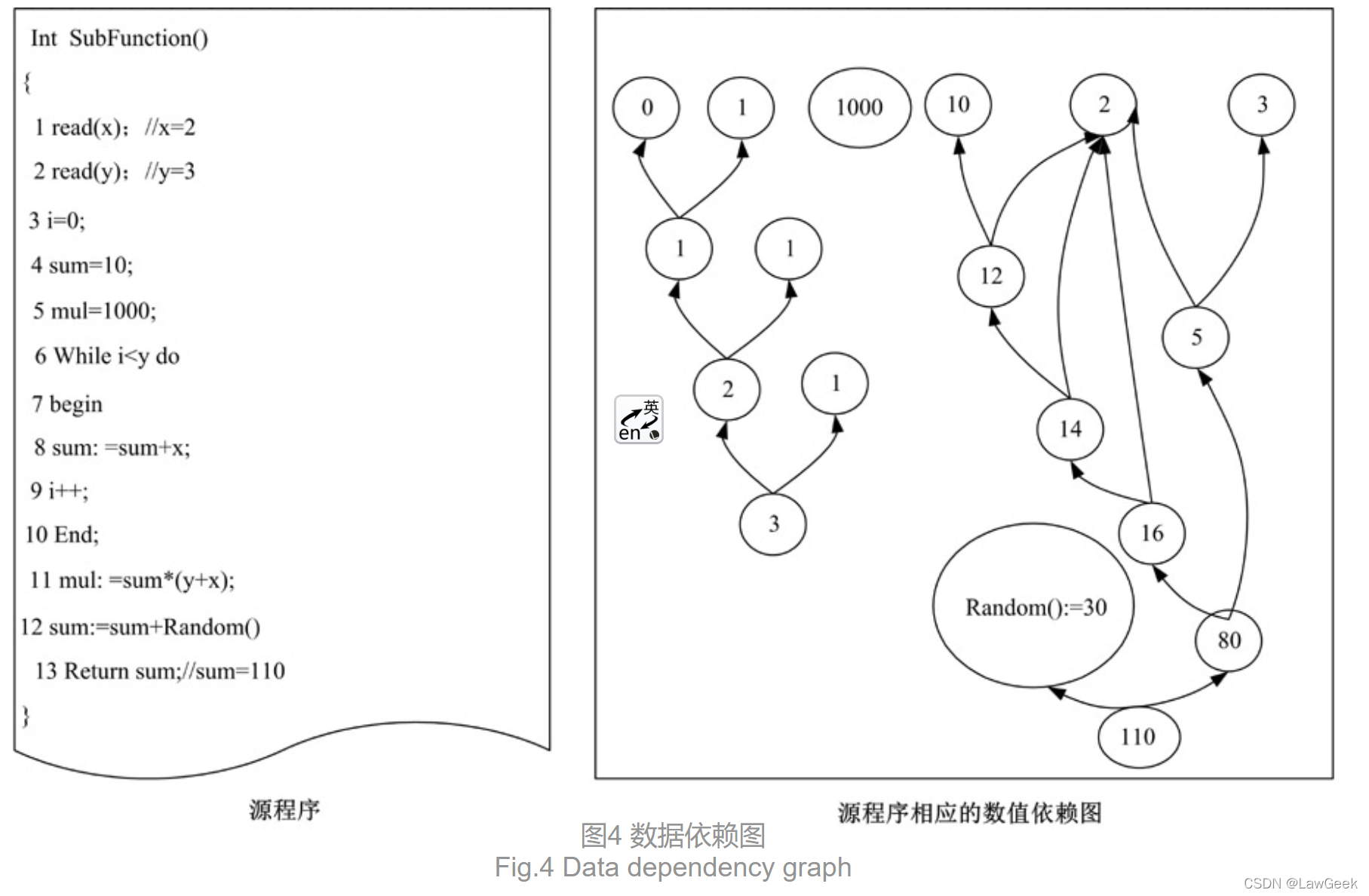
图4给定的源程序, 运行程序并输入x=2, y=3, 跟踪程序运行过程, 记录数据变化, 得到数据流DS={2, 3, 0, 10, 1000, 12, 1, 1, 14, 1, 2, 16, 1, 3, 5, 80, 30, 110}, 即为V, 其中因为数据的产生过程为12=10+2, 1=1+0, 14=12+2, 2=1+1, 16=14+2, 3=2+1, 80=16× 5, 30=Random(), 110=30+80, 所以其中的数据依赖关系依次为12=Dep(sum=sum+x, 10), 12=Dep(sum=sum+x, 2), 1=Dep(i++, 0), 1=Dep(i++, 1), …, 110=Dep(sum=sum+Random(), 80), 110=Dep(sum=sum+Random(), 30)。将得到的数据依赖关系形成数据对E={(12, 10), (12, 2), (1, 0), (1, 1), …, (110, 30), (110, 80)}即为边集合, 使用E和V构成图形DDG。
由数据定义的独立性表明, 数据不可能被重复定义, 则说明数据依赖图为有向无环图。
DDG的生成
DDG的生成:基于CFG生成或者基于VSA(值集分析)生成















 8165
8165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









