







目录
167. 两数之和 II - 输入有序数组
1. 题目要求

2. 解决过程
测试用例
[1,2,3,4]
7
[2,7,11,15]
9
[3,24,50,79,88,150,345]
200
[12,13,23,28,43,44,59,60,61,68,70,86,88,92,124,125,136,168,173,173,180,199,212,221,227,230,277,282,306,314,316,321,325,328,336,337,363,365,368,370,370,371,375,384,387,394,400,404,414,422,422,427,430,435,457,493,506,527,531,538,541,546,568,583,585,587,650,652,677,691,730,737,740,751,755,764,778,783,785,789,794,803,809,815,847,858,863,863,874,887,896,916,920,926,927,930,933,957,981,997]
542个人实现
法一:暴力迭代。空间复杂度 O(1),时间复杂度 O(n^2)。
2020/07/20 - 超出时间限制 ...
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
slow = 0 # 慢指针
while slow < len(numbers)-1:
fast = slow + 1
while fast < len(numbers):
summ = numbers[slow] + numbers[fast] # 求和
if summ == target:
return [slow+1, fast+1] # 找到和为 target 的 index
if numbers[fast] < target:
fast += 1
else:
break # 提前退出本轮遍历
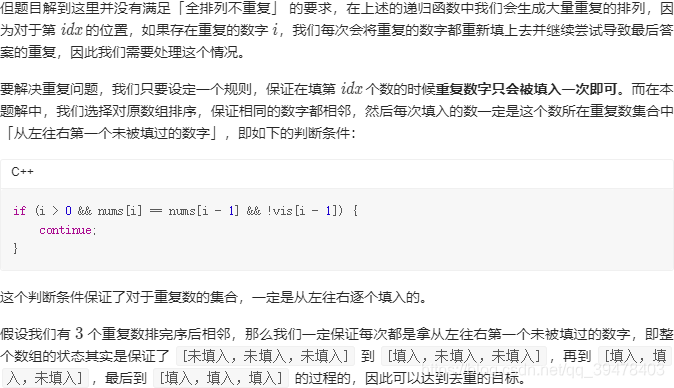
slow += 1法二:双指针。快慢指针的动态规划处理,即根据两数之和不断调整指针位置,直至找到目标和对应的索引。空间复杂度 O(1),时间复杂度 O(n) ?
与官方实现法二对比可知:一方面,个人实现法二相当于快指针 fast 先从左到右,再逐渐往左;而官方实现法二的快指针 fast 直接从最右端开始。另一方面,对严谨思路的匮乏,使得实现方式缺乏理论的有效支撑,以至于无法找到优化点。
2020/07/20 - 55.23% (48ms) - 总算写出来了,但还存在不足
## 思想同官方实现法二, 但实现存在一些冗余
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
slow = 0 # 慢指针
fast = 1 # 快指针
limit = len(numbers)-1 # 快指针上限
while slow < fast < len(numbers): # 保持基本顺序
summ = numbers[slow] + numbers[fast] # 求和
if summ == target:
return [slow+1, fast+1] # 找到和为 target 的 index
if summ < target:
if (fast < limit) and (numbers[fast+1] < target):
fast += 1 # fast 不到上限 limit 且下一位数小于 target, 移动快指针
else:
slow += 1 # fast 到达上限 limit 时, 移动 slow
if summ > target:
limit -= 1 # limit 降低
fast -= 1 # fast 回退官方实现与说明


class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
n = len(numbers)
for i in range(n):
low, high = i + 1, n - 1 # 低位指针, 高位指针
while low <= high:
mid = (low + high) // 2
if numbers[mid] == target - numbers[i]:
return [i + 1, mid + 1]
elif numbers[mid] > target - numbers[i]:
high = mid - 1
else:
low = mid + 1
return [-1, -1]2020/07/20 - 11.53% (92ms) - 很低效


# 注意官方解释和说明更严谨, 值得学习!
class Solution:
def twoSum(self, numbers: List[int], target: int) -> List[int]:
low, high = 0, len(numbers) - 1 # 慢指针, 快指针, 将从两端向中间缩小范围
while low < high:
total = numbers[low] + numbers[high]
if total == target:
return [low + 1, high + 1]
elif total < target:
low += 1
else:
high -= 1
return [-1, -1]2020/07/20 - 96.54% (36ms) - 最佳

其他实现与说明

// C++ implementation
vector<int> twoSum(vector<int>& numbers, int target) {
int i = 0;
int j = numbers.size() - 1;
while (i < j) {
int sum = numbers[i] + numbers[j];
if (sum < target) {
i++;
} else if (sum > target) {
j--;
} else {
return vector<int>{i+1, j+1};
}
}
return vector<int>{-1, -1};
}![]()



![]()


![]()

其他评论
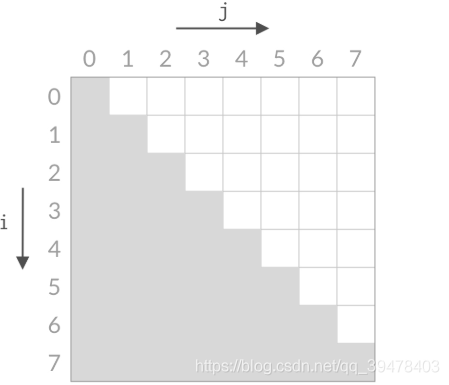
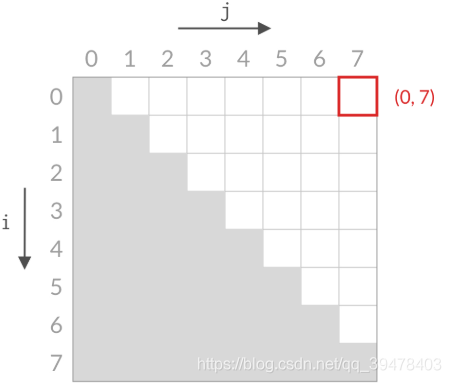
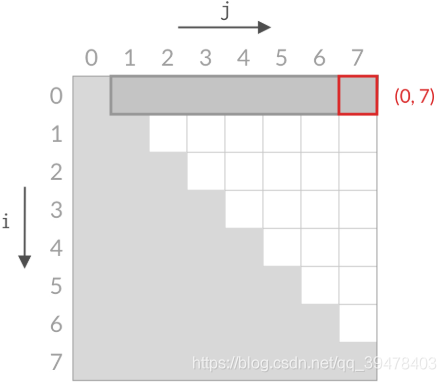
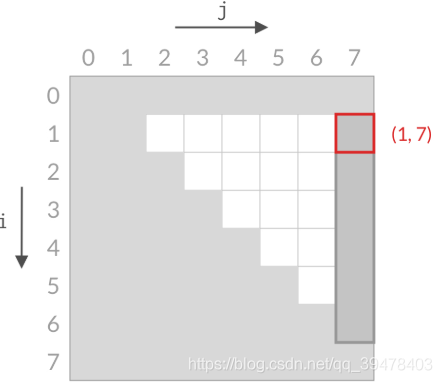
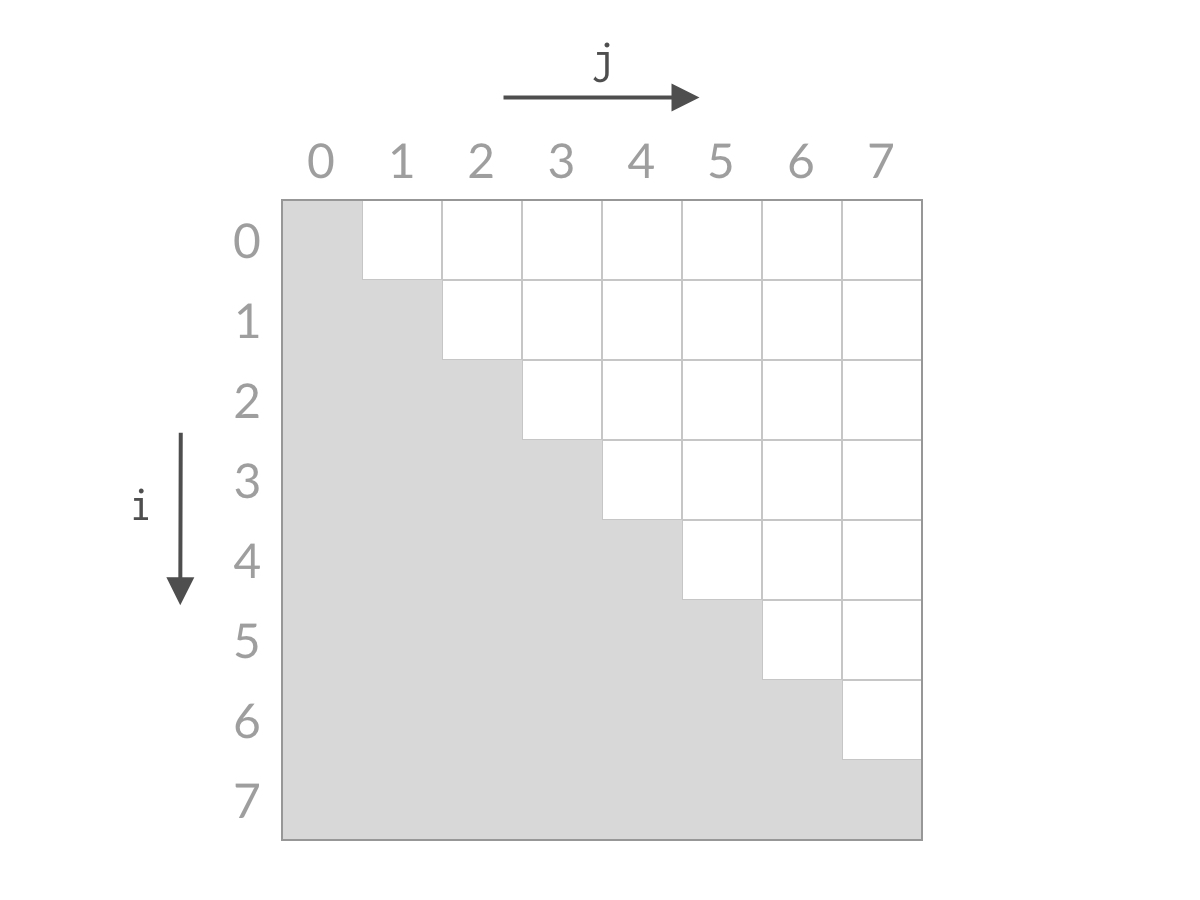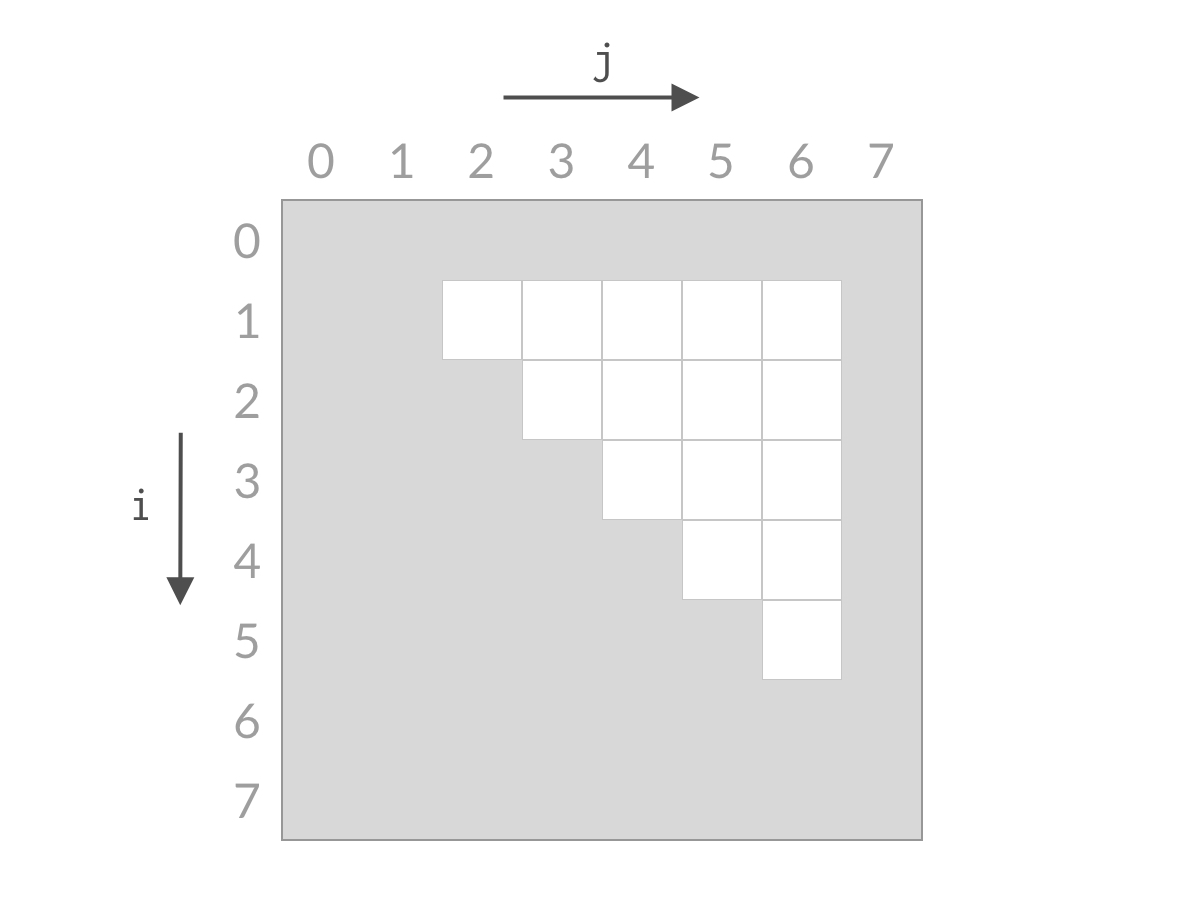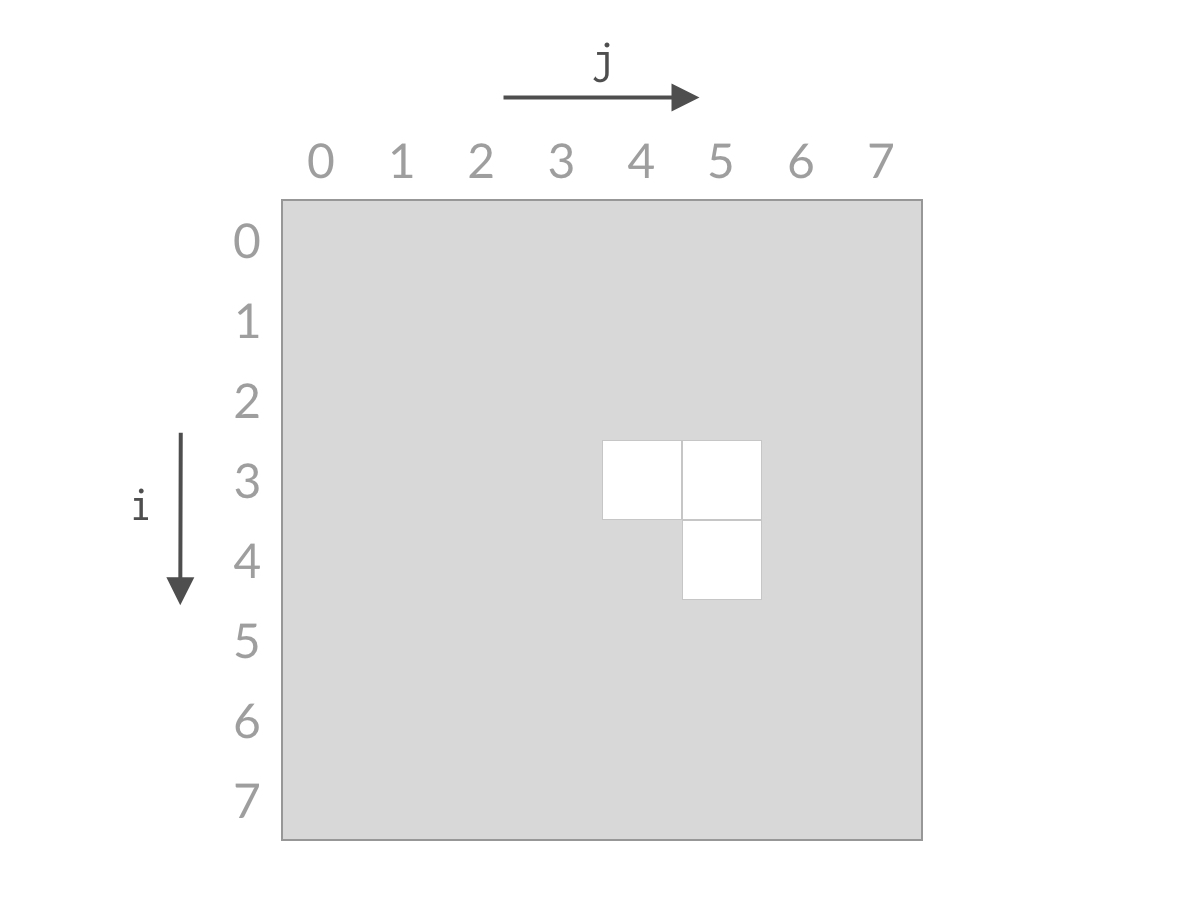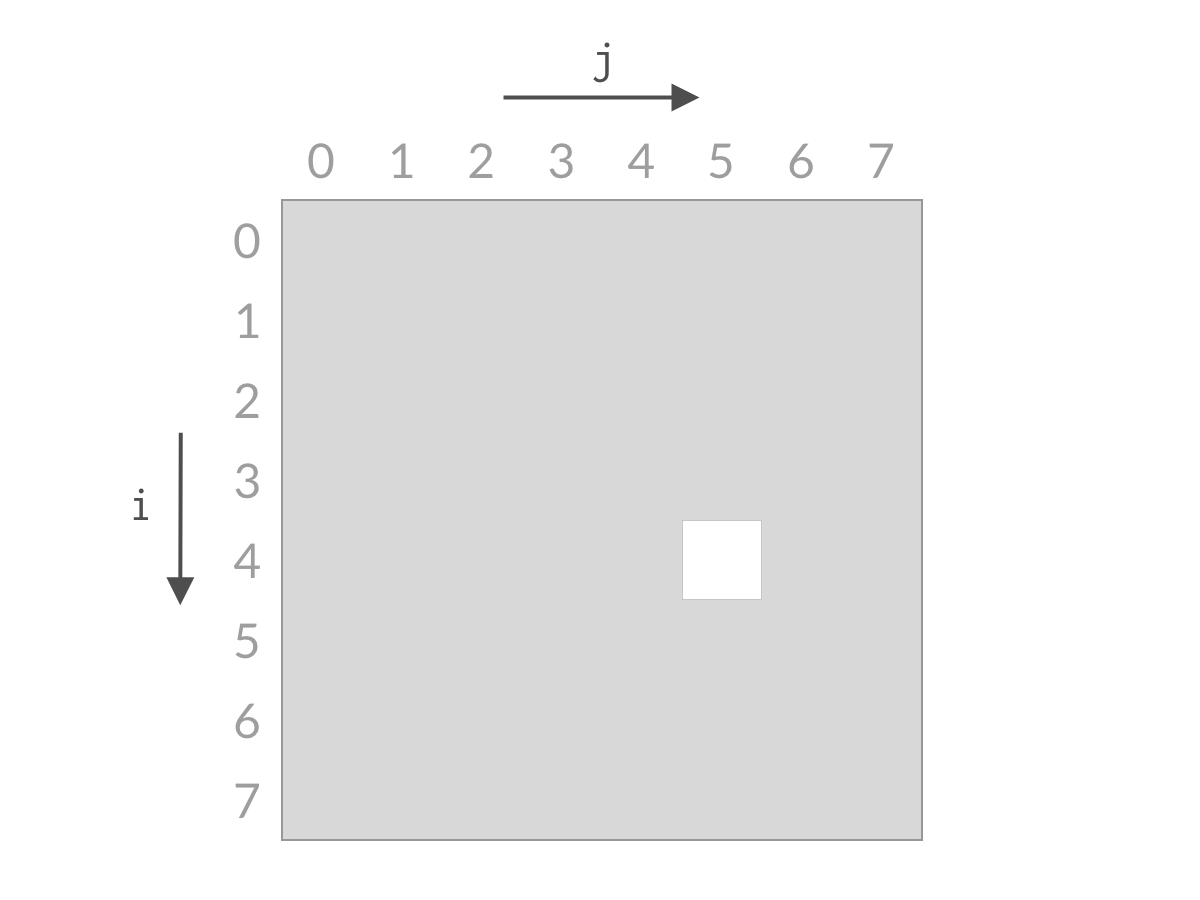
甲:双指针本质:相等于杨氏矩阵,而杨氏矩阵又相等于有序集合的笛卡尔积。右上角的数字就等于原序列的第一个值加上最后一个值,而我们向下走一步就意味着 left 向后移动一位,这刚好就是当前位置小于 target 的情况。同理,向左走一步就意味着 right 向前移动一步,也就是当前位置大于 target 的情况。
乙:双指针的搜索方法确实和杨氏矩阵一样,不过这道题的搜索空间是个倒三角形状,左下角不存在元素,这就和杨氏矩阵不太一样了。
参考文献
https://leetcode-cn.com/problems/two-sum-ii-input-array-is-sorted/
392. 判断子序列
1. 题目要求

2. 解决过程
个人实现
法一:双指针 + 暴力迭代。空间复杂度 O(1),时间复杂度 O(m+n)。
2020/07/27 - 83.32% (40ms) - 很朴素和有效的方法
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
left = right = 0 # 双指针
while (left < len(s)) and (right < len(t)):
if s[left] == t[right]:
left += 1
right += 1
return True if left == len(s) else False官方实现与说明

# 完全同个人实现
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
n, m = len(s), len(t)
i = j = 0
while i < n and j < m:
if s[i] == t[j]:
i += 1
j += 1
return i == n

![]()
class Solution:
def isSubsequence(self, s: str, t: str) -> bool:
n, m = len(s), len(t)
f = [[0] * 26 for _ in range(m)]
f.append([m] * 26)
for i in range(m - 1, -1, -1):
for j in range(26):
f[i][j] = i if ord(t[i]) == j + ord('a') else f[i + 1][j]
add = 0
for i in range(n):
if f[add][ord(s[i]) - ord('a')] == m:
return False
add = f[add][ord(s[i]) - ord('a')] + 1
return True2020/07/27 - 17.02% (152ms) - 太慢了

参考文献
https://leetcode-cn.com/problems/is-subsequence/
https://leetcode-cn.com/problems/is-subsequence/solution/pan-duan-zi-xu-lie-by-leetcode-solution/
415. 字符串相加
1. 题目要求

2. 解决过程
禁用方式
2020/08/03 - 99.41% (36ms) - 面试官已将你提出群聊 ...
class Solution:
def addStrings(self, num1: str, num2: str) -> str:
return str(eval(num1) + eval(num2))个人实现
法一:暴力法。双指针暴力迭代计算,然后强制类型转换。空间复杂度 O(1),时间复杂度 O(n)。
2020/08/03 - 5.01% (576ms)
class Solution:
def addStrings(self, num1: str, num2: str) -> str:
length = max(len(num1), len(num2)) # 长度
summ = 0 # 和
for i in range(length):
left = int(num1[-i-1]) if i < len(num1) else 0
right = int(num2[-i-1]) if i < len(num2) else 0
carry, unit = divmod(left+right, 10) # 进位, 本位
summ = summ + carry*(10**(i+1)) + unit*(10**i) # 累积求和
return str(summ)官方实现与说明

// C++ implementation
class Solution {
public:
string addStrings(string num1, string num2) {
int i = num1.length() - 1, j = num2.length() - 1, add = 0;
string ans = "";
while (i >= 0 || j >= 0 || add != 0) {
int x = i >= 0 ? num1[i] - '0' : 0;
int y = j >= 0 ? num2[j] - '0' : 0;
int result = x + y + add;
ans.push_back('0' + result % 10);
add = result / 10;
i -= 1;
j -= 1;
}
// 计算完以后的答案需要翻转过来
reverse(ans.begin(), ans.end());
return ans;
}
};
其他实现
法一:暴力法改。

class Solution:
def addStrings(self, num1: str, num2: str) -> str:
res = "" # 结果字符串
i, j, carry = len(num1) - 1, len(num2) - 1, 0
while i >= 0 or j >= 0:
n1 = int(num1[i]) if i >= 0 else 0
n2 = int(num2[j]) if j >= 0 else 0
tmp = n1 + n2 + carry # 求和
carry = tmp // 10 # 进位留到下次计算
res = str(tmp % 10) + res # 本位添加到结果字符串中
i, j = i - 1, j - 1 # 索引同步移动
return "1" + res if carry else res2020/08/03 - 99.90% (28ms) - 一步步竖式加法计算并生成字符加入 res 要比暴力计算要高效很多
参考文献
https://leetcode-cn.com/problems/add-strings/
https://leetcode-cn.com/problems/add-strings/solution/zi-fu-chuan-xiang-jia-by-leetcode-solution/
https://leetcode-cn.com/problems/add-strings/solution/add-strings-shuang-zhi-zhen-fa-by-jyd/
647. 回文子串
1. 题目要求
![]()

![]()
2. 解决过程
个人实现
法一:朴素法/暴力枚举法。遍历所有字符串及其子串进行一一测验和计数。空间复杂度 O(1),时间复杂度 O(n³)。
2020/08/19 - 7.72% (684ms) - 最低效是必然的,显然需要特定的算法
class Solution:
def countSubstrings(self, s: str) -> int:
kinds = 0 # 回文串总数
for start in range(len(s)): # 测验串切片起点
for end in range(start+1, len(s)+1): # 测验串切片终点
if s[start:end] == s[start:end][::-1]: # 测验
kinds += 1 # 总数 +1
return kinds法一改:朴素法/暴力枚举法。由于每个单字符必为回文子串,故可以直接将计数器 kind 初始化为字符串 s 的长度,而无需在后续的循环中考虑单字符的情况。空间复杂度 O(1),时间复杂度 O(n³)。
2020/08/19 - 8.27% (676ms) - 对朴素法的小小小优化
class Solution:
def countSubstrings(self, s: str) -> int:
kinds = len(s) # 回文串总数初始化 - 每个单字符必符合要求
for start in range(len(s)-1): # 测验串切片起点, 在倒数第2个即可停下
for end in range(start+2, len(s)+1): # 测验串切片终点, 无需再测试单字符
if s[start:end] == s[start:end][::-1]: # 测验
kinds += 1 # 总数 +1
return kinds官方实现与说明


class Solution:
def countSubstrings(self, s: str) -> int:
n = len(s)
ans = 0
for i in range(2*n-1):
l = i // 2 # 回文中心左起始位置
r = l + i % 2 # 回文中心右起始位置 (回文长度奇偶性 i 对右起点有影响)
while (l >= 0) and (r < n) and (s[l] == s[r]): # 单个字符相同
l -= 1 # 左移
r += 1 # 右移
ans += 1 # 种类计数 +1
return ans2020/08/19 - 89.89% (124ms)




// C++ implementation
// Manacher 算法 又叫 “马拉车” 算法
class Solution {
public:
int countSubstrings(string s) {
int n = s.size();
string t = "$#";
for (const char &c: s) {
t += c;
t += '#';
}
n = t.size();
t += '!';
auto f = vector <int> (n);
int iMax = 0, rMax = 0, ans = 0;
for (int i = 1; i < n; ++i) {
// 初始化 f[i]
f[i] = (i <= rMax) ? min(rMax - i + 1, f[2 * iMax - i]) : 1;
// 中心拓展
while (t[i + f[i]] == t[i - f[i]]) ++f[i];
// 动态维护 iMax 和 rMax
if (i + f[i] - 1 > rMax) {
iMax = i;
rMax = i + f[i] - 1;
}
// 统计答案, 当前贡献为 (f[i] - 1) / 2 上取整
ans += (f[i] / 2);
}
return ans;
}
};# Python implementation
class Solution:
def countSubstrings(self, s: str) -> int:
t = "%#"
for k in range(len(s)):
t += s[k]
t += "#"
n = len(t)
t += "!"
f = [None for j in range(n)]
iMax = rMax = ans = 0
for i in range(1, n):
# 初始化 f[i]
f[i] = min(rMax-i+1, f[2*iMax-i]) if i <= rMax else 1
# 中心拓展
while t[i+f[i]] == t[i-f[i]]:
f[i] += 1
# 动态维护 iMax 和 rMax
if i+f[i]-1 > rMax:
iMax = i
rMax = i + f[i] - 1
# 统计答案, 当前贡献为 (f[i] - 1) // 2 上取整
ans += (f[i] // 2)
return ans2020/08/19 - 99.80% (40ms) - 最佳

其他实现与说明
未完待续
参考文献
https://leetcode-cn.com/problems/palindromic-substrings/submissions/
201. 数字范围按位与
1. 题目要求

2. 解决过程
测试用例
0
2147483647
20000
2147483647失败测试
法一:暴力法。空间复杂度 O(1),时间复杂度 O(n)。
2020/08/23 - 超出时间限制
class Solution:
def rangeBitwiseAnd(self, m: int, n: int) -> int:
if m == 0:
return 0
result = m
for num in range(m+1, n+1):
result = result & num
return result官方实现与说明

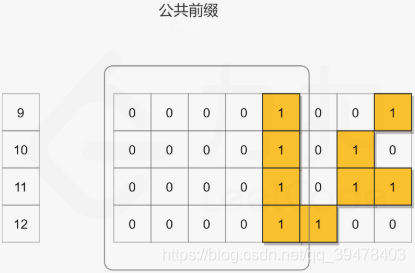


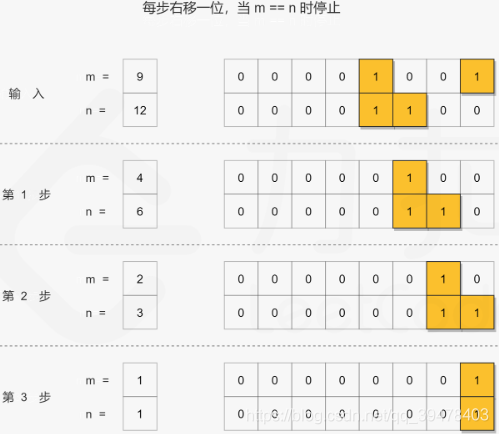

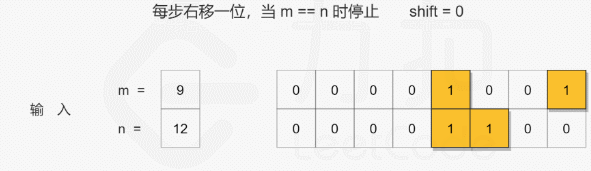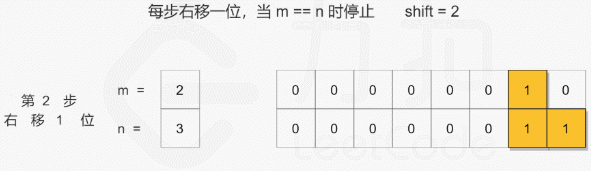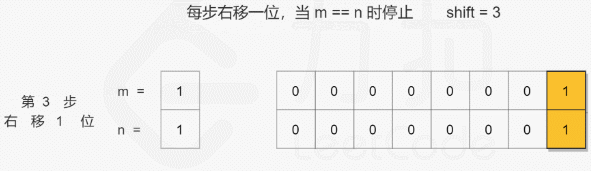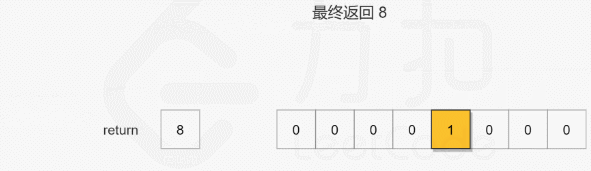
## 对位运算还是不够熟悉!
class Solution:
def rangeBitwiseAnd(self, m: int, n: int) -> int:
# 初始化移位次数计数器
shift = 0
# 找到公共前缀, 即移位至 m = n
while m < n:
m = m >> 1
n = n >> 1
shift += 1
return m << shift2020/08/23 - 93.31% (64ms)




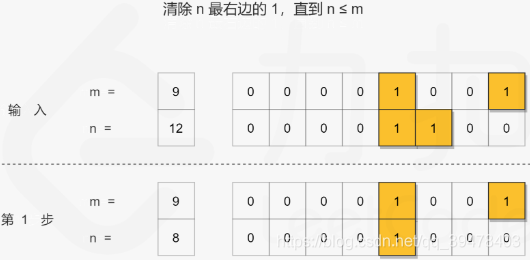
![]()
class Solution:
def rangeBitwiseAnd(self, m: int, n: int) -> int:
while m < n:
# 抹去最右边的 1
n = n & (n - 1)
return n2020/08/23 - 98.92% (56ms) - 最佳

参考文献
https://leetcode-cn.com/problems/bitwise-and-of-numbers-range/submissions/
17. 电话号码的数字组合
1. 题目要求
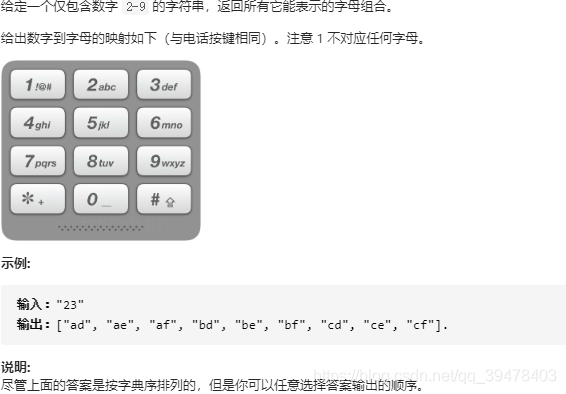
2. 解决过程
个人实现
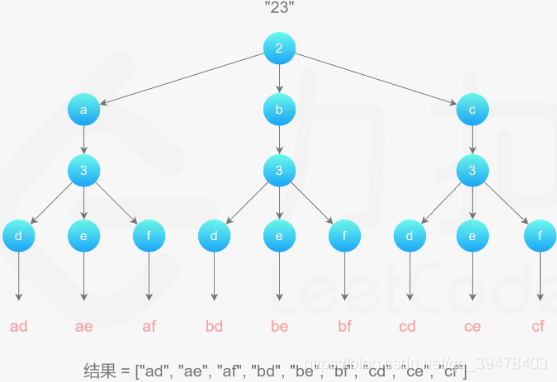
法一:哈希表 + BFS 迭代实现。
先通过哈希表 tel 建立起数字到字符元组的映射,然后新建一个辅助队列 Q。遍历输入数字字符串 digits,从哈希表 tel 取出当前数字字符 num 对应的字符元组 alp。接着,令辅助队列 Q 中已存在的组合依次出队。设当前组合为 cur,则遍历字符元组 alp 依次取出字符 char 拼接到当前组合 cur 的末尾得到 cur+char,并使之入队。依次类推,完成所有可能的组合。
从另一个角度看,这相当于一个 N 叉数的层序遍历问题 (N ∈ {3,4}),从该层面上就很好理解了。空间复杂度 O(n),时间复杂度 O(n²)。
2020/08/26 - 98.98% (28ms) - 最佳
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return []
tel = {"2":("a", "b", "c"), "3":("d", "e", "f"),
"4":("g", "h", "i"), "5":("j", "k", "l"),
"6":("m", "n", "o"), "7":("p", "q", "r", "s"),
"8":("t", "u", "v"), "9":("w", "x", "y", "z")}
Q = collections.deque([""])
for num in digits:
alp = tel[num] # 当前数字字符映射到字符元组
kinds = len(Q) # 已存在组合数
for _ in range(kinds):
cur = Q.popleft() # 当前组合
for char in alp: # 遍历新增字符元组
Q.append(cur+char)
return list(Q)官方实现与说明

class Solution:
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return list()
phoneMap = {
"2": "abc",
"3": "def",
"4": "ghi",
"5": "jkl",
"6": "mno",
"7": "pqrs",
"8": "tuv",
"9": "wxyz",
}
def backtrack(index: int):
if index == len(digits):
combinations.append("".join(combination)) # 当前组合整合并记录
else:
digit = digits[index] # 当前数字字符
for letter in phoneMap[digit]: # 遍历数字字符对应字符串
combination.append(letter) # 加入当前组合
backtrack(index+1)
combination.pop() # 当前组合已记录, 弹出
combination = list() # 辅助栈
combinations = list() # 结果列表
backtrack(0)
return combinations2020/08/27 - 68.98% (40ms)

其他实现与说明
法一:回溯 + DFS 递归实现。
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return []
# 用数组映射表可更节省点内存,第二个位置是"abc“, 第三个位置是"def"...
d = [" ", "*", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"]
def dfs(tmp, index):
# 递归终止条件
if index == len(digits):
res.append(tmp)
return
# 当前数字字符
c = digits[index]
# chr(48) = "0", ord(c)-48 获取 c 的 ASCII 码后 -48 即可索引查数组,
letters = d[ord(c)-48]
# 遍历字符串
for i in letters:
# 调用下一层递归
dfs(tmp+i, index+1)
res = []
dfs("", 0)
return res2020/08/27 - 87.86% (36ms)
参考文献
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/submissions/
557. 反转字符串中的单词 III
1. 题目要求

2. 解决过程
个人实现 - 其实跟逆序有关的大都可以借助栈实现
法一:将字符串按单词分成字符串列表,然后分别对各字符串反转,最后合并回字符串。本实现仅供观察。
2020/08/30 - 77.57% (44ms) - 不要一直用特有的内置函数,复杂度不好分析
class Solution:
def reverseWords(self, s: str) -> str:
return " ".join(map(lambda x: x[::-1], s.split()))法二:先对整个字符串反转,在将字符串按单词分成字符串列表,对各字符串反转,最后合并会字符串。本实现仅供观察。
2020/08/30 - 90.13% (40ms) - 减少了特有内置函数的使用
class Solution:
def reverseWords(self, s: str) -> str:
temp = s[::-1].split()
return " ".join(temp[::-1])官方实现与说明

// C++ implementation
class Solution {
public:
string reverseWords(string s) {
string ret;
int length = s.length();
int i = 0;
while (i < length) {
int start = i;
while (i < length && s[i] != ' ') {
i++;
}
for (int p = start; p < i; p++) {
ret.push_back(s[start + i - 1 - p]);
}
while (i < length && s[i] == ' ') {
i++;
ret.push_back(' ');
}
}
return ret;
}
}; 

// C++ implementation
class Solution {
public:
string reverseWords(string s) {
int length = s.length();
int i = 0;
while (i < length) {
int start = i;
while (i < length && s[i] != ' ') {
i++;
}
int left = start, right = i - 1;
while (left < right) {
swap(s[left], s[right]);
left++;
right--;
}
while (i < length && s[i] == ' ') {
i++;
}
}
return s;
}
}; 
参考文献
https://leetcode-cn.com/problems/reverse-words-in-a-string-iii/
47. 全排列 II
1. 题目要求

2. 解决过程
个人实现
法一:暴力法。
2020/09/18 - 5.78% (1340ms)
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(cur, opt):
if not opt:
if cur not in result:
result.append(cur)
return
for index in range(len(opt)):
cur_temp = copy.copy(cur) # 浅拷贝
opt_temp = copy.copy(opt) # 浅拷贝
cur_temp.append(opt_temp.pop(index))
dfs(cur_temp, opt_temp)
result = []
dfs([], nums)
return result法一改:暴力法。
2020/09/18 - 19.24% (508ms)
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(cur, opt):
if not opt:
if tuple(cur) not in seen:
seen.add(tuple(cur)) # 使用元组存储于哈希集合
result.append(cur)
return
for index in range(len(opt)):
cur_temp = copy.copy(cur) # 浅拷贝
opt_temp = copy.copy(opt) # 浅拷贝
cur_temp.append(opt_temp.pop(index))
dfs(cur_temp, opt_temp)
seen = set() # 使用哈希集合存储不重复排列
result = [] # 结果列表
dfs([], nums)
return result官方实现与说明

// C++ implementation
class Solution {
vector<int> vis;
public:
void backtrack(vector<int>& nums, vector<vector<int>>& ans, int idx, vector<int>& perm) {
if (idx == nums.size()) {
ans.emplace_back(perm);
return;
}
for (int i = 0; i < (int)nums.size(); ++i) {
if (vis[i] || (i > 0 && nums[i] == nums[i - 1] && !vis[i - 1])) {
continue;
}
perm.emplace_back(nums[i]);
vis[i] = 1;
backtrack(nums, ans, idx + 1, perm);
vis[i] = 0;
perm.pop_back();
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<vector<int>> ans;
vector<int> perm;
vis.resize(nums.size());
sort(nums.begin(), nums.end());
backtrack(nums, ans, 0, perm);
return ans;
}
};
其他实现与说明 1
![]()
// C++ implementation
class Solution {
public:
vector<vector<int>> ans;
vector<int>temp;
void dfs(vector<int>&nums, int count, int len)
{
if(count==len) {ans.push_back(temp); return;}
int holder = 0xffff;
for(int i=0;i<len;++i)
{
if(nums[i] == 0xffff || nums[i] == holder) continue;
holder = nums[i];
temp.push_back(nums[i]);
nums[i] = 0xffff;
dfs(nums, count+1, len);
temp.pop_back();
nums[i] = holder;
}
return;
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
int len = nums.size();
sort(nums.begin(), nums.end());
dfs(nums, 0, len);
return ans;
}
};其他实现与说明 2
2020/09/18 - 98.23% (40ms) - 最佳
# Python implementation
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(curr, rest):
if not rest:
result.append(curr)
return
for i in range(len(rest)):
if rest[i] in rest[:i]: ## 当前数字之前已使用过, 不再于本次使用, 以避免重用
continue
dfs(curr + [rest[i]], rest[:i] + rest[i+1:]) # 列表拼接将生成新列表, 免去手动拷贝的繁琐操作
result = []
dfs([], nums)
return result其他实现与说明 3
2020/09/18 - 98.23% (40ms) - 最佳
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(index):
if index == len(nums)-1: # 所有数字都已组合完毕
result.append(nums[:])
return
seen = set() # 在当前数字 nums[index]下, 已使用数字集合
for i in range(index, len(nums)):
if nums[i] in seen: # 避免重复使用相同数字
continue
seen.add(nums[i])
# 令所有数字 nums[i] 与当前数字 nums[index] 交换
nums[i], nums[index] = nums[index], nums[i] ## 通过交换避免切片和拼接
dfs(index+1)
nums[i], nums[index] = nums[index], nums[i] # 还原, 避免影响下次使用
result = []
dfs(0)
return result 其他实现与说明 4


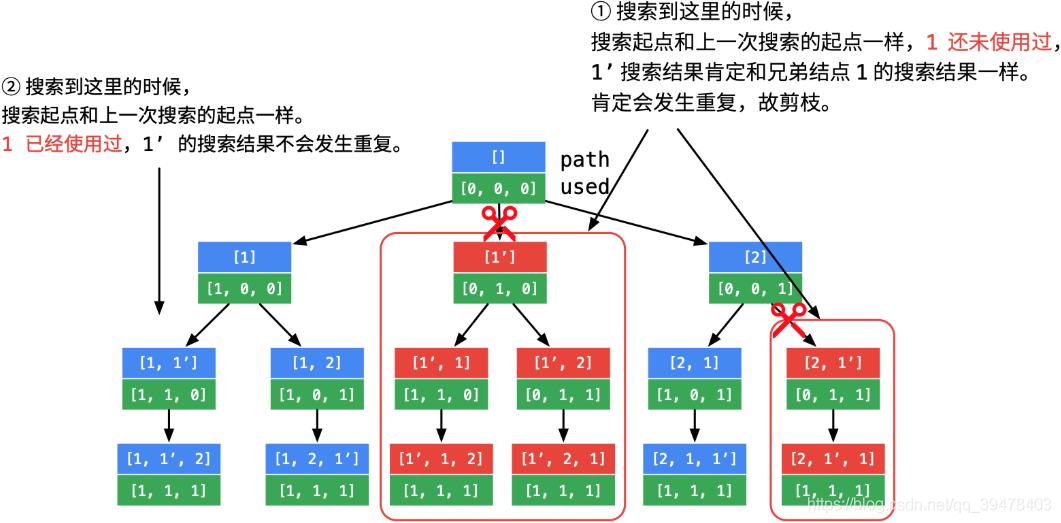


2020/09/18 - 70.10% (52ms)
# Python implementation
class Solution:
def permuteUnique(self, nums: List[int]) -> List[List[int]]:
def dfs(nums, size, depth, path, used, res):
if depth == size:
res.append(path.copy())
return
for i in range(size):
if not used[i]:
if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:
continue
used[i] = True
path.append(nums[i])
dfs(nums, size, depth + 1, path, used, res)
used[i] = False
path.pop()
size = len(nums)
if size == 0:
return []
nums.sort()
used = [False] * len(nums)
res = []
dfs(nums, size, 0, [], used, res)
return res
参考文献
https://leetcode-cn.com/problems/permutations-ii/submissions/
https://leetcode-cn.com/problems/permutations-ii/solution/quan-pai-lie-ii-by-leetcode-solution/
1002. 查找常用字符
1. 题目要求



2. 解决过程
测试用例
["bella","label","roller"]
["cool","lock","cook"]
["label"]
["acabcddd","bcbdbcbd","baddbadb","cbdddcac","aacbcccd","ccccddda","cababaab","addcaccd"]个人实现
法一:哈希映射。以 dict 作为统计的中间形式。
2020/10/14 - 95.27% (48ms)
class Solution:
def commonChars(self, A: List[str]) -> List[str]:
# 字符串列表仅含单个元素, 直接输出
if len(A) == 1:
return [char for char in A[0]]
# 目标计数器 首元素计数
counter = {}
for c in A[0]:
if counter.get(c) is None:
counter[c] = 0
counter[c] += 1
# 遍历字符串列表其余单词
for j in range(1, len(A)):
# 统计当前单词字符至临时计数器
temp = {}
for c in A[j]:
if temp.get(c) is None:
temp[c] = 0
temp[c] += 1
# 记录目标计数器需要移除的字符
del_key = []
# 遍历目标计数器
for k in counter.keys():
# 若字符 (key) 不存在于当前单词, 加入移除列表 del_key
if temp.get(k) is None:
del_key.append(k)
# 若字符 (key) 在当前单词出现次数小于目标计数器计数, 减少计数 (value)
elif temp[k] < counter[k]:
counter[k] = temp[k]
# 根据列表移除字符 (key)
for d in del_key:
del counter[d]
# 结果字符列表 dict → list
result = [key for key, value in counter.items() for _ in range(value)]
return result法一改:使用 collections.Counter 简化。
2020/10/14 - 95.27% (48ms)
class Solution:
def commonChars(self, A: List[str]) -> List[str]:
# 目标计数器 首元素计数
counter = collections.Counter(A[0])
# 字符串列表仅含单个元素, 直接输出
if len(A) == 1:
return list(counter.elements())
# 遍历字符串列表其余单词
for j in range(1, len(A)):
# 统计当前单词字符至临时计数器
temp = collections.Counter(A[j])
# 记录目标计数器需要移除的字符
del_key = []
# 遍历目标计数器
for k in counter.keys():
# 若字符 (key) 不存在于当前单词, 加入移除列表 del_key
if temp.get(k) is None:
del_key.append(k)
# 若字符 (key) 在当前单词出现次数小于目标计数器计数, 减少计数 (value)
elif temp[k] < counter[k]:
counter[k] = temp[k]
# 根据列表移除字符 (key)
for d in del_key:
del counter[d]
# 结果字符列表
return list(counter.elements())官方实现与说明

// C++ implementation
class Solution {
public:
vector<string> commonChars(vector<string>& A) {
vector<int> minfreq(26, INT_MAX);
vector<int> freq(26); // 为什么不定义在 range for 中 —— 也可以
for (const string& word: A) {
// vector<int> freq(26);
fill(freq.begin(), freq.end(), 0);
for (char ch: word) {
++freq[ch - 'a'];
}
for (int i = 0; i < 26; ++i) {
minfreq[i] = min(minfreq[i], freq[i]);
}
}
vector<string> ans;
for (int i = 0; i < 26; ++i) {
for (int j = 0; j < minfreq[i]; ++j) {
ans.emplace_back(1, i + 'a');
}
}
return ans;
}
};# Python implementation
class Solution:
def commonChars(self, A: List[str]) -> List[str]:
# 存储字符 c 在所有字符串中出现次数的最小值
minfreq = [float("inf")] * 26
# 遍历字符串列表
for word in A:
freq = [0] * 26 # 临时计数数组
for ch in word:
freq[ord(ch) - ord("a")] += 1
for i in range(26):
minfreq[i] = min(minfreq[i], freq[i]) # 取出现次数的最小值
ans = list()
for i in range(26):
ans.extend([chr(i + ord("a"))] * minfreq[i])
return ans2020/10/14 - 21.30% (72ms)

其他实现与说明
# Python implementation
class Solution:
def commonChars(self, A: List[str]) -> List[str]:
res = None
for a in A:
c = collections.Counter(a)
if res is None:
res = c
else:
res &= c # 关键步骤
return list(res.elements())# Python implementation
class Solution:
def commonChars(self, A: List[str]) -> List[str]:
return list(reduce(lambda x, y: x & y, map(collections.Counter, A)).elements())// C++ implementation
class Solution {
public:
vector<string> commonChars(vector<string>& A) {
vector<string> result;
if (A.size() == 0) return result;
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
hash[A[0][i] - 'a']++;
}
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
for (int i = 1; i < A.size(); i++) {
memset(hashOtherStr, 0, 26 * sizeof(int));
for (int j = 0; j < A[i].size(); j++) {
hashOtherStr[A[i][j] - 'a']++;
}
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
for (int k = 0; k < 26; k++) {
hash[k] = min(hash[k], hashOtherStr[k]);
}
}
// 将hash统计的字符次数,转成输出形式
for (int i = 0; i < 26; i++) {
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
string s(1, i + 'a'); // char -> string
result.push_back(s);
hash[i]--;
}
}
return result;
}
};参考文献
https://leetcode-cn.com/problems/find-common-characters/
977. 有序数组的平方
1. 题目要求
![]()


2. 解决过程
个人实现
关于直接平方各元素,然后原地排序的思路十分明显直白,以下不作赘述。
法一:堆排序。空间复杂度 O(n),时间复杂度 O(nlogn)。
2020/10/16 - 99.39% (240ms) - 次优
class Solution:
def sortedSquares(self, A: List[int]) -> List[int]:
# B = list(map(lambda i: i*i, A)) # map - 构造平方值列表 (涉及类型转换, 效率更低)
B = [i*i for i in A] # 列表推导式 - 构造平方值列表
heapify(B) # 堆排序 - 小顶堆
return [heappop(B) for _ in range(len(A))] # 列表推导式 - 依次弹出堆顶最小值官方实现与说明

// C++ implementation
class Solution {
public:
vector<int> sortedSquares(vector<int>& A) {
vector<int> ans;
for (int num: A) {
ans.push_back(num * num);
}
sort(ans.begin(), ans.end());
return ans;
}
};# Python implementation
class Solution:
def sortedSquares(self, A: List[int]) -> List[int]:
return sorted(num * num for num in A)2020/10/16 - 99.91% (216ms) - 最佳 - 看来 Python 内置函数的优化还是很不错的


// C++ implementation
class Solution {
public:
vector<int> sortedSquares(vector<int>& A) {
int n = A.size();
int negative = -1;
for (int i = 0; i < n; ++i) {
if (A[i] < 0) {
negative = i;
} else {
break;
}
}
vector<int> ans;
int i = negative, j = negative + 1;
while (i >= 0 || j < n) {
if (i < 0) {
ans.push_back(A[j] * A[j]);
++j;
}
else if (j == n) {
ans.push_back(A[i] * A[i]);
--i;
}
else if (A[i] * A[i] < A[j] * A[j]) {
ans.push_back(A[i] * A[i]);
--i;
}
else {
ans.push_back(A[j] * A[j]);
++j;
}
}
return ans;
}
};# Python implementation
class Solution:
def sortedSquares(self, A: List[int]) -> List[int]:
n = len(A)
negative = -1 # 分界点
for i, num in enumerate(A):
if num < 0:
negative = i
else:
break
ans = [] # 改用 [] 比 list 快 2-3 倍
i, j = negative, negative + 1
while i >= 0 or j < n:
if i < 0: # 左侧负数提前耗尽
ans.append(A[j] * A[j])
j += 1
elif j == n: # 右侧非负数提前耗尽
ans.append(A[i] * A[i])
i -= 1
elif A[i] * A[i] < A[j] * A[j]: # 右侧数平方更大
ans.append(A[i] * A[i])
i -= 1
else:
ans.append(A[j] * A[j]) # 左侧数平方更大
j += 1
return ans2020/10/16 - 96.37% (248ms) - 其实查找最大负数的位置可用 二分查找


// C++ implementation
class Solution {
public:
vector<int> sortedSquares(vector<int>& A) {
int n = A.size();
vector<int> ans(n); // 等长向量, 从大往小赋值修改
for (int i = 0, j = n - 1, pos = n - 1; i <= j;) {
if (A[i] * A[i] > A[j] * A[j]) {
ans[pos] = A[i] * A[i];
++i;
}
else {
ans[pos] = A[j] * A[j];
--j;
}
--pos;
}
return ans;
}
};# Python implementation
class Solution:
def sortedSquares(self, A: List[int]) -> List[int]:
n = len(A)
ans = [0] * n
i, j, pos = 0, n - 1, n - 1
while i <= j:
if A[i] * A[i] > A[j] * A[j]:
ans[pos] = A[i] * A[i]
i += 1
else:
ans[pos] = A[j] * A[j]
j -= 1
pos -= 1
return ans2020/10/16 - 99.39% (240ms) - 次优


参考文献














 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









