







文章目录
KMP算法
1. 暴力做法是怎么做的
1.1 时间复杂度: O(n^2)
直接利用双指针进行循环判断
- 循环遍历长串
- 二重循环遍历短串
- 经过比较如果不匹配, 就进行下一个字母进行重新匹配
S[N], p[M]; // s 是长串, p 是短串
for(int i = 1; i < = n; i ++)
{
bool flag = true;
for(int j = 1; j <= m; j ++)
if(s[i] !] p[j])
{
flag = false;
break;
}
}
2. 怎么去优化它

2.1 一般情况:
- 当子串匹配到中间时候,如果下一个字母出现不匹配情况,这时按照暴力做法就会移动长串的指针一位,然后进行下一次匹配
- 我们可以发现当匹配到一部分后,这时是存在一部分信息的,如果能利用前面匹配的信息,下次遍历就会少遍历几次,达到优化效果

2.2 原理:
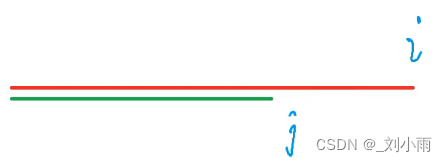
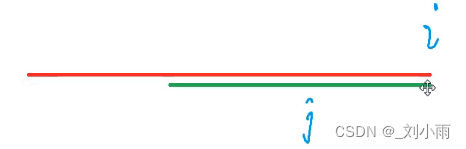
需要找到最少移动几位,才能保证移动后(最下面的红线)前缀 和之前短串(中间红线)后缀{以跟长串不匹配的字符为界限}
现在就需要预处理一个短串中以每个子串结束的 前缀和后缀相等的最长大小是多少。这就是KMP中最核心的next 数组。
以 next[i] = j; 为例;表示的是 p字符串数组中是以i 为终点的子串 p[1~j] = p[i - j + 1, i] 是相等的
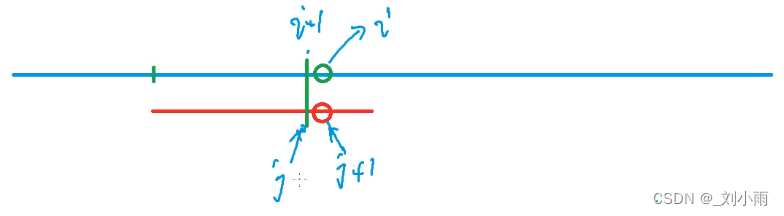
2.3 匹配过程
现在重新开始上面的分析:
假设: 当长串移动到i 位置和短串不匹配了, 对应下图就是 s[i] != p[j + 1]; , 此时利用kmp 算法后应该最少向右移动多少,其实就是移动j - next[j];
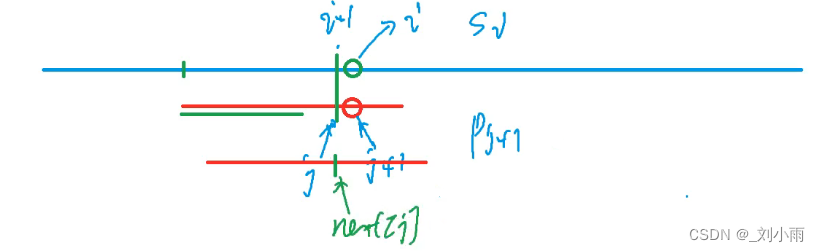
下图可知:当next数组值大时,就比表示前缀和后缀相等的字符多,此时移动的位数就少,这么分析就是移动了j - next[j], 但在代码中可以直接表示为 比较s[i] = p[next[j] + 1],即 直接比较next[j] 下一个字符就行了,不必分析移动了多少位; 如果不匹配,则可以递归的进行这个过程。
2.4 kmp 匹配的实现代码
// kmp 匹配过程
for (int i =1, j = 0; i <= m; i ++)
{
// p 没退回起点 或者 子串不匹配 (这里比较的是 s 数组i位 和 p 数组的j + 1 位)
while( j && s[i] != p[j + 1]) j = ne[j];
// 如果能匹配, 指针j 向后移动
if (s[i] == p[j + 1]) j ++;
if (j == n)
{
// cout << i - m << ' ';
printf("%d ", i - n);
// 这里比较结束了, 需要把j 赋值为 ne[j], 待下一次进行匹配
j = ne[j];
}
}
2.5 next 数组构造过程
接下来就是kmp算法的核心数组 next 的求法过程
其实也跟上面的过程有点类似, 只不过这里是换成自己与自己进行匹配操作得出来的(代码仿照上面来)
- 这下面三根线都是短串, 当短串 匹配到 位置i 后, 发现不匹配后,需要完后移动多少位呢
- 这里假设已经存在next数组了, 这时就直接将中间的红线移动到最下面的红线,也就是直接对ne[j] 的下一个字符进行比较, 如果不符合要求,就继续移动,将ne[j] 换成 ne[ne[j]], 红线向后移动(图中未画出)
下图是一个整体的过程:
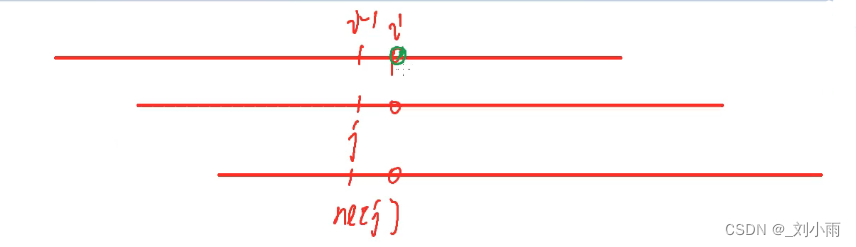
拆分成两个步骤就是下面这样
- 当需要求ne[i] 等于多少时,此时子串时这样进行匹配的 ; 此时的
p[a~b] = p[1~j] - 当遇到p[i] != p[j + 1] j = ne[j]
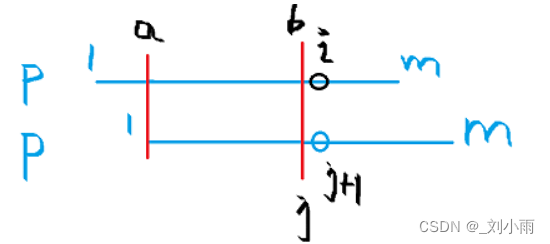
- 上面是自己跟自己匹配的过程,现在匹配结束后ne[i] = j; 这就是next 数组的构造过程
2.6 next 数组 构造过程code:
// 这里的数组都是从1开始的
// 这里ne[1] 不必求, 如果不匹配直接从头开始了
for(int i = 2, j = 0; i <= n; i ++)
{
// 如果没有回到起点 && 第i 个位置和第 j + 1 个位置不匹配
while(j && p[i] != p[j + 1]) j =ne[j]; // 如果不匹配,退而求其次
if(p[i] == p[j + 1]) j ++;
ne[i] = j;
}
可能上述还是有点抽象, 这时可以手动模拟,和代码对比,理解next 数组的构造过程
2.7 手动模拟next 数组 构造
2.7.1 例1
对 p = “abcab”

2.7.2 例2

3. KMP例题
给定一个模式串 S,以及一个模板串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串 P 在模式串 S 中多次作为子串出现。
求出模板串 P 在模式串 S 中所有出现的位置的起始下标。
输入样例:
3
aba
5
ababa
输出样例:
0 2
3.1 KMP 完整代码:
#include <iostream>
using namespace std;
const int N = 10010, M = 100010;
int n,m;
char p[N], s[M];
int ne[N]; // next 这个名字可能会报错
int main()
{
// 字符串从1 开始
cin >> n >> p + 1 >> m>> s + 1;
// cout << n << m << endl;
// cout << p + 1;
// 求next 过程, 这里不能将i = 1, 否则error
for(int i = 2, j = 0; i <= n; i ++)
{
while( j && p[i] != p[ j + 1]) j = ne[j];
if(p[i] == p[j + 1]) j ++;
ne[i] = j;
}
// kmp 匹配过程
for (int i =1, j = 0; i <= m; i ++)
{
while( j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++;
if (j == n)
{
// 匹配成功
printf("%d ", i - n);
// 这里比较结束了, 需要把j 赋值为 ne[j], 待下一次进行匹配
j = ne[j];
}
}
return 0;
}
3.2 时间复杂度O(n)
分析: 上面一层遍历n次, 下面m最多减m次,实际上是O(2m), 所以时间复杂度为O(n)
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









