










正则表达式的规则很容易理解,但是正则表达式并不能直接用来解析字符串,我们还要引入一种适合转化为计算机程序的模型。今天我们引入的这种模型就叫做有穷自动机(finite automation,FA),有时也叫有穷状态机(finite state machine)。有穷自动机首先包含一个有限状态的集合,还包含了从一个状态到另外一个状态的转换。有穷自动机看上去就像是一个有向图,其中状态是图的节点,而状态转换则是图的边。此外这些状态中还必须有一个初始状态和至少一个接受状态。
自动机是一种非常有力的工具,其完备的理论可以参考编译原理或者形式语言与自动机等相关教材。从某种定义角度而言,图灵机也是自动机的一种。这里提到的自动机特指有限状态自动机,简称为FA,根据状态转移的性质又分为确定的自动机(DFA)和非确定的自动机(NFA)。FA的表达能力等价于正规表达式或者正规文法。
FA可以看做是一个有向带权图,图的顶点集合称为自动机的状态集合,图的权值集合为自动机的字母集合,图的边代表了自动机中状态变化的情况。此外,根据需要,自动机还需指定初始状态和终态。FA最基本的作用就是形式化描述,而且有利于编程实现。以下提到自动机全部指的是DFA。
考虑仅由字母{a, b}组成的字符串,要求字符串中字母b必须成对出现,否则字符串非法。这个规则实现起来其实非常简单,不需要自动机也完全可以。但是我们考虑使用自动机来进行判断。顺便,该规则的正规表达式描述是:(a|bb)*。星号运算代表重复若干次,包括零次。
我们考虑做一个图来表示描述该规则的DFA。令状态1为初始状态,显然在状态1上,我们还没有违反规则。因此,经过字母a以后我们还可以回到状态1。经过字母b就不能回到状态1了,此时需要一个新状态,令其为2。
状态2表示“待定的”状态,在这个状态时不能肯定字符串是非法的,但也不是合法的。在状态2上,如果经过字母b,就回到了合法的状态也就是状态1,;如果经过字母a,则该字符串肯定是非法的。建立一个新状态即状态3,用于表示非法状态。
状态3比较简单,已经到了非法状态,其后的任何字母都不会改变这个状态了。因此,该DFA可以表示如下。

程序实现也非常简单,状态和字母都被编码成整数,使用一个矩阵表示状态转移,再写一个函数表示自动机的运行,对每一个字符串,从状态1开始运行,运行完毕进行状态判断即可。最后能停留在状态1的字符串才是符合规则的,其余都是非法的。
下面的图展示了一个有穷自动机,有根从外边来的箭头指向的状态表示初始状态,有个黑圈的状态是接受状态:
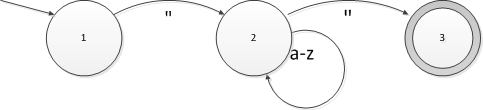
现在我们来看看有穷自动机怎么处理输入的字符串:
- 一开始,自动机处于初始状态
- 输入字符串的第一个字符,这时自动机会查询当前状态上与输入字符相匹配的边,并沿这条边转换到下一个状态。
- 继续输入下一个字符,重复第二步,查询当前状态上的边并进行状态转换
- 当字符串全部输入后,如果自动机正好处于接受状态上,就说该自动机接受了这一字符串。
刚才我们画的自动机,假如输入的字符串是"hello"(带引号)。一开始状态机处于状态1,输入引号以后就沿引号的边转换到了状态2;接下来输入hello都会沿着a-z这条边回到状态2,最后输入引号,转换到了状态3。由于状态3是接受状态,那么这个自动机就会接受这个字符串。而如果字符串是"abc(不带后面的引号),那么当字符串输入完毕之后自动机会处在状态2,而状态2不是接受状态,所以这个自动机就不接受"abc这个字符串。一个自动机接受的所有字符串组成的集合称作这个自动机的语言。这里语言的概念和上一回我们介绍正则表达式的语言概念是一样,都表示一个有限字符集上的字符串集合。
上面我们画的自动机是一个确定性有穷自动机(DFA),其特点是从每一个状态只能发出一条具有某个符号的边。也就是说不能出现同一个符号出现在同一状态发出的两条边上。但是,还有一种非确定性有穷自动机(NFA),它允许从一个状态发出多条具有相同符号的边,甚至允许发出标有ε(表示空)符号的边,也就是说,NFA可以不输入任何字符就自动沿ε边转换到下一个状态。下图展示了一个非确定性有穷自动机:

非确定性有穷自动机在遇到两条边上有相同的符号,会选择哪一边呢?遇到ε边到底会转移还是不会转移呢?答案是,NFA会自动猜测应该选择哪一条边,而且每次都能猜对。比如说,上面的NFA,假如输入字符串是aa,它就会选择右边这条路径,并且接受这个字符串;假如输入字符是aaa,它就会走左边这条路径,并接受字符串。它绝不会在输入字符是aaa的时候选择右边路径然后做出不接受这一判断。由于我们的计算机并没有这种“猜测”能力,大家可能会对NFA具有这种能力感到奇怪。有些人在刚刚接触这些概念的时候可能会觉得NFA因为具有自动猜测的能力,应该要比DFA更加强大。但事实上是,DFA、NFA和正则表达式是等价的,任何NFA都存在一个与之接受同样语言的DFA,和一个定义相同语言的正则表达式;同理任何正则表达式,也存在一个接受其所定义语言的NFA和一个DFA。这三种模型虽然定义迥然不同,但却表示同样的正则语言。幸运的是,只需要很简单的规则,就能把任何正则表达式转化成NFA,而任何一个NFA又都可以转化为DFA,这样我们就能把正则表达式转化为易于编程的DFA,来真正进行词法分析的工作。(注,也有正则表达式引擎直接模拟NFA的运行来解析字符串,有兴趣的读者可以自行寻找有关的资料。)
现在我们来看怎么把正则表达式转化为NFA。我们上次学到正则表达式有两种基本要素——字符表达式和ε表达式,以及三种基本运算——并、连接和闭包。首先我们来看最基础的ε表达式,它的NFA是这样的:

接下来是字符表达式a,它的NFA是这样:

所有正则表达式都可以转化为一个有一条输入边,以及一个接受状态的的正则表达式,我们先假设一个一般的正则表达式的NFA是这样:

然后我们定义两个正则表达试的并运算,X|Y的NFA为:(实际应用中,常常可以简化掉一部分ε转换边)

两个这正则表达式的连接运算,XY的NFA为:

一个正则表达式的克林闭包运算,Y*的NFA为:

递归运用以上规则,就可以把任何正则表达式转化为NFA。我们来试试看。上次研究了标识符的正则表达式[a-z][a-z0-9]*,运用以上规则,转换成的NFA是:

词法分析时,我们要把所有的单词的正则表达式分别转换成NFA,然后用“并”的关系将所有NFA连接到一起,就成了词法分析所需的最终NFA。
















 6133
6133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











