







相信看这篇文章的你们,都和我一样对Hadoop和Apache Spark的选择有一定的疑惑,今天查了不少资料,我们就来谈谈这两种 平台的比较与选择吧,看看对于工作和发展,到底哪个更好。
一、Hadoop与Spark
1.Spark
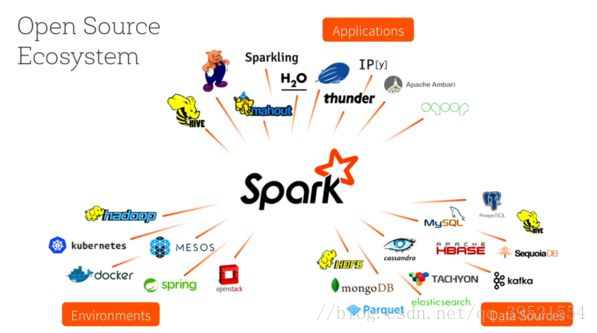
Spark是一个用来实现快速而通用的集群计算的平台。速度方面,Spark扩展了广泛使用的MapReduce计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。
Spark项目包含多个紧密集成的组件。Spark的核心是一个对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。
2.Hadoop
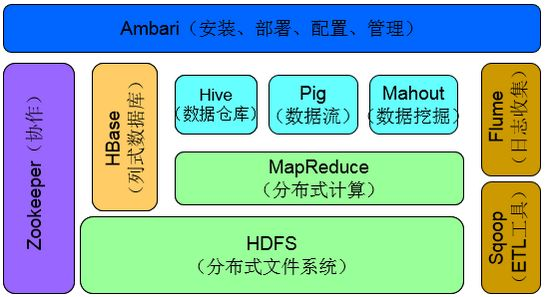
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二、异与同
- 解决问题的层面不一样
首先,Hadoop和Apache Spark两者都是大数据框架,但是各自存在的目的不尽相同。Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











