







需求: 实现统计 每个手机号的 上行包 下行包 总包
案例资源和文件:http://pan.baidu.com/s/1eSMmpkm
首先定义了一类接收数据处理过程中map阶段输出的value.
package com.vampire.taobao;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class PackgeFlow implements Writable {
private Long uppackge;
private Long downpackge;
private Long entriepackgeLong;
public void write(DataOutput out) throws IOException {
out.writeLong(uppackge);
out.writeLong(downpackge);
out.writeLong(entriepackgeLong);
}
public void readFields(DataInput in) throws IOException {
uppackge=in.readLong();
downpackge=in.readLong();
entriepackgeLong=in.readLong();
}
public Long getUppackge() {
return uppackge;
}
public void setUppackge(Long uppackge) {
this.uppackge = uppackge;
}
public Long getDownpackge() {
return downpackge;
}
public void setDownpackge(Long downpackge) {
this.downpackge = downpackge;
}
public Long getEntriepackgeLong() {
return entriepackgeLong;
}
public void setEntriepackgeLong(Long entriepackgeLong) {
this.entriepackgeLong = entriepackgeLong;
}
public PackgeFlow() {
super();
}
@Override
public String toString() {
return "PackgeFlow[uppackge=" + uppackge + ",downpackge="
+ downpackge + ",entriepackgeLong=" + entriepackgeLong + "]";
}
public PackgeFlow(Long uppackge, Long downpackge, Long entriepackgeLong) {
super();
this.uppackge = uppackge;
this.downpackge = downpackge;
this.entriepackgeLong = entriepackgeLong;
}
public void set(Long uppackge, Long downpackge, Long entriepackgeLong) {
this.uppackge = uppackge;
this.downpackge = downpackge;
this.entriepackgeLong = entriepackgeLong;
}
}
实现mapReduer的过程
package com.vampire.taobao;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.task.reduce.MapOutput;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class PackgeRun extends Configured implements Tool{
// 拿到日志中的一行数据,并且切分成各个字段,取出需要的字段
// 手机号 上行包 下行包,然后封装成k-v发送出去
public static class Pkmaper extends
Mapper<LongWritable, Text, Text, PackgeFlow> {
private Text mapOutKey=new Text();
private PackgeFlow mapOutput=new PackgeFlow();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
String line=value.toString();
String [] str = line.split("\t");
mapOutKey.set(str[1]);
String up=str[6];
String down=str[7];
mapOutput.set(Long.parseLong(up), Long.parseLong(down), Long.parseLong(up)+Long.parseLong(down));
context.write(mapOutKey, mapOutput);
}
}
public static class Pkreduce extends
Reducer<Text, PackgeFlow,Text, PackgeFlow> {
private PackgeFlow packgeFlow=new PackgeFlow();
@Override
protected void reduce(Text text, Iterable<PackgeFlow> iterable,
Contextcontext)
throws IOException, InterruptedException{
long sum_up=0;
long sum_down=0;
long sum_enp=0;
for(PackgeFlow f:iterable){
sum_up+=f.getUppackge();
sum_down+=f.getDownpackge();
sum_enp+=f.getEntriepackgeLong();
}
packgeFlow.set(sum_up, sum_down, sum_enp);
context.write(text, packgeFlow);
}
}
public int run(String[] args) throws Exception {
//连接Hadoop需要获取Hadoop的配置信息
Configurationconfiguration =new Configuration();
//根据需要配置修改
// configuration.set(name, value);
//生成对象的job类型
Job job=Job.getInstance(configuration, this.getClass().getSimpleName());
job.setJarByClass(getClass());
//设置job具体的输入目录,map和reduce逻辑
//a.设置输入目录
Path inPath=new Path(args[0]);
FileInputFormat.setInputPaths(job, inPath);
job.setMapperClass(Pkmaper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PackgeFlow.class);
// job.setNumReduceTasks(7);
job.setReducerClass(Pkreduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(PackgeFlow.class);
//b.设置输出目录
Path outPath=new Path(args[1]);
FileSystem fs=outPath.getFileSystem(configuration) ;
//输出目录如果存在,则自动删除
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job,outPath);
//提交job
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configurationconfiguration =new Configuration();
args=new String []{"hdfs://vampire01:8020/input/123.data","hdfs://vampire01:8020/output"};
int run = ToolRunner.run(configuration, new PackgeRun() , args);
System.exit(run);
}
}
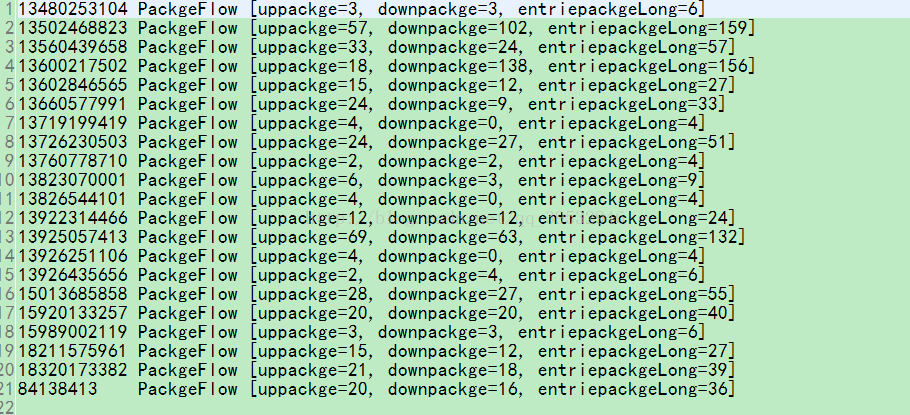
part00XXXX文件
mapReduce过程














 5655
5655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









