







三个机制【关键字:flush[刷新] compaction(minor major)【合并】 split【切分】】
1.一张表被划分成很多region,交给不同的regionserver管理
2.Hbase表根据rowkey划分成多个region
默认region大小是256M,分布式存储和负载均衡的最小单位
=》数据增加,在超过阈值(256)
257M(一分为二) split =》 找到对应region上的workey的startkey和endkey,从中间值切分成两个
3.memstrore【flush】 和 storefile【compaction】
1)一个region由多个store组成,一个store对应一个CF(列簇)
2)store包括位于内存中的memstore和位于磁盘的storefile,写操作先写入memstore,当memstore中的数据达到某个阈值(128M),regionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
3)当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction) ,在合并过程中会进行版本合并和删除工作,形成更大的storefile。
4)当一个region所有storefile的大小和超过一定阈值(256M)后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
5)storefile实际存储在hdfs上,又叫做hfile
【Flush基准参数】
基于memstore级别
基于单个region级别
基于regionserver级别
基于时间 默认是一个小时一次
手动flush
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<!--一台服务器regionserver所有memstore总容量(eg:100个region)达到40%就flush -->
<name>hbase.regionserver.global.memstore.upperLimit</name>
<value>0.4</value>
</property>
<!--一台服务器gionserver所有memstore总容量达到38%就会先flush一部分较大的memstore -->
<property>
<name>hbase.regionserver.global.memstore.lowerLimit</name>
<value>0.38</value>
</property>
##compacion机制
把小的storefile文件合并成大的storefile,因为同一个rowkey会始终合并成一个storefile。
默认小文件个数达到3个,或某个regionServer的mem总和达到128M就会执行合并操作.
##split机制
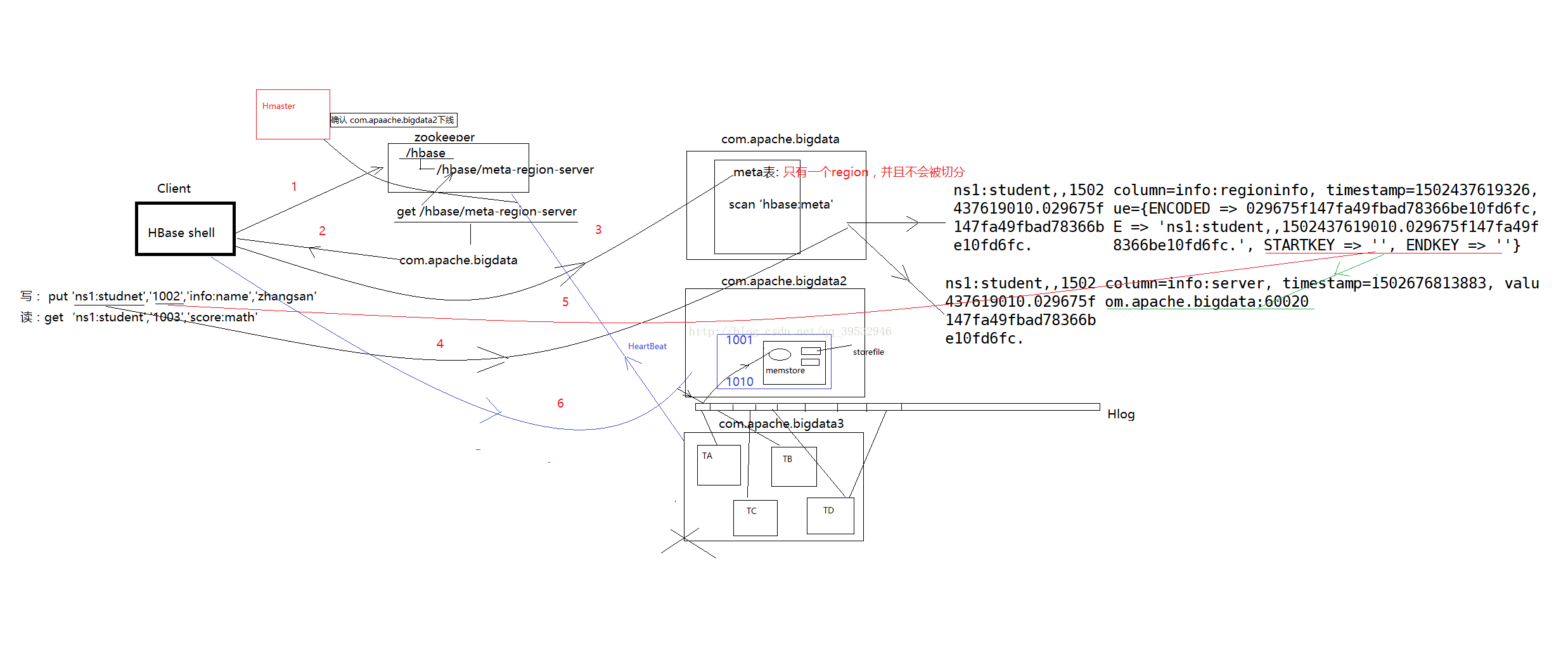
HBase的读写流程
Hbase:Meta =》The hbase:meta table holds references to all User Table regions
** Meta用户表的region信息(属于哪张用户表,这张表里包含了 哪些region,这些region交给了哪些regionserverg管理)
** 每个region的rowkey范围
(一)读数据流程 [scan get]
1)client访问zookeeper集群,zookeeper集群保存了meta的位置,获取meta被哪台regionserver服务器管理(老版本 -root- -meta-)
2)client向这台regionserver服务器发起访问请求(-meta-)
3)cliente从meta表的rgion获取到用户表信息(region、 rowkey起始范围),向对应的regionserver服务器发起数据访问请求
4)这台regionserver服务器接收到数据请求访问并响应数据给客户端
5)先扫描memstore,再扫描blockcache,再去扫描storefile
(二)写数据流程 [create put delete]
1)client访问zookeeper集群,获取meta表位置,并确定当前写入数据属于哪个region(rowkey),并确定regio对应的regionserver
2)client向这台regionserver服务器发起写入数据请求
3)regionserver服务器接收请求,并响应写入
4)写入WAL(Hlog)和memstore(内存)
5)当memstore数据达到阀值会flush进磁盘形成一个storefile文件(128M) --flush
6)小文件storefile合并成为一个大的storefile文件 --compact
7) 当storefile大小超过10G(默认值),会进行split --- split
** HLog
** WAL(write-ahead-log) 模仿oracle
** 防止意外断电数据丢失
** 整个读写流程,没有经过Master















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









