






一部分文件资源:部分
一、前置章节
1.配置linux
(1)问题:配置SSH免密登录,第二步在每一台机器都执行:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3若出现错误,需要将root用户登录后默认地址更改到有.ssh/的目录下
vim /etc/passwd
# 找到相应的用户,修改倒数第一个冒号前面的目录即可(例如:/home/fwx)注意:此时我配置的免密切换登录,用户是普通用户(fwx),不是老师视频中的root用户
(2)配置JDK环境
链接:https://pan.baidu.com/s/1S7ZSMENmpxAHyb729omVqQ?pwd=qxef
提取码:qxef
2.概念
(1)大数据特征:从海量的高增长,多类别,低信息密度的数据中挖掘出高质量的结果
(2)大数据的核心工作:
①数据存储:可以妥善存储海量待处理数据
②数据计算:可以从海量数据中计算出背后的价值
③数据传输:协助在各个环节中完成海量数据的传输
(3)大数据的软件生态:
①存储:HDFS,HBase,Kudu,云平台
②计算:MapReduce,Spark,Flink
③传输:Kafka,Pulsar,Flume,Sqoop
(4)Hadoop提供:分布式数据存储,分布式数据计算,分布式资源调度
(5)Hadoop三个功能组件:HDFS,MapReduce,YARN
二、分布式存储 HDFS
1.分布式的基础架构:服务器数量多,混乱
(1)分布式的调度主要有两类架构模式:
①去中心化模式:服务期之间基于特定规则进行同步协调
②中心化模式:主从模式(如hadoop)
2.HDFS组件:Hadoop分布式文件系统
(1)HDFS集群:
①主角色:NameNode(老大) node1
②从角色:DataNode(员工) node1/2/3
③主角色辅助角色:SecondaryNameNode(秘书) node1
(2)部署集群:
#1 上传Hadoop 安装包
#2 解压到/export/server
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
#3 构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4/ hadoop
#4 进入hadoop安装包
cd hadoop
①安装包目录结构:
bin:存放Hadoop各类程序(命令)
etc:存放Hadoop的配置文件
sbin:管理员程序
②修改配置文件:
workers:配置从节点(DataNode)
cd etc/hadoop
vim workers
# 填入如下内容
node1
node2
node3
hadoop-env.sh:配置Hadoop的相关环境变量
# 填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logscore-site.xml:Hadoop核心配置文件(xml:配置kv值)
# 在文件内部填入如下内容
# 第一个key:HDFS文件系统的网络通讯路径
# 第一个value:协议为hdfs:// namenode为node1 namenode的通讯端口为8020
# 第二个key:io操作文件缓冲区大小
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>hdfs-site.xml:HDFS核心配置文件
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name> # datanode的权限
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> # namenode的存储
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value> # namenode的主机
</property>
<property>
<name>dfs.blocksize</name> #块大小
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name> #并发数
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> #datanode的存储目录
<value>/data/dn</value>
</property>
</configuration>
以上文件在./hadoop/etc/hadoop目录下
③准备数据目录:
namenode数据存放node1的/data/nn
datanode数据存放node1、node2、node3的/data/dn
# node1节点:
mkdir -p /data/nn
mkdir /data/dn
# node2和node3节点:
mkdir -p /data/dn④分发Hadoop文件夹:
# 在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
⑤配置环境变量
# 三台同样配置
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin⑥授权为普通用户
chown -R 普通用户:普通用户组 /data
chown -R 普通用户:普通用户组 /export⑦格式化整个文件系统
# 格式化namenode
# 确保以hadoop用户执行
su - fwx
# 格式化namenode
hadoop namenode -format
#启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 若有‘命令未找到’的错误,表明环境变量没配置好,以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh(3)集群部署常见问题
①Permission denied:当前用户无权操作
除了视频中:/data和/export/server/hadoop-3.3.4中没权限,也要保证/home/fwx/.ssh中普通用户有权限
②command not found:没配置好环境变量
③启动集群后只有node1正常:workers文件没正确配置
start-dfs.sh-->启动SecondaryNameNode
start-dfs.sh--根据core-site.xml-->启动NameNode
start-dfs.sh--根据workers-->启动datanode(此步错误)
④未格式化:node1无NameNode,node2/3无反应
(4)查看HDFS WEBUI
3.HDFS的Shell操作
(1)进程启停管理
①一键启停脚本:
start-dfs.sh的执行原理:在此机器上启动SNN,读取core-sitexml,确认并启动
NameNode所在机器,读取workers,确定DataNode所在机器,启动全部DataNode
②当前机器进程启停:
hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
(2)文件系统操作命令
①HDFS文件系统路径:hdfs://node1:8020
linux路径:file://
②hdfs命令:hdfs dfs -命令
如:ls,mkdir,cat,cp,mv,chown
③上传/下载文件到HDFS指定目录下
hdfs dfs -put/get 本地文件 目标
可选项:-f:覆盖目标文件
-p:保留访问和修改时间,所有权和权限
④追加数据:本地 追加到 hdfs
hdfs dfs -appendToFile 本地文件 目标
若将`本地文件`换成`-`,则输入为从标准输入中读取
⑤rm(可选项:-skipTrash跳过回收站)
回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
# 回收站默认位置:/user/用户名/.Trash(3)HDFS客户端-Jetbrians产品插件
①Big Data Tools:方便操作HDFS
Ⅰ.pycharm下载此插件
Ⅱ.windows配置环境变量(推荐配置系统变量)---windows中的hadoop路径
Ⅲ.下载hadoop.dll与winutils.exe
Ⅳ.这俩放入$HADOOP_HOME/bin
Ⅴ.打开pycharm的此插件,点HDFS
第一种(自定义):uri填NNip地址,用户名fwx,测试连接
第二种(配置文件夹):路径填/hadoop/etc/hadoop,但需要像linux一样的配置文件
注意:避免虚拟机IP与云服务器IP相撞
(4)HDFS客户端-NFS(网络文件系统):NFS这个插件,可以对外提供NFS网关,
供其他系统挂载
①配置NFS
Ⅰ.在core-site.xml中新增(注意fwx)
# 允许hadoop用户代理任何其他用户组
<property>
<name>hadoop.proxyuser.fwx.groups</name>
<value>*</value>
</property>
# 允许代理任意服务器的请求
<property>
<name>hadoop.proxyuser.fwx.hosts</name>
<value>*</value>
</property>
Ⅱ.在hdfs-site.xml(注意fwx)
# NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户)
<property>
<name>nfs.superuser</name>
<value>fwx</value>
</property>
# NFS接受数据上传时使用的临时目录
<property>
<name>nfs.dump.dir</name>
<value>/tmp/.hdfs-nfs</value>
</property>
# NFS允许连接的客户端IP和权限,rw--读写,
<property>
<name>nfs.exports.allowed.hosts</name>
<value>192.168.88.1 rw</value> # 多个ip用`;`相隔
</property>Ⅲ.俩文件分发到node2和node3,重启集群
scp core-site.xml hdfs-site.xml node2:`pwd`/
scp core-site.xml hdfs-site.xml node3:`pwd`/Ⅳ.停止系统的NFS相关进程
systemctl stop nfs;systemctl disable nfs
yum remove -y rpcbindⅤ.启动portmap(HDFS自带的rpcbind功能)(root执行):hdfs --daemon start portmap
Ⅵ.启动nfs(HDFS自带的nfs功能)(hadoop执行):hdfs --daemon start nfs3
②验证NFS
在node2/node3执行:
Ⅰ.rpcinfo -p node1

Ⅱ.showmount -e node1
![]()
③在windows挂载HDFS文件系统
win11家庭版升级专业版激活码:J8WVF-9X3GM-4WVYC-VDHQG-42CXT
输入密钥后,打开powershell输入:irm massgrave.dev/get.ps1 | iex(没反应的科学上网)
选择1
Ⅰ.控制面板->程序->启动或关闭windows功能->勾上NFS->确定
Ⅱ.cmd->net use X: \\192.168.88.142\!(连接一个网络地址,挂载到X盘,NNip地址)
4.HDFS的存储原理
(1)修改副本数
①在hdfs-site.xml中设置文件上传到HDFS中拥有的副本数量(默认值3)
<property>
<name>dfs.replication</name>
<value>3</value>
</property>②修改已经存在的文件的副本数量
# 修改为两个副本存储 -R :对子目录生效
hdfs dfs -setrep [-R] 2 path
(2)fsck命令:检查文件的副本数
hdfs fsck path [-files [-blocks [-locations]]]
-files 可以列出路径内的文件状态
-files -blocks 有几个块,多少副本
-files -blocks -locations 输出每一个block详细(3)NameNode元数据
Ⅰ.NameNode基于多个edits和一个fsimage,完成整个文件系统的管理和维护
①edits(像log):流水账文件,记录hdfs每一次操作,以及影响的文件所对应的block
②fsimage文件:将全部的edits文件,合并的最终结果
Ⅱ.SecondaryNameNode的作用:合并元数据
(4)HDFS数据的读写流程
客户端找一个datanode就行,剩下的副本复制由datanode之间完成
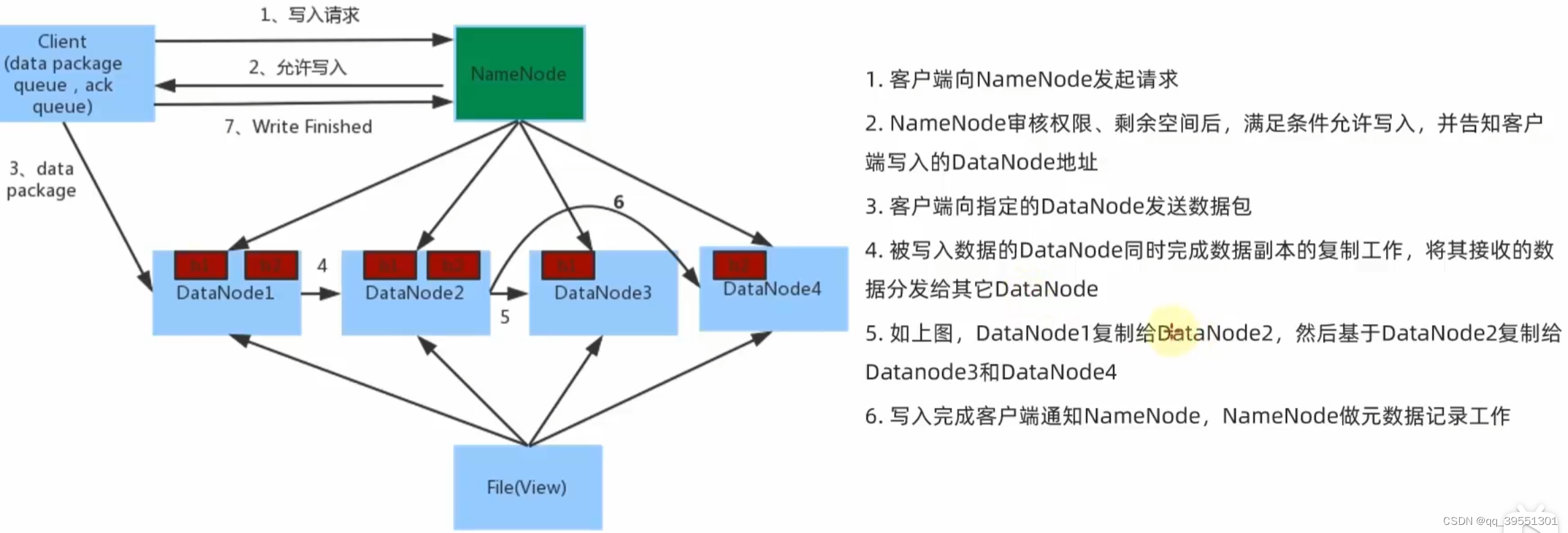
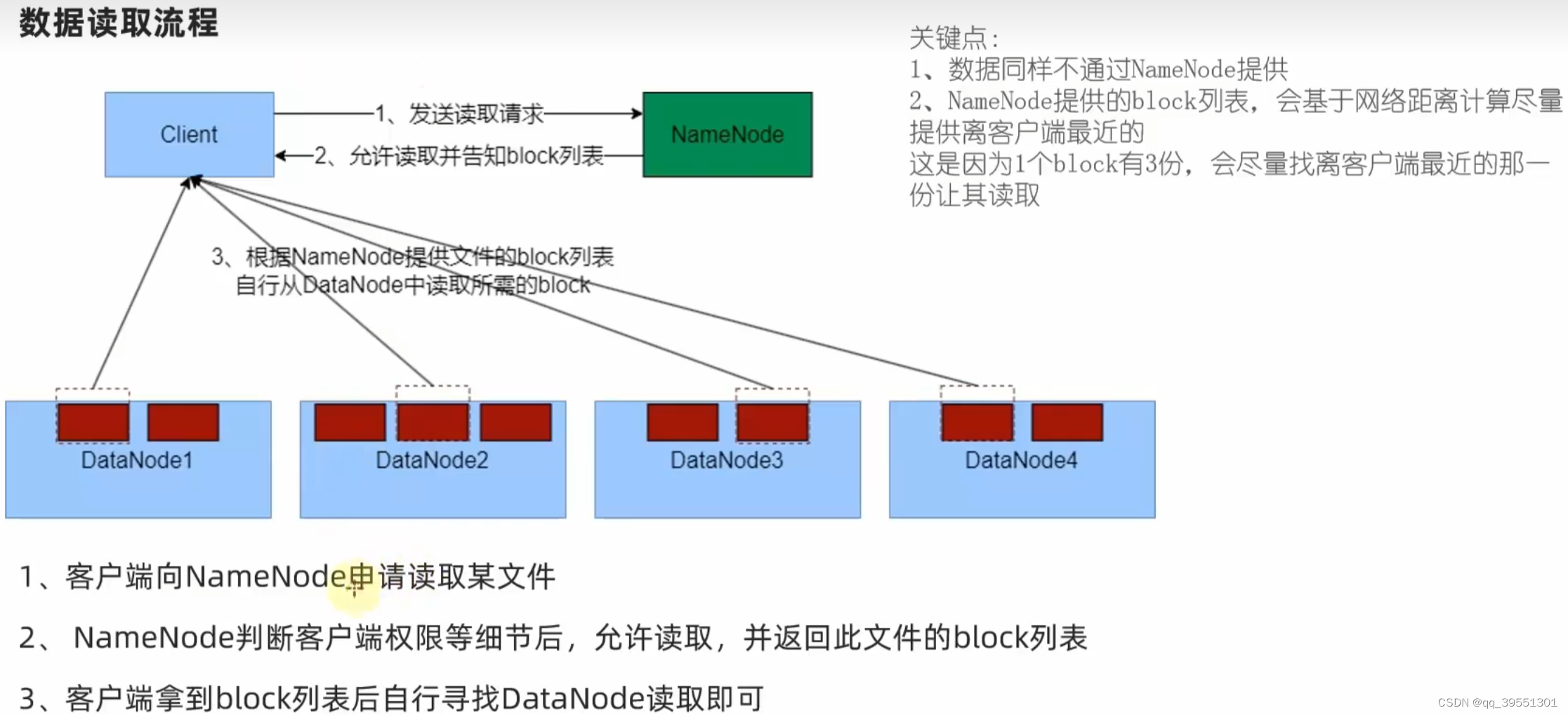
三、MapReduce & YARN入门
1.分布式计算常见的2种工作模式:
(1)分散->汇总(MapReduce)
(2)中心调度->步骤执行(Spark,Flink)
2.YARN:主从结构
(1)核心:
①主角色:ResourceManager--整个集群的资源调度者
②从角色:NodeManager--单个服务器的资源调度者
辅助:③代理服务器:YARN运行时会有个WEB UI,保障WEB UI访问的安全性
④历史服务器:记录历史程序运行信息和日志
(2)YARN的容器:在所属服务器上分配资源的手段,提前占资源
3.YARN集群部署
(1)配置文件
mapred-env.sh
mapred-site.xml
yarn-env.sh
yarn-site.xml
链接:https://pan.baidu.com/s/1yxiSWV96Dp92YZyn46gwgw?pwd=oqou
提取码:oqou
(2)分发配置文件
①scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
②scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
(3)集群启动命令
①一键启动YARN集群:start-yarn.sh
②一键停止YARN集群:stop-yarn.sh
③单台启动或停止:yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
④历史服务器启动和停止:mapred --daemon start|stop historyserver
(4)查看YARN的WEB UI页面
注意:整个快照
(5)提交MapReduce任务到YARN执行
内置的MapReduce程序:wordcount--单词计数程序 pi--求圆周率

①提交示例MapReduce程序WordCount到YARN中执行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1
参数wordcount,表示运行jar包中的单词计数程序(Java Class)
参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
参数2是结果输出路径(hdfs://node1:8020/output/wc1), 需要确保文件不存在
②提交求圆周率示例程序
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 3 1000参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
参数3,表示设置几个map任务
参数1000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)
四、分布式SQL计算--Hive入门
1.概念

(1)Hive:将sql语句翻译成MapReduce,Hive是单机工具,但是它可以提交给分布式运行的MapReduce程序运行。
(2)功能:①元数据管理(如存到mysql) ②解析器(sql到mapreduce)
(3)组件:
①元数据管理(Metastore 服务进程)
②SQL解析器(Driver驱动程序),完成SQL解析、执行优化、代码提交等功能
③用户接口:提供用户和Hive交互的功能

2.hive部署
链接:https://pan.baidu.com/s/10HN36zmlSJz6W0lFpQhG0A?pwd=vxkv
提取码:vxkv
(1) 安装mysql
①如果文件中降低密码复杂度不对
# 查看密码策略
show variables like '%validate_password%';
# 设置密码策略为低
set global validate_password.policy=LOW;
# 减少密码长度
set global validate_password.length=4;②卸载mysql
https://blog.csdn.net/best_luxi/article/details/107066029
(2)配置hadoop
配置core-site.xml(跟NFS一样)
(3)安装hive
下载:
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解压到node1服务器的:/export/server/内
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
# 设置软连接
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
(4)提供mysql驱动包
# 下载MySQL驱动包:
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
# 将下载好的驱动jar包,放入:Hive安装文件夹的lib目录内
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/(5)配置hive
# 在Hive的conf目录内,新建hive-env.sh文件,填入内容:
export HADOOP_HOME=/export/server/hadoop
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
# 在Hive的conf目录内,新建hive-site.xml文件,填入链接代码(6)初始化元数据库
# 新建数据库:hive
CREATE DATABASE hive CHARSET UTF8;
# 执行元数据库初始化
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
# 初始化后,会在MySQL的hive库中新建74张元数据管理的表。
(7)启动Hive
# fwx用户拥有权限
chown -R fwx:fwx hive
# 创建一个hive的日志文件夹:
mkdir /export/server/hive/logsps:不知道为什么,所有步骤都正确,但还是初始化元数据库错误,最后去某宝花钱配置的
3.Hive客户端
(1)HiveServer2 & Beeline
①HiveServer2服务:是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接
可以连接ThriftServer的客户端有:
Ⅰ.Hive内置的 beeline客户端工具(命令行工具)
Ⅱ.第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
# 启动元数据管理(metastore)服务
后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
# 启动hiveserver2服务
后台启动:nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &②Beeline客户端:是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信
# 使用beeline客户端
/export/server/hive/bin/beeline
# 访问hiveserver2协议(hive默认端口10000)
! connect jdbc:hive2://node1:10000
# 输入用户:fwx,密码为空如果connect错误,显示:No known driver to handle "jdbc:hive://node1:10000"
则需要看运行了几个RunJar,把多余的关掉重新开
如果再不行,就重启hdfs集群
五、BI:商业智能
1.FineBI:安装后->把hive连接驱动里的文件复制到Fine6.0\webapps\webroot\WEB-INF\lib(打好驱动)->在FineBI中选择“管理系统”->插件管理->从本地安装->找到fr-plugin-hive-driver-loader-3.0.zip资源包->hive隔离插件















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









