






Urllib
一、urllib的使用
#python自带的库
import urllib.request
if __name__ == '__main__':
# 1.流程
# (1)定义url
url = 'http://www.baidu.com'
# (2)摸底浏览器向服务器发送请求--响应
response=urllib.request.urlopen(url)
# (3)获取响应中的页面的源码--内容
# read方法 返回二进制数据
content=response.read().decode('utf-8')
# 2.1个类型,6个方法
# (1)类型:<class 'http.client.HTTPResponse'>
print(type(response))
# (2)read一个字节一个字节的读,返回5个字节
print(response.read(5))
# (3)读一行/读多行readlines
print(response.readline())
# (4)返回状态码:200--逻辑对
print(response.getcode())
# (5)返回url地址
print(response.geturl())
# (6)获取响应头信息
print(response.getheaders())
# 3.urllib_下载
# 注意:python中参数可以写:①k=v值②v值
# (1)url检索
# ①html
urllib.request.urlretrieve('http://www.baidu.com','baidu1.html')
# ②图片
urllib.request.urlretrieve('网址','xxx.jpg')
# ③视频
urllib.request.urlretrieve('网址','xxx.mp4')二、请求对象的定制
import urllib.request
if __name__ == '__main__':
url = 'https://www.baidu.com'
# 1.UA(User Agent),用户代理:使服务器能识别客户的各种信息
# (1)定制请求对象:解决反爬的第一种手段
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
# 因为urlopen方法不能存储字典 所有headers不能传递进去==>定制请求对象
# response= urllib.request.urlopen(url,headers)
request = urllib.request.Request(url=url,headers=headers)
# (2)打印源码
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
三、编解码
1.get请求方式
import urllib.parse
import urllib.request
if __name__ == '__main__':
#需求 获取周杰伦的网页源码
url = 'https://www.baidu.com/s?&wd=周杰伦'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
request = urllib.request.Request(url=url,headers=headers)
# 1.此时周杰伦三个字在ASCII表之外,所以需要变成unicode编码的格式==>我们需要依赖于urllib.parse
# (1)quote:转化单个参数
name=urllib.parse.quote("周杰伦")
# (2)urlencode:转换多个参数(&连接)
data={
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
a=urllib.parse.urlencode(data)
url="https://www.baidu.com/s?"
new_data=urllib.parse.urlencode(data)
url=url+new_data
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
2.post请求方式
import urllib.parse
import urllib.request
if __name__ == '__main__':
url='https://fanyi.baidu.com/sug'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
data={'kw':'spider'}
# post请求的参数 必须要进行编码
data= urllib.parse.urlencode(data).encode('utf-8')
# post请求的参数,是不会拼接在url的后面,而是需要放在请求对象定制的参数中
request=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf-8')
print(content)
# 此时content是str,转成json
import json
obj=json.loads(content)
print(obj)
# 总结:①post请求方式必须编码,编码之后必须
# ②参数是放在请求对象定制的方法中(date)3.总结:post和get区别?
①get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
②
post
请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用
encode
方法
四、ajax的get请求(ajax对应X-Requested-With:XMLHttpRequest)
import urllib.parse
import urllib.request
def create_request(page):
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action='
data={
'start':(page-1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url=url+data
print(url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('douban_'+str(page)+'.json', 'w',encoding='utf-8') as f:
f.write(content)
if __name__ == '__main__':
start_page=int(input("请输入起始的页码"))
end_page=int(input("请输入结束的页码"))
for page in range(start_page,end_page+1):
# 每一页都有定制的请求对象
request=create_request(page)
# 获取响应的数据
content=get_content(request)
# 下载
down_load(page,content)
五、URLError\HTTPError
1.HTTPError类是URLError类的子类
2.导入的包:import urllib.error
3.(1)HTTPError:服务器响应问题,urllib.error.HTTPError
(2)URLError:爬虫代码问题,urllib.error.URLError
六、cookie登录
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是爬取却是报错了-编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错
# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
# 下面信息在weibo.cn中,冒号开头的没啥用
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
##### cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
##### referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)七、Handler处理器
# 需求 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# (1)获取hanlder对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3) 调用open方法
# response = urllib.request.urlopen(request)
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)八、代理服务器
import urllib.request
# 代理池
proxies_pool = [
{'http':'118.24.219.151:16817'},
{'http':'118.24.219.151:16817'},
]
import random
proxies = random.choice(proxies_pool)
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
# handler build_opener open
# 准备 (1)获取hanlder对象
# proxy代理服务器
handler = urllib.request.ProxyHandler(proxies=proxies)
# 融入 (2)获取opener对象
opener = urllib.request.build_opener(handler)
# 请求 (3) 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)解析
一、xpath:解析.xml
# 安装
1.扩展程序
2.拖拽xpath.zip到浏览器中
# 使用
1.ctrl + shift + x:打开
2.摁住shift + 鼠标:选中
# 1.导包
from lxml import etree
# 2.xpath解析
# (1)本地文件 extree.parse
# (2)服务器响应文件 extree.HTML()
tree=etree.parse('test1.html')
# 3.查找所需数据
# tree.xpath('xpath路径')
li_list = tree.xpath('//ul/li[@id="l1"]/@class')[0]
# 判断列表的长度
print(li_list) # 地址
print(len(li_list)) # 个数
# 4.xpath查询
# ①路径查询
//:查找所有 子孙 节点
/ :只找 子 节点
li_list = tree.xpath('//body/ul/li')
# ②谓词查询
div[@id]
div[@id="maincontent"]
# a.查找所有有id的属性的li标签
# text()获取标签中的内容
li_list = tree.xpath('//ul/li[@id]/text()')
# b.查找id为l1的li标签(注意引号的问题)
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# c.查找id有哪些
li_list = tree.xpath('//ul/li/@id')
# ③属性查询
@class
# ④模糊查询
div[contains(@id, "he")]
div[starts‐with(@id, "he")]
# 包括有i的,不是只有i的
li_list=tree.xpath('//ul/li[contains(@id,"i")]')# urllib.request.urlretrieve('图片地址','文件的名字').
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')二、JsonPath:解析.json
# 安装
pip install jsonpath
# jsonpath的使用:
obj = json.load(open('json文件', 'r', encoding='utf‐8'))
result = jsonpath.jsonpath(obj, '筛选条件(链接最后的表格)')
# 导包
import jsonpath
import json
# 所有的作者
author_list=jsonpath.jsonpath(obj,'$.store..price')
print(author_list)
直接看最后一个表格
Selenium
一、Selenium:帮你反爬,模拟正常用户
# 1.下载浏览器驱动
# 2.下载包
pip install selenium
from selenium.webdriver.edge.service import Service
from selenium import webdriver
# 加载浏览器驱动
s = Service("msedgedriver.exe")
# 创建一个浏览器(初始化)
browser = webdriver.Edge(service=s)
# 最大化窗口
browser.maximize_window()
# 得到网址
browser.get("https://www.baidu.com")
# 获取源码
source=browser.page_source
print(source)1.元素定位
# 导入By类,用于指定元素定位方式
from selenium.webdriver.common.by import By
# 常用三种,其他搜
browser.find_element(By.ID,value=" ") #id
browser.find_element(By.NAME,value=" ") #name
browser.find_element(By.XPATH,value=" ") # xpath2.自动化交互
# 打印网页标题
driver.title
# 关闭浏览器
driver.quit()
# 搭配定位元素,输入文本框
# 找到文本框位置
input_box = driver.find_element(By.ID, '')
# 输入信息
input_box.send_keys('Hello, Selenium!')
# 找到提交按钮位置
button = driver.find_element(By.ID, ' ')
# 提交按钮
button.click()二、handless
# 1.为了加载浏览器驱动
from selenium.webdriver.edge.service import Service
from selenium import webdriver
# 2.为了headless,无头模式:后台运行服务器
from selenium.webdriver.edge.options import Options
# 1.加载浏览器驱动
s = Service("msedgedriver.exe")
# 2.headless模式
edge_options = Options()
edge_options.add_argument('--headless')
# 创建一个浏览器
driver = webdriver.Edge(options=edge_options,service=s)
# 得到网址
driver.get("https://www.baidu.com")
driver.page_source
print(driver.page_source)requests
一、基本使用
pip install requests
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
data = {
'wd':'北京'
}
# get请求
response = requests.get(url,params=data,headers=headers)
# post请求
r = requests.post(url = post_url,headers=headers,data=data)
# 代理
proxy={'http':'ip地址:端口号'}
response = requests.get(url=url,params=data,headers=headers,proxies=proxy)1.定制参数
①参数使用
params
传递
②参数无需
urlencode
编码
③不需要请求对象的定制
④请求资源路径中?可加可不加
2.response的属性以及类型
类型 :
models.Response
r.text :
获取源码
r.encoding
:访问或定制编码方式
r.url
:获取请求的
url
r.content
:响应的字节类型
r.status_code
:响应的状态码
r.headers
:响应的头信息
3.cookie
## 难点
# (1) 隐藏域
# (2) 验证码
# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# _VIEWSTATE: /m1O5dxmOo7f1qlmvtnyNyhhaUrWNVTs3TMKIsm1lvpIgs0WWWUCQHl5iMrvLlwnsqLUN6Wh1aNpitc4WnOt0So3k6UYdFyqCPI6jWSvC8yBA1Q39I7uuR4NjGo=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: 595165358@qq.com
# pwd: action
# code: PId7
# denglu: 登录
# 1.我们观察到_VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量
# 难点:(1)_VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码
# 获取_VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 有坑:获取验证码图片后,会刷新验证码,在提交请求后,验证码不正确
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# requests里面有一个方法 session() 通过session的返回值 就能使用请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)scrapy
一、scrapy
# 1.创建scrapy项目
scrapy startproject 项目名称
# 项目组成:
spiders
__init__.py
自定义的爬虫文件.py ‐‐‐》由我们自己创建,是实现爬虫核心功能的文件
__init__.py
items.py ‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares.py ‐‐‐》中间件 代理
pipelines.py ‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理
默认是300优先级,值越小优先级越高(1‐1000)
settings.py ‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等
# 2.创建爬虫文件:要在spiders文件中去创建爬虫文件
cd 项目名/项目名/spiders
# scrapy genspider 爬虫文件的名字 要爬取网页
scrapy genspider baidu http://www.baidu.com
# 如果请求接口是html为结尾的,那么不需要加/的
allowed_domains ‐‐》 爬虫允许的域名,在爬取时候,如果不是此域名之下的url,会被过滤掉
start_urls ‐‐》 声明了爬虫的起始地址,可以写多个url,一般是一个
parse(self, response) ‐‐》解析数据的回调函数
response.text ‐‐》源码-字符串
response.body ‐‐》二进制文件
response.xpath()‐》xpath方法的返回值类型是selector列表
extract() ‐‐》提取的是selector对象的是data
extract_first() ‐‐》提取的是selector列表中的第一个数据
# 3.运行爬虫文件
scrapy crawl 爬虫名称 scrapy工作原理 (重点)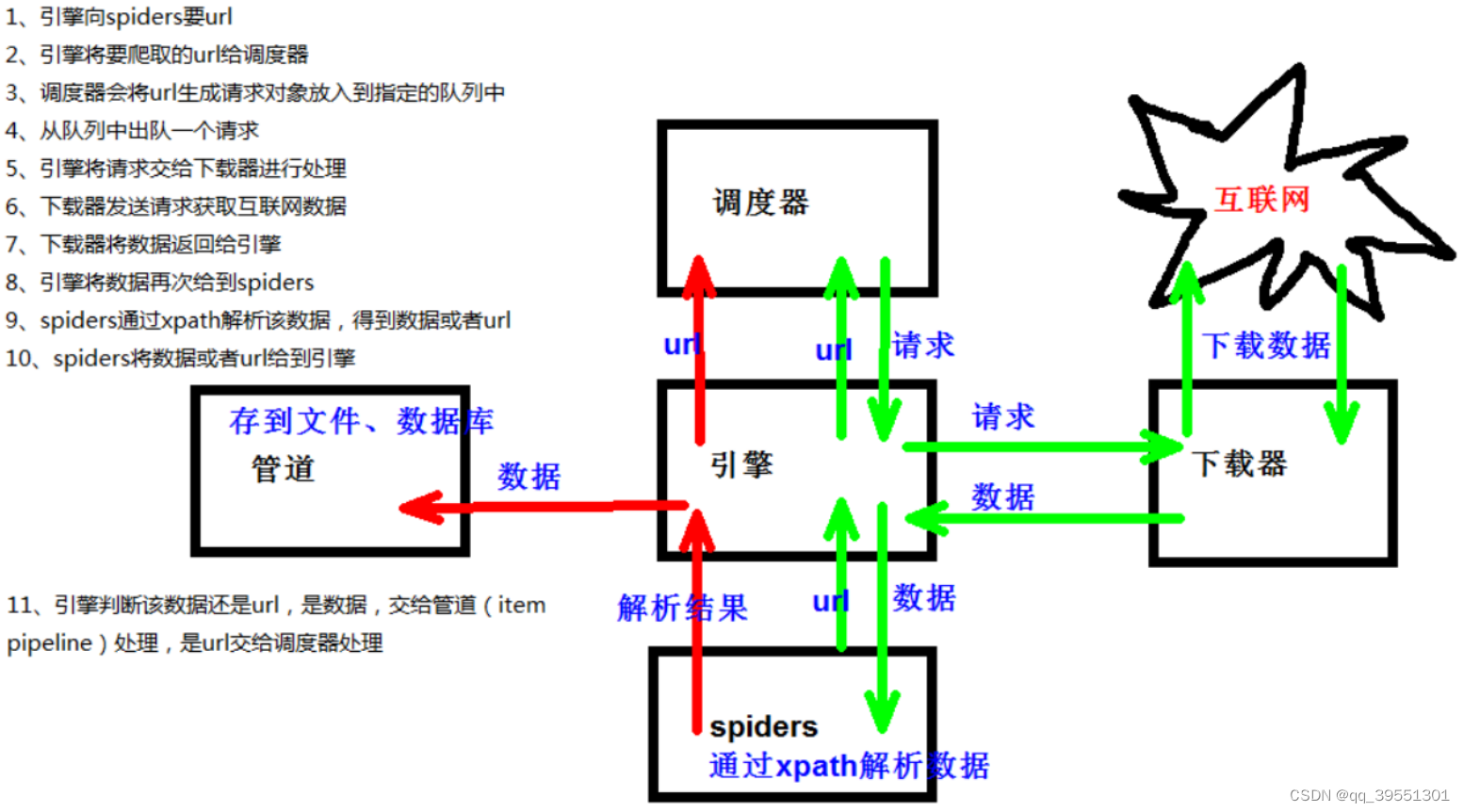
二、scrapy shell
# 进入到scrapy shell的终端 直接在window的终端中输入scrapy shell 域名
# 如果想看到一些高亮 或者 自动补全 那么可以安装ipython # pip install ipython
scrapy shell www.baidu.com
# 之后,进入ipython模式三、yield
1. 函数内部:
带有
yield
的函数不再是一个普通函数,而是一个生成器
generator
,可用于迭代
2.
生成器是实现了迭代器协议的一种特殊迭代器。生成器通过
yield关键字在函数中
暂停执行(yield类似return,但是实现卡住程序和执行当前位置后一行),并在每次迭代时恢复执行,直到遇到下一个yield语句或者函数结束
# items.py文件下
# 通俗的说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()# dangdang.py文件
import scrapy
from scrapy_dangdang_001.items import ScrapyDangdang001Item
class DangdangSpider(scrapy.Spider):
name = "dangdang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["https://category.dangdang.com/cp01.54.26.00.00.00.html"]
base_url = "https://category.dangdang.com/pg1"
page=1
def parse(self, response):
# pipelines 下载数据
# items 定义数据结构的
# src = //ul[@id="component_59"]/li//img/@src
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# 所有的seletor(选择器)的对象 都可以再次调用xpath方法
li_list=response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
# 图片会有懒加载的可能:懒加载就是你页面没滑到图片那里,他是不会加载的,但是那时候的图片地址是错误的
# @data-original解决懒加载
# 但是注意第一张照片比较特殊,可能本来就是加载好的
src = li.xpath('.//img/@data-original').extract_first()
if src:
src=src
else:
src=li.xpath('.//img/@src').extract_first()
name=li.xpath('.//img/@alt').extract_first()
price=li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book=ScrapyDangdang001Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
if self.page<100:
self.page+=1
url=self.base_url+str(self.page)+'-cp01.54.26.00.00.00.html'
# 怎么调用parse方法呢
# scrapy.Request 就是 scrapy的get请求
# url是请求地址,callback是要执行的函数
yield scrapy.Request(url=url, callback=self.parse)# pipelines.py文件
# 1.如果想使用管道的话,那么就必须在settings中开启管道 # ITEM_PIPELINES
# ITEM_PIPELINES的V值是优先级,越小优先级越高
class ScrapyDangdang001Pipeline:
# 2.open_spider和close_spider这两个函数是内置的,代表爬虫文件开始之前执行(1次)/结束之后(1次)
def open_spider(self, spider):
self.f=open('book.json','w',encoding='utf-8')
# 1.item就是yield的book对象
def process_item(self, item, spider):
# 1.以下模式不推荐,因为io操作频繁
# # (1) write方法必须要写一个字符串,而不能是其他的对象==》需要强转
# # (2) w 会覆盖==》所以选择a
#
# with open('book.json', 'a',encoding='utf-8')as f:
# f.write(str(item))
self.f.write(str(item))
return item
def close_spider(self, spider):
self.f.close()
import urllib.request
# 3.多条管道同时开启
# (1) 定义管道类
# (2) 在settings中开启管道
# 说明:上面那条管道是为了下载json数据,下面这条管道是为了下载图片数据。当yield数据过来时,两条管道都会运行
class Dangdang001Pipeline:
def process_item(self, item, spider):
url = 'http:'+item.get("src")
filename = './books/'+item.get("name")+'.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item# settings.py文件
ITEM_PIPELINES = {
"scrapy_dangdang_001.pipelines.ScrapyDangdang001Pipeline": 300,
"scrapy_dangdang_001.pipelines.Dangdang001Pipeline" : 301
}四、CrawlSpider:scrapy.spiders的派生类
如果有需要跟进链接的需求,就是爬取了网页之后,需要提取链接再次爬取,使用
CrawlSpider
1.创建项目:scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类:scrapy genspider ‐t crawl read www.dushu.com
4.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
# (1)正则表达式 提取符合正则的链接
allow = (),
# (2)xpath,提取符合xpath规则的链接
restrict_xpaths = ())
# (1)正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
# (2)xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
5.提取连接
link.extract_links(response)
6.注意事项
【注1】callback只能写函数名字符串, callback='parse_item'
【注2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item 【注‐
‐稍后看】follow=true 是否跟进 就是按照提取连接规则进行提取
运行原理:
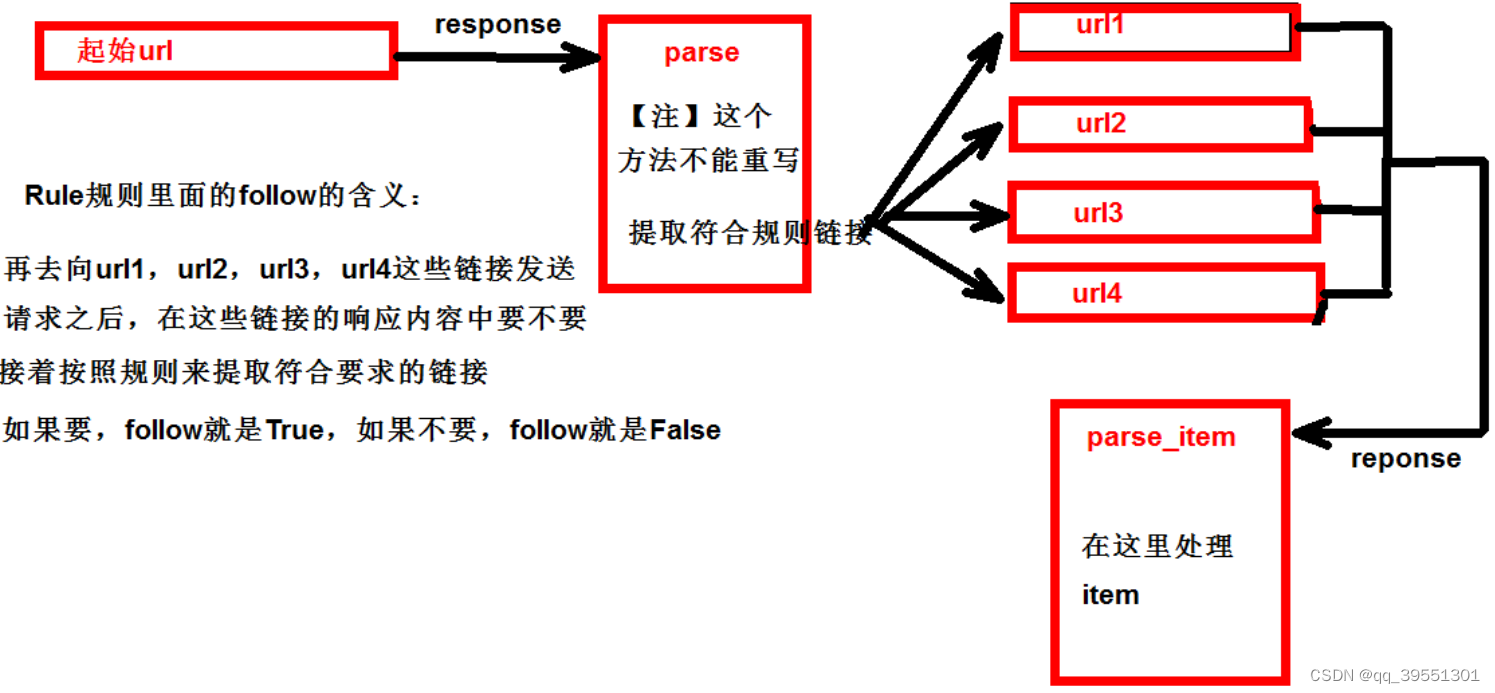
数据入库
(1)settings配置参数:
DB_HOST = '192.168.231.128'
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWORD = '1234'
DB_NAME = 'test'
DB_CHARSET = 'utf8'
(2)管道配置
# 固定的
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline(object):
#__init__方法和open_spider的作用是一样的
#init是获取settings中的连接参数
def __init__(self):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.pwd = settings['DB_PWD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
# 连接数据库并且获取cursor对象
def connect(self):
self.conn = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
password=self.pwd,
db=self.name,
charset=self.charset)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(image_url, book_name, author, info) values("%s",
"%s", "%s", "%s")' % (item['image_url'], item['book_name'], item['author'],
item['info'])
sql = 'insert into book(image_url,book_name,author,info) values
("{}","{}","{}","{}")'.format(item['image_url'], item['book_name'],
item['author'],item['info'])
# 执行sql语句
self.cursor.execute(sql)
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
self.cursor.close()五、日志信息和日志等级
(1)日志级别:
CRITICAL:严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息(默认)
(2)settings.py文件设置:
LOG_FILE : 将屏幕显示的信息全部记录到文件中。文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级六、scrapy的post请求
(1)重写start_requests方法:
def start_requests(self)
(2) start_requests的返回值:
scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data)
url: 要发送的post地址
headers:可以定制头信息
callback: 回调函数
formdata: post所携带的数据,这是一个字典七、代理
(1)到settings.py中,打开一个选项
DOWNLOADER_MIDDLEWARES = {
'postproject.middlewares.Proxy': 543,
}
(2)到middlewares.py中写代码
def process_request(self, request, spider):
request.meta['proxy'] = 'https://113.68.202.10:9999'
return None














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









