







CSDN源码下载:MapReduce实现二度好友推荐算法
一、Hadoop安装
可参考文章:Win10下安装Hadoop2.7.3
二、问题描述
好友推荐功能简单的说是这样一个需求:
预测某两个人是否认识,并推荐为好友,并且某两个非好友的用户,他们的共同好友越多,那么他们越可能认识。
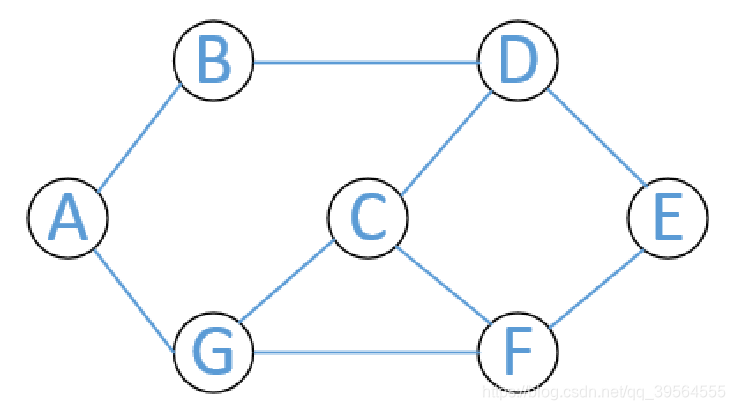
以QQ好友举例,顶点A、B、C到G分别是QQ用户,两顶点之间的边表示两顶点代表的用户之间相互关注。比如,B、G有共同好友A,应该推荐B、G认识,而D、F有两个共同好友C、E,那么更加应该推荐D、F认识。
三、思路分析
- 推荐者与被推荐者一定有一个或多个相同的好友
- 全局去寻找好友列表中两两关系
- 去除直接好友
- 统计两两关系出现次数
四、步骤讲解
- 导入数据

- 第一次Map,映射<(好友,好友), 0/1>键值对
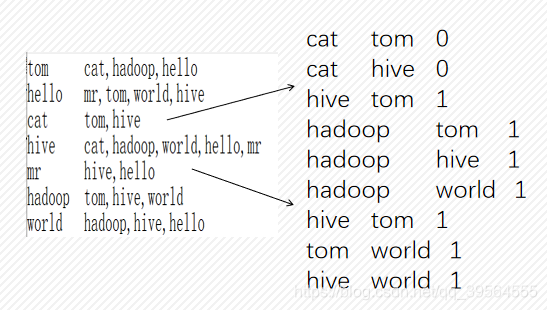
- 第一次Reduce,统计共同好友个数,去掉直接好友

- 第一次进行job运算

- 第二次Map,映射<(用户,hot值),好友:hot值>
由于在MapReduce中,key值自动能够排序,而value值往往不可以。所以为了根据每一个用户与其他用户的共同好友个数从高到低排序,不仅需要将用户名作为key,还需要将该用户与推介用户的共同好友个数作为key的一部分。 - 第二次Reduce,对结果进行排序拼接处理
hello:2,hadoop:2,mr:1,world:1, - 第二次Job运算,得到结果

五、代码
- 输入数据friends_demo.txt(用户 直接好友)
tom cat,hadoop,hello
hello mr,tom,world,hive
cat tom,hiv
hive cat,hadoop,world,hello,mr
mr hive,hello
hadoop tom,hive,world
world hadoop,hive,hello
- 类型定义
由于A1:A2与A2:A1是同一个潜在好友列表,为了能够方便的统计,故统一按照字典排序,输出A1:A2格式。
package friends_7_demo2;
import org.apache.hadoop.io.Text;
public class FoF extends Text {
public FoF() {
super();
}
public FoF(String friend01,String friend02) {
set(getof(friend01,friend02));
}
private String getof(String friend01, String friend02) {
int c = friend01.compareTo(friend02);
if (c>0) {
return friend02+"\t"+friend01;
}
return friend01+"\t"+friend02;
}
}
- 定义Map01
package friends_7_demo2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* map函数,统计好友之间的FOF关系列表(FOF关系:潜在好友关系)
*/
public class Map01 extends Mapper<LongWritable, Text, FoF, IntWritable> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String lines = value.toString(); // 用户所有的好友列表
String userAndFriends[] = StringUtils.split(lines, '\t');
String user = userAndFriends[0];
String[] friends;
if(userAndFriends.length == 1){
return;
}else if (userAndFriends[1].length() == 1){
friends = new String[]{userAndFriends[1]};
}else {
friends= userAndFriends[1].split(",");
}
//好友之间的FOF关系矩阵
for (int i = 0; i < friends.length; i++) {
String friend = friends[i];
context.write(new FoF(user,friend),new IntWritable(0));//输出好友列表,值为0。方便在reduce阶段去除已经是好友的FOF关系。
for (int j = i+1; j < friends.length; j++) {
String friend2 = friends[j];
context.write(new FoF(friend, friend2), new IntWritable(1));//输出好友之间的FOF关系列表,值为1,方便reduce阶段累加
}
}
}
}
- 定义Reduce01
package friends_7_demo2;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* reduce函数,统计全部的FOF关系列表的系数
*/
public class Reduce01 extends Reducer<FoF, IntWritable, Text, NullWritable> {
@Override
protected void reduce(FoF key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
boolean f = true;
for(IntWritable i : values){
if (0==i.get()) { //已经是好友关系
f=false;
break;
}
sum+=i.get(); //累计,统计FOF的系数
}
System.out.println("******************Reduce01*******************");
if (f) {
String msg = StringUtils.split(key.toString(), '\t')[0]+" "+StringUtils.split(key.toString(), '\t')[1]+" "+sum;
System.out.println(msg);
context.write(new Text(msg), NullWritable.get()); //输出key为潜在好友对,值为出现的次数
}
}
}
- 定义JobFriends类,实现jobOne
package friends_7_demo2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobFriends {
public static void main(String[] args) {
Boolean flag = jobOne();
if (flag) {
jobTwo();
}
}
// MapReduce01
private static Boolean jobOne() {
Configuration config = new Configuration();
boolean flag = false;
try{
Job job = Job.getInstance(config);
job.setJarByClass(JobFriends.class);
job.setJobName("fof one job");
job.setMapperClass(Map01.class);
job.setReducerClass(Reduce01.class);
job.setOutputKeyClass(FoF.class);
job.setOutputValueClass(IntWritable.class);
Path input = new Path("……\\input\\friends_7.txt");
FileInputFormat.addInputPath(job, input);
Path output = new Path("……\\output\\friends_7\\f1");
//如果文件存在,,删除文件,方便后续调试代码
if (output.getFileSystem(config).exists(output)) {
output.getFileSystem(config).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
flag = job.waitForCompletion(true);
if (flag) {
System.out.println("job1 success...");
}
} catch(Exception e){
e.printStackTrace();
}
return flag;
}
}
输出结果:
cat hadoop 2
cat hello 2
cat mr 1
cat world 1
hadoop hello 3
hadoop mr 1
hive tom 3
mr tom 1
mr world 2
tom world 2
- 好友推荐计算,类型定义
由于在MapReduce中,key值自动能够排序,而value值往往不可以。所以为了根据每一个用户与其他用户的共同好友个数从高到低排序,不仅需要将用户名作为key,还需要将该用户与推介用户的共同好友个数作为key的一部分,所以需要重新定义一个类。
package friends_7_demo2;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* FriendSort作为key和value,FriendSort:用户名+FOF系数
* 用户名一致,FOF系数从大到小排序。 很容易得到一个用户的好友推介的列表
*/
public class FriendSort implements WritableComparable<FriendSort> {
private String friend;
private int hot;
public String getFriend() {
return friend;
}
public void setFriend(String friend) {
this.friend = friend;
}
public int getHot() {
return hot;
}
public void setHot(int hot) {
this.hot = hot;
}
public FriendSort() {
super();
}
public FriendSort(String friend, int hot) {
this.friend = friend;
this.hot = hot;
}
//反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.friend=in.readUTF();
this.hot=in.readInt();
}
//序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(friend);
out.writeInt(hot);
}
//判断是否为同一用户,并通过hot值排序
@Override
public int compareTo(FriendSort newFriend) {
System.out.println(friend+"-------"+newFriend.getFriend());
int c = friend.compareTo(newFriend.getFriend());
int e = -Integer.compare(hot, newFriend.getHot());
if (c==0) {
return e;
}
return c;
}
}
- 定义Map02
package friends_7_demo2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
/**
* map函数,每个用户的推介好友列表,并按推介指数从大到小排序
*/
public class Map02 extends Mapper<LongWritable, Text, FriendSort, Text > {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String lines = value.toString();
String friend01 = StringUtils.split(lines,' ')[0];
String friend02 = StringUtils.split(lines,' ')[1]; //推介的好友
int hot = Integer.parseInt(StringUtils.split(lines,' ')[2]); // 该推介好友的推介系数
System.out.println("**************Map02******************");
System.out.println(friend01+" "+friend02+" "+hot);
System.out.println(friend02+" "+friend01+" "+hot);
context.write(new FriendSort(friend01,hot),new Text(friend02+":"+hot)); //mapkey输出用户和好友推介系数
context.write(new FriendSort(friend02,hot),new Text(friend01+":"+hot)); //好友关系是相互的
}
}
- 定义sort类
package friends_7_demo2;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* 将key根据用户名和次数排序
*/
public class NumSort extends WritableComparator {
public NumSort(){
super(FriendSort.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
FriendSort o1 =(FriendSort) a;
FriendSort o2 =(FriendSort) b;
int r =o1.getFriend().compareTo(o2.getFriend());
if(r==0){
return -Integer.compare(o1.getHot(), o2.getHot());
}
return r;
}
}
- 定义group类
package friends_7_demo2;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* 将同一个用户作为一个Group,同时被reduce处理
*/
public class UserGroup extends WritableComparator {
public UserGroup(){
super(FriendSort.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {
FriendSort o1 =(FriendSort) a;
FriendSort o2 =(FriendSort) b;
return o1.getFriend().compareTo(o2.getFriend());
}
}
- 定义Reduce02
package friends_7_demo2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* reduce函数
*/
public class Reduce02 extends Reducer<FriendSort, Text, Text, Text> {
@Override
protected void reduce(FriendSort user, Iterable<Text> friends, Context context)
throws IOException, InterruptedException {
String msg = "";
//拼接推荐好友
for(Text friend :friends){
System.out.println("***************Reduce02*****************");
msg += friend.toString()+",";
System.out.println(msg);
}
context.write(new Text(user.getFriend()), new Text(msg));
}
}
- 定义 JobTwo 类
package friends_7_demo2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobFriends {
public static void main(String[] args) {
Boolean flag = jobOne();
if (flag) {
jobTwo();
}
}
// MapReduce01
private static Boolean jobOne() {
Configuration config = new Configuration();
boolean flag = false;
try{
Job job = Job.getInstance(config);
job.setJarByClass(JobFriends.class);
job.setJobName("fof one job");
job.setMapperClass(Map01.class);
job.setReducerClass(Reduce01.class);
job.setOutputKeyClass(FoF.class);
job.setOutputValueClass(IntWritable.class);
Path input = new Path("……\\input\\friends_7.txt");
FileInputFormat.addInputPath(job, input);
Path output = new Path("……\\output\\friends_7\\f1");
//如果文件存在,,删除文件,方便后续调试代码
if (output.getFileSystem(config).exists(output)) {
output.getFileSystem(config).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
flag = job.waitForCompletion(true);
if (flag) {
System.out.println("job1 success...");
}
} catch(Exception e){
e.printStackTrace();
}
return flag;
}
private static Boolean jobTwo() {
Configuration config =new Configuration();
Boolean flag = false;
try {
Job job = Job.getInstance(config);
job.setJarByClass(JobFriends.class);
job.setJobName("fof two job");
job.setMapperClass(Map02.class);
job.setReducerClass(Reduce02.class);
job.setSortComparatorClass(NumSort.class); //sort类
job.setGroupingComparatorClass(UserGroup.class); //group类
job.setMapOutputKeyClass(FriendSort.class);
job.setMapOutputValueClass(Text.class);
Path input = new Path("……\\output\\friends_7\\f1");
FileInputFormat.addInputPath(job, input);
Path output = new Path("……\\output\\friends_7\\f2");
//如果文件存在,,删除文件,方便后续调试代码
if (output.getFileSystem(config).exists(output)) {
output.getFileSystem(config).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
flag = job.waitForCompletion(true);
if (flag) {
System.out.println("job2 success...");
}
} catch (Exception e) {
e.printStackTrace();
};
return flag;
}
}
输出最终结果:
cat hello:2,hadoop:2,mr:1,world:1,
hadoop hello:3,cat:2,mr:1,
hello hadoop:3,cat:2,
hive tom:3,
mr world:2,hadoop:1,tom:1,cat:1,
tom hive:3,world:2,mr:1,
world mr:2,tom:2,cat:1,
参考文章:【1】MapReduce实例——好友推荐 - sinat_34045444的博客
【2】hadoop学习笔记–8.MapReduce案例一:简单好友推介实现 - 云计算技术频道 - 红黑联盟
【3】mapreduce实现——腾讯大数据QQ共同好友推荐系统_码神岛
【4】MR — 好友推荐算法 - ImCoder博客’s 文章
【5】Hadoop实例:二度人脉与好友推荐 - 程序园
【6】推荐算法之好友推荐 - - ITeye博客
【7】Hadoop实例:二度人脉与好友推荐 - intergret的个人空间 - OSCHINA
【8】MapReduce 社交好友推荐算法 - 夏延 - 博客园
【9】MapReduce模拟小型推荐系统 - ThisisWilli - CSDN博客
【10】MapReduce模拟实现好友推荐系统 - 张不帅 - CSDN博客














 1702
1702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









