







DMP说明:
DMP(Data Management Platform)数据管理平台,是把分散的多方数据进行整合纳入统一的技术平台,并对这些数据进行标准化和细分,让用户可以把这些细分结果推向现有的互动营销环境里的平台。
1.项目背景
互联网广告(本项目针对手机,OTT,PC)的崛起得益于信息技术的发展和普及,智能的终端设备迅猛的发展。
互联网广告的优势:
1)受众多 10亿+网民
2)可以跟踪用户的行为,进而可以做精准营销
2.dsp流程
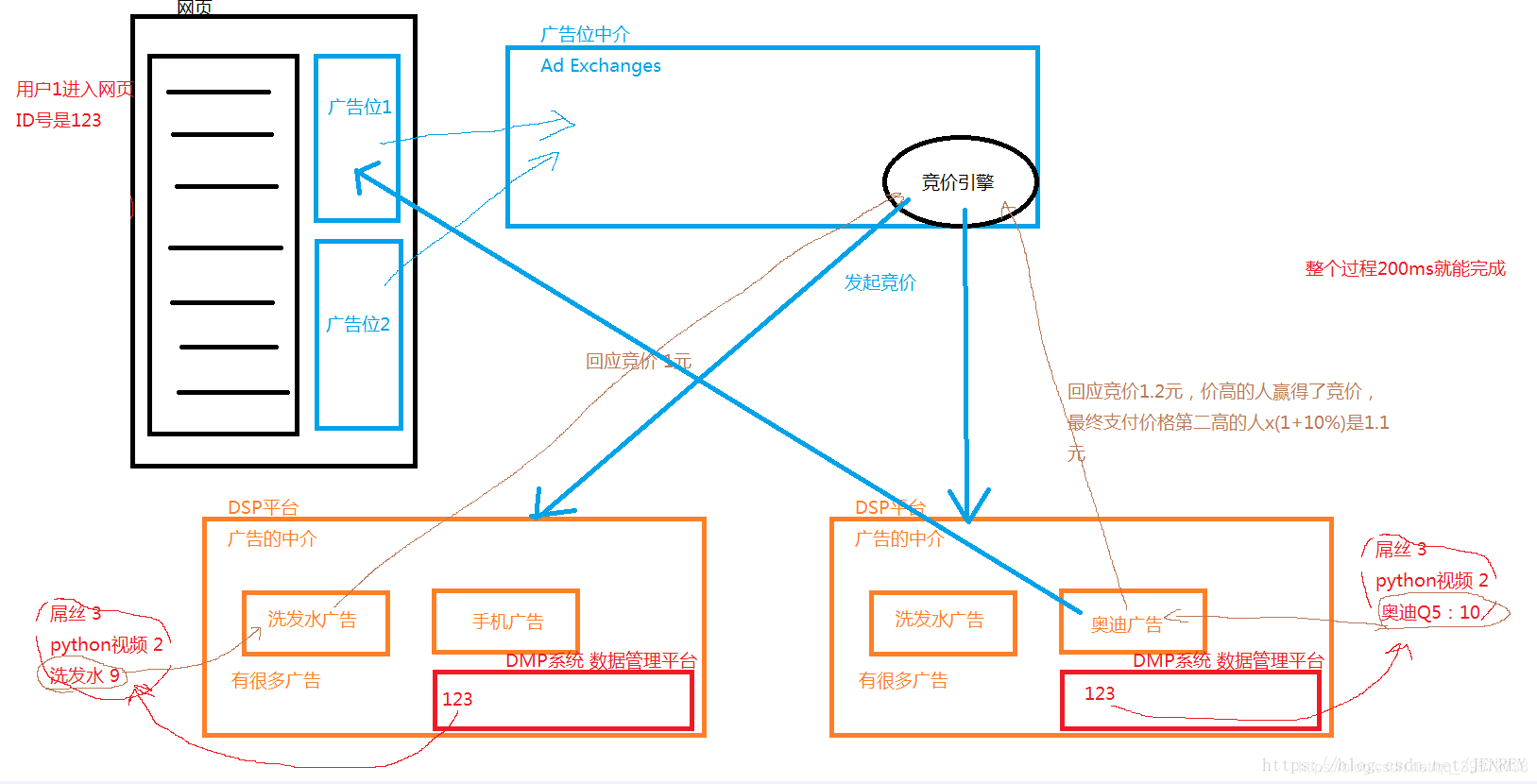
如果用户是第一次进来,在DMP中没有信息,有默认的广告投放公司,比如可口可乐会去投(追求曝光率)
DSP主要是有两个属性,1就是广告,2就是DMP系统,里面有我们用户的信息(比如关注的物品的权重)
3.项目开发部分
项目开展之前进行一下操作,成为项目准备阶段
1)需求分析
这里简单的说几句,因为涉及到公司机密和技术要点,不便于详细说明,望理解。
dmp项目就是用来支撑精准广告投放的,主要是用用户画像,根据埋点采集的数据,进行ETL处理,然后进行数据分析,抽象出来一些标签,再根据用户行为数据,从不同维度数据的权重,给用户打上标签,实现广告精准投放。
2)技术架构
详细的请看下图:
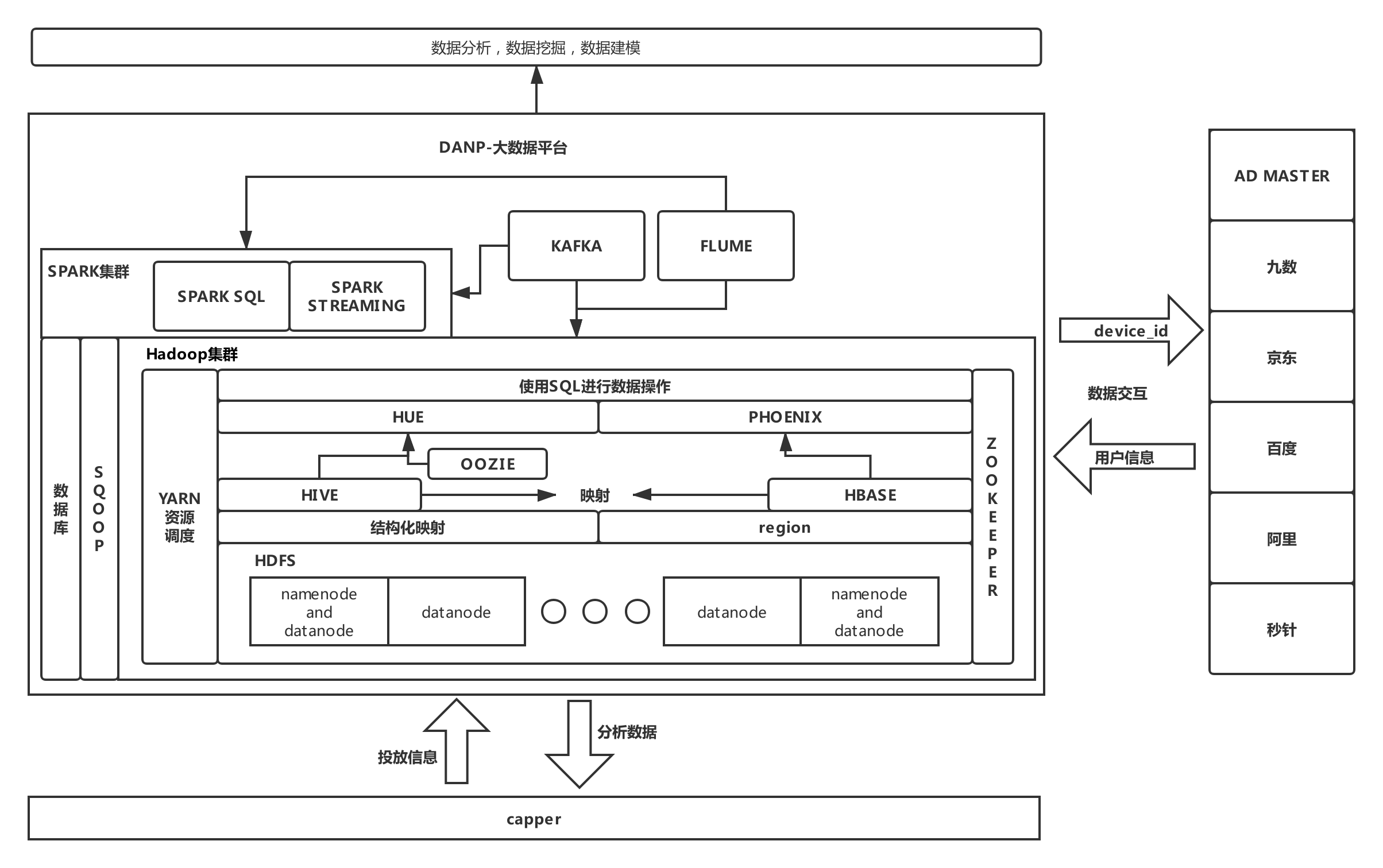
3)技术选型
CDH5.16.1(hadoop2.6.x,hbase等)
Spark2.3(sparksql,sparkstreaming)
Java1.8
Scala2.11.8
kafka10.1
这里贴出几种类型数据展示一下:
1>.行为数据
0bb49045000057eee4ed3a580019ca06,0,0,0,100002,未知,26C7B9C83DB4B6197CEB80D53B3F5DA,1,1,0,0,2016-10-0106:19:17,139.227.161.115,com.apptreehot.horse,马上赚,AQ+KIQeBhehxf6xf98BFFnl+CV00p,A10%E55F%BC%E6%AO%B%,1,4.1.1,760,980,上海市,上海市,4,3,Wifi,0,0,2,插屏,1,2,6,未知,1,0,0,0,0,0,0,0,0,555,240,290,AQ+KIQeBhexf6x988FFnl+CVOOp,1,0,0,0,0,0,mm_26632353_8068780_27326559,2016-10-01 06:19:17,
2>.dmp检测数据
2019-08-15 00:07:35 {dmp:admaster;deviceid:DEVICE_948134c7097826d47ac1680388ef1811;adxtype:39;ip:112.23.190.244;dealid:d700cb8047d96660eef5dba91054f81f;4|1121394:1;4|1121393:0;}
3>.投放日志数据(默认分隔符"\001")
dsp_imp_uv_table.ip221.15.29.238
dsp_imp_uv_table.request_typeGET
dsp_imp_uv_table.url_hostdspo.htm
dsp_imp_uv_table.media_id17
dsp_imp_uv_table.creative_id2050317000
dsp_imp_uv_table.device_idDEVICE_b2f945a1ea91809b4832d8b160d01bd8
dsp_imp_uv_table.ts1551369958
dsp_imp_uv_table.str1-
dsp_imp_uv_table.str2-
dsp_imp_uv_table.uaCupid/3.0;NetType/unknown
dsp_imp_uv_table.str3-
dsp_imp_uv_table.http_type200
dsp_imp_uv_table.date_id20190301
以上为三种数据格式。
所以第一步要考虑数据存储问题,这里还考虑到以后要进行数据分析,数据量大(每天近乎10T采集数据),这里选用hdfs用于存放原始数据。
竟然选用了hadoop,那数据分析工具自然选用hive。对上述数据类型进行建表,完成数据仓库的ODS(临时存储层)层。
简单的列举几个sql:
表一:
create EXTERNAL table IF NOT EXISTS danp_data_db.dsp_imp_uv_table(
ip string,
request_type string,
url_host string,
media_id string,
creative_id string,
device_id string,
ts string,
str1 string,
str2 string,
ua string,
str3 string,
http_type string
)
partitioned by (date_id string)
row format delimited fields terminated by '\t'
stored as TEXTFILE
LOCATION '/hive_data/danp_data/dsp_get';
表二:
create EXTERNAL table x_test.dmp(
dmp string,
deviceid string,
adxtype string,
ip string,
dealid string,
audiences map<STRING,STRING>
)
partitioned by (date_id string,media string)
row format delimited fields terminated by '\001'
COLLECTION ITEMS TERMINATED BY ','
map keys terminated by '='
stored as TEXTFILE
LOCATION '/dmp_dataclean/dmp_table';
分区表刷新分区
MSCK REPAIR TABLE dmp_db.dmp_partition_table;
当我们对ODS层搭建完成,这时需要数据流入,所以写了定时脚本(crontab),让数据每天自己入库,相关脚本如下:
#!/bin/bash
export JAVA_HOME=/usr/share/java/jdk1.8.0_211
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
date_idv=`date -d "-1 day" +"%Y%m%d"`
echo "--------------------clean data date:$date_idv--------------------"
hdfs dfs -mkdir /hive_data/dmp/data/$date_idv;
for name in /data/dmp_data/*/*$date_idv.txt
do
hdfs dfs -put $name /hive_data/dmp/data/$date_idv;
echo "--------------------date into hdfs success:$name--------------------"
done;
echo "--------------------data clean begin--------------------"
hadoop jar /data/dmp_data/xyy_jars/DmpDataClean.jar work01 /hive_data/dmp/data/$date_idv /hive_data/dmp/data/$date_idv/output $date_idv;
echo "--------------------clean success--------------------"
hdfs dfs -mv /hive_data/dmp/data/$date_idv/output/* /hive_data/dmp/table;
hdfs dfs -mkdir /hive_data/dmp/dmp_partition_table/date_id=$date_idv;
echo "--------------------data analyze--------------------"
hive -e "insert overwrite directory \"/hive_data/dmp/dmp_partition_table/date_id=$(date -d "-1 day" +"%Y%m%d")\" select logtime, dmp, deviceid, adxtype, ip, dealid, audiences from dmp_db.dmp_table where logdate=\"$(date -d "-1 day" +"%Y-%m-%d")\" ";
echo "--------------------get data success--------------------"
echo "--------------------add patition--------------------"
hive -e "MSCK REPAIR TABLE dmp_db.dmp_partition_table;";
echo "--------------------everything be ok--------------------"
DmpDataClean.jar代码如下(公司要求,有删减)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class DataClean {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://"+args[0]+":8020");
Job job = Job.getInstance(conf);
job.setJarByClass(DataClean.class);
job.setMapperClass(DCmapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
//FileInputFormat.setInputPaths(job, new Path("C:\\Users\\yxiong02\\Desktop\\data\\input"));
//FileOutputFormat.setOutputPath(job, new Path("C:\\Users\\yxiong02\\Desktop\\data\\output"));
job.setNumReduceTasks(0);
MyOut.setOutputName(job, args[3]);
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
class MyOut extends TextOutputFormat {
protected static void setOutputName(JobContext job, String name) {
job.getConfiguration().set(BASE_OUTPUT_NAME, name);
}
}
class DCmapper extends Mapper<LongWritable,Text,Text,NullWritable>{
protected void map(LongWritable key, Text value, Context context){
System.out.println("开始执行");
String line=value.toString();
System.out.println("原始数据---------->"+line);
String cleandata=null;
try{
cleandata = clean(line);
}catch (Exception e){
System.out.println("清洗失败~");
}
try{
if(cleandata!=null){
context.write(new Text(cleandata),NullWritable.get());
System.out.println("清洗数据---------->"+cleandata);
}
}catch (Exception e){
System.out.println(e);
}
}
public static String clean(String s){
Pattern pattern = Pattern.compile("([0-9]{4}-[0-9]{2}-[0-9]{2})\\s([0-9]{2}:[0-9]{2}:[0-9]{2})\\s\\{(.*dealid:\\w+);(.*);}");
Matcher matcher = pattern.matcher(s);
if(matcher.find()){
String data1=matcher.group(1);
String data2=matcher.group(2);
String data3=matcher.group(3);
String data4=matcher.group(4);
StringBuilder sb=new StringBuilder();
sb.append(data1+"\001");
sb.append(data2+"\001");
for(String s1:data3.split(";")){
String[] split = s1.split(":");
sb.append(split[1]+"\001");
}
Map<String,String> map=new HashMap();
if(data4.contains(";")){
for(String ds:data4.split(";")){
String[] a=((ds.split("\\|"))[1]).split(":");
map.put(a[0],a[1]);
}
}else {
String[] a=((data4.split("\\|"))[1]).split(":");
map.put(a[0],a[1]);
}
if(!map.isEmpty()){
String s1 = map.toString();
String substring = s1.substring(s1.indexOf("{") + 1, s1.indexOf("}"));
sb.append(substring);
return sb.toString();
}else {
return null;
}
}else {
return null;
}
}
}
以上均为让检测数据每天自动化流入ODS层。
以上工作完成之后,需要根据需求完成数据分析与提取。这里举一例:
select date_id,
dealid,
substr(logtime,1,2) as hours,
(map_keys(audiences))[0] as pg,
(map_values(audiences))[0] as zt,
count((map_values(audiences))[0]) as num
from dmp_db.dmp_partition_table
group by date_id,dealid,substr(logtime,1,2),(map_keys(audiences))[0],(map_values(audiences))[0]
order by date_id,dealid,hours
将抽取出来的数据存入PDW(数据仓库)层,降低表的复杂度,减少连表查询。
这里的相关工作同上面的脚本,也可以看到数据会自动加载到PDW层。
然后就是数据的MID(数据集市层)层:
-----为数据集市层,这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是PDW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。从数据的广度来说,仍然覆盖了所有业务数据。
最后就是针对每一波投放,准备数据的APP(应用层)层
-----为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。从数据的广度来说,则并不一定会覆盖所有业务数据,而是MID层数据的一个真子集,从某种意义上来说是MID层数据的一个重复。从极端情况来说,可以为每一张报表在APP层构建一个模型来支持,达到以空间换时间的目的数据仓库的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
针对这一层的数据,处理逻辑会复杂一些,相关操作如下:
1>.整理训练集数据,在历史数据中心抽取60%做为训练集,提取相关字段,给每个维度定义相应的权重(维度:deviceid,sex,people,ip,address,saletype,cars…等)。
2>.第一步适当的降低维度,排除无关精要的维度,提高有用维度的权重,相关model如下
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import numpy as np
import matplotlib.pyplot as mp
import sklearn.linear_model as lm
import sklearn.metrics as sm
import pickle
#采集数据
x,y = [],[]
with open('./single.txt','r') as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(',')]
x.append(data[:-1])
y.append(data[-1])
x = np.array(x)
y = np.array(y)
#创建模型,也就意味着选择了算法
model = lm.LinearRegression() #线性回归
#训练模型
model.fit(x,y)
#根据输入预测输出
pred_y = model.predict(x)
#打印每个样本的实际输出和预测输出
for true, pred in zip(y,pred_y):
print(true,'----->',pred)
mp.figure('Linear Regression', facecolor='lightgray')
mp.title('Linear Regression', fontsize=20)
mp.xlabel('x', fontsize=14)
mp.ylabel('y', fontsize=14)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.scatter(x, y, c='dodgerblue', alpha=0.75, s=60, label='Sample')
#得到输入从小到大的索引值
sorted_indices = x.T[0].argsort()
mp.plot(x[sorted_indices],pred_y[sorted_indices],c='orangered',label='Regression')
mp.legend()
mp.show()
#检测model:
import sklearn.metrics as sm
# 平均绝地值误差: 1/m * ∑|实际输出减去预测输出| 取绝地值
print(sm.mean_absolute_error(y,pred_y))
# 平均平方误差: SQRT(1/m * ∑(实际输出减去预测输出)^2)
print(sm.mean_squared_error(y,pred_y))
# 中位数绝对值误差:MEDIAN(|实际输出减去预测输出|)
print(sm.median_absolute_error(y,pred_y))
# R2得分 误差越接近于正无穷,r2值越接近于0,误差越接近0,r2值越接近1(相当于做了一次归一化)
print(sm.r2_score(y,pred_y))
因为算法为公司机密,这里就没有放源码,这里只是我自己写的小demo,望大佬们海涵。
其实model的作用就在于判断一个数据库里没有的数据,我们如何判断这一个流量吃不吃。至此dmp的数据存储和分析告一段落,但是在dsp投放的流程中,dmp只能算底层,接下来开始投放逻辑这一阶段。
第一:解决实时投放问题
当一个流量来了,要判断这个deviceid是否存在于我们库里面(这里的库指的是我们通过分析,存下来的人群数据。当然这里不会查询hive,这将是一个极其漫长的过程,在广告投放之前,我们会摘取数据先存放到redis里面,这里又涉及到一个技术点,docker,我们在docker里面搭建redis),如果存在,这个流量我们就吃,不存在我们再走数据分析阶段,通过之前离线分析的算法,实时对行为进行分析,然后再判断要不要投放,这里用到kafka+sparkstreaming的Receiver方式。
代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by jy02268879 on 2018/7/19.
*
* Spark Streaming 基于 Receiver 对接Kafka
*/
object KafkaReceiver {
def main(args: Array[String]): Unit = {
if(args.length != 4){
System.err.println("Usage: KafkaReceiver <zkQuorum> <groupId> <topics> <numPartitions>")
System.exit(1)
}
val Array(zkQuorum, groupId, topics, numPartitions) = args
val sparkConf = new SparkConf().setAppName("KafkaReceiver").setMaster("local[3]")
val ssc = new StreamingContext(sparkConf,Seconds(5))
val topicMap = topics.split(",").map((_,numPartitions.toInt)).toMap
val messages = KafkaUtils.createStream(ssc,zkQuorum,groupId,topicMap)
messages.print()
messages.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
只是流程代码,不包含逻辑。
第二:超时数据处理
对于超时数据的处理就很简单了,直接存入hdfs的ODS层,然后走批处理,被定时任务处理掉。
到这里我们的dmp项目大致完成,剩下的就是日常bug修复,考虑超时问题的解决方案。
这里再规整一下技术点:
sparkstreaming+kafka的Receiver模式,完成数据实时分析。
hive on spark提高数据处理速度。
线性回归和逻辑回归等相关算法进行数据分析(由于本人不是算法人员,只知道一个大概,望大佬们谅解)。
就先写到这里,之后代码整理好了再上传,或者相关逻辑的修改,也会更新,开发就是一个测试过程,看哪个技术更合适,所以慢慢来吧















 4575
4575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









