







概述
为了解决只使用高水位而导致数据丢失或数据不一致的问题,Kafka 引入了Leader Epoch。
Leader Epoch,可以认为是 Leader 版本。它由两部分数据组成<Epoch, Start Offset>:
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
- 起始位移
(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
Broker 会在内存中为每个分区都缓存 Leader Epoch 数据,同时它还会定期地将这些信息持久化到一个 checkpoint 文件中。当 Leader 副本写入消息到磁盘时,Broker 会尝试更新这部分缓存。如果该 Leader 是首次写入消息,那么 Broker 会向缓存中增加一个 Leader Epoch 条目,否则就不做更新。这样,每次有 Leader 变更时,新的 Leader 副本会查询这部分缓存,取出对应的 Leader Epoch 的起始位移,以避免数据丢失和不一致的情况。
具体流程
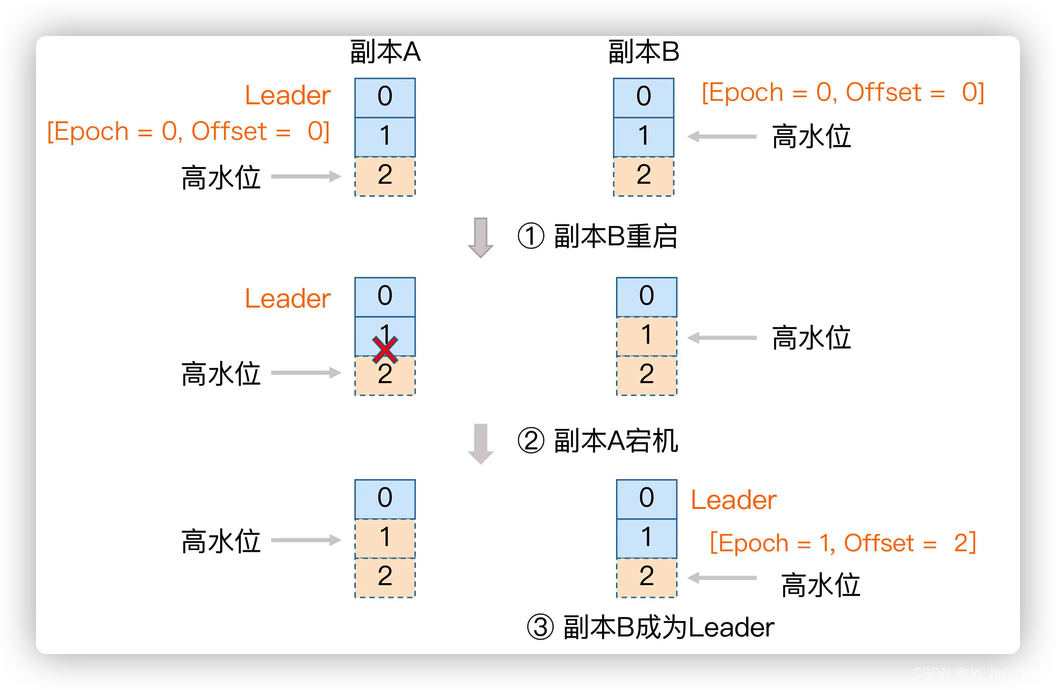
- 前面的步骤都一样,只不过当 Follower 副本 B 重启回来后,需要向 A 发送一个特殊的请求去获取 Leader 的 LEO 值 → 2。当获知到 Leader LEO=2 后,B 发现该 LEO 值 ≥ 自己的 LEO 值小,而且缓存中也没有保存任何
Start Offset > 2的 Epoch 条目,因此 B 无需执行任何日志截断操作。这是对高水位机制的一个明显改进,即副本是否执行日志截断不再依赖于高水位进行判断。 - 此时 A 宕机了,B 成为 Leader。当 A 重启回来后,执行与 B 相同的逻辑判断,发现也不用执行日志截断,至此位移值为 1 的那条消息在两个副本中均得到保留。后面当生产者程序向 B 写入新消息时,副本 B 所在的 Broker 缓存中,会生成新的 Leader Epoch 条目:[Epoch=1, Offset=2]。之后,副本 B 会使用这个条目帮助判断后续是否执行日志截断操作。
参考自胡夕老师《Kafka核心技术与实战》极客时间专栏,老师的课很棒,强烈推荐!















 2760
2760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









