







注:记录读取iso8859-1编码遇到的一些问题。目前主流的编码方式是utf-8,因此对于iso8859-1编码的相关资料比较少。
首先介绍一下
ISO-8859-1
(截图来自http://zh.wikipedia.org/wiki/ISO/IEC_8859-1,对于iso-8859编码详细可以去维基百科看)

读取用iso-8859-1编码的txt文件
def read_txtfile_iso8859(txtpath):
# read txt file wih iso8859 code
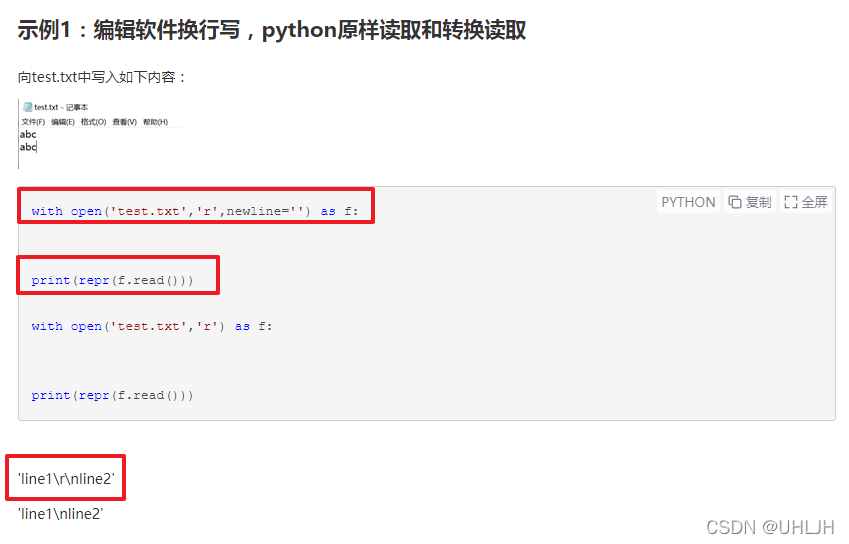
# 这里的newline =''很重要,后面再说
f = open(txtpath,newline='',encoding='iso8859-1')
codes = f.read()
f.close()
return codes
将iso-8859-1的字符转换为字节/二进制比特,并且保存到另外一个txt
# 这个是把单个字符转换为单字节,多个字符转换为多个字节,并且append成list
def code_type_iso8859_to_binstrlist(code):
datastrlist = []
for i in range(len(code)):
# 这里主要是转化为字节
data_hex = hex(ord(code[i]))
# 将字节转化长度为8的0/1的比特流
databin = bin(int(data_hex,16))[2:]
if len(databin) < 8:
databin = (8 - len(databin)) * '0' + databin
datastrlist.append(databin)
return datastrlist
# 这个是把list转化为string
codestring =''
def data_type_strlist_to_str(strlist):
codestring = strlist[0]
for i in range(1,len(strlist)):
codestring = codestring + strlist[i]
return codestring
# 将上面的codestring直接写入txt中,则新的txt就全是0/1的比特流
def wtrite_txtfile_default(txtpath,data):
with open(txtpath,'w') as f:
f.write(data)
f.close()
把0/1比特流的txt文件再次转化为基于iso-8859-1编码的txt文件
# 把0/1比特流的txt文件读取进来
def read_txtfile_default(txtpath):
f = open(txtpath,"r")
codes = f.read()
f.close()
return codes
# 把string转化为list
def data_type_str_to_strlist(data):
# this function is uesd to tans
codelen = len(data)
codenum = int(codelen / 8 )
strlist = []
for i in range(codenum):
strlist.append(data[i*8:i*8+8])
return strlist
# 把strlist再转化为字符编码,并且拼接到一起
def code_type_binstrlist_to_iso8859(code_strlist):
codeiso8859 = ''
for i in range(len(code_strlist)):
decdata = int(code_strlist[i],2)
chrdata = chr(decdata)
codeiso8859 = codeiso8859 + chrdata
return codeiso8859
# 最后写入到txt文件中
def write_txtfile_iso8859(txtpath,data):
with open(txtpath,'w',encoding='iso8859-1') as f:
f.write(data)
f.close
一些注意事项
理论上,经过上面可以的步骤,可以实现字符编码(iso-8859-1)---->0/1比特流------>字符编码(iso-8859-1)的转换。
其中有一个需要注意的点就是换行符。
也就是上面提到的
# 这里的newline =''很重要
f = open(txtpath,newline='',encoding='iso8859-1')
一开始,一直无法实现文件的完整复制,存在的有时候可以完整复制有时候不行。经过排查问题,发现是txt文件中换行符问题,这里需要感谢https://www.cnblogs.com/jeancheng/p/13759550.html这一博客给到的启发。
















 5644
5644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









