







这篇文章只是为了巩固自身的学习,所以有些步骤不大全,但是把代码拼起来也是可以运行的。
该项目也是根据网上教程做的,教程只爬取了一页的评论,本人在爬取全部评论的时候遇到了问题:因为找不到cursor赋值的规律,参数中cursor值需要手动修改,一次可以爬十页,若有大佬可以解决,希望可以告知。
还是有一些问题的,之后慢慢解决
难点
- 在js中找到加密算法
- 模拟js加密得到params
- 根据评论页面修改data(这里我虽然可以得到所有页面的数据,但每10页需要修改data中参数cursor的值,而且cursor的获取也是从网页中手动得到,希望有人可以帮助解决)
在js中找出加密过程(建议通过视频了解)
- 先找到传递评论数据的包
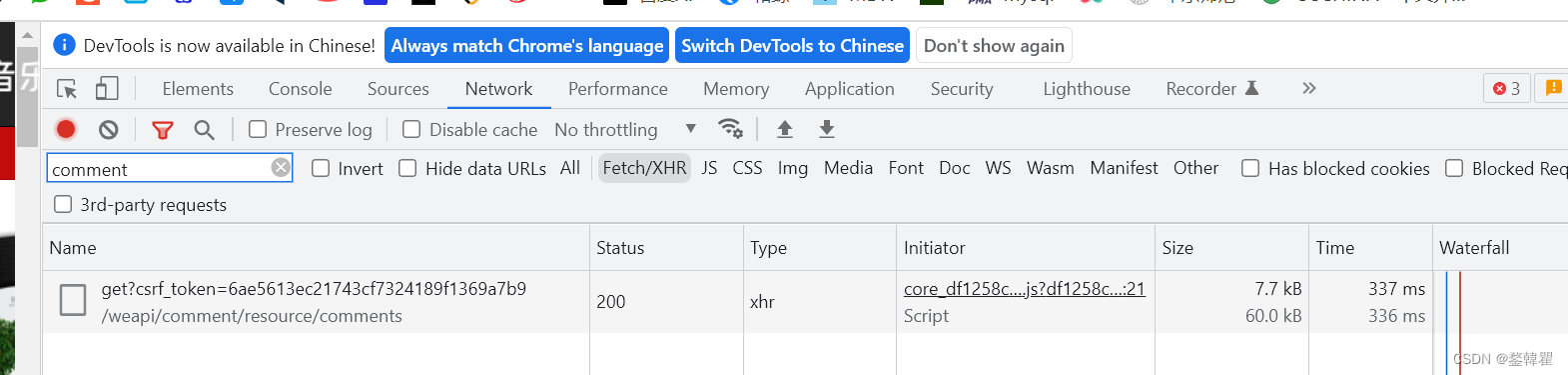
一般像这种评论,可以试试英文搜索,免得一个个看
- 在headers中看到的请求方式是post,就去playload看它传递的参数。
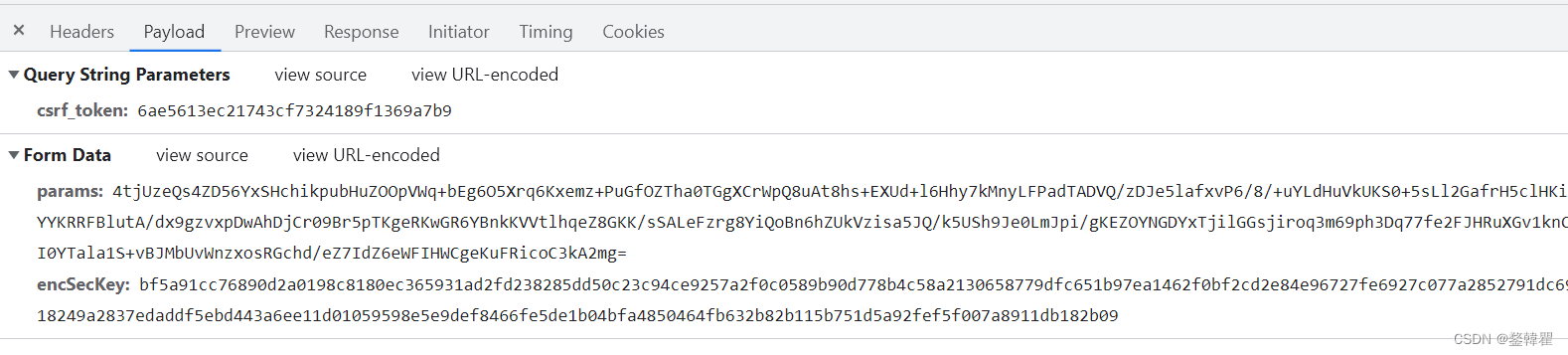
这里的params和encSecKey明显经过的加密处理,我们也可以直接用里面的参数,得到一页的数据,但下一页就需要同样按照这个方法获取params和encSecKey。
用selenium自动化去获取网页来可能更为方便,但这次是为了学习加密解密的过程。
3.找到js中传递参数的程序,并设置断点,刷新捕捉
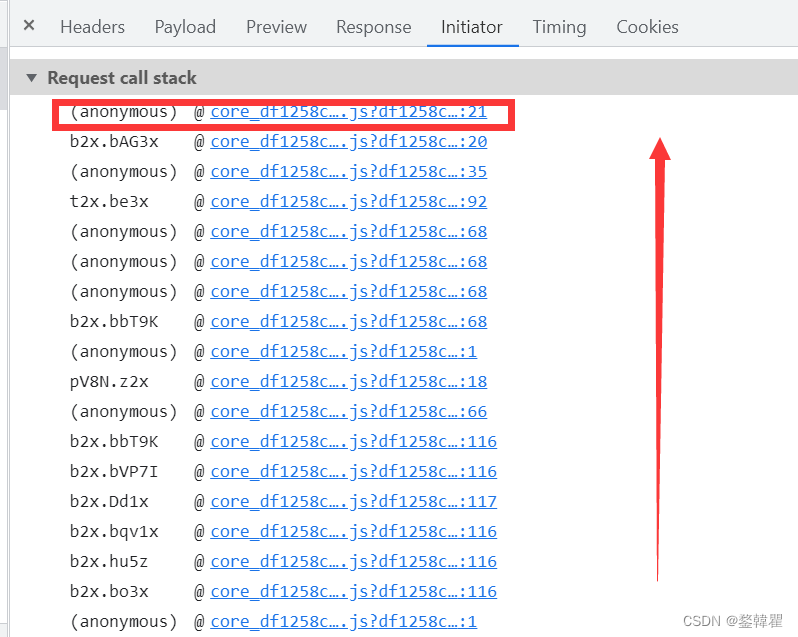
在initiator中,request call stack执行过程是由下往上的,所以直接点击最上面的,进入js代码中。点击代码下方的{}使代码变整洁。
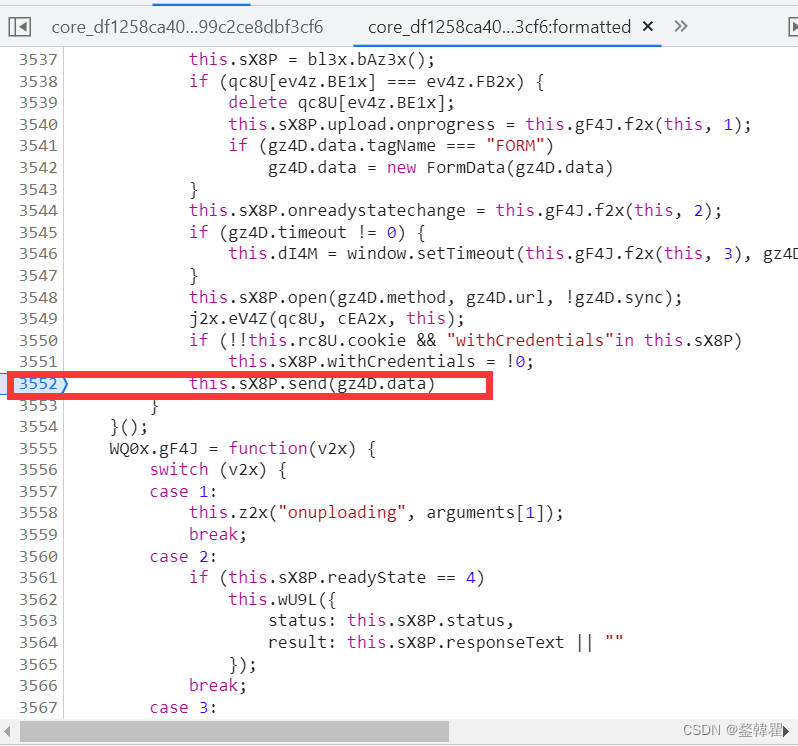
设置断点,重新刷新网页
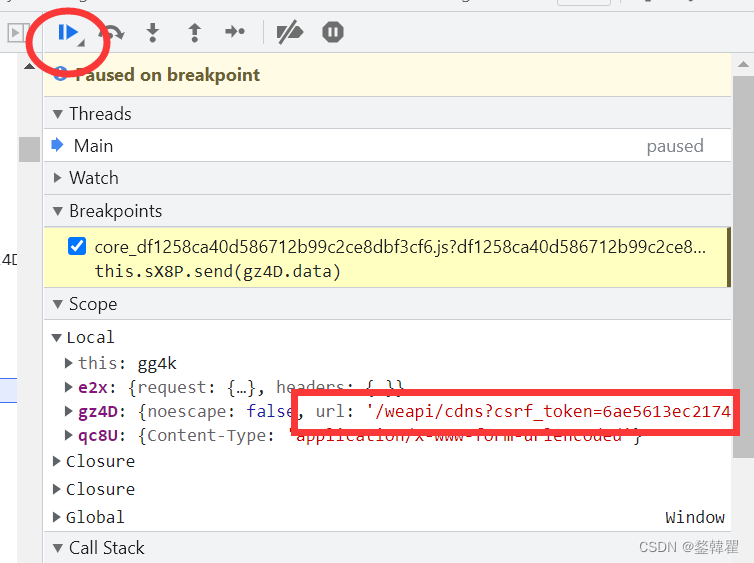
这里看url,我们点蓝色的剪头,知道看到有comment出现
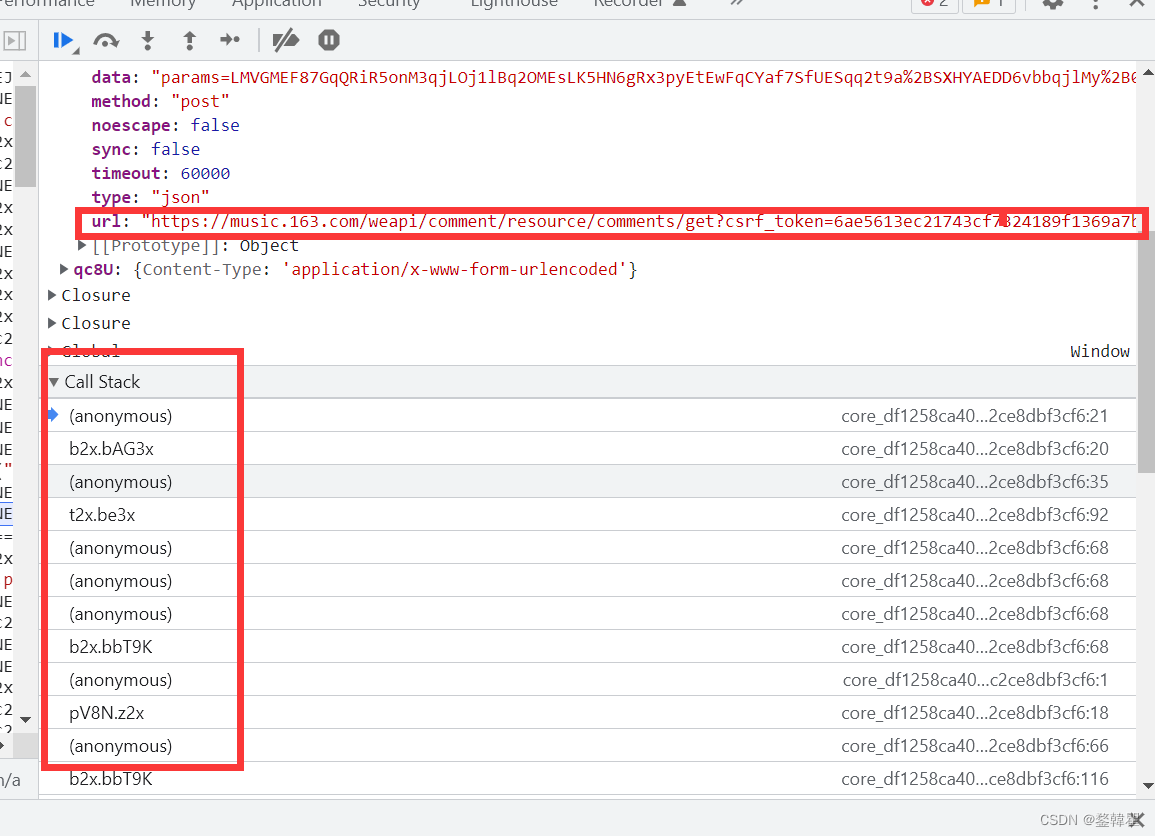
找到评论的url之后,由上到下依次点击call Stack,找到加密的程序。
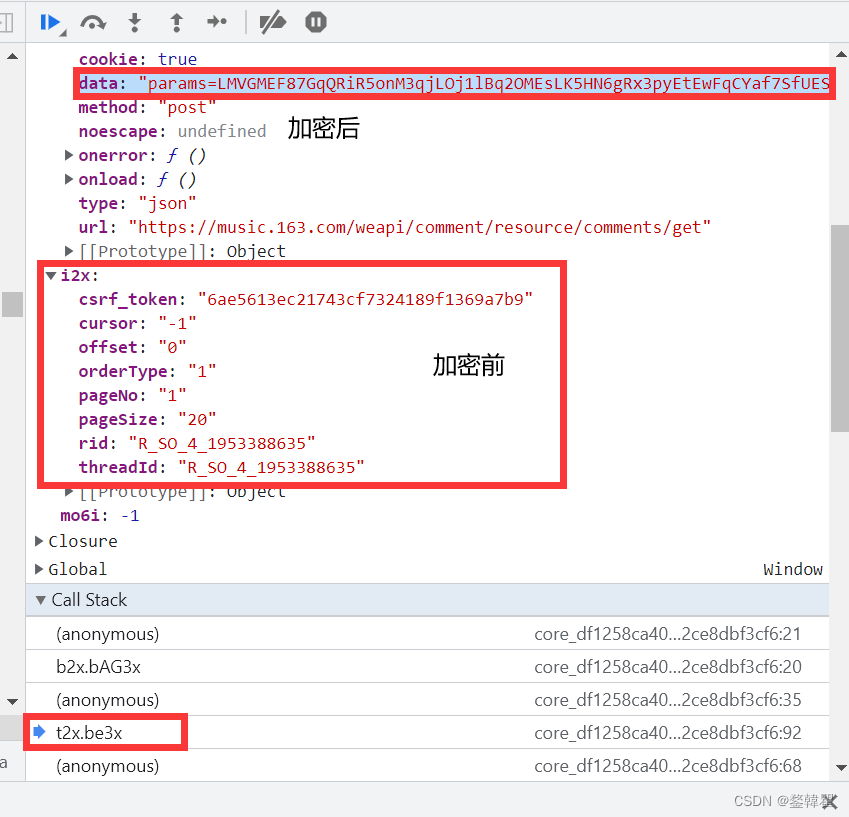
可以看出,在t2x.be3x中进行的加密运算,所以去js代码里找到它的加密过程。
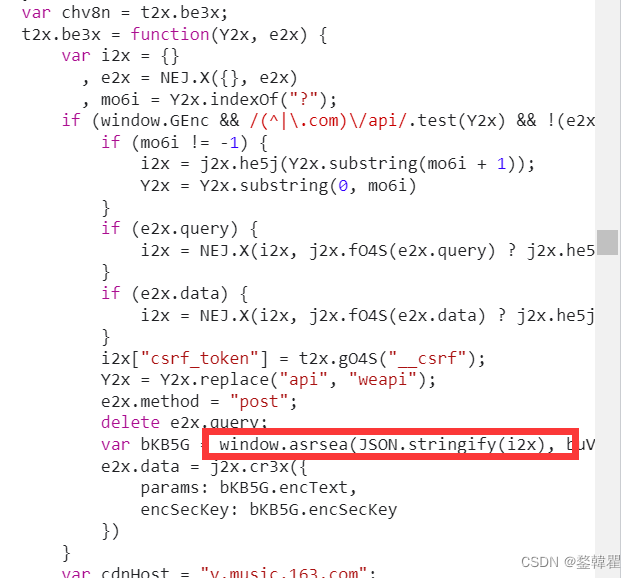
仔细研究这个加密函数就可以得到加密过程,这里不进行过多讲解,主要还是可以根据教学视频得到完整且更细致的过程。
使用Crypto包还原加密过程
如果遇到crypto包安装问题,可以试着升级pip,然后pip install cryptodome,本人是这样解决的。
经过加密分析,当确定i的值之后,可以直接得到encSecKey, 所以这里所需要做的过程只有将 data转化成params

data中是这样的数据,然后进行加密生成params
加密算法加密数据都为byte类型,所以需要转码,而且加密的内容,比如data需要让它的长度为16的整数倍,所以还要写一个to_16(data)函数
def to_16(data): # 字符串补齐16整数倍
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
def encryption(a, b): # a是要加密的内容,a为字符串
c = b.encode('utf-8')
d = '0102030405060708'.encode('utf-8')
encryptors = AES.new(c, AES.MODE_CBC, d) # 都为byte型数据
a = to_16(a)
result = encryptors.encrypt(a.encode('utf-8')) # 加密的内容长度必须是16的倍数
return str(b64encode(result), 'utf-8')
# 直接解码是无法被‘utf-8’识别,所以要用b64encode()先处理,再转成字符串
根据js中加密内容,进行了两次加密,所以要进行两次调用,然后得到params
def GetParams(data): # data为字符串
enText = encryption(data, g)
params = encryption(enText, i)
return params
这里data,因为要改变里面的参数值,且原来的data是字典,要变成字符串,所以这里我写了一个函数,这个函数有两个变量,page是页面,cursor是另外一个参数,本人并未发现cursor取值的规律,一番搜索也没有弄清楚,cursor每取一个值,可以爬10页的评论,且data中页面号并不影响结果,主要offset这个参数,取值范围是(0-180)以20为增量。
def GetD(page,cursor):
d = {
"csrf_token": "6ae5613ec21743cf7324189f1369a7b9",
"offset": f"{page*20-20}",
"orderType": "1",
"pageSize": "20",
"rid": "R_SO_4_1953388635",
"threadId": "R_SO_4_1953388635",
"total": "false",
"cursor":cursor
}
data = json.dumps(d)
return data # 返回字符串
这里简单爬取下评论
def CrawlComment(params):
data = {
"params": params,
"encSecKey": encSecKey
}
try:
content = requests.post(url, data=data)
temp = content.json()
comment = temp['data']['comments']
for item in comment:
print(item['content'])
except Exception as e:
print(e)
def CrawlAllComment():
for page in range(1, 10):
enText = encryption(GetD(page, "-1"), g)
# cursor取值为“-1-”,爬取的是1-10页,cursor取“1657284932215” 爬取的是11-20页
params = encryption(enText, i)
CrawlComment(params)
# 一些导入的包和数据
import requests
import json
from Crypto.Cipher import AES
from base64 import b64encode
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token=6ae5613ec21743cf7324189f1369a7b9"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like'
' Gecko) Chrome/103.0.0.0 Safari/537.36'
}
f = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf" \
"695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b" \
"8e289dc6935b3ece0462db0a22b8e7"
g = '0CoJUm6Qyw8W8jud'
i = "ujeWEtsr8dMNVG3M"
encSecKey = "3fe0afe0b977b19a03d9e7e5123f9995e48d91314b53fcfc86a85df5d0d59d7f521e8684ac2dd823fe8ecbecf2358388017" \
"ee9cd78ebadba67dae3f6165640a564eb0f86529e29352e0c0a7b296b24f50bfc58a64798adbbdfc13f6edde7e6afbc382983" \
"4333fa725cdb0b5b3a1b0a35232b17e1ef570780f5b6ab82d0f2813f"
if __name__ == '__main__':
CrawlAllComment()















 1685
1685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









