







文章目录
一、堆溢出前置知识
堆与栈的区别:
- 栈是有硬件直接支持的(CPU)
- 栈存储数据、控制流信息
- 堆是由操作系统的库函数支持的
- 堆存储数据
分配器 glibc malloc 分配器
起初数据段之上是没有堆的,进程运行在栈上;malloc才创造堆
多线程情况下arena的分配
主线程分配arena,线程1、2分别分配arena,那么线程3需要需要重复使用已经分配好的arena
分配器循环遍历arena,如果lock成功(也就是有线程如果没有使用堆空间),那么该线程的arena供线程3使用。若没有找到可用arena,则将线程3阻塞,直到找到可用的位置。
(个人思考: 所以对于多线程编程,是一定要及时free堆空间的,否则内存泄露,有线程会一直阻塞?)
arena、heap、trunk的关系
对于thread arena, 可以维护多个堆,每个堆都有自己的堆header
对于main arena,不必维护多个堆,也就无需heap_info,因为空间耗尽的时候用brk扩展空间,直到碰到内存映射段。不必像thread arena使用mmap
一个堆可以划分为多个trunk
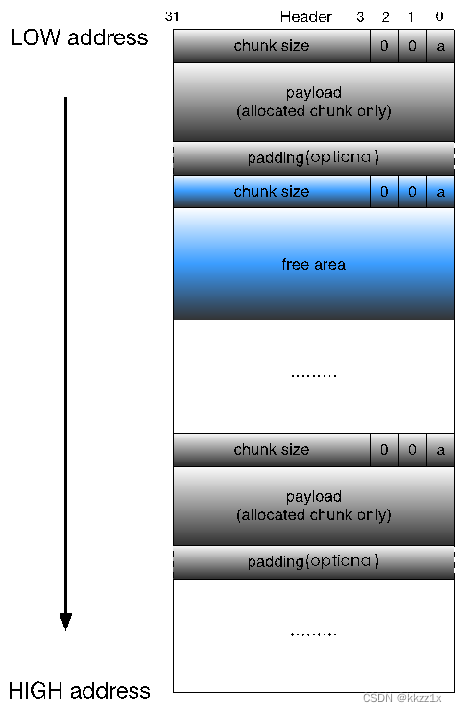
还未进化的堆块设计
allocated trunk的格式
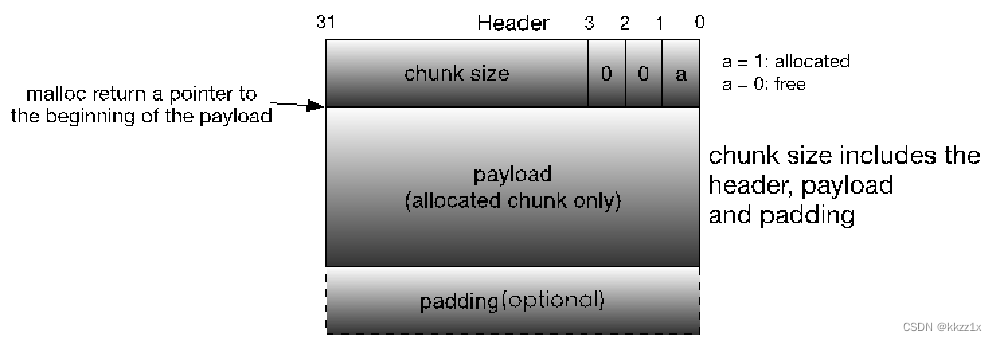
padding用来对齐,整个chunk大小为9的整数倍
free chunk的格式
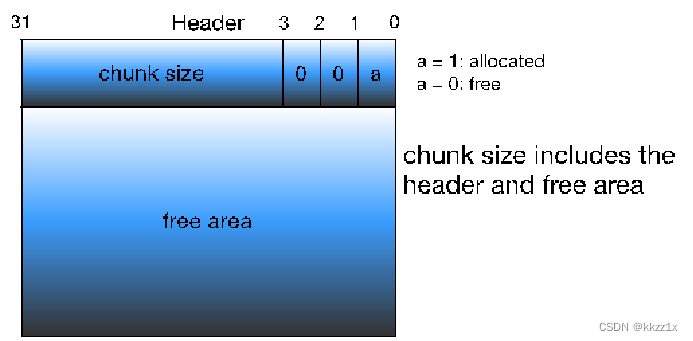
可以看出,很普通,结构上是一样的,通过标志位p来区分chunk有没有被分配。chunk size(第三位标志位)+payload/free area
将chunk堆起来就行了。 结构叫做隐式链表,该链表隐式地由每个chunk的size字段连接(这样得到了边界)。在进行分配操作的时候,堆内存分配器遍历整个堆内存的chunk,分析chunk的size字段,找到合适的chunk。
缺点
效率很低,在内存回收方面,难以对多个相邻的free chunk进行合并操作。 内存碎片多
进化后的堆块设计(带边界标记的chunk合并技术)
怎么合并?
向前合并 (需要边界标记)
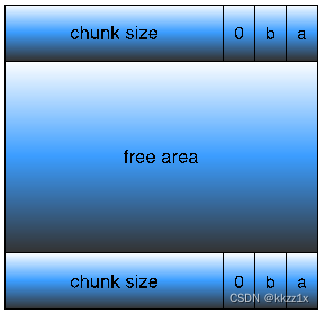
free area的头部、尾部都要记录chunk size。
通过这个foot,当前这个chunk可以知道上一个chunk的大小(为头部的前4个字节处),然后就知道上一个chunk的起始位置和分配状态,加以合并。
缺点: 头部+首部开销,对于频繁的小内存的申请和释放操作会造成很大的性能损耗。 对于前一个chunk是allocated chunk(也就是当前chunk标志位p=1),不需要这个foot。
三个标志位
N non main arena
M 当前chunk是否为mmap得到的
P 前一个chunk是否被分配了(分配了那么上一个无foot,不需要合并)
想要知道当前chunk有无被分配,那需要查询下一个chunk size字段。
M、N就是用于满足多线程的标志需求(non main arena? is_mmapped?)
再进一步
不需要foot!
将foot移到下一个的首部,存放前一个chunk的大小!(这样就能合并前一个了)
对于空闲chunk,还有fd,bk,使用显示链表bin,加快内存分配和释放效率
now:
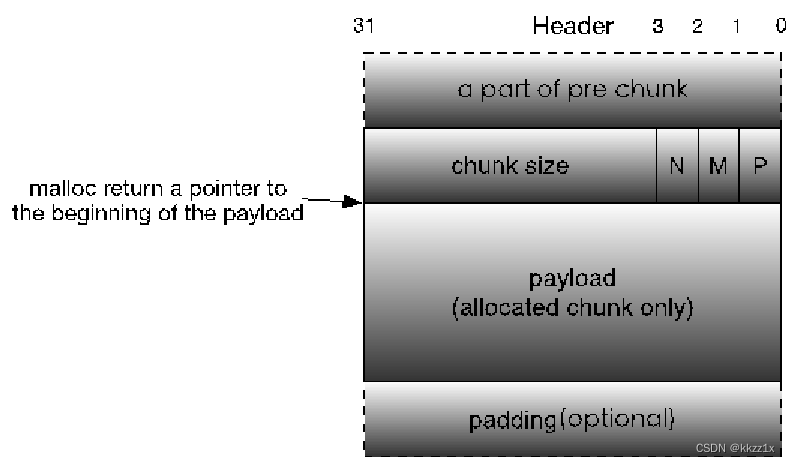

pre chunk size:
前一个chunk空闲,则表示前一个chunk的大小;不空闲,则填充前一块用户数据
bin——记录free chunk的链表数据结构
一共136个
- fast bins
10个(由fastbinY数组记录所有fastbin) 16-80字节 - bins
第一个为unsorted bin(刚free不确定大小和频繁调用的chunk),bin2-63 为small bin(<512B),64-126为large bin
fast bin
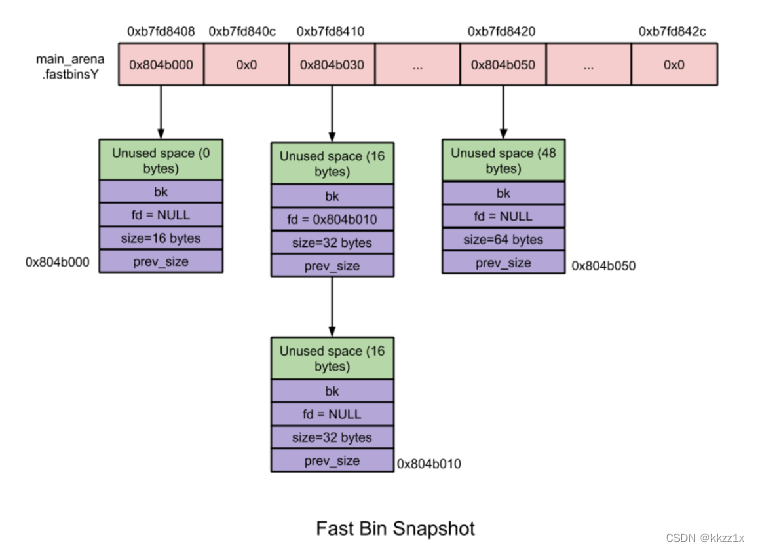
chunk 大小:8 字节递增。 fast bins 由一系列所维护 chunk 大小以 8 字节递增的 bins 组成。也即,fast bin[0] 维护大小为 16 字节的 chunk、fast bin[1] 维护大小为 24 字节的 chunk。依此类推…… 指定 fast bin 中所有 chunk 大小相同;
在 malloc 初始化过程中,最大的 fast bin 的大小被设置为 64 而非 80 字节。因为默认情况下只有大小 16 ~ 64 的 chunk 被归为 fast chunk 。
无需合并 —— 两个相邻 chunk 不会被合并。虽然这可能会加剧内存碎片化,但也大大加速了内存释放的速度!
(与上一part的隐式链表做对比!)
对于fastbin,malloc和free的chunk类似于栈; 是单链表,一条链表中所有chunk大小都相等
bins
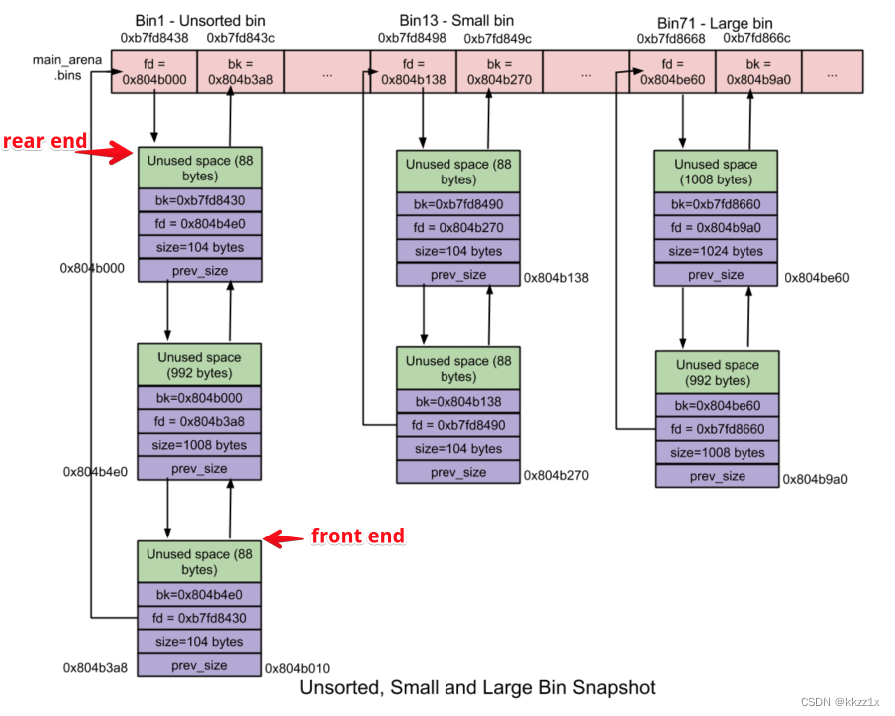
是循环双链表
每个small bin也是一个由对应free chunk组成的循环双链表。第一个small bin中chunk大小为16字节,后续每个small bin中chunk的大小依次增加8字节,即最后一个small bin的chunk为16 + 61*8 = 508字节。
大于512字节的chunk称之为large chunk,large bin就是用于管理这些large chunk的。第一个large bin中chunk size为512~575字节,第二个large bin中chunk size为576 ~ 639字节。紧随其后的16个large bin依次以512字节步长为间隔;之后的8个bin以步长4096为间隔;再之后的4个bin以32768字节为间隔;之后的2个bin以262144字节为间隔;剩下的chunk就放在最后一个large bin中。
鉴于同一个large bin中每个chunk的大小不一定相同,因此为了加快内存分配和释放的速度,就将同一个large bin中的所有chunk按照chunk size进行从大到小的排列:最大的chunk放在链表的front end,最小的chunk放在rear end。
Top chunk
一个chunk处于arena的最顶部 ,就是top chunk,不属于任何bin
在所有free chunk都没法满足申请的内存大小时候,切割使用。
切割需要的,留下一部分成为新的topchunk
如果还是不够,那需要sbrk扩展heap,或者用mmap分配新的heap
二、堆溢出
攻击fastbin
看了半天。
buf0=malloc(32)
buf1=malloc(32)
free(buf1)
free(buf0) //用的是尾插,此时fastbin[i]的rear指向chunk0
buf0=malloc(32) //此时buf0用的是chunk0, rear指向chunk0->fd,也就是chunk1
read(buf0) //进行溢出,使得溢出到chunk0的fd(AAAA)
buf1=malloc(32) //chunk1被分配,此时rear指向chunk1->fd,也就是溢出得到的AAAA
buf2=malloc(32) // “虚假的”chunk被分配
read(buf2) //控制buf2所在内存
攻击利用:
AAAA替换为any_address-8 (虚假chunk的头地址)
并在这个地址处伪造一个presize=0,size=0x29的堆块,则能够控制malloc返回值,结合后面的read实现任意地址写
攻击unlink
unlink:P指的删除

几个概念
向后合并
将prev free chunk合并到当前free chunk,叫做向后合并。
将前一个合并后,删除
向前合并
将后面free chunk合并到当前,叫做向前合并。
需要检测的是next chunk是不是free。 检查标志位next-> next.P
合并,删除。
利用:(原理有书读了再补)
fd =free函数got表地址-12
bk=shellcode地址
Use After free


(sc版ppt)对buf1进行写,还会影响buf2/3
个人理解: 对buf2写,影响buf1这个指针所指的地址
double free
堆块分配和释放:
堆空间管理本质上是对bin链表的维护;
堆块释放后,原本指向它的指针不销毁;结果是指针悬空,指针指向了未使用的内存,但仍然可以引用该空间
(堆空间是由用户管理,而不是系统,因此不安全)
double free释放重引用漏洞的一个特例
一般流程:(重要)
- 申请一段空间,将其释放但不将指针置空(p1)
- 申请空间p2,由于malloc分配的过程使得p2指向的空间为刚刚释放的p1指针空间
- 构造恶意的数据将p2指向的内存空间布局好(即覆盖p1中的数据)
- 利用p1















 6044
6044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









