







CS速成课笔记
前言
首先是大致介绍笔记组成,来源,参考以及建议。
内容源于【计算机科学速成课】- Crash Course Computer Science ,是学习时做的一些简单笔记,从别的大佬的笔记里扒了不少内容和图片,仅用于自己学习复习时使用。加了一些自己帮助学习的例子
私货。原字幕我看文件大小估计至少12w个字(因为是双语字幕而且经常出现重复行,源文件938k直接砍半抹零头保守估计400k,然后假定文件使用UTF-8编码,则一个汉字3b,那么20kb就包含6000多个汉字,那这400k就保守估计出12w的汉字了)那我这笔记还算精炼的Σ(っ °Д °;)っ
笔记组成大致如下
1-9章:计算机基本组成 - 从开关到逻辑门到CPU
10-16章:编程语言 - 编程方式语言发展,处理数据方法的发展
17-23章:操作系统与文件系统 - 怎样管理计算机与相关文件
24-25章:促进计算机发展的历史 - 战争与商业化对计算机的发展促进
26-27章:计算机图形界面 - 计算机与人交互方式的简化
28-30章:互联网组成 - 计算机数据交互方式的发展
31-33章:计算机安全 - 网络数据安全怎样受到挑战与保护手法
34-40章:计算机拓展应用 - 让计算机利用自身优势做的从与人类相似到超越人类
1-27章: 计算机发展到从专注硬件到软件,专注于将计算机贴近人类
28-40章:计算机网络与AI教育,专注于将计算机超越人类
建议学习时如果像我一样觉得看视频太拖沓(但是视频补充的例子确实很关键)可以参考他人笔记以及视频字幕。
偏概括的笔记,作者记到压缩那一章附近就没了,CrashCourse_CS_notes (P1-P5) - Syddd的文章
相对完整的笔记,但是作者中间互联网到加密那一块没有做笔记。计算机科学速成课笔记 - 问夏的文章
计算机的基本元件-开关
前一章感觉只是介绍历史的草草看过觉得没有特别需要注意的就没特意去记笔记
计算机是由各种电路组合而成的,而电路由电源,用电器(负载),中间环节(导线,开关)组成。以下是开关的演变,从继电器到真空管到晶体管。
继电器
早起的电路开关继电器是用电控制的机械开关,它连接着一个线圈,当线圈通电时会产生感应磁场吸引上方机械臂从而闭合电路(联通线路得到高电平)。但是金属机械臂是有质量的,无法快速开关而且反复移动会很容易产生损耗。
真空管
单项流通电流 - 二极管
热电子管把两个电极放在一个气密的真空玻璃灯泡中。其中一个电极A可以加热以发射电子(热电子发射Thermioic emission),另一个电极B则会吸引电子来形成电流。只有当电极B带正电时才能吸引电子,否则电子无法从电极A跨越真空区域。这种电流只能单向流动的电子部件就是二极管(二极管通常让电流从阴极流向阳极,吸引电子的被称为阳极,发送电子的被称为阴极)。

可控制电流开闭 - 三极管
而之后又在两个电极间加入了第三个控制电极,向控制电极施加正电荷会允许流动,反之则阻止电子流动。因此通过控制线路开闭实现了继电器的功能的就是三极真空管。因为真空管内没有会动的组件,意味着更少的磨损,但是也相对比较脆弱而且会像灯泡一样烧坏,体积也比较大。

晶体管
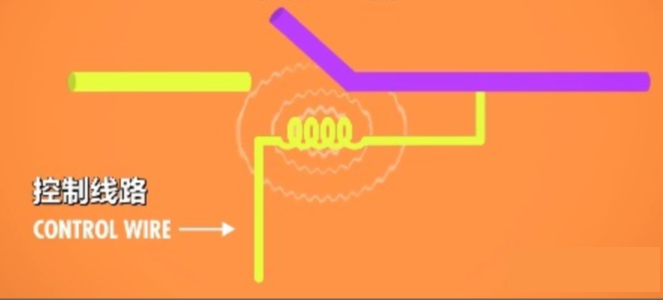
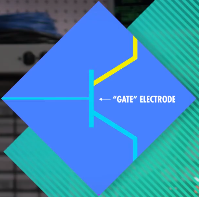
晶体管也是一个用于控制电路闭合断开的开关,晶体管有两个电极,这两个电极之间通过半导体材料隔开。半导体这种材料有时候导电,有时候不导电(常温下导电性位于导体与绝缘间,通过外界干扰改变导电性)。而控制线链接到一个”门“电极,通过改变门的电荷就可以改变半导体材料的导电性。控制了半导体导电性就可以控制电流是否流动了。
布尔逻辑和逻辑门
布尔逻辑
布尔逻辑把一些简单的逻辑思维数学化,而此处逻辑即判断事物真假或是非,布尔逻辑以代数的形式将真假区分为变量值true和false。
例:
- 所有人都会死(大前提,true)
- 苏格拉底是人(小前提,true)
- 所以,苏格拉底也是会死的(结论,true)
以上例子是亚里士多德提出的经典逻辑三段论,客观推导下结论必然为真,而布尔代数则是多个判断之间的逻辑关系演算,也被称为逻辑代数。即用布尔逻辑以布尔代数的形式运算多个判断之间的关系。
布尔代数
布尔代数不是算数运算,但仍有相应的规则与运算法则
- 布尔代数中,数值只能取
true和false或者0和1- 布尔代数中,变量可以进行
"或且非"三种逻辑操作- 布尔运算满足
交换律,结合律,吸收律,反演律
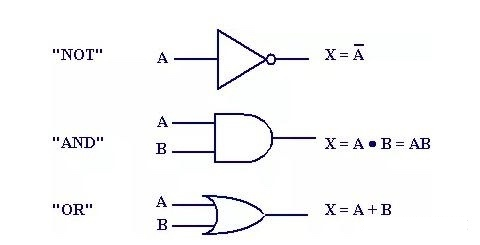
逻辑门
在计算机中布尔逻辑以开关接通状态为1(true),开关不通状态为0(false)。这样就可以用电路的开关模拟逻辑状态,组成逻辑电路。又因为组成的逻辑电路可以控制电流的流通堵塞与路径,又被称作逻辑门。
AND 与门
对应布尔代数且操作,设有两输入A,B其同时为TRUE时输出TRUE,否则都输出FALSE
| 输入A | 输入B | 输出 |
|---|---|---|
| T | F | F |
| F | T | F |
| T | T | T |
| F | F | F |
此处使用T代表True,F代表False,像这样列出所有情况的表也称为真值表
OR 或门
两输出其中一个为TRUE则输出TRUE,都不为TRUE则输出FALSE
| 输入A | 输入B | 输出 |
|---|---|---|
| T | F | T |
| F | T | T |
| T | T | T |
| F | F | F |
NOT 非门
非门只接受一个输入,且会将输入置反,即输入TRUE输出FALSE,输入FALSE输出TRUE
| 输入A | 输出 |
|---|---|
| T | F |
| F | T |
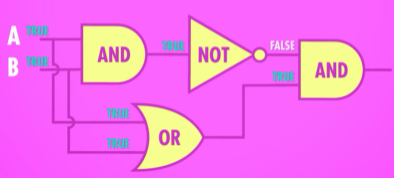
XOR 异或门
异或门是基于以上三种逻辑门构建的,其逻辑为接受两个输入,两输入相同则输出FALSE,输入不同则输出TRUE
真值表如下
| 输入A | 输入B | 输出 |
|---|---|---|
| T | F | T |
| F | T | T |
| F | F | F |
| T | T | F |
其中电路图如下,最好将真值表带入进行运算一遍,还可以试试用红石电路实现(因为红石电路不懂怎么优化结构,最后只实现一个全加器1就没有接着做了)
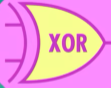
理解异或门组成后便可将其抽象,概括为与其它逻辑门一样直接用于运算即可,不必关心具体实现用了几根晶体管
二进制
二进制表示正负整数
二进制以01表示任何整数,简单说便是逢2进1。
例如
- 十进制8可以二进制表示为0000 1000(前方0补位,表示八位二进制)
- 十进制11可表示为二进制 0000 1011
例子中二进制以八位二进制数至多表示0到255,即0至
2
8
−
1
2^8 -1
28−1平时常见的二进制数通常是32位类型。而能表示到最大255是因为此处忽略了符号,即此前二进制表示为无符号整数,如果需要表达负数数值范围会改为 -128至127(1000 0000 至 0111 1111)
而二进制也可以表示负数,二进制位数中最高位为符号位,其为1时则表示是负数。(即表示正数还是负数看人,也看下面的码制)
如
- 1000 1000 可表示为二进制 -8(八位二进制,有符号表示为-8,无符号则表示为136)
码制
计算机中的符号数有三种表示方法,即原码,反码和补码。三种表示方法均有符号位和数值位两部分,符号位都是0表示正,1表示负。数值位则三种表示方法都不同。原码…嗯…就是原码即符号位加上数值位真值的绝对值
例
- 0000 1001 原码 = 0000 1001 (八位二进制原码表达范围为-127至127)
反码
将二进制每一位取反2 (即用每一位都是1的二进制数去减操作数)
例
- 110001的反码 = 001110 = 111111 - 110001 (八位二进制反码表达范围为-127至127)
补码
而补码则是原码取反码后+1(即补码想取原码需要-1后取反,但记-1后取反不如直接在该补码上再求补码也可得出原码),注意计算机中数值都是以补码形式存储
例
- 0101 补码 = 1010 + 1 = 1011 (八位二进制补码表达范围为-128至127)
此处补码能表示至-128 时因为 1000 0000 数学上表示为128,而原码反码在8位内存中无法表示, 又因为表示补码有限保证符号位不变,而1000 0000恰好保证补码表示为负数,与0000 0000表示一个就浪费了,刚好多表示一个数即-128
补码的补码又等于原码即 原码 取反 +1 取反 +1 = 原码
例:
1001 补码 = 0111 补码 → 1001
bit和byte
1位二进制为1bit,八位2进制则为1bytes
1bytes = 8bits
1Mb = 1024bytes
1Gb = 1024Mb
1Tb = 1024 Gb
二进制表示 浮点数
浮点数(如1.14514)等小数是程序中常用的数据类型,而现代计算机一般都以IEEE 754标准存储浮点数,在内存中存储的形式为:
| 数字符号位(数符) | 指数位(阶码) | 有效位数(尾数) |
|---|---|---|
| sign | exponent | fraction |
不同长度的浮点数指数位于小数位分配数量不同,其中常用浮点数分配位数表如下
| sign | exponent | fraction/significand | all | offset | |
|---|---|---|---|---|---|
| 32位单精度浮点数 | 1 | 8 | 23 | 32 | 127 |
| 64位单精度浮点数 | 1 | 11 | 52 | 64 | 1023 |
以下是浮点数转二进制的例子:
例如114.125(很想写514但是转成小数位数太多了)
- 先把整数部分和小数部分转换成二进制
- 整数部分除二求余得: 1110010
- 小数部分乘二取整得: 001
- 0.125 x 2 =》 0 0.25 x 2 => 0 0.5 x 2 => 1 1 ==> 001
- 合起来为1110010.001转换为二进制浮点数,即把小数点移动到整数位只有1,即为: 1.110010001 * 2^110 小数点左移6(二进制110)位.
- 二进制浮点数对应三部分的值
- 数字符号位: 浮点数为正数,此处为0
- 指数计算公式为: 指数位数+偏移量, 偏移量为(2^(e-1)-1);e为指数位数。此处指数位数为刚才左移的位数,此处为110,此处为32位单精度小数,偏移量为127,因此指数为: 110 + 01111111 = 10000100,尾数则为小数点后数:110010001
- 则最终结果为
01000010011001000100000000000000
二进制表示文字-Ascii码
用于表示文字(英文字母等)经常会使用的是Ascii码,由七位二进制组成的,默认只收录了128个字符,后128个是拓展Ascii码用于收容外来语字母,图形符号和数学符号
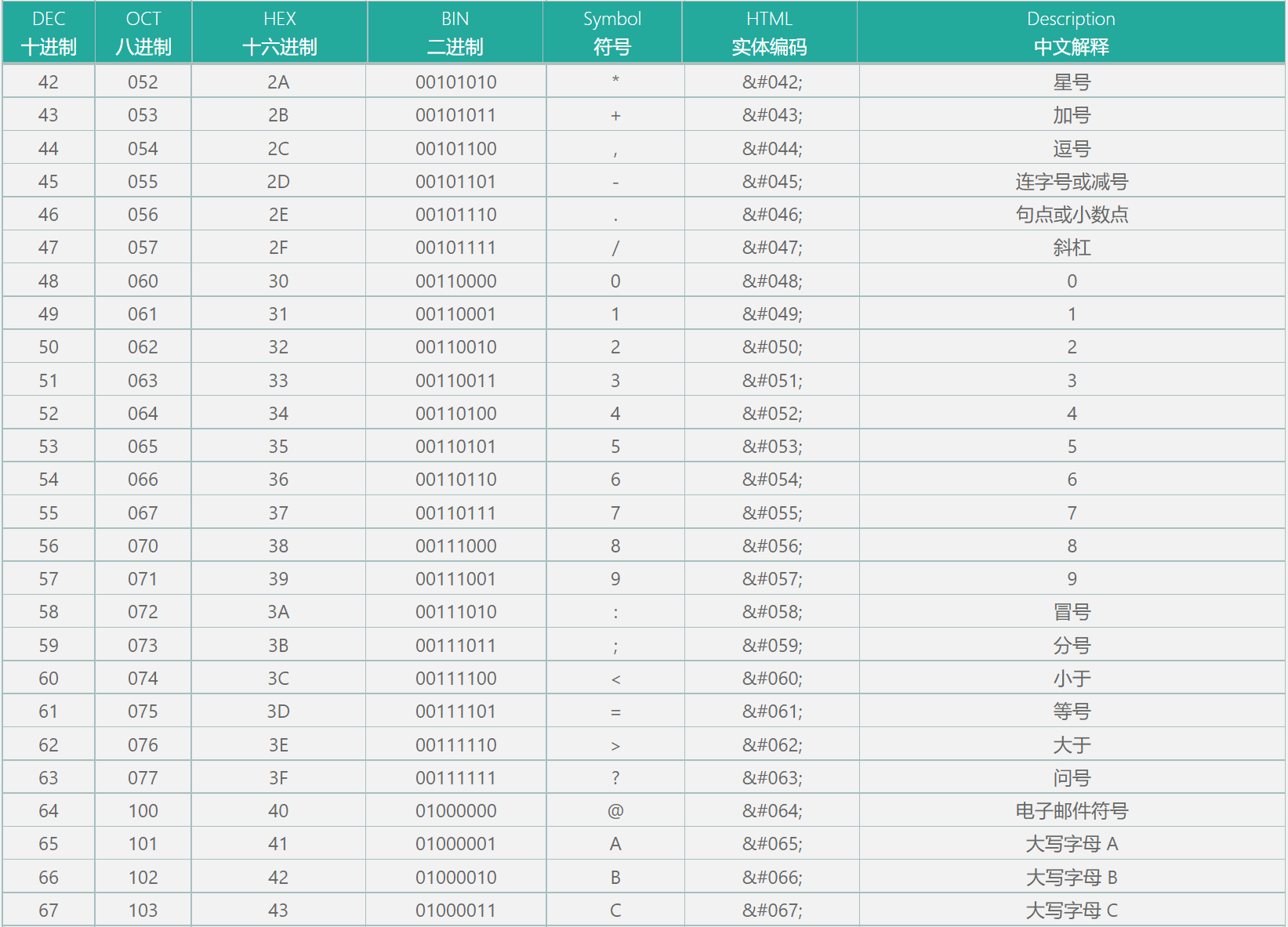
常用需要记的几个Ascii码如下
- 字符0-9的Ascii码: 48 - 57
- 大写字母A-Z的Ascii码: 65 - 90
- 小写字母a-z的Ascii码: 97 - 122(大小写a相差32)
- 空字符Ascii码: 0
- 制表符(tab)Ascii码: 9
- 换行符Ascii码: 10
其余为了统一文本的unicode-8之类的就不拓展了,总之二进制可以表示的除了数字文字还有包括各类文件等所有东西…
算数逻辑单元 ALU
ALU | Arithmetic and Logic Unit
ALU是计算机里负责运算的组件,基本由一个算术单元与一个逻辑单元组成,基本上是为了解决用逻辑门实现加法的单元
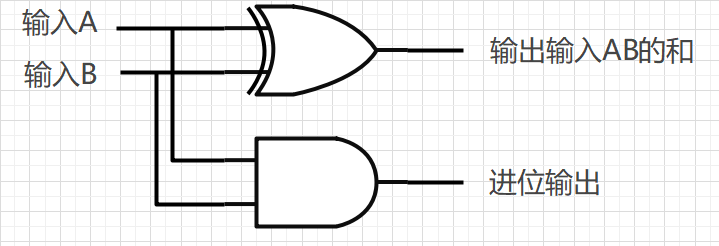
处理一位加法|半加器
一位加法(两个一位input)真值表如下
| InputA | InputB | Output |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 10 |
很明显除了第四行别的异或门都能处理,那么只要再异或门的输入ab上再加一个与门进行判断就能处理进位了
处理3bit加法|全加器
| InputA | InputB | InputC | 进位 | 总和 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 | 0 |
| 1 | 1 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 |
全加器则是处理三位输入,除了ab还有进位输入c,然后将ab输入的输出和s与进位输入c输入到另一个半加器中即可输入abc的和,而该半加器的输出进位co与输入ab的输出进位co进行与操作后即可得到abc的进位co

八位行波进位加法器
将上一位全加器/半加器的进位输出作为下一位全加器的进位输入,依靠八个FA(Full Adder)或者一个HA(Half Adder)和七个FA组成
因为第一位没有进位输入所以可以使用HA
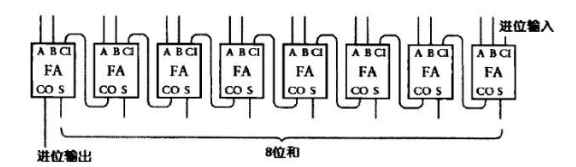
溢出 StackOverFlow
上面的八位行波进位加法器在最后一位仍然有进位输出,而这个加法器在执行是输出了该进位这说明加法运算超出了表达的最大范围255,导致数值溢出。这往往会造成一些程序bug,例如
1.吃豆人256关崩溃
2.核平甘地(貌似是传闻)
游戏中角色有和平属性(侵略指数),其中角色甘地的和平属性为1,而其中选择的阵营又有一个会导致角色和平数值-2,于是如果玩家或ai操控甘地角色选择了该阵营则为导致数值从1-2溢出到最高的255,于是甘地成为了游戏中最狂热的战争狂人。具体的表现就是喜欢拿核弹砸玩家的脸

超前进位加法器
现代计算机上使用的加法器,对普通全加器进行改良后的并行加法器
ALU可实现操作与结构
ALU可实现的八种基本数学运算
- 加法 ADD
- 带进位的加法 ADD WITH CARRY
- 减法 SUBTRACT
- 带借位的减法 SUBTRACT WITH BORROW
- 增量 INCREMENT
- 减量 DECREMENT
- 数字无改变通过 PASS THROUGH
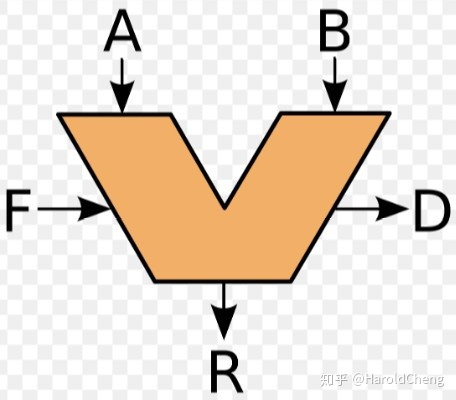
AB是输入(8位),R是输出(8位),F是用于告诉ALU执行什么操作的操作码(4位),D是输出的标志(1位),八位ALU通常有三种标志
- 溢出标志,操作溢出
- 为0标志,通过一堆或门对每个数字进行判断得出是否全部位为0
- 为负标志,相减看是否大于0判断
寄存器和内存
存储
随机存储器(RAM)在通电时才可存取数据,而不通电也可长期存储数据的则是持久存储(PMem)
一位数据存储
只需要在AND,OR门输出上接一条回路到输出即可实现存储0和1
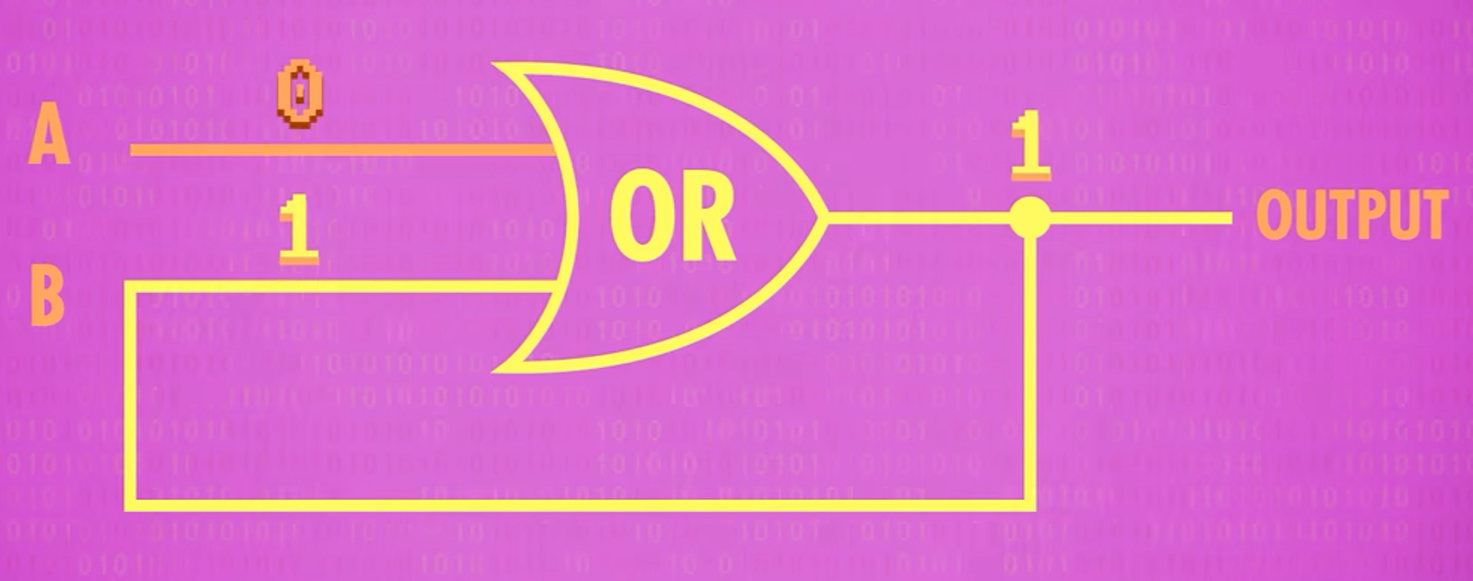
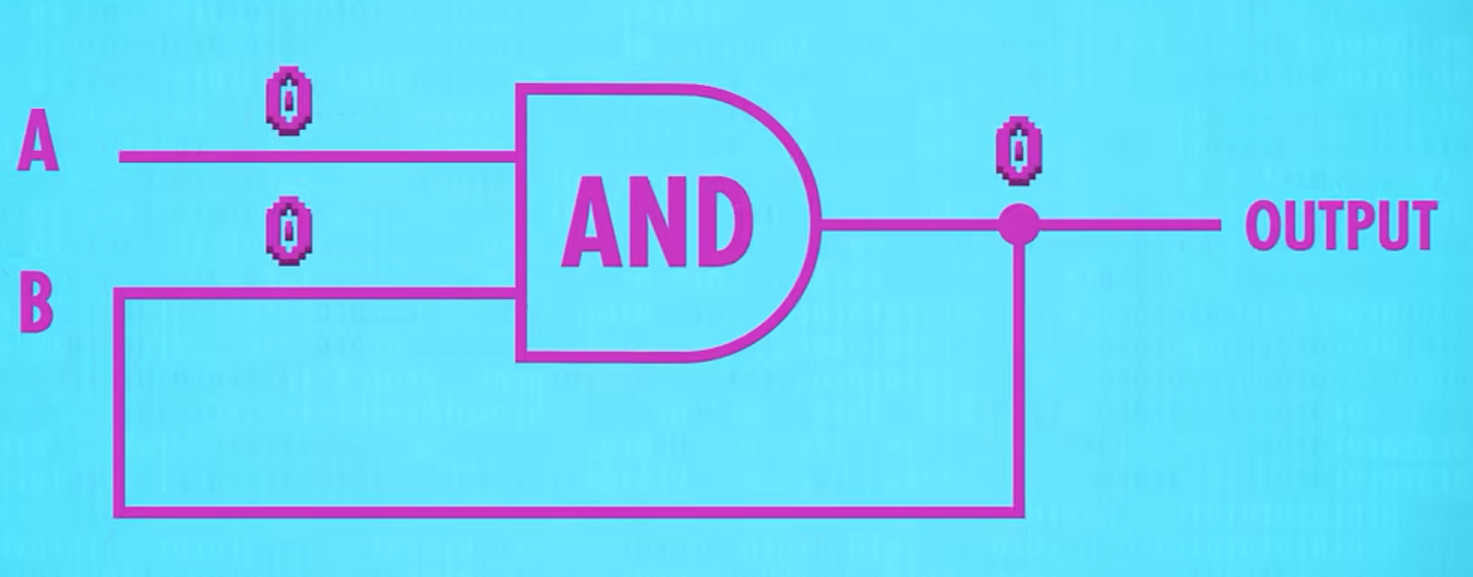
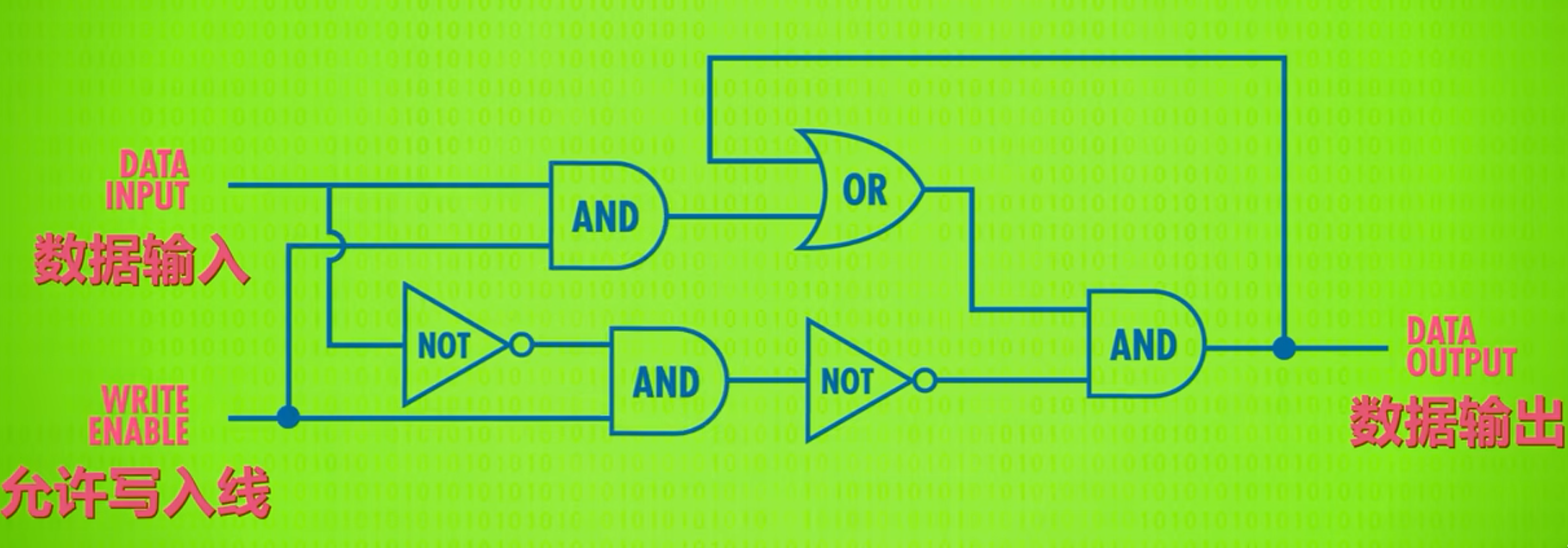
锁存器 LATCH
组合逻辑门即可实现AND-OR锁存器(AND-OR LATCH)
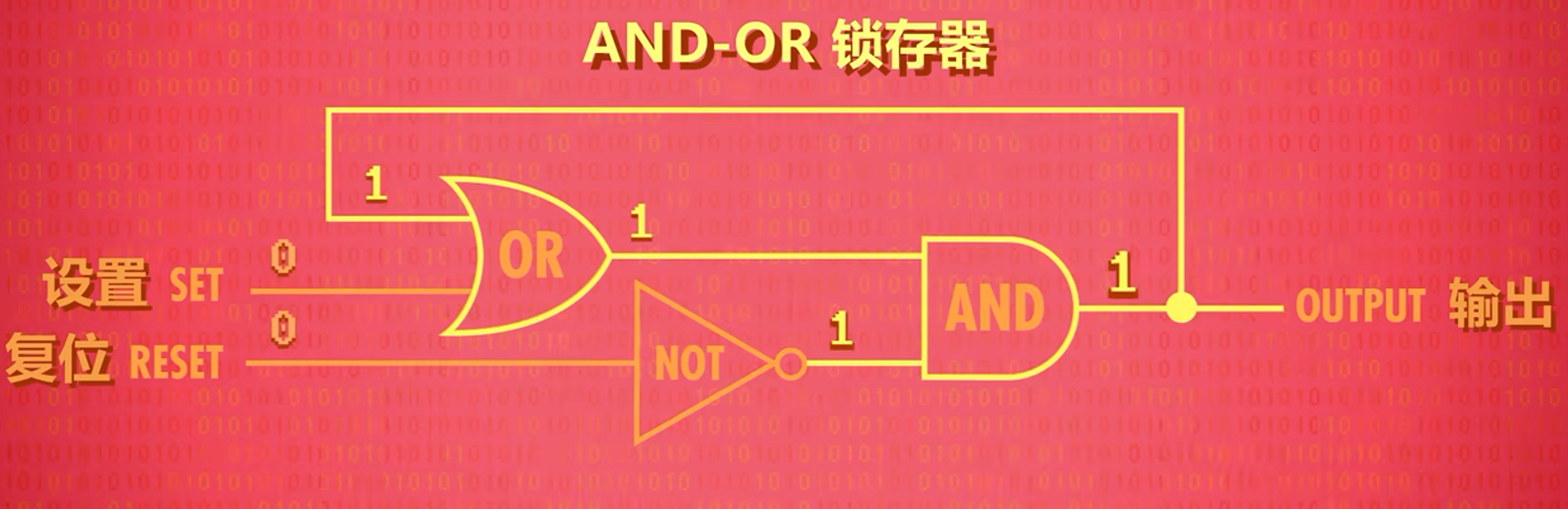
其中SET的0作为初始值一开始被默认初始化存储在锁存器中,不复位(复位设为0)的情况下SET设为1即可将SET值存储于锁存器中。无论SET当前输入与锁存器中存储着什么,复位(复位设为1)后都会将存储内存与输出都初始化为初始值0‘
即SET控制锁存器存储并输出1,RESET控制锁存器存储并输出0
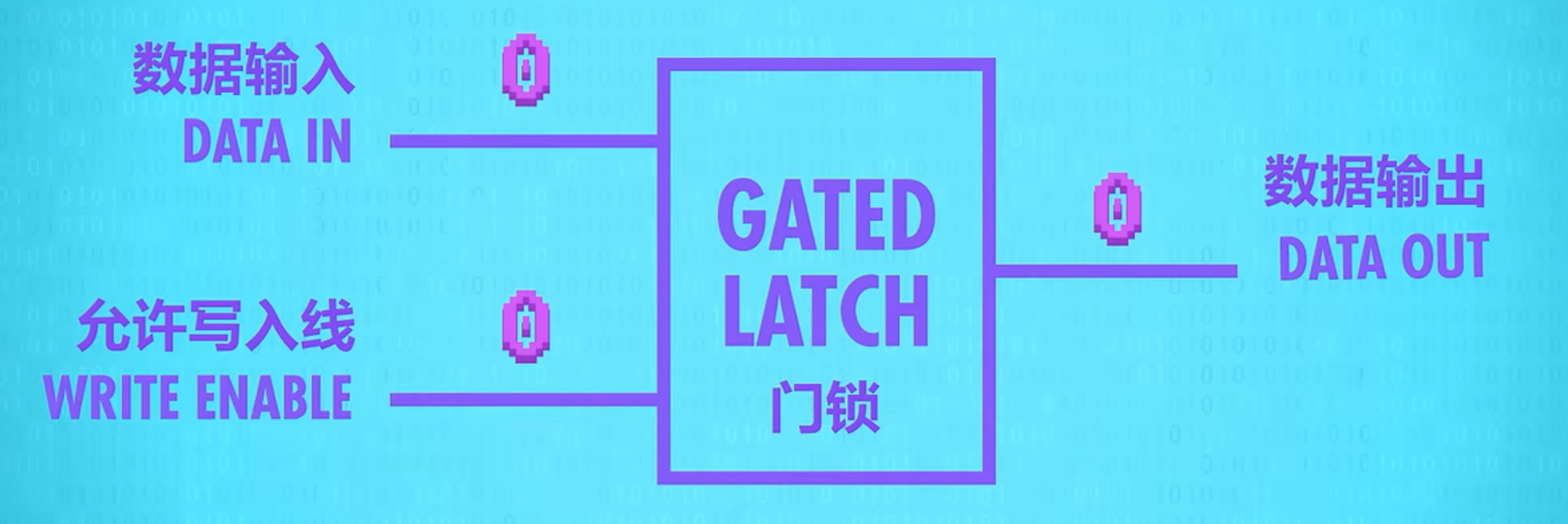
门锁 GATED LATCH
WRITE ENABLE控制数据是否可写,可写时通过DATA INPUT输入写入相应数据,不可写时则存储了数据可写时DATA INPUT写入的数据(初始值0)。
寄存器 REGISTER
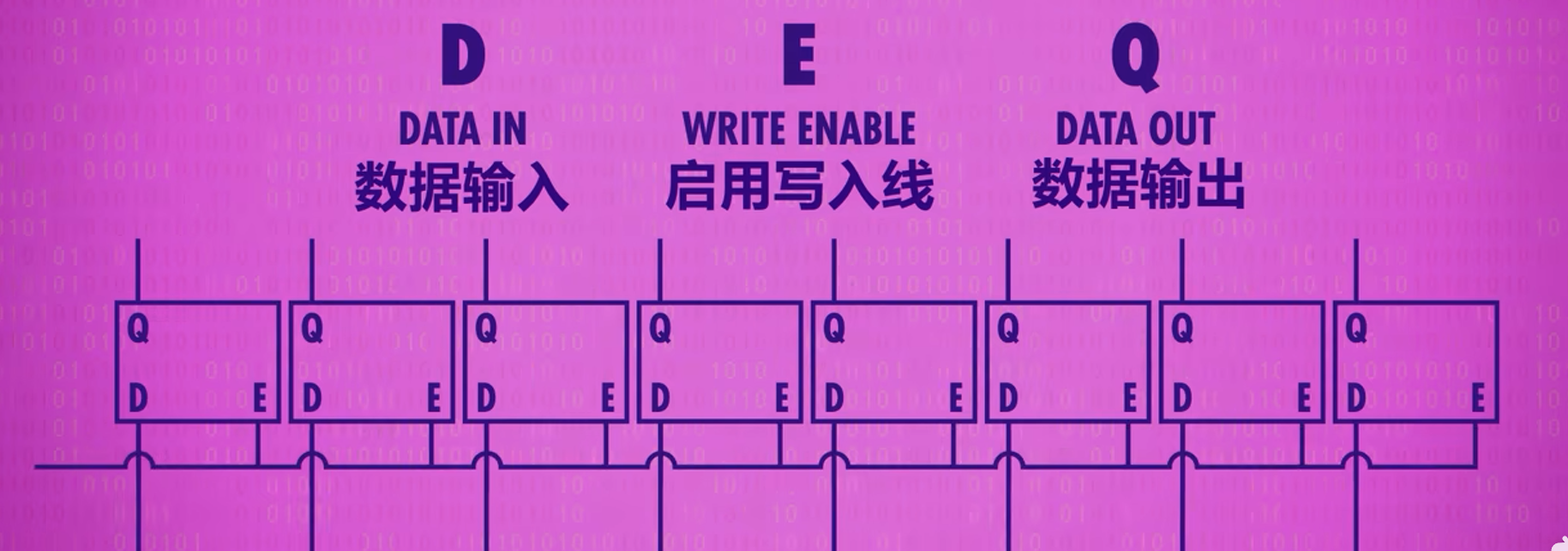
寄存器是多个锁存器的集合。一个锁存器存储一位数字,想要存储多位数字的寄存器包含锁存器的个数称为位宽WIDTH。8位寄存器用一根总线(BUS)控制所有锁存器的WRITE ENABLE。则总用线为8条输入8条输出加1条总线等于17条。而为了避免并排放置锁存器增加线路造成的空间浪费,通常使用矩阵排列锁存器的方式来减少线路使用以减少空间。

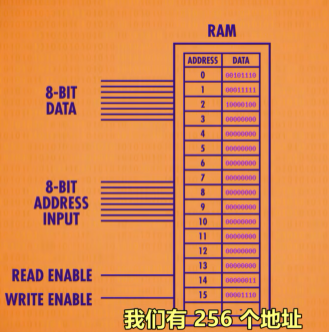
启用单个锁存器只需要打开相应的行线和列线,确保WRITE ENABLE允许写入线为1才能写入数据。那么256位寄存器只需要 16根行线 + 16根列线 + 1根数据线+ 1根允许写入线+ 1根允许读取线
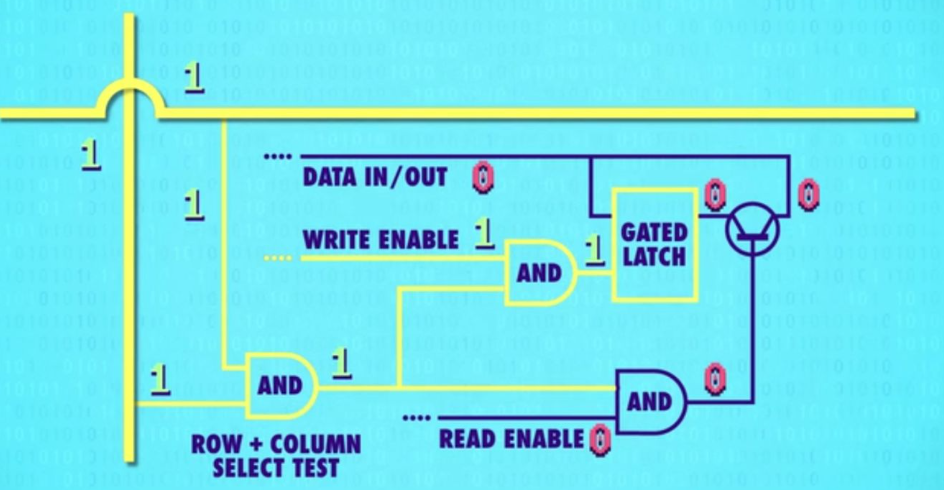
指定寄存器中行列
使用地址描述寄存器的行列,对于256位寄存器(16*16的矩阵)只需要两个4BITS的行地址和列地址即可。如选择4行2列则地址为”01000010“
为了实现将地址二进制位传给寄存器,需要使用到多路复用器MULTIPLEXER,输入4BITS的二进制地址后会选择某一行或某一列的线将其设为1

内存
接着抽象出一个256位内存,8位地址分别是行的4位与列的4位
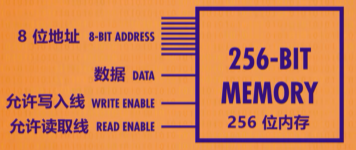
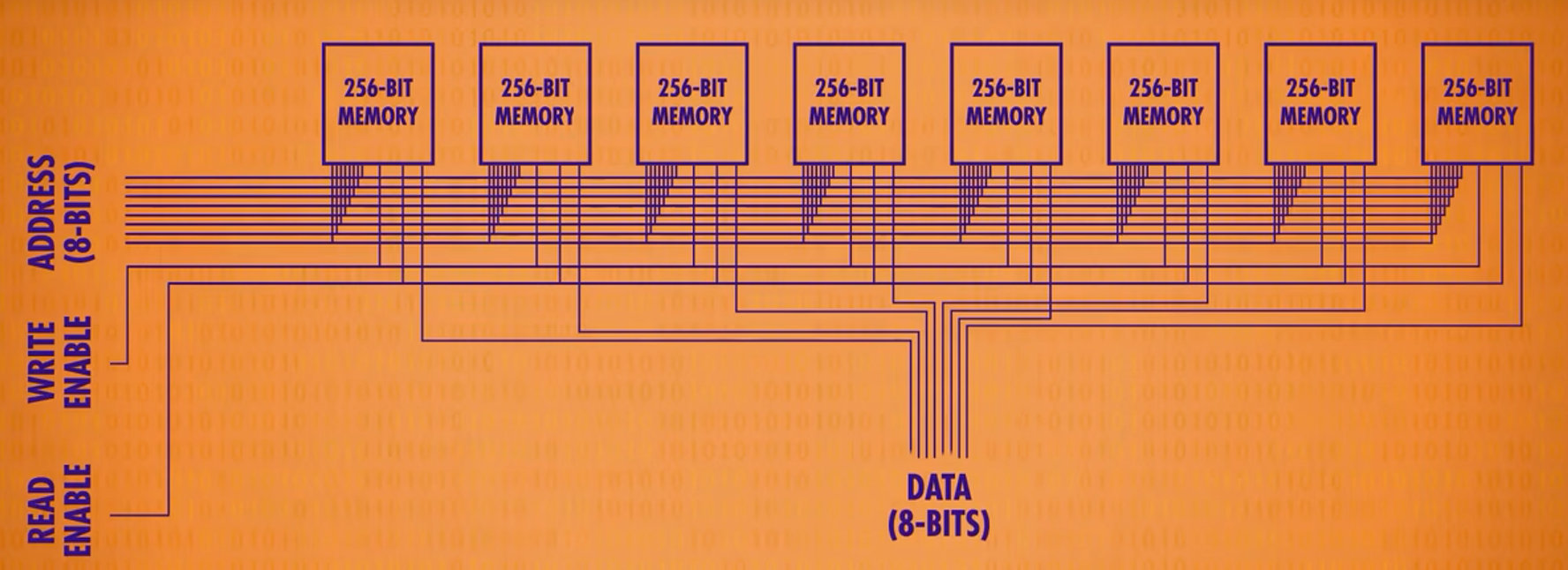
而单独一个内存也只能存储256bits的数据,也做不了甚么,于是进一步并列组成,将8个256bits的内存组成一个可以存储256byte(1byte = 8bits)的RAM。
最后将此进一步抽象为一个整体的可寻址内存,现代计算机的内存都是采取类似的方法迭代扩大来扩大内存规模。而内存地址增多,地址的bits也需要不断增加。
以上是一块用锁存器组成一步步抽象出来的SRAM(静态随机存取存储器)
中央处理器CPU
CPU | Central Processing Unit 组成与用处
前面的ALU(算术逻辑单元)用于执行计算,REGISTER(寄存器)用来存一个很小的值,RAM(内存)用于在不同地址存大量值,而除了独立于CPU的内存外加上时钟与其它组件组合起来就可以基本组成一个CPU。而组成这些组件时会忽略部分细节的抽象化,用一条线链接两个组件时这条线只是所有必须线路的抽象,而这种抽象的高层次视角称为微体系架构。
CPU负责执行程序,而程序是指令的有序集合,根据指令的不同CPU会执行不同的操作。如计算指令,CPU会让ALU进行数学运算,也可能是内存指令,CPU会和内存通信,然后读写值。
对CPU支持的所有指令分配一个id组成指令表,在假设的下表中有四个指令,前四位bit存储的操作码表明当前指令的操作,后四位则是操作涉及的数据来源(内存地址或寄存器)。
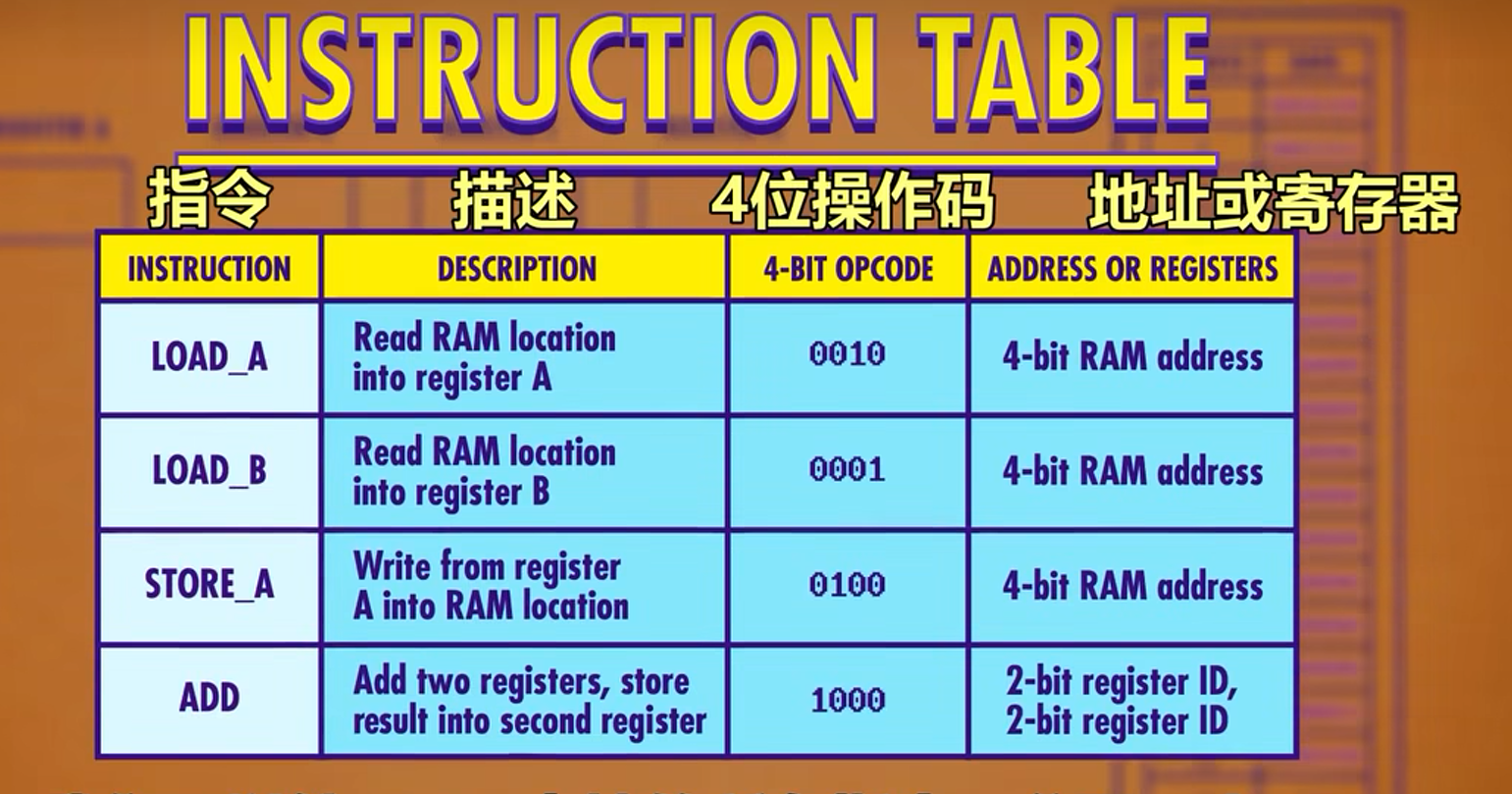
而CPU指令的组成还需要两个寄存器,分别存储当前指令与指令的内存地址
- 指令地址寄存器 : 存储当前指令的内存地址
- 指令寄存器 : 存储当前指令
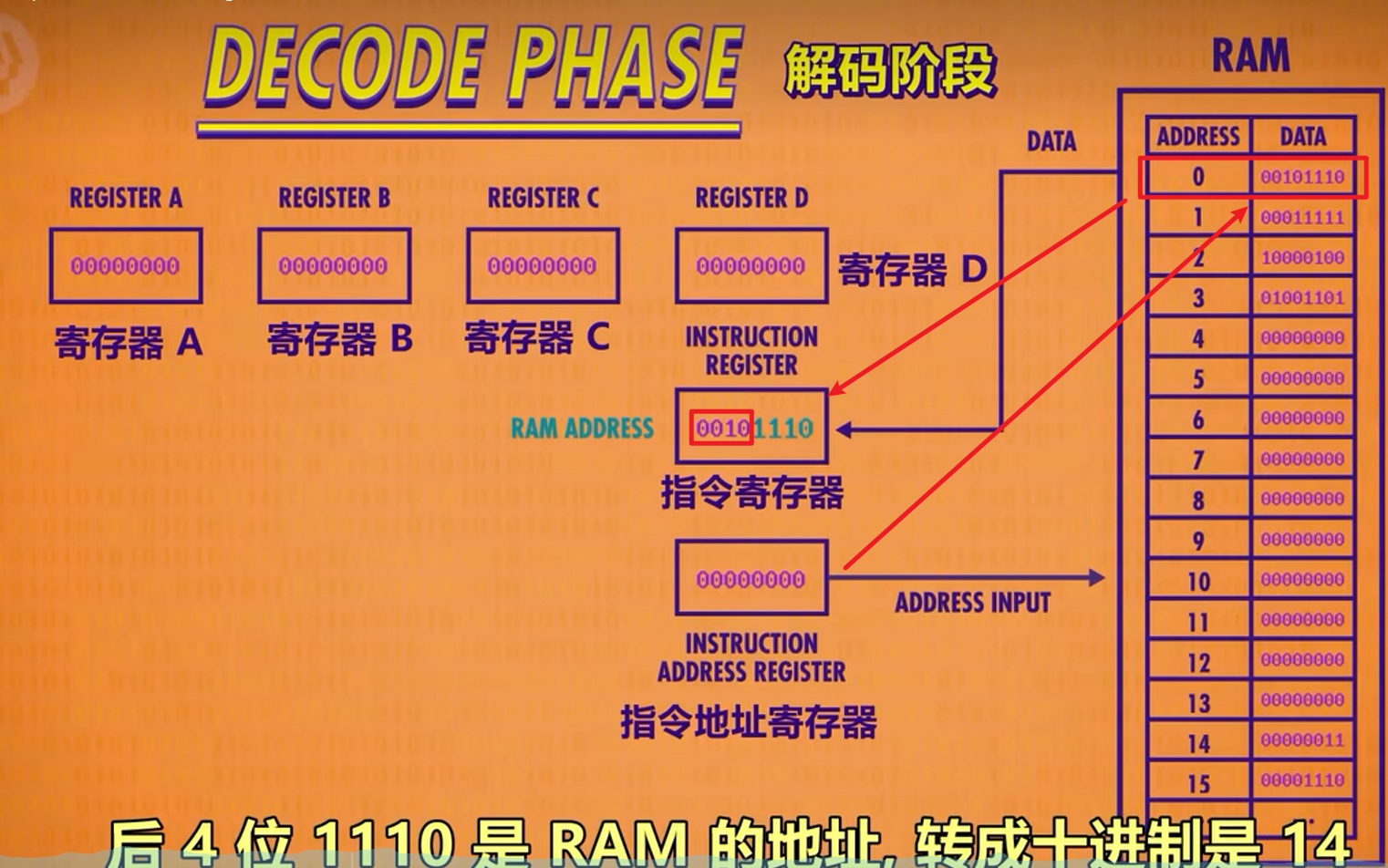
上图为假设在RAM中已存放程序然后执行的流程。指令的运行有三个阶段,分别是取指令,解码和执行。
指令运行流程
- 取指令
- 指令地址寄存器
链接内存,内存取得指令地址内容将对应地址数据内容传到指令寄存器中(图中内存将第一位内容00101110传入指令寄存器)- 解码
- 指令由
控制单元根据指令表解码(控制单元由逻辑门组成,用于判断指令),从前四位匹配得出当前是LOAD_A指令,将后四位内存地址中的值(RAM[1110] = RAM[14] = 0011 = 3)存入A寄存器中- 执行
- 指令判断后根据需要打开允许写入和读取线等将数据按照指令执行。执行完毕后
指令地址寄存器+1以进行下一个指令。执行就结束了
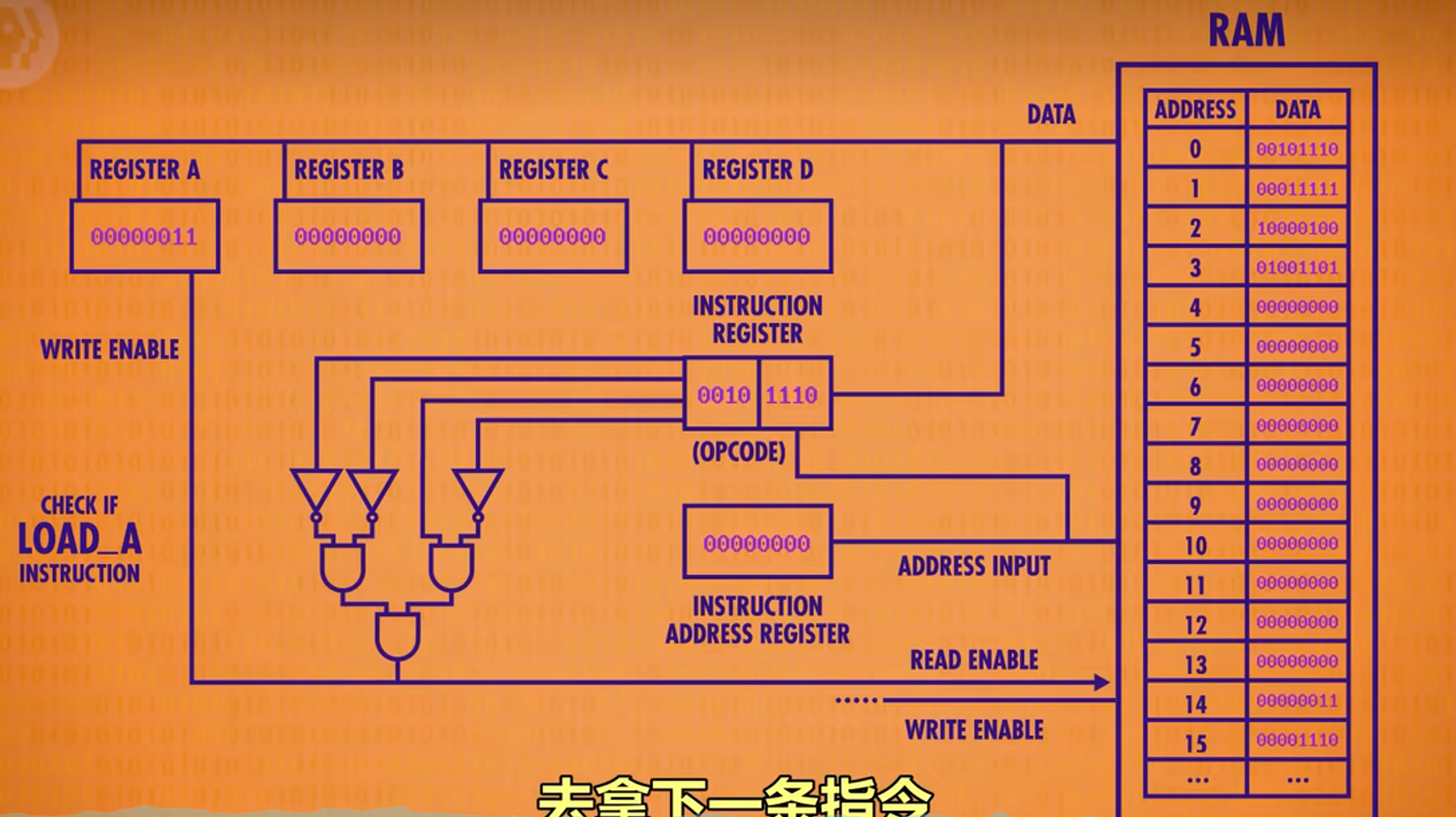
因为判断每一个指令需要相应的逻辑电路,所以这里将这些抽象为一个整体部件控制单元(Control Unit)
A NEW LEVEL OF ABSTRACTION

为了处理运算指令,还需要组合上ALU。例如相加操作,控制单元接受指令和数据后,将数据和操作码输入ALU,然后ALU将输出值传回控制单元,关闭ALU,将输出值传入指定的寄存器中。最后指令地址+1结束该次循环。
以上指令运行流程一次的速度就称为时间速度单位时Hz,1Hz代表一秒执行一个周期。而cpu中是自动执行,时钟以精确的时间间隔触发电信号来确保cpu按照一定间隔自动执行指令。
CPU超频提高时钟速度以提升CPU性能但过度超频容易过热,降频降低时钟速度以降低CPU性能以省电。
指令和程序
指令集
指令集是对于特定CPU存储在其内部的固定程序,通过指令集中的不同指令按照一定顺序排列就可以实现不同的程序。这里拓展上次的四条语句
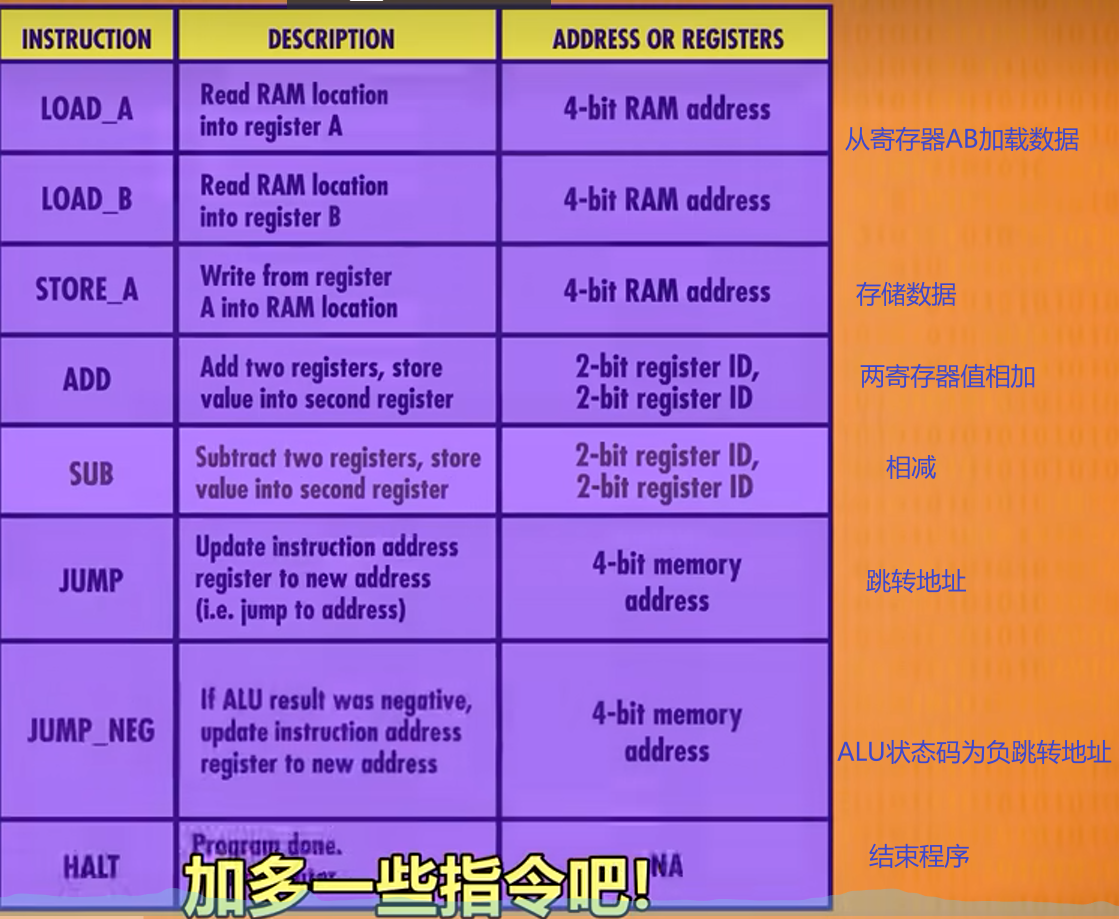
循环和条件指令
其中JUMP_等命令适用于控制程序循环,类似c语言的goto(goto不被建议使用)。例如JUMP_NEG指令会根据ALU中的计算的结果(此处为小于0)决定是否跳转,除了JUMP_NEG判断负数跳转外,包括JUMP IF EQUAL(相同跳转),JUMP IF GREATER(大于跳转)等都可以使程序实现循环执行的功能。
指令长度
此处假设cpu指令都是8位,操作码占了4位,最多也只能代表16个指令。相对如今计算机来说非常少。现代计算机有两种方法来解决
- 用更多位代表指令,例如拓展至32位或者64位指令长度
- 或者使用
可变指令长度,例如一些指令后面不会跟随数据的如HALT,就会立马执行节省后面的指令位,而执行到JUMP等携带数据的指令能利用到之前节省的空间(个人理解),携带数据的指令后面的被称为立即值(立即数),这样设计,指令可以是任意长度。
高级CPU设计
过了下一章之后就偏软件了,虽然也很核心(例如数据结构啥的)但估计会筛去一点觉得不重要的
为CPU提速
为CPU提升速度早期计算机到现代计算机厂商和科学家们发明了各种新技术来提高性能。
-
减少晶体管切换时间
- 早期提速的方式便是
减少晶体管的切换时间,使晶体管组成了逻辑门,ALU以及各种部件
- 早期提速的方式便是
-
利用复杂电路实现算法
- 例如除法和乘法需要程序多次运行减法和加法,为了省去循环的功夫,现代cpu直接在
硬件层面上设计了除法等复杂电路以节省某些运算。让cpu更大更复杂,但也加快了运行速度
- 例如除法和乘法需要程序多次运行减法和加法,为了省去循环的功夫,现代cpu直接在
-
给CPU增加缓存
- RAM是CPU之外的独立组件,通过总线(Bus)传递数据,为了避免数据传输带来的延迟,解决的方法是为CPU
增加一点RAM作为缓存。读取时RAM将一批数据提前传入CPU缓存,这样处理的时候CPU直接从离得近的缓存中获取数据就比从RAM中获取数据要快
- RAM是CPU之外的独立组件,通过总线(Bus)传递数据,为了避免数据传输带来的延迟,解决的方法是为CPU
如果想要的数据已存在缓存中则叫做
缓存命中,否则叫做缓存未命中。缓存也可以作为临时空间存储一些运算过程中的中间值,适合长/复杂的运算。但是计算完后的值想要存储会先存入缓存中,而缓存中的值可能还有运算的中间值导致缓存和RAM内数据不一致,因此缓存里的数据要对RAM里的数据进行同步更新。对此缓存里的每块空间都有一个叫做脏位的标记声明该数据是否修改过。同步更新一般是发生在缓存满了,又需要缓存时。这时会检查缓存中的脏位,如果是脏的就将数据写回RAM中。
指令运行方式
还可以通过不同的指令运行方式以提升CPU速度。
- 顺序串行执行
- 严格按照顺序上一条命令结束才执行下一条命令
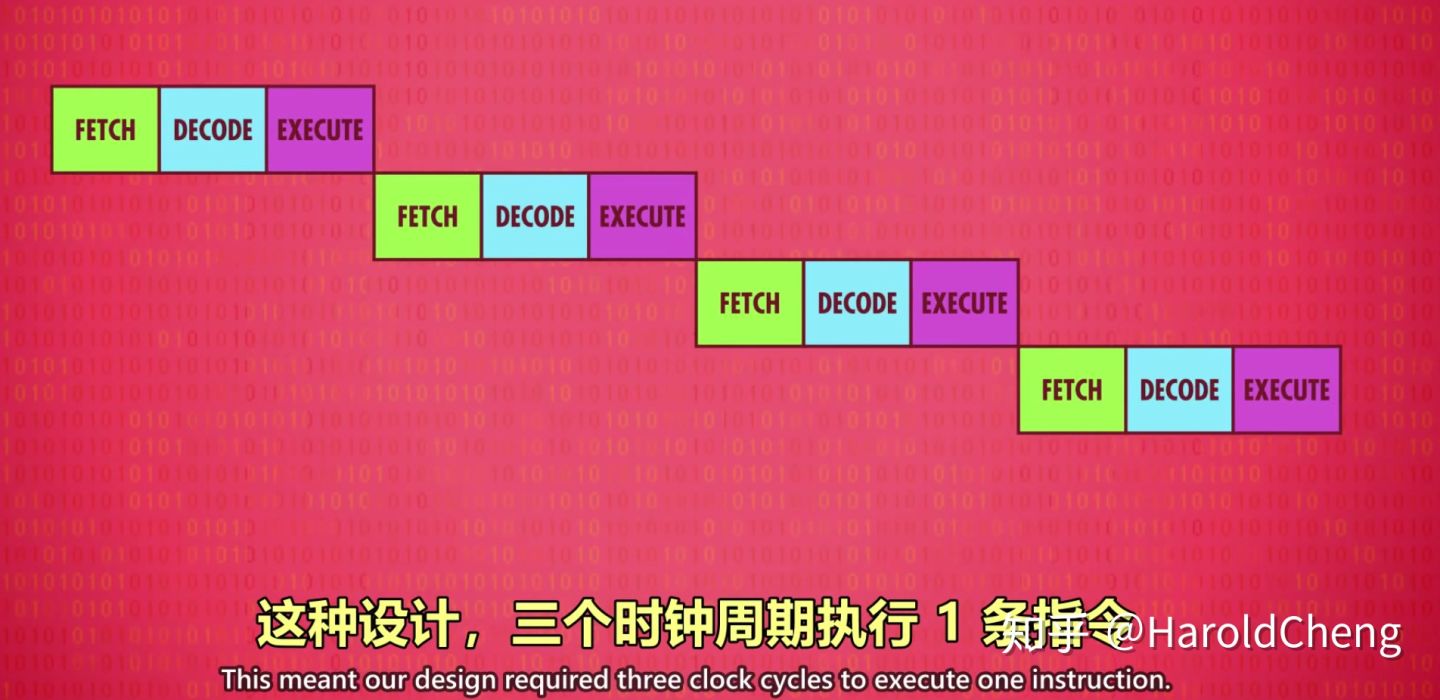
- 顺序并行执行
- 在上一条指令执行时就处理下一个指令的解码步骤,下下条指令的读取步骤。

- 乱序执行
- cpu进一步
动态排序有依赖关系的指令,最小化这种流水线停工时间,非常复杂但是高效率。类似于贪心算法中的区间调度问题
- cpu进一步
- 推测执行 | 分支预测
- 简单的处理器看到JUMP指令会等待JUMP的条件值再继续执行,而高级的处理器会
提前猜测哪个条件可能大,提前把指令放在流水线上,如果猜测正确立即执行,错误则清空刚才加载的指令重新加载。而为了减少清空次数提高猜测准确率的方法就是分支预测,现代计算机的猜测准确率高达90%
- 简单的处理器看到JUMP指令会等待JUMP的条件值再继续执行,而高级的处理器会
cpu上还可以使用超标量处理器SUPERCALAR PROCESSOR一次性处理多条指令(类似多线程)。为出现频率很高的指令加多几个相同的电路,ALU执行。
而以上的流程是针对一个流水线CPU来说的,另一个方法是运行多个指令流。CPU芯片内的多个独立处理单元(多核)就像有多个CPU能够合作运算(共用一个CPU的缓存)。如果多核还不够就用多个cpu
早期编程方式
可编程纺织机
用孔板控制的可编程纺织机,用于为衣服织出复杂图案

穿控卡纸编程
根据穿孔卡孔有无决定数据有无的穿控卡纸编程,存的是数据而不是程序,曾用于美国人口普查,穿孔表示信息状态。

插线板编程
通过插电线控制机器不同部分传数据和信号的插线板编程,用于使计算机正确执行不同运算,但是更换程序换线流程在当时计算机上非常繁琐,机电计算机普遍采用

冯诺依曼体系结构
现在计算机的基础-冯诺依曼体系结构,将程序与所需数据,程序产生数据都存在内存中。早期冯诺依曼结构计算机仍旧使用穿孔纸卡的方式将程序指令传入内存中,也使用打孔的方式输出程序运行之后的结果。冯诺依曼结构组成包括
- 处理器(包括ALU)
- 数据寄存器
- 指令寄存器
- 指令地址寄存器
- 内存(存数据和指令)
面板编程
用一大堆开关和按钮控制,通过开关进行二进制代码编写运行程序。面板上的指示灯则表示函数的状态和内存的值

编程语言发展史
机器语言
使用二进制(机器语言,机器码)编写的程序,早期编写时将对应的操作码编写成操作码表,写入程序前用操作码在纸上写出相应的伪代码,写入时对照操作码表喂入计算机运行。
汇编语言
将每个操作码分配一个方便记忆的助记符,助记符后紧跟数据形成完整指令。于是可以使用诸如LOAD_A 14等形式编写代码而不是101010这样子写。
写成的汇编语言通过汇编器来通过输入助记符等文字指令自动转换成二进制指令。
高级语言
A-0语言是相比汇编语言更高级的语言,一行高级语言可能会转换成几十条二进制指令。同时当时还出现了编译器的概念:将高级语言转换成汇编语言或CPU可以直接执行的机器码(机器语言)这种低级语言。高级语言抽象了与底层硬件如内存,寄存器交互的细节。出现了如变量这种代表内存地址的抽象。
例如图中Python和汇编语言的对比,Python不需要像汇编一样考虑从哪个内存位置中存取值,计算结果存储在哪个寄存器等问题。

而主宰了早期计算机编程的语言Fortran语言比同等的手写汇编代码短20倍,并且Fortran编译器(Compiler)会把代码转成机器码,虽然运行速度会慢一点,但是代码编写速度会大大提高。
通用编程高级语言
早期大部分语言和编译器只能运行在一种计算机上,升级电脑后可能导致所有代码需要重写(现在不少语言就为了兼容老版本会留一些兼容性处理,但不是一直兼容,会标记代码过时或许将在未来某个版本废弃)。于是当时人们组成联盟开发了一种通用商业语言Cobol,这种语言使当时所有编译器都可以接受相同的Cobol代码。
- 1960年代 Algol, Lisp, Basic
- 70年代 Pascal, C, Smalltalk
- 80年代 C++, Objective-C
- 90年代 Python, Java, Ruby
- 新千年 Swift, C#, Go
编程原理-语句和函数
通用的语法和函数
语句和语法
语句是指提前设定语法规则后在编程语言中能表达一定含义的编程命令。以下是一般的赋值语句,使用Python实现
当下大部分的编程语言都是自顶向下的顺序执行,上面的代码就是从上至下创建了三个变量abc,并将对应的值赋值给了相应的变量
此处赋值语句只需要注意 变量名=变量值这样的形式即可
a = 114514
b = 1919810
c = 42
然后顺序执行还不足够,还需要相应的流程控制语句控制代码执行的顺序等状态。最常见的流程控制语句如条件判断语句if简单说就是如果什么为真就做什么,否则就做其余什么在if语句内条件为真则执行if下面的代码,否则执行else下面的代码

除了if这种只能判断一次的语句,还有可以多次循环判断的语句while, while判断条件为真时则重复执行内部代码
a = 8
# 程序输出8 7 6 5 4
while a>3:
print(a)
a = a - 1
# 赋值为变量自身当前值-1
或者for循环结构,一般是判断当前变量大小进行指定次数的循环
# range生成相应范围整数数组[0, 1, 2, 3, 4]
for a in range(5):
print(a)
# 输出0 1 2 3 4
for(i=0;i<5;i++){
console.log(i);
//js代码,输出0 1 2 3 4
}
函数
将代码封装成函数是将代码语句封装隐藏程序复杂度与提高复用度的方法。即将重复的代码抽象成直接调用的函数语句有些语言也称为方法或子程序。类似模块化,将一些底层的东西封装起来只需要知道其输入,输出等状态。内部细节不需要特别在意。当前的低代码平台感觉也是同样的逻辑,于是现在编程语言中大部分语言都不需要自己编写代码实现数学函数,例如求幂,角度弧度互换等基本都已经被专业人员预先写好了(一般被预先写好封装的代码函数集合叫做库Libraries)。当然到算法就不可避免的需要自己编写一些算法的实现,如快速幂
// n代表指数,m代表次幂
private static int pow(int n, int m)
int res = 1;
int base = n;
while(m != 0) {
if ((m&1) == 1) {
res = res * base;
}
base = base * base;
m = m >> 1;
}
return res;
}
算法入门

算法是用于解决某种问题的具体方法,解决方法通常关注所需要的时间和所需要的空间两个因素。
排序算法
常见的算法可以说都是在排序,常见的顺序如升序 1 2 3 4 ,降序 4 3 2 1 以及各种特定要求下的顺序… 最常见的算法如冒泡排序,希尔排序,归并排序,选择排序,快速排序,插入排序等(虽然之前学过一个月算法,但也只记得冒泡怎么写了)。视频中选择排序就是先扫一遍数据,最小的放最前面,然后从第二位开始重复扫数据放最小到第二第三第四位到数据末尾排好了。复杂度O(n^2)
复杂度又是个需要细讲的东西了,简单说就是用算法复杂度表示算法的执行效率,如单次操作一条语句即可完成程序,那算法复杂度就是O(1),如果需要循环整个数组(设数组长为n),那复杂度就是O(n)。这种就是大O表示法。其中n是指最优情况和最差情况的平均值,且忽略常系数取最高位。括号中的值描述了算法的增速趋势
如选择排序,最优情况下数据本身是升序,那就不用排序,全部逆序的最差情况就需要执行交换操作n-1次,耗时约为 (n-1) + (n-2) + (n-3) + … + 1 ,则总计T = [n*(n-1)]/2 = (n^2)/2 - n/2 取最高位忽略常系数为n^2
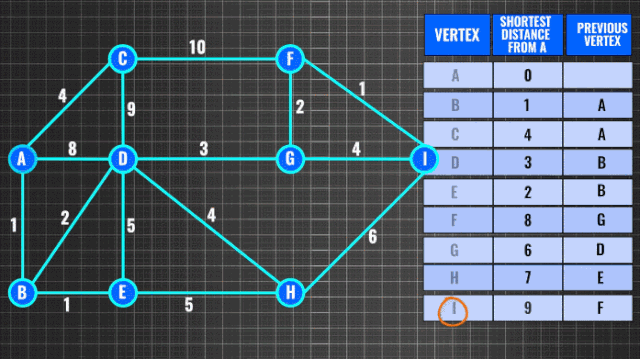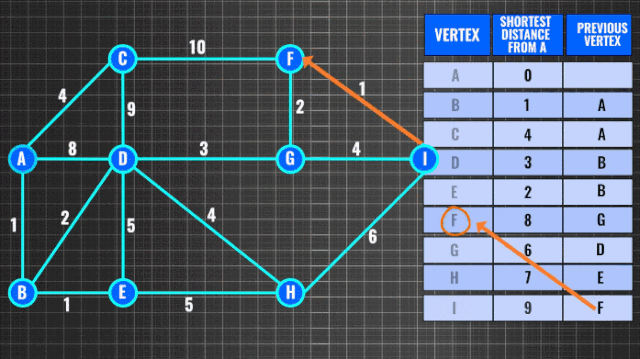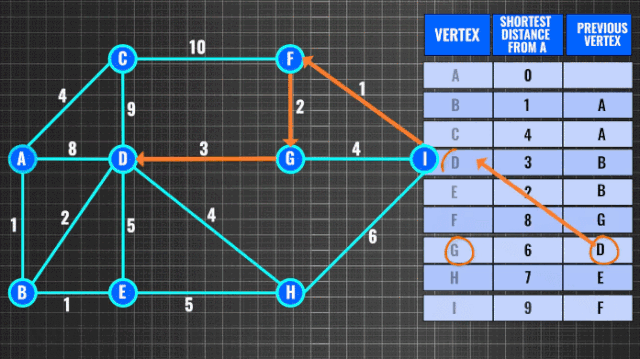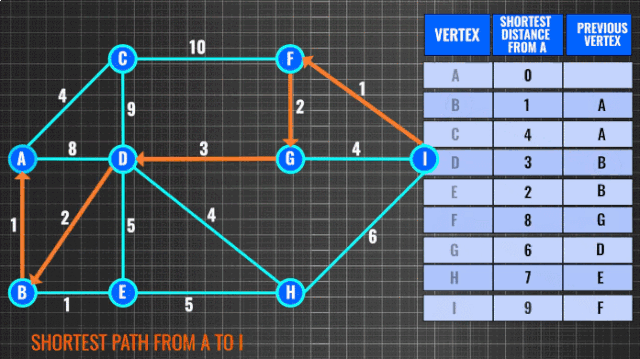
图搜索也是常见的问题之一,求有权图最短路径通常使用Dijkstra算法,复杂度O(n^2)
等下次蓝桥之前或许会提前再次夯基础用算法4复习做个相关的算法笔记。
数据结构
数据结构用于格式化要处理的数据,方便算法统一处理读取。
常见数据结构
- 数组 Array
- 字符串 String
- 矩阵 Matrix
- 结构体 Struct
- 指针 Pointer
- 节点 Node
- 链表 Linked List
- 队列 Queue
- 栈 Stack
- 二叉树 Binary Tree
- 红黑树 Red-Black Tree
- 堆 Heaps
数组
数组在内存地址中表示为一组连续的内存空间,长度为10的数组arr可以使用 arr[0] ~ arr[9]的地址存储数值。数组变量本身一般表示的是首元素地址arr[0]。即创建数组后得到一个可访问连续左闭右开区间的容器,使用数组名[下标]获取数组内存地址引用以修改或获取值。
字符串
字符串是由字符组成的不可变数组,一般表示为"String"可以表现为['S','t','r','i','n','g',NULL]数组,末尾通常是空值NULL表示字符串末尾。
矩阵
大致可以看作嵌套数组,如
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
常用于处理图像,表格等情况
结构体
将多种不同类型的数据抽象在一起表示为结构体,类似于面对对象的感觉。
#incude<stdio.h>
// 定义结构体
struct{
int a;
int b;
} my_struct,my_test;// 结构体名字
// c语言程序入口
int main(void){
printf("Please input:");
// 获取输入设置参数
scanf("%d %d",&(my_struct.a),&(my_struct.b));
// 对象赋值,应该是引用传递
my_test = my_struct;
printf("%d %d\n",my_test.a,my_test.b);
}
链表
用到两个类型,指针表示一个指向内存地址的变量方便调用设置值,一个节点包括定义值和指向前后内存地址的指针(可选)。 节点也是一种定义的结构体,包括变量值和指针,多个连成的节点就叫链表。
链表的设计于相对数组开辟一串连续的内存空间,链表不用开辟连续的内存空间,因为节点指针可以自己指向别的内存地址。而数组连续的内存空间可以保证查询数据快(可以使用下标),而链表需要从第一个节点一个个往下一个节点的指针中递归查询。


队列和栈
队列和栈基于链表或数组都可以实现。队列是先进先出(FIFO)的数据结构,像排队一样数据在末尾入队插入,出队将队首的数据取出。栈像是羽毛球筒一样的先进后出(FILO)的结构,数据插入提取都是从栈顶(末尾)操作,想象一个羽毛球筒,入栈是扔进羽毛球叠到最后(栈顶),出栈则是倒出最后(栈顶)一个羽毛球。

树
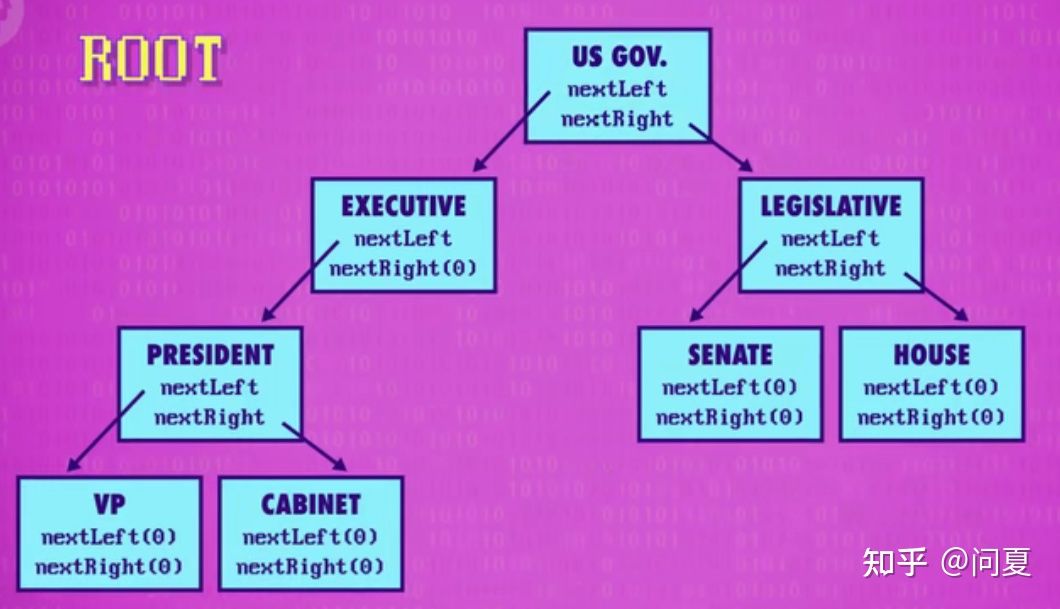
二叉树表现为一个节点最多拥有两个指针指向两个子节点,往下指向更多子节点,子节点又各自指向一个或两个子节点的树结构。最高的节点为子节点,其余都是子节点,妹有任何子节点的节点为叶节点。像是从上至下的有向图,从根到叶是单向的。
图
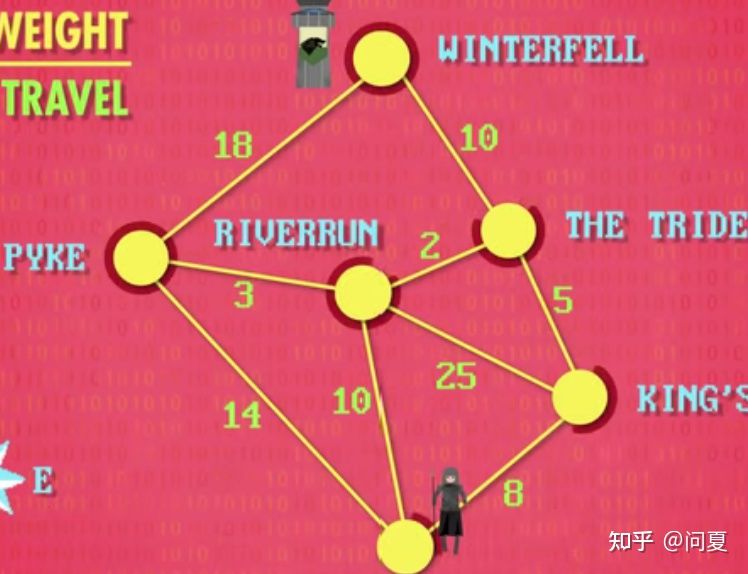
图是数据节点间通过边链接,边可以有权值和方向,通常是求一个节点到其它节点的最短路径啥的问题会用到图。
其余数据结构包括堆,树拓展的b+树,红黑树,哈夫曼树啥的希望有生之年能了解以下(
图灵
可判定性的问题
是否存在一种可以回答任何正确的逻辑语句正确与否的算法。
图灵机
图灵机是一台理论上的计算设备,有无限可以存储符号的纸带和读写符号的读写头以及一个保存当前状态的状态量。加上一组描述机器运行的规则,在理论上有足够的内存和时间可以实现任何计算(类似无限猴子)
停机问题
停机问题指是否存在可以在不执行某一问题的前提下判断图灵机是否会一直运算下去,即是否存在一个程序能够判断另外一个程序在特定的输入下,是会给出结果(停机)还是会无限执行下去(不停机)
而结论是没有这样的算法/程序, 即不是所有问题都能用计算解决
例如一个函数可以判断出另一个函数是否会停机
# 伪代码 Pseudocode
def is_halt(program, input) -> bool
# 如果程序program有返回则返回true表示会停机,无返回则返回false表示不停机
# 无限循环函数
def loop():
while(True):
pass
def fuc(inp)
if inp == 0:
return
else:
loop()
# 停机
is_halt(fuc,0)
# 不停机
is_halt(fuc,1)
# 以下是利用自我指涉证明停机问题无法解决的hack函数
# 自我指涉一般指自我描述
def hack(program):
if is_halt(program,program):
loop()
else:
return
'''
调用时会引发矛盾和悖论 如果停机程序is_halt认为hack(hack)会停机
那么实际上是不断递归循环调用自己不停机
如果认为hack(hack)不会停机,那么返回空输出(return) ,那么实际上hack(hack)会立即返回结果
'''
is_halt(hack,hack)

人工智能与图灵测试
图灵测试指如果计算机能让人类相信它是人类才算是智能。人工智能就是制造智能的机器,更特指制作人工智能的程序。人工智能模仿人类的思考方式使计算机能智能的思考问题,人工智能通过研究人类大脑的思考、学习和工作方式,然后将研究结果作为开发智能软件和系统的基础。
软件工程
将大型软件的代码进行科学管理的一门学科。
面对对象
这里面对对象是将代码结构化优化层级管理也能隐藏复杂度的一种方法。如将代码打包成函数,这里将相关代码和函数都打包在一起打包成对象。如
class Person{
String name;
int age;
public void setAge(int age){
this.age = age;
}
public int getAge(){
return this.age;
}
}
//将person相关属性函数封装成对象
Person p = new Person();
p.setAge(24);
System.out.printf("%d岁,是学生", p.getAge());
一个对象可以包含其他对象,函数和变量。需要访问对象中包含对象的某个函数时就需要通过该对象不断向内寻找Person.Organ.Hand.CatchSomething(target),这样将底层代码封装提供继承以隐藏复杂度(当然学习代码编写还是要看源码是怎么实现的)
开发文档
面向对象可以将代码模块化使人们可以直接使用它而不关心内部细节,这样子团队协作就可以专注于自己的模块使多人能够同时工作于一个大项目。而开发文档就是用于协定统一开发标准的一种方式。开发完项目后,团队需要完成解释文档,帮助理解代码都在做什么,以及定义好程序编程接口(API)
API帮助不同程序员合作且不需要知道具体细节只用知道调用方式。API还控制项目哪些函数和数据开放给外部访问调用,哪些只提供内部访问使用。
面向对象的核心是隐藏复杂度和选择性公开代码功能。
private String str = "这个字符串外部无法调用"
// 这个方法外部可调用,这样避免外部直接调用到程序内部的变量 方便进一步处理数据等操作
public String void getStr(){
return this.str;
}
集成开发环境IDE
现代软件的开发,一般需要借助开发器。开发器集成了编译、调试、整理代码等功能,因为集成了所有的东西,因此叫集成开发环境,简称IDE(Integrated Develop Environment)
如果代码编译时出现错误,IDE会定位出错误代码并给出提示来解决问题。运行时也可以通过打断点等方式来调试debug。
源代码管理
源代码管理也叫版本控制,大型程序都有源代码管理,他们将代码放到另一个称为代码仓库的服务器上可实现远程开发多地协作的操作。因为放在远程服务器做着代码管理,代码出现错误时也可以通过备份找到未修改前的版本并定位出是谁修改了哪里的代码。通常使用git,svn等工具进行版本控制。

测试
测试代码是相当重要的一环,测试一般由个人或者小团队完成。测试又统称为质量保存测试,简称QA,它需要严格测试软件的各方面并模拟各种情况看看软件会不会出错。特别是某些金融,安全相关的地方更是需要特别注意。程序在发布前往往会有多个版本,beta版本是接近完成可以面向大众进行免费测试的版本,而alpha版本则是比较粗糙用来测试效果的版本。
集成电路与摩尔定律
集成电路的出现
一开始计算机由独立的部件通过线路连在一起组成(即分立元件)。因为元件都是分立的所以计算机体积非常大而且昂贵。而解决方法就是将计算机所有元件集成,将多个组件整合在一块变成一个独立元件,这就是集成电路IC(Integrated Circuit)

印刷电路板 PCB Printed Circuit Board
为了解决集成电路仍需通过电路连接制造计算机的问题制造了印刷电路板PCB,PCB可以大规模生产而无需焊接或用一大堆线,它通过蚀刻金属线的方式将零件连接到一起。

光刻
光刻简单说就是把复杂图案印到如半导体等材料上,可以通过这种技术将复杂金属电路印在半导体上面以集成个多的元件制造复杂电路。
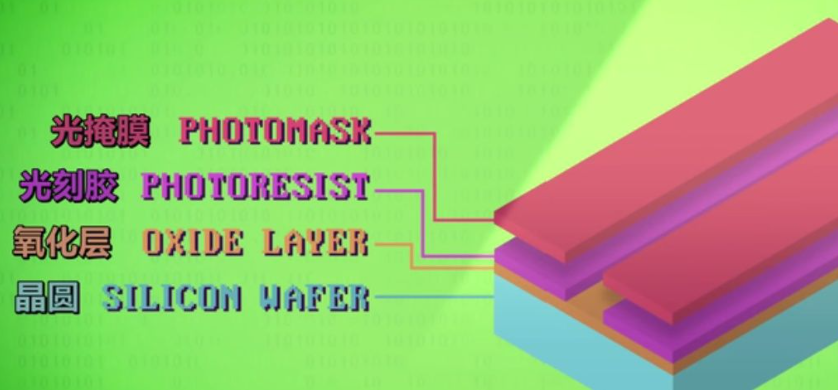
光刻机光刻电路的流程为,对于一块硅(晶圆),上面加氧化层,光刻胶和光掩模,然后用强光照射使光刻胶消失,把露出部分的氧化层清晰掉再清洗掉光刻胶。然后为了提高导电性将硅露出来的区域掺杂其余元素材料。于是就可以接着在氧化层上做通道以使用细小金属导线链接不同晶体管。通过类似的方式就可以集成出晶体管,电容,电阻等集成电路
摩尔定律
1965年,摩尔看到了趋势:每两年左右,得益于材料和制造技术的发展,同样大小的空间,能塞进两倍数量的晶体管。这叫摩尔定律。芯片的价格也不断下降。即集成电路上可以容纳的晶体管数目在大约每经过18个月到24个月便会增加一倍
但是摩尔定律现在也在接近极限,进一步做小,会面临两个问题。
- 用光掩膜把图案加到晶圆上,因为光的波长,精度已经达到极限。
- 当晶体管非常小,电极之间可能只距离几个原子,电子会跳过间隙,叫量子隧道贯穿效应
操作系统
批处理
早期计算机处理程序还是一个一个处理的,而现在可以运行多个。系统运行完一个程序后会自动运行下一个程序,不会浪费时间在更换程序上,因为早期计算机放程序的时间比程序本身运行的时间要慢,所以诞生了批处理这种可以一次性给计算机载入多个程序且运行完一个程序后自动运行下一个程序的技术。
操作系统简介与作用
操作系统OS(Operating System)是拥有操作硬件能力和特殊权限,能够运行和管理其它程序的一种程序。OS一般是开机第一个启动的程序。其它程序都由操作系统启动。
OS作为硬件和软件之间的媒介能够一套硬件适配不同软件,提供了API以抽象化硬件(设备驱动程序)能够使程序员不需要特意考虑外部设备的交互。且拥有能同时运行多个程序的多任务处理能力,通过中断和调度等技术在执行一个程序的同时让其休眠并执行其它程序。
虚拟内存
不同的数据在计算机中存放于不同的位置(内存地址), 为了更方便的追踪管理这些数据隐藏手动管理搜索这些地址的复杂性,操作系统将内存地址进行虚拟化即将一个虚拟的内存地址映射到实际的物理地址上。对一个程序来说所有地址都是从0开始的连续地址,实际被映射的实际地址可能实际并不连续。

操作系统会自动地将程序的虚拟地址与物理地址进行映射,这种机制使得程序的内存大小可以被灵活的增减分配,这种灵活增减内存大小的技术叫动态内存分配
而为了避免程序出错乱写数据,会给程序一定的内存范围,使程序不会将错误的数据写到其它内存下,这叫内存保护
分时操作系统
分时操作系统是为了让多个用户使用一台计算机而开发的系统,它通过让每一个用户只能使用CPU和内存的一部分,确保了不同用户数据的安全性。Multics是早期最有影响的分时操作系统,它从设计时就考虑到了安全的重要性(不希望恶意用户访问到不公开的数据),但是因为其系统过度设计导致内存占用计算机一半之多而未能流行起来。
Unix操作系统
Unix系统将操作系统分为两个部分
- 操作系统核心功能
- 内核: 如多任务,内存管理和I/O管理
- 一些有用的工具
- 相关程序,库

内存和储存介质
内存和存储器
内存Memory是非永久性保存数据,断电时会丢失,称内存为易失性存储器。而存储器Storage可以永久性存储数据。纸卡因为便宜耐用且不用电作为最早的存储介质,坏处就是读取慢而且只能写入一次,若要存储临时值用纸卡就不合适了。
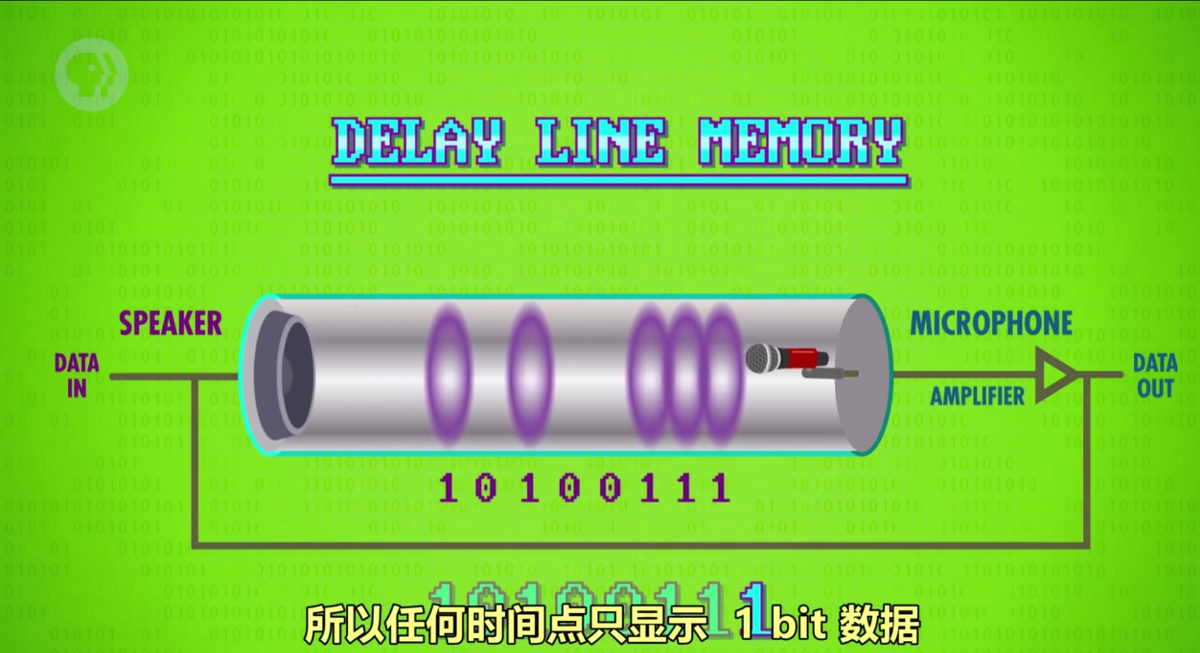
延迟线存储器 Delay Line Memory
延迟线存储器的原理是一个管子装满如水银的液体,管子一端为扬声器,另一端为麦克风。麦克风接受扬声器发出的声波转换为电信号,而声波的延迟可以用来存储数据,接收到表示1,无则表示0。收到声波转换为电信号通过放大器放大再通过线路接入扬声器形成循环回路就可以存储这段信号。而延长线存储器的缺点是每个时刻只能读取1bit数据,访问特定数据需要等待它从循环中出现。
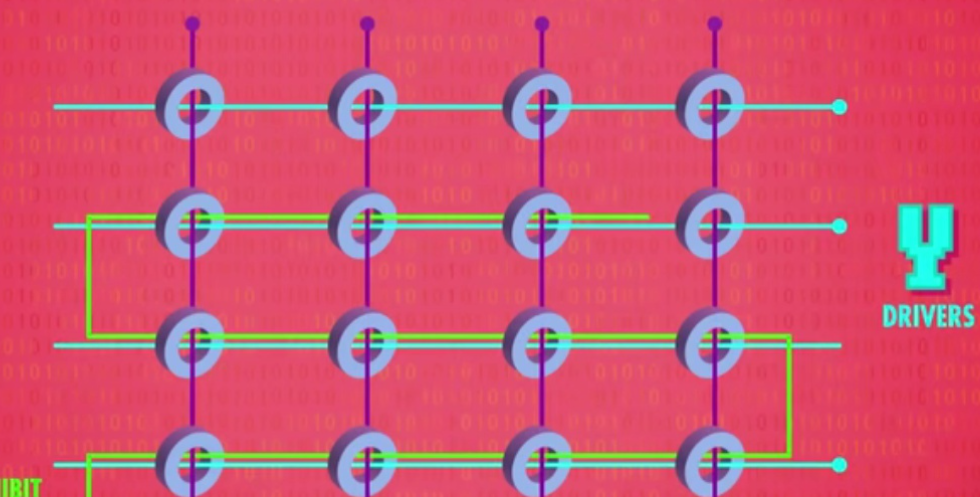
磁芯存储器 Magnetic Core Memory
中间还出过用金属线的震动表示数据的磁致伸缩延迟存储器但是后来出现了性能、可靠性和成本都更好的磁芯存储器就导致延迟存储器很快过期了。磁芯存储器给磁芯绕电线形成磁圈,并施加正反电流使其正反磁化就可以表示01存储信息。这样关掉电流后磁化方向也不会变确保长期存储,而单个磁芯还不够用需要将磁芯排列成矩阵,通过行列的导线来选择特定磁芯读取数据。(参照前面矩阵排列锁存器)

磁带
磁带是纤薄柔软的一长条磁性带子,卷在轴上。磁带驱动器的写头绕上电线,通上电流之后可以使磁带的一部分磁化来写入数据,读头用来检测磁带极性以读取数据。磁带驱动器很贵,但是磁带很便宜所以磁带一般用于数据存储。但是磁带不能随机存取数据,只能连续存取数据导致访问速度是磁带的缺点
现代存储器
磁鼓存储器Magneic Drum Memory促进了硬盘的发展,其通过金属圆筒覆盖磁性材料用以记录数据,磁鼓持续旋转可以读取数据,其运行原理和磁带的原理差不多。都是用读写头探测表面的磁性从而存取数据。

光盘CD采用光学原理存储数据,光盘表面存在很多小坑,由光学传感器捕获解码为二进制信号
磁盘Disk(软盘)形状类似于光盘,一张磁盘很薄,可以将很多张磁盘叠在一起。读写头可以上下寻找需要的磁盘,等待其转到相应的数据位置进行读取(同时具备随机存取和顺序存取的特点)

计算机内存层次结构
一台计算机的内存组成通常不是单一的而是由很多种不同原理结构的内存组成。小部分但昂贵快速的结构在金字塔结构上层。大部分但便宜相对慢的结构在金字塔结构下层。
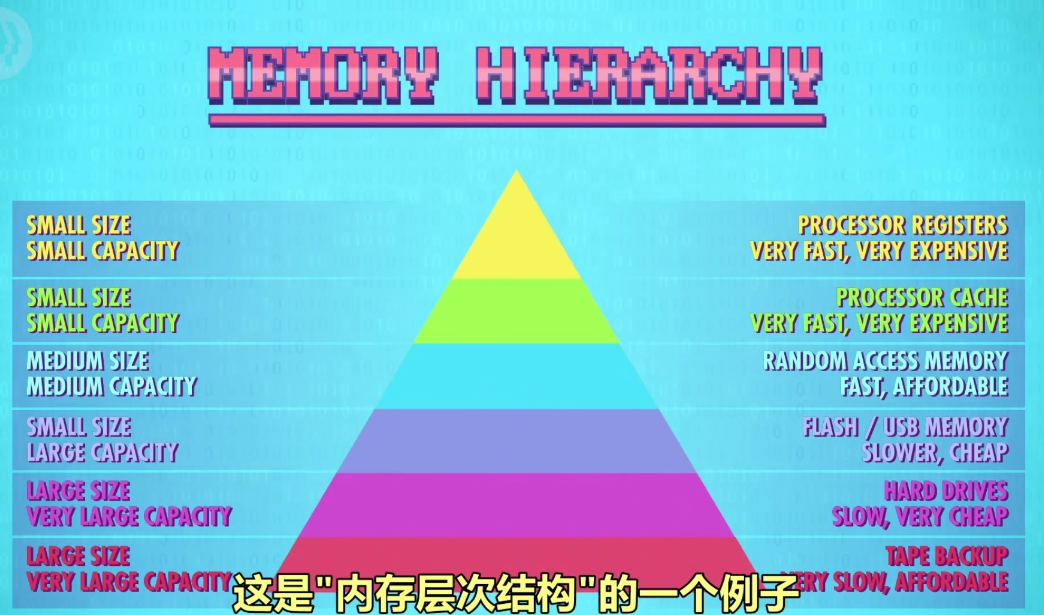
而如今计算机仍然采用混合内存组成结构,一般是固态SSD硬盘作为系统盘,机械硬盘存储数据。而内存存储的趋势是朝着固态的方向发展,尽可能减少机械结构,这样可以提高读写速度,同时可以减少机械结构带来的故障
文件与文件系统
文件格式
文件本质都是0和1组成的二进制码,不同的文件格式可以更快更方便的管理文件。最简单的文本文件格式就是TXT格式,其文件内容通常编码为ANSI编码(ASCII编码基础上拓展的一种编码)或者Unicode编码。
元数据 | 文件头
常见的音频文件如波形文件(wave)的格式wav,能存储音频文件,码率,单声道和立体声等数据。而描述文件数据内容的数据叫元数据。元数据(也叫文件头,文件头规定了文件的基本属性)通常位于实际数据前面。如波形文件的音频数据紧跟在元数据后面就是一长串数字,数字代表每秒捕获多次的声音幅度。这些振幅就是对声音每秒上千次采样的表示,播放音频文件时扬声器就会产生相同的波形来播出声音。
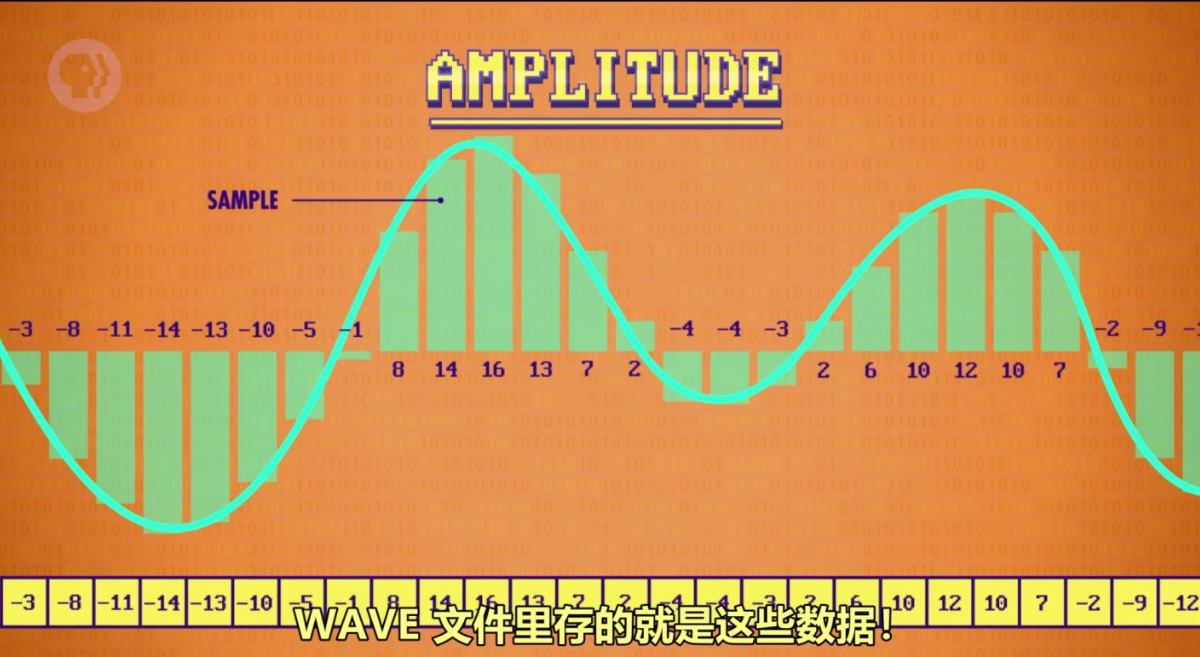
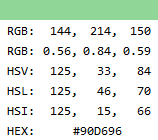
而存储图片的就是位图bmp(Bitmap)格式,通常将图片以RGB三种颜色的通道混合表示颜色,将图片切分为最小单位就是像素(即图片由像素矩阵组成)。每个像素由rgb加色三原色形成。bmp文件开头也是元数据,有图像宽度,图像高,颜色深度等信息。BMP文件是一串二进制代码,每三位分别表示红绿蓝的深度。


现代计算机存储文件的方式
- 平面文件系统
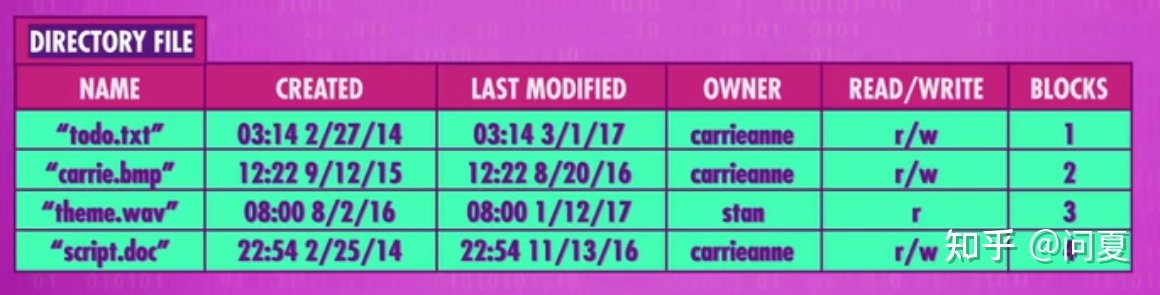
早期计算机只能存一个文件,会顺序连续放置文件。而后面随着计算能力和存储容量的提高,存储多个文件就非常的有用。通常最简单的是连续存储,而连续存储文件时为了获取不同文件的开头和结尾等位置需要通过存储在存储器开头的目录文件。
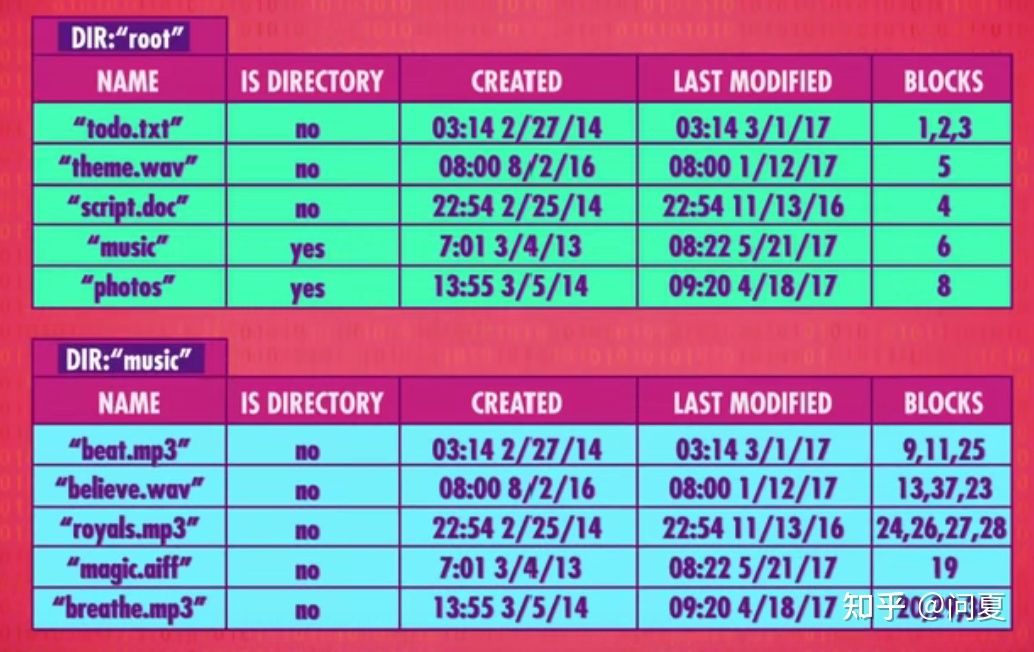
目录文件存储着所有文件的名称,创建时间,是否可写,文件起始位置和文件大小信息。这种将文件连续存储的就是平面文件系统。
文件连续存储时,如果前一个文件存储信息过多就可能会覆盖后一个文件。解决方案有:
- 将空间分块分配,那么一些较小的文件就会留出一些预留空间可以方便移动和管理(似乎很多问题都是动态分配来处理呢)。
- 将文件拆分到多个分块内,目录文件中记录拆分后文件所在的块,类似之前虚拟内存的映射处理方法。
删除某个文件时,计算机会将目录文件内对应的文件信息删除,而实际文件可能并未被删除而是被其它新文件覆盖。
文件因为拆分成分块(称为碎片),分散在多个块内不利于读取和写入。所以出现了碎片化管理技术,碎片化整理就是将原来分散在多个块内的数据按顺序整理好方便整理(针对顺序存取结构)。

2.分层文件系统
平面层的数据不利用文件查看,所以出现了树结构的分层文件系统
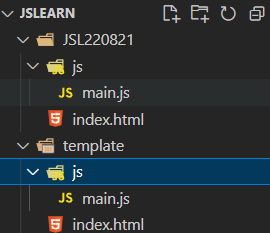
即会有一个根目录,根目录下可能有文件,文件夹。而文件夹也可以包含文件夹。这样就可以实现无限深度的文件夹。在同一个文件夹下做文件的移动只需要修改删除对应的目录文件即可。而文件数据存储的地方并不发生变化。
压缩
压缩是为了能够存储更多文件与提高传输文件时的速度。
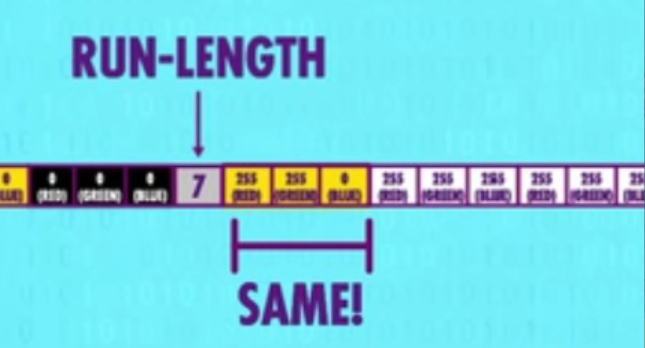
游程编码压缩 Run-Length Encoding
游程编码压缩适合经常出现相同值的文件,如图片文件中的重复颜色,就可以为最开始的颜色前加一个数字表示重复次数,相应的还要为所有颜色前都加上数字表示重复次数以统一规范方便解压程序解压。
当时看到这里就想起来偶尔了解过的霍夫曼树,结果下面还真讲了。类似于摩斯电码中使用频率高的字母拼写也会相对容易一些。
而这种压缩没有损失任何数据的压缩就是无损压缩
霍夫曼树 Huffman Tree 和 字典编码 Dictionary coders
另一种无损压缩字典编码用更紧凑的方式表示数据块。字典编码需要一个字典存储代码和数据之间的对应关系。
如将一张图片的颜色将按照指定像素进行分块。1像素包含3位颜色rgb数据,即1像素占3个字节。此处将例子中图片2个像素当成一个块。于是图片只剩下了四种不同的色组分块。接下来就是为这些色组生成紧凑代码(用于映射色组的值)。

而霍夫曼树就是一种高效的编码方式。方法如下
- 列出所有块和相应的出现频率
- 每轮选两个最低频率
- 两个最低频率块组成树(树的频率为组成频率总和)
- 重复流程
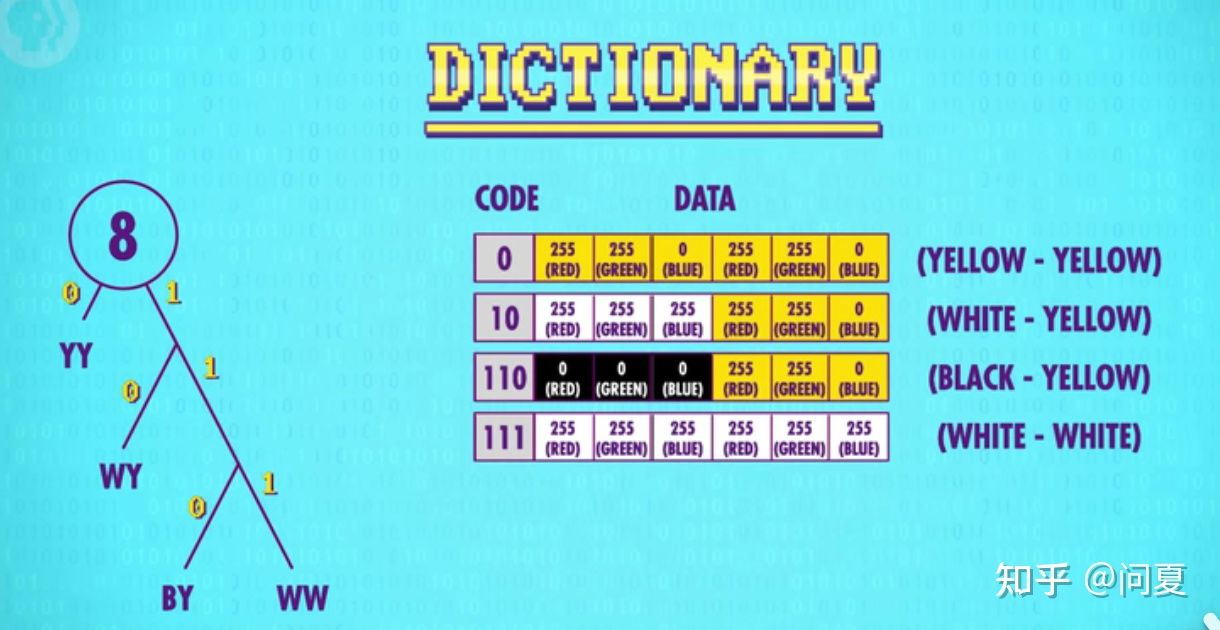
霍夫曼树最后组合生成的树是按照频率排列的,且树的每个分支用01表示。就得到了二进制与颜色块的字典(唯一不重复)。因为每条路径是唯一的,这意味着每个代码都是无前缀不需要以其它代码作为开头。而得到字典就可以将图片原来的颜色二进制码压缩。
消除冗余法和紧凑表示法通常会组合使用,几乎所有的无损格式都用了它们,比如GIF、PNG、PDF、ZIP。游程编码和字典编码,都是无损压缩,压缩不会丢失位信息,解压可以完全恢复。
感知编码 和 有损压缩
删除人类无法感知的数据的有损压缩方法为感知编码。如音频文件中录到了人类听不到的超声波数据都可以扔掉,MP3就是音频的一种压缩方式。而图像的有损压缩也有jpeg格式的例子
因为人眼会习惯性的观察对比度强的区域
这也是绘画中常见技巧,将引导视线集中处细节描绘的精致而其余地方细节量调低乃至鬼捣几笔,具体例子可参考wlop画作中常见的近景人物与远景的乌鸦的处理啥的

比如物体边缘
因为人眼需要图形感来识别物体,乃至人物图形设计会给人物带来相应的情感属性,常见于美式画风(人物有棱有角或者圆润),一眼识别不出来的那基本属于抽象艺术范畴了
以及看不出不大的颜色变化。(同样有相关的绘画技巧应用如藏色,调整明度丰富画面等技巧。可参考krenz画作,好像私货加的有点多,就当引入例子加强记忆吧)


这种有损压缩方法打开ps选择存储为web格式可以看到很多相关技术,如舍弃一些元数据,开启图片仿色等都可以有效压缩数据。
仿色是个很有趣的话题,之前画像素画的时候就了解过类似的技法,应该是
抖动dither

时间冗余
视频就是一长串的连续图片帧的组合,每秒可能有24帧或者60帧往上,而视频之间帧与帧之间有时变化很小,比如背景,这叫时间冗余,视频不用每一帧都存这些像素,可以只存变化的部分。还有的通过帧分析,用多个补丁代表物体,然后帧之间直接移动这些补丁。MP4就是一种很流行的视频压缩格式。
命令行界面 | 人机交互
人机交互Human-Computer Interaction指关于用户通过输入和输出获得数据,设备如何显示反馈输出信息等相关知识的学科。
人机交互设备的变化
早期通过齿轮,旋钮和开关等机械结构来输入输出。反馈输出信息则是打印在纸上。而之后出现了打孔纸卡和磁带则取代了机械输入,而反馈输出信息仍旧是是打印在纸上。在小型计算机变得足够便宜和快之后出现了键盘QWERTY 打字机用以输入。

早期的计算机使用的特殊打字机即电传打字机可用于发电报使得两人可以长距离通信。此时的电传打字机可用于输出,接受到远程的电信号以打印出相应的字符。
命令行界面与屏幕
随着电视机的量产,屏幕也逐渐变得可以代替电传打字机作为输出的承载。屏幕就像无限长度的纸,除了输入和输出字,没有其它东西。这种代替电传打字机的屏幕也叫做终端。通过电传打字机的协议处理计算机的输入和输出。
现在的程序输出语句常用的
利用键盘,输入一个命令,然后按回车,计算机就会输出结果回来,这叫“命令行界面”。比如,输入ls,计算机就会列出所有文件到打印机上。这就是早期的命令交互界面。

现在使用win+r -> input: cmd -> enter 就能打开win10自带的命令行(据说win11要更新命令行工具来着)
命令行工具可以说是编程不得不碰了,linux系统当下还多是纯命令行的系统(部署服务器常用)
屏幕和2D图形显示
早期屏幕用途
早期输出显示是分开的,将文本任务和图形任务分开处理。因为早期屏幕虽然无法显示清晰文字但是更新显示内容很快,就多用于跟踪程序的运行情况,比如寄存器的值这种临时值。而输出的计算结果当时一般还是打印在纸上。

阴极射线管 CRT Cathode Ray Tube
阴极射线管CRT是当时最早最有影响力的显示技术
原理是把电子发射到有磷光体涂层的屏幕上,当电子撞击涂层时,会发光几分之一秒,由于电子是带电粒子,路径可以用磁场控制,屏幕内用板子或线圈,把电子引导到想要的位置上。
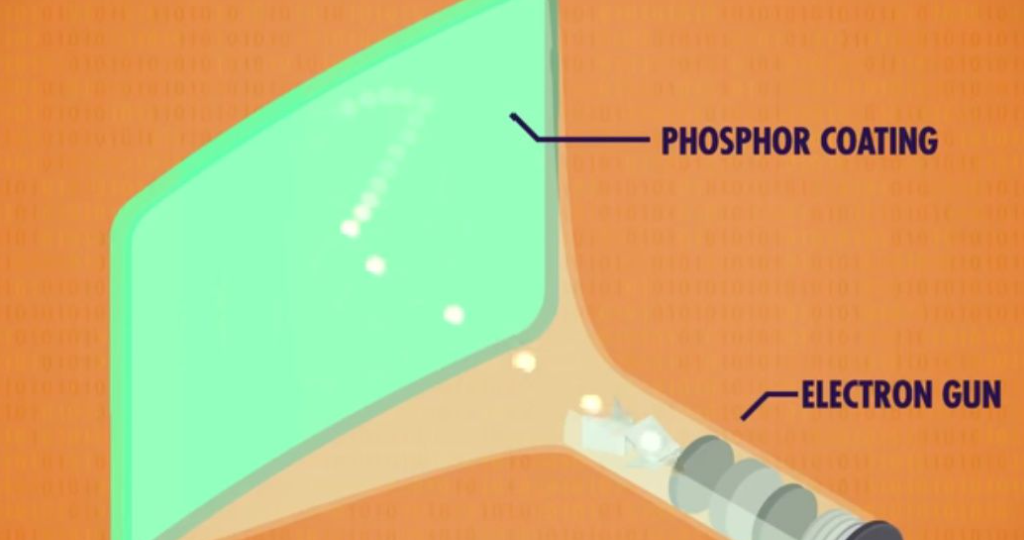
CRT绘图方式有两种:
矢量扫描: 引导电子束描绘出形状,重复地够快就可以显示出图形光栅扫描: 按照固定路径,一行行来,从上到下,从左到右,不断重复,只在特定路径扫描。
ps:现在给图片增加复古效果就有通过为图片添加类似CRT的电视扫描线效果实现的
液晶显示技术LCD和像素Pixel
随着技术发展,出现了LCD (Liquid Crystal Displays)液晶显示技术,LCD绘图方式也是用的光栅扫描,每秒更新多次像素里的RGB颜色。像素则是屏幕上清晰显示的点。
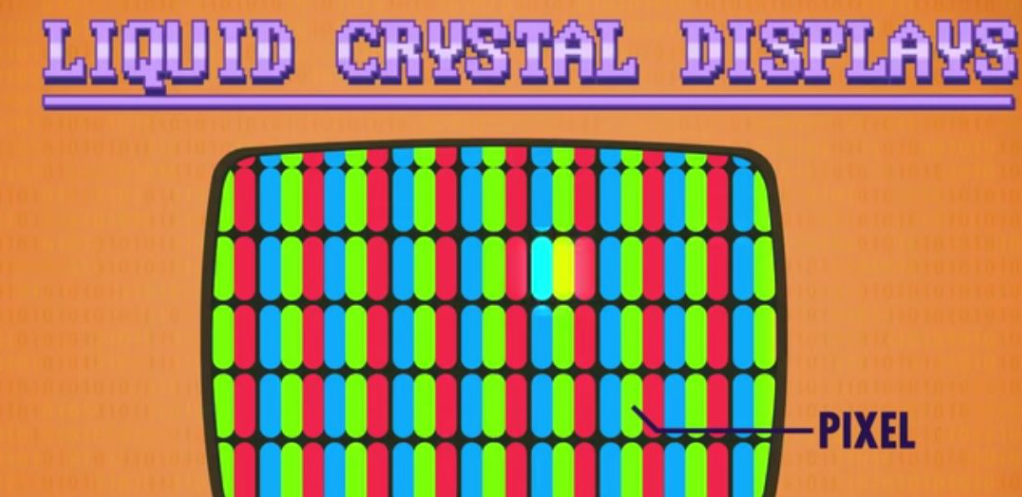
字符生成器 和 字符显示
早期计算机因为存储空间不够所以不用像素显示而是使用Ascii码字符集显示。当时屏幕显示字符使用的是80 x 25字符模式(一行80列,共25行,当下代码编写也基本遵守代码一行不超过80个字符的规范)。
80 * 25 = 2000,即当时屏幕一页最多显示2000个符号,符号用八位Ascii码显示总计也才16000bit相对使用像素显示图片要节省的多。
计算机需要一个能从内存中读取符号转换成光栅图像的额外硬件才能在屏幕上显示图像。这个硬件就是字符生成器,算是第一代显卡。字符生成器内部只用一小块只读存储器ROM以存储每个字符的点阵图案图形。
为了显示,字符生成器会访问内存中专为图形保留的一块特殊区域,即屏幕缓冲区。程序需要显示或修改文字的时候修改这块区域的值就可以了。当时人们就用这些Ascii码绘制界面,绘制Ascii艺术等。(现在b站页面打开开发者工具调到控制台也能看到一个Ascii码组成的小电视)
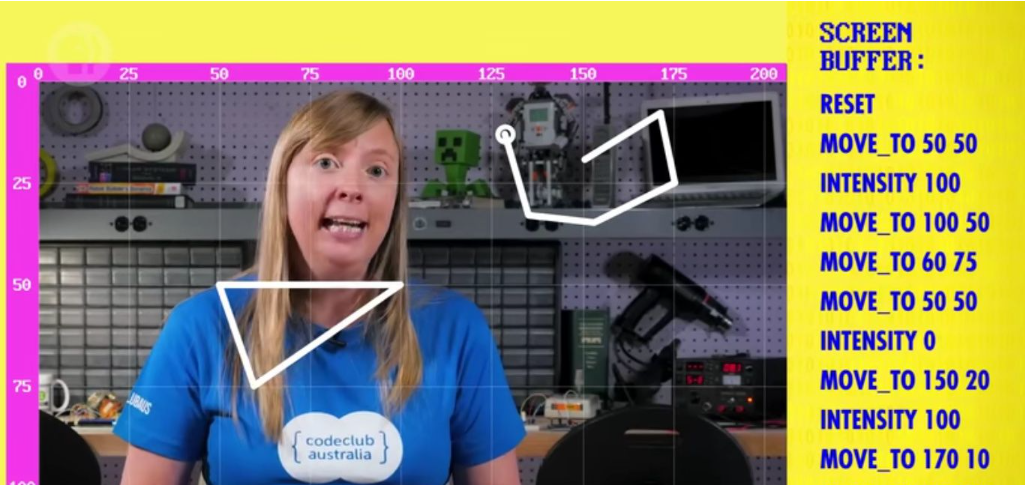
矢量扫描 绘制图形
通过矢量扫描法以绘制任意图案,包括文字也是用线条画出来。通过矢量命令以绘制图案,因为可以不断改变命令所以可以绘制动态图像(动画)。
现在web前端的canvas绘图也是差不多的方式,类似在纸上标记点连线
Sketchpad 与 位图显示
Sketchpad是在1962年诞生的一个交互式图形界面,用途是计算机辅助设计(CAD)。用户可以用光笔画线和简单形状,程序里面还自带了许多元件,帮助进行设计图案(使绘制线条完美平行,长度相同包括动态缩放等)。这个发明有巨大意义,它们代表了人机交互的关键转折点。
而1960年代末才出现最早用真正像素显示的计算机和显示器。将内存中的位(bit)对应屏幕上的像素,这叫位图显示。图形类似于一个巨大像素矩阵。类似将字符数据,矢量数据存在内存中的缓存区,计算机把像素数据存在内存中一个叫帧缓冲区的特殊区域。早期这些数据还存在内存里,后来则存在高速视频内存VRAM内,而VRAM则在显卡上(显卡的显存的一种形式)
冷战和消费主义
冷战
二战后美苏冷战,美国在这期间花费大量资金在科学与工程学上使计算机技术迅速发展到了足够商用,消费者购买商用产品又继续推动了产品发展。
Memex假想计算机 与 美国国家科学基金会
Memex是当时假想的计算机,Memex的出现促进了人民对计算机未来的思考,在Memex假想的发布者范内瓦·布什建议下,美国建立了国家科学基金会,负责给科学研究提供政府资金。
晶体管设备 与 太空竞赛
1950年代,消费者开始买晶体管设备,收音机因为小而便携受到人们欢迎。于是日本为了从二战后恢复从贝尔实验室获得了晶体管得授权使索尼制作了晶体管收音机帮助振兴了日本的半导体行业。
1961年苏联把加加林送上太空,美国为了追赶苏联提出登月计划花费大量资金资助太空计划,为了使用计算机导航太空船而促进了世界计算机工艺发展(太空电脑使用集成电路促进集成电路发展)。

消费级电子设备
这期间集成电路发展随着军事需要得到了更进一步的发展,特别是洲际导弹,核弹。超级计算机推进集成电路工艺的前提就是服务于美国政府机构。
美国半导体最初只看重政府高利润合同而忽略了消费者市场,被日本抓住机会发展消费级电子设备使市场被日本占领大半而导致美国半导体行业开始衰败,很多公司倒闭,英特尔也转型处理器。
个人计算机革命
1970年代初随着集成技术和CPU发展提升性能使计算机制造成本下降,使个人拥有计算机变得可行。
商业计算机和Basic语言
1975年出现第一台取得商业成功的个人计算机Altair 8800,这台计算机需要自己购买组件进行组装。当时的计算机编程语言仍然是机器语言,于是比尔·盖茨和保罗·艾伦为这台计算机开发了能运行Basic语言的程序Basic解释器(Interpreter),区别于运行前提前转换的编译器Compiler,解释器在运行时将Basic语言转换为机器语言。
开箱即用的计算机
后面的计算机选择了提供全套设备的整体机而不用自己购买组配各个组件。如Apple-Ⅱ,当时的Apple-II,TRS-80 1型,Commodore PET 2001等计算机都是一体化设计且自带Basic解释器使不那么精通计算机的人也能使用Basic编写程序。
这些计算机针对普通消费者使计算机第一次大规模的出现在家庭,小公司以及学校中。扩大了市场也为计算机行业注入了全新的可能性。
IBM兼容框架 与 苹果公司封闭框架
IBM公司为了抓住市场,也开发了自己的计算机,这台计算机最与众不同的是,它可以添加其他外设设备,比如显卡、声卡和游戏控制杆等等。
这种开放式架构叫IBM兼容IBM Compatible。开放的架构使得当时这台电脑包括IBM的对手公司也可以基于这套架构开发自己的软硬件,于是市面公司几乎都选择了使用同种架构,除了苹果公司之外不使用IBM兼容架构得计算机都失败了。
而苹果公司选择了相反的封闭架构,使用户无法添加新设备到计算机中,因此苹果可以控制从硬件到软件自己设计以保证用户体验和可靠性。后续为了对抗IBM兼容体系,苹果公司推出了普通人第一台可以买到的带图形用户界面的计算机麦金塔Macintosh

图形用户界面 Graphical User Interface
GUI相对于命令行界面不需要记住指令,只需要在屏幕上直观的点击就可以完成指定的任务,使普通人也能轻易的使用计算机。
而图形化界面是从1968年道格拉斯·恩格尔巴特设计的现代化计算机演示得到启发的,他设计的现代化的计算机,包括图形界面、鼠标等等,功能包括进行视频通话、多人文档操作和多窗口等等。
施乐奥托 与 WIMP界面
第一台真正带有GUI的计算机施乐奥托Xerox Alto在施乐公司新成立的帕洛阿尔托研究中心完成。施乐计算机将2D屏幕当作桌面。用户可以打开多个程序,每个程序都在一个框里,叫窗口。窗口可以重叠,挡住后面的东西。还有桌面组件,比如计算器和时钟。这台计算机的发明者用窗口Window、图标Icon、菜单Menu和指针Pointer来设计界面,因此叫WIMP界面。施乐奥托团队首先使用了“剪切,复制,粘贴这样的术语。
WIMP界面还提供了一套基本部件,包括可复用的基本元素如按钮,可选框,滑动条和标签页等组件。
需要注意的是GUI是事件驱动编程,不像之前代码从上到下顺序执行,GUI代码可以在任意时间执行以相应事件。
假如一个按钮点击触发事件,就需要在GUI初始化时在初始化函数中为按钮的点击事件设置相应的函数以处理事件。然后按钮点击时就会触发相应的函数以响应事件。
//伪代码 通过new方式获取相应实例
let gui = new Gui();
let button = new Button();
// 在gui界面初始化时设置点击事件
gui.onInit = ()=>{
//设置点击事件 此处使用js lambda表达式传入按钮对象view
button.setOnClick( view => {
btnClick();
});
}
//按钮事件
function btnClick(){
console.log('我被点击了捏')
}
微软苹果后日谈
后面史蒂夫·乔布斯去施乐参观后也推出了相应的图形化计算机,微软也从最开始1.0的DOS命令行界面继续推陈出新并在1995年推出 Windows 95 提供新的图形界面。甚至微软为了让桌面更简单友好开发了Microsoft Bob——类似于房子的设计却大获失败(
于是现在使用的界面都是人们自然选择后的结果,现在Windows,Mac,Linux包括其它GUI几乎都是施乐奥托WIMP的变化版,未来只会设计出更强大的GUI。
3D图形
图像投影
三维空间使用的是xyz的三维坐标,但是2d屏幕的计算机无法表示三维坐标。所以要将三维图形投影到二维平面屏幕上(MVP变换Model-View-Projection)。三维投影包括正交投影,透视投影等。
正交投影即每边互相平行,透视投影则符合现实世界透视规律,平行线段会在远处聚拢于一点消失
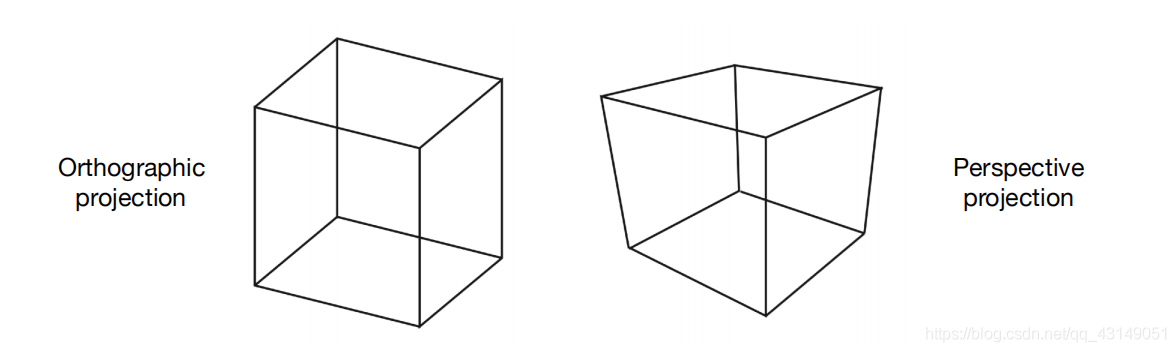
图形渲染
3D图形学中组成图形的一般是使用三角形,此处三角形在在3D图形学中称之为多边形(Polygons)。一堆多边形的集合则称之为网格(Mesh),网格越密,表面越光滑,细节越多。但是计算量也更多,游戏设计者通常就要为平衡角色真实度和多边形数量费心。下面将3D坐标投影成2D的坐标后就可以使用画2D线段的函数来链接这些点,这叫线框渲染。
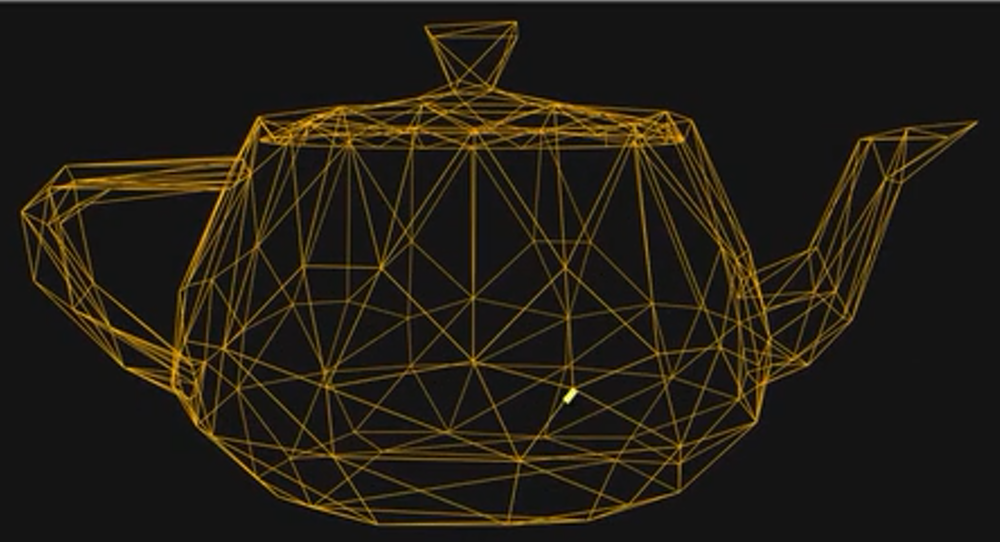
当年远哭就是硬叠多边形导致一代硬件杀手流传

使用三角形是因为三角形的简单稳固,给定3个3d坐标就能绘制出一个唯一平面。
图像填充
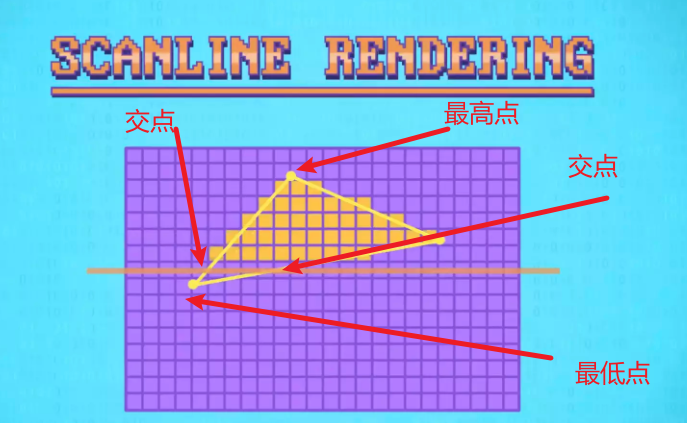
扫描线渲染Scanline Rendering是填充图像的经典算法,图像填充通常是将3D图像的多边形转换成一块填满像素的区域。扫描线算法填充的速度叫填充速率(fillrate)
扫描线算法会填充两个相交点之间的像素:
- 读取多边形的3个点
- 从最高点(y值最大的点)到最低点逐行处理
- 计算每一行和多边形相交的两个点
- 填充每一行两个交点之间的像素
为了避免边缘都是锯齿(狗牙)Jaggies,通常会使用抗锯齿Anti- Aaliasing,通常是在多边形边缘位置将填充颜色的明度,饱和度等参数进行调整让颜色浅一些。类似于ps的羽化效果。

画家算法
用于处理渲染图片时的遮挡Occlusion,用排序算法从远到近排列,然后从远到近渲染,因为画家也是先画背景再画更近的物体所以叫画家算法。

深度缓冲 Z Buffering
深度缓冲是另一种绘制遮挡物体的方法,该算法不需要排序,其记录每个像素与摄像机的距离并在内存中存一个数字矩阵。首先每个像素的初始距离初始化为无限大,然后从第一个多边形开始处理。比较当前记录距离与多边形距离的最小值并记录。比较完后在内存存储相应的距离矩阵,所有多边形处理完后就拥有一个能表示多边形哪些能显示哪些被遮挡的数字矩阵Z缓冲区。通过处理后的Z缓冲区配合扫描线算法的改进高级版配合就可以解决勘测到线的交叉点,判断某像素是否在最终场景可见的问题。
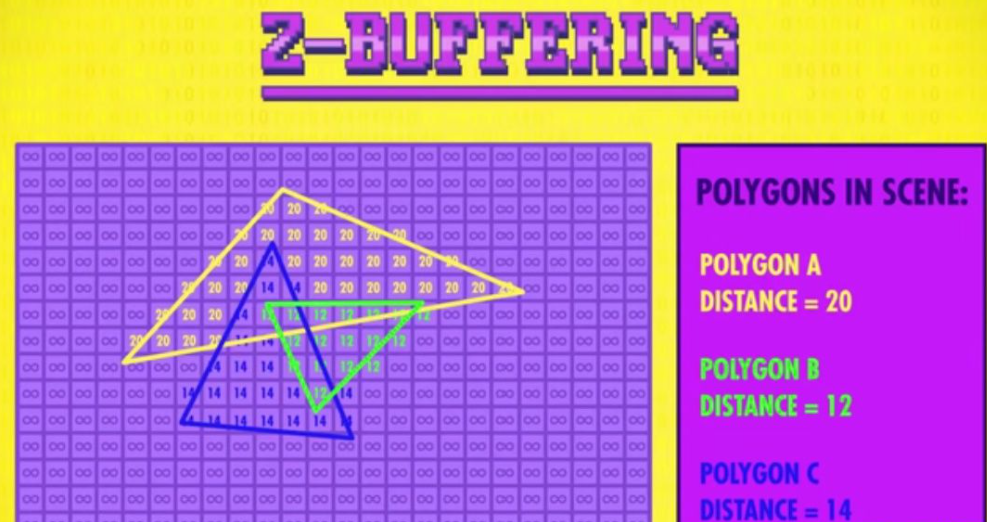
两个多边形距离相同时会出现哪个绘制在上面的问题,因为
没对多边形排序且多边形会在内存中移来移去,访问顺序会不断变化以及计算浮点数的舍入误差导致哪一个绘制在上面是不可预测的,于是就会导致出现游戏中两个物体闪来闪去的显现,这称作Z-fighting错误。
3D游戏里面有个优化叫背景剔除Back Face Culling,也就是三角形的两面,游戏只加载玩家能看到的那一面,另一面不加载因为玩家角色的头部或地面往往只能看到朝外的一面。这样若穿到另一面,容易产生透视BUG。CF就经常能卡出相应的bug,卡箱子缝隙啥的。
明暗处理
明暗处理要考虑这些多边形面对的方向,它们不平行于屏幕,而是面对不同方向。它们面对的方向叫表面法线。得到多边形的面对的方向就可以根据设置的光照角度计算出多边形被照亮的程度。对每个多边形执行同样的步骤就实现了最基本的照明算法平面着色。
法线:始终垂直于某平面的虚线
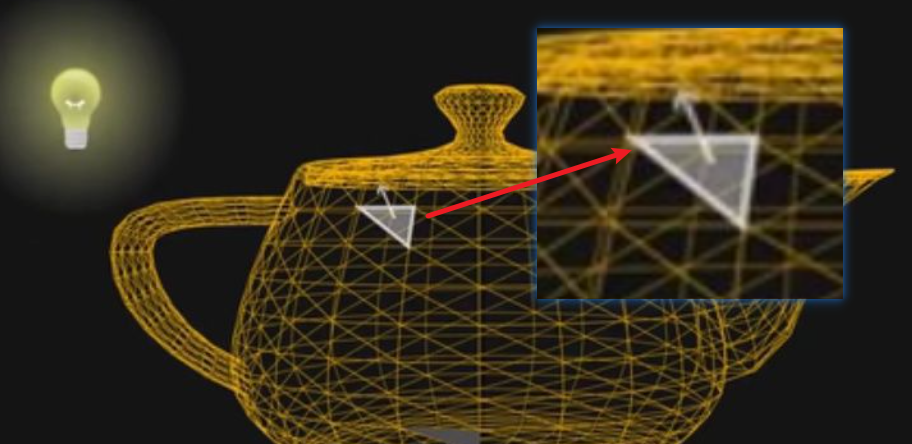

通过 高洛德着色或 冯氏着色等算法就能得到光滑的光影。

纹理映射
纹理映射是最简单的为3D模型填充纹理的算法,其使用扫描线算法填充多边形时根据内存内的纹理图像决定像素用什么颜色。为了实现填充相应颜色需要把多边形坐标和纹理坐标对应,从相应区域中取平均颜色并填充多边形。为了处理渲染3D场景的并行渲染也有专门的处理器即GPU图形处理单元,GPU在显卡上,周围有专用的RAM。


计算机网络
第一个计算机网络
计算机网络出现是因为大型计算机开始随处可见以后对信息的快速交换的需求变得迫切了起来。第一个计算机网络球鞋网络Sneakernet出现在1950~1960年代通常在公司或研究室内部使用,比把纸卡和磁带送到另一栋楼里更快速可靠。而且网络还可以共享物理资源,如办公室共享一台联网打印机。
局域网 Local Area Networks 和 MAC地址
局域网LAN指计算机近距离构成的小型网络,局域网能小到是同一个房间里的两台机器,或大到校园里的上千台机器。最著名和成功的局域网技术是以太网Ethernet,从1970年代开发使用到至今。
以太网通过以太网电缆将计算机互相链接,数据被计算机通过电信号的形式在电缆中传送。因为电缆是共享的,所有连在同一个以太网上的计算机都能观察到数据。为了让特定唯一的计算机可以接收到指定数据,以太网需要每台计算机自带唯一的MAC地址(Media Access Control address)。这样计算机就只需要监听到以太网电缆中出现自己的MAC地址才处理数据。常用于以太网和WIFI无线网络。
载波侦听多路访问CSMA 与 指数退避 Exponential Backoff
CSMA(Carrier Sense Multiple Access)指多台电脑共享一个传输媒介,载体(Carrier)指传输数据的共享媒介。例如以太网的载体是铜线电缆,WIFI的载体是无线电波。带宽则是载体传输数据的速度。
随着网络流量上升 两台计算机想同时写入数据的概率也会上升,则数据可能会混在一起导致冲突Collision。最明显的解决方法是停止传输等待网络空闲再重试一遍,而其他计算机也这样做的话就导致冲突的发生率更高。
于是以太网使用了更简单有效的解决方法,数据冲突的时候依然停止传输等待,但不等待同样的时间,而是在原本同样的等待时间下增加一个随机时间。这样子以错开相同的计算机冲突的可能性,但这不能完全解决问题,所以还需要另一个技巧:指数退避。指数退避则是随着冲突的次数增加使等待时间指数级增长。如第一次冲突为等待 1秒+随机时间,第二次就等待 2秒,然后4秒,8秒,16秒直到传输成功。因为计算机退避的时间越长冲突的次数就降的越低,这样就可以使数据不再轻易冲突使网络变得顺畅。
冲突域 Collision Domain
为了减少冲突与提升效率,需要减少同一载体中设备的数量。这里载体和其中的设备总称为冲突域。而减少设备数量的方法可以是使用交换机Switch将一个冲突域拆成两个冲突域,交换机位于两个更小的网络之间只在必要时在两个网络间传数据。
交换机会记录一个标记了哪个MAC地址在哪个网络的列表。于是单独一个网络内的数据传输不会通过交换机,因此交换机拆分的网络中的数据传输可以同时发生,但是如果拆分的网络间想要互相传输数据,那么两个网络都会被短暂的占用。包括最大的网络互联网,大的计算机网络也是这样构建的。
事实上华为就是做交换机起家的(电话交换机)
报文交换 Message Switching
连接两台相隔遥远的计算机或网路,最简单的办法, 是分配一条专用的通信线路。早期电话系统这样运作时往往需要一些接线员来将电路链接到正确的目的地以实现电话的指定拨打,这种将电路连接到正确目的地的任务就叫电路交换。这种方法能用但是总有闲置的线路导致不灵活而且价格昂贵,于是现代有了另一个传输数据的方法即报文交换。
报文可以判断数据传输时的目标地址以选择相关的路由节点,乃至根据网络状况选择最快的节点以及传输路径发生故障时选择另一条路径重新传输数据。简单说就是报文交换决定了数据传输的目标以及如何传输。
报文的具体格式为IP Internet Protocol,每一个联网的电脑都会有一个IP地址用于传输数据。这里的路由Route指路由器从一个接口收到数据进行定向转发到另一个接口的过程,可以理解为指明数据传输最短路径。路由节点则通常是路由器Router,可以连接不同的网络,能够选择数据传送路径并对数据进行转发 的网络设备。
报文交换的优点是可以根据网络状况选择不同路由,相对可靠而且容错率高。但是当报文比较大时则会堵塞线路。所以就有了分组交换这种将大报文切分成很多名为数据包的小文件来运输的技术。并且有阻塞控制技术,即路由器会平衡与其他路由器之间的负载,以确保传输可以快速可靠。
消息沿着路由跳转的次数 叫跳数(Hop-Count),看到哪条线路的跳数很高,说明大概率出了故障需要即时处理,这叫跳数限制(Hop-Limit)。
互联网
电脑如何连接互联网
电脑链接互联网需要先连到通过WIFI路由器连接所有设备组成的局域网LAN,WIFI路由器一般属于互联网提供商ISP(Internet Service Provider)如移动联通等公司。然后局域网再连接到广域网WAN,广域网通过一个可能覆盖一个街区的区域性路由器连接到更大的可能覆盖整个城市的广域网,连续跳转连接几次就能连接到互联网主干。
互联网协议 IP Internet Protocol
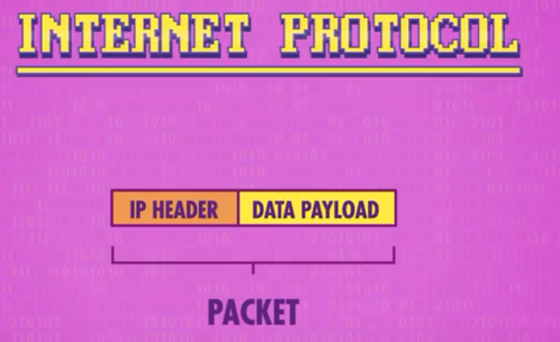
互联网是一个巨型分布式网络3,会把传输的数据拆成一个个数据包来传输。大的数据包还会拆成小的数据包以传输。而数据包(packet)想要在互联网上传输就要符合互联网协议(IP)标准。
IP协议是一个非常底层的协议,数据包的头部(数据负载前面)只包含含数据地址。此处图中IP HEADER存储描述传输数据的数据即元数据(meta-data),DATA PAYLOAD 数据负载指则是被传输的数据。两者一同组成符合IP协议的数据包。
用户数据协议 UDP与校验和
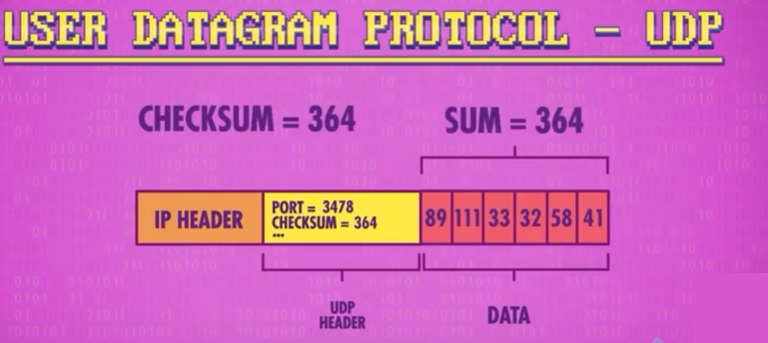
UDP(User Datagram Protocol)是高级于IP的协议,IP只负责描述将数据传输到哪台计算机,而UDP则负责描述将数据包传输到计算机上的哪个程序上。
UDP也具有头部,这个头部包括了两个信息,用于描述数据包发往哪个程序的端口号Port Number以及校验数据是否损坏的校验和 Check Sum。
每个想访问网络的程序都要向操作系统申请一个端口号,操作系统收到数据包的时候就会读取UDP头部中的端口号将其交给对应的程序。而校验和则是发送数据包前将所有数据加在一起算出校验和存储在头部。然后接收到这个数据包的时候就会将收到的数据重新加在一起将结果与头部校验和进行验证。结果一致则代表数据正常无损坏,如果不一致则说明数据在传输时损坏了。那只能把损坏数据扔掉。UDP校验和以 16 位形式存储 (就是16个0或1)如果校验和超过了16位能表示的最大值65535高位数就会被扔掉保留低位。
虽然UDP 无法得知发送数据包后是否到达,也不提供数据修复或数据重发的机制。但是它既简单又快,在一些不要求完整数据传输的程序中会很有用。
传输控制协议 TCP
TCP(Transmission Control Protocol)在需要完整数据传输时使用,TCP 和 UDP 一样,头部也在存数据前面,通常这样的组合被称为TCP/IP 。
TCP/IP是一个协议族,因为TCP/IP协议包括TCP、IP、UDP、ICMP、RIP、TELNET、FTP、SMTP、ARP、TFTP等许多协议,而不单单是TCP和IP。
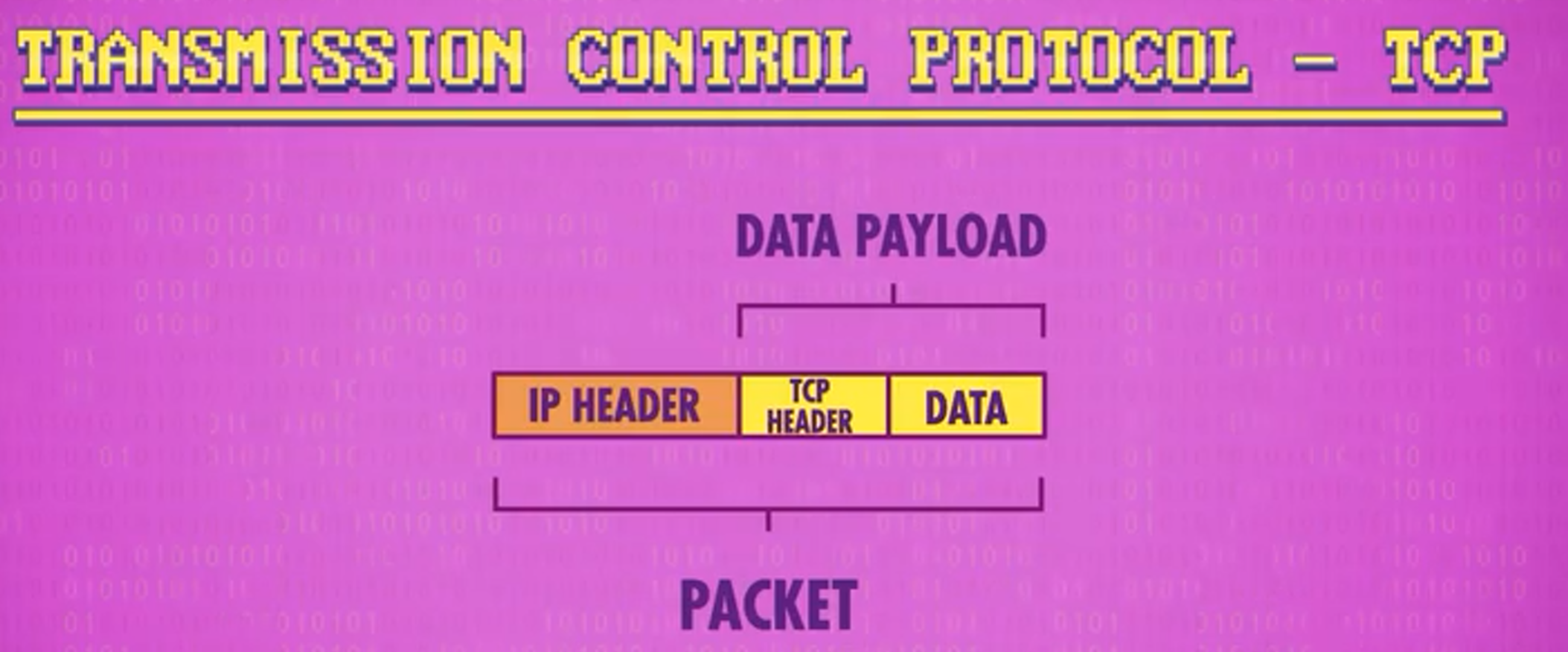
TCP也有端口号和校验和,但它还有更高级的功能,包括以下两种以及更多
- TCP数据包有序号 - 可控制接收方收到数据包后根据序号排成正确顺序,即使到达时间不同或者到达时乱序。
- TCP要求接收方收到数据包后需要给发送方发送
确认码(ACK)表示收到了
得知上一个数据包成功抵达后,发送方会发下一个数据包,假设这次发出去之后,没收到确认码那么肯定哪里错了。如果过了一定时间还没收到确认码,发送方会再发一次。因为收件方有序列号,所以也不怕确认码只是延误或者中途丢失,收到重复的数据包直接删掉即可。
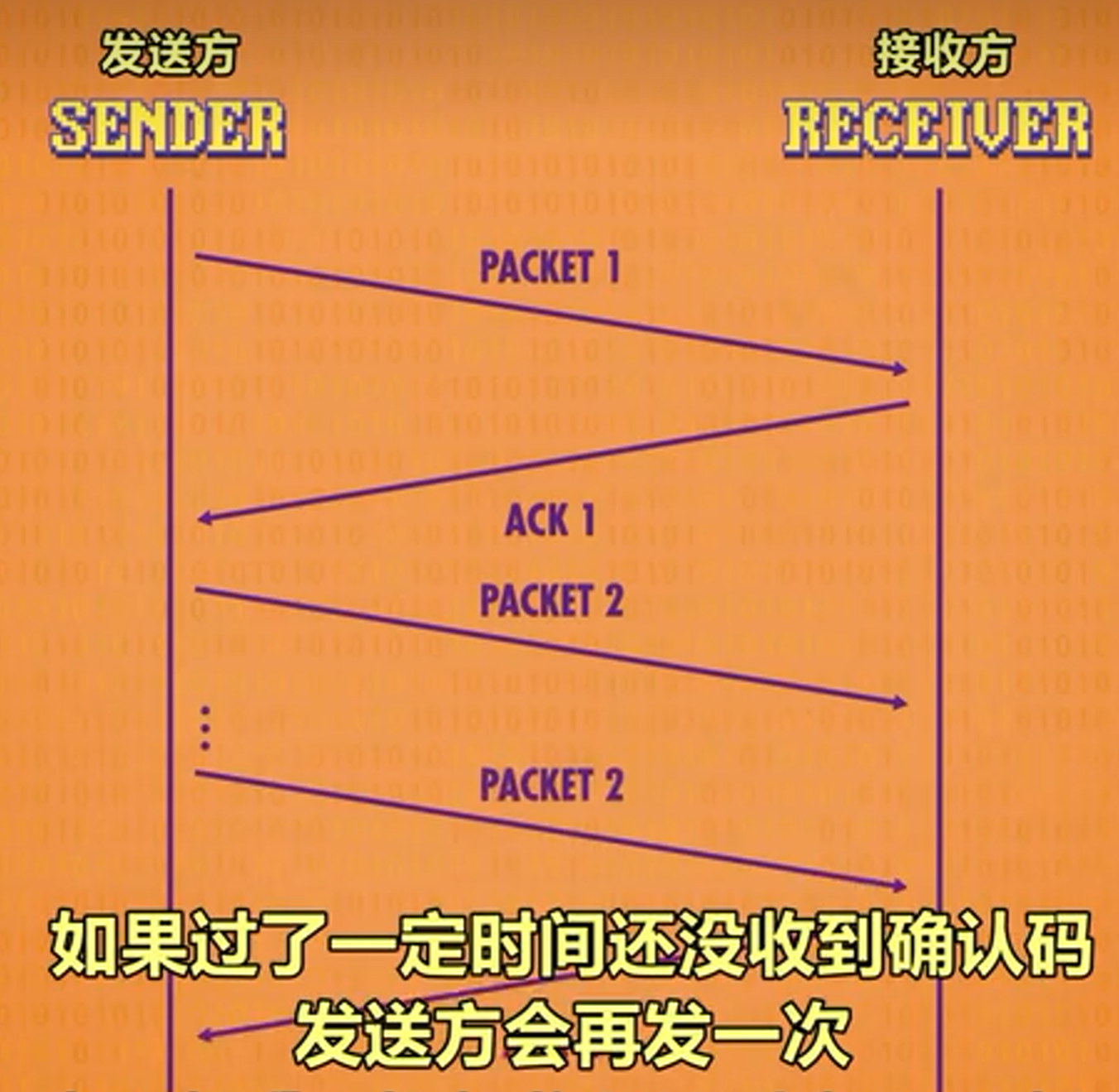
而且TCP可以同时发多个数据包,收多个确认码,不用浪费时间等确认码。而且可以通过确认码的成功率和来回时间用于推测网络的拥堵程度,TCP可以根据这个调整同时发包数量,解决拥堵问题。
即TCP可以处理乱序和丢失数据包,丢了重发并且可以根据拥挤情况自动调整传输率。
而TCP对时间要求很高的程序则不适用,因为这些确认码使得数据包数量翻倍却没有传输更多信息。
域名系统 DNS Domain Name System
计算机网络访问一个网站需要IP地址与端口号。例如163.177.151.109的80端口http://163.177.151.109:80,这是百度首页的IP地址和端口号。
事实上直接输入IP地址也可以,因为80端口作为HTTP协议的默认端口是被隐藏起来的可以直接访问。不同协议有不同的默认端口。
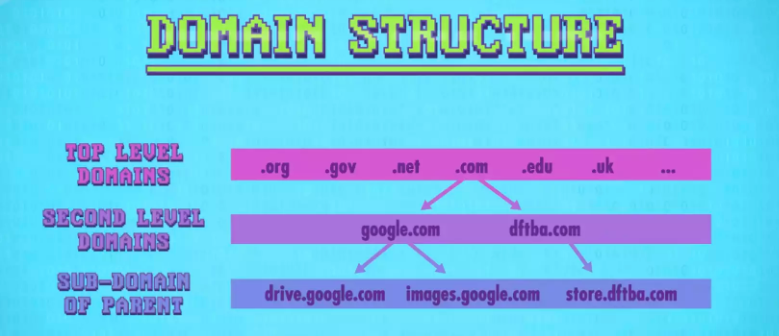
为了更方便记忆网站地址,互联网通过域名系统把域名和IP地址一一对应。例如直接输入www.baidu.com浏览器就会向ISP提供的DNS服务器查询相应的IP地址,DNS查表查到相应域名就会返回对应的IP地址。为了方便管理注册的域名,DNS通过顶级域名TLD等方式将域名分级进行树结构的存储。而这些子树的数据就散布在很多DNS服务器上使不同服务器负责树的不同部分。
OSI 开放式系统互联通信参考模型
OSI(Open System Interconnection)是概念性框架,将网络通信抽象划分成多层使每一层可以只处理各自的问题。
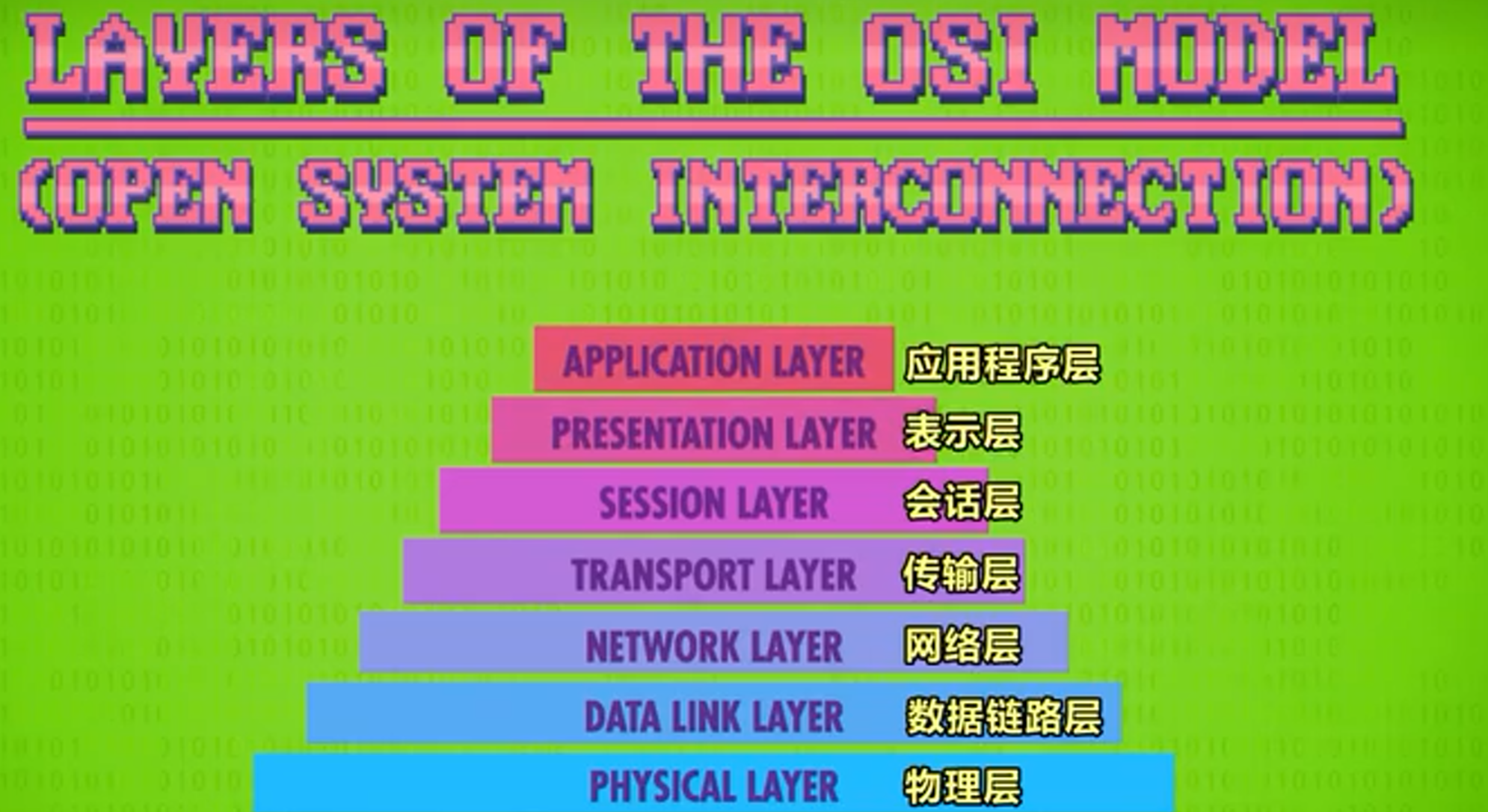
物理层的范围包括线路里的电信号以及无线网络的无线信号。
而数据链路层负责操控物理层,范围包括媒体访问控制地址MAC,碰撞检测,指数退避以及其他底层协议。
网络层则负责各种报文交换和路由
UDP,TCP这些协议负责在计算机之间进行点到点的传输,而且还会检测和修复错误。这些就包括在传输层的范围内。
会话层则使用TCP和UDP来创建链接,传递信息,然后关掉链接。这一套流程就叫做会话。查询DNS或者查看网页时就会发生这一套流程。
万维网 WWW World Wide Web
万维网基本单位 与 超链接
万维网在互联网之上运行,是互联网中传输最多数据的程序。万维网分布在全球数百万个服务器上,可以用浏览器来访问万维网。
万维网基本单位是单个页面,页面有内容也有去往另一个页面的超链接(Hyperlinks|Hypertext)。这些超链接连接着不同的页面形成巨大的互联网网络。
状态码, 统一资源定位器, 超文本传输协议
状态码代表当前所访问网页的状态,常见的包括访问正常200,服务器资源不存在404等。400-499状态码代表客户端出错。
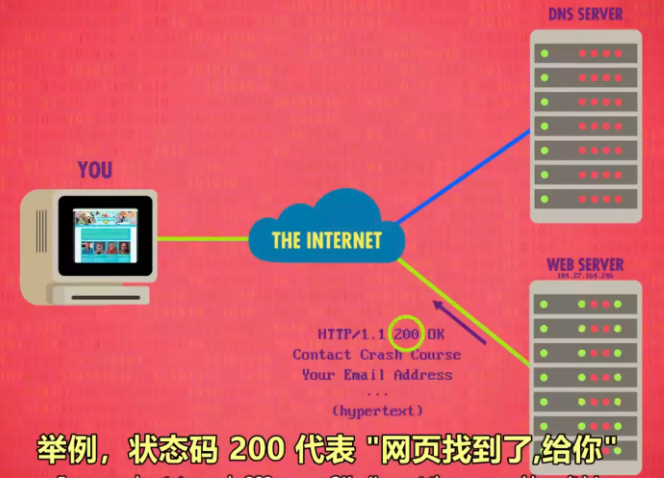
每个网页需要一个唯一的地址去定位区分,即URL Uniform Resource Locator。才能使使网页能相互连接。当访问一个网站输入url后计算机会进行DNS查找获取对应IP地址,然后浏览器打开一个TCP连接到这个运行着网络服务器的IP地址。然后通过服务器标准端口80端口向服务器请求默认的主页或者url内请求的子页面。这里从服务器获取页面的方法是使用HTTP(超文本传输协议)
超文本标记语言 HTML
HTML(Hypertext Markup Language)适用于开发页面的标记语言,一开始用于区分什么是链接什么是文本。现在通过层叠样式表 (CSS)和JavaScript等语言配合就能开发出现代网页。

万维网发展 与 网络中立性
第一个浏览器和服务器由 Tim Berners-Lee 编写,后面为了方便访问网页一开始人们维护一些超链接目录。后续随着网络越来越大出现了搜索引擎。出现了爬虫,索引等概念。
网络中立性Net Neutrality则是要求平等对待每个数据包,不让某些数据包的速度和优先级出现区别。

后面的部分大概会比较草率的带过,因为感觉有点概念上的了解就可以了。真正需要学习相关专业知识的时候再细分补充。
计算机安全
计算机安全是保护系统和数据的保密性,完整性和可用性。
- 保密性:只有有权限的人,才能读取计算机系统和数据
- 完整性:只有有权限的人,才能使用和修改系统和数据
- 可用性:有权限的人,可以随时访问计算机系统和数据
威胁模型
为了实现这三个性质,安全专家会从抽象层面想象敌人可能是谁。这叫威胁模型分析模型会对攻击者有个大致描述:能力如何,目标可能是什么,可能用什么手段,攻击手段又叫攻击矢量,威胁模型分析让你能为特定情境做准备,不被可能的攻击手段数量所淹没。
很多安全问题可以总结成2个问题:你是谁?你能访问什么?
身份验证 Authentication
为了区分谁是谁,使用 身份认证(Authentication)让计算机得知使用者是谁。身份认证有三种各有利弊的方式:
What you know, 你知道什么 - 例如通过只有用户和计算机知道的用户名,密码等进行验证What you have, 你有什么 - 基于用户有特定物体,例如加密狗这种加密硬件What you are, 你是什么 - 基于人,例如生物识别验证器,虹膜,指纹,人脸等识别

访问控制 Access Control
系统知道你是谁后,它需要知道你能访问什么,因此需要有个规范,说明谁能访问什么,修改什么,使用什么。这可以通过权限或访问控制列表(ACL)来实现,其中描述了用户对每个文件,文件夹和程序的访问权限。
常见权限包括三种:
读Read权限允许用户查看文件内容写Write权限允许用户修改内容执行Execute权限允许用户运行文件,比如程序
为了确保保密性,完整性和可用性,权限还需要织需要不同层级,例如有三个访问级别:公开,机密,绝密。那么拥有每个权限的用户只能访问自己当前级别与以下的数据,只能修改自己当前级别的数据。这样就可以保证绝密, 不会意外泄露到机密文件或公共文件里。这个不能向上读,不能向下写的方法,叫 Bell-LaPadula 模型。还有许多其他的访问控制模型,但哪个模型最好,取决于具体情况。
安全内核,独立安全检查和质量验证
身份验证和访问控制帮助计算机知道你是谁以及你可以访问什么,但计算机无法确保哪些程序或代码会出现漏洞以被控制了计算机的操作系统。为了减少执行错误,减少执行,使用安全内核或一组尽可能少的操作系统软件以确保安全性接近可验证并保证系统级安全。
即通过最小化代码数量试图保证代码是安全的。而现在最好的验证代码安全性的手段是独立安全检查和质量验证。包括安全型代码几乎都是开源的,可以让外部开发人员以新鲜的眼光和不同领域的专业知识,以发现代码的问题。
隔离Isolation 和 沙盒 Sandbox
隔离指开发人员在程序开发时就计划好当程序被攻破后,如何限制损害,控制损害的最大程度,并且不让它危害到计算机上其他东西。要实现隔离可以沙盒程序,即将软件运行于一个受限的系统环境中,操作系统会给每个程序独有的内存块,其他程序不能动。一台计算机可以运行多个虚拟机,如果一个程序出错,最糟糕的情况是它自己崩溃,或者搞坏它处于的虚拟机。
黑客与攻击
黑客种类
黑帽子: 也就是黑客, 可以是对热衷技术的人才的称呼,这时候是个中性带褒义色彩的; 也可以是对利用技术破解软/硬件系统, 以达到谋利, 技术炫耀, 或带有某种情感诉求的目的(如发泄愤怒, 报复等)的人的称呼.红帽子: 是指维护国家利益,利用网络技术入侵别的国家电脑,为自己国家争光的黑客.白帽子: 这是针对那些以保护各式各样的软/硬件系统为目的, 利用技术对系统进行侵入破解,以寻找系统漏洞或弱点, 进而帮助加固系统的技术人才的称呼.灰帽子: 是指那些懂得技术防御原理,并且有实力突破这些防御的黑客——虽然一般情况下他们不会这样去做。
单纯的提到红帽也可能是在说红帽公司,一家开源解决方案供应商

社会工程学
社会工程学Social Engineering是黑客入侵最常见的方式,不是通过技术而是通过欺骗让别人泄密信息。或让别人配置电脑系统,变得易于攻击。
网络钓鱼 Phishing 和 假托 Pretexing
最常见的攻击是网络钓鱼。例如通过信息,邮件等发送一个链接让人登录然后实际上很有可能会进入一个像官网的假网站导致输入用户名和密码后,信息会发给黑客导致账户信息暴露。
另一种方法叫假托(Pretexting)。例如攻击者给某个公司打电话,假装是IT部门的人。攻击者的第一通电话一般会叫人转接,这样另一个人接的时候,电话看起来像内部的。然后让别人把电脑配置得容易入侵,或让他们泄露机密信息,比如密码或网络配置。

木马 与 暴力破解
木马病毒(Trojan Hourses)是计算机黑客用于远程控制计算机的程序,木马会伪装成无害的东西,比如照片或发票,但实际上是会偷数据,比如银行凭证,或者会加密文件,交赎金才解密的恶意程序。
如果攻击者无法用木马或电话欺骗,那攻击者只能被迫用其他手段。例如暴力尝试,尝试所有可能的密码,直到进入系统。大多数现代系统会加长等待时间,来抵御这种攻击,每次失败就加长等待时间,甚至失败超过一定次数后,完全锁住。

NAND镜像 与 漏洞利用 Exploit
NAND镜像(NAND Mirroring)是最近出现一种攻破方法,适用于能物理接触到电脑的情况。可以往内存上接几根线复制整个内存,复制之后,暴力尝试密码,直到设备让你等待。这时只要把复制的内容覆盖掉内存,本质上重置了内存,就不用等待,可以继续尝试密码了,现在更新的设备已经有机制阻止这种攻击。
无法物理接触到设备时黑客就必须远程攻击,比如通过互联网。远程攻击一般需要攻击者利用系统漏洞来获得某些能力或访问权限,这叫漏洞利用(Exploit)
缓存区溢出 ,边界检查 与 金丝雀
缓冲区溢出(Buffer Overflow)是一种常见的漏洞利用。缓冲区是预留的一块内存空间的一种概称。缓存区溢出则是在系统缓存数据时输入数据超出系统给定缓存区大小时覆盖掉相邻内存的数据。入侵者可以利用这个漏洞在程序的内存中注入有意义的值以获取管理员权限。
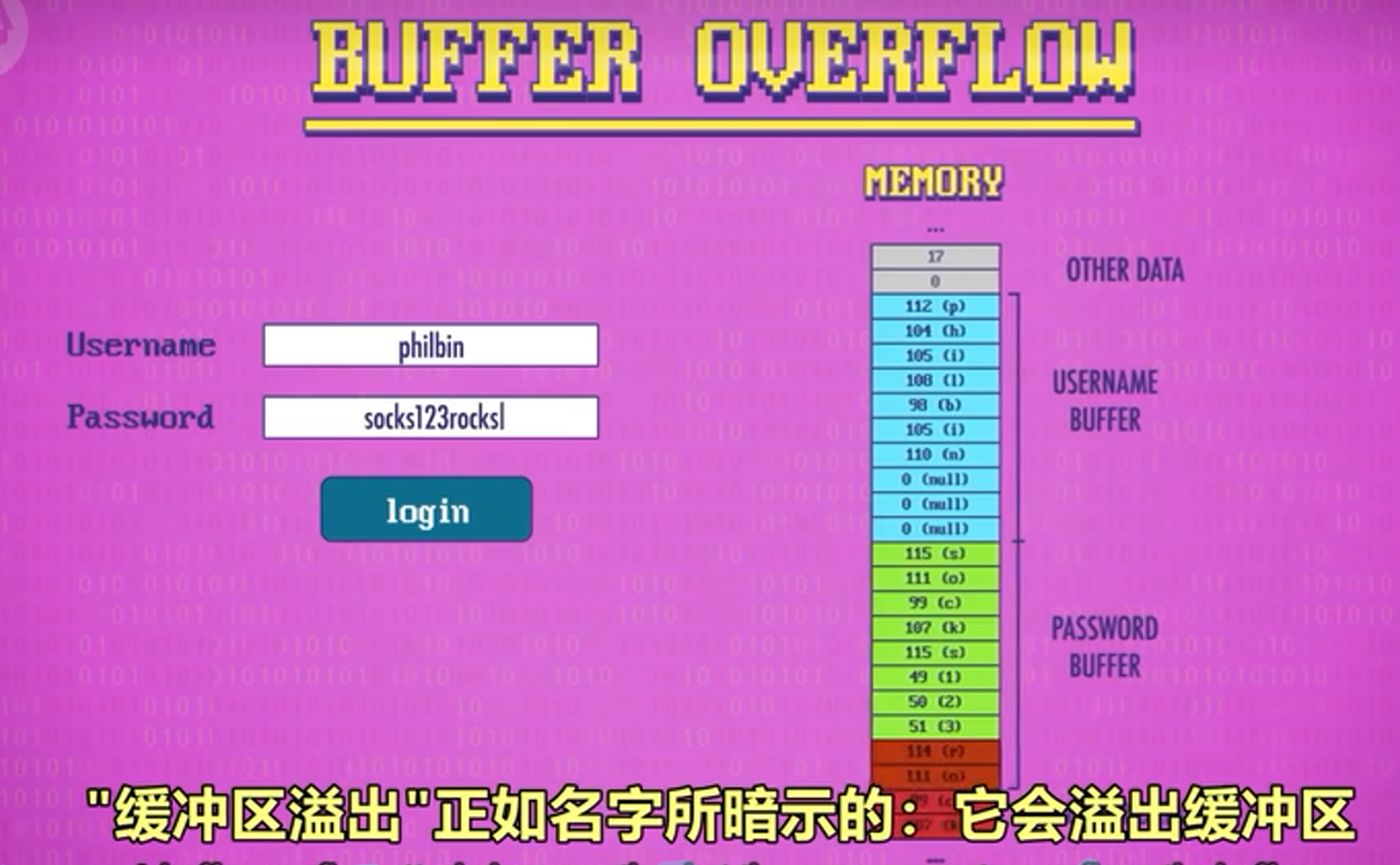
有很多方法能阻止缓冲区溢出,最简单的方法是边界检查(Bounds Checking),即将用户输入值复制到缓冲区之前先检查长度是否超出缓冲区大小。许多现代编程语言都自带了边界检查,程序也会随机存放变量在内存中的位置,使入侵者就不知道应该覆盖内存的哪里。
程序也可以在缓冲区附近留一些不用的空间去跟踪里面的值,看是否发生变化,如果发生了变化,说明有攻击者在乱来。这些不用的内存空间叫金丝雀(Canaries),因为以前矿工会带金丝雀下矿,他们通过随时观察金丝雀的状况来判断矿井内瓦斯和有害气体的含量,确保自己的安全。

代码注入 和 零日漏洞
代码注入Code Injection是最常用于攻击用数据库的网站的入侵手段。服务器在检查用户输入数据时一般会执行一段SQL查询代码指定从数据库中查询什么数据,但是代码注入可以通过在用户名等字段中插入SQL代码以进行删除数据库,数据表等破坏。
而零日漏洞(Zero Day Vulnerability)就是当软件制造者还不知道软件有新漏洞被发现时的这个新漏洞。
蠕虫 和 僵尸网络
蠕虫(Worms)是一种能够利用系统漏洞通过网络进行自我传播的恶意程序,它是利用网络进行复制和传播,传染途径是通过网络和电子邮件。最初的蠕虫病毒定义是因为在DOS环境下,病毒发作时会在屏幕上出现一条类似虫子的东西,胡乱吞吃屏幕上的字母并将其改形。

僵尸网络(Botnet)则是黑客将入侵控制的大量电脑组成的网络。可以用于发大量垃圾邮件,用别人电脑的计算能力和电费挖比特币,或发起拒绝服务攻击(DDoS)以攻击服务器。
加密
系统架构师为了保护系统安全会部署多层防御即多层不同的安全机制来阻碍攻击者,计算机安全中最常见的防御形式就是通过密码学(cryptography)将信息进行加密。为了加密信息,要用加密算法(Cipher) 把明文转为密文,不知道解密方法的话密文看起来就只是一堆乱码。把明文转成密文叫加密(encryption),把密文恢复回明文叫解密(decryption)

恺撒加密 和 移位加密
恺撒加密是替换加密这一大类的一种,算法把每个字母替换成其他字母,例如将所有明文FIRST中所有密码后移一位得出密文GJSTU,这里后移的一位就是偏移量。
下面是位移1次的对比:
| 明文字母表 | Z | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 密文字母表 | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
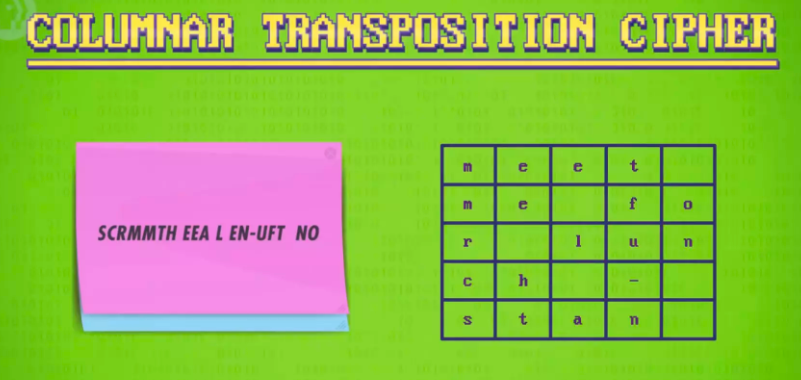
而另一类加密算法是移位加密,例如列移位加密加密就是将明文填入网格,然后选择一个顺序,从左从上至下读取,这样就得到了不同排列顺序的加密顺序。解密的关键则是知道读取反向和网格大小。
英格码机 和 对称加密
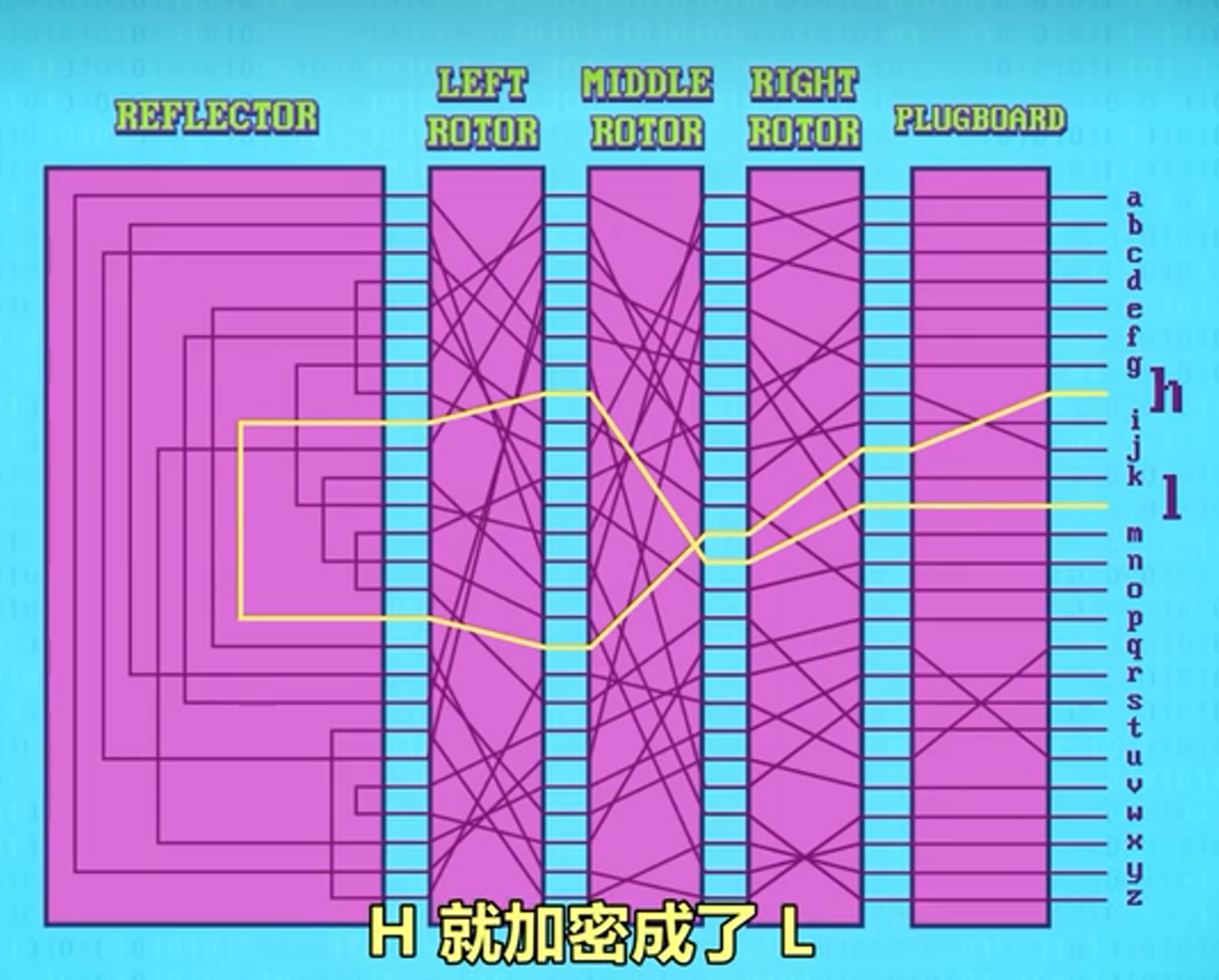
德国的英格玛(Enigma)机是纳粹在战时用于加密通讯信息的机器,它有一系列转子(rotros) ,是加密的关键。转子一面有26个接触点,代表26个字母,输入字母后线会连到另一面,替换字母。
这个字母替换的流程也是替换加密。而英格玛机更复杂一些,因为它有3个或更多转子,并让一个转子的输出作为下一个转子的输入。还可以按不同顺序放入转子,提供更多字母替换映射。
转子之后是一个叫反射器(Reflector)的特殊电路,它每个引脚会连到另一个引脚,并把信号发回给转子,最后发回到机器表面的插板就可以得到加密后的字母。这里插板的字母按照既定的顺序排列的话还可以增加一层复杂度,类似某些app的安全键盘会让用户使用乱序的键盘。
而这样子的设计字母加密后一定会变成另一个字母,为了避免被观察出规律,后续设计成每输入一个字母,转子会转一格。如果输入A-A-A,可能会变成B-D-K,映射会随着每次按键而改变。这样解密难度又上升了不少。
对称加密(Symmetrical Encryption)也称为密钥加密,所谓对称,就是采用这种加密方法的双方,使用方式用同样的密钥(Secret Key)进行加密和解密。密钥是控制加密以及解密过程的指令。
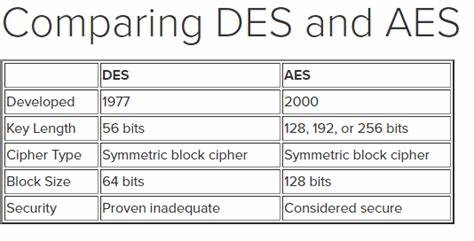
早期对称加密算法中应用最广泛的是IBM 和 NSA 于1977年开发的数据加密标准即Data Encryption Standard (DES), DES最初用的是56 bit长度的二进制密钥,意味着有2的56次方,或大约72千万亿个不同密钥。在当年大部分人都没有足够计算能力 来暴力破解所有可能密钥。直到技术进步到1999年以后暴力破解变得可能。
于是 2001 年又出现了:高级加密标准即 Advanced Encryption Standard (AES),AES 用更长的密钥 - 128位/192位/256位 - 让暴力破解更加困难,AES将数据切成一块一块,每块16个字节,然后用密钥进行一系列替换加密和移位加密,再加上一些其他操作,进一步加密信息,每一块数据,会重复这个过程10次或以上。只重复10次和使用128位密钥是基于基于性能的权衡,当前的加密已经足够使暴力破解困难了,就没必要加大加密难度使时间浪费在加密上。
密钥交换 和 非对称加密
以上的加密技术都依赖于发送者和接收者都知道密钥,发件人用密钥加密,收件人用相同的密钥解密。而互联网时代密钥没办法简单的通过口头约定,或依靠物品来约定。而在公开的互联网上传递密钥的解决方案是密钥交换。
密钥交换是一种不发送密钥, 但依然让两台计算机在密钥上达成共识的算法。可以用单向函数来实现,单项函数是一种数学操作,很容易算出结果,但想从结果逆向推算出输入非常困难。
迪菲-赫尔曼(Diffie-Hellman)密钥交换就是一种相关的安全协议 ,在 Diffie-Hellman 中,单向函数是模幂运算。
意思是先做幂运算,拿一个数字当底数,拿一个数字当指数,比如 A^b mod C。
例如想算3的5次方,模31,先算3的5次方,得到243,然后除31,取余数,得到26。
即 3^5 mod 31 = 243 mod 31 = 26
重点是
如果只给余数和基数。很难得知指数是多少如果已知3的某次方 模31,余数是7,需要试很多次才能直到次方是多少,如果把数字变长一些,比如几百位长那么想找到秘密指数是多少,几乎是不可能的。
Diffie-Hellman用`模幂运算算出双方共享的密钥的流程:
- 首先,有公开的值 -
基数:B和模数:M,发送方选取秘密指数:X - 然后计算出
B^X mod M的结果发送给接收方 - 接收方也选一个
秘密指数:Y,然后把B^Y mod M的结果发回发送方 - 为了算出 双方共用的密钥,双方用收到的结果与自身选取的秘密指数,进行模幂运算
(B^Y mod M)^X mod M=(B^X mod M)^Y mod M,B^XY mod M=B^YX mod M
其中最后一步数学上是相等的,也就能做到即使双方从来没给对方发过各自的秘密指数也能通过收到的结果当密钥以建立共享密钥。
建议自己推一下,视频中给出的算法描述是错误的。因为数学学的不咋地我是带了个值验证了一下

非对称加密( Asymmetric Encryption)则是有两个不同的密钥,一个是公开的,另一个是私有的。人们用公钥加密消息,只有有私钥的人能解密。
知道公钥只能加密但不能解密,或者用私钥加密公钥解密。就像一个不可伪造的签名,任何人都可以用公钥解密,但加密只有私钥的持有人 能加密。这能证明数据来自正确的服务器或个人,而不是某个假冒者。目前最流行的非对称加密技术是 RSA

emm…再说最后一遍,時間が加速する,后面的地方确实还没打算学习,只是将字幕文本进行大致的复制整理。

机器学习与人工智能
机器学习 ML Machine Learning
机器学习的本质是利用计算机擅长存放,整理,获取和处理大量数据的特质去用特定的算法使计算机可以从数据中学习,然后自行做出预测和决定。

人工智能 AI Artificial Intelligence
虽然机器学习(ML)和人工智能(AI)常常混着用,但大多数计算机科学家认为机器学习是为了实现人工智能这个更宏大目标而研究的技术之一。
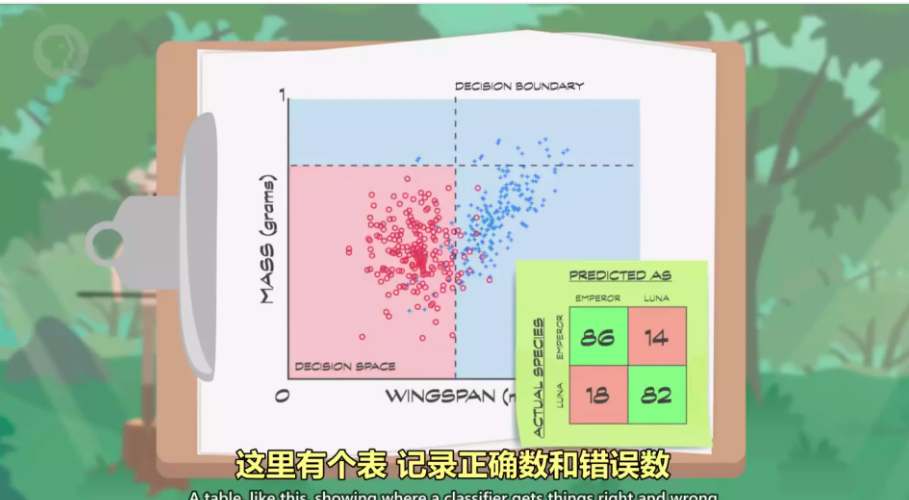
分类 决策边界 混淆矩阵
这里以分类 Classification作为例子。例如判断飞蛾是月蛾还是帝蛾,做分类的算法叫分类器Classifier。算法为了减少复杂性会把数据简化成特征用于帮助分类。
对于飞蛾分类的例子,可以用两个特征:翼展和重量,为了训练分类器做出好的预测,需要得到足够的训练数据。收集训练数据时不只记录特征值Feature,还会把种类也写上,这叫标记数据。
因为只有两个特征,很容易就能用散点图把数据可视化。红色标了100个帝蛾,蓝色标了100个月蛾,中间有一定重叠表明想完全区分两个组比较困难。
这里就需要使用机器学习算法找出最佳区分。这里通过估算判断翼展小于45毫米的 很可能是帝蛾,重量必须小于0.75g的很可能是帝蛾。在散点图为这两个数据标记一条线继续细分数据。这些线叫 决策边界Decision boundaries

而分类错误数和正确数用一个叫做混淆矩阵Confusion Matrix的表记录。
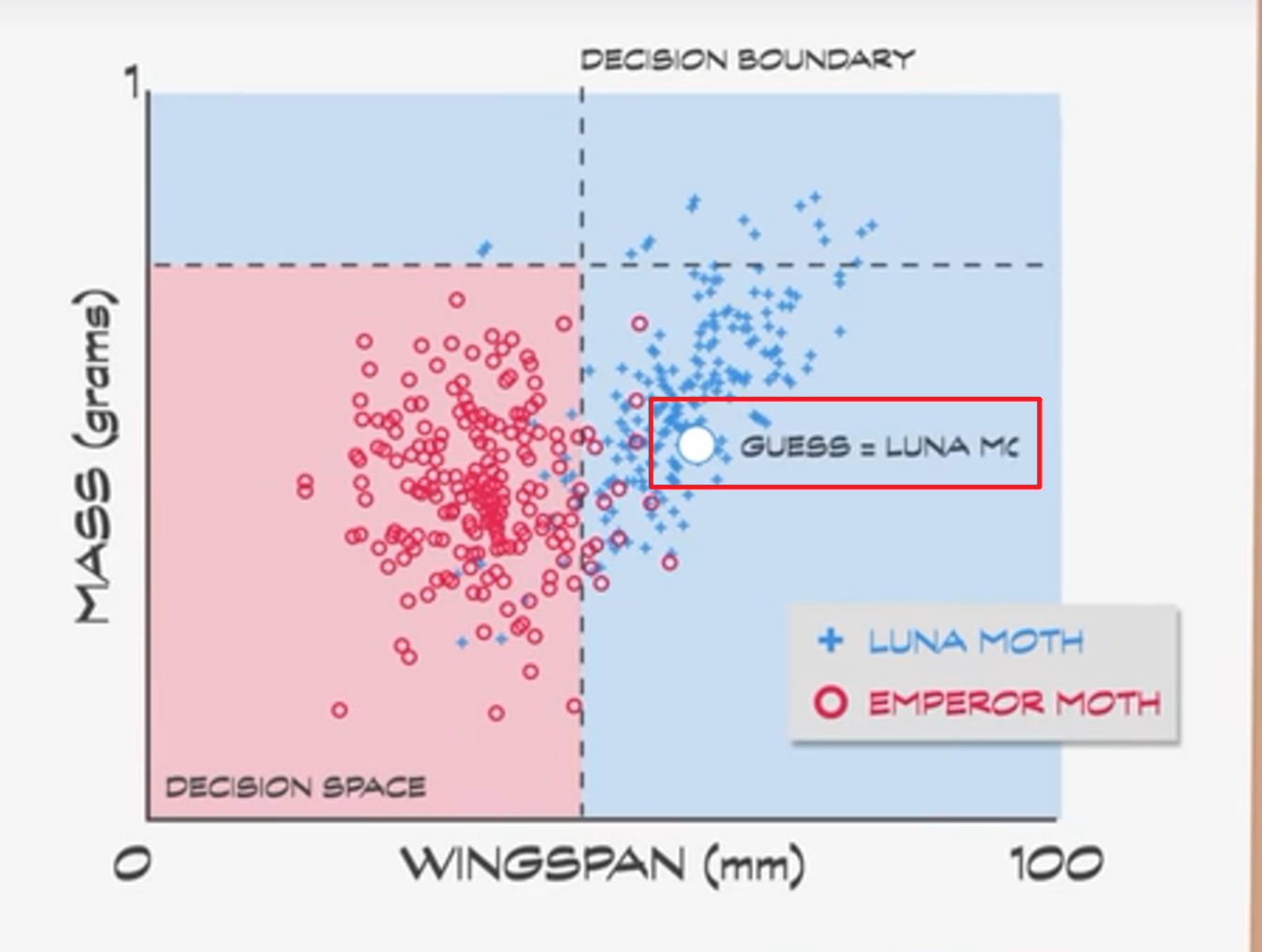
机器学习算法的目的就是是最大化正确分类 + 最小化错误分类。如果碰到一只不认识的飞蛾就可以测量它的特征, 并绘制到决策空间上。这样的数据是未标签数据, 通过决策边界就可以猜测其种类。
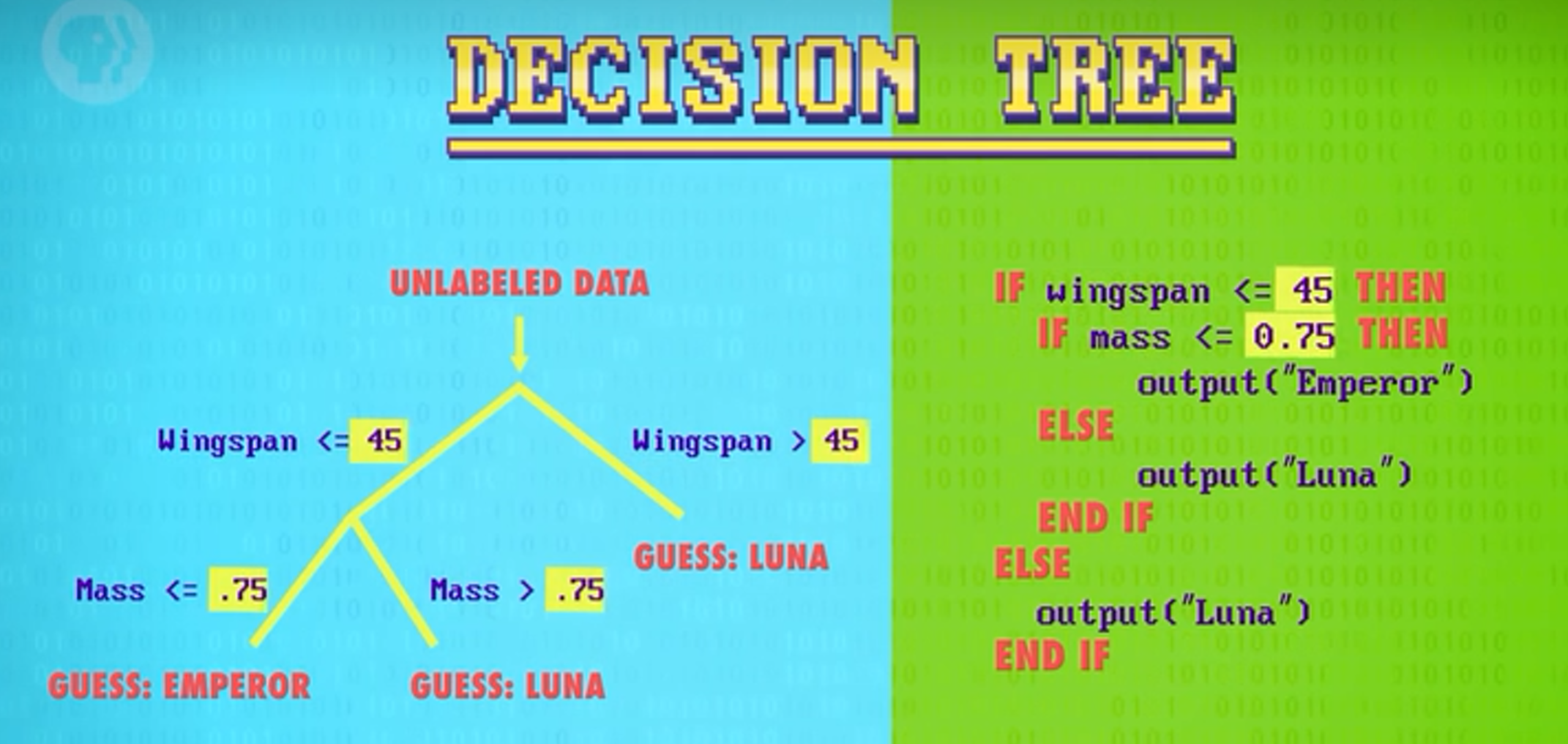
决策树 支持向量机
这个用决策边界把决策空间切成几个盒子的简单方法,可以用决策树Decision tree来表示。用 if 语句写代码,会像右侧,画成图像的数据结构就像左侧的树结构。用多个决策树来预测就被称为森林。
支持向量机Support Vector Machines则是不用树的方法,本质上是用不一定是直线的任意线段来切分决策空间,可以用多项式或其他数学函数切分。

人工神经网路 深度学习
人工神经网络Artificial Neural Network是一大类用了统计学的机器学习算法中,不用统计学的算法其灵感来自大脑里的神经元。可以接收多个输入,然后整合并发出一个信号。
其分为输入层、隐藏层和输出层。通过使用标记数据进行训练,不断调节神经网络的权重,增减偏差值修正,一开始这些偏差和权重会设置成随机值。随着算法执行的结果调整这些值逐渐提高准确性以模拟人类学习的过程。
神经元有应用于输出的激活函数,也叫传递函数。激活函数应用于输出和对结果执行最后一次数学修改。例如修正输出值限制在-1和+1之间。加权,求和,偏置,激活函数会应用于一层里的每个神经元并向前传播,一次一层。最后输出层中数字最高的就是结果。
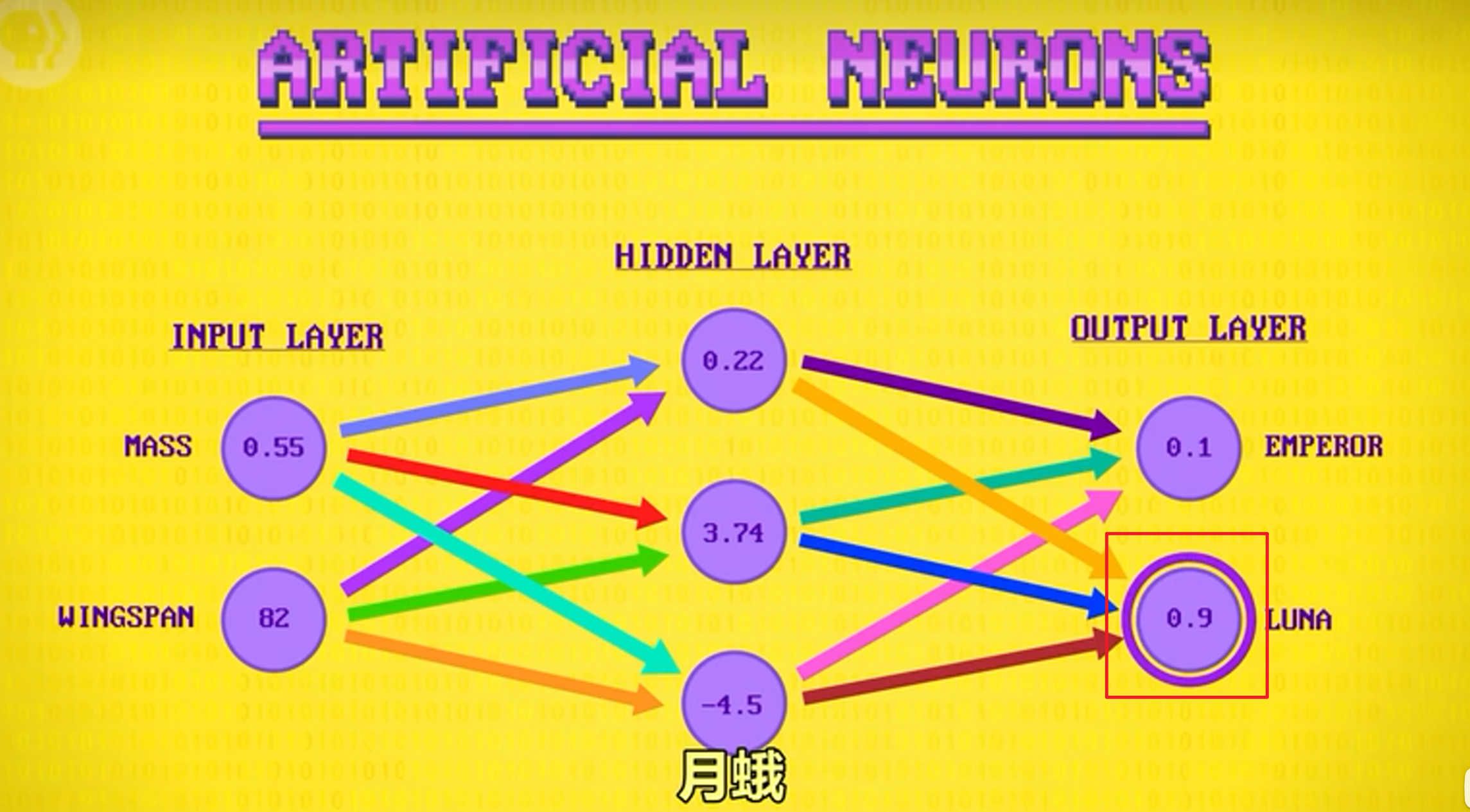
深度学习Deep learning指其隐藏层不是只能有一层,可以有很多层。训练更复杂的网络 需要更多的计算量和数据,尽管神经网络已经发明了很多年。但还是深层神经网络也直到最近才随着近年来硬件的发展成为可能。现今的深层神经网络可以执行开车,翻译,诊断医疗状况等等任务。

强AI与弱AI
这种只能做特定任务的AI叫弱AI或窄AI,真正通用的,像人一样聪明的AI,叫 强AI。但目前没人能做出来接近人类智能的 AI

强化学习
强化学习 是一种很强大的方法,其和人类的学习方式非常类似。都是学习什么管用,什么不管用,并自己发现成功的策略。
计算机视觉
因为视觉是信息最多的感官,视觉也是最常用的与世界交互的方式。所以计算机科学家一直都致力于让计算机有视觉感知,计算机视觉这个领域目标便是让计算机理解图像和视频
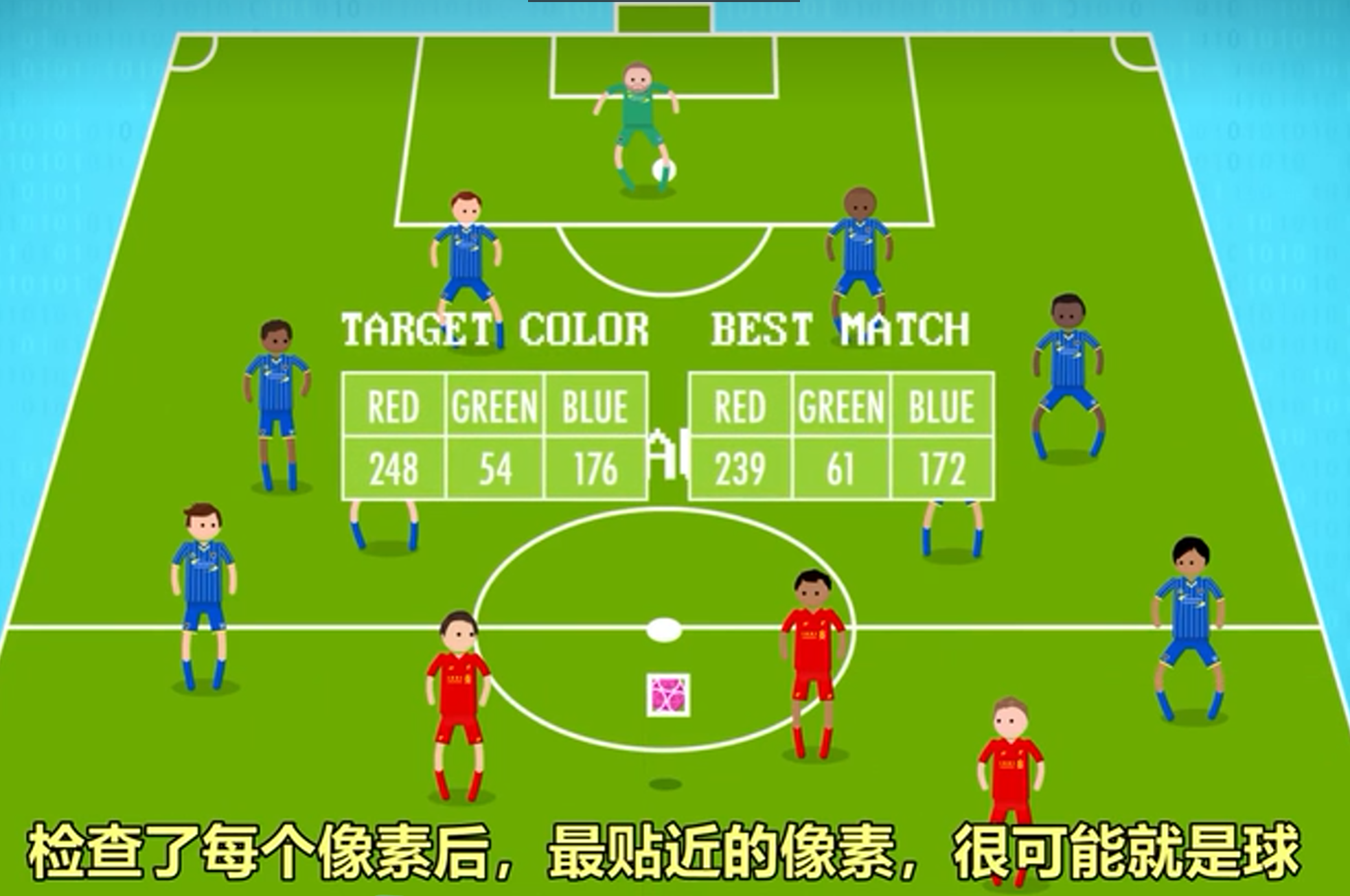
颜色跟踪法
颜色跟踪法是最简单的计算机视觉算法,算法运行时是一个个像素搜索,因为颜色是在一个像素里。其通常从图片左上角开始,逐个检查像素,找出最接近跟踪物体颜色的像素。但是因为光线和阴影等情况,跟踪效果可能不会很好,还可能会因为某个其他物体颜色与跟踪物体的颜色而导致结果混乱。
边缘检测 核/过滤器 卷积
颜色跟踪法不适合占多个像素的特征,为了识别如物体边缘等由多个像素组成的特征。算法要将图片中的像素分块处理。
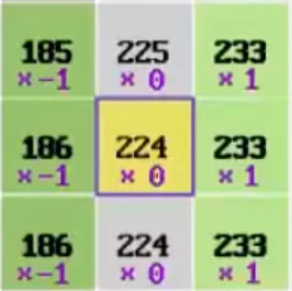
例如寻找垂直边缘,这里先将图片转成灰度图(去色/饱和度降为0),然后对比一张图片某点左右两侧的图像差异,差异越大,越有可能证明这点就是边缘点。这个操作用到一个矩阵完成检测,这个矩阵叫做核kernel或过滤器filter

里面的数字用来带入像素块做乘法,然后将总和存到块的中心像素里。
例如下图中将图片灰度化后每个像素只保留了灰度值,现在把核矩阵的中心匹配上进行检测的像素,根据核指定每个像素要乘的值,然后把所有数字加起来就得出最后的结果147并应用于块的中心(重新设置了灰度值)。这种把 应用于像素块的操作叫卷积convolution
Prewitt 算子 人脸检测
上面的核是检测垂直边缘的核。如果要检测水平边缘,可以使用其他的核(就是上面矩阵的转置)。这两个水平和垂直边缘增强的核叫Prewitt 算子 Prewitt Operators以发明者命名,核能做很多种图像转换。例如匹配特定形状,锐化图像,模糊图像。
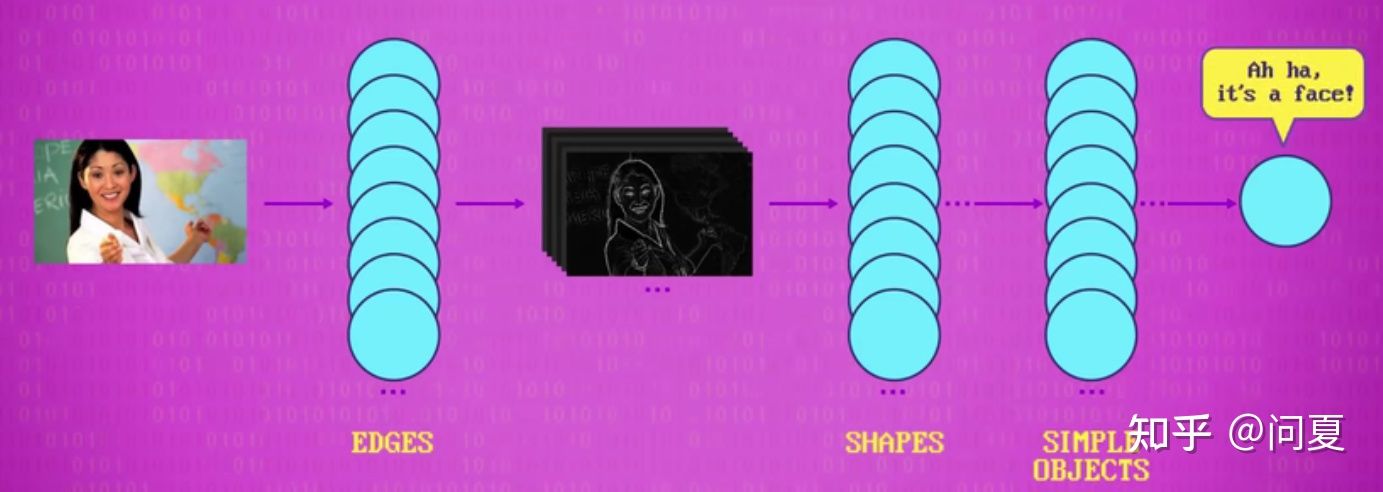
虽然每个核单独找出脸的能力很弱,但组合在一起会相当准确,于是把多个核组合进行检测,就可以识别到人脸,这叫人脸检测算法,这是一个早期比较重要的算法。叫 维奥拉·琼斯 人脸检测算法

卷积积神经网络 Convolutional Neural Networks
现在最热门的是卷积神经网络。神经网络可以学习核中的值,来完成图像识别。每一层的卷积网络,可以做出一部分检测,经过多层卷积网络,最后得到图像的检测结果。卷积神经网络的设计一般需要很多层,所以算是深度学习。
卷积神经网络有很多作用,比如可以进行文字识别OCR,CT扫描中发现肿瘤,检测马路是否拥堵等等。计算机可以利用目标定位和机器视觉,判断人们人脸表情。此外还有生物识别,通过判断两只眼睛之间的距离,以及前额多高等等,让计算机来识别生物特征。
自然语言处理 NLP
人类的语言叫自然语言,自然语言有大量词汇,有些词有多种含义,不同口音。人写们在作和说时话也会错犯,但大部情况分下言语序顺的并不解理影响。而自然语言处理,便是让计算机理解语言的领域,结合计算机科学与语言学的交叉学科。
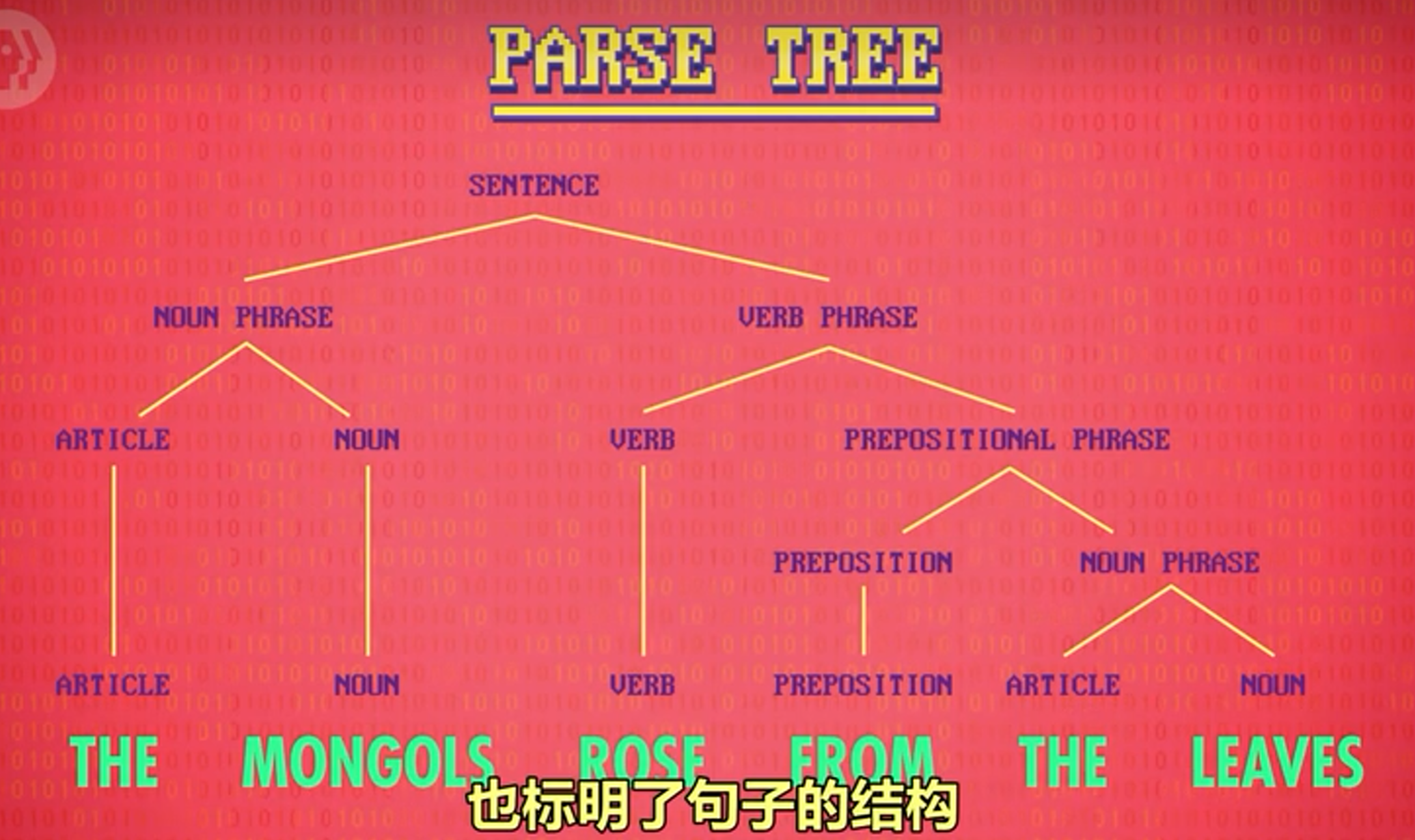
NLP过程 分析树
早期NLP的问题是怎么把句子切成一块块以方便处理(分治处理嘛可不是)。为了使计算机懂得语法,NLP通过词汇的词性和短语结构规则以构建分析树。
分析树给每个单词标了可能是什么词性,也标明了句子的结构使数据块更小 更容易处理。
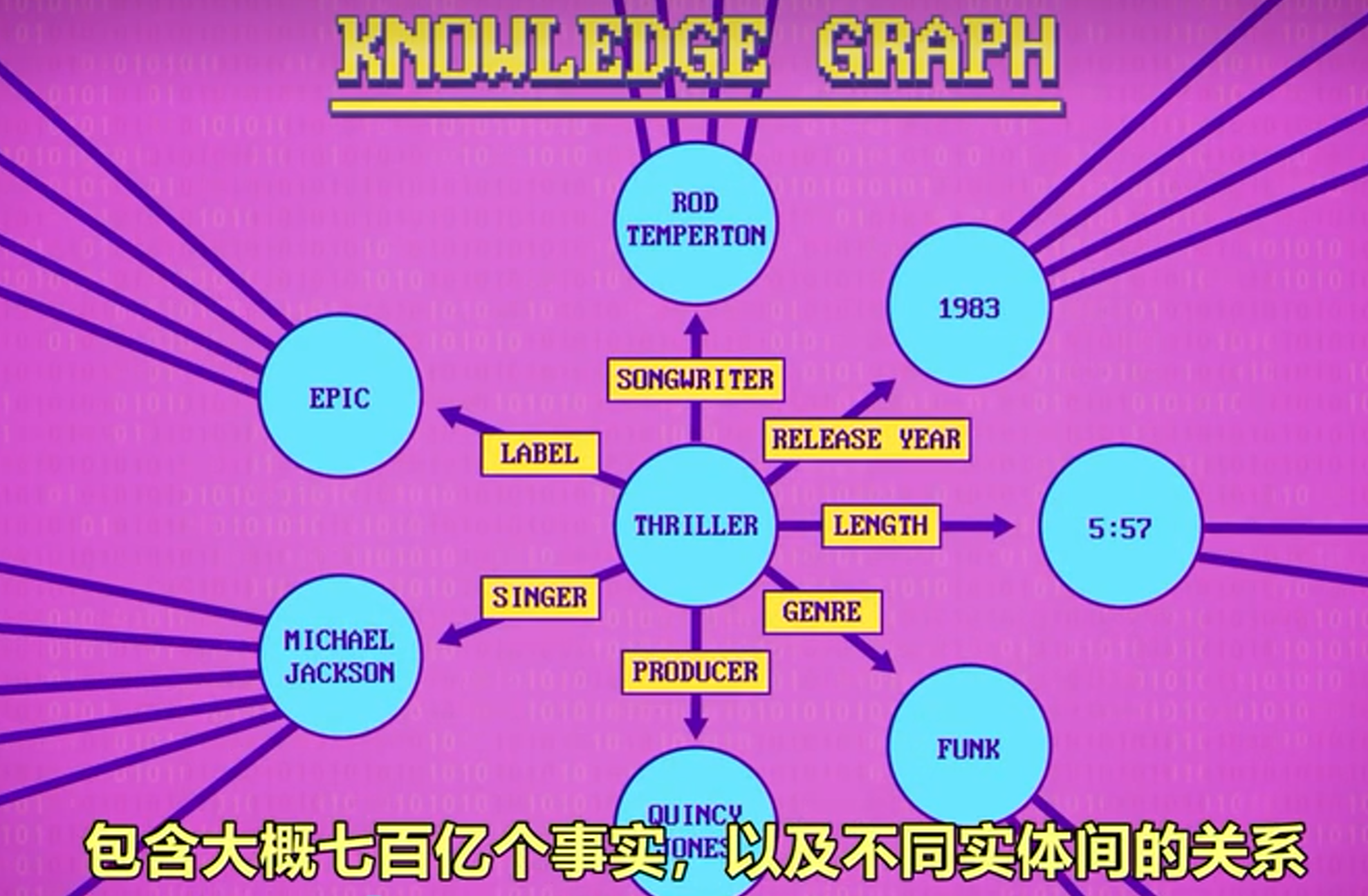
知识图谱
短语结构规则和其他语言结构化的方法,还可以用来生产句子。当数据存在语义网络时,这种方法最有效。实体相互连接,提供了构造句子的所有成分。这种技术谷歌版的叫知识图谱。
语音识别
语音识别这个领域是关于如何从声音中提取词汇,随着计算机处理能力的发展,实时处理语言变得可能。语言处理,也不是手工提取,而是基于机器学习。
如今,最强大的语音识别系统,用的是深度神经网络。我们得到的语音,如果直接利用其波形振幅时间图,我们不能很好识别。但是通过快速傅里叶变换(Fast Fourier Transform),得到不同频率的振幅时间图(这里横轴是时间,竖轴是不同频率的振幅)。通过不同的高峰区域(共振峰),高峰区域指的是声音较大的区域(亮纹处),可以让计算机识别元音然后紧接着识别出整个词。

而构成单词的声音片段叫音素,英语大概有44种音素,所以声音识别变成了音素识别。语音识别结合里面包含有单词顺序的统计信息的语言模型,语音识别成功率会更高。
音素(phone),是根据语音的自然属性划分出来的最小语音单位,依据音节里的发音动作来分析,一个动作构成一个音素。音素分为元音与辅音两大类。如汉语音节啊(ā)只有一个音素,爱(ài)有两个音素,代(dài)有三个音素等。
语音合成
语音合成 Speech Synthesis是让计算机输出语音,原理是让计算机分解各个词,然后播放出音频。早期的语音合成是音素合成。但现在的各种智能语音助手已经显得好了很多。
机器人
机器人总的来说,就是由计算机控制,可以自动执行一系列动作的机器。
CNC机器
早期的机器人,可以认为是一些自动机器,如自动计时器等等。第一台计算机控制的机器出现在1940年代晚期,叫数控机器,Computer Numerical Control(CNC)可以执行一连串程序指定的操作。精细控制,生产出人类用普通机械工具很难手工生产的物品。

负反馈回路 PID控制器
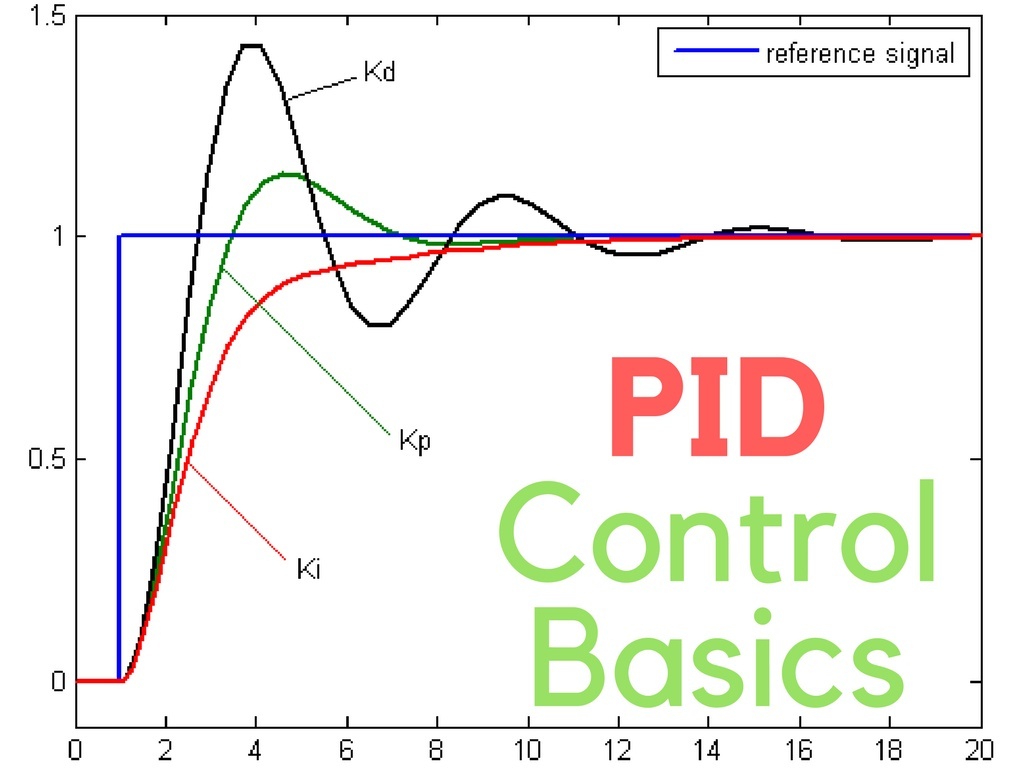
第一个商业贩卖的可编程工业机器人叫Unimate,于1960年卖给通用汽车公司。严格控制环境如工厂流水线内的生产环境下一般使用负反馈回路控制机器。负反馈回路包含获取环境信息的传感器,处理传感器传入值与目标值差异的控制器,然后用电机等物理组件做出动作。
但是现实世界中机器人会受到如摩擦力,风,等等各种外力影响。为了处理这些外力,通过一个包含有控制回路和反馈机制的机制,叫 比例-积分-微分控制器(PID 控制器) 。现在已经从硬件改进为纯软件了,包括比如汽车的循环系统,无人机调整螺旋桨速度保持水平等都运用了PID控制器。
PID控制器通过控制三个值以帮助解决未来可能出现的错误。三个值包括
- 比例值——实际值和理想值差多少
- 积分值——一段时间误差的总和
- 导数值(微分值)——期望值和实际值之间的变化率
机器人三定律
艾萨克·阿西莫夫为机器人行为指定的道德指南,简单说就是让机器人不要伤害人类。
- 第一定律:机器人不得伤害人类个体,或者目睹人类个体将遭受危险而袖手不管
- 第二定律:机器人必须服从人给予它的命令,当该命令与第一定律冲突时例外
- 第三定律:机器人在不违反第一、第二定律的情况下要尽可能保护自己的生存

计算机心理学
为了做出方便人类使用的计算机,需要了解计算机和人类的优缺点,利用计算心理学,以求更好的计算机设计。优秀的系统设计师在创造软件时会运用社会心理学,认知心理学,行为心理学,感知心理学的原理
利用视觉系统,认知系统设计界面
人类擅长给颜色强度排序,但不擅长给颜色排序。前者指按照颜色深浅排列很容易,但是将颜色排序按照色相排序对人类就很困难,即使能想到按照光的波长排序也显得很累,大部分人会排的很满而且容易出错。由于视觉系统天生是这样,所以用不同颜色显示连续性数据,是个糟糕的选择。如果数据没有顺序(如分类数据),用不同颜色就很合适
两者对于界面设计的利用包括Android的材料设计,颜色上就会要求一个界面限定一个色系的颜色,通过不同颜色区分出内容的重要级别以及强调某些内容。而多个(一般一个界面颜色不超过3个)不同的颜色会干扰对界面优先级的判断而很少使用。
理解人类的认知系统能帮助设计更好的界面,比如,如果信息分块了即(把信息分成更小,更有意义的块),会更容易读,更容易记。界面设计使用分块虽然更费时费空间效率更低,但比如下拉菜单和带按钮的菜单栏等分块更有利于人类浏览,记忆以提高效率。
直观功能
直观功能 为如何操作物体提供线索且广泛用于图形界面,直观功能做的好,用户只需要看一眼就知道怎么做:
例如窗口右上角的三个按钮,可以很直观的感觉出是控制窗口三个状态(最小化,最大化和关闭)

当然这可能是习惯被电子驯化之后的结果,类似于看到手柄就感觉是游戏相关,看到一个▶就感觉是播放什么东西。再联想到事实上拨号键盘和1.44mb软盘现在已经很少用了,但还是作为图标符号被保留了下来。
认出与回想
认出与回想是和直观功能相关的一个心理学概念,指的是用文字,图片或声音等感觉来触发记忆会容易得多,例如考试中选择题比填空题容易得多(再例如百词斩脱离图片就不记得单词)。所以使用图标表示功能,如垃圾桶表示回收站。
但是,让所有菜单选项好找好记,有时候意味着用的时候会慢一些。这与另一个心理学概念专业知识冲突,当使用界面熟悉之后,速度会更快一些,所以好的界面应该提供多种方法来实现目标,一个例子是复制粘贴,可以在右键的下拉菜单中找到,也可以用快捷键,一种适合新手,一种适合专家,两者都不耽误。

情感计算 与 人机交互
情感计算系统,能够通过传感器等分析人类情感,根据用户的状态做出合适地反应,让使用电脑更加愉快以此来优化计算机使用体验。通过情感计算,计算机知道如何回应用户的状态。
人们往往会被看到的内容情绪影响,变得积极或消极。如果想说服,讲课,或引起注意,眼神注视非常重要,谈话时注视对方,可以提升参与感等等,这些东西都是计算心理学的内容。
人机交互也是一个重要的领域,人类喜欢拟人化的物体尤其是会动的物体。人机交互HRI,是一个研究人类和计算机交互的领域。而随着机器人做得越来越像人类,人们对其外貌与人类的相似度,做出的行为都会被心理学+计算机科学很大程度的影响。

教育科技
计算机带来的最大改变之一是信息的创造和传播能力。随着知识载体从广播和电视,到DVD和光碟逐步迭代,教育科技行业在高速地发展着。(小时候英语听力还是发磁带,现在都是小程序打开听力视频了)
影像学习 大型开放式在线课程MOOC
影像学习中有三个主动学习的技巧可以显著提高学习概率:
- 调整视频速度到适合自己帮助理解视频
- 在理解困难处暂停仔细思考
- 完成视频中提供练习
而MOOC(Massive Open Online Courses)是这个老想法的新化身。其为了有效学习,学生需要及时获得反馈,于是有两种相对有效的方法,一个方法是同学相互打分,另一个是开发相应的电脑打分算法辅助作业打分。
智能辅导系统 Intelligent Tutoring Systems
智能辅导系统一般使用AI实现,目的是在正确的时间提供正确的资料,让用户练习没理解的难的部分,而不是给出用户已经学会的内容。
假设学生在一个假想的辅导系统中研究一个代数问题,这里使用判断规则来表示问题的执行步骤。即此例中3x + 7 = 4的判断规则表示正确的下一步即两侧-7,这样通过学生的下一步结果是否符合判断规则就可以判断其常犯错误。
学生做完一个步骤后可能触发多个判断规则,系为了弄清 是什么原因让学生选了那个答案。会将判断规则和算法结合使用,判断可能原因。判断规则+选择算法,组合在一起成为 域模型。
智能辅导系统负责创建和维护学生模型,记录学生已经掌握的判断规则,以及还需要练习的生疏部分,这就是个性化辅导需要的。

贝叶斯知识追踪
但只靠学生对一些问题的回答,来弄清学生知道什么,不知道什么,是很大的挑战。所以一般常用贝叶斯知识追踪 来解决这个问题。其通过给学生出题,会看学生答题的正确度,更新学生掌握程度的估算值。再过对学生做题结果的判断,用四种概率更新学生模型:
- 学生学会的概率
- 学生瞎猜的概率
- 学生失误的概率
- 学生做题过程中学会的概率

通过贝叶斯知识追踪的结果系统会选择适合学生的问题,让学生在挑战中学习知识,这叫自适应式程序
教育数据挖掘 Educational Data Mining
App 或网站收集上百万学习者的数据以发现包括常见错误,一般哪里难倒学生,回答前暂停了多久,哪个部分加速视频,学生如何在论坛和其他人互动等数据评估学生知识掌握状态的领域叫做教育数据挖掘。
奇点,天网与计算机的未来
普适计算
普适计算,又称普存计算、普及计算、遍布式计算、泛在计算,是一个强调和环境融为一体的计算概念,而计算机本身则从人们的视线里消失。普适计算已经有了很大发展,现在我们的冰箱、电视和手表等等,凡是电子产品,都有计算机的影子(智能家居生态)。不过它未能像空气一样融入人的生活。
奇点
在未来,计算机的计算能力会不断发展,最终会超过人类的计算能力。然后人的参与会越来越少,人工超级智能会开始改造自己。而智能科技的失控性发展则叫奇点,不过暂时奇点还在遥远的未来。
技术性事业
随着计算机和人工智能的发展,有些职业不需要人来进行了,尤其是一些重复性的行为或者繁杂劳动力的行为,这就是最常见的技术性失业。往早了说当初纺织机出现,纺织工人失业。自动接线板出现,电话接线员事业。现在AI生成代码(文本),生成绘画作品也逐步出现了,而随着这些科技的进步,结果上看终究是使社会生产力提高,改善了人们的生活水平。
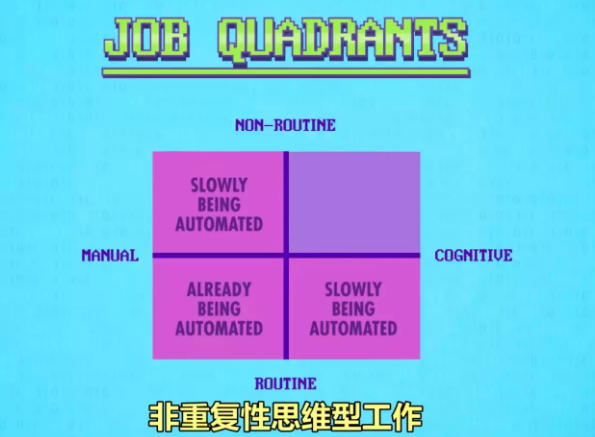
这里工作可分为四个象限
- 手工型工作 - 比如组装零件
- 思维型工作 - 比如选股票
- 重复性工作 - 流水线做相同的事情
- 创造性工作 - 需要创造性的解决问题
这里暂时除了非重复性思维型工作包括教师和艺术家其余工作都有被自动化逐渐取代的可能。
未来
一些超人类主义者认为会出现改造人,人类和科技融合在一起,增强智力和身体。也有人说,人死后人的脑子里的信息进入电脑中,成为数字人。或者机器人以超出人类的寿命替代人类去探索宇宙。

总结和感想
这里是提前写好的一些总结和感想
大概花了三个星期多才记了这些笔记,起初刚看到这个视频的时候还是直接硬看。然后看到ALU那块遭重了,一眼看不明白决定在纸上理一理。
然后感觉容易忘想着记个笔记,然后搜索到了相关笔记进行缝合借鉴。感觉自己的体会和总结能力似乎没有得到相应的提升,倒是了解了不少相关的知识,然后发现计算机这一学科真的水好深啊(难视),每一个知识点下面都有几乎查不完的细节,就光算法和数据结构我估计啃一个学期也拿捏不住。
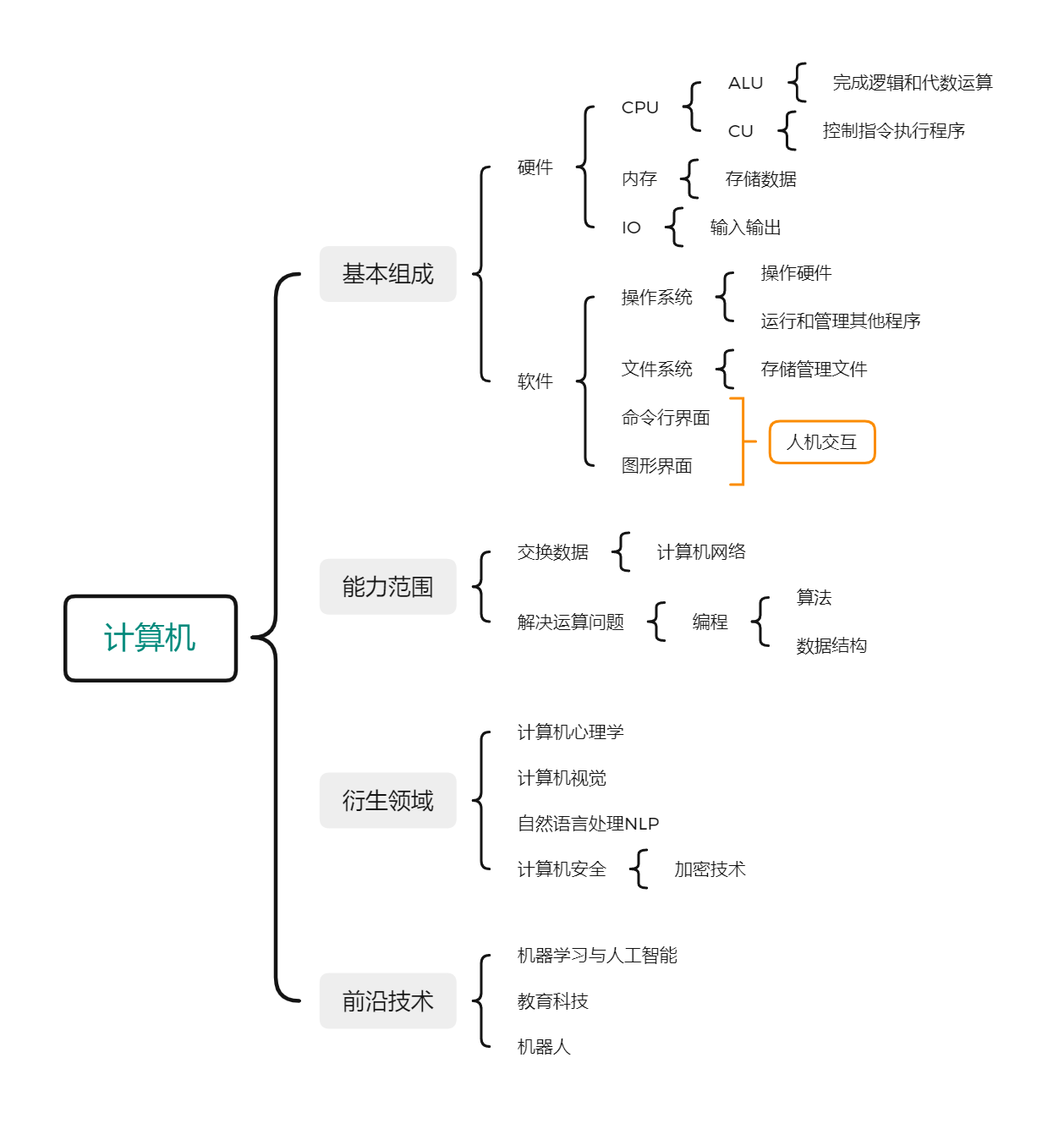
估计最后做完笔记自己看一遍理一理做个思维导图啥的就去从编码和计算机是怎么跑起来这两本书里学习了。然后再考虑CSAPP和TAOCP吧。能从暑假大概划拉一个月鸟瞰一下cs感觉也不算特别摆了。开学看前两本书的中间还想顺便学学数据库(mysql&php)和linux(两个都是学校课业要求),捡起第一行代码敲敲复习。下面是一个简单总结的脑图,可能有不少问题
参考链接
前面大致参考(几乎就是缝合)两个知乎回答的,后面不想看视频找到了视频的字幕和相关总结笔记,于是后面是同时开着三个窗口对比试图总结学习。
-
32 计算机科学速成课 02:电子计算机、继电器、术语“bug”的来源、真空管、晶体管、发展路径 - 小王同学在积累的文章 - 知乎
-
【计算机科学速成课笔记】CrashCourse_CS_notes (P1-P5) - Syddd的文章 - 知乎 ,偏概括
-
https://github.com/1c7/crash-course-computer-science-chinese
-
https://qastack.cn/software/148677/why-is-80-characters-the-standard-limit-for-code-width


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









