







KMP学习笔记
前置基础知识
学习KMP算法时四处缝合的笔记

-
字符串模式匹配
假定给出两字符串// 此处为了表明字符串由子串组成使用了拼接进行强调 String S = "A"+"ABBCC"+"DDEEFFGG"; String T = "ABBCC"; 此处T称为模式,在主串S中寻找子串T的过程就叫做模式匹配。
-
BF(Brute Force)算法(朴素的模式匹配算法)
BF算法即暴力算法,是普通的模式匹配算法,是将主串S的第一个字符与模式T的第一个字符进行匹配,若相等则继续往后比较S和T的字符。不相等则比较S的第二个字符和T的第一个字符依次比较直到得出最后的比较结果。
此处假定给出主串S和模式T为:// 指定S长度m为8,T长度n为5 String S = "AAAAAAAG"; String T = "AAAAG"; 从第一位逐位判断可以看到会在主串S在第五个位置发现不匹配模式T,于是S后移三位才能匹配到T,中间遍历了两次T的长度n就重复了。最坏情况下模式T位于主串最后位,需要迭代m-n+1轮,每轮比对n次则一共比较了(m-n+1) * n 次。时间复杂度随着m大于n会逼近至O(mn)
-
前/后缀, 公共前缀后缀
前后缀指不包含字符串本身,即不包含首尾字符的子串,如字符串 ABCBCA
// 其前缀包括 String prefix = "A AB ABC ABCB ABCBC"; // 后缀包括 String suffix = "A CA BCA CBCA BCBCA"; 而公共前缀后缀则指前后缀相同 如此处 只有 一个公共前缀后缀 A
BF算法暴力匹配
先从比较好理解的BF算法的运行过程开始再引出KMP算法
首先规定i是主串S的索引下标,j是模式T的索引下标,分表表示主串S和模式T当前匹配的位置。则代码运行基于以下两条原理
- 如果当前字符匹配成功(
S[i] = T[j]),则继续匹配下一个字符 ( i++, j++ ) - 如果匹配失败(称为失配
S[i] != T[j]),则主串从当前已匹配字符的下一位继续匹配,模式则从头匹配。即令i = i - j + 1, j = 0
代码
以下是BF实现代码和运行实例
public class Test {
public static void main(String[] args) {
String S = "ababcabcacbab";
String T = "abcac";
long st = System.currentTimeMillis();
int res = BF(S.toCharArray(), T.toCharArray());
if(res != -1) {
System.out.printf("匹配主串索引为%d\n", res);
System.out.printf("匹配结果为 '%s' \n", S.substring(res, res+T.length()));
}else {
System.out.println("模式不匹配");
}
System.out.printf("运行时间: %d ms. \n", (System.currentTimeMillis() - st));
}
static int BF(char[] S, char[] T) {
int i = 0, j = 0;
while(i!=S.length && j!=T.length) {
if(S[i] == T[j]) {
i++;
j++;
}else {
i = i - j + 1;
j = 0;
}
}
// 模式能遍历完说明匹配成功 返回当前匹配字符开始处
if(j==T.length) return i-j;
return -1;
}
}
运行步骤
用实例中的主串和模式的运行过程来理解代码
首先初始化两个索引指针,未遍历到的字符统一标志为黑色
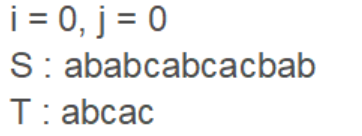
第一次循环至失配, 标志为红色的为当前失配坐标处,蓝色则为当前循环匹配子串
可以看到第一次匹配至2就出现了a和c不匹配,所以i重设为 i - j + 1 = 1,j = 0 从头开始遍历字符串
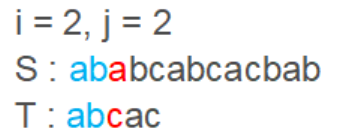
第二次循环第一位判断就失配了,于是此时 i = i - j + 1 = 2, j = 0 标记为灰色字体为不再需要遍历的子串
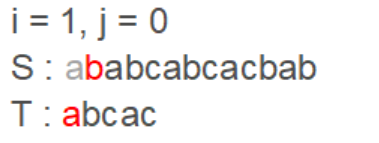
第三次循环至第7位失配,重设为 i = 3, j = 0 从此看出每次 i 索引位都是设为当次循环匹配字符开始处的下一位

第四五次循环都是第一位失配

第六次匹配成功,此时i = 9,j = 4 匹配成功自家后j到达模式长度结束循环,最终代码返回前判断模式是否遍历完来决定是返回当前匹配索引开始处还是表示不匹配的-1

缺点分析
在运行时会出现已经匹配了一段字符后失配则重新回溯的情况。如第四五次循环,第三次循环中已经匹配过的bc显然与第一个字符a是不匹配的,那这两次循环实际上是没有意义浪费了时间的。如果将第三次循环结束后将模式当前索引向左滑动三位继续 i = 6, j = 1 的字符匹配,会明显加快进程。这样就引出了不回溯 i 以加快匹配效率的KMP算法。
KMP算法
KMP(Knuth–Morris–Pratt)算法是一种字符串
模式匹配算法。核心原理是利用匹配失败后的信息,尽量减少模式串与主串的匹配此处以达到快速匹配的目的。时间复杂度为O(m+n)
它的改进在于,每当从某个起始位置开始一轮匹配后,如果在匹配过程中出现失配,不回溯 i 而是利用已经得到的部分匹配结果将 指针 在 模式 上向右移动(退回)尽可能远的一段距离 再按照规则进行下一轮匹配
失效函数值 Next
而实现每个位置失配都能找到相应模式退回相应的回溯值通过一个 通常被命名为next的 失效函数值 实现。这个数组存储模式每个子串的最长公共前缀后缀长度。因为是前缀后缀长度,不包含字符串本身,所以第一位值标记为-1占位。
如对于字符串abcac 可以构建出失效函数值
int[] next = {-1,0,0,0,1};
因为列出每一位 a, ab, abc , abca 只有最后一位有公共前缀后缀, 则值为长度1。 其他都没有公共前缀后缀则值为0。
代码实现求失效函数值
能够手推出失效函数值还需要能用代码实现,这里通过第一位占位 值为-1 和第一个子串为单个字符则没有前后缀 值为0 可简单推出 next[0] = -1, next[1] = 0 于是接下来的问题是如何用代码实现继续往下构造
此处通过一个模式串构建失效函数值的例子来试图弄明白罢!
给定模式P如下
String P = "ABCDABE";
先手推出next
int[] = {-1, 0, 0, 0, 0, 1, 2};
手推的过程中可以感受到有一个比对前后缀的过程,这里可以用BF算法中的思想,将读取每一个子串作为模式,原本的模式作为主串进行匹配。
先初始化出 一个长度为P长度且第一个值为-1的数组,此处再定义一个用于遍历模式的指针j 此处j作为”主”串指针,t则为模式指针
static int[] buildNext(char[] P) {
int m = P.length;
int j = 0;
int[] next = new int[m];
int t = next[0] = -1;
return next;
}
那么首先遍历条件就是 j < m -1 了 ,即遍历范围除了模式本身。而判断条件是主串中 模式指针和主串指针 是否匹配(确实)
于是添加代码如下, 此处判断t == -1是用于判断首位, 并且或判断的短路效应会使前面 t==-1 条件为true时会停止继续判断 P[j] == P[t] 的条件避免越界错误
注意能理解将模式作为主串即可
static int[] buildNext(char[] P) {
int m = P.length;
int j = 0;
int[] next = new int[m];
int t = next[0] = -1;
while(j < m -1) {
if(t < 0 || P[j] == P[t]) {
}
}
return next;
}
于是匹配或位于 行首则将指针各自加1并 在匹配的情况下 将 当前匹配 最长公共前后缀长度 结果t 存入next的主串指针处,失配则将模式串指针赋值为当前next 的模式串指针处
因为int数组构建默认值都为0,失配一般都会将模式串指针t重新赋值为 0 (回溯)
此处匹配前后缀的原理是主串指针一直自加,一开始差值为1恰好判断子串长度为2位,如果失配则模式指针回溯已重新匹配当前循环前后缀
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] next =buildNext("ABCDABE".toCharArray());
System.out.println(Arrays.toString(next));
}
static int[] buildNext(char[] P) {
int m = P.length;
int j = 0;
int[] next = new int[m];
int t = next[0] = -1;
while(j < m -1) {
if(t < 0 || P[j] == P[t]) {
j++;
t++;
next[j] = t;
}else {
t = next[t];
}
}
return next;
}
}
附带了实现和运行例子
运行步骤
此处大致将例子 String P = "ABCDABE";运行过程描述一下方便理解。

KMP代码实现
首先规定 i 是主串S的 索引指针,j 是模式P 的索引指针。则KMP代码基于以下三条规则运行
- 如果
j = -1, 则i++, j++继续往下匹配 - 如果字符匹配
(S[i] = P[j]), 则i++, j++继续往下匹配 - 如果失配
( j != -1, 且 S[i] != P[j]), 则主串指针 i 不变, j 设为 失效函数值中相应值( j = next[i] ),意味着失配时模式指针相对于主串指针向右移动j - next[j]位。
则有代码如下
public class Test {
public static void main(String[] args) {
String S = "ababcabcacbab";
String T = "abcac";
int[] next =buildNext("abcac".toCharArray());
long st = System.currentTimeMillis();
int res = KMP(0, next, S.toCharArray(), T.toCharArray());
if(res != -1) {
System.out.printf("匹配主串索引为%d\n", res);
System.out.printf("匹配结果为 '%s' \n", S.substring(res, res+T.length()));
}else {
System.out.println("模式不匹配");
}
System.out.printf("运行时间: %d ms. \n", (System.currentTimeMillis() - st));
}
static int[] buildNext(char[] P) {
int m = P.length;
int j = 0;
int[] next = new int[m];
int t = next[0] = -1;
while(j < m -1) {
if(0 > t || P[j] == P[t]) {
j++;
t++;
next[j] = t;
}else {
t = next[t];
}
}
return next;
}
static int KMP(int start, int[] next, char[] S, char[] T) {
int i = start;
int j = 0;
while(i != S.length && j != T.length) {
if(j < 0 || S[i] == T[j]) {
i++;
j++;
}else {
j = next[j];
}
}
if(j == T.length) return i - j;
return -1;
}
}
运行步骤
实在懒得逐个写解释了(
判断-1只有首位不相等才会发生
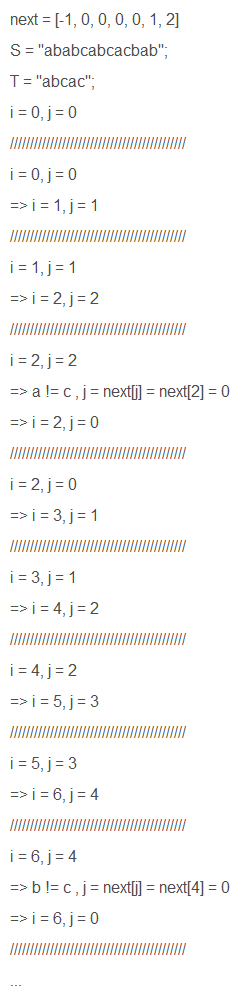
使用情景
如果多跑几个会发现实际上KMP花费的实际往往比暴力算法还久(当然样例量级小到一定程度也差不了多少),这是因为KMP算法的优势是在查找的串越长,重复序列越多优势才越多的(因为需要构建失效函数值才能启动,而朴素算法直接就能启动)。例如只有01的超长包括重复字符串就很适合用KMP匹配。实际使用使用暴力算法还是KMP还得看数据量级
例题
有空了在这里贴点KMP例题方便巩固一下知识点
28. 找出字符串中第一个匹配项的下标
这都题可以直接调indexOf的api,但可以写kmp练手(
手撕朴素法
class Solution {
public int strStr(String haystack, String needle) {
int i = 0;
int j = 0;
while(i!=haystack.length() && j!=needle.length()){
if(haystack.charAt(i)==needle.charAt(j)){
i++;
j++;
}else{
i = i - j + 1;
j = 0;
}
}
if(j == needle.length()) return i-j;
return -1;
}
}
KMP ,不熟练写了两个bug,一开始是子串指针回溯手糊写成了回溯 主串指针,第二个是判断 j 忘记写了,写上j == -1 的效率比 j<0 慢了一倍是没想到的。应该是我推导代码的时候哪里理解错了? 蒜了,想不明白,洗洗睡了。
class Solution {
public int strStr(String haystack, String needle) {
if(needle.length()==0) return 0;
int i = 0;
int j = 0;
int m = haystack.length();
int n = needle.length();
int[] next = buildNext(needle);
while(i!=m && j!=n){
if(j<0 || haystack.charAt(i)==needle.charAt(j)){
i++;
j++;
}else{
j = next[j];
}
}
if(j == n) return i-j;
return -1;
}
public int[] buildNext(String P){
int i = 0;
int m = P.length();
int[] next = new int[m];
int j = next[0] = -1;
while(i<m-1){
if(j<0 || P.charAt(i)==P.charAt(j)){
i++;
j++;
next[i] = j;
}else{
j = next[j];
}
}
return next;
}
}















 4935
4935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









