







提示:根据上文搭建的Prometheus服务器继续测试
链接: https://blog.csdn.net/qq_39738963/article/details/128177076
PromQL语法测试以及普罗联邦集群搭建
提示:以下是本篇文章正文内容,下面案例可供参考
一、PromQL
PromQL(Prometheus Query language)即 Prometheus查询语言的简称,它是 Prometheus 内置的查询语言,Prometheus 作为强大的开源监控系统,它最大的依赖便是PromQL,它是监控数据个性化查询、展示的基础,所以要掌握Prometheus,掌握PromQL是必备的前提。
PromQL 可以使用户实时地查找和聚合时间序列数据,表达式计算结果可以在图表中展示,也可以在Prometheus表达式浏览器中以表格形式展示,或者作为数据源, 以HTTP API的方式提供给外部系统使用。
[官网链接](https://prometheus.io/docs/prometheus/latest/querying/basics)
1、数据类型、指标类型、匹配器、运算
> 四种数据类型
1. Instant vector 【瞬时向量/数据】
- 是对目标实例查询到的同一个时间戳的一组时间序列数据(按照时间的推移对数据进存储和展示),每个时间序列包含单个数据样本
比如node_memory_MemFree_bytes查询的是当前剩余内存(可用内存)就是一个瞬时向量,该表达式的返回值中只会包含该时间序列中的最新的一个样本值,而相应的这样的表达式称之为瞬时向量表达式 ,例如
curl 'http://192.168.182.51:9090/api/v1/query' --data 'query=node_memory_MemFree_bytes'

2. Range vector 【区间向量/数据】:
- 是指在任何一个时间范围内,抓取的所有度量指标数据。比如最近一天的网卡流量趋势图、或最近5分钟的node节点内容可用字节数等,例如
curl 'http://192.168.182.51:9090/api/v1/query' --data 'query=node_memory_MemFree_bytes{instance="192.168.182.52:9100"}[5m]'


3. Scalar 【标量/纯量数据 】:
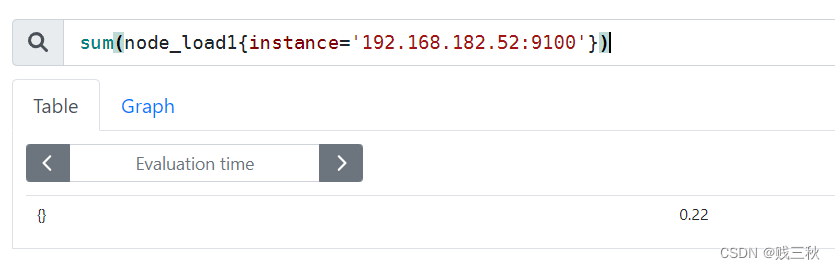
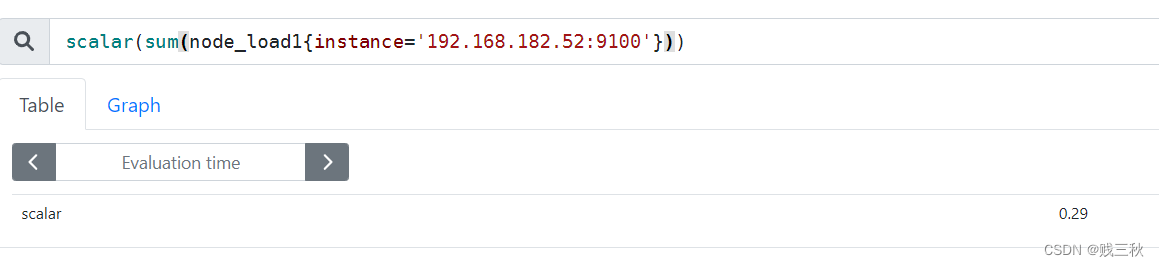
- 是一个浮点数类型的数据值,使用node_load1获取到时一个瞬时向量后,在使用prometheus的内置函数scalar()将瞬时向量转换为标量
例如:scalar(sum(node_load1))
4. String 【字符串】:
- 字符串,目前暂未使用
> 普罗四种指标类型
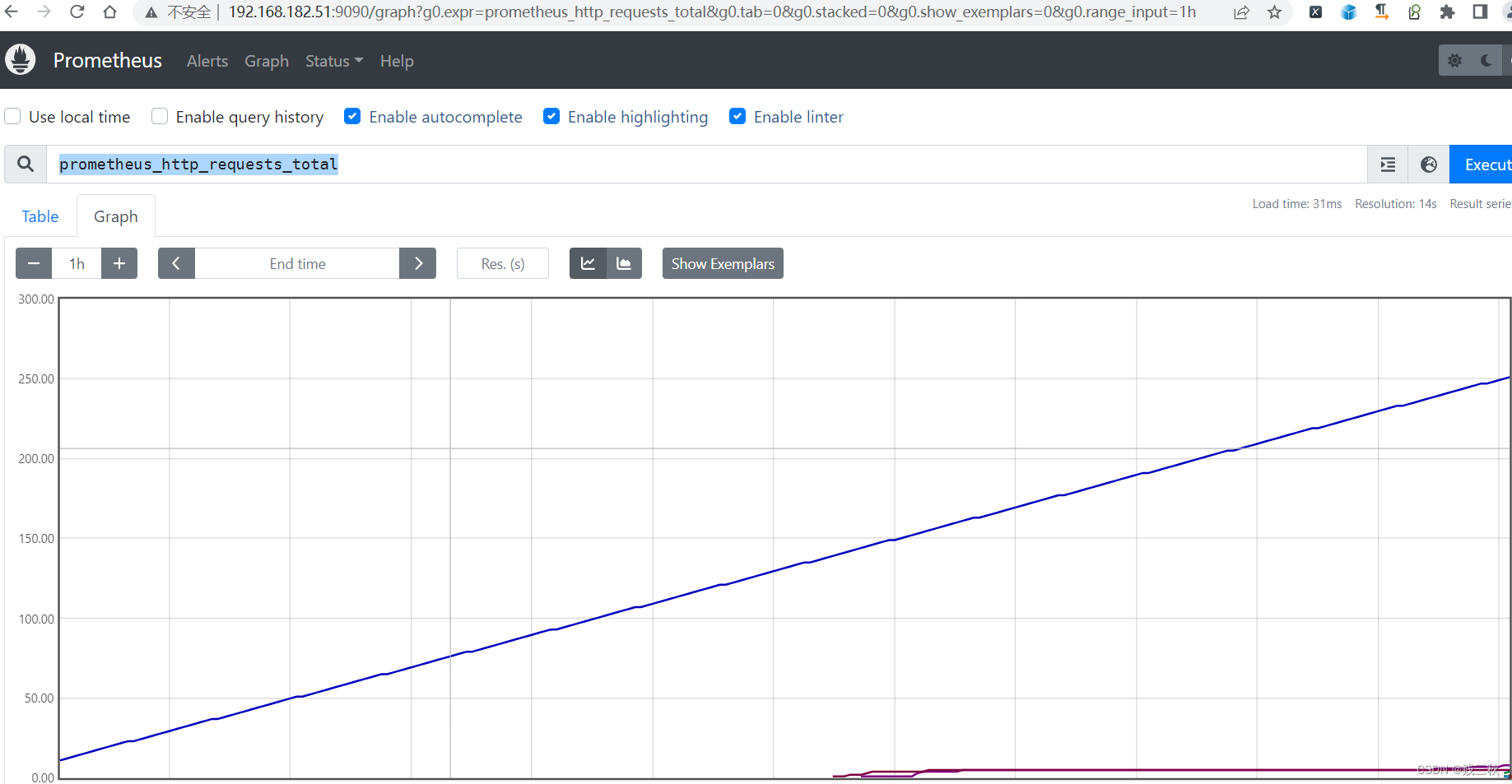
1. Counter: 计数器 ⇒ 累积数据类型,只增不减
prometheus_http_requests_total
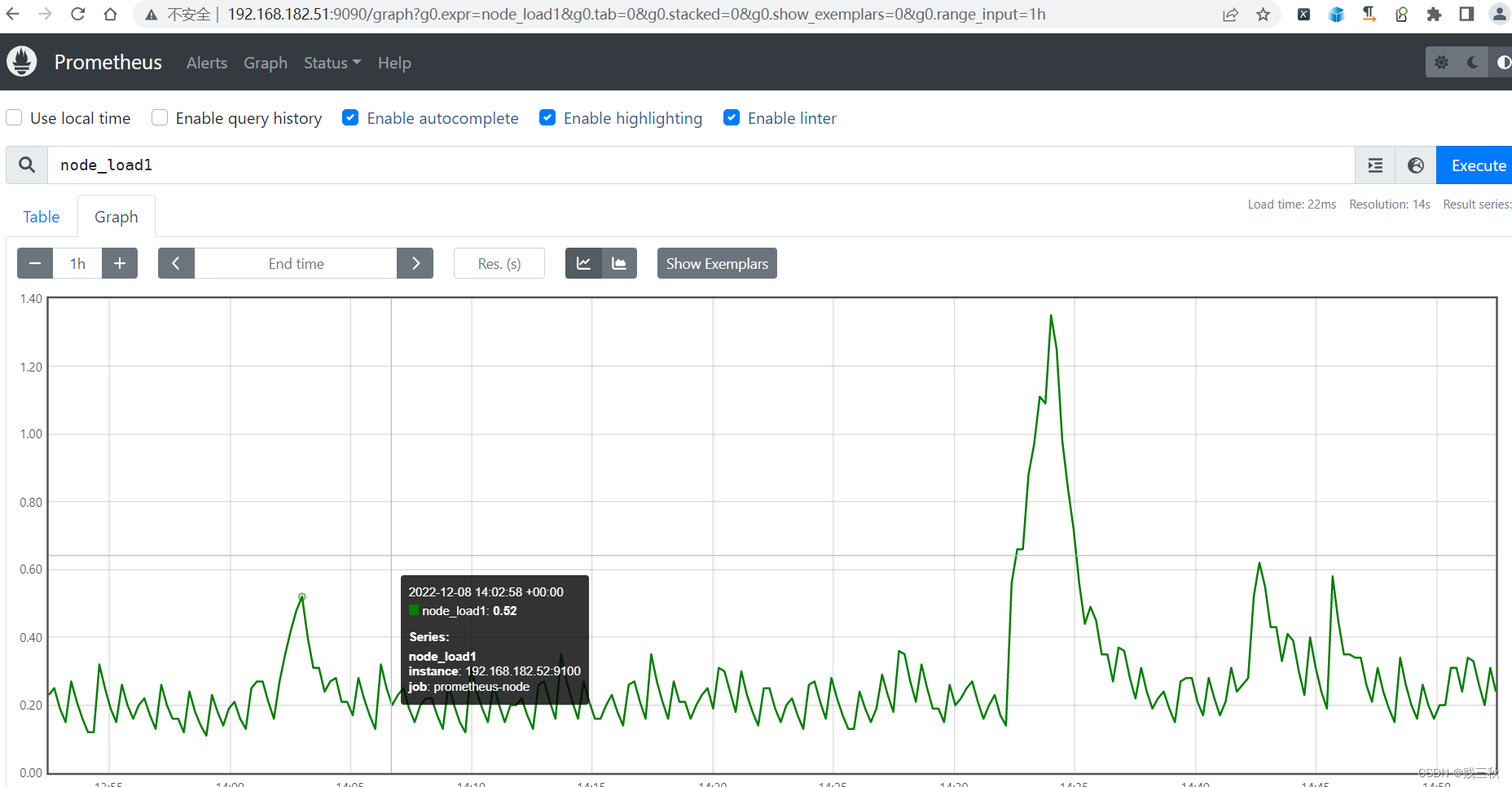
2. Gauge: 仪表盘 ⇒ 实时数据
3. Histogram:累积直方图 ⇒ 累积采样
- Histogram会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),假如每分钟产生一个当前的活跃连接数,那么一天24小时*60分钟=1440分钟就会产生1440个数据
5. Summary:摘要
- 摘要图,也是一组数据,默认统计选中的指标的最近10分钟内的数据的分位数,可以指定数据统计时间范围,基于分位数(Quantile),亦称分位点,是指用分割点(cut point)将随机数据统计并划分为几个具有相同概率的连续区间,常见的为四分位,四分位数是将数据样本统计后分成四个区间,将范围内的数据进行百分比的占比统计,从0到1,表示是0%-100%,(0%-25%,%25-50%,50%-75%,75%-100%),利用四分位数,可以快速了解数据的大概统计结果。
> 匹配器
= :选择与
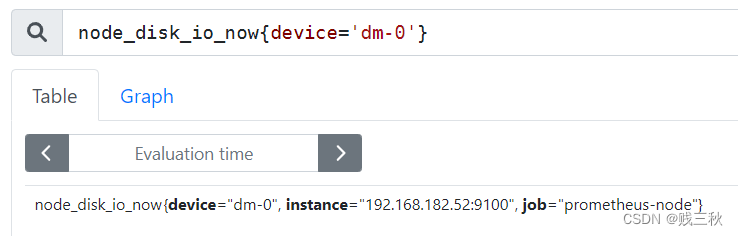
!= :选择与提供字符串相反的标签,去反
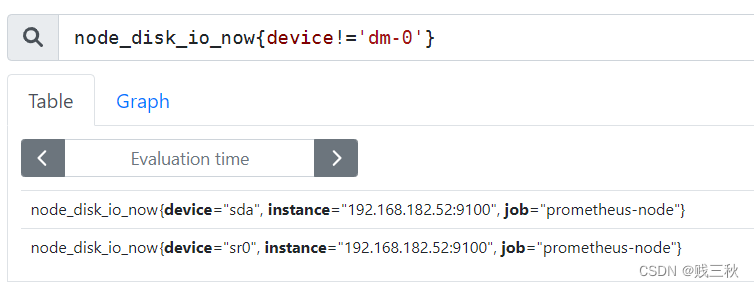
=~ :选择正则表达式与提供字符串相匹配的标签
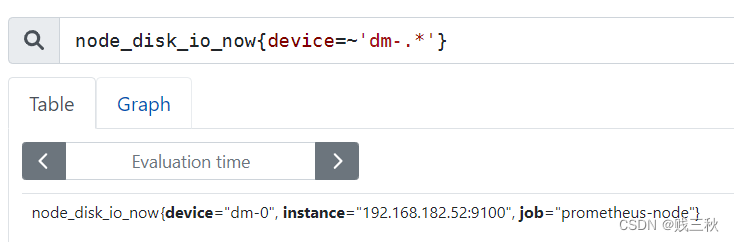
!~ :选择正则表达式与提供的字符串不匹配的标签
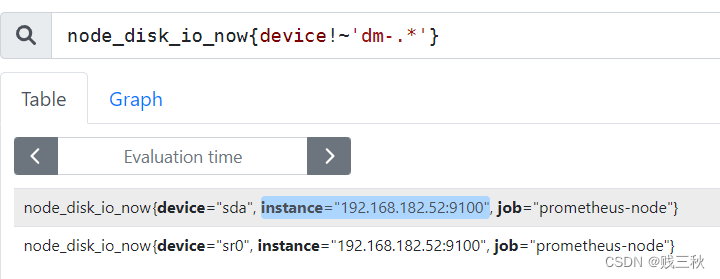
> PromQL 时间范围
- s == 秒
- m == 分钟
- h == 小时
- d == 天
- w == 周
- y == 年
> 运算符
- 加(+)减(-)乘(*)除(/)模(%)幂(^)

> 聚合运算
- max() == 获取最大值
- min() == 获取最小值
- avg() == 获取平均值
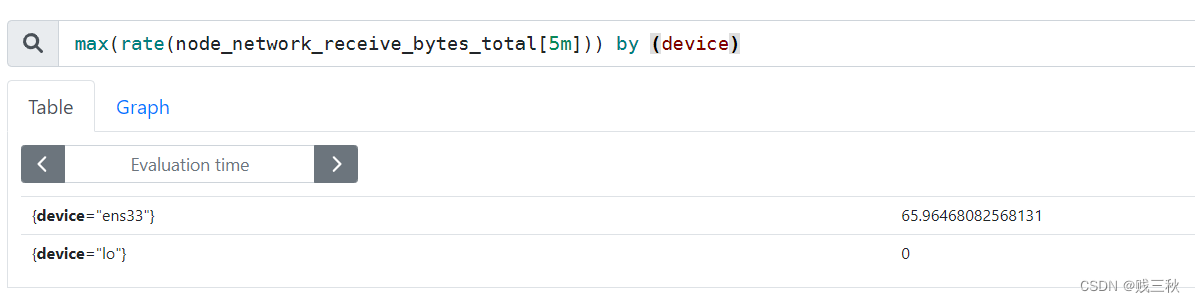
- count() == 计算条数
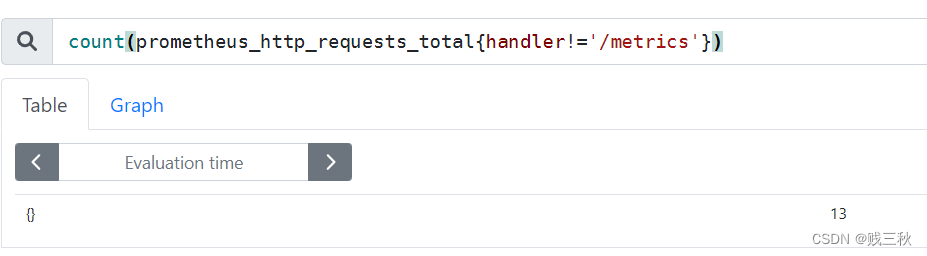
- sum() == 求和

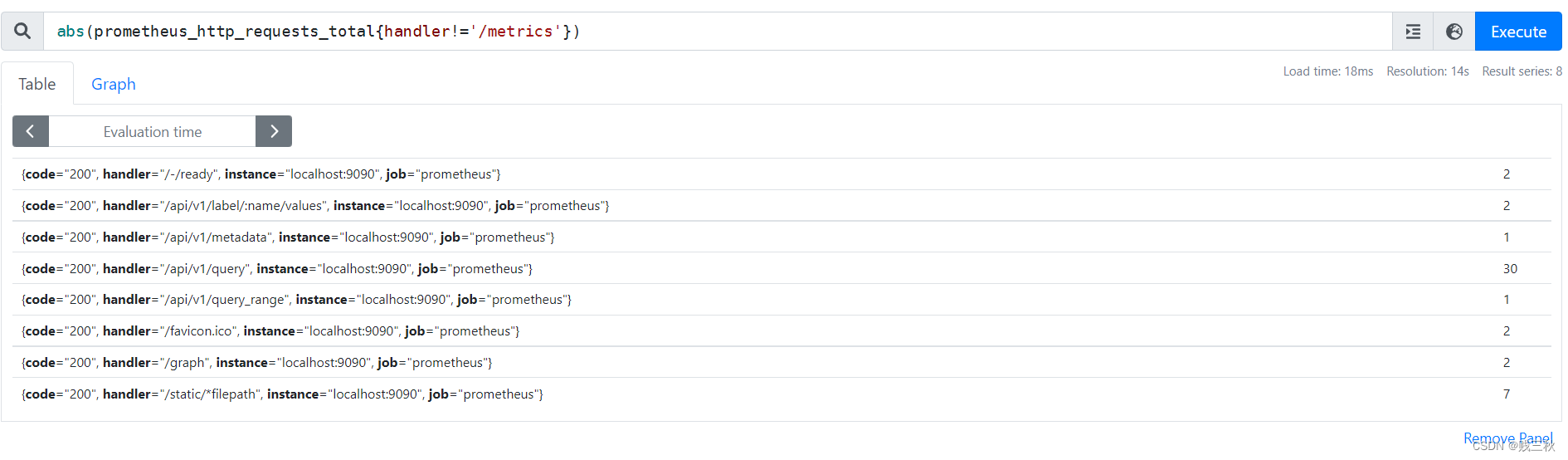
- abs() # 返回指标数据的值(绝对值)
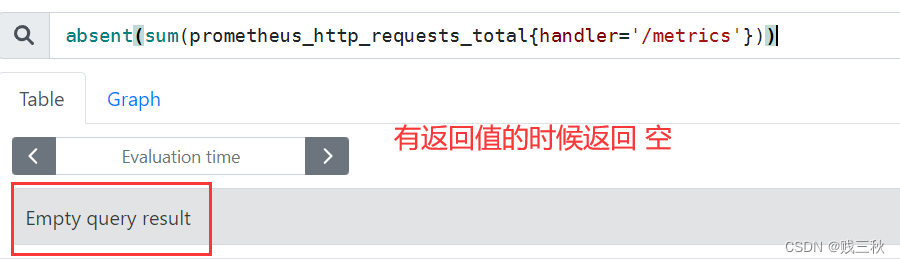
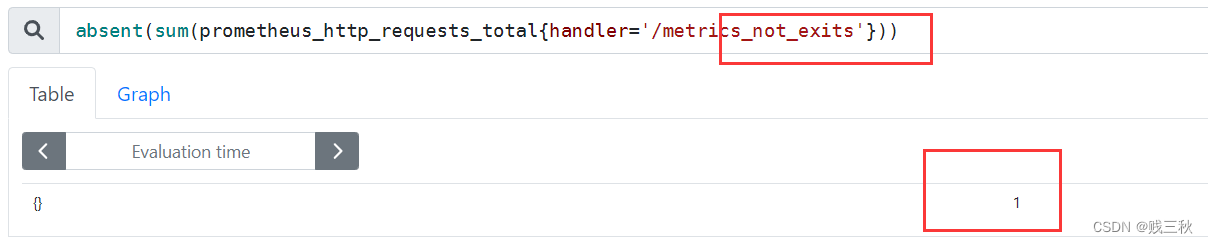
- absent() # 如果有数据就返回空,没有数据返回1,可以用于对监控项设置告警
absent(sum(prometheus_http_requests_total{handler='/metrics'}))

absent(sum(prometheus_http_requests_total{handler='/metrics_not_exits'}))
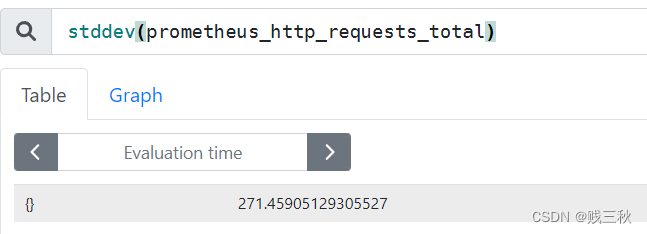
- stddev() # 标准差,标准差越大,数据差距越大
stddev(prometheus_http_requests_total)

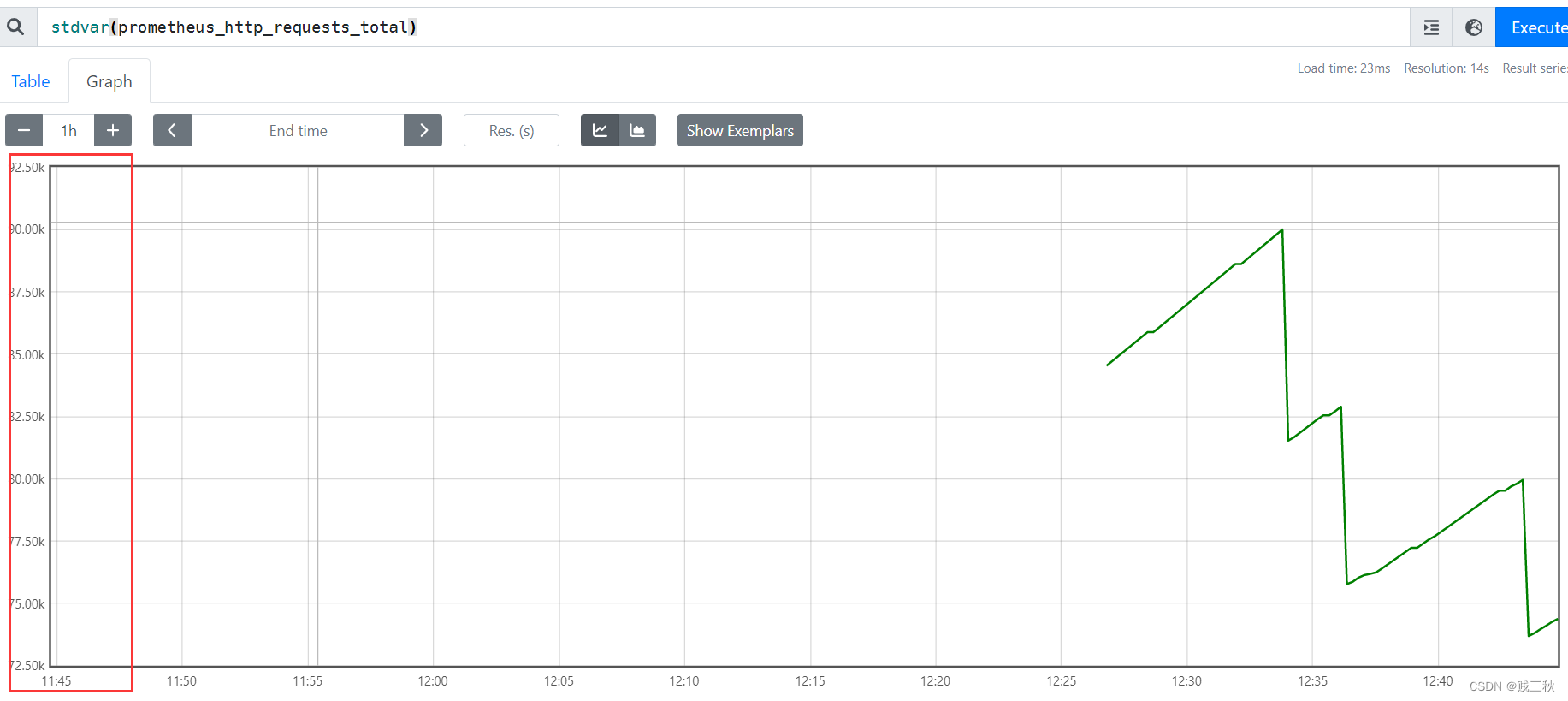
- stdavr() # 平方差,比标准差更明显,数据显示更凸显数据的不平衡

- topk() # 样本排名最大的N个数据
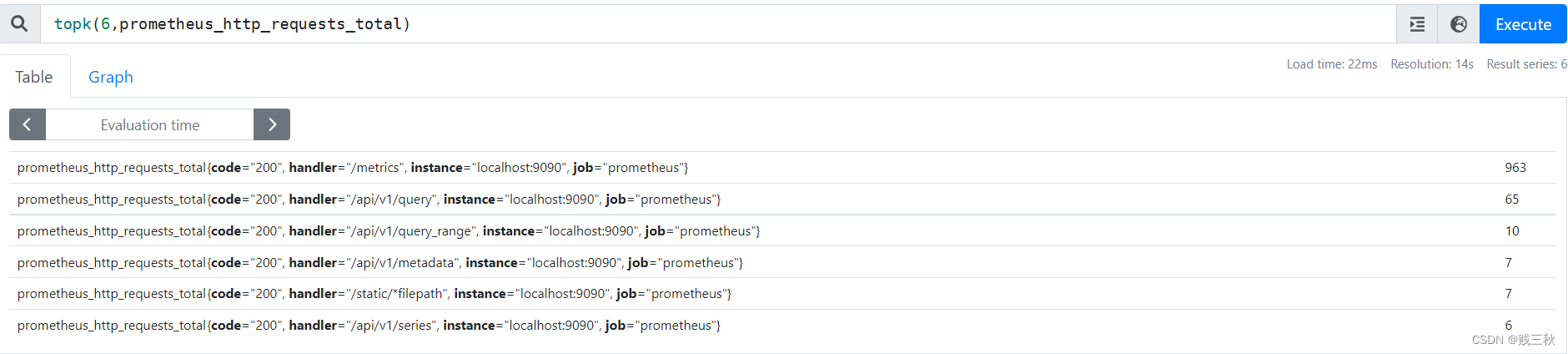
例如,取从大到小前6的数据
topk(6,prometheus_http_requests_total)
- bottomk() # 取排名最小的N个数据
bottomk(6,prometheus_http_requests_total)

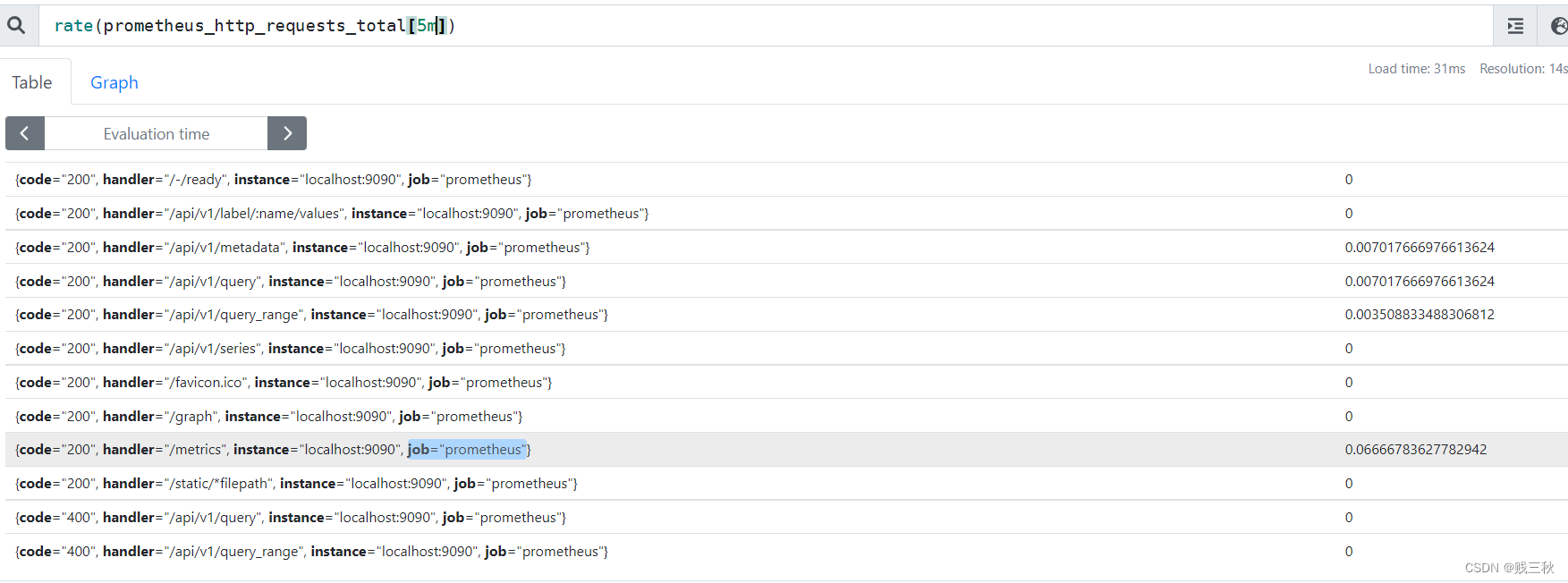
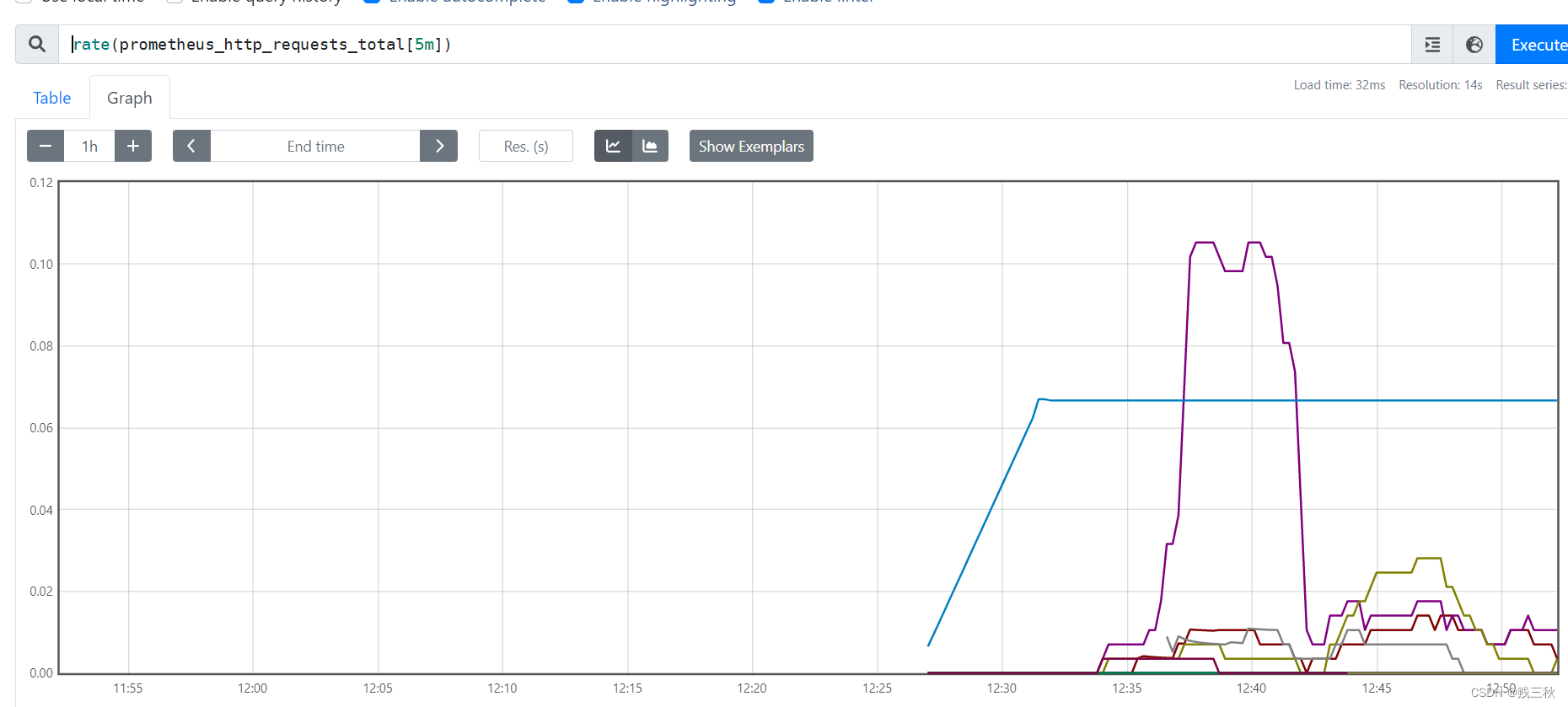
- rate() # 是专门搭配counter数据类型使用函数,rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果,适合用于计算数据相对平稳的数据。
rate(prometheus_http_requests_total[5m])
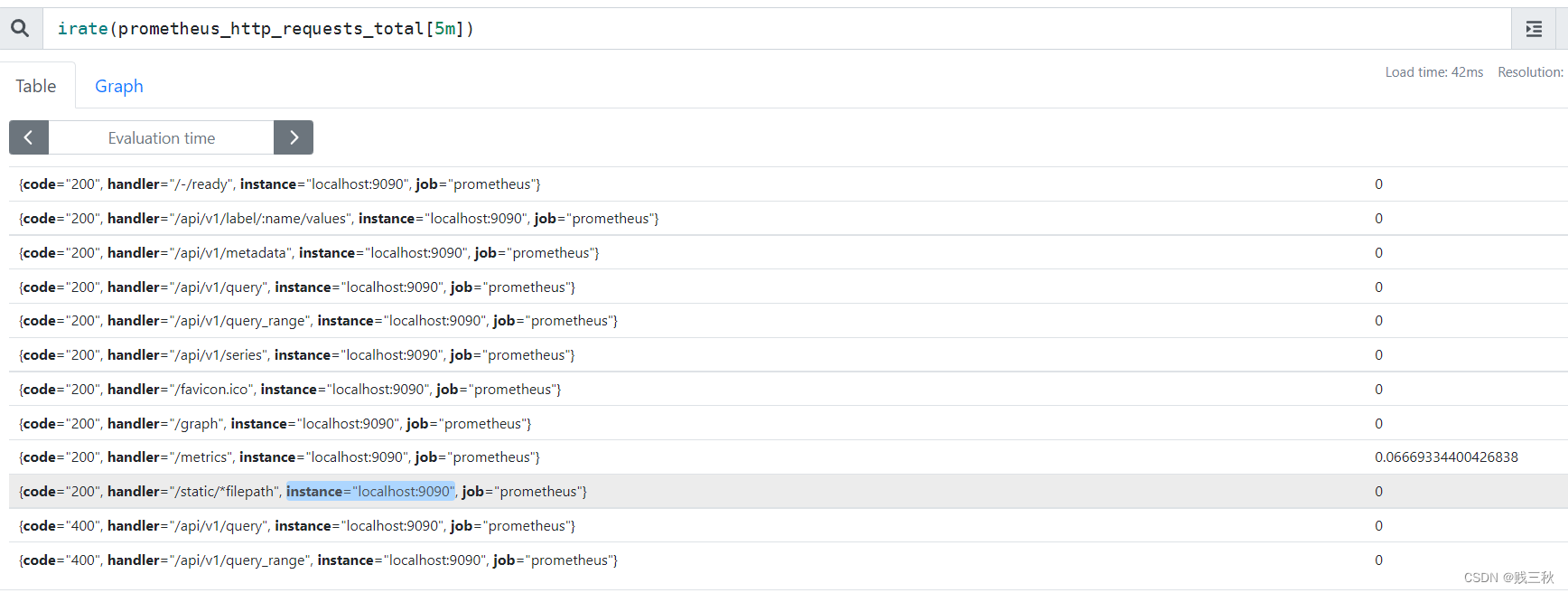
- irate() # 也是专门搭配counter数据类型使用函数,irate取的是在指定时间范围内的最近两个数据点来算速率,适合计算数据变化比较大的数据,显示的数据相对比较准确,所以官网文档说:irate适合快速变化的计数器(counter),而rate适合缓慢变化的计数器(counter)。
irate(prometheus_http_requests_total[5m])
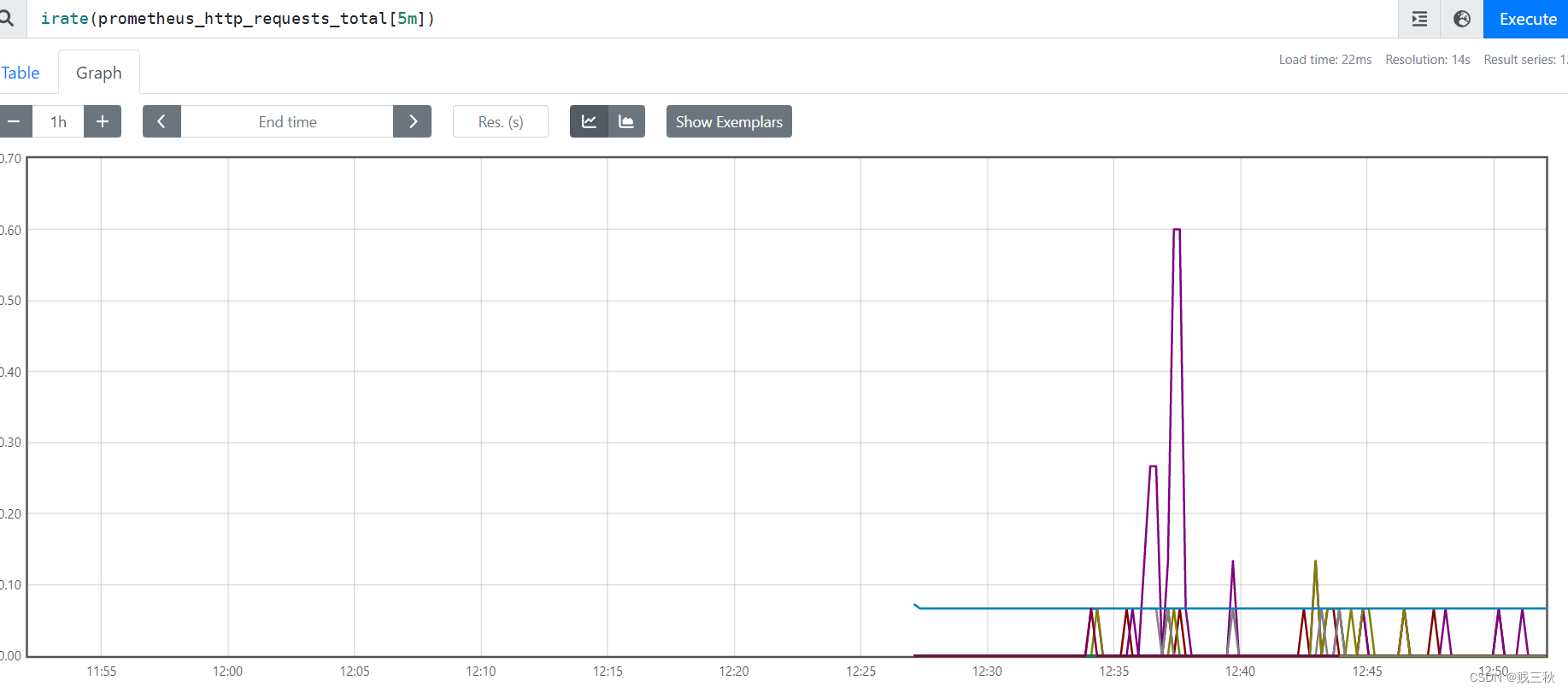
- by() # 在计算的结果中,只保留by指定的标签的值,并起初其他所有的
sum(rate(node_network_receive_packets_total{instance=~'.*'}[10m])) by(instance)

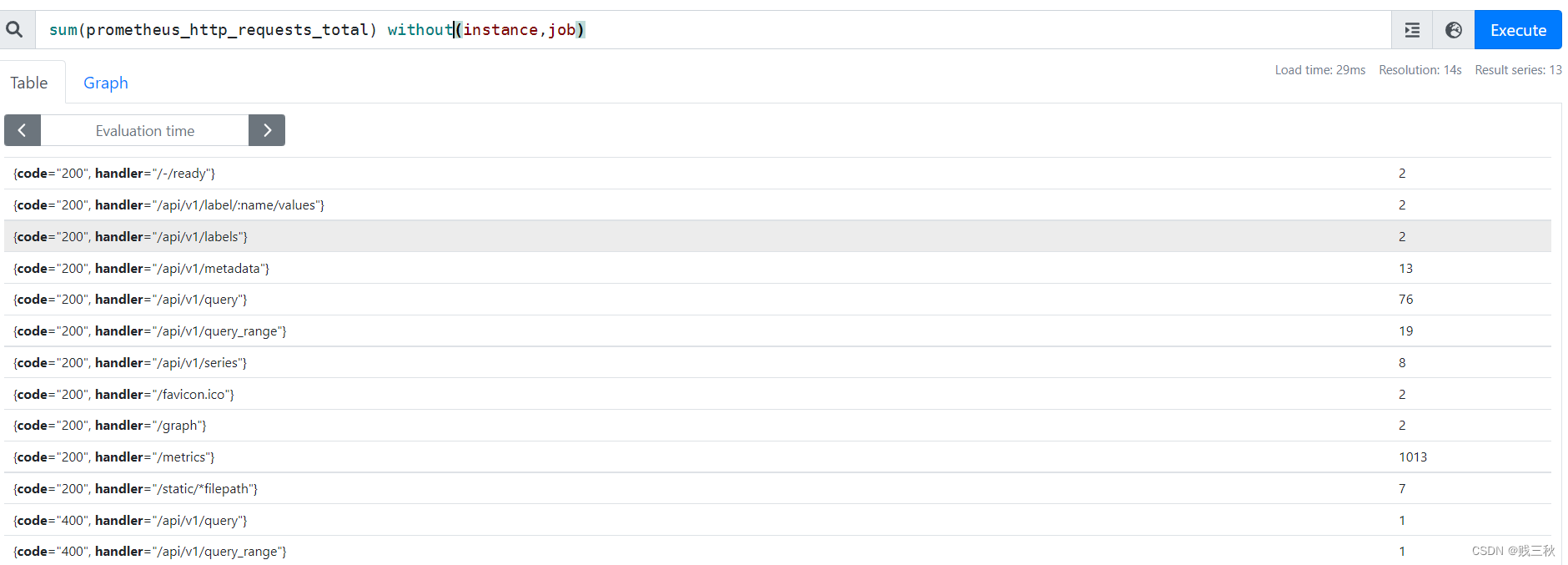
- without() # 在计算结果中移除without列表的标签,保留其他
sum(prometheus_http_requests_total) without(instance,job)
二、pushGateway
简介
- pushgateway用于临时的指标数据收集。
- pushgateway不支持数据领取(pull模式),需要客户端主动将数据推送给pushgateway。
- pushgateway可以单独运行在一个节点,然后需要自定义监控脚本把需要监控的主动推送给pushgateway的API接口,然后pushgateway再等待prometheus server抓取数据,即pushgateway本身没有任何抓取监控数据的功能,目前pushgateway只能被动的等待数据从客户端进行推送。
–persistence.file=“” #数据保存的文件,默认只保存在内存中
–persistence.interval=5m #数据持久化的间隔时间
pushgateway安装测试
1、二进制部署
- 官网下载二进制包 pushgateway1.5.1
- 在/apps路径下解压安装包,并指定软连接
tar xvf pushgateway-1.5.1.linux-amd64.tar.gz
ln -sv /apps/pushgateway-1.5.1.linux-amd64 /apps/pushgateway
- 创建service文件,启动服务并设置开机自启
/etc/systemd/system/pushgateway.service
[Unit]
Description=Prometheus pushgateway
After=network.target
[Service]
ExecStart=/apps/pushgateway/pushgateway
[Install]
WantedBy=multi-user.target
systemctl daemon-reload && systemctl start pushgateway && systemctl enable pushgateway
2、 docker部署
docker run -d --name pushgateway -p 9091:9091 prom/pushgateway:v1.5.1
3、验证
- 端口9091监听

- 访问查看
http://192.168.182.52:9091/#
http://192.168.182.52:9091/metrics
4、数据推送测试
- 通过curl命令测试推送流程
APP – (push metrics) --> Push Gateway <-- (pull metics) --> Prometheus
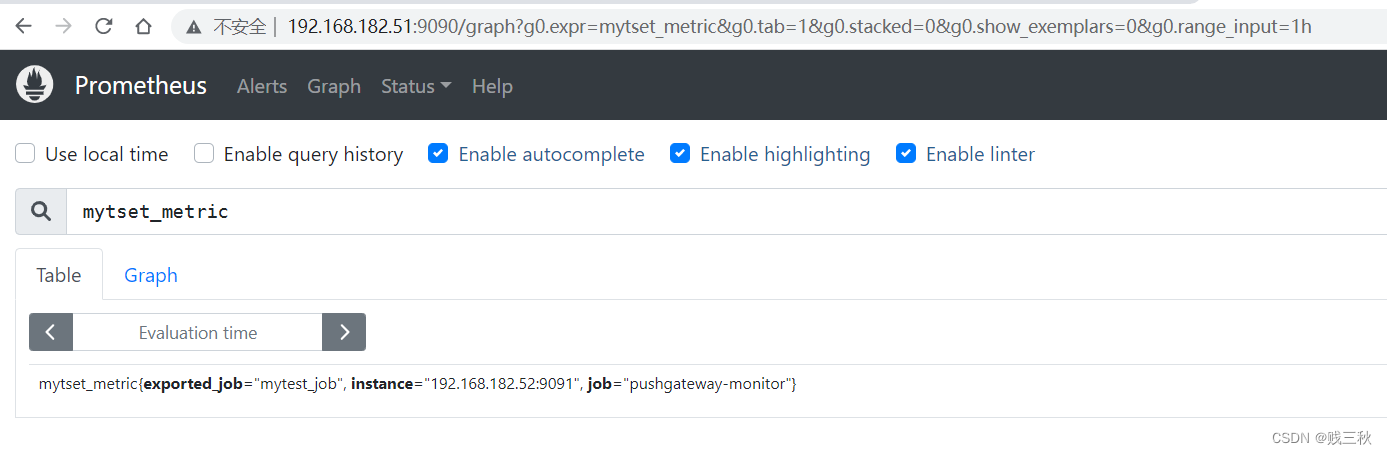
推送一个job(mytest_job),数据格式key value (mytset_metric 2022)
echo 'mytset_metric 2022' | curl --data-binary @- http://192.168.182.52:9091/metrics/job/mytest_job
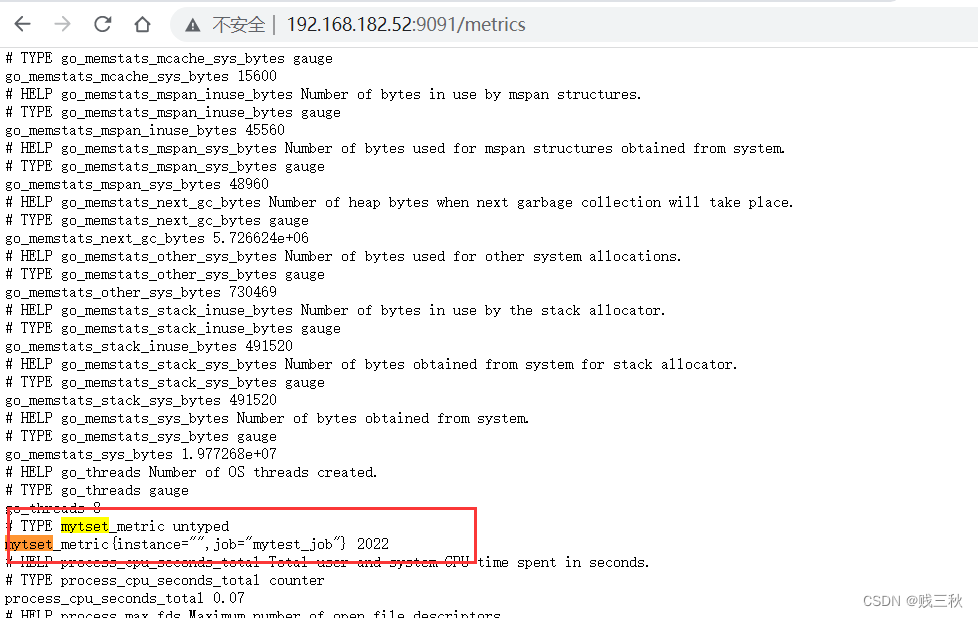

- 推送多条数据
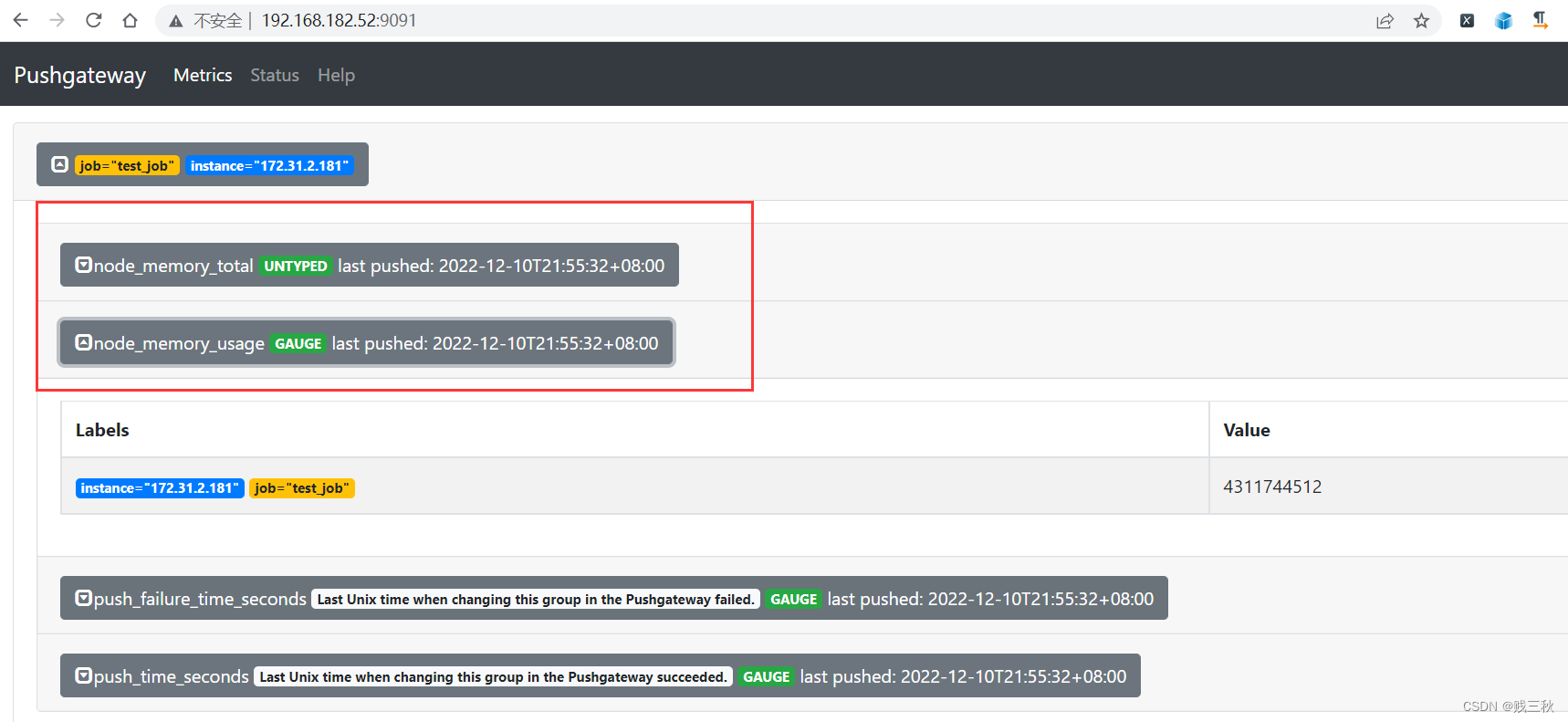
cat <<EOF | curl --data-binary @- http://192.168.182.52:9091/metrics/job/test_job/instance/172.31.2.181
#TYPE node_memory_usage gauge
node_memory_usage 4311744512
# TYPE memory_total gauge
node_memory_total 103481868288
EOF
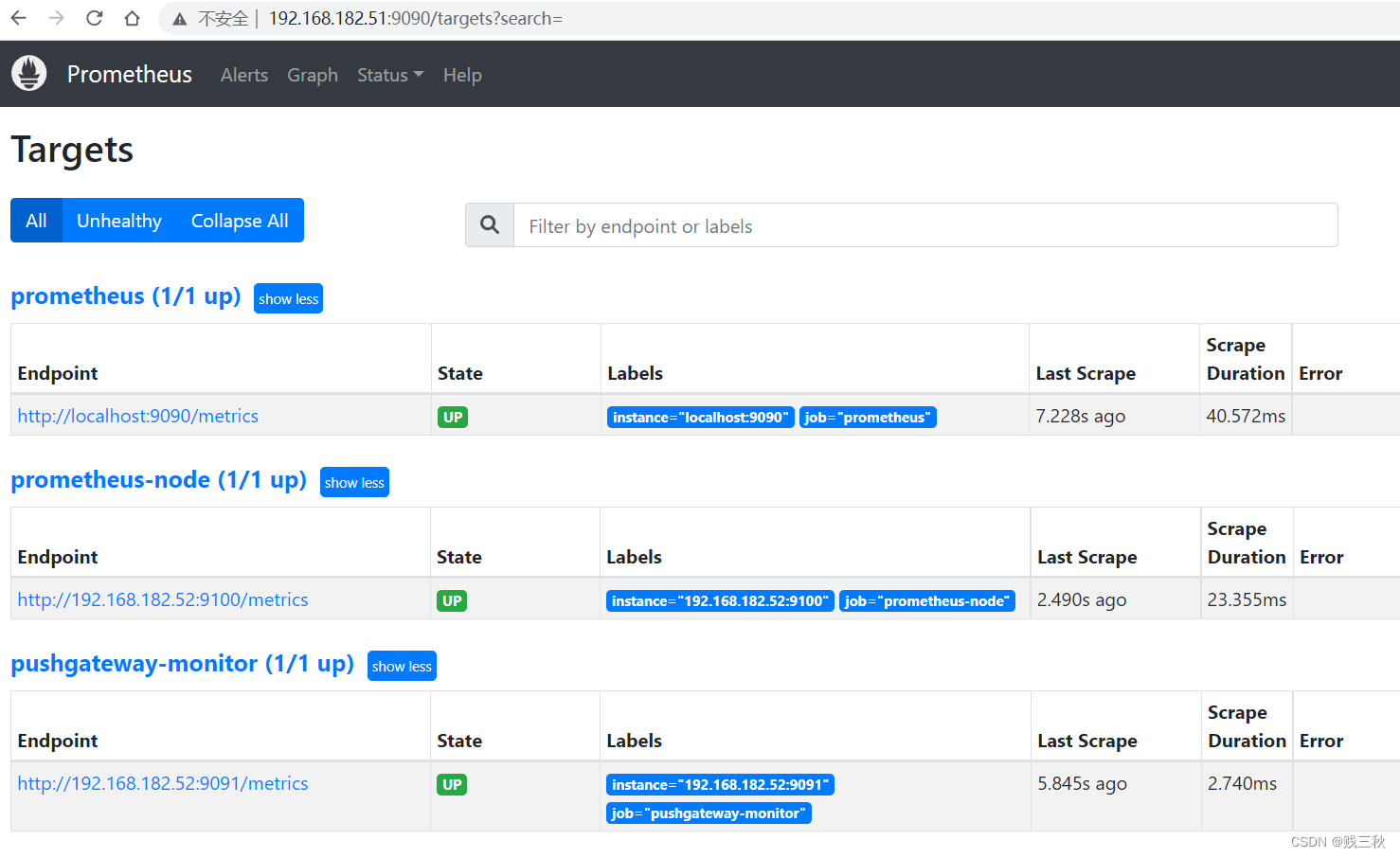
5、Prometheus配置采集pushgateway数据
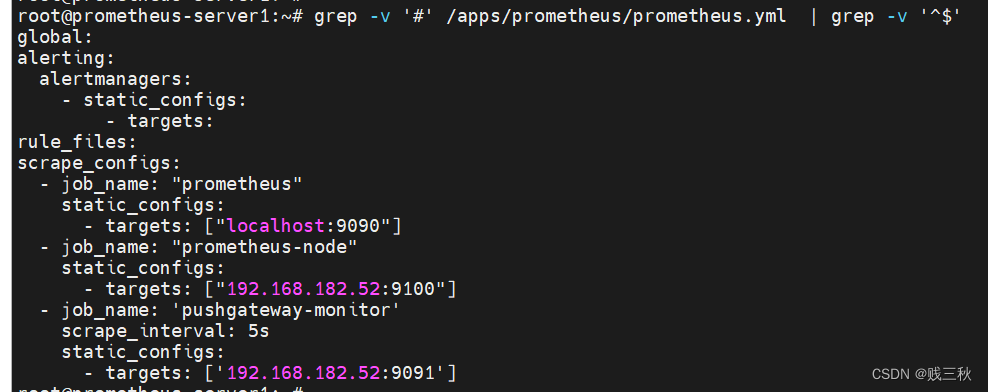
- 登录Prometheus服务器,修改配置文件
/apps/prometheus/prometheus.yml
- job_name: 'pushgateway-monitor'
scrape_interval: 5s
static_configs:
- targets: ['192.168.182.52:9091']
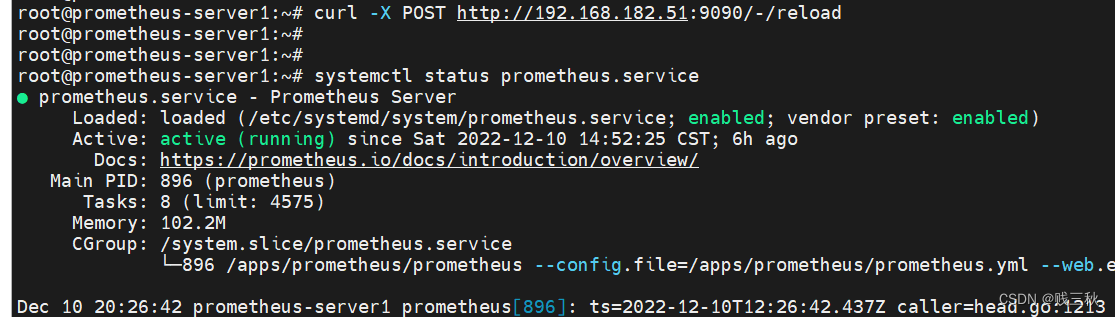
- 重启服务或者重新加载使配置生效
curl -X POST http://192.168.182.51:9090/-/reload
不用重启服务使配置生效
- 通过脚本推送数据
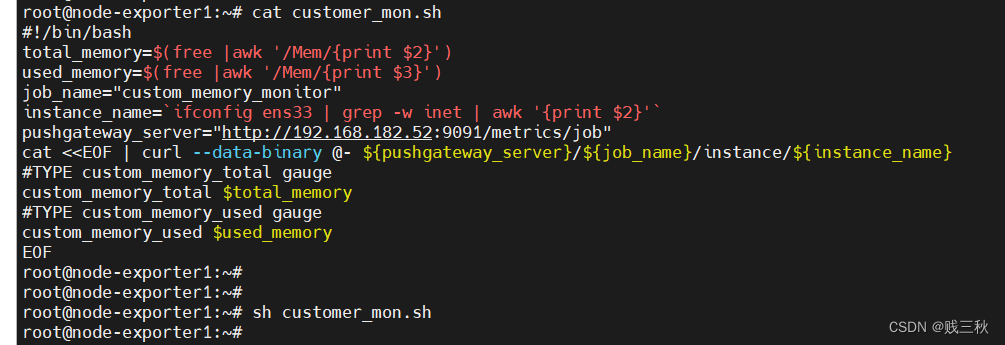
#!/bin/bash
total_memory=$(free |awk '/Mem/{print $2}')
used_memory=$(free |awk '/Mem/{print $3}')
job_name="custom_memory_monitor"
# 测试机器网卡是ens33
instance_name=`ifconfig ens33 | grep -w inet | awk '{print $2}'`
pushgateway_server="http://192.168.182.52:9091/metrics/job"
cat <<EOF | curl --data-binary @- ${pushgateway_server}/${job_name}/instance/${instance_name}
#TYPE custom_memory_total gauge
custom_memory_total $total_memory
#TYPE custom_memory_used gauge
custom_memory_used $used_memory
EOF

三、联邦集群
1、环境搭建
- 集群部署,通过Prometheus的master节点收集其他Prometheus服务器的数据
- Prometheus服务器的数据可以互相抓取,如果作为联邦的master,只需要在配置文件增加其他Prometheus的server配置即可
联邦master配置,这里使用59节点作为联邦master,51作为联邦node节点,安装Prometheus服务器参考之前的文档,安装即可,本机测试直接将51的虚拟机克隆了
vim /apps/prometheus/prometheus.yml
- job_name: 'prometheus-federate-51'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.182.51:9090'
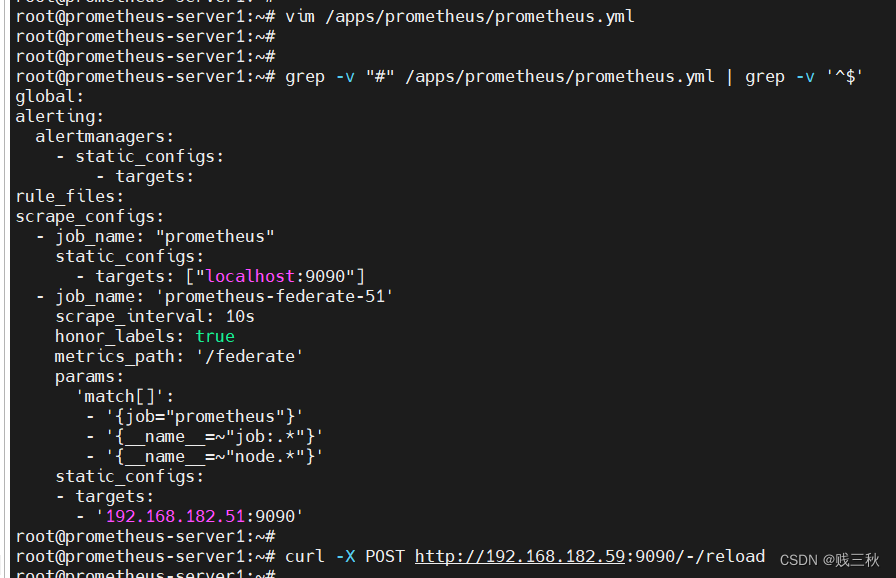
通过reload接口,使配置热加载
curl -X POST http://192.168.182.59:9090/-/reload
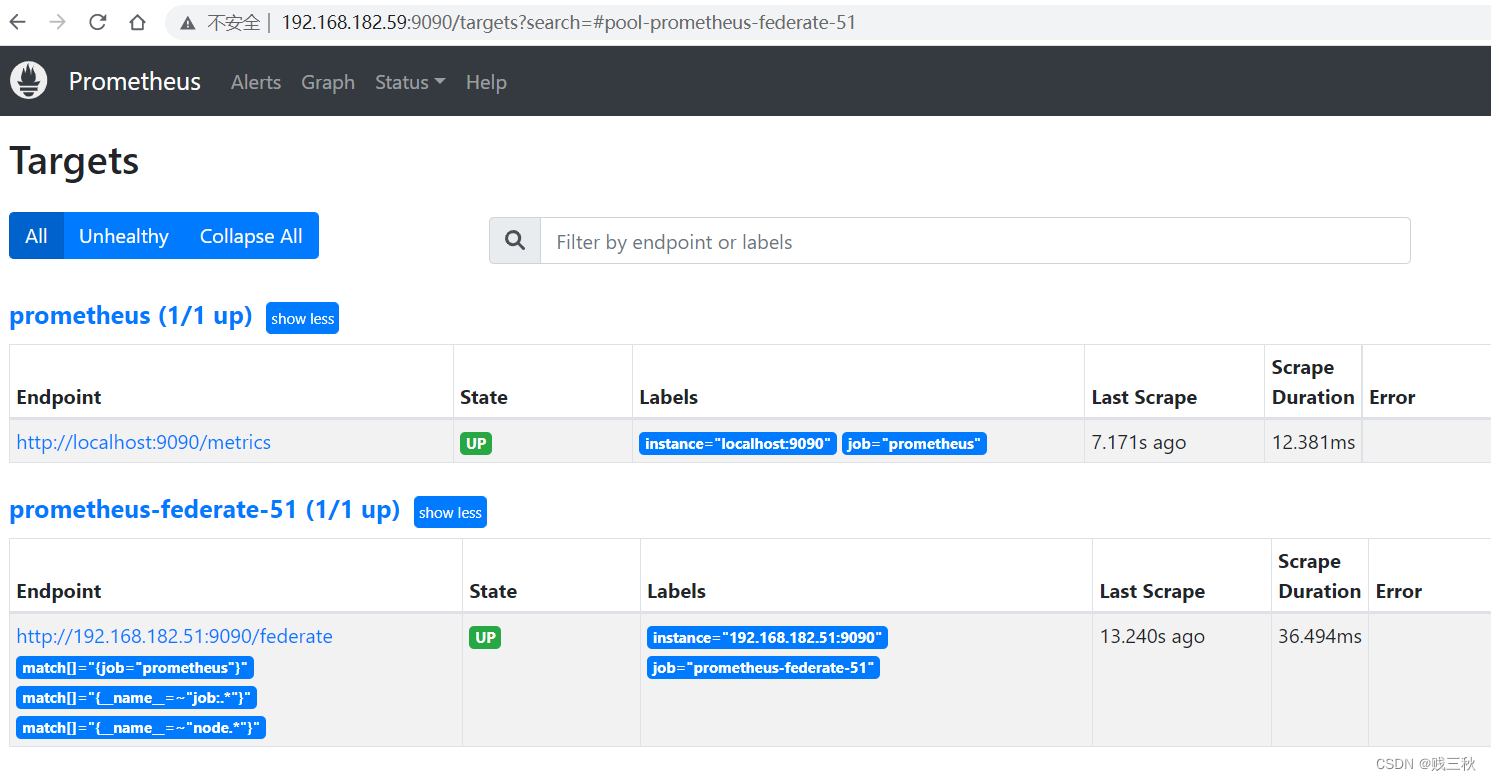
2、结果验证
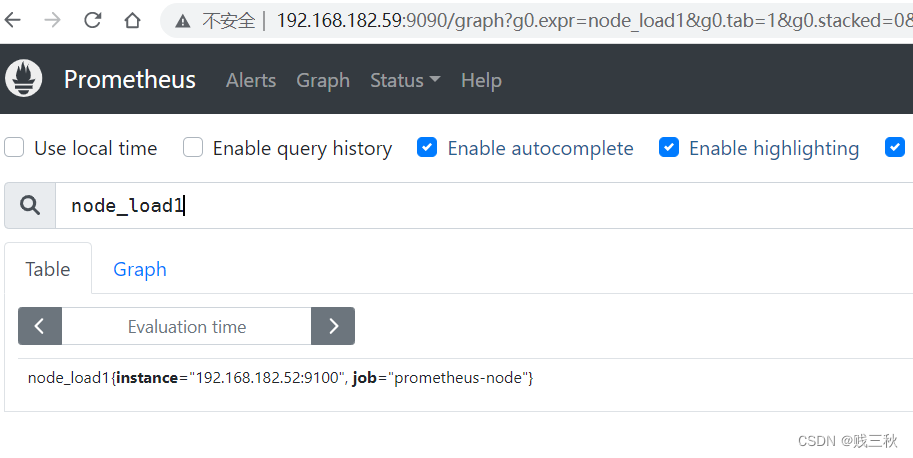
59联邦master节点没有配置52节点node,但通过联邦node(51)获取到了其数据
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









