







目录
1.准备工作
1.1 启动pycharm
打开Terminal,输入
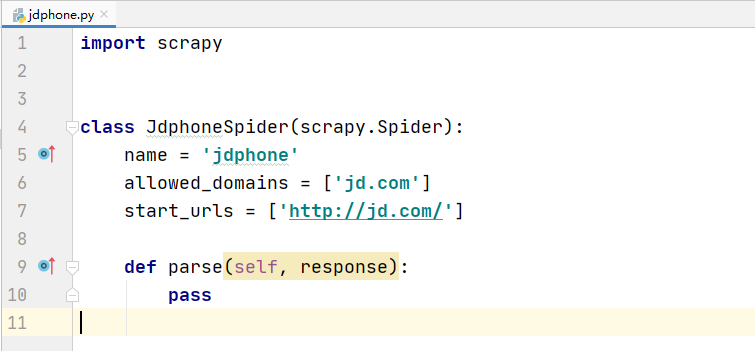
scrapy startproject jdcrawler可以看到scrapy自动为我们生成了项目地址

我们进入到jdcrawler的目录下,接着输入
scrapy genspider jdphone jd.com
可以看到我们已经在 spider 目录下创建了一个名为 jdphone 的爬虫,并且设置了这个爬虫的名称是 jdphone ,允许爬取的目录是 jd.com ,并且设置了一个默认的开始url
1.2 setting.py 配置
首先要设置UA头,直接把注释取消后,到京东的网站上刷新后在network随便一个资源里就可以看到

我也不知道为啥要改这个

我这里将LOG_LEVEL设置为了WARING,这就意味着除了waring以上等级的讯息都不会打印在控制台里,如果你想看到具体scrapy的运行流程,可以不需要添加这一条
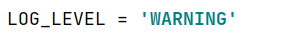
这边是设置了 scrapy 的爬虫中间件,这个中间件位于浏览器返回来的 response 之后和爬虫的页面处理函数之前(具体的 scrapy 框架的运行流程可以去网上查看,这边就不重复了),其实这边我本来是想着可能京东的页面是js动态渲染的,在中间件这里设置一个 selenium 来获取直接请求获取不到的内容,结果发现京东并没有js动态渲染,,所以这里可设可不设。不过我后面会讲如果当前要爬取的页面是动态渲染的该如何去添加 selenium

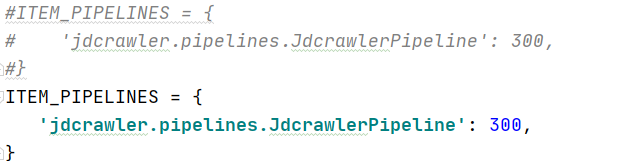
这边是设置了 scrapy 的 piplines 功能是否打开,这个 piplines 的作用是可以将提取的item保存到不同的储存器中去,包括mongodb ,mysql ,redis等,我这边选用的是mongodb来储存数据,后续的具体代码在
piplines.py 中书写
1.3爬取页面分析
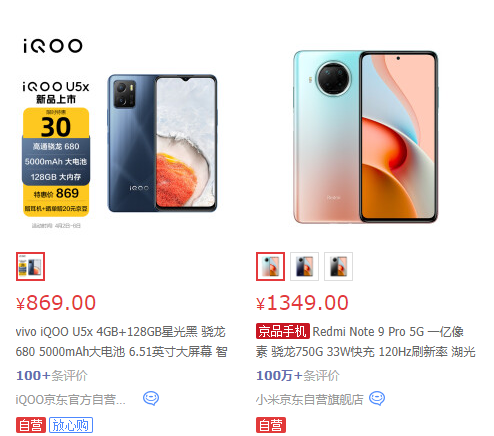
我们来到京东页面在搜索框输入手机,可以看到手机的商品页面都是分块的,初始页面上只有简单的名字,图片,价格等信息,所以我们需要进入到具体的商品页面:也就是点击商品名后进入的页面,来获取到我们想要的信息
进入到商品页面后我们可以看到具体的商品信息,那我们的主要目标就确认下来了

接下来我们要思考爬取下一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3602
3602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











