







提示:文章写于20220803,持续更新中,可以去专栏查看最新版本哦,如有不解或错误,请务必批评指正!
前言
在工作中不论是不是it行业,总会遇到采集数据的工作,近期有一个“朋友”需要七麦的app应用数据,而我打开浏览器,“撇”了一眼链接,打开f12,看了一眼get请求,30秒后,想也没想就答应了,并且1小时搞定。。。后来。。就没有后来了。。。
ps:如果没有耐心去研究的话,真的不如手工点。
简介:
1、请求参数加密解析过程,附带源码
2、代理使用方案进化过程
一、请求分析
1、因为数据源来自XHR异步请求,所以这边不需要bs4去解析html,直接上图:

----- 这里我们发现每个请求都有个analysis,刚开始以为是base64加密,结果解密一看好像还有点东西
2、刚开始也是和大家一样能站在巨人的肩膀上,于是就去搜了一下大神们的解析,结果还真有,于是就直接按照大神们的写法直接抄上去了,结果发现好像没有成功,心情再次低落。。。不过还是要做的嘛。于是乎,我们开始了不情愿的解析现在七麦更新后的加密算法:
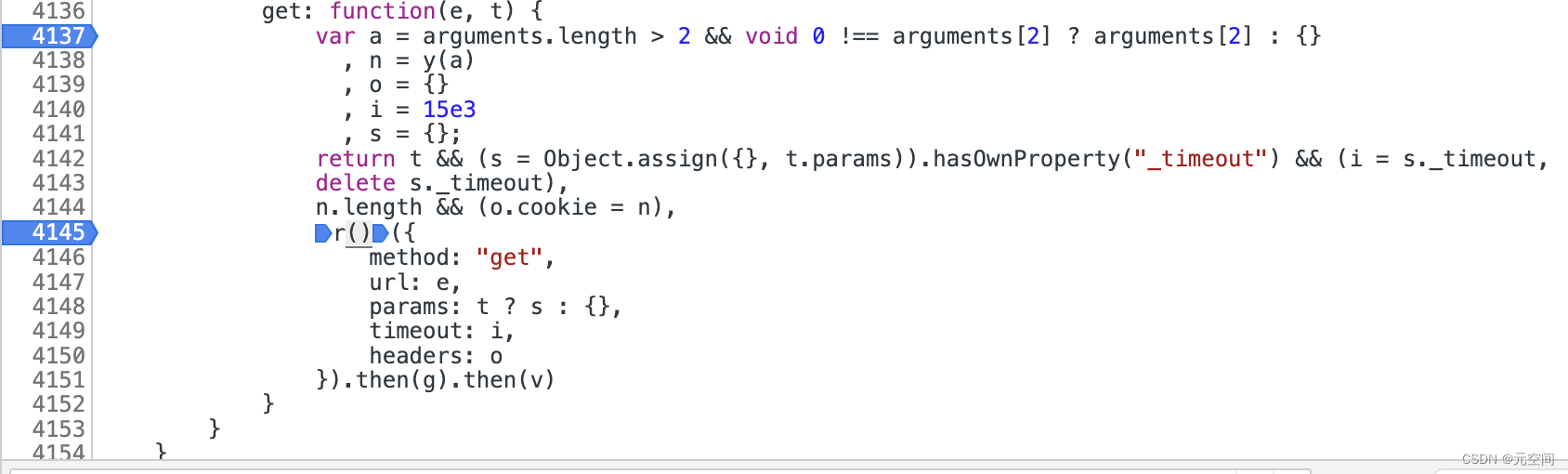
首先开搜,发现这个请求的位置(注意有两个matches,我是搜安卓的请求上面的那个是苹果的),于是乎打断点跟进(压缩后的js确实很看的很难受,但是我好像发现一个办法找到方法的位置)
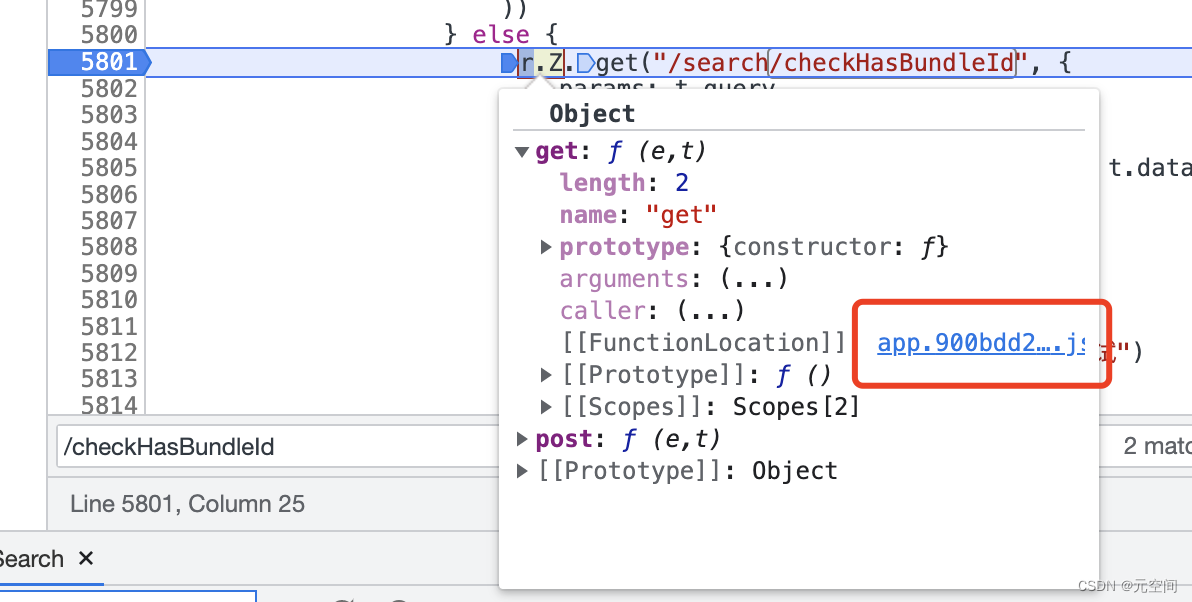
虽然穿了马甲,但是还是可以找到你,嗨害嗨~
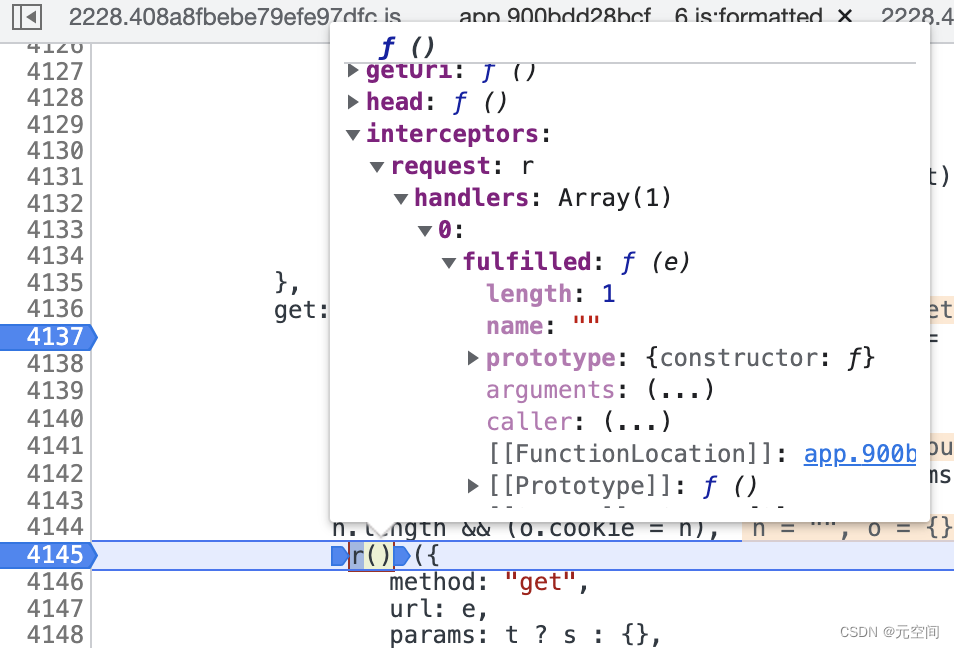
这个地方对于后端出生的我找起来有点困难,应该是r()返回一个方法,直接看r是看不到里面的,这里需要看r()整体,发现返回的请求工具类中有一个拦截器(intercepter),对于request请求有个handler处理器,处理器对当前请求做了一个填充(fulfilled),所以这里需要进入填充的代码逻辑,我们继续:
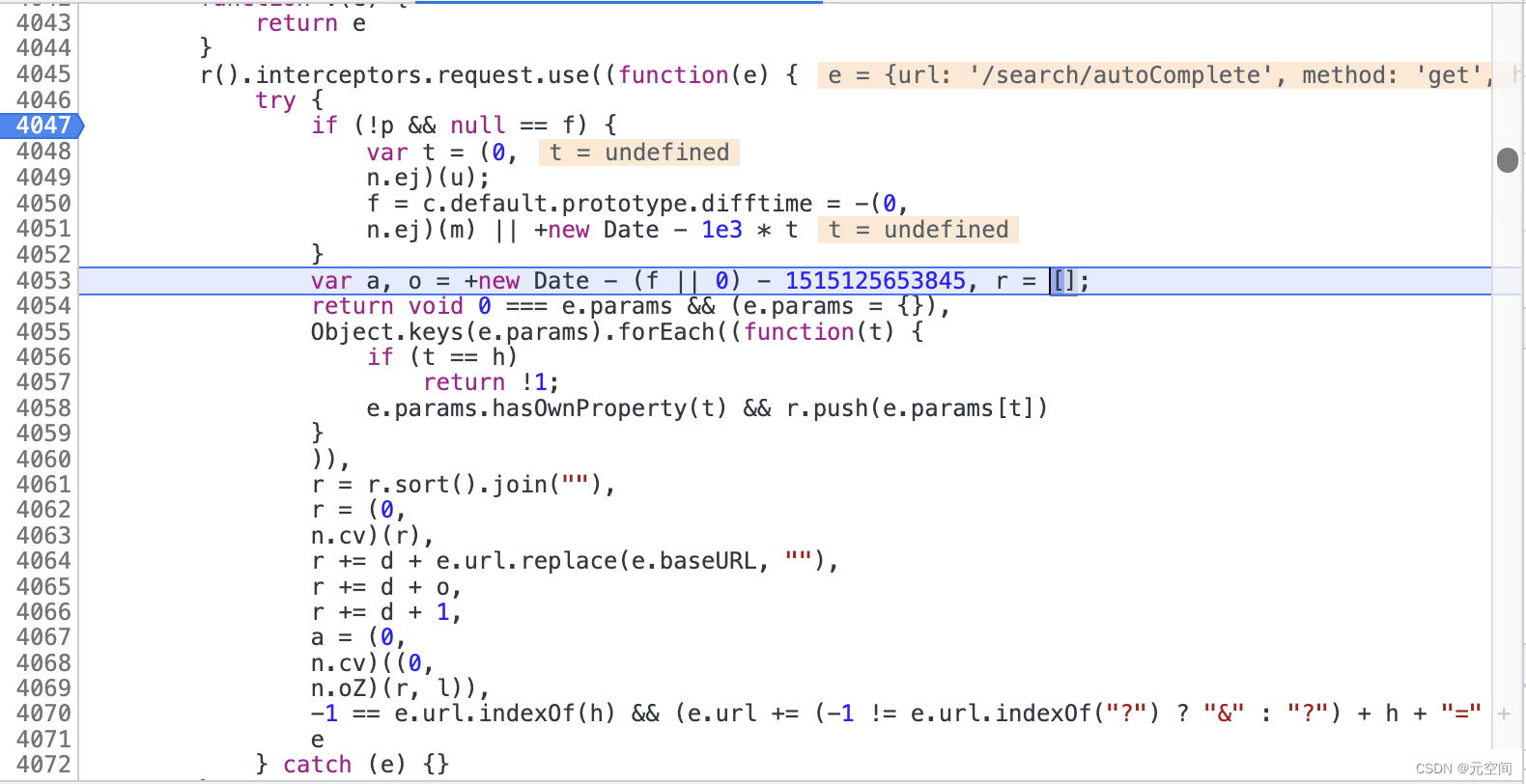
这里就是填充的全部逻辑了,看起来不知道干了啥,但是通过debug看每一步的结果就能够看清楚了,这里对当前请求做出了如下处理:
1、首先获取一个时间戳,o变量,这里f变量经过测试没有什么太大的用,设置为0就可以
2、接下来4055行到4061行做了两件事,将入参放入到r数组中,并对r的参数进行排序后转为字符串。
3、注意这里,n.cv进去发现就是base64加密,可以通过前面的方式进入到源码,通过base64解密一下这里的加密串看看是不是base64加密,到4063行时,参数字符串已经被加密完成了
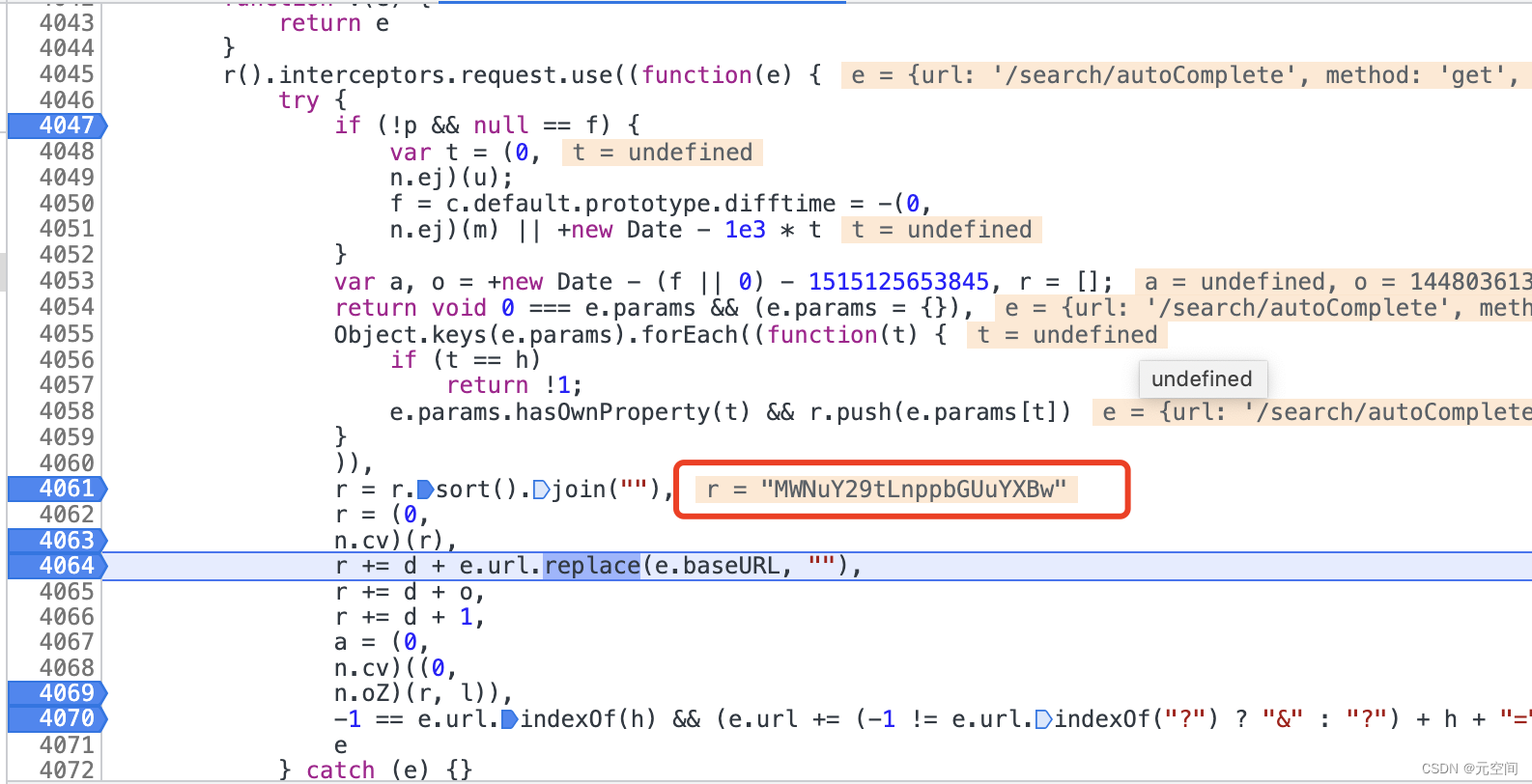
4、接下来发现d=’@#‘,所以到4066行之后:
r = base64(参数字符串) + ’@#‘ + url(去掉baseURL) + ’@#‘ + 时间戳 + ’@#‘ + 1 ,如图:
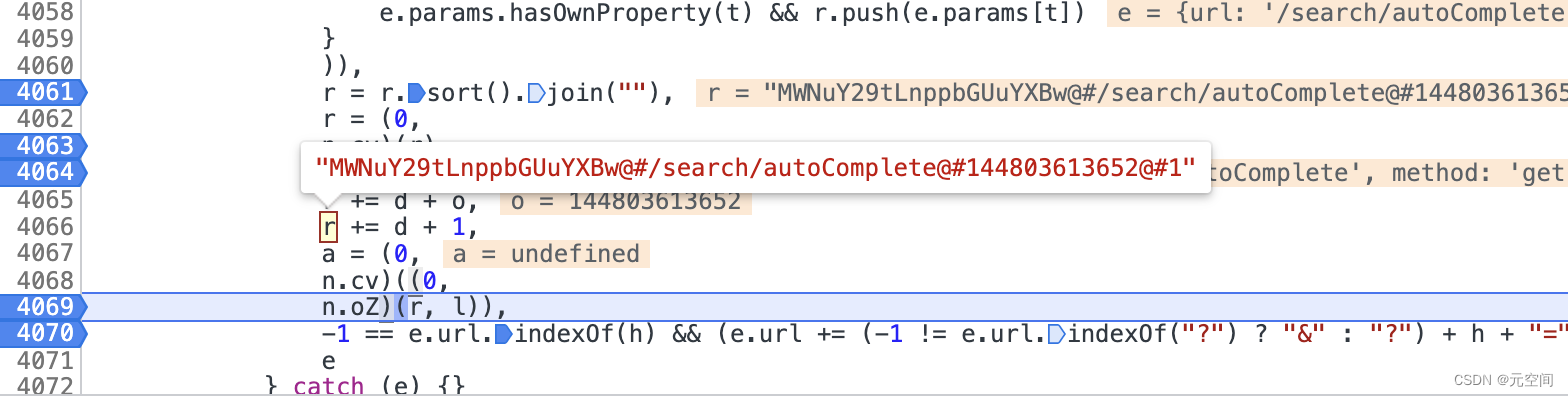
5、n.oZ这里其实就是加密算法了:
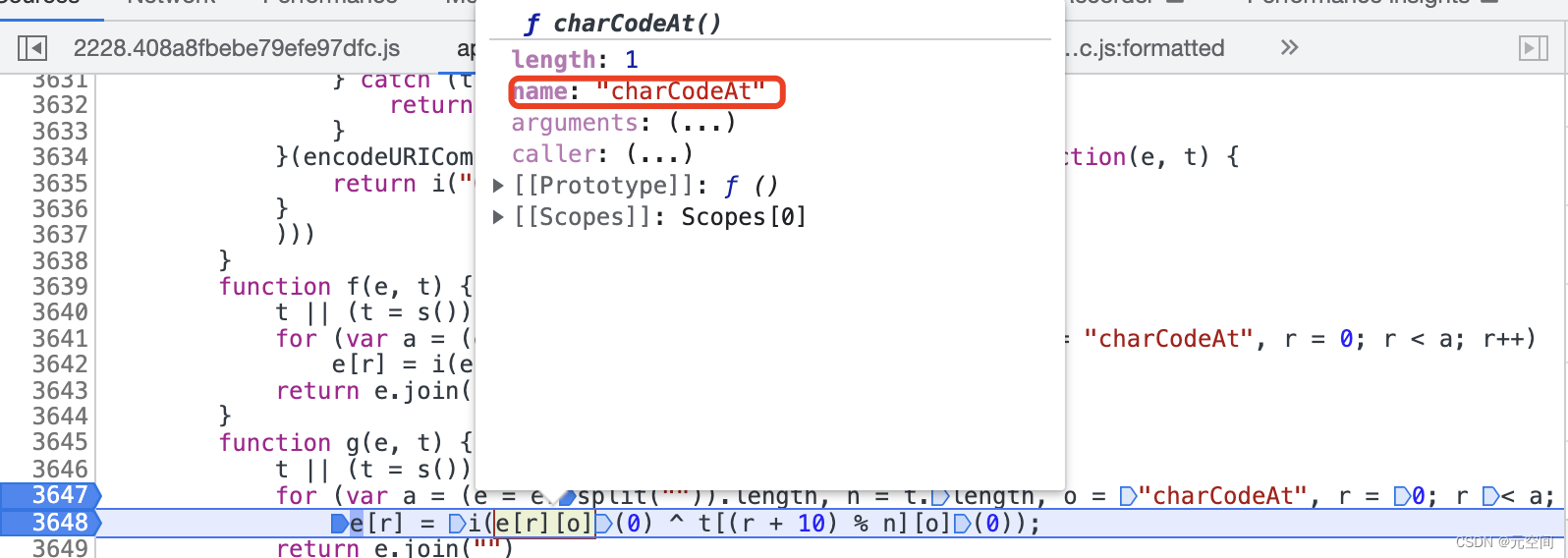
其实就是将r字符串中的每一位做了charcode转换后,又做了简单的偏移和异或计算计算重新赋值回r,小伙伴自己debug的话是可以看懂的。
6、执行后回到上一个堆栈
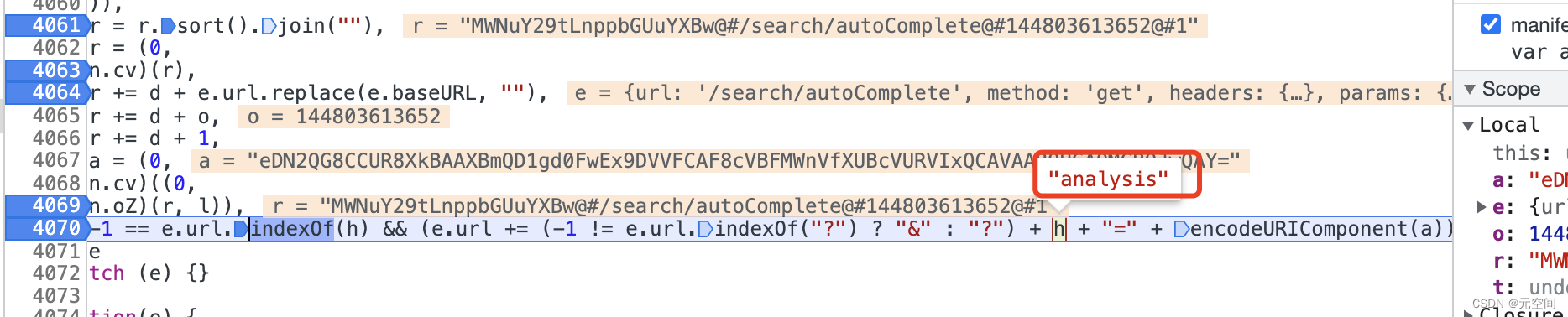
终于在这找到了主角analysis!后面对结果a做了urlencode操作,a就是r字符串被n.oZ后,再base64的结果:

到这里请求的分析就结束了,总结一下:
analysis = uriEncode(base64(n.oZ(base64(参数字符串) + ’@#‘ + url(去掉baseURL) + ’@#‘ + 时间戳 + ’@#‘ + 1)))
其中n.oZ函数为自定义的加密算法,可以手动实现,不算麻烦
到这里已经可以看到请求成功了,不再参数异常了

二、代理方式
1.代理原因:
经过了请求分析后我也以为就直接开爬,结果10次请求没到,就gg了,请求接口返回code:10605,msg大家自行查看
2.解决方案
首先代理分三个等级:
透明、普代、高代
1、透明:服务器知道你用的代理,并且知道你的公网ip,所以你还敢用吗?
2、普代:服务器知道你用的代理,但是不知道你的公网ip,应该勉强能用
3、高代:服务器不知道你用的代理,所以怎么知道当前ip是不是你的公网呢?
这里通过请求提供免费代理ip的网址(自己搜:快代理之类的),能找到很多ip,但是质量都很差,所以呢,这里需要你自己去实现一个生产者消费者的数据结构,其实也不难,一劳永逸嘛
3、方案实现
实现方案很简单,通过一个编译单元(java里的文件叫法,python不知道是不是),纳管一个dq双端队列对象,这里dq对象在多线程的情况下能够帮你解决线程同步的问题,不用再去自行加锁了。
再给两个文件,一个文件专门用来做七麦请求的,一个文件专门做代理ip的。
七麦请求文件:这个文件可以是任何网站的请求,这里不限制,请求时使用dq中的ip作为代理,如果代理ip请求失败则从dq中删除这个代理。
代理ip文件:这个文件就是开启多线程对你收集来的所有代理ip的网站进行爬取ip+端口,然后通过httpbin进行检查是否能用,如果能用就往dq里面插入这个ip供请求端使用
4、代码实现
获取代理网中的ip
for i in range(1, 4705):
try:
req = requests.get("代理ip提供网址", timeout=5)
html = req.text
req.encoding = "utf-8"
soup = BeautifulSoup(html, features="html.parser")
iplist = soup.select('.hot-product-content tbody tr')
for tag in iplist:
try:
if availableIP != "":
return
ipport = tag.findAll('td')[0].text + ":" + tag.findAll('td')[1].text
print(ipport)
proxies["https"] = ipport
rsp = requests.get(testProxyUrlHTTPS, proxies=proxies, timeout=5)
print("wa!!!!!!!,找到一个!:", json.loads(rsp.text))
GlobalPost.append(ipport)
print("#####当前ip可用列表:############3")
GlobalPost.printList()
print("###############################3")
# print(tag.findAll('td')[1].text)
except:
print("不可用ip:", ipport + " ", end="")
continue
except:
continue
finally:
if i == 20:
i = 1
纳管一个双端队列
# 全局变量,作为邮差
import collections
# dq队列作为变量传递
def initDq():
global dq
dq = collections.deque()
def pop():
return dq.pop()
def append(a):
try:
dq.index(a)
except:
dq.append(a)
def size():
return dq.__len__()
def get(index):
return dq.__getitem__(index)
def remove(e):
try:
dq.remove(e)
except:
return
def printList():
for i in dq:
print(i)
if __name__ == '__main__':
initDq()
append("123")
append("345")
printList()
写在最后
方案和代码仅提供学习和思考使用,切勿随意滥用!如有错误和不合理的地方,务必批评指正~
如果需要git源码可咨询2260755767@qq.com或在评论区回复即可.















 2787
2787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











