







一、概述
MCDF的主要功能是将输入端的三个通道数据,通过数据整形和过滤,最终输出。
可以将MCDF的设计结构分别四个模块:
- 上行数据的通道从端(channel slave)
- 仲裁器(arbiter)
- 整形器(formatter)
- 控制寄存器(control registers)
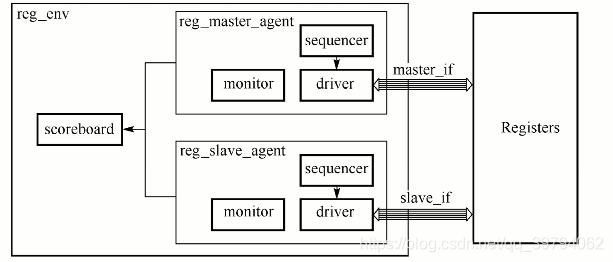
二、reg_env
对于寄存器模块的验证环境reg_env,它的组织包括:
reg_master_agent,提供寄存器接口驱动信号。reg_slave_agent,提供寄存器接口反馈信号。scoreboard,分别从reg_master_agent内的monitor和reg_slave_agent内的monitor获取监测数据,并且进行数据对比。
三、chnl_env
数据通道从端的验证环境chnl_env的组件包括:
chnl_master_agent,提供上行的激励数据。chnl_slave_agent,提供用来模拟arbiter仲裁信号,并且接受流出数据。reg_cfg_agent,用来提供模拟寄存器的配置信号,并且接收内置FIFO的余量信号。scoreboard,分别从chnl_master_agent、chnl_slave_agent、reg_cfg_agent的monitor接收检测数据,并且对channel的流入流出数据进行比对。

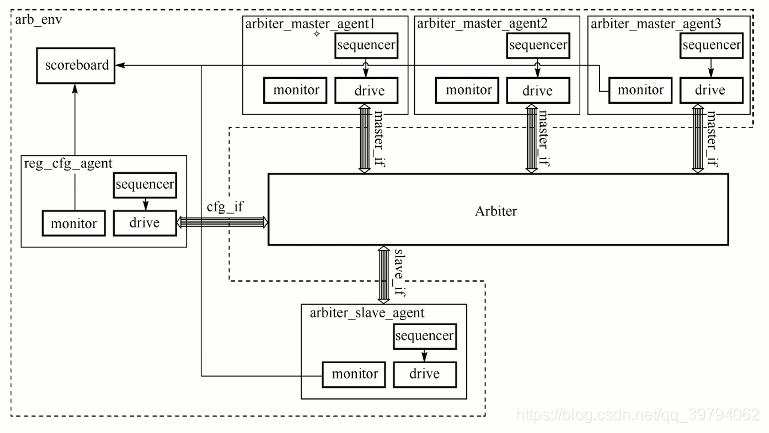
四、arb_env
仲裁器的验证环境arb_env的组件包括:
- 模拟channel输出接口的arbiter_master_agent的三个实例,用来对arbiter提供并行数据输入,同时对arbiter反馈的仲裁信号做出响应。
- arbiter_slave_agent,用来接收arbiter的输出数据,模拟formatter的行为,对arbiter的输出信号做出响应。
- reg_cfg_agent,提供用来模拟寄存器的配置信号,对三个channel数据源分别做出不同的优先级配置。
- scoreboard,从三个arbiter_master_agent、arbiter_slave_agent、reg_cfg_agent中的monitor获取监测数据,对arbiter的仲裁机制做出预测,并且将输入输出数据按照预测的优先级做出比对。
五、fmt_env
整形器的验证环境fmt_env的组件包括:
- fmt_master_agent,用来模拟arbiter的输出数据。
- fmt_slave_agent,用来模拟MCDF的下行数据接收端。
- reg_cfg_agent,用来模拟寄存器的配置信号,用来指定输出数据包的长度。
- scoreboard,从fmt_master_agent、fmt_slave_agent、reg_cfg_agent的monitor获取检测数据,通过数据包长度来预测输出的数据包,与formatter输出的数据包进行比对。

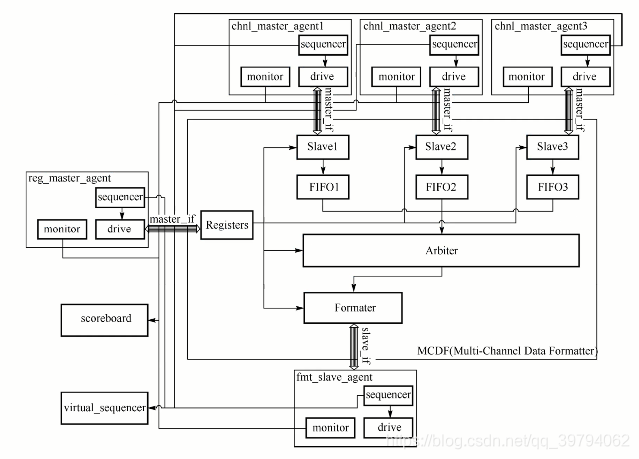
六、环境集成方案一
MCDF顶层验证环境复用了这些模块验证环境的组件,reg_master_agent、chnl_master_agent、fmt_slave_agent,通过这三个激励组件可以有效生成新的激励序列,而将各个agent的sequencer句柄合并在一起时,virtual sequencer的作用就体现出来了,可以通过这个中心化的序列分发管道,将各个agent的sequencer也集中管理。MCDF的scoreboard提供了一个完整的数据通路覆盖方案,即从各个agent的monitor的数据检测端口将数据收集起来,同时建立MCDF的参考模型,预测输出数据包,最终进行数据比对。
验证环境结构图
代码实现
class mcdf_env1 extends uvm_env;
`uvm_component_utils(mcdf_env1)
reg_master_agent reg_mst;
chnl_master_agent chnl_mst1;
chnl_master_agent chnl_mst2;
chnl_master_agent chnl_mst3;
fmt_slave_agent fmt_slv;
mcdf_virtual_sequencer virt_sqr;
mcdf_scoreboard sb;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
reg_mst = reg_master_agent::type_id::create("reg_mst", this);
chnl_mst1 = chnl_master_agent::type_id::create("chnl_mst1", this);
chnl_mst2 = chnl_master_agent::type_id::create("chnl_mst2", this);
chnl_mst3 = chnl_master_agent::type_id::create("chnl_mst3", this);
fmt_slv = fmt_slave_agent::type_id::create("fmt_slv", this);
virt_sqr = mcdf_virtual_sequencer::type_id::create("virt_sqr", this);
sb = mcdf_scoreboard::type_id::create("sb", this);
endfunction
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
//virtual sequencer connect
virt_sqr.reg_sqr = reg_mst.sequencer;
virt_sqr.chnl_sqr1 = chnl_mst1.sequencer;
virt_sqr.chnl_sqr2 = chnl_mst2.sequencer;
virt_sqr.chnl_sqr3 = chnl_mst3.sequencer;
virt_sqr.fmt_sqr = fmt_slv.sequencer;
//monitor transactions to scoreboard
reg_mst.monitor.ap.connect(sb.reg_export);
chnl_mst1.monitor.ap.connect(sb.chnl1_export);
chnl_mst2.monitor.ap.connect(sb.chnl2_export);
chnl_mst3.monitor.ap.connect(sb.chnl3_export);
fmt_slv.monitor.ap.connect(sb.fmt_export);
endfunction
endclass
七、环境集成方案二
在方案一中最大的额外投入在于需要新建一个scoreboard用来检查MCDF的整体功能,而方案二的目的在于复用底层模块环境的scoreboard,减少顶层环境的额外成本,顶层环境的组件都直接复用了各个模块验证环境,顶层环境在集成模块验证环境时,需要将各个子模块中的agent配置为不同模式(active或者passive),以此适应顶层场景,所以不需要实现新的scoreboard,而是可以复用原有模块验证环境的scoreboard。
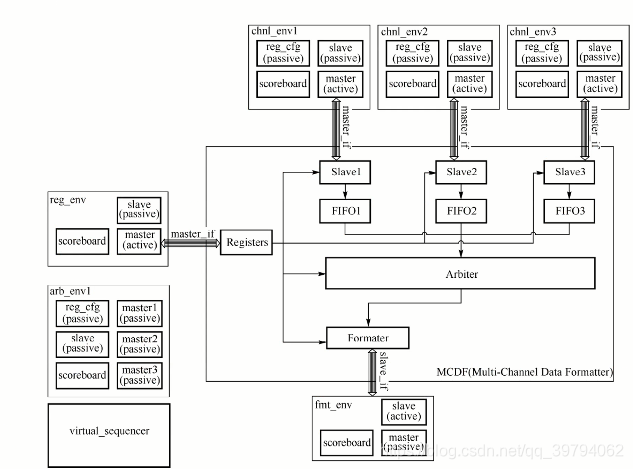
方案一和方案二相同的地方在于,顶层都需要新建virtual sequencer和sequence,用来生成顶层的测试序列。而virtual sequencer也不是从零创建的,它本身也是利用原有模块环境的序列库,进行了有机的组合,最后协调生成了新的测试序列。从方案二可以看出,mcdf_env的子组件不再是uvm_agent类,而是各个模块的验证环境uvm_env类。通过直接复用这些子环境,也间接复用了它们内部的scoreboard,在build阶段,需要将各个子环境中不需要再产生激励的agent,配置为passive模式,而默认情况下这些agent均为active模式。这种复用方式使得我们无需再新建一个MCDF scoreboard,只需要确保MCDF的各个子模块都有scoreboard会检查功能,这样从整体上便可以覆盖完整的数据通路。
代码实现
class mcdf_env1 extends uvm_env;
`uvm_component_utils(mcdf_env1)
reg_env reg_e;
chnl_env chnl_e1;
chnl_env chnl_e2;
chnl_env chnl_e3;
fmt_env fmt_e;
arb_env arb_e;
mcdf_virtual_sequencer virt_sqr;
function void build_phase(uvm_phase phase);
super.build_phase(phase);
//将子环境配置为active或者passive模式
uvm_config_db#(int)::set(this, "reg_e.slave", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e1.slave", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e1.reg_cfg", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e2.slave", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e2.reg_cfg", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e3.slave", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "chnl_e3.reg_cfg", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "arb_e.master1", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "arb_e.master2", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "arb_e.master3", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "arb_e.slave", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "arb_e.reg_cfg", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "fmt_e.master", "is_active", UVM_PASSIVE);
uvm_config_db#(int)::set(this, "fmt_e.reg_cfg", "is_active", UVM_PASSIVE);
//创建子环境
reg_e = reg_env::type_id::create("reg_e", this);
chnl_e1 = chnl_env::type_id::create("chnl_e1", this);
chnl_e2 = chnl_env::type_id::create("chnl_e2", this);
chnl_e3 = chnl_env::type_id::create("chnl_e3", this);
virt_sqr = mcdf_virtual_sequencer::type_id::create("virt_sqr", this);
endfunction
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
//virtual sequencer connection
virt_sqr.reg_sqr = reg_e.master.sequencer;
virt_sqr.chnl_sqr1 = chnl_e1.master.sequencer;
virt_sqr.chnl_sqr2 = chnl_e2.master.sequencer;
virt_sqr.chnl_sqr3 = chnl_e3.master.sequencer;
virt_sqr.fmt_sqr = fmt_e.slave.sequencer;
endfunction
endclass
八、总结
从上面框图和代码中可以看出,UVM带来的环境复用,相比于之前SV验证环境具备了以下几个优势:
- 各个模块的验证环境是独立封装的,对外不需要保留数据端口,因此便于环境的进一步集成复用。
- 由于UVM自身的phase机制,在顶层协调各个子环境时,无需考虑由于子环境之间的例化顺序而导致的对象句柄引用悬空的问题。
- 由于子环境的测试序列是相对独立的,这使得顶层在复用子环境测试序列而构成
virtual sequence时,不需要其它额外的迁移成本。 - UVM提供的
config_db配置方式,使得整体环境的结构和运行模式都可以从树状的config对象中获取,这也使得顶层环境可以在不同uvm_test进行集中管理配置。














 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









