










扒一扒HashMap和ConcurrentHashMap的本质
Java集合,或者说Java容器,可以分为两大派系,一类是实现了Collection接口的容器,另一类是实现了Map接口的容器。这篇文章要将的就是实现了Map接口的HashMap集合。
先来看一下Map接口整体的框架

-
HashMap
HashMap集合是线程不安全的,在JDK 8 之前HashMap是由数组+链表组成的,数组是HashMap的主体部分,链表则是主要为了解决hash冲突而存在的,主要是采用拉链法解决冲突。到了JDK 8及以后,HashMap由数组+链表+红黑树组成,红黑树的出现主要是优化了hash冲突的解决方案,当链表长度大于等于8,并且数组的长度大于等于64的时候,就会将链表转为红黑树,来优化搜索时间。
-
Hashtable
相当于线程安全的HashMap,Hashtable之所以说是线程安全的,是因为Hashtable中的方法全部都加了Synchronized同步关键字,保证了多线程的情况下是并发安全的,但是这样也就导致了性能低下,并发程度低。Hashtable是由数组+链表组成的,数组是 Hashtable的主体,链表则是主要为了解决哈希冲突而存在的。
-
TreeMap
TreeMap还实现了SortedMap子接口,使得TreeMap具备了排序的能力,底层排序的实现是红黑树
-
LinkedHashMap
是HashMap的子类,它的底层仍然是基于拉链式散列结构即由数组+链表+红黑树组成,在此基础上还增加了一条双向链表,可以保持键值对的插入顺序,同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
我们平常使用最多的应该是HashMap,讲下来主要讲一讲JDK 8的HashMap集合
首先我们要明确HashMap是双列集合,是以key-value键值对的形式来存储数据的,可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。就这一点HashTable是不允许有 null 键和 null 值。
HashMap内部类Node用来封装K-V键值对。每一个节点都会保存自身的hash值、key、value、以及下一个节点的。多个节点就可以构成链表结构。

HashMap中还维护了一个table成员变量,它是一个Node类型的数组
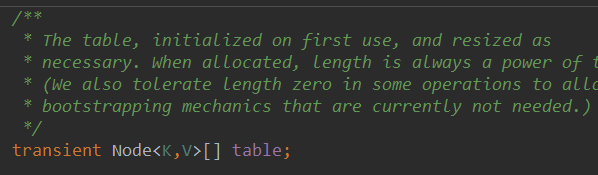
所以也就形成了数组+链表的基本形式,当链表过长会进行树化
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XdegSUL2-1630893464999)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905114852457.png)]](https://img-blog.csdnimg.cn/9bed8c1b63974cf593ca8cccc5577383.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_19,color_FFFFFF,t_70,g_se,x_16)
我们使用HashMap集合最基本的操作无非就是put添加元素和get获取元素,接下来说一下HashMap添加元素的方式它的扩容机制
在向HashMap集合中添加元素时,put()方法首先会调用hash(),根据当前key计算出hash值,来确定table数组中的索引位置

注意!hash值并不等价于hashcode值,hash()函数会利用当前key的hashcode值来计算出hash值并返回,从这里我们也可以看出HashMap是允许key值为null的,如果为null值,hash值就会直接返回0,否则就会计算hash值

在展开将hash()函数之前,我们先来说一下hashCode()与equals(),以及==与equals的区别
hashCode()与equals()
我们如果判断两个对象?主要就是通过这两个函数来判断的,这两个方法一起被重写,可以自己定义如何判断两个对象是否相同。如果两个对象相等,那么它们的hashcode值一定也是相同的,对这两个对象使用equals()会返回true。但是,两个对象如果hashcode值相同,并不代表这两个对象一定是相等的。hashcode()函数会对堆空间中的对象产生唯一的一个独特值,存放在对象头中的运行时元数据中,用来唯一标识一个对象。
==与equals的区别
对于基本类型来说,使用==就是比较的二者的值是否相等。
对于引用类型来说,使用==比较的是这两个引用是否指向同一个对象地址,也就是比较二者存放的地址值是否是一样的。
对来引用类型来说,使用如果equals()没有被重写,那么比较的就是它们的地址是否相等,如果equals()被重写,比如String类型,则比较的是地址里的内容。
下面展开来说一说hash()函数,hash值是将当前key的hashcode值的高16位和低16位进行异或操作计算出来的结果。hash()函数也称为干扰函数,相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。那么为什么要进行异或运算?直接使用hashcode值不行吗?
实际上这样做有两点:
- 尽可能降低hash碰撞,使得计算出hash值越分散越好
- 采用位运算,算法高效
这里并没有直接使用hashcode值来充当hash值,这是因为将hash值转为table数组索引的公式为index = hash & (n-1),就是把hash值和数组长度-1做了一个按位与的操作。而hashcode返回的值是一个int类型的整数,int类型的整数是32位,表示范围从-2147483648到2147483648,前前后后加起来差不多40亿的映射空间,如果使用这么大的值充当hash值,问题是一个40亿长度的数组,内存是放不下的,所以需要对数组长度进行取模运算,利用余数来确定数组的索引值。与n取模等价于和n-1相与!,在HashMap的先高16位异或低16位计算出hash值以后,再取模运算,取模运算转化成位运算公式a%(2^n) 等价于 a&(2^n-1),而&操作比%操作具有更高的效率!同时这也正好解释了为什么HashMap的数组长度要取2的整数次幂,这是因为(数组长度-1)正好相当于一个低位掩码(高位为0,低位为1)。与操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eCbNAHli-1630893465003)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905141332613.png)]](https://img-blog.csdnimg.cn/d22aba086e104ce08239fa91b6c40fab.png)
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。此时干扰函数的作用就体现出来了,将当前key的hashcode值无符号右移,让高16位和低16位进行异或操作,目的就是为了混合hashcode的高位和低位,以此来加大低位的随机性。

在计算出数组索引值之后,会调用putVal()方法,向数组中添加元素

第一次向HashMap中添加元素时,table为null,会调用resize()进行扩容

默认初始化容量为16,阈值是默认的加载因子(0.75) * 默认初始化容量 = 12
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FVptPmLg-1630893669404)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905142740522.png)]](https://img-blog.csdnimg.cn/b280eec4825744638b049a1a7299c454.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)

加载因子
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
那什么默认值是0.75呢?这个默认值实际上是官方给出的一个比较合理的值,这个0.75是根据统计学和概率学中的泊松分布计算出来的。加载因子太大就会导致查找元素效率低,太小都会导致数组的利用率低,数组中存放的数据就会很分散。同时0.75会使得发生碰撞概率最小。
阈值
加载因子 * 容量 = 阈值,也就是说在HashMap还没有满了的时候,只要HashMap中元素个数达到了阈值就会触发扩容
根据默认的容量初始化值创建出一个newTab数组

扩容创建出新的数组之后,就会根据hash值计算出数组索引位置,如果数组中这个索引位置是空的,说明没有发生哈希冲突,就会直接把元素加入到数组中

如果根据hash值计算出的数组索引位置上已经存放过元素了,那么就发生了hash冲突。
首先判断发生冲突的两个节点的hash值是否相等,相等说明发生hash冲突,然后在判断这两个key是否是同一个对象,因为有可能不相同的两个对象计算出相同的hash值,或者按照重写的自定义的equals函数来判断这两个对象是否相同。如果发生冲突的这个两个key相同,就会发生覆盖,用新的value值替代原数据。


如果判断这两个key不相等,就会进一步判断当前节点类型是不是树形节点,如果是树形节点,就会创建一个树形节点插入红黑树中

如果不是树形节点,通过for循环,当前节点会和链表中的每一个节点进行比较,如果与其中任何一个节点的相同就会跳出循环,替换原来的value值。如果都不相同,就会创建一个节点挂载到链表的最后,条件新的节点之后还需要判断当前链表节点长度是否到达了8个,到达则需要树化成红黑树。


仅仅当前链表长度到达8还不行,还需要数组长度到达64,才会真正进行转成红黑树,否则会进行扩容,增加数组的长度

成功加入元素之后,会判断HashMap集合中元素个数是否超过了阈值,超过阈值就会再次触发扩容机制
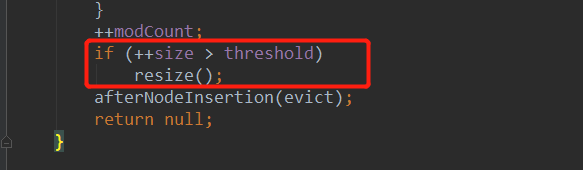
容量变成原来的2倍,阈值也变成原来的2倍。如果说扩容超过最大值就不再扩容了,还是使用原来的容量大小,并把阈值设置为Integer最大值

进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8TNZ7t3o-1630893465014)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905154902422.png)]](https://img-blog.csdnimg.cn/9f235db313fb44fc9a2597a9647a4384.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)
至此,向HashMap中添加元素和扩容的答题流程讲的差不多,总结一下就是:
在向HashMap中插入元素的时候,首先会根据元素的key计算hash值,然后转换成table数组中的索引index,由于数组长度是有限的,并且不同的对象不同的key很有可能计算出hash值是相同的,如果说数组中对应的index索引位置已经存放过元素了,此时就会比较这两个元素是否相同,相同则会覆盖,不同的话就会使用尾插法,加到这个Node节点的最后,也就形成了链表结构。如果链表长度大于等于8并且数组长度大于等于64就会将链表进行树化成红黑树。如果加入元素之后超过了阈值,机会触发扩容机制,容量变成原来的2倍,并将原来的元素重新hash散列分配。
之前我们说过HashMap是线程不安全的,平时我们一般大都是在多线程高并发的场景下操作,那么在多线程情况下使用HashMap就会导致一些线程安全问题。在JDK 8 之前HashMap多线程操作很有可能导致死循环,其主要原因在于HashMap在jdk1.7中采用头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题。到了JDK 8及以后,采用了尾插法,虽然解决了这个问题,但是多线程下使用 HashMap 还是会存在其他问题,比如数据丢失。那么我们如何保证在多线程下的安全问题?
-
使用Hashtable保证线程
Hashtable中的方法使用了Synchronized同步关键字,可以保证多线程下安全问题,但是效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,相当于把所有的操作给串行化。如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。基本已经弃用。
-
使用Collections工具类
Collections工具类中的synchronizedMap()方法,相当于给HashMap包装了一层同步方法,来进行同步控制,效率也是非常低。
-
使用 ConcurrentHashMap
它是JUC包下的并发集合,可以说是ConcurrentHashMap是为了专门解决HashMap并发问题而生的。也是最推荐使用的。
接下来主要讲一下ConcurrentHashMap这个并发集合
在JDK 7的时候,ConcurrentHashMap底层数据结构是分段的数组+链表,将整个数组进行分割分段(Segment),采用分段锁的思想,每一把锁只锁住容器中其中一部分数据,多线程访问容器里不同数据段的数据就不会存在锁竞争的问题,提高了并发访问效率。ConcurrnetHashMap由很多个 Segment 组合,每一个Segment都相当于HashMap中的table数组,或者说相当于一个HashMap结构,也就是说ConcurrnetHashMap结构相当于里面包含了多个HashMap结构。每一个HashEntity数组可以扩容,也就是说每一个HashMap可以进行扩容,但是Segment数组不可以扩容,一旦初始化就不能改变,默认Segment片段的个数为16个,相当于有16个HashMap结构。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JFErniM2-1630893829155)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905171514952.png)]](https://img-blog.csdnimg.cn/7e1b749cdf4346f38baccb9ae7c94433.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)
分段锁Segment继承了ReentrantLock,所以它是可重入锁,Segment数组中的每一个Segment相当于一个HashMap集合,在并发情况下,对于不同的Segment的数据进行操作是不同考虑锁竞争的。由于Segment类似于HashMap,所以默认加载因子也是0.75,默认的并发等级,即Segment数组的默认初始化容量也是16。理论上相当于允许16个线程并发执行。

Segment数组的大小ssize是由concurrentLevel来决定的,但是却不一定等于concurrentLevel,ssize一定是大于或等于concurrentLevel的最小的2的次幂。concurrentLevel最大值设置为65536。为什么Segment的数组大小一定是2的次幂?其实主要是便于通过按位与的散列算法来定位Segment的index。和HashMap数组默认容量初始值是16是一样的原因。有一点需要注意,Segment中HashEntry的数组长度默认初始值为2,并且长度一定为2的n次方,要与HashMap的默认初始化容量16区分开来。
ConcurrentHashMap不允许key和value为null,这一点和HashMap不同。在调用put()向ConcurrentHashMap里面添加元素时,首先是定位segment并且确保定位的segment已经初始化,然后调用segment的put()方法。
我们知道HashMap中定位数组索引index = hash & (n-1),那segment是如何定位的?实际上是使用两个全局变量segmentShift和segmentMask来定位的,计算公式为int j =(hash >>> segmentShift) & segmentMask,这个公式和HashMap计算index索引的思想是一样的,将根据key计算出来的hash值无符号右移segmentShift然后和和segmentMask按位与。相当于把hash值的高几位和segmentMask按位与。
计算出来segment之后,调用segment的put()方法开始往HashEntry数组中放数据,Segment继承了ReentrantLock可重入锁,首先调用tryLock()方法尝试获取锁,获取锁成功后,会计算出数据要放在HashEntry数组中的index索引位置,计算公式和HashMap一样。如果这个位置上的HashEntry不存在,直接头插法放入,如果这个位置上的HashEntry存在了,说明形成了链表,则遍历链表中的每一个元素,判断当前要插入的元素的key和hash值是否和链表中元素有相同的,如果有则覆盖原来的value,如果没有则采用头插法插入,插入后如果达到阈值就会触发扩容机制,ConcurrentHashMap的扩容只会扩容到原来的两倍,并且重新rehash。最后释放锁。整个添加元素的流程基本上和HashMap一模一样。
有可能你会想tryLock()方法尝试获取锁,如果获取不成功怎么办?它会调用scanAndLockForPut()方法不断的自旋 tryLock() 获取锁,当自旋次数大于指定次数时,使用 lock() 阻塞,直到获取到锁。在自旋时会遍历定位到的HashEnry位置的链表(遍历主要借着这段获取锁的空隙,使CPU缓存链表),若遍历过程中,由于其他线程的操作导致链表头结点变化,则需要重新遍历。
至于get()方法来获取元素,先定位Segment位置,再定位HashEntry,只需要计算得到key的存放位置,然后遍历找到相同key的元素即可,get方法不需要加锁。
到了JDK8 的时候改为了和HashMap一样的数据结构,即数组+链表+红黑树。不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 + 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hXw8RnRq-1630893465028)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210905173818337.png)]](https://img-blog.csdnimg.cn/2bd25afc44e543e3b4d0ef7e28ba4c1a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xVHYNxhn-1630893465031)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210906090541188.png)]](https://img-blog.csdnimg.cn/75d794b0ec8e4b519674328f96d1b99c.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)
在调用put()方法向集合中添加元素时,首先根据key的hashcode值计算出hash值,计算公式和HashMap一样。然后判断table数组是否已经完成初始化,如果完成则根据hash值计算出Node节点在数组中对应的索引位置,计算公式也和HashMap一样,如果这个索引位置为空,就利用自旋+CAS操作尝试写入。

如果计算出的数组索引位置不为空,并且这个位置的节点的hash值为MOVED(值为1),那么就会进行扩容。否则就会利用Synchronized加锁写入数据,并入节点数量大于等于了8就会进行树化成红黑树。和JDK 7 不同,JDK 8采用的是尾插法。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZeNZanQ9-1630893465037)(C:\Users\Jian\AppData\Roaming\Typora\typora-user-images\image-20210906093212418.png)]](https://img-blog.csdnimg.cn/3f1f4b7be82d48f0bcf2714e0fdf8d1b.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54WO5Li25YyF,size_20,color_FFFFFF,t_70,g_se,x_16)
get()方法来获取元素的方式,基本上也和之前一样。首先计算出hash值并转换为数组对应的索引位置,如果索引位置的头节点恰好就是要查找的那个节点,就直接返回头节点的value值,如果说头节点的hash值小于0,说明正在扩容或者是一颗红黑树,如果是链表就遍历进行查找。

至此,ConcurrentHashMap 讲的也差不多了,可能你会发现ConcurrentHashMap在JDK7 、8发生了一些变化。
JDK 7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
JDK 8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 JDK 7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 + 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小(≥8)时会转化成红黑树,在冲突小于一定数量(≤6)时又退回链表。
不过总体来看,ConcurrentHashMap并发容器的put()、get()、以及扩容机制大部分操作和HashMap是一样的,相当于把HashMap进行了优化改造,使得HashMap具备了多线程安全的特性。















 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









