







Collections.sort是java自带的一个排序api,相信绝大多数小伙伴都用过这个api,非常常用。既然这么常用,我觉着有必要研究一下它内部是怎么实现的,避免掉坑。先说点排序算法相关的基本知识。
排序算法有2个非常重要的指标,我们需要关注。
1.是否原地排序
2.是否稳定排序
第一个指标是说算法中是否借助了额外的空间进行排序操作
第二个指标是说算法是否稳定
如何理解 稳定 这个词呢?我们举个例子。
比如说:我们要对一组学生按照出生日期升序排列。相同生日的订单,再按照年龄升序排列。如何实现这个需求呢?
这个需求实现的思路是:要注意先按照生日升序排,然后再按照年龄排(反过来实现,难度会倍增)可以借助Collections.sort实现,伪代码如下:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private int id;
private String name;
private int age;
private long birthday;
}
//测试方法,建1000个待排序的对象
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
int[] studentAge = new int[]{66, 77, 88, 99, 100, 110, 111};
int[] studentBirthday = new int[]{12345, 12347, 12353, 12358, 12389, 1234509, 1234556};
Random random = new Random();
Student student;
for (int i = 0; i < 1000; i++) {
student = Student.builder()
.id(i)
.name("测试"+i)
.age(studentAge[random.nextInt(6)])
.birthday(studentBirthday[random.nextInt(6)])
.build();
studentList.add(student);
}
Comparator<Student> birthdayComparator = (o1, o2) -> {
if (o1.getBirthday() > o2.getBirthday()) {
return 1;
} else if (o1.getBirthday() < o2.getBirthday()) {
return -1;
} else {
return 0;
}
};
Comparator<Student> ageComparator = (o1, o2) -> {
if (o1.getAge() > o2.getAge()) {
return 1;
} else if (o1.getAge() < o2.getAge()) {
return -1;
} else {
return 0;
}
};
//either provide a Comparable class type or a Customize Compartor
Collections.sort(studentList,birthdayComparator);
Collections.sort(studentList,ageComparator);
System.out.println(JSON.toJSONString(studentList));
}
这个时候,我们就要思考一个问题,我按照生日升序完毕,再按照年龄排的话,之前按生日排好序的序列会不会发生变化呢?
这个问题,其实就是我今天想聊的话题。直接说结论,Collections.sort是稳定排序,按照生日升序完毕,再按照年龄排。之前按生日排序的序列不会发生变化。
接下来,聊一下Collections.sort的实现。入口是Collections类中的这个方法
public static <T> void sort(List<T> list, Comparator<? super T> c) {
list.sort(c);
}
然后进入List接口中的sort方法,如下
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
注意这是一个default方法,接口的默认实现。这里说一个本地debug的小知识点。我们只知道接口,如果这个接口有很多实现,如何知道接口到底走哪个实现类呢?有一个简单的办法,我们可以直接将断点打在接口上,像下面这样。
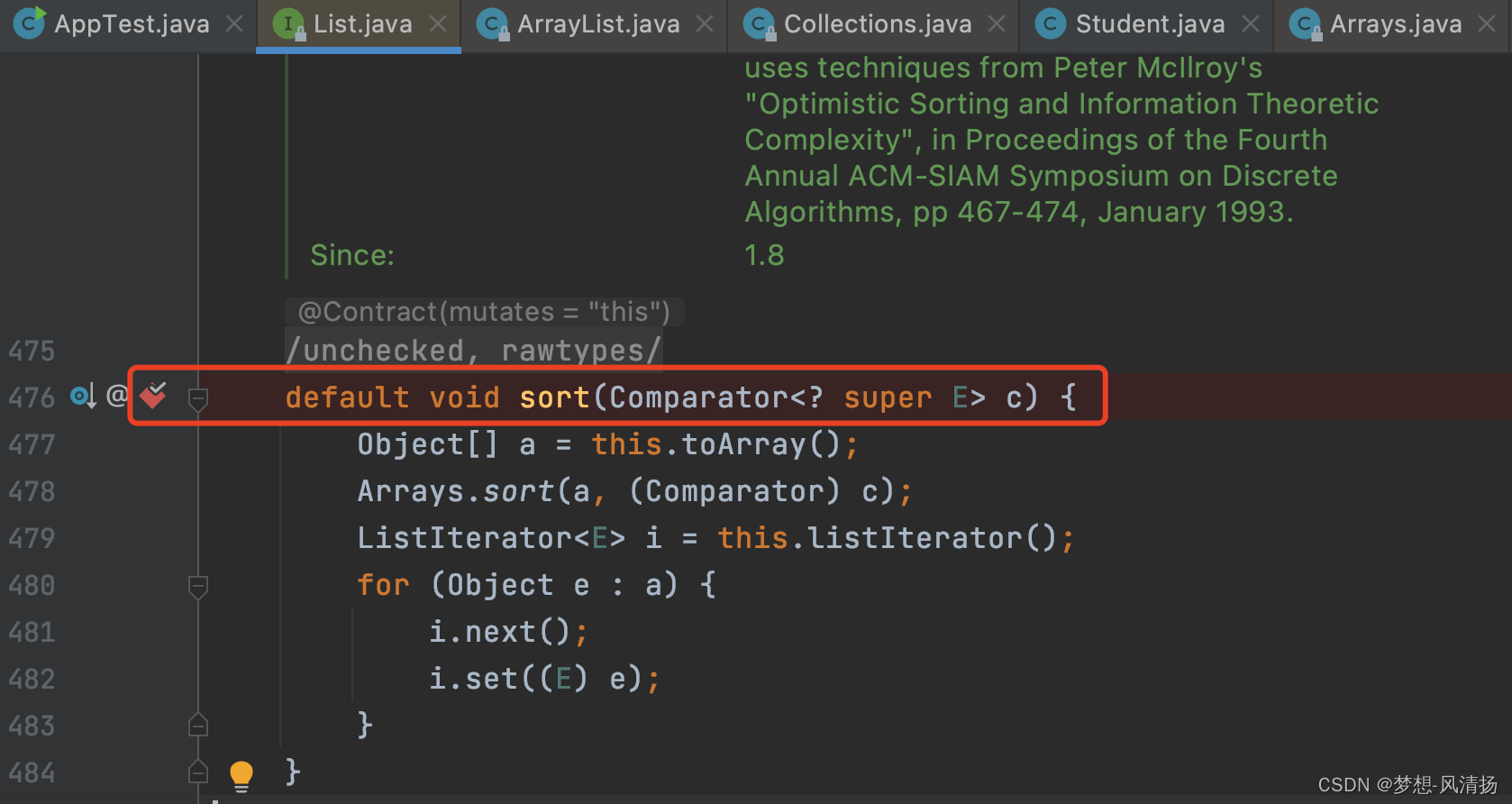
Idea可以自动识别到实现类,并进入实现类中
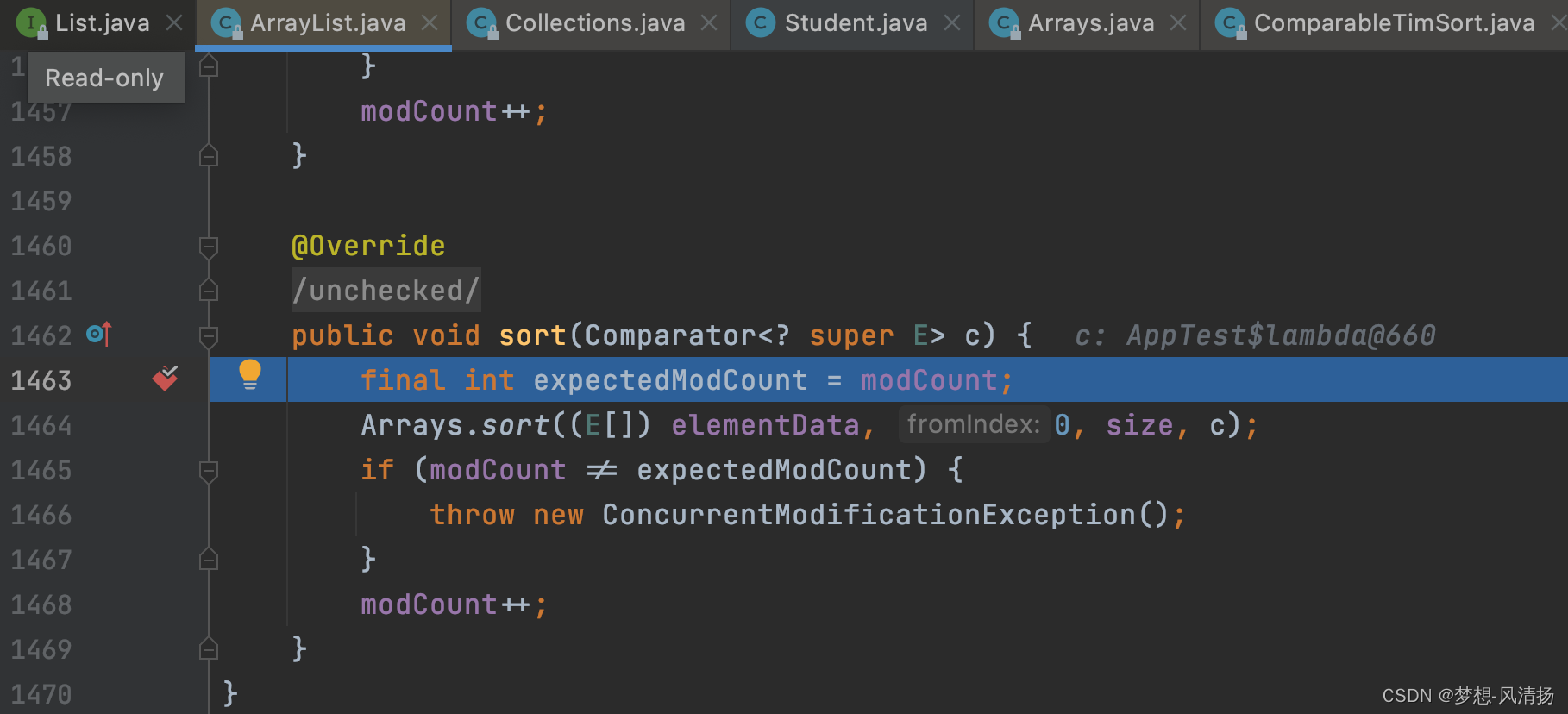
这个小技巧非常的实用,大家记得记在小本本上。下面聊回正题,进入ArrayList的sort方法后,最关键的是Arrays.sort方法,我们看一下这个方法的实现
public static <T> void sort(T[] a, int fromIndex, int toIndex,
Comparator<? super T> c) {
if (c == null) {
sort(a, fromIndex, toIndex);
} else {
rangeCheck(a.length, fromIndex, toIndex);
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, fromIndex, toIndex, c);
else
TimSort.sort(a, fromIndex, toIndex, c, null, 0, 0);
}
}
根据当前的条件可知,c不为null,并且LegacyMergeSort.userRequested是false,执行了TimSort排序,这里提一句这个TimSort,这个排序算法是一个叫Tim Peters 在2002年实现的,维基百科定义如下:
Timsort 是一种混合稳定的排序算法,源自合并排序和插入排序,旨在较好地处理真实世界中各种各样的数据。它使用了 Peter Mcllroy 的"乐观排序和信息理论上复杂性"中的技术,参见 第四届年度ACM-SIAM离散算法研讨会论文集,第467-474页,1993年。 它由 Tim Peters 在2002年实现,并应用于 Python编程语言。该算法通过查找已经排好序的数据子序列,在此基础上对剩余部分更有效地排序。 该算法通过不断地将特定子序列(称为一个 run )与现有的 run 合并,直到满足某些条件为止来达成的更有效的排序。 从 2.3 版本起,Timsort 一直是 Python 的标准排序算法。 它还被 Java SE7[4], Android platform[5], GNU Octave,[6] 谷歌浏览器,[7] 和 Swift[8] 用于对非原始类型的数组排序。
通过以上描述,隐约感觉这个排序算法的来头很大。实际上,这个算法是在经典的排序算法上进行了改良,下面我们就揭开这个算法神秘的面纱。维基百科上说了一大堆,我们只需要关注其中的2点。
1.该算法通过查找已经排好序的数据子序列,在此基础上对剩余部分更有效的排序
2.该算法通过不断的将特定子序列(称为一个run)与现有的run合并
大家记住这两点,Tim老哥的算法就是围绕以上两点来实现的。我没有贴一些动态图,大家想看动态图的话,可以看这篇文章世界上最快的排序算法
好,下面开始分析
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c,
T[] work, int workBase, int workLen) {
assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length;
//计算集合的大小
int nRemaining = hi - lo;
if (nRemaining < 2)
//集合中的元素数量是0或1说明元素已经有序,无需排序
return;
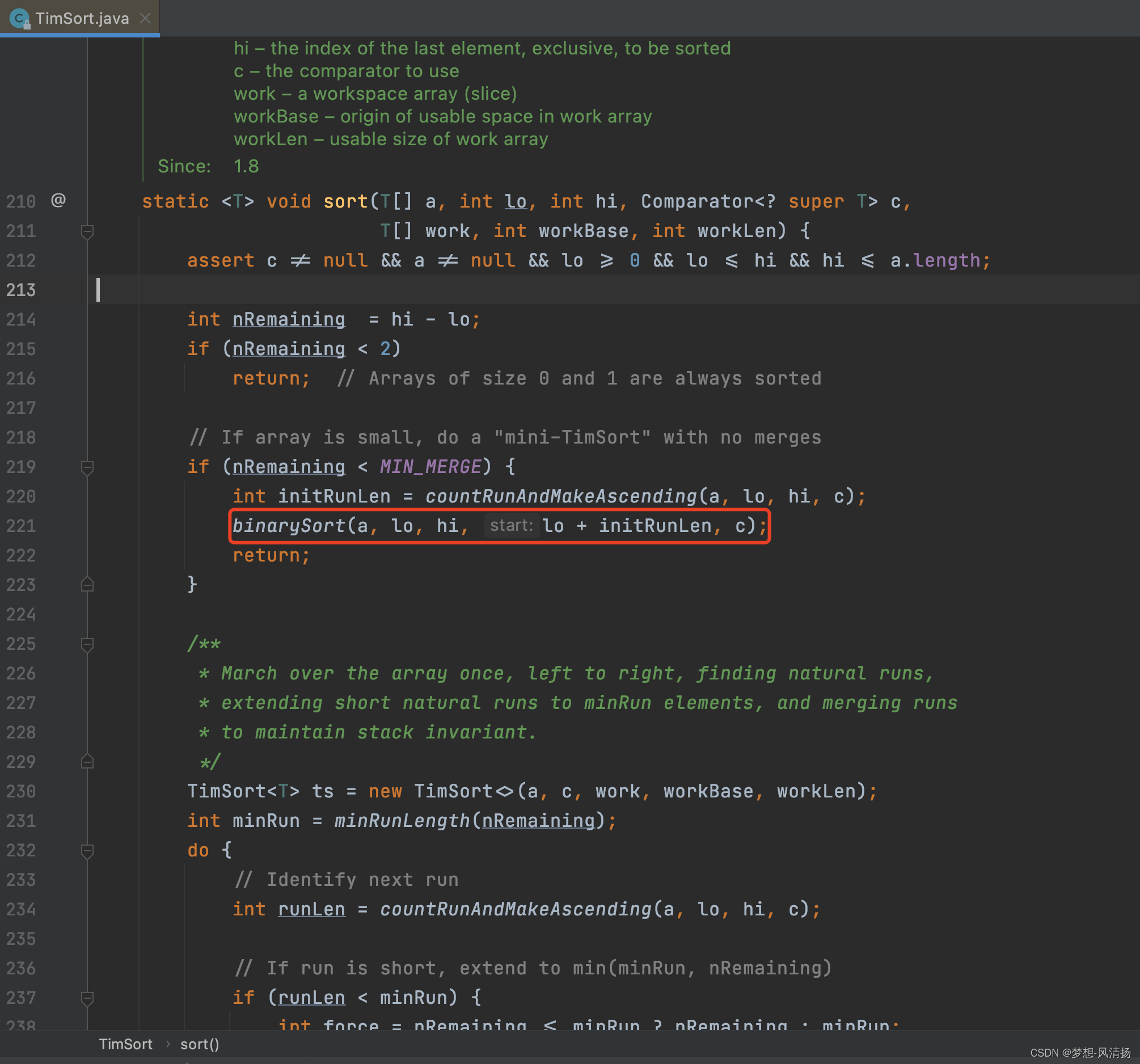
//如果集合元素数量小于32,使用二分查找算法进行排序。小数据量时,二分查找+普通插入排序就可以了
if (nRemaining < MIN_MERGE) {
//获取集合中有序元素的数量,以该数量为基础对其余元素进行排序
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*/
TimSort<T> ts = new TimSort<>(a, c, work, workBase, workLen);
//计算run块的大小,这个大小是根据你打算排序的数据量来的。取值为16-32之间
int minRun = minRunLength(nRemaining);
do {
//从待排序数组中找到一段升序的集合,这部分数据就不用排序了,因为已经有序。
//Tim老哥的优化其实主要就是针对这种已经有序的集合,找到这种有序段,直接进行数组拷贝,比原始的归并排序挨个
//比较元素要快。
int runLen = countRunAndMakeAscending(a, lo, hi, c);
//如果有序的数据段小于minRun的长度,比如本例中,我们的数据量是1000,minRun是32。假如我们找到的有序数据
//段是3的话,有序数据段的长度不足32,我们就需要使用二分搜索+插入排序对(32-3)个元素进行排序。排成升序的
//效果
if (runLen < minRun) {
//如果剩余元素不足一个run块的大小,那就拍剩余的元素就ok了,否则就需要排一个run块的大小
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}
//把run块放入栈中
ts.pushRun(lo, runLen);
//执行合并操作
ts.mergeCollapse();
//寻找下一个run块
lo += runLen;
//待排序数据减去一个run块的大小
nRemaining -= runLen;
} while (nRemaining != 0);
//合并剩余的run块,完成合并操作
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
//获取集合中有序元素的数量,如果有序数据为逆序,进行反转
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi,
Comparator<? super T> c) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
if (c.compare(a[runHi++], a[lo]) < 0) { // 逆序
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // 正序
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
//二分查找法对数据进行排序,该方法的时间复杂度是O(nlogn),但是因为引入了System.arrayCopy方法,所以最坏情况下,可能会退化为O(n²)。
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
assert lo <= start && start <= hi;
if (start == lo)
start++;
for ( ; start < hi; start++) {
T pivot = a[start];
int left = lo;
int right = start;
assert left <= right;
//start索引前面的数据都是排好序的,我们需要给pivot这个数据找到它应该放的位置
while (left < right) {
int mid = (left + right) >>> 1;
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* The invariants still hold: pivot >= all in [lo, left) and
* pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the
* first slot after them -- that's why this sort is stable.
* Slide elements over to make room for pivot.
*/
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
Peter老哥的注释写的已经很清晰了,我觉着不需要我再解释啥了。这个binarySort方法主要就是利用了二分查找算法,找到pivot应该在的位置后,对该位置以后的数据进行搬移,给pivot元素腾位置,最后执行a[left] = pivot,将pivot元素放到腾出来的位置。然后利用该方法对剩余元素继续排序。
minRunLength的实现
private static int minRunLength(int n) {
assert n >= 0;
int r = 0; // Becomes 1 if any 1 bits are shifted off
while (n >= MIN_MERGE) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
这里又用到了位运算,再补点小知识点
|和&是或运算和与运算,这个很简单,不多说。
两个大于号(>>),这个是右移操作,相当于我们平时用的除2操作,但是性能上要比除操作快得多。右移后,空出的符号位用原来的符号补齐。什么意思呢?
String binaryString = Integer.toBinaryString(-12);
System.out.println(binaryString);
String binaryStringRightMove = Integer.toBinaryString(-12 >> 3);
System.out.println(binaryStringRightMove);
输出:
11111111111111111111111111110100
11111111111111111111111111111110
右移前,左边的符号位上都是1,所以右移后,左边不足32位了,需要用1进行补齐
三个大于号(>>>),这个是无符号右移,也是除2操作,和上面的>>操作不同的是,右移后,左边空出的符号位用0补齐。这种移动方式会导致数据的符号发生变化,比如:-2 >>> 1是2147483647。
String binaryString = Integer.toBinaryString(-12);
System.out.println(binaryString);
String binaryStringRightMove = Integer.toBinaryString(-12 >>> 3);
System.out.println(binaryStringRightMove);
输出:
11111111111111111111111111110100
00011111111111111111111111111110
//用2个栈来存储run块的数据,runBase存储的是run块的起始位置。runLen存储的是run块的大小,run块合并后,大小会发生变化
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++;
}
//执行合并操作,需要满足合并条件,否则忽略本次合并
private void mergeCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {
if (runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
//对2个run块执行合并操作,需要借助第三方数组
private void mergeAt(int i) {
assert stackSize >= 2;
assert i >= 0;
assert i == stackSize - 2 || i == stackSize - 3;
int base1 = runBase[i];
int len1 = runLen[i];
int base2 = runBase[i + 1];
int len2 = runLen[i + 1];
assert len1 > 0 && len2 > 0;
assert base1 + len1 == base2;
/*
* Record the length of the combined runs; if i is the 3rd-last
* run now, also slide over the last run (which isn't involved
* in this merge). The current run (i+1) goes away in any case.
*/
runLen[i] = len1 + len2;
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
stackSize--;
/*
* Find where the first element of run2 goes in run1. Prior elements
* in run1 can be ignored (because they're already in place).
* 这是一个优化点。原版注释写的很清楚,找到run2块的第一个元素在第一个run1块中的位置i,因为2个run块都是有序
* 的,所以i之前的位置就不需要比较了,直接合并即可。
*/
int k = gallopRight(a[base2], a, base1, len1, 0, c);
assert k >= 0;
base1 += k;
len1 -= k;
if (len1 == 0)
return;
/*
* Find where the last element of run1 goes in run2. Subsequent elements
* in run2 can be ignored (because they're already in place).
* 同样找到run1的最后一个元素在run2中的位置j,那j之后的元素也就不需要比较了,直接合并即可。
*/
len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c);
assert len2 >= 0;
if (len2 == 0)
return;
// Merge remaining runs, using tmp array with min(len1, len2) elements
//将不需要比较的元素挑出来后,下面就开始进行真正的归并排序操作了。这里也是一个优化点,比较2个run块的大小,哪
//个小,就将哪个拷贝到临时数组中,这样可以省点空间
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}
//执行真正的合并操作
private void mergeLo(int base1, int len1, int base2, int len2) {
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
// Copy first run into temp array
T[] a = this.a; // For performance
//申请临时数组
T[] tmp = ensureCapacity(len1);
int cursor1 = tmpBase; // Indexes into tmp array
int cursor2 = base2; // Indexes int a
int dest = base1; // Indexes int a
//将run块1中的待排序数据拷贝到临时数组中,去除了gallopRight中找到的部分
System.arraycopy(a, base1, tmp, cursor1, len1);
// Move first element of second run and deal with degenerate cases
a[dest++] = a[cursor2++];
if (--len2 == 0) {
System.arraycopy(tmp, cursor1, a, dest, len1);
return;
}
if (len1 == 1) {
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
return;
}
Comparator<? super T> c = this.c; // Use local variable for performance
int minGallop = this.minGallop; // " " " " "
outer:
//这个死循环里有2个do-while循环
while (true) {
int count1 = 0; // Number of times in a row that first run won
int count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run starts
* winning consistently.
* 第一个do-while循环,进行合并曹组,同时记录连续有序数据块的长度。超过7个时就进入gallop方式。gallop
* 模式其实就是找到已经有序的数据块,直接进行数组拷贝
*/
do {
assert len1 > 1 && len2 > 0;
if (c.compare(a[cursor2], tmp[cursor1]) < 0) {
a[dest++] = a[cursor2++];
count2++;
count1 = 0;
if (--len2 == 0)
break outer;
} else {
a[dest++] = tmp[cursor1++];
count1++;
count2 = 0;
if (--len1 == 1)
break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a
* huge win. So try that, and continue galloping until (if ever)
* neither run appears to be winning consistently anymore.
*/
do {
assert len1 > 1 && len2 > 0;
count1 = gallopRight(a[cursor2], tmp, cursor1, len1, 0, c);
if (count1 != 0) {
System.arraycopy(tmp, cursor1, a, dest, count1);
dest += count1;
cursor1 += count1;
len1 -= count1;
if (len1 <= 1) // len1 == 1 || len1 == 0
break outer;
}
a[dest++] = a[cursor2++];
if (--len2 == 0)
break outer;
count2 = gallopLeft(tmp[cursor1], a, cursor2, len2, 0, c);
if (count2 != 0) {
System.arraycopy(a, cursor2, a, dest, count2);
dest += count2;
cursor2 += count2;
len2 -= count2;
if (len2 == 0)
break outer;
}
a[dest++] = tmp[cursor1++];
if (--len1 == 1)
break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0)
minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len1 == 1) {
assert len2 > 0;
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
} else if (len1 == 0) {
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len2 == 0;
assert len1 > 1;
System.arraycopy(tmp, cursor1, a, dest, len1);
}
}
//上面的数据块合并存在忽略的情况,这里的合并操作就是针对栈中整体的run块了,相当于来一个大收官。
private void mergeForceCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
}
}
上面分析了这么多,我们来总结一下Tim老哥的TimSort排序算法。实际上,从根上来说,主要还是归并排序算法。如果待排序数组中存在部分已有序的数据段,那TimSort算法的比较次数要小于普通的归并排序,虽然说最差情况下的时间复杂度也是O(nlogn),但是空间复杂度只有n/2,相较于普通的归并排序算法,时间复杂度是稳定的O(nlogn)以及空间复杂度是稳定O(n)。TimSort算法的优势非常大。TimSort主要的优化点有以下几个。
1.数据量较小,直接使用二分查找+插入排序进行排序
2.数据量较大时,引入run块的概念,但是会先找到run块中已排好序的部分,减少比较次数
3.使用额外的数组空间进行合并操作时,只用一半的空间即可
续:
最近正好用到了排序的需求,需求很简单,就是产品给了排序规则,我们按照这个排序规则对集合数据进行排序。正好用上了前段时间写的这个Collections.sort,感觉对之前写的二分查找+插入排序的部分还是有点不明白。再根据这个实际的案例分析一波。排序规则伪代码如下:
public class CardTradeComparator implements Comparator<CouponVO> {
@Override
public int compare(CouponVO o1, CouponVO o2) {
if(o1 == null || o2 == null){
return 0;
}
if(o1.getCouponType() > o2.getCouponType()){
return 1;
}
if(o1.getCouponType() < o2.getCouponType()){
return -1;
}
BigDecimal bigDecimalFirst = o1.getAmount;
BigDecimal bigDecimalTwo = o2.getAmount;
if (Objects.isNull(bigDecimalFirst) || Objects.isNull(bigDecimalTwo)) {
return 0;
}
if (bigDecimalFirst.compareTo(bigDecimalTwo) == -1) {
return 1;
}
if (bigDecimalFirst.compareTo(bigDecimalTwo) == 1) {
return -1;
}
return 0;
}
}
不知道你们有没有一个疑问。这个排序规则如何覆盖上面这么多比较方式的呢?假如有一个元素a我们比较完之后,它就进入了集合中,那后面假如元素b和元素a需要比较的时候,如何保证元素b一定能和a比较上呢?
假如我们的元素小于32个,那执行的就是这个binarySort方法,二分查找+插入排序
这个方法,我们之前其实剖析过,今天再把它拎出来聊一聊:
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
//start索引前的元素已经排好序了,直接对start后的元素进行排序就ok了。这个优化点解决了:当集合是有序的情况下,插入排序的问题,原始的插入排序算法,即使数据已经有序,它还是要挨个元素比较一遍。
assert lo <= start && start <= hi;
if (start == lo)
start++;
for ( ; start < hi; start++) {
//待排序元素
T pivot = a[start];
int left = lo;
int right = start;
assert left <= right;
/*
* Invariants:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
*/
//二分查找,找到待排序元素应该存在的位置
while (left < right) {
int mid = (left + right) >>> 1;
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* The invariants still hold: pivot >= all in [lo, left) and
* pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the
* first slot after them -- that's why this sort is stable.
* Slide elements over to make room for pivot.
*/
int n = start - left; // The number of elements to move
//移动元素,给pivot元素腾地方
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
其实经过上面的分析,我们就知道了集合中的元素和已经排好序的元素都会再比较一遍。有用类型比较的,有用金额比较的。相同比较维度的放一堆。















 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









