







写在前面
本文是学习Linux2.6内核的总结,不免涉及到一些具体的数据结构,只关注原理的可以跳过。感兴趣的话结合数据结构能够理解更佳深刻。
进程
- 进程是程序执行时的一个实例
- 多个终端或用户执行同一个可执行文件,会生成多个进程
进程的状态
进程状态类型字段:
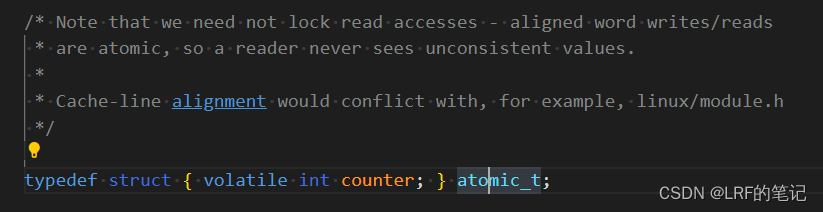
volatile long state;
进程状态定义:

- TASK_RUNNING: 进程在运行中或准备运行
- TASK_INTERRUPTIBLE: 进程被挂起,等待某个条件为真时重新执行,如硬件中断、系统资源或某个信号
- TASK_UNINTERRUPTIBLE: 进程被挂起,但信号不会改变其状态
- TASK_STOPPED: 进程暂停
- TASK_TRACED: 进程被debugger程序暂停
- TASK_ZOMBIE: 进程被终止,但是父进程还没有回收子进程资源
- TASK_DEAD: 父进程发出回收进程命令后,短暂进入此状态,最终进程被系统删除
进程状态转换
进程描述符
-
每个进程对应一个进程描述符(process description),对应
task_struct结构体类型 -
每个进程描述符对象里有一个进程标识符(PID),唯一标识该进程,对应
pid_t类型(实际就是int) -
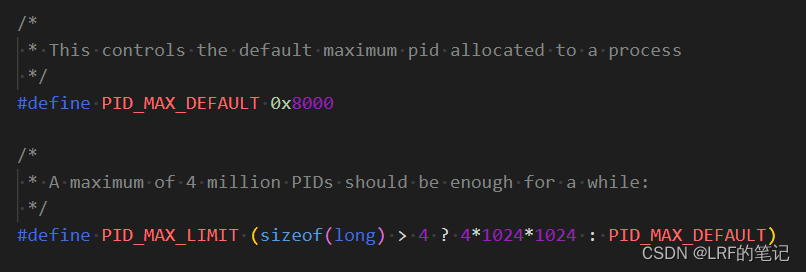
PID按顺序编号,新创建的子进程的PID加1,使用到达上限后循环使用较小的闲置的编号,默认最大上限是32768(0x8000),在LP64系统下是4194304(0x400000),可以在
/proc/sys/kernel/pid_max文件修改成小于上限值的值
-
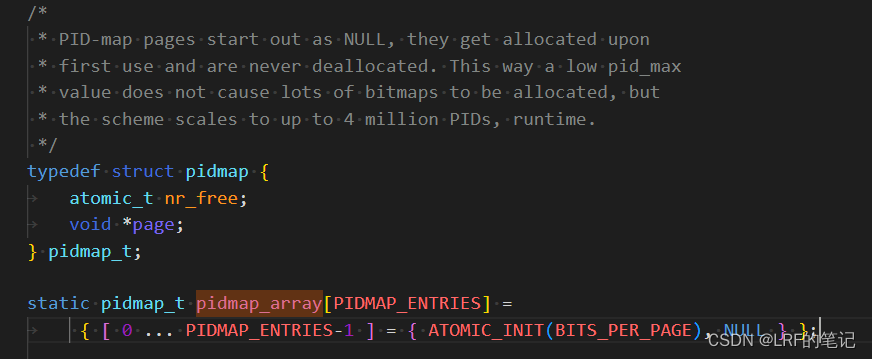
系统需要知道哪些编号是使用和空闲,因此利用位图
pidmap_array表示每个编号的使用状态
-
一个线程组中的线程共享同一个PID
-
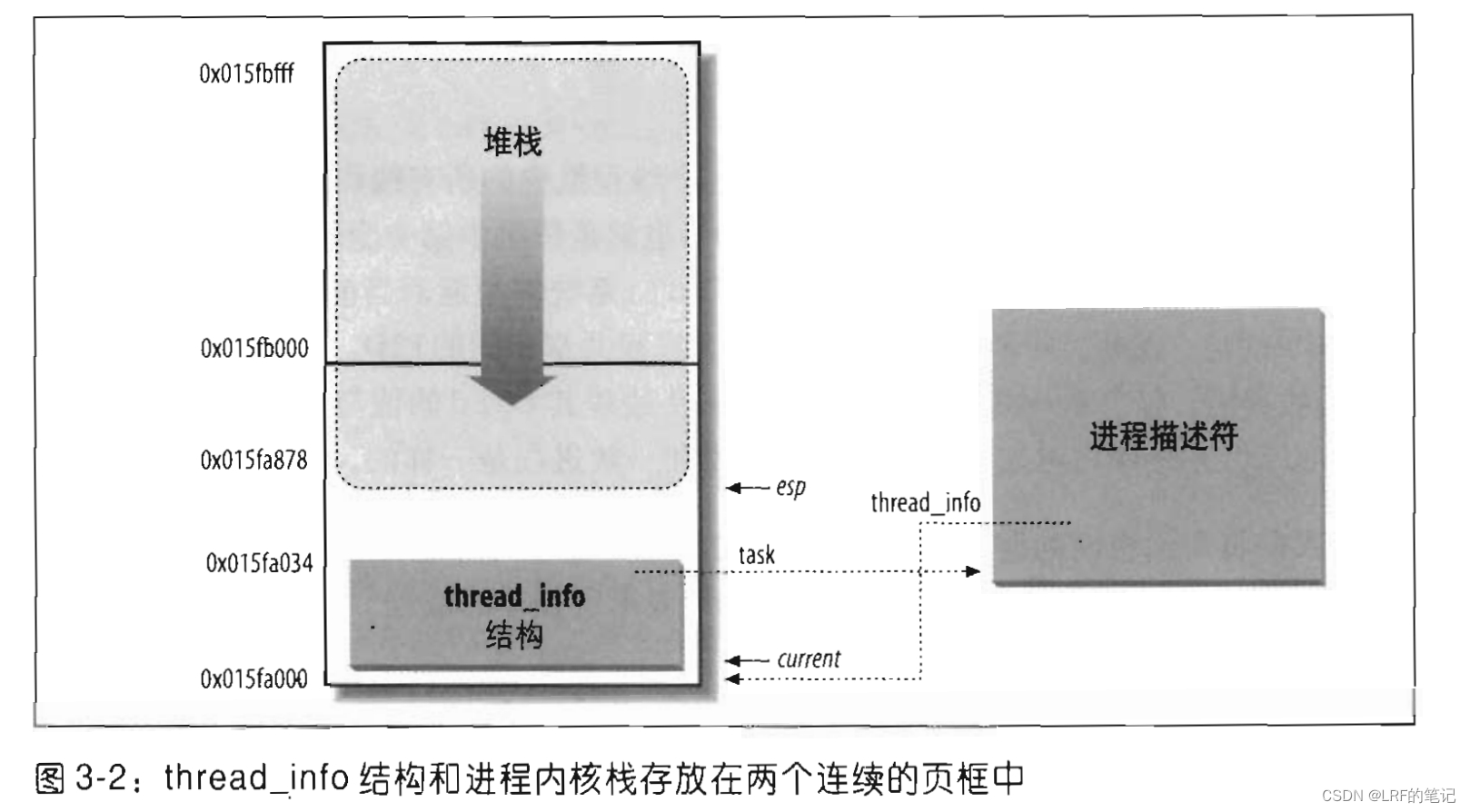
内核为每个进程创建了进程堆栈(用于访问该进程内核态数据),每个进程对应一个线程描述符,这2个对象一般在内存中是连续的,总共占用8K(8192,即2个页框)字节(如果内存碎片很严重可以在内核编译时指定使用4K,即1个页框,但是内核需要额外的栈保证异常或嵌套调用情况下不会出现栈溢出)
-
如上图所示,进程描述符对象通过
*thread_info指向其线程描述符,线程描述符对象通过*task指向其进程描述符
进程链表
-
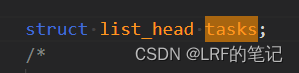
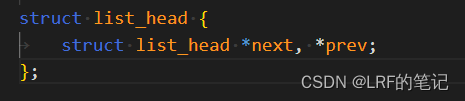
进程链表的支持,每个进程描述符
task_struct都有tasks字段,其是list_head结构体类型,具有指向自身类型的next指针和prev指针,指向下一个和前一个进程描述符的tasks字段,如此可以把进程用链表链起来(双向链表的应用):
-
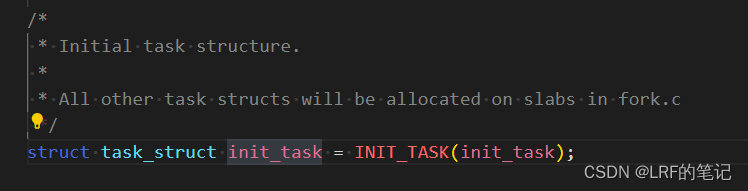
进程链表的表头是
init_task,即0号进程,init_task的初始化是用INIT_TASK宏完成的:
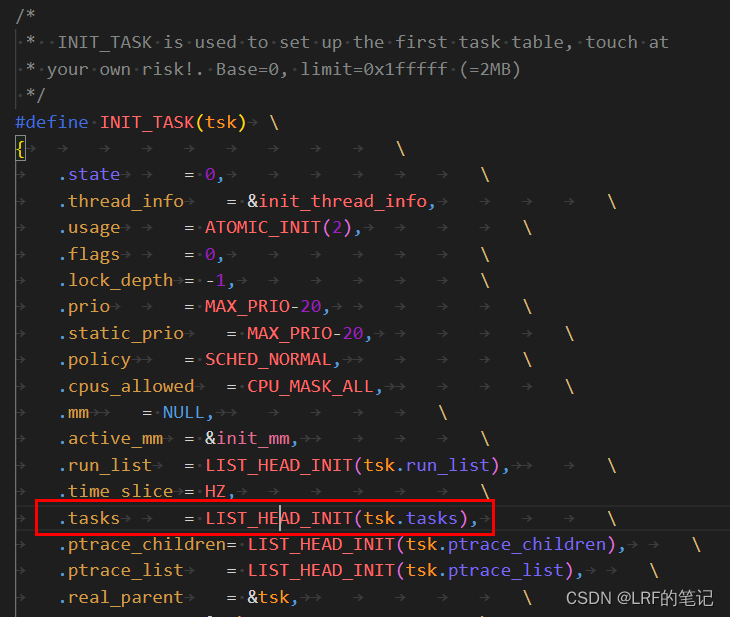

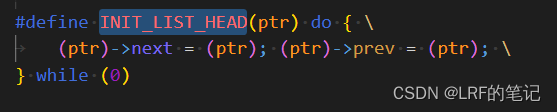
先重点看下0号进程的链表情况,init_task.tasks.next和init_task.tasks.prev初始化成自身的tasks的地址,此时链表情况如下:
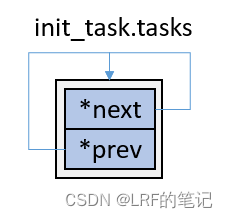
-
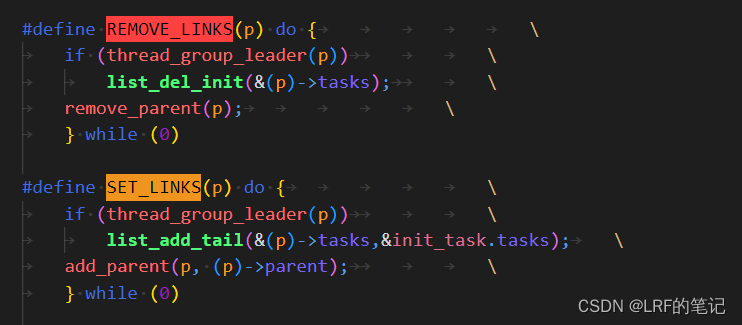
进程链表的插入和删除是由
SET_LINKS和REMOVE_LINKS宏完成的,调用的关键函数是list_add_tail和list_del_init:
看一下list_add_tail的实现方式:
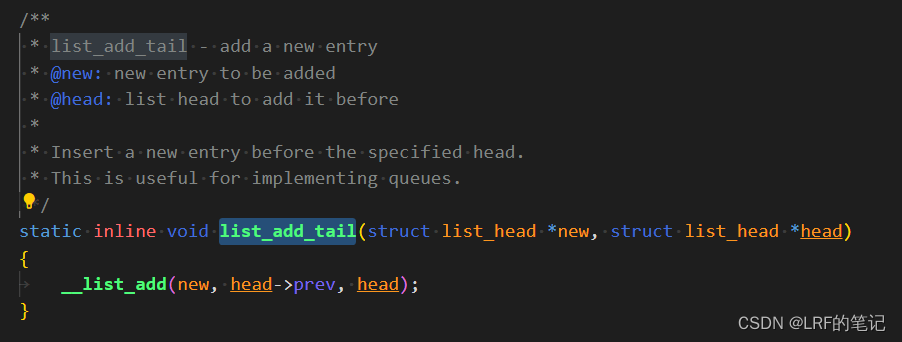
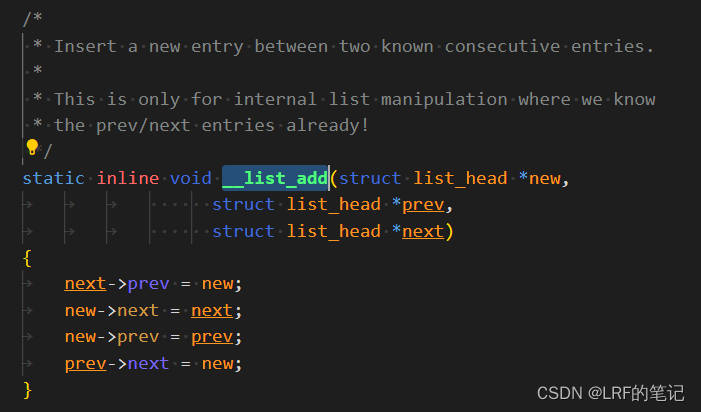
最关键的是上述4条指针赋值,在__list_add函数里,new是要插入的task_struct.tasks对象,prev是init_task.tasks.prev指向的task_struct.tasks对象,next是init_task.tasks对象本身。第1条和第2条处理new和init_task的指向关系,第3条和第4条处理new和init_task.prev的指向关系。可以看到,插入链表new是把new插入到init_task和init_task.prev之间,然后更改下new、init_task和init_task.prev三者的指向关系,改完后依然保持环形双向链表状态。举个例子,插入1号进程,指针变化前后对比:
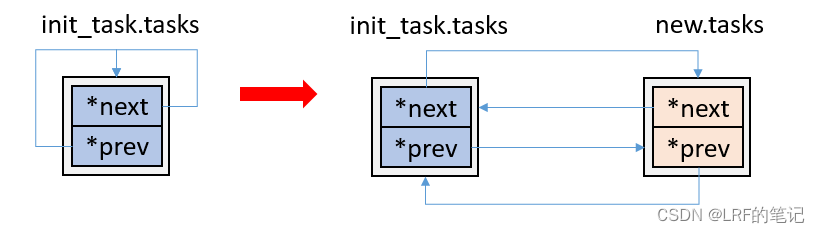
如果继续插入2号进程,指针变化前后对比:

再插入新的节点是一样的道理。可能有点绕,不过自己画一画就很好理解了。注意一点,每个next和prev指针指向的都是task_struct.tasks类型对象,而不是task_struct.tasks.next或task_struct.tasks.prev对象(注意看上图箭头)。个人觉得这里代码写的容易搞混淆,__list_add函数的入参prev和next取名不太好,应该叫prev_tasks或prev_node可能比较好理解一些,next同理。再来看一下
list_del_init的实现:
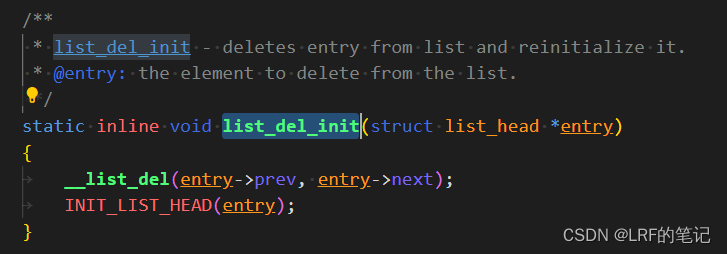
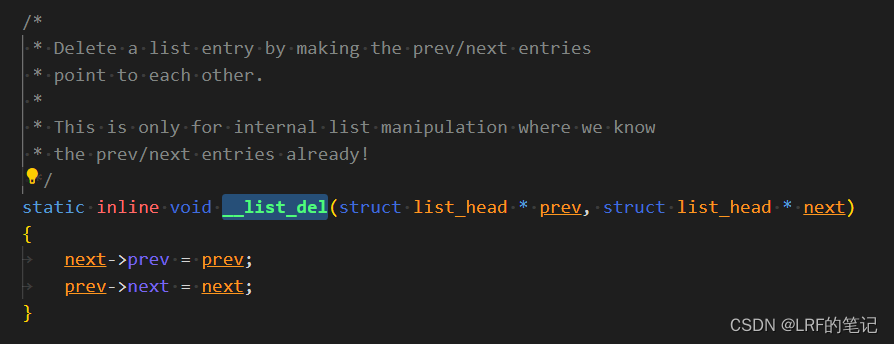
有了之前插入链表的理解,删除链表的代码也就很简单了。entry->prev和entry->next分别指向entry的前后节点,删除一个双向链表的节点就是把该节点的前后节点链起来,这就是__list_del函数干的事情。例如把上图的new节点删除,指针变化前后对比:

被删除的
entry节点被重新初始化(reinitialize),其next和prev指针指向自身。 -
一个进程可以包含多个线程(thread),且这些线程共享同一个PID,属于一个线程组。一个线程组有一个领头线程(thread group leader)。实际上,创建一个新进程,其领头线程就是自身,其进程描述符存于
tgid,因此这个线程的pid等于tgid,后续创建的线程的PID都等于领头线程的PID。 -
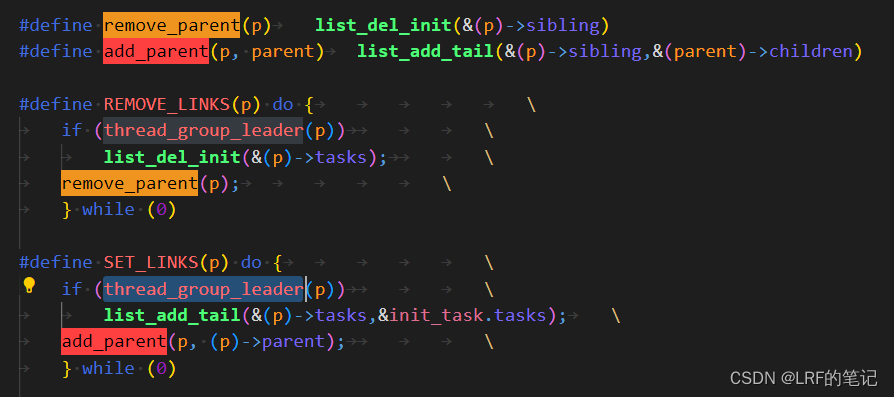
在上述插入和删除链表的实现中,
SET_LINKS、REMOVE_LINKS宏都有个判断分支:thread_group_leader,实际上就是判断pid和tgid是否相等,如果相等说明是领头线程,插入的话是在init_task后插入,删除的话是删除其tasks;如果不相等说明不是领头线程,插入的话是把其兄弟节点(sibling)插入到其父进程的孩子节点((p->parent)->children)后面,删除的话是删除其兄弟节点:
-
进程链表的遍历,内核提供了遍历的宏定义:
for_each_process,从init_task开始一直遍历到链表尾部(实际上循环链表的尾部就是再次遍历到初始位置):

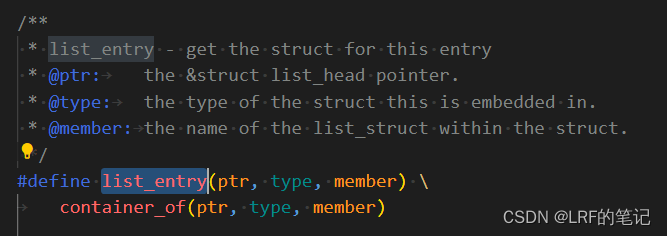
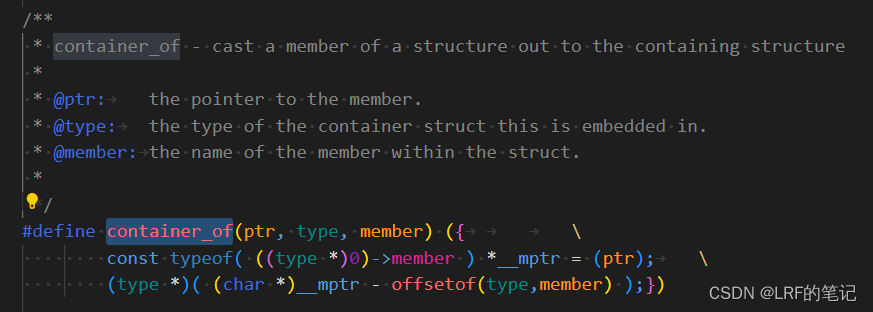
container_of的大致思路就是用一个临时变量__mptr指向当前节点,然后计算下一个节点的偏移量(通过__mptr和task_struct与其成员变量tasks的偏移 之差)强转成*task_struct类型返回,赋值给当前节点。
TASK_RUNNING状态进程的切换
- 进程调度程序只会在TASK_RUNNING状态的进程里选择一个进程执行
- Linux内核用链表把所有TASK_RUNNING进程链在一起,如果链表数量过多,扫描链表的时间会很久。所以内核采用了优先级数组(
prio_array)的实现方案,把不同优先级的TASK_RUNNING进程放在不同的运行队列里,队列用链表实现
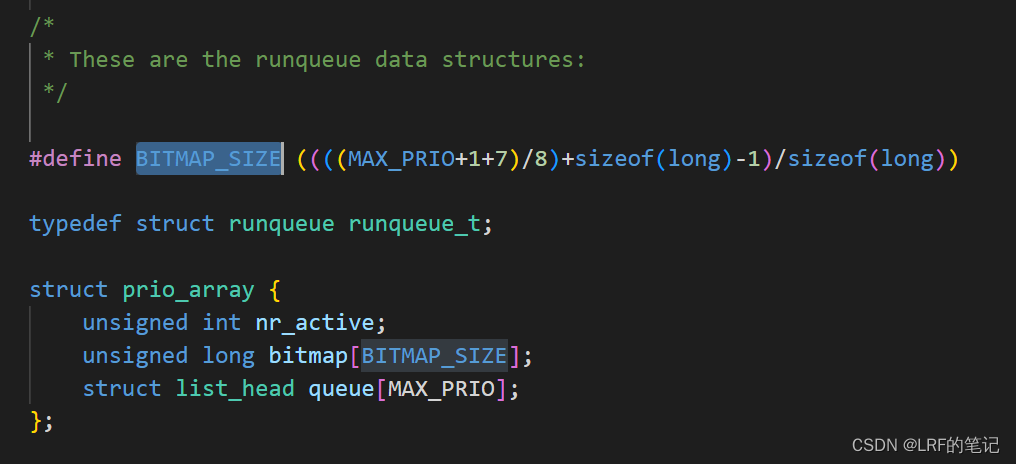
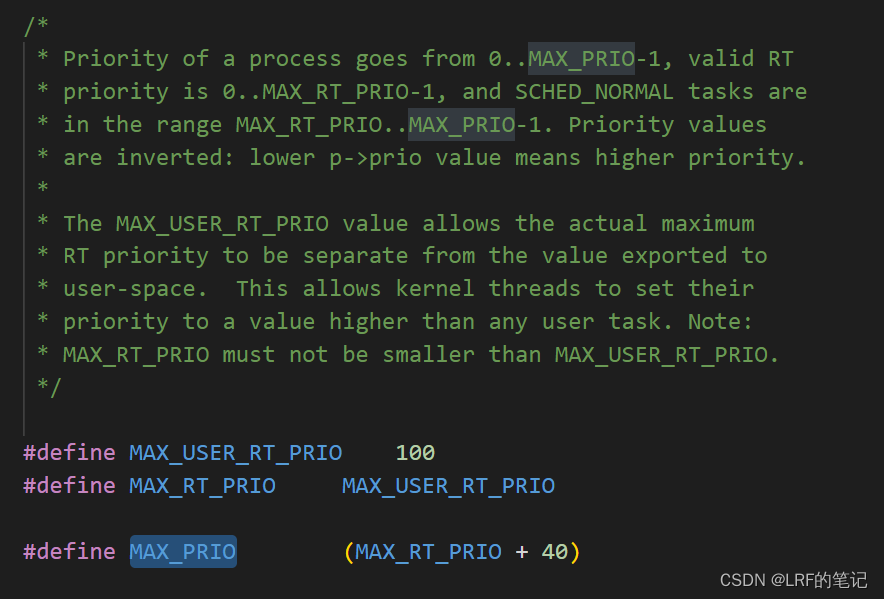
- 如上图所示,Linux内核总共定义了140个优先级(0-139),其中0-99用于实时优先级(
MAX_RT_PRIO),100-139用于非实时优先级。调度程序会根据当前进程是否是实时进程采取不同的优先级调度。 - 在用户态可以使用的优先级由
MAX_USER_RT_PRIO定义,MAX_RT_PRIO不能小于MAX_USER_RT_PRIO,这样内核态才能设置比用户态更高的优先级。进程描述符内的优先级字段(p->prio)是经过转化计算的,数值越低,优先级越高。 - 把进程插入运行队列:把某个进程插入某个优先级的运行队列,调用
enqueue_task接口:
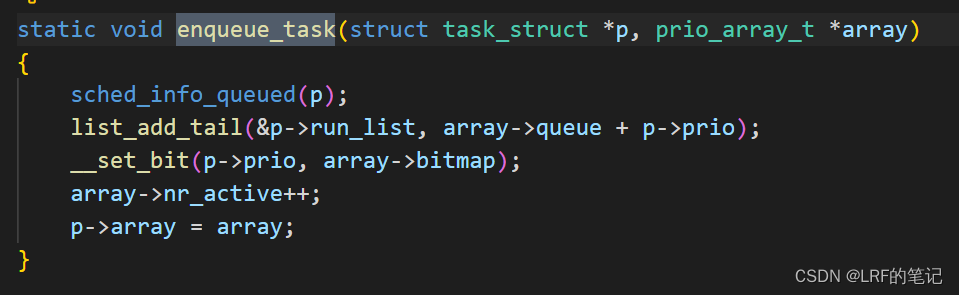
实现原理就是把进程p的run_list插入到运行队列数组array对应优先级的队列,然后设置对应优先级的bitmap(标志对应优先级的进程链表是否为空),活跃的进程数量+1,最后把进程p的array字段指向运行队列(使得通过进程描述符找到其在运行队列中的位置)。 - 从运行队列删除某进程:把某个进程从运行队列删除,调用
dequeue_task接口:
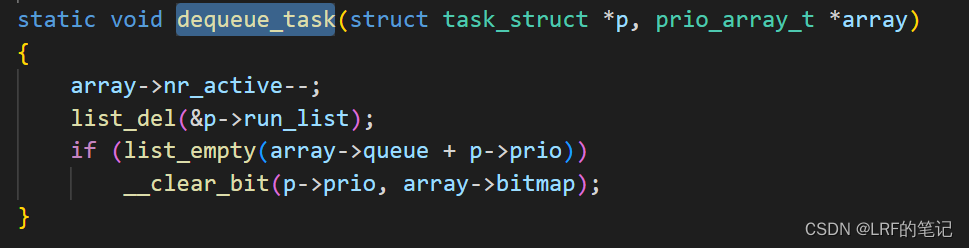
实现原理基本上就是插入的逆操作。涉及到一些list_xxx接口是内核提供的通用双向链表操作系列接口,具体实现参考源代码。
几种进程PID与进程描述符的关系
-
类Unix的操作系统把资源管理和调度的不同,一般把程序分为进程和线程。在Linux里,进程和线程实际上是同一个结构体表示,即
task_struct,只是线程的部分资源(如文件系统、打开的文件、虚拟内存等)和他的进程共享。因此在Linux中,线程又被成为“轻量级进程”。 -
在Linux中,每个进程可以创建属于自己的多个线程,其中有一个线程是“领头进程(线程)”。进程ID用
pid字段表示,领头进程ID用tgid字段表示。一个进程被创建出来时,默认其就是领头进程,pid等于tgid,后续由该进程创建出来的线程都附属于领头进程(tgid相同),但是各自都有唯一的pid:struct task_struct { ... pid_t pid; pid_t tgid; ... }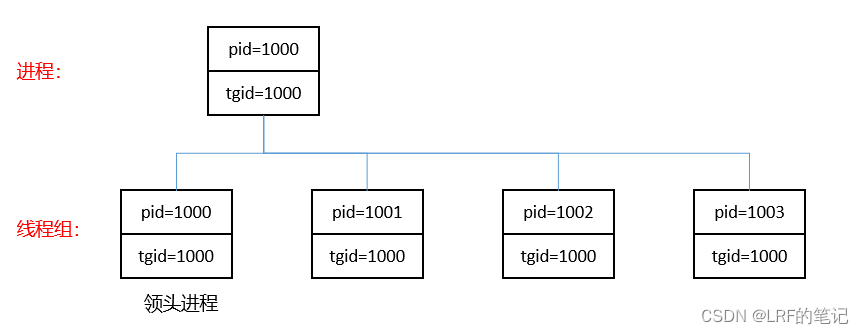
-
Linux中还有进程组和会话的概念,可以参考会话、进程组、线程组以及控制终端这篇博客。简单理解,一条shell命令会创建一个进程组,可能会创建多个进程(例如
top | more),top进程先创建,因此他就是该进程组的领头进程。一台Linux主机可以允许多个用户创建多个会话,每个会话的第一个进程(一般是shell进程)就是该会话的领头进程。 -
基于以上描述,Linux中有四类进程PID:进程的PID、线程组的领头进程PID、进程组的领头进程PID、会话领头进程PID。
-
从进程描述符查找其pid是方便的(
p->pid),但是反过来就不是了。有些时候需要根据pid查找该进程描述符(如kill系统调用),如果遍历进程描述符链表一一查询其pid值就太慢了。因此Linux内核为pid创建了散列(哈希)表,可以通过散列算法直接找出pid对应的进程描述符task_struct。tgid、pgrp、session同理:

实现方式就是定义了一个散列表结构体数组pid_hash,每个元素对应每种PID类型的散列表:struct hlist_node { struct hlist_node *next, **pprev; }; struct hlist_head { struct hlist_node *first; }; enum pid_type { PIDTYPE_PID, PIDTYPE_TGID, PIDTYPE_PGID, PIDTYPE_SID, PIDTYPE_MAX }; static struct hlist_head *pid_hash[PIDTYPE_MAX];散列表中的每个对象指向了
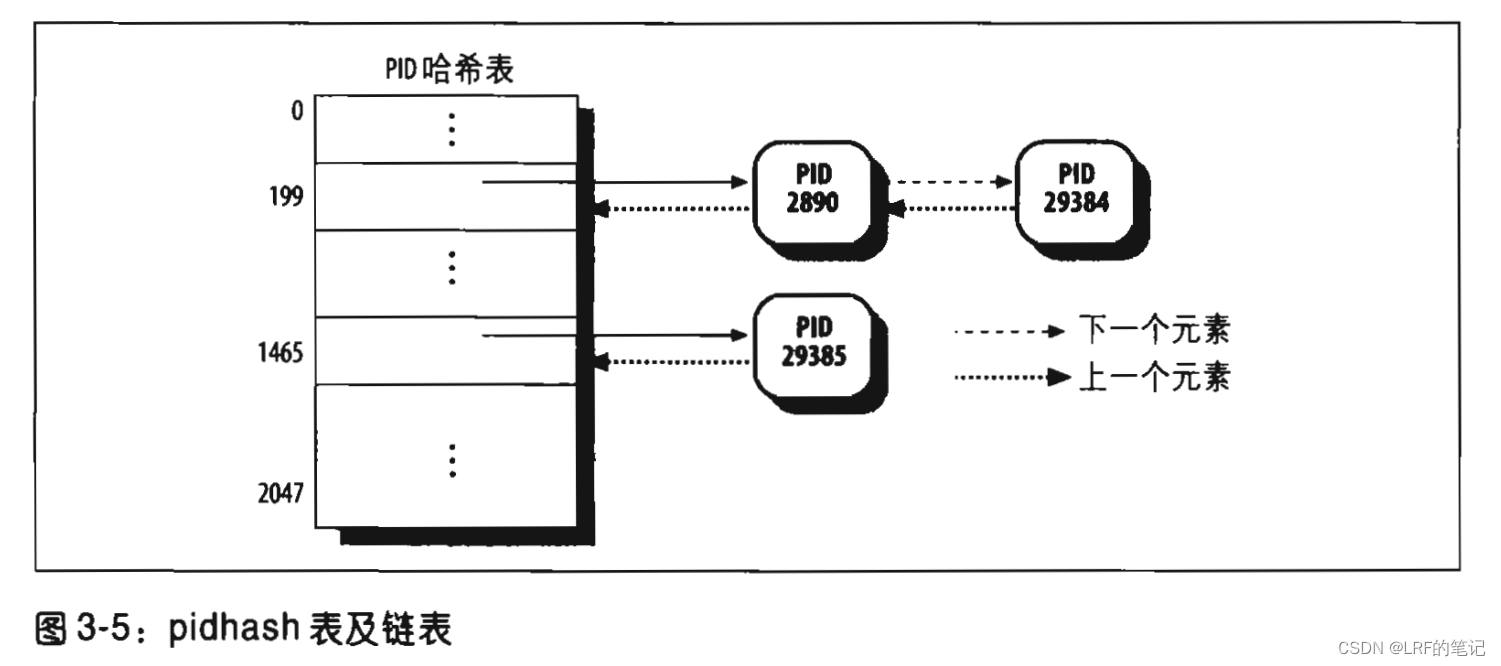
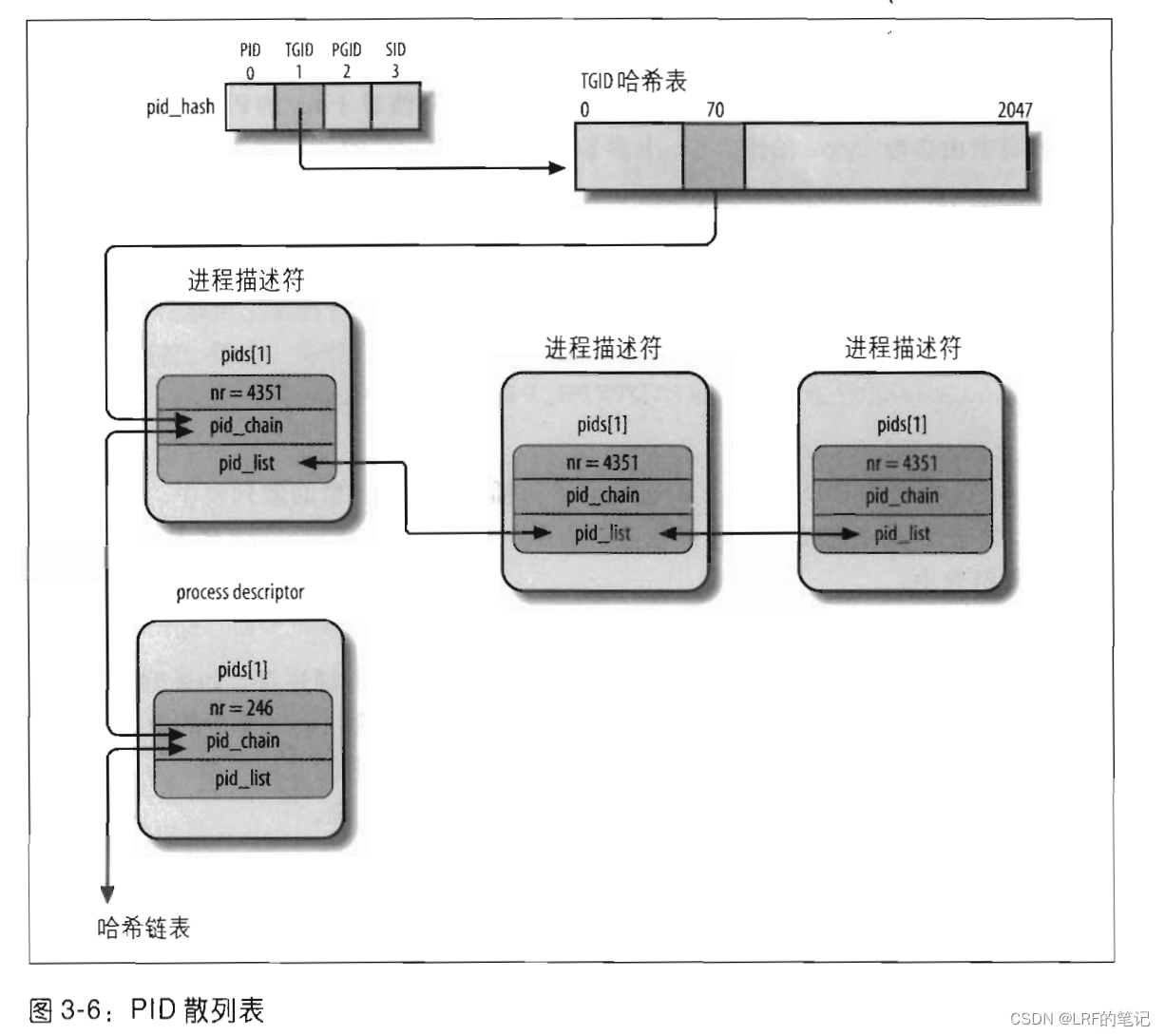
hlist_node类型的元素,那如何使进程描述符和PID散列表关联起来呢?答案是在进程描述符中也定义4种PID,用于散列表指向该地址:struct pid { /* Try to keep pid_chain in the same cacheline as nr for find_pid */ int nr; // pid的数值 struct hlist_node pid_chain; // 链接散列链表的下一个和前一个元素 /* list of pids with the same nr, only one of them is in the hash */ struct list_head pid_list; // 每个pid的进程链表头 }; struct task_struct { ... /* PID/PID hash table linkage. */ struct pid pids[PIDTYPE_MAX]; ... }pid.nr字段很好理解,就是PID值,pid.pid_chain如何理解呢?众所周知,散列表是由哈希函数计算出的哈希值作为检索索引,理论上必然存在哈希碰撞(冲突/colliding),尤其是对于内核内存空间受限的情况下,散列表的表项是有限的。所以如果出现多个同类型PID都散列到同一个索引处,需要把多个PID链起来,这就是pid.pid_chain的作用。
pid.pid_list如何理解呢?前面说了,同一个线程组的进程具有相同的tgid,因此这些进程都会散列到同一个索引,pid.pid_list的作用就是把这些进程链接起来。总体关系图如下:
-
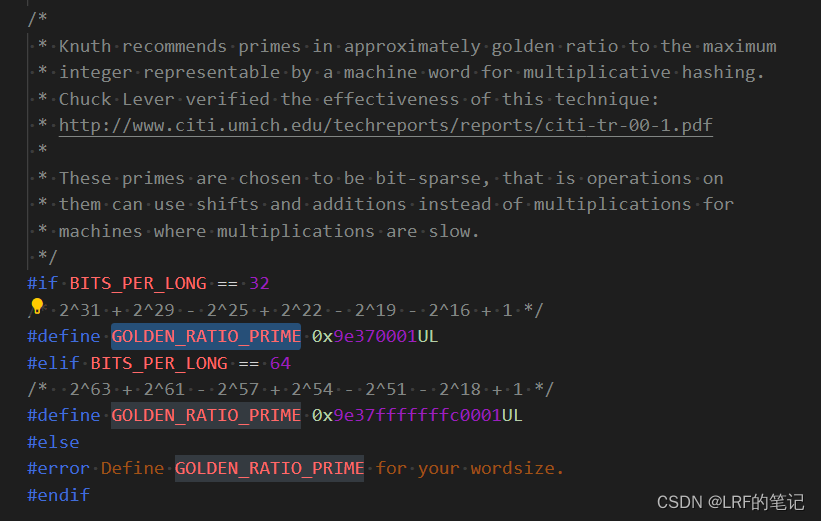
PID的散列函数,Linux内核采用
pid_hashfn接口将PID值散列成一个整型值:static inline unsigned long hash_long(unsigned long val, unsigned int bits) { unsigned long hash = val; #if BITS_PER_LONG == 64 /* Sigh, gcc can't optimise this alone like it does for 32 bits. */ unsigned long n = hash; n <<= 18; hash -= n; n <<= 33; hash -= n; n <<= 3; hash += n; n <<= 3; hash -= n; n <<= 4; hash += n; n <<= 2; hash += n; #else /* On some cpus multiply is faster, on others gcc will do shifts */ hash *= GOLDEN_RATIO_PRIME; #endif /* High bits are more random, so use them. */ return hash >> (BITS_PER_LONG - bits); } #define pid_hashfn(nr) hash_long((unsigned long)nr, pidhash_shift)散列函数的输出值范围和散列表表项占用内存(页框)大小相关,因为不能散列到超出页框的表项。具体的散列算法涉及到大素数的理论知识,其目的是尽可能少的产生碰撞。有兴趣的可以深入了解一下:

-
有PID散列表就肯定有配套的操作,内核提供了如下接口:
// 根据pid类型和pid值查找对应的task task_t *find_task_by_pid_type(int type, int nr) // do-while宏,遍历每个 do_each_task_pid(who, type, task) while_each_task_pid(who, type, task) // 从type类型的PID散列表中查找PID=nr的pid struct pid * fastcall find_pid(enum pid_type type, int nr) // 把task指向的PID=nr的进程描述符插入到type类型的散列表中 int fastcall attach_pid(task_t *task, enum pid_type type, int nr) // 从type类型的PID进程链表中删除task所指向的进程描述符 void fastcall detach_pid(task_t *task, enum pid_type type)
进程等待队列
- 当进程等待某个事件的发生,或某种资源时,内核会把该进程插入到一个等待队列(即睡眠进程),等到进程可以执行时才唤醒他。
- 等待队列是由双向链表实现的(又是双向链表,可见这个数据结构使用很频繁),队列中每个元素都是指向进程描述符的指针,还有标识进程是否是互斥进程的标志、唤醒进程的函数、指向下一个元素的指针。
- 内核定义了一系列函数和宏,作用于等待队列上的操作,使得进程从TASK_RUNNING状态睡眠时如何插入到等待队列, 将处于什么状态(TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE),以及进程从睡眠返回时从等待队列中移除该进程。
进程切换
- 前面说到,CPU可以调度进程,在多个进程之间切换运行。这个特性叫做“进程切换”,或者叫“任务切换”,也叫“上下文切换”。
- 由于进程在执行时,CPU寄存器和内存堆栈里具有该进程需要的数据,为了使进程切换出去后再切换回来依然能够从之前的断点处继续执行,内核需要在进程切换时保存“现场”。
- 保存现场主要分为“硬件上下文切换”和“内核态堆栈切换”。前者的原理是在每个CPU上创建一个TSS(任务状态段)和进程描述符的
thread字段用于保存硬件上下文(寄存器数据)。 switch_to宏完成具体的进程切换动作,同时保存和加载FPU/MMX/XMM寄存器。.
内核线程
- 普通线程可以运行在用户态,也可以运行在内核态。相比普通线程,如果有一些任务不希望和普通线程一样参与调度,可以创建为内核线程,内核线程只运行在内核态,内存地址空间也只利用内核态地址空间。
- 创建内核线程的接口是
kernel_thread,参数与普通线程类似,内部调用do_fork,并且避免复制调用进程的页表(因此运行在内核态,不需要父进程的页表)。
0号进程和1号进程
- 0号进程是所有进程的祖先,所以0号进程又叫“idle进程”或“swapper进程”,是内核线程。
- 0号进程的进程描述符由宏
INIT_TASK静态初始化。 - 1号进程由0号进程创建,又叫“init进程”
进程撤销和终止
- 进程总有终止的时候,从C代码角度,一般的进程终止是通过C库函数
exit()完成的。 - 内核通过2个函数完成进程终止:
exit_group():终止整个线程组(BTW,我在Linux2.6的内核代码里查到的是sys_exit_group函数),内部通过do_group_exit()向线程组中的其他进程发送SIGKILL信号,然后调用do_exit()终止本进程。exit():终止某一个线程,而不管所属线程组的其他线程,内部通过do_exit()完成主要功能。
- 父进程通过
wait系统调用获取子进程的退出状态,然后回收子进程的资源。如果父进程比子进程提前终止,那么子进程就变成了僵尸进程(ZOMBIE),没有父进程回收他的资源,所以内核会把僵尸进程挂载init进程下,这样init进程就可以回收这些僵尸进程的资源了。















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









