







列举常见的设计模式
1、装饰模式
装饰器模式和适配器模式的区别?
对装饰器模式来说,装饰者(decorator)和被装饰者(decoratee)都实现同一个 接口。对代理模式来说,代理类(proxy class)和真实处理的类(real class)都实现同一个接口。他们之间的边界确实比较模糊,两者都是对类的方法进行扩展,具体区别如下:
装饰器模式强调的是增强自身,在被装饰之后你能够在被增强的类上使用增强后的功能。增强后你还是你,只不过能力更强了而已;
代理模式强调要让别人帮你去做一些本身与你业务没有太多关系的职责(记录日志、设置缓存)。代理模式是为了实现对象的控制,因为被代理的对象往往难以直接获得或者是其内部不想暴露出来。
静态代理和动态代理模式的区别?
链接
静态代理和动态代理实现结果其实是一样的,都可以实现代理模式。
动态代理相比静态代理,使用了工厂+反射的方法,可以更好的扩展接口,更符合软工的开闭原则,
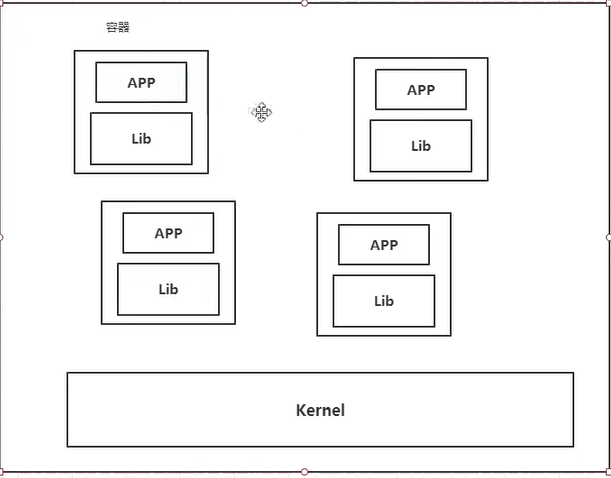
docker的基本原理
docker是一个容器,非常轻便。
镜像:除了基本程序(jar)意外,还搭配环境和中间件和配置(mysql、redis等),开包及用,非常方便。
一个镜像只有4M,而一个虚拟机可能大小有几个g

虚拟化技术缺点:
1、占用资源比较多
2、冗余步骤多
3、启动很慢
容器化技术:
1、不需要构建虚拟系统,直接运行在宿主的主机上,容器没有自己的内核,也没有虚拟硬件,轻量
2、容器间完全隔离,不受影响
linux 常用的命令
- df -h [enter] 检查硬盘空间
- free 检查内存使用情况:

- top 检查线程的cpu负载情况
- jstack命令查看线程内存信息 jstack pid [enter]
- cat /proc/cpuinfo 查看cpu信息
什么是缓存穿透,缓存击穿,缓存雪崩
缓存穿透
查询一个数据库不存在的数据而进行的恶性攻击。由于数据本身并不存在,因此缓存并不会被动写入。当数据流大时,数据库会挂掉。
解决方法:
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方法:
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
解决方法:
使用redis进行缓存,在value值存上过期时间,当发现准备要过期的时候,就去重新更新过期时间。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key); redis.set(key, dbValue); redis.delete(keyMutex);
}
}
});
}
return value;
}
布隆过滤器
链接
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。

主要用于解决缓存穿透的问题
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛。
linux 命令
1、grep 查找命令
grep -n 10 “bug” 查找内容
2、find -n 查找文件,支持模糊查找
4、head 、tail 查看文件的前、后
一致性哈希
单例模式的实现方法
知乎
静态内部类(线程安全)
描述:这种方式达到跟双重校验锁一样的效果,这种方式只适用于静态域的情况,双重校验锁可在实例域需要延迟初始化时使用
//静态内部类
public class InstanceFactory{
private static Instance instance;
private static class getInstance {
private Instance instance= new Instance();
}
public Instcne getInstance() {
return instance;
}
}
双重校验锁(DCL,即double-checked locking)(线程安全)
描述:对懒汉式(线程安全)的优化,采用双锁的机制,安全且在多线程情况下能保持高性能.
public class InstanceFactory{
private volatile static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (Instance.class) {
if (instance == null) {
instance = new Instance();
}
}
}
return instance;
}
}
Mavven的依赖传递和依赖原则
文章
1、依赖传递
scope 控制 ,scope = compile则可以实现依赖的传递
A.jar依赖于B.jar,而B.jar依赖于C.jar,若让A依赖于C

2、依赖原则
- 路径最短优先原则
- 路径长度相同: 1、同一个pom.xml文件,优先原则
2、不同pom.xml文件,覆盖原则
生成这和消费者模型
链接
使用阻塞队列















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









