






第一章
1.1什么是数据结构
数据结构就是指计算机内部数据的组织形式和存储方法,主要包括:线性结构,树,图。
线性结构:由n个元素构成的有限序列。就是有限的一维数表。具体的讲线性结构包括:顺序表、链表、栈、队列等基本形式。顺序表和链表是从数据的储存形式上区分的,栈和队列是从逻辑功能上区分的。栈和队列是基于顺序表和链表的,他们由顺序表和链表构成。
树:“一对多”
图:“多对多”
1.2顺序表
顺序表的特征:
1.唯一的表名
2.内存单元连续储存
3.数据顺序存放
1.2.1定义顺序表
静态定义(与定义数组类似)
#define maxsize 100
Elemtype sqlist[Maxsize];//Elemtype顺序表的类型,可以是int char
int len;//定义顺序表的长度,方便对顺序表进行操作
动态定义
#define maxsize 100
typedef struct{
Elemtype *elem;
int length;
int listsize;
}sqlist;//定义类型为sqlist的结构体,其成员包括:顺序表的首地址,顺序表中表的长度,顺序表的储存空间容量;
void initsqlist(sqlist *L){//initsqlist()的参数是sqlist类型的指针变量,因此可以直接在函数中对顺序表进行操作
L->elem=(int *)malloc(maxsize*sizeof(Elemtype));
if(!L->elem) exit(0);
L->length=0;//将L->length置为0,表明刚刚生成一张顺序表,此时表内尚无内容
L->listsize=maxsize;//将L->listsize置为maxsize,表明该顺序表占据的内存空间大小为maxsize(以sizeof(Elemtype)为单位)
}
结构体
link
函数malloc()的用法:
link
1.2.2向顺序表中插入元素
基于静态顺序表
void Inserelem(Elemtype sqlist[],int &n,int i,Elemtype item){//向顺序表sqlist中第i个元素插入itme,该顺序表原长度为n
int t;
if(n==maxsize||i<1||i>n-1)
exit(0);//非法插入
for(t=n-1;t>=i-1;t--)
sqlist[t+1]=sqlist[t];//位置i-1与位置i-1以后的元素顺序向后移一位
sqlist[i-1]=item;//位置i-1插入item
n=n+1;//表长加1
}
基于动态顺序表
void Inserelem(sqlist *L,int i,Elemtype item){//向顺序表L中第i个位置上插入元素item
Elemtype *base,*insertptr,*p;
if(i<1||i>L->length+1)exit(0);//非法插入
if(L->length>=L->listsize)
{
base=(Elemtype*)realloc(L->elem,(L->listsize+10)*sizeof(Elemtype));//重新追加空间
L->elem=base;//更新内存基地址
L->listsize=L->listsize+100;//储存空间增大100单元
}
//由于顺序表是建立在动态储存空间的,因此可以随时扩充,故向表尾插入元素时,如果顺序表已满,可以追加一段内存空间
insertptr=&(L->elem[i-1]);//insertptr为插入位置
for(p=&(L->elem[L->len-1]);p>=insertptr;p--)
{
*(p+1)=*p;//将i-1以后的元素顺序后移一个元素的位置
}
*insertptr=item;//在第i个位置上插入item
L->length++;表长加1
}
函数realloc()的用法:
link
1.2.2从顺序表中删除元素
基于静态顺序表
void Delelem(Elemtype sqlist[],int &n,int i){//将顺序表sqlist中第i个元素删除,原顺序表的长度为n
int t;
if(i<1||i>n-1)
exit(0);//非法删除
for(t=i-1;t<=n-1;t++)
sqlist[t]=sqlist[t+1];//位置i-1与位置i-1以后的元素顺序向前移一位
sqlist[i-1]=item;
n--;//表长减1
}
基于动态顺序表
void Delelem(sqlist *L,int i){//向顺序表L中第i个位置上删除元素
Elemtype *p;
if(i<1||i>L->length+1)exit(0);//非法删除
for(p=&(L->elem[i-1]);p<=L->elem+L->length-1;p++)
{
*p=*(p+1);//将i-1以后的元素顺序后移一个元素的位置
}
L->length--;表长加1
}
1.3链表
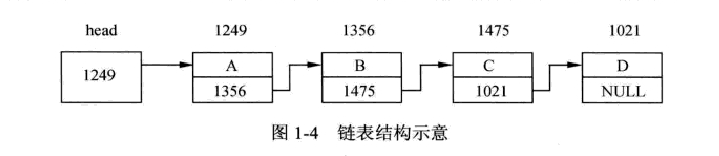
链表的特征:
1.每个节点都有两部分:a.数据域:用来存放数据元素本身的信息、b.指针域:存放后继节点的位置。
2.链表在逻辑上连续,物理上不一定连续存储。
3.只要获得链表的头结点,就可以通过指针遍历整条链表。
C语言描述:
typedef struct node
{
Elemtype data;//数据域
struct node *next;//指针域
}LNode,*LinkList;
这种自定义的方式将struct node定义为LNode类型。这里*LinkList是指向LNode数据类型的指针型定义,也就是说:
LNode *L;
和
LinkList L;
是等价的。它们都定义了一个指向LNode类型的指针。
关键字typedef的用法:
link
1.3.1如何创建链表
尾插法创建链表
LinkList *Createlinklist(int n){//创建一条长度为n的链表
int i;
LinkList p,r,list=NULL;//p指向最后一个节点,r指向一般节点(当前生成的节点),list指向头结点
for(i=0;i<n;i++){
r=(LinkList)malloc(sizeof(Lnode));
r->date=Get(n);//Get()函数用来产生数据域的值
r->next=NULL;
if(list==NULL)//如果list为空,说明当前生成的节点是第一个节点,即头节点
list=r;
else
p->next=r;
p=r;//将r的值赋给p,目的是让p再次指向最后一个节点,以便生成下一个节点,即保证p永远指向最后一个节点
}
return list;
}
头插法创建链表
link
1.3.2向链表中插入节点

在指针q指向的节点后面插入节点的步骤:
1.创建一个新节点用指针p指向该节点;
2.将q指向节点的next域内容赋值给p指向节点的next域;
3.将p的值赋给q的next域。
代码描述如下:
void insertList(LinkList *list,LinkList q,ElemType e){
LinkList p;
p=(LinkList)malloc(sizeof(LNode));//生成一个新节点,由p指向它
p->date=e;//新节点的数据域赋值e
p->next=NULL;
if(*list==NULL){//当链表为空时
*list=p;
}
else
{
p->next=q->next;//将q指向的节点的指针域赋给p指向节点的指针域
q->next=p;//将p赋值给q指向节点的指针域
}
}
caution
函数insertList()的参数中有一个LinkList *list,他是指向LinkList类型的指针变量,相当于指向LNode类型的指针的指针。这是因为在函数中要对list,也就是表头指针进行修改,而调用该函数时,实参时&list,而不是list。因此必须采用指针参数传递的办法,否则无法在被调函数中修改主函数中定义的变量的内容。
1.3.3从链表中删除结点
1.q所指向的是链表的第一个节点。只需将q所指结点的指针域next的值赋值给头指针list,让list指向第二个节点,在释放掉q所指结点即可。

2.当q所指向的前驱结点的指针已知时(假设为r),只需将q所指结点的指针域next的值赋给r的指针域next,再释放掉q所指结点即可。
3.当q所指向的前驱结点的指针未知。
代码描述如下:
void deLink(LinkList *list,LinkList r,LinkList q)
{
if(q==*list)
*list=q->next;//删除链表的第一种情形
else
r->next=q->next;//删除链表的第二种情形
free(q);
}
当q所指向的结点的前驱结点未知时,需要先通过链表头指针list遍历链表,找到q的前驱结点的指针,将该指针赋值给指针变量r,再按照第二种情形去做即可。
代码描述如下:
void deLink(LinkList *list,LinkList q){
LinkList r;
if(*list==q){
*list=q->next;
free(q);
}
else{
for(r=*list;r->next==q;r=r->next);//遍历链表,找到q的前驱结点的指针
r->next=q->next;
free(q);
}
}
1.3.4销毁一个链表
从首节点开始销毁:
void destroyLinkList(LinkList *list){
LinkList q,p;//p指向当前要销毁的结点,q用来保存每次销毁后的链表。
p=*list;
while(p){//判断只要p不为空(NULL),就将p指向下个结点的指针赋给q,并应用函数free()释放掉p所指向的结点,p再指向下一个结点。
q=p->next;
free(p);
p=q;
}
*list=NULL;//防止list变为野指针。链表再内存也被完全的释放掉了
}
free()的用法
link
1.4 栈
栈就是一个线性表,具有以下特点:
1.先进后出;
2.栈的操作只能在栈顶也就是表尾进行。

顺序栈的代码表述:
typedef struct {
Elemtype *base;//指向栈底,Elemtype 是栈内储存的数据类型,可以是int char 等
Elemtype *top;//指向栈顶,对栈进行操作
int stacksize;//栈的容量
} sqStack;
1.4.1 栈的初始化
#define STACK_SIZE 100
void Initstack(sqStack *s)
{
s->base=(sqStack *)malloc(STACK_SIZE*sizeof(sqStack));//为栈分配STACK_SIZE大小的空间
if(s->base==NULL)exit(0);//分配失败
s->top=s->base;//刚创建时由于是空栈,所以栈顶就是栈底
s->stacksize=STACK_SIZE ;
}
初始化后栈的示意图如下:

1.4.2 入栈操作
void push(sqStack *s,elem e)
{
if(s->top-s->base==s->stacksize){//判断是否栈满,若栈满,则追加空间
s->base=(sqStack *)realloc(s->base,(s->stacksize+10)*sizeof(sqStack));
if(s->base==NULL) exit(0);
s->top=s->base+s->stacksize;//s->top指针移动到s->base+s->stacksize的位置上
s->stacksize=s->stacksize+10;//栈容量更新;
}
*(s->top)=e;
s->top++;//top始终指向栈顶元素的上一个空间;
}
1.4.3 出栈操作
void pop(sqStack *s,elemtype *e)
{
if(s->top==s->base) exit(0);//若为空栈则返回
else{//top指针下移,然后将其所指的内容取出
s->top--;
*e=*s->top;
}
}
1.4.3 其他操作
清空:
void Clearstack(sqStack *s)
{
s->top=s->base;
}
tip:清空一个栈只是清空了栈的内容,但是栈的物理空间并未销毁
销毁:
void Destroystack(sqStack *s)
{
int i,len;
len=s->stacksize;
for(i=0;i<len;i++)
{
free(s->base);
s->base++;
}
s->top=s->base=NULL;
s->stacksize=0;
}
计算容量
int Stacklen(sqStack *s)
{
return(s.top-s.base);
}
1.5 队列
1.一种先进先出的线性表;
2.只允许数据在队列的队尾进入,在队列的队头取出。
只要掌握了队列的队头指针和队尾指针就可以对队列进行各种操作。

基于链表的队列称为链队列,代码表述如下:
typedef struct QNode{
Elemtype date;
Qnode *next;
}QNode,*Queueptr;
typedef struct{
Queueptr front;//指向链表的头部
Queueptr rear;//指向链表的尾部
}LinkQueue;
1.5.1 初始化一个队列
有两个任务:
1.创建一个头结点;
2.将队列的头指针和尾指针都指向这个结点。
代码表述如下:
void InitQueue(LinkQueue *s)
{
s->rear=s->front=(QNode *)malloc(sizeof(Qnode));
if(s->front==NULL)exit(0);
s->front->next=NULL;//将头结点的指针域置空
}
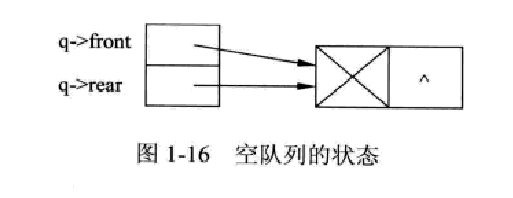
1.5.2 入队列操作
void InsertQueue(LinkQueue *s,Elemtype e)
{
Queueptr p;
p=(Queueptr)malloc(sizeof(QNode));//创建一个指向新节点的Queueptr型指针
if(s->head==NULL) exit(0);
p->next=NULL;
p->date=e;//将数据加入到链表新节点的数据域
s->rear->next=p;//向链表的尾部添加新结点
s->rear=p;//队尾指针指向新节点
}
过程如下图所示:

1.5.3 出队列操作
每当有数据从队列种移出时,队头结点不会改变,但是队头结点的next指针会后移,当队列中只有一个元素时,取出数据后,队尾指针也将移到队头。代码描述如下:
void DeQueue(LinkQueue *s,Elemtype *e)//将队列s的头元素取出,将结果存入e
{
Queueptr p=NULL;
if(s->front==s->rear) exit(0);
p=s->front->next;
*e=p->date;
s->front->=p->next;
if(p==s->rear) s->rear=s->front;//若队列种只有一个元素,则取出这个元素后队列将变成空队列,于是将队尾指针移动到队头
}


1.5.4 销毁队列操作
void DestroyQueue(LinkQueue *s)
{
while(s->front){
s->rear=s->front->next;
free(s->front);
s->front=s->rear;
}
}
1.5.5 循环队列
循环队列实际上是一个线性表,具有固定的储存空间。
与一般的队列相同的是:元素必须从队尾入队列,必须从队头出队列;
与一般队列不同的是:循环队列的头指针和尾指针随着队列元素的出入不断地发生变化(一般队列是头指针不发生变化,头指针的next指针和尾指针前一个元素的next指针发生变化)
循环队列的逻辑结构如下:

这里约定:循环队列的队头指针始终指向第一个元素,队尾指针始终指向最后一个元素的下一个空间,逻辑上就是一个首尾连接的环形缓冲区
1.5.6 循环队列的实现
逻辑上用取模的运算结果,无论是入队列的front+1操作还是出队列的rear+1操作,实际上都是模加操作,这样才能在连续的线性空间中模拟出逻辑上循环的队列;代码描述入下:
- 定义一个循环队列
#define maxsize 100
typedef struct{
Elemtype *base;
int front;
int rear;
}cycleQueeue;
- 初始化一个循环队列
void Initqueue(cycleQueeue *s)
{
s->base=(Elemtype *)malloc(maxsize*sizeof(Elemtype ));
if(q->base==NULL)exit(0);
s->front=s->rear=0;
}
- 向循环队列中加元素
void Insertqueue(cycleQueeue *s,Elemtype e)
{
if((s->rear+1)%maxsize==s->front)exit(0);
s->base[s->rear]=e;
s->rear=(s->rear+1)%maxsize;
}
- 向循环队列中删除元素
void Deletqueue(cycleQueeue *s,Elemtype *e)
{
if(s->front==s->rear) return;
*e=s->base[s->front];
s->front=(s->front+1)%maxsize;
}
1.6 树结构
树结构采用的是非线性结构组织数据
树的定义:树由n个结点组成的有穷集合,在任意一颗非空树中:
1.有且仅有一个根节点;
2.当n>1时,其余结点分为m(m>0)个有限集,其中每个集合本身又是一棵树,称为根的子树。

1.6.1 树结构的计算机储存形式
树在计算机中用多重链表储存,代码表述如下:
typedef struct node{
datetype date;//结点的数据域,用来储存数据;
struct node *childnode[10];//结点的指针域,为一个指针数组,数组里的每一个指针都指向孩子结点
}

1.6.2 二叉树的定义
二叉树是这样的树结构:它或者为空,或者由根结点加上互不交叉的称为左子树和右子树的二叉树组成,链式储存的二叉树结点的储存结构如下:

代码表述如下:
typedef struct BiTNode
{
dateType date;//结点的数据域;
struct BiTNode *rchild,*lchild;//指向左孩子和右孩子
}BiTNode,*bitree;
其中:
BiTNode *t;
等价于
bitree t;
1.6.3 二叉树的遍历
- 先序遍历:1.访问根节点 2.先序遍历左子树 3.先序遍历右子树
void Preordertraverse(bitree T)
{
if(T)//递归结束条件,T为空
{
visit(T);//访问根节点
Preordertraverse(T->lchild);//先序遍历左子树
Preordertraverse(T->rchild);//先序遍历右子树
}
}
- 中序遍历:1.中序遍历左子树 2.访问根节点 3.中序遍历右子树
void Inordertraverse(bitree T)
{
if(T)//递归结束条件,T为空
{
Inordertraverse(T->lchild);//中序遍历左子树
visit(T);//访问根节点
Inordertraverse(T->rchild);//中序遍历右子树
}
}
- 后序遍历:1.后序遍历左子树 2.后序遍历右子树 3.访问根节点
void Posordertraverse(bitree T)
{
if(T)//递归结束条件,T为空
{
Posordertraverse(T->lchild);//后序遍历左子树
Posordertraverse(T->rchild);//后序遍历右子树
visit(T);//访问根节点
}
}
这里面visit()函数的作用要具体而定;
1.6.4 创建二叉树
用先序遍历创建一棵二叉树,代码描述如下:
typedef struct BiTNode
{
char date;
struct BiTNode *lchild,*rchild;
}BiTNode,*BiTree;
void CreatBitree(BiTree *t)
{
char e;
scanf("%c",&e);
if(e==' ')*t=NULL;
else
{
*t=(BiTree)malloc(sizeof(BiTNode));
*t->date=e;
CreatBitree(&(*t->lchild));
CreatBitree(&(*t->rchild));
}
}

若创建上面的二叉树,则需要输入的内容为:ABC@@D@@E@F@@。
1.7 图结构
图是由非空有限集合V(由N个顶点构成)和边的集合E构成(顶点之间的关系),若图G的每一条边都没有方向,则称为无向图,若图G的每一条边都有方向,则称为有向图。

1.7.1 邻接表的定义
图的邻接表储存方式是顺序数组和链表相结合的储存方式:顺序数组用来储存顶点信息,链表用来储存边的信息,对图中的每一个顶点建立一个链表,每个链表前面设置一个结点称为顶点结点。顶点结点的结构如下:

vertex域存放顶点的数据信息,next域存放连接顶点的第一条边。边结点的结构如下:
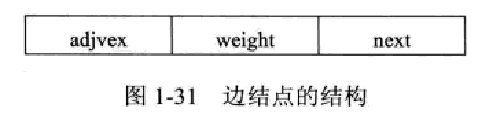
adjvex域用来存放该边的另一顶点在数组中的位置(数组下标);weight用来存放该边的权重,对于无权重的图,该项省略;next将第i个链表的所有边结点连接成一个链表,最后一个边结点的next域指向NULL。

无向图的邻接表储存形式如下:

代码描述如下:
#define maxvertex 20
typedef struct arcnode//定义边结点
{
int adjvex;//边在图中的位置;
struct arcnode *next ;//指向下一条边
infotype *weight;//边的权重,可省略
}arcnode;
typedef struct vnode//定义顶点结点
{
elemtype date;//顶点中存放的数据
arcnode *firstarc;//指向连接顶点的第一条边
}vnode;
vnode G[maxvertex ];//定义vnode类型的数组G,它是储存图的容器
1.7.2 图的创建
应先画出图的逻辑结构,以下图为例:

上图的邻接表储存形式为:

创建一个图的步骤为:
(1):创建顶点结点:即创建储存表中顶点的顺序表;
(2):创建边结点:即创建储存表中的单链表;
代码描述如下:
CreatGraph(int n,vnode G[])
{
arcnode *p,*q;
int i,e;
for(i=0;i<n;i++)
{
G[i].date=Getdate();
G[i].firstarc=NULL;
}
for(i=0;i<n;i++)
{
printf("Creat the edges for the %dth vertex:\n",i);
scanf("%d",&e);
while(e!=-1)
{
p=(arcnode *)malloc(sizeof(arcnode));
p->adjvex=e;
p->next=NULL;
if(G[i].firstarc=NULL)G[i].firstarc=p;
q->next=p;
q=p;
scanf("%d",&e);
}
}
}
1.7.3 图的遍历(1)——深度优先搜索
void DFS(vnode G[],int v)
{
int w;//w为标志位
visit(v);//访问v结点
visit[v]=1;//将数组visit[]v结点对应的位置1,表示该节点已经被访问
w=FirstAdj(G,v);//查询v结点的第一个邻接点,w中返回的是第一个邻接点在图中的位置,若v无临界点则返回-1
while(w!=-1)
{
if(visit[w]==0)
DFS(G[],w);//若visit[w]为0表示w结点未被访问过,否则递归访问其他结点
w=NextAdj(v);//查询v结点的下一个邻接点,若没有下一个邻接点,则返回-1
}
}
void Travel_DFS(vnode G[],int visit[];int n)
{
int i;
for(i=0;i<n;i++)
visit[i]=0;//visit[]中记录的是第i个结点有没有被访问的情况,刚开始的时候visit[]中的元素全置0,表示所有的结点都未被访问过
for(i=0;i<n;i++)
if(visit[v]==0)
DFS(G[],i);//若第i个结点对应的元素为0,则递归访问i个结点
}

用上述递归遍历图1-37非连通图的过程如下:
假设以v0为遍历的起点,访问标志数组初始值为visit[5]={0,0,0,0,0}
1.访问v0结点,将数组visit[]中v0结点对应的位置置1;
2.查询v0结点的第一个邻接点v1,w=1;
3.数组visit[]中v10成立,因为它没有被访问过;接下来执行函数DFS(G[],1),即递归查询;
3.1访问v1结点,将数组visit[]中v1结点对应的位置置1;
3.2查询v1结点的第一个邻接点v2,w=2;
3.3数组visit[]中v20成立,因为它没有被访问过;接下来执行函数DFS(G[],2),即递归查询;
3.3.1访问v2结点,将数组中v2结点对应的位置置1;
3.3.2查询v2结点的第一个邻接点v0,w=0;
3.3.3数组visit[]中v0==0不成立,因为它已经被访问过;
3.3.4查询v2结点的下一个邻接点,w=-1;因为都被访问过;
3.4查询v1结点的下一个邻接点,w=-1;因为都被访问过;
4.查询v0结点的下一个邻接点,w=-1,因为都被访问过;
DFS()结束。
1.7.4 图的遍历(2)——广度优先搜索
void BFS(VNode G[],int v)
{
int w;
visit(v);//访问结点v
visited[v]=1;//结点v对应的数组位置置1
EnQueue(q,v);//结点v入队列
while(EmptyQ(q))//只要队列不为空,则进行以下的操作
{
DeQueue(&q,&v);//出队列,元素由v返回
w=FirstAdj(G,v);//搜索v的第一个邻接点,若没有邻接点则返回-1
while(W!=-1)
{
if(visited[w]==0)
{
visit(w);
EnQueue(&q,&w);//若visited[w]==0,说明结点w未被访问过,则执行访问结点w,并将结点w入队列
}
visited[w]=1;//访问结点w后将visited[]数组w对应位置1
w=NextAdj(G,v);
}
}
}
void Travel_BFS(VNode G[],int visited[], int n)//主函数
{
int i;
for(i=0;i<n;i++)
{
visited[i]=0;
}
for(i=0;i<n;i++)
if(visited==0)
BFS(G[],i);
}

遍历的步骤如下:
1.访问结点v0,结点v0入队列,此时队列为{v0},将顶点v0对应的访问标记置1,此时visited[]数组为{1,0,0,0,0};
2.结点v0出队列,元素由v返回,找到v0的第一个邻接点v1,访问v1,v1入队列,此时队列为{v1},将顶点v0对应的访问标记置1,此时visited[]数组为{1,1,0,0,0};找到v0的下一个邻接点v2;
3.访问v2,v2入队列,此时队列为{v1,v2},将顶点v2对应的访问标记置1,此时visited[]数组为{1,1,1,0,0};下一次执行NextAdj()时,将返回-1;
4.结点v1出队列,此时队列为{v2},找到v1的第一个邻接点v3,访问v3,v3入队列,此时队列为{v2,v3},将顶点v3对应的访问标记置1,此时visited[]数组为{1,1,1,1,0};找到v1的下一个邻接点v4;
5.访问v4,v4入队列,此时队列为{v2,v3,v4},将顶点v4对应的访问标记置1,此时visited[]数组为{1,1,1,1,1};下一次执行NextAdj()时,将返回-1;
6.结点v2出队列,此时队列为{v3,v4},由于v2没有邻接点,执行FirstAdj时将返回-1;
7.结点v3出队列,此时队列为{v4},由于v3没有邻接点,执行FirstAdj时将返回-1;
8.结点v4出队列,此时队列为空,由于v4没有邻接点,执行FirstAdj时将返回-1
BFS结束;
其中FirstAdj()函数的代码表述如下:(该函数的功能是返回顶点v的第一个邻接点在数组G中的下标。如果该顶点无邻接点,则返回-1)
int FirstAdj(VNode G[],int v)
{
if(G[v].firstarc->NULL) return -1;
else return (G[v].firstarc)->adjvex;
}
NextAdj()函数的代码表述如下:
int NextAdj(VNode G[],int v)
{
arcnode *p;
p=G[v].firstarc;
while(p!=NULL)
{
if(visited[p->adjvex]) p=p->next;//该顶点已被访问,继续向下查找
else return p->adjvex;//返回v的下一个邻接点在数组G中的下标
}
return -1;//已经没有下一个邻接点
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









