







为什么用ArcFace
前一篇文章已经提到了问什么不能直接用softmax loss做损失,是因为类与类之间交界处不容易分开,而center loss能把他分开是因为缩小了类内距,就是给每一个中心点,让每个类中的特征点无限向中心点靠拢。缩小类内距的同时,间接缩小了类间距。而ArcFace是直接缩小了类间距。
下面是我用mnist数字十分类做的直接用softmax loss和arcFace做的效果图:


第一个图是直接用softmax loss做的,很明显在交接处没有分开,第二个图是arcface做的效果,每一个类都清晰可见。
arcFace推导过程。
因为arcFace是对softmax loss的改进,先看softmax loss。
softmax loss:
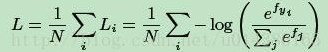
N是样本的数量,i代表第i个样本,j代表第j个类别,fyi代表着第i个样本所属的类别的分数
fyi是全连接层的输出,代表着每一个类别的分数,
每一个分数即为权重W和特征向量X的内积
每个样本的softmax值即为:
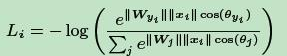
由于w是通过损失反向传播不断更新的,x是随着前面的w变化而变化的,所以要改进softmax需要只能改cos(θ)或者θ,而论文作者实验证明改θ比改cos(θ)效果更好,所以有了Arcface。
Arcface公式:

arcface限制条件:

mnist数据集实现arcface(Pytorch):
import matplotlib.pyplot as plt
import numpy as np
import os
import torch.nn.functional as F
class Arcsoftmax(nn.Module):
def __init__(self, feature_num, cls_num):
super(Arcsoftmax, self).__init__()
self.w = nn.Parameter(torch.randn(feature_num, cls_num).cuda())
self.func = nn.Softmax()
def forward(self, x, s, m):
x_norm = F.normalize(x, dim=1)
w_norm = F.normalize(self.w, dim=0)
cosa = torch.matmul(x_norm, w_norm)/10
a = torch.acos(cosa)
arcsoftmax = torch.exp(
s * torch.cos(a + m) * 10) / (torch.sum(torch.exp(s * cosa * 10), dim=1, keepdim=True) - torch.exp(
s * cosa * 10) + torch.exp(s * torch.cos(a + m) * 10))
# arcsoftmax = torch.exp(s*torch.cos(a+m)*10) / (torch.sum(torch.exp(s*cosa*10
# ), dim=1, keepdim=True) - torch.exp(s*cosa*10) + torch.exp(s*torch.cos(a+m) * 10))
return arcsoftmax
class ClsNet(nn.Module):
def __init__(self):
super().__init__()
self.conv_layer = nn.Sequential(nn.Conv2d(1, 32, 3), nn.BatchNorm2d(32), nn.PReLU(),
nn.Conv2d(32, 64, 3), nn.BatchNorm2d(64), nn.PReLU(),
nn.MaxPool2d(3, 2))
self.feature_layer = nn.Sequential(nn.Linear(11 * 11 * 64, 256), nn.BatchNorm1d(256), nn.PReLU(),
nn.Linear(256, 128), nn.BatchNorm1d(128), nn.PReLU(),
nn.Linear(128, 2), nn.PReLU())
self.arcsoftmax = Arcsoftmax(2, 10)
self.loss_fn = nn.NLLLoss()
def forward(self, x, s, m):
conv = self.conv_layer(x)
conv = conv.reshape(x.size(0), -1)
feature = self.feature_layer(conv)
out = self.arcsoftmax(feature, s, m)
out = torch.log(out)
print(out.shape)
return feature, out
def get_loss(self, out, ys):
return self.loss_fn(out, ys)
if __name__ == '__main__':
train_data = datasets.MNIST(
root='mnist',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_data = torchvision.datasets.MNIST(
root='mnist',
train=False,
transform = torchvision.transforms.ToTensor(),
download=False
)
train = DataLoader(dataset=train_data, batch_size=1024, shuffle=True, drop_last= True)
test = DataLoader(dataset=test_data, batch_size=1024, shuffle=True)
# transform = transforms.Compose([
# transforms.Resize(28, 28),
# transforms.ToTensor(),
# transforms.Normalize((0.5,), (0.5,)),
net = ClsNet().cuda()
# net = net.to(device)
path = r'params/weightnet2.pt'
if os.path.exists(path):
net.load_state_dict(torch.load(path))
net.eval()
print('load susseful')
else:
print('load fail')
# epoch = 1024
# optimism = optim.SGD(net.parameters(), lr=1e-3)
optimism = optim.Adam(net.parameters(), lr=0.0005)
# scheduler = lr_scheduler.StepLR(optimism, 10, gamma=0.8)
# optimizer = optim.SGD(net.parameters(), weight_decay=0.0005, lr=0.001, momentum=0.9)
# scheduler = lr_scheduler.StepLR(optimizer, 20, gamma=0.8)
# optimizercenter = optim.SGD(Centerloss.parameters(), lr=0.5)
losses = []
# In[]
c = ['#ff0000', '#ffff00', '#00ff00', '#00ffff', '#0000ff',
'#ff00ff', '#990000', '#999900', '#009900', '#009999']
epoch = 10000
d = 0
# fig, ax = plt.subplots()
for i in range(epoch):
# scheduler.step()
print('epoch: {}'.format(i))
print(len(train))
tar = []
out = []
for j, (input, target) in enumerate(train):
input = input.cuda()
target = target.cuda()
feature, output = net(input, 1, 0.01)
loss = net.get_loss(output, target)
# label = torch.argmax(output, dim=1) # 选出最大值的索引作为标签
# 清空梯度 反向传播 更新梯度
optimism.zero_grad()
loss.backward()
optimism.step()
feature = feature.cpu().detach().numpy()
# print(output)
target = target.cpu().detach()
# print(target)
out.extend(feature)
tar.extend(target)
print('[epochs - {} - {} / {}] loss: {} '.format(
i, j, len(train), loss.float()))
outstack = np.stack(out)
tarstack = torch.stack(tar)
# plt.cla()
plt.ion()
if j == 3:
d += 1
for m in range(10):
index = torch.tensor(torch.nonzero(tarstack == m))
# print(index)
plt.scatter(outstack[:, 0][index[:, 0]], outstack[:, 1][index[:, 0]], c=c[m], marker='.')
plt.show()
plt.pause(1)
plt.savefig('picture1.2/{0}.jpg'.format(d))
print('save sussece')
# plt.ioff()
# plt.clf()
plt.close()
torch.save(net.state_dict(), r'params/weightnet2.pt')















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









