







模型的评估和选择
1、精度
分类错误的样本数量占样本总数的比例为‘错误率’,若有m个样本,其中a个样本被错误分类,则错误率为
E
=
m
a
E=\frac{m}{a}
E=am
,相应的‘精度’就等于1-E。一般来说,在训练集上的误差称为训练误差,在新样本上的误差称为泛化误差。我们最终的目的是得到一个泛化误差较低的学习器,然而在很多情况下,我们并不知道新样本。因此,我们只能努力降低训练误差,同时提高模型的泛化能力。
2、过拟合与欠拟合
我们努力降低学习器的训练误差,因此,学习器会尽可能挖掘出训练样本的内在规律。有时候,学习器把训练样本自身特有的结构当做了一般规律,当遇到新样本时就不能做出正确的判断。这种情况就称为过拟合,也就是说学习器过于强大,将样本自身的特有情况挖掘出来作为判断的依据。欠拟合则相反,是由于只学习到训练样本的一部分规律,在遇到新样本时判断错误。
一般来说,复杂的模型会具有更强的学习力,意味着具有更高的过拟合风险。理想状态下,我们应该选择泛化误差最小的模型,但是由于我们无法直接观察到泛化误差,而训练误差又因为无法反映出是否过拟合,所以不是一个合适的评价标准。因此,模型选择必须有一套合适的评估方法。

3、评估方法
比较好的一种办法就是将已有的数据集拆分成训练集和测试集,要求是训练集和测试集互斥。
3.1留出法
直接将数据集D分为训练集S和测试集T,在S集上训练模型,然后使用T进行评估。需要注意的地方:
- 训练集和测试集尽可能保持数据分布的一致。分类任务中,训练集和测试集的类别比例应该保持相似。如果训练集中有500个正样本、1000个负样本,则测试集也最好拥有一样的正负样本比例。
- 不同的训练集和测试集会产生不同的模型评估结果,因此,不能把一次划分的结果作为模型评估的结果,一般采用多次的模型划分后训练模型评估模型,最后取平均值作为评估结果。
- 所用于训练的训练集数量较少,不能完全代表数据集D的特征,则学习器所学到的规律不能完全表达出D的规律。若用于测试的训练集数量少,则测试结果不具有参考性。因此,训练集和测试集的划分比例要控制好,要视数据集的大小而定,一般将数据集的 2 3 \frac{2}{3} 32~ 4 5 \frac{4}{5} 54作为训练集,剩下的作为测试集。
3.2交叉验证法
将数据集D以分层抽样分为 k k k个互斥的子集,使用其中的 k − 1 k-1 k−1个子集训练模型,剩下的1个作为测试集,循环使用则可以训练 k k k次,最终返回 k k k次测试的均值。

假定有m个样本,留其中的1个样本作为测试集,这样的交叉验证称为‘留一法’,优点在于评估的结果较为准确,缺点在于数据集较大的时候计算开销巨大,而且评估也未必一定比其他的方法准确。
3.3自助法
给定包含m个样本集的数据集
D
D
D,对其采取有放回的随机抽样,产生包含m个样本的数据集
D
′
D′
D′,显然D中会有一部分数据被重复采样,也有一部分数据不会被采样。可以估计出,不被采样到的概率是
(
1
−
1
m
)
m
(1-\frac{1}{m})^{m}
(1−m1)m,取极限估计概率
lim
m
→
+
∞
(
1
−
1
m
)
m
=
1
e
≈
0.368
{\lim_{m \to +\infty}}(1-\frac{1}{m})^m=\frac{1}{e}\approx 0.368
m→+∞lim(1−m1)m=e1≈0.368
也就是说,大概有
1
/
3
1/3
1/3的样本没有出现在
D
′
D′
D′中,使用
D
′
D′
D′作为训练集,原始数据集D作为测试集。这种测试结果也称为’包外估计‘(out-of-bag estimate)。
这种方法在大数据集上应用会引入估计偏差,因为对大数据来说 1 / 3 1/3 1/3的数据量足以改变数据的分布。因此,自助法在小样本上很有用。
4 模型评价标准
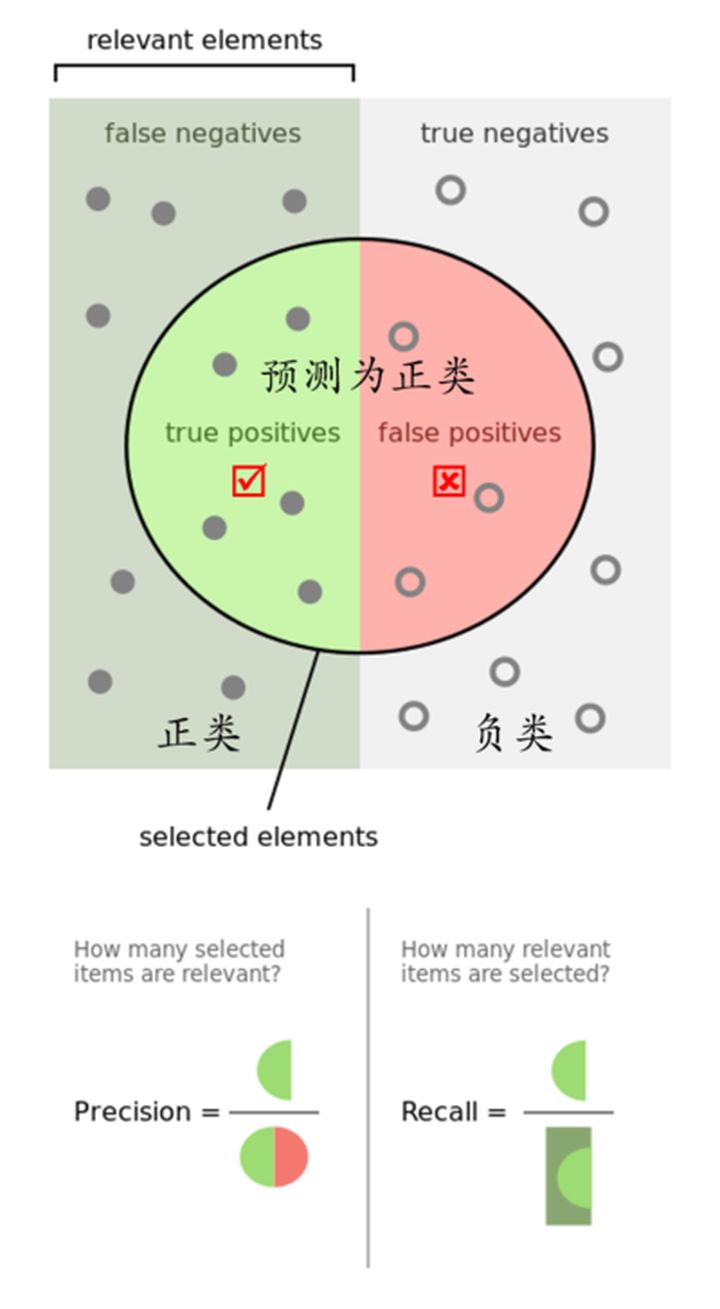
前文已经讨论过模型选择的评价方法,我们还需要模型的评价标准才能满足模型选择。下面分别介绍准确率和召回率。以二分类为例
TP: Ture Positive 真正例
FP: False Positive 假正例
TN: True Negative 真反例
FN: False Negative 假反例
其中TP+FP+TN+FN=总样本集
1. 精确率(Precision)
P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
精确率是对预测结果而言,表示预测为正的结果中有多少是真正例。
2. 召回率 (Recall)
R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP
召回率是对于样本而言,共有 T P + F N TP+FN TP+FN个样本,其中被正确分类的有多少。
3. 准确率 (Accuracy)
A = T P + T N T P + T N + F N + F P A=\frac{TP+TN}{TP+TN+FN+FP} A=TP+TN+FN+FPTP+TN
指的是在所有的分类样本中,分类正确的有多少。
4. F1
精确率和召回率是一对矛盾的指标。召回率高意味着其中的一类被尽可能的分出来了,那么极端情况下,学习器把正负两类全分为正例,此时正例全部被区分出来,召回率很高,但是精确率很低。因此单纯使用一种指标并不是很好的模型评价策略,因此提出F1值。
F
1
=
2
∗
P
∗
R
P
+
R
=
2
∗
T
P
样
例
总
数
+
T
P
−
T
N
F1 = \frac{2*P*R}{P+R}=\frac{2*TP}{样例总数+TP-TN}
F1=P+R2∗P∗R=样例总数+TP−TN2∗TP
F1值为精确率和召回率的调和平均值。
5.ROC与AUC
受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。
ROC曲线的纵轴是‘真正例率’(TPR)正例被正确区分出来的概率,横轴是‘假正例率’(FPR)反例中被错误分类的概率。
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP}{TP+FN}
TPR=TP+FNTP
F P R = F P T N + F P FPR = \frac{FP}{TN+FP} FPR=TN+FPFP
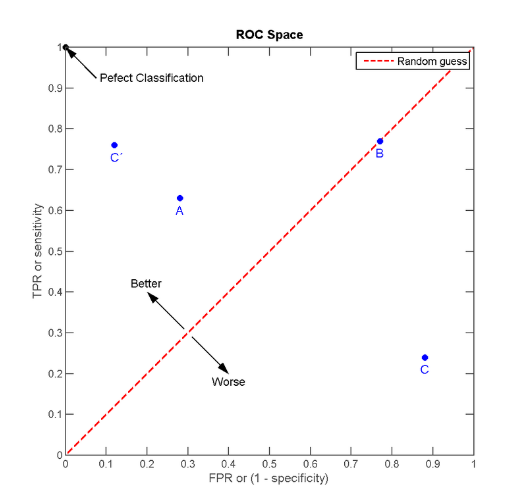
显然,我们希望真正例率越大越好,也就是正例被正确区分出来的概率越大越好,也就是TPR=1。同时,我们也希望假正例率越低越好,因为如果模型把所有样本都分成正例,此时TPR为1,也就是所有的正例都被正确区分出来了,但是所有的反例都被错误的分成了正例,因此假正例率也为1,位于ROC坐标中的右上角(1,1)。这样的模型并不是我们需要的,我们需要正例和反例都尽量被正确的区分出来,所以TPR应该尽量大,FPR尽量小。
例子:假设现在有雷达用于探测敌军飞机,现在雷达反馈10个信号,其中8个是飞机,2个是大鸟。经过分析后确认,其中9个是飞机,1个是鸟。则真正例为 8 9 \frac{8}{9} 98,雷达漏掉了一架飞机。我们希望雷达能够检测到所有的飞机,经过调整后,雷达反馈10个信号,并把10个信号全部标记为飞机,经过分析确认,里面有1架飞机,9只鸟,此时真正例为1,假正例也为1,雷达虽然认出了所有的飞机,但这并不是我们希望的分类器。雷达最好是把所有的飞机都分出来,并且不要把鸟认为飞机,也就是真正例率为1,假正例率为0。显然,这俩个坐标值是相互制约的。

对于不同的模型,ROC曲线被另一个学习器完全包住,则说明后一个学习器性能优于前一个。若两个学习器的ROC曲线交叉,则不能断言谁更优秀。因此使用ROC曲线下面积作为评价标准。ROC曲线下面积称为AUC(Area Under ROC Curve)















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









